【AI大模型】如何处理RAG老大难PDF解析?看完这一篇你就知道了!!
MinerU是一款先进的PDF解析工具,通过集成多模型和模块化设计,高效处理复杂PDF。与PaddleOCR相比,其在表格、图片等元素的完整性处理上更优,生成的中间态JSON文件更适合生产环境。该工具对RAG和Deep Research等大模型应用具有重要价值,能将PDF转换为结构化数据,提升大模型理解能力。文章详细介绍了其技术优势、部署流程及源码逻辑,为开发者提供了全面指南。
1.MinerU vs PaddleOCR
- 中间态.json文件对比
博主将MinerU与PaddleOCR解析PDF的中间态.json文件进行对比,发现:二者在公式、表格、图片表现都类似。如果表格中有合并单元格,则二者识别都会出现问题。
MinerU能够将表格的脚注、题目等都作为同一个字典的不同key字段,比如表格2,会将3个字段都放入同一个字典对象中。同样地,MinerU在图片上也能将题目、图片主体、脚注都放在同一个字典对象中。PaddleOCR在表格、图片上都不能实现这一点,PaddleOCR的处理方式是将表格的3个属性作为并列的3个字典顺序放置,而不是作为同一个字典对象。事实上,对于生产环境(需要处理大量复杂文档),我们需要的不是PDF解析的markdown文件,而是中间态.json文件,因此在表格、图片的整体的完整性来说,MinrU胜出。下图中是MinerU识别Table 2的效果:
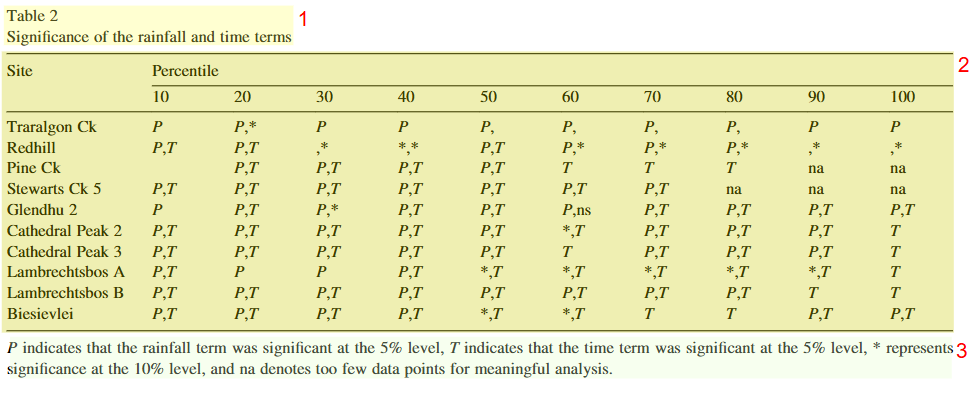
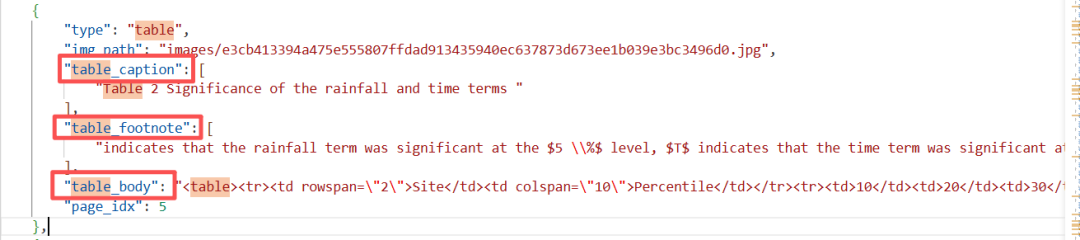
但在MinerU的.json文件中,图片主体解析内容找不到,只是识别出了图片。而PaddleOCR是能够识别图片主体的内容的。这一块PaddleOCR胜出。下图中是MinerU识别Figure 1的效果:
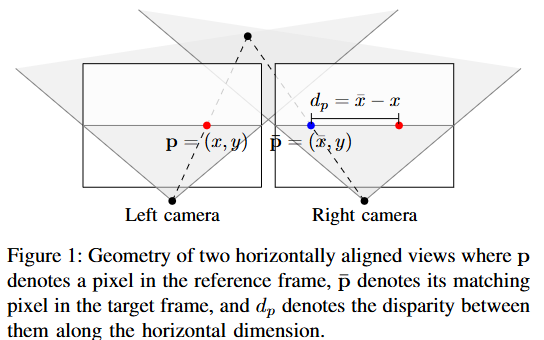

综合对比下来,MinerU的表现稍好。
- 解析PDF有价值吗?
