Bert 的 Embedding层
本文演示了BERT模型中token、segment和position三种embedding的构造与相加流程。通过定义词表、初始化三个Embedding层,对输入序列的token、句子片段和位置信息分别进行编码,最终将三种embedding逐元素相加得到Transformer的输入表示。示例展示了一个包含[CLS]和[SEP]标记的典型BERT输入格式,输出为11×768维的矩阵,符合BERT Ba
任务概述
目标:演示 BERT 中 token/segment/position 三种 Embedding 的构造与相加流程。
代码逻辑拆解
-
构造词表与超参
vocab定义了样例字符到索引的映射(词表),vocab_size与embedding_dim分别控制词表大小与每个 token embedding 的维度(此处 768 与原生 BERT Base 对齐)。- 三个
nn.Embedding层分别负责 token/segment/position;token_embedding设置了padding_idx=0以在 pad 位置产生零向量。
-
准备输入序列
token、seg、pos分别表示 token ids、句子片段 ids、位置 ids,示例中是一个两句拼接的输入[CLS] ... [SEP] ... [SEP]。- 通过
torch.LongTensor转换为张量,形状均为(seq_len,),保证三路 embedding 可以逐元素对应。
关于 [CLS] 和 [SEP] 的解释:
在 BERT 等 Transformer 模型里,输入通常会被包装成:
[CLS] 第一句 [SEP] 第二句 [SEP]
这三个特殊 token 的英文全称与作用如下:
[CLS],全称:Classification
作用:整个序列的“聚合”表示。BERT 把这一位的输出向量直接拿去做下游分类任务(如句子级情感、NLI),因此叫 Classification token。
[SEP],全称:Separator
作用:分隔不同句子或文本片段,同时告诉模型“左右属于不同语义范围”。在句子对任务里,两个句子之间用一个 [SEP];在单句任务里,句尾也加一个 [SEP] 作为结束标志。
记住:
[CLS] = Classification(分类头)
[SEP] = Separator(分隔符)
-
计算三路 Embedding
token_emb = token_embedding(tensor_token)得到词语语义表示。seg_emb = segment_embedding(tensor_seg)表示句子 A/B 信息。pos_emb = position_embedding(tensor_pos)提供绝对位置信息。
-
逐元素相加得到最终输入
output = token_emb + seg_emb + pos_emb得到 shape 为(seq_len, embedding_dim)的矩阵,即可直接送入后续 Transformer encoder。- 打印
output与output.size()用于验证。
Bert Embedding 机制说明
- Token Embedding:将词/字转换为稠密向量,提供语义基础。
- Segment Embedding:在 NSP 等任务中区分句子 A/B;示例中
seg的前半部分为 0,后半部分为 1。 - Position Embedding:BERT 采用可学习的位置向量,保留序列的顺序信息。
- 向量求和:三种信息在每个位置上叠加,形成 Transformer 的输入表示;在实际模型中还会接 LayerNorm 与 Dropout(本示例未展示)。
该脚本通过一个最小可运行示例展示了上述流程,便于理解 BERT 输入建模的组成。
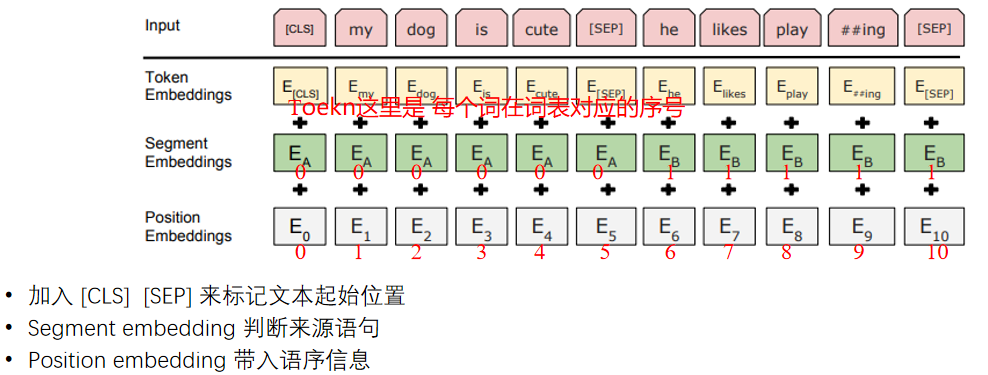
Bert Embedding 完整流程
#coding:utf8
import torch
import torch.nn as nn
'''
embedding层的处理
'''
#构造字符表
vocab = {
"[pad]" : 0,
"my" : 1,
"dog" : 2,
"is" : 3,
"cute" : 4,
"he" : 5,
"likes" : 6,
"play" : 7,
"##ing" : 8,
"[cls]" : 9,
"[sep]" : 10,
"[unk]":11
}
vocab_size = len(vocab)
embedding_dim = 768
token_embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
segment_embedding = nn.Embedding(2, embedding_dim)
position_embedding = nn.Embedding(512, embedding_dim)
#构造输入
# [cls] my dog is cute [sep] he likes play ##ing [sep]
token = [9, 1, 2, 3, 6, 10, 5, 6, 7, 8, 10]
seg = [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
pos = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
tensor_token = torch.LongTensor(token)
tensor_seg = torch.LongTensor(seg)
tensor_pos = torch.LongTensor(pos)
# torch.Size([11])
print(tensor_token.size())
# torch.Size([11])
print(tensor_seg.size())
# torch.Size([11])
print(tensor_pos.size())
#计算embedding
token_emb = token_embedding(tensor_token)
seg_emb = segment_embedding(tensor_seg)
pos_emb = position_embedding(tensor_pos)
# torch.Size([11, 768])
print(token_emb.size())
# torch.Size([11, 768])
print(seg_emb.size())
# torch.Size([11, 768])
print(pos_emb.size())
#加和输出
output = token_emb + seg_emb + pos_emb
# print(output)
# torch.Size([11, 768])
print(output.size())

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)