MinerU和PaddleOCR这类解析PDF文档的工具有什么价值呢?
在RAG和Deep Research应用中,多格式文件的解析始终是一大挑战,word、ppt等格式的文件解析的技术栈已经非常成熟了,但对于结构复杂、排版方式多样的PDF文件,目前没有一个非常完美的技术栈。因此,只要PDF解析技术能够攻克,RAG、Deep Research的效果能大大增强。
在RAG应用中,MinerU能够将复杂PDF文档转换为结构化数据,为大模型提供高质量的检索材料。例如,将学术论文中的公式、表格和图表提取为LaTeX、HTML和Markdown格式,便于大模型理解文档内容并生成高质量的回答。
在Deep Research应用中,MinerU的价值更为突出。深度研究通常需要处理大量复杂文档,提取关键信息并进行分析。MinerU能够自动识别文档中的多模态内容,包括文本、公式、表格和图片等,并将它们转换为机器可读的格式,为后续的语义分析、知识提取和数据挖掘提供基础。
MinerU的模块化设计和中间态JSON文件,使得它特别适合与大模型结合使用。例如,可以将中间态JSON文件作为大模型的输入,让模型理解文档的结构和内容;或者将大模型的输出与中间态JSON文件结合,进行更深入的分析和推理。这种结合可以充分发挥大模型的语义理解和推理能力,同时利用MinerU的文档解析能力,实现更智能的研究和应用。
2.MinerU处理复杂PDF文档的技术优势
一,MinerU集成多模型:针对不同类型的文档元素使用专门优化的模型进行处理。例如,对于第1步布局检测,MinerU集成了DocLayout-YOLO、YOLO-v10和LayoutLMv3三种模型,可根据文档类型选择最适合的模型进行处理。这些模型经过大量复杂PDF文档的微调,在论文、教科书、研究报告和财务报告等多样化文档上实现了准确的提取结果。
二,MinerU的微调策略:通过使用多格式的PDF文档注释数据对模型进行微调,MinerU能够更好地适应各种复杂文档类型。例如,DocLayout-YOLO在大规模、多样化的合成文档数据集(DocSynth-300K)上进行了预训练,使其能更好地泛化到现实世界中各种复杂的文档布局 。同时,MinerU还针对特定任务进行了专门优化,如公式识别使用了UniMERNet,这是一种为现实世界场景中的各种公式识别而设计的算法,能够处理复杂的长公式、手写公式和嘈杂的截图公式。
三,MinerU的模块化设计:通过将文档解析过程分解为多个独立但协同工作的模块,MinerU能够灵活应对不同类型的文档挑战。这种设计使得每个模块都能专注于特定任务,同时整体流程又能保持高效和准确。例如,对于扫描版PDF,MinerU会自动启用OCR模式;而对于文本型PDF,则直接提取文本内容,避免不必要的处理步骤。
四,MinerU的中间态JSON文件:与PaddleOCR一样,MinerU的中间态JSON文件具备的灵活性。该文件包含了完整的文档解析信息,包括页面元数据、元素坐标、类型分类、OCR文本、公式LaTeX代码、表格结构等。我们可以根据需求自定义输出格式,如Markdown、HTML或JSON,也可以提取特定元素进行深入分析。这种设计使得MinerU不仅能够满足基本的文档转换需求,还能支持更复杂的下游应用,如RAG系统和知识图谱构建。
3.布局检测和模型选择的关联机制
MinerU的布局检测是整个文档解析流程的第一步,其质量直接影响后续所有任务的效果。MinerU提供了多种布局检测模型,包括DocLayout-YOLO、YOLO-v10和LayoutLMv3,这些模型各有特点,适用于不同类型的文档。
布局检测模型的选择直接影响后续解析任务的执行方式和效果。例如,DocLayout-YOLO是基于YOLO目标检测框架进行优化的,将版面分析任务视为计算机视觉中的对象检测问题 。该模型在DocSynth-300K数据集上进行了预训练,并引入了GL-CRM模块,使模型能够灵活调整其"视野",从而有效处理从单行标题到整页表格等不同尺度的版面元素 。这种全局到局部的感受野使其在检测表格边界和公式区域时具有优势。
相比之下,LayoutLMv3则更擅长理解文档中的文本布局和语义关系。该模型通过整合视觉和语言信息,能够更好地识别文本块之间的层次结构,这对于确定阅读顺序和段落划分非常关键。因此,MinerU会根据文档类型和内容特点,灵活选择最适合的布局检测模型。
布局检测模型的输出结果是后续所有解析任务的基础。这些结果以JSON格式存储,包含每个检测到的元素的类型、边界框坐标和置信度等信息,为公式检测、表格识别和OCR等任务提供了精确的定位和分类。例如,当检测到表格区域时,系统会调用表格识别模型进行处理;当检测到公式区域时,则会调用公式识别模型。这种基于布局检测结果的任务触发机制,确保了处理流程的高效和精准。
4.PDF分类方法实现机制
MinerU的PDF分类方法决定了后续使用哪种解析策略。PDF分类主要通过分析文档元数据、内容特征和格式类型来实现,具体包括以下几个方面:
一,MinerU会检查PDF的元数据,确定其基本类型。例如,判断文档是否为扫描版(图像型PDF)、文本型PDF(可复制文本)或图层型PDF(文本不可复制,解析乱码)。这种初步分类有助于确定是否需要启用OCR处理。对于扫描版PDF,MinerU会自动启用OCR模式;而对于文本型PDF,则直接提取文本内容,提高处理效率。
二,MinerU会分析文档内容特征,如图像占比、文本结构和排版方式等。比如,通过检测文档中是否存在大量图像或表格,来判断是否需要使用特定的模型进行处理。这种基于内容特征的分类,有助于选择最适合的模型组合,提高解析质量。
三,MinerU还支持通过我们配置参数指定解析方法。比如,我们可以通过命令行参数--method指定使用ocr、txt或auto模式,后者会根据文档类型自动选择最佳解析策略。这种设计既考虑了自动化处理,也提供了手动控制的灵活性。
在代码实现中,PDF分类主要通过classify()方法完成。该方法接收PDF的二进制数据作为输入,返回SupportedPdfParseMethod枚举值,指示应使用OCR还是TXT方法进行解析。具体实现可能包括以下几个步骤:
- 检查PDF是否为扫描版,这通常通过检测文档是否主要由图像组成来实现。
- 分析文档中的文本可复制性,判断是否为图层型PDF。
- 检测文档是否存在乱码,这可能与编码格式或字体嵌入有关。
- 根据上述分析结果,结合文档类型(如论文、财务报告等),确定最佳解析方法。
需要说明:MinerU的PDF分类方法并不是一个独立的模型,而是结合了多种分析技术和逻辑判断。这种设计使得分类过程更加高效和准确,同时避免了额外的模型开销。
5.OCR处理后的文本语义连贯性保障
MinerU在OCR处理后的文本语义连贯性保障方面采用了多种技术手段。文本语义连贯性主要通过布局分析和跨距结果处理来实现,确保提取的文本符合人类的阅读顺序。
一,MinerU使用DocLayout-YOLO等模型进行布局分析,准确定位文档中的文本块、表格、图片和公式等元素的位置和层次关系。这种布局信息为后续的文本排序提供了基础,确保提取的文本按照文档的实际排版顺序排列。
二,MinerU实现了基于版面的文本排序和拼接机制。在管线处理阶段,系统会根据布局检测结果,确定块级别的顺序,删减无用元素,并依靠版面对内容排序、拼装,保证正文流畅。处理方式包括坐标修复、高iou处理、图片与表格描述合并、公式替换、图标转储、Layout排序、无用移出和复杂布局过滤等。
三,MinerU还支持多语言OCR处理,使用PaddleOCR模型识别80多种语言的文本。对于混合语言文档,系统会自动识别并转换为相应的语言格式,减少语义混乱的可能性。
在代码实现中,OCR处理后的文本语义连贯性保障主要通过pipe_ocr_mode()和pipe_txt_mode()方法完成。这些方法接收OCR或文本提取的结果,结合布局信息,生成结构化的中间态JSON文件,其中包含了文本块的位置、类型和内容等信息。我们作为使用者可以根据这些信息,进一步调整文本的顺序和格式,确保语义连贯。
值得注意的是,MinerU的文本语义连贯性保障并不是一个完美的过程,特别是在处理高度复杂或非标准排版的文档时。因此,系统提供了中间态JSON文件,方面我们进行人工检查和调整,确保提高文本的语义连贯性。
6.表格识别
MinerU的表格识别模块并不是孤立的,而是与布局检测、OCR和公式识别等模块紧密协作。布局检测模型会先定位表格区域,OCR模型提取表格中的文本,表格识别模型再根据这些信息重建表格结构。
MinerU提供了两种表格识别方式:StructEqTable和PaddleOCR+TableMaster,它们在技术实现和适用场景上有显著差异。StructEqTable更适合处理复杂中文表格和需要高质量结构化输出的场景,如学术论文、财务报告等。而****PaddleOCR+TableMaster则更适合资源受限环境或处理简单表格,如发票、名片等。
| 特性 | StructEqTable | PaddleOCR+TableMaster |
|---|---|---|
| 技术原理 | 多模态大模型端到端解析 | OCR文本提取+表格结构识别 |
| 语言支持 | 优秀(特别是中文) | 良好(依赖OCR语言支持) |
| 处理速度 | 较慢(依赖GPU算力) | 较快(算法轻量) |
| 复杂表格处理 | 强(支持合并单元格、跨页表格) | 弱(主要处理简单表格) |
| 输出格式 | LaTeX/HTML/Markdown | HTML |
| 算力需求 | 高(需要GPU) | 低(CPU即可) |
| 部署复杂度 | 高(模型较大) | 低(模块化设计) |
7.多页PDF的并行处理机制
从demo代码来看,MinerU目前主要采用顺序处理的方式处理多页PDF文档。在doc_analyze()函数中,系统会遍历所有页面,按顺序处理每一页的内容。这种设计虽然简单,但在处理多页PDF时可能存在性能瓶颈。
然而,MinerU的架构设计为多页PDF的并行处理提供了可能性。具体来说,框架的分页抽象(Dataset和apply()方法)允许通过多进程/线程拆分页面任务,实现并行处理。例如,可以将PDF的不同页面分配给不同的处理线程,充分利用多核CPU或GPU的计算资源,提高处理速度。
在代码实现中,PymuDocDataset类实现了页面的迭代和访问,使得系统能够按需获取特定页面的数据。这种设计使得并行处理成为可能,因为每个页面可以独立处理,无需依赖其他页面的结果。此外,ModelSingleton类管理模型实例,确保模型只初始化一次,避免了并行处理中的重复初始化开销。
博主发现,MinerU的并行处理能力目前尚未在官方版本中完全实现,但通过框架的模块化设计,我们可以根据需求自行扩展。比如,在apply()方法中,可以添加多进程支持,将页面处理任务分配给不同的进程。或者使用线程池,提高处理效率。这种灵活性是MinerU作为开源工具的重要优势。
8.中间态JSON文件的价值
中间态JSON文件是MinerU处理流程中的关键产出,具有多方面的重要价值和作用。
一,中间态JSON文件提供了完整的文档解析信息:包括页面元数据、元素坐标、类型分类、OCR文本、公式LaTeX代码、表格结构等。因此我们能够根据需求自定义输出格式,如Markdown、HTML或JSON,也可以提取特定元素进行深入分析。例如,可以仅提取文档中的公式或表格,用于后续的数学符号识别或表格数据提取。
二,这种中间态JSON文件支持灵活的后处理和定制化:MinerU的管线处理阶段会将模型解析得到的数据输入到处理管线中,进行后处理,如确定块级别的顺序、删减无用元素、依靠版面对内容排序、拼装等。这些处理方式包括坐标修复、高iou处理、图片与表格描述合并、公式替换、图标转储、Layout排序、无用移出和复杂布局过滤等。通过中间态JSON文件,你可以修改这些处理逻辑,添加自己的后处理步骤,或调整现有步骤的参数,以满足特定需求。
三,便于人工质检和错误修正:在MinerU生成的middle.json中间态文档中,每个块都是一个元素,包含相应的页码、位置、类型和内容等信息。这使得人工检查错误(如公式识别错误、表格边界偏差)时,能够精确定位问题所在,并进行修正。例如,可以修改中间态JSON中的公式内容,然后重新生成Markdown文件,无需重新运行整个解析流程。
四,适合生产环境:中间态JSON文件为下游应用提供了统一的数据接口,无论是RAG系统、知识图谱构建还是其他文档处理应用,都可以基于中间态JSON文件进行开发,无需了解底层的模型和处理逻辑。这种统一的数据接口降低了集成难度,提高了系统的可扩展性。
在代码实现中,中间态JSON文件通过pipe_result.get_middle_json()方法获取,并通过pipe_result.dump_middle_json()方法保存到文件。你可以修改这些方法,添加自定义的后处理逻辑,或调整JSON结构,来满足特定需求。
需要提醒,中间态JSON文件的结构和内容会随着MinerU版本的更新而变化。比如,在0.9.2版本中,MinerU集成了StructTable-InternVL2-1B模型以实现表格识别功能;而在0.9.0版本中,系统进行了广泛的代码重构,优化了配置文件功能开关,添加了独立的公式检测开关,提高了处理速度和内存使用效率。
9.MinerU部署教程及源代码逻辑
- MinerU本地部署教程
(一)PowerShell 中运行下面代码,创建Conda环境并安装magic-pdf[full]
conda create -n mineru 'python=3.12' -y
conda activate mineru
pip install -U "magic-pdf[full]" -i https://mirrors.aliyun.com/pypi/simple
(二)PowerShell 中运行下面代码,拉取MinerU源码
git clone https://github.com/opendatalab/MinerU.git
cd Mineru
(三)PowerShell 中运行下面代码,从modelscope下载模型
pip install modelscope
python mineru/cli/models_download.py
(四)PowerShell 中运行下面代码,使用国内 Hugging Face 镜像源
$env:HF_ENDPOINT="https://hf-mirror.com"
(五)PowerShell 中运行下面代码,解析demo中的pdf
python demo/demo.py
- demo.py源代码逐行注释
import copy
import json
import os
from pathlib import Path
from loguru import logger
from mineru.cli.common import convert_pdf_bytes_to_bytes_by_pypdfium2, prepare_env, read_fn
from mineru.data.data_reader_writer import FileBasedDataWriter
from mineru.utils.draw_bbox import draw_layout_bbox, draw_span_bbox
from mineru.utils.enum_class import MakeMode
from mineru.backend.vlm.vlm_analyze import doc_analyze as vlm_doc_analyze
from mineru.backend.pipeline.pipeline_analyze import doc_analyze as pipeline_doc_analyze
from mineru.backend.pipeline.pipeline_middle_json_mkcontent import union_make as pipeline_union_make
from mineru.backend.pipeline.model_json_to_middle_json import result_to_middle_json as pipeline_result_to_middle_json
from mineru.backend.vlm.vlm_middle_json_mkcontent import union_make as vlm_union_make
from mineru.utils.models_download_utils import auto_download_and_get_model_root_path
def do_parse(
output_dir: str, # 输出目录,用于存储解析结果
pdf_file_names: list[str], # PDF文件名列表
pdf_bytes_list: list[bytes], # PDF字节数据列表
p_lang_list: list[str], # 每个PDF对应的语言设置,默认'ch'(中文)
backend: str = "pipeline", # 解析PDF使用的后端,默认'pipeline'
parse_method: str = "auto", # 解析方法,默认'auto'(自动选择)
formula_enable: bool = True, # 是否启用公式解析
table_enable: bool = True, # 是否启用表格解析
server_url: str | None = None, # 当使用'vlm-sglang-client'后端时,指定服务器地址
f_draw_layout_bbox: bool = True, # 是否绘制布局边界框
f_draw_span_bbox: bool = True, # 是否绘制文本跨度边界框
f_dump_md: bool = True, # 是否保存Markdown文件
f_dump_middle_json: bool = True, # 是否保存中间JSON文件
f_dump_model_output: bool = True, # 是否保存模型输出文件
f_dump_orig_pdf: bool = True, # 是否保存原始PDF文件
f_dump_content_list: bool = True, # 是否保存内容列表文件
f make md mode: MakeMode = MakeMode.MM_MD, # Markdown生成模式,默认MM_MD
start_page_id: int = 0, # 开始解析的页面ID,默认0(从第一页开始)
end_page_id: int | None = None # 结束解析的页面ID,默认None(解析所有页面)
):
# PDF解析后端选择
if backend == "pipeline":
# 对每个PDF字节数据执行页面范围提取
for idx, pdf_bytes in enumerate(pdf_bytes_list):
# 使用pypdfium2库提取指定页面范围的PDF内容
new_pdf_bytes = convert_pdf_bytes_to_bytes_by_pypdfium2(
pdf_bytes, start_page_id, end_page_id
)
# 更新PDF字节列表,替换为提取后的数据
pdf_bytes_list[idx] = new_pdf_bytes
# 执行PDF文档分析,根据parse_method选择解析方式
infer_results, all_image_lists, all_pdf_docs, lang_list, ocr_enabled_list = \
pipeline_doc_analyze(
pdf_bytes_list,
p_lang_list,
parse_method=parse_method,
formula_enable(formula_enable,
table_enable=table_enable
)
# 遍历处理每个解析结果
for idx, model_list in enumerate(infer_results):
# 创建中间JSON的深度拷贝
model_json = copy.deepcopy(model_list)
# 获取对应的PDF文件名
pdf_file_name = pdf_file_names[idx]
# 准备输出环境,创建本地图像目录和Markdown目录
local_image_dir, local_md_dir = prepare_env(
output_dir, pdf_file_name, parse_method
)
# 创建文件写入器实例
image作家, md作家 = FileBasedDataWriter(local_image_dir), \
FileBasedDataWriter(local_md_dir)
# 获取当前PDF的图像列表和PDF文档对象
images_list = all_image_lists[idx]
pdf_doc = all_pdf_docs[idx]
# 获取当前PDF的语言设置
_lang = lang_list[idx]
# 获取OCR是否启用的状态
_ocr_enable = ocr_enabled_list[idx]
# 将解析结果转换为中间JSON格式
middle_json = pipeline_result_to_middle_json(
model_list,
images_list,
pdf_doc,
image_writer,
_lang,
_ocr_enable,
formula_enable
)
# 获取PDF元信息
pdf_info = middle_json["pdf_info"]
# 根据配置绘制布局边界框
if f_draw_layout_bbox:
# 使用绘制函数生成带布局框的PDF
draw_layout_bbox(
pdf_info,
pdf_bytes,
local_md_dir,
f"{pdf_file_name}_layout.pdf"
)
# 根据配置绘制文本跨度边界框
if f_draw_span_bbox:
# 使用绘制函数生成带文本框的PDF
draw_span_bbox(
pdf_info,
pdf_bytes,
local_md_dir,
f"{pdf_file_name}_span.pdf"
)
# 根据配置保存原始PDF文件
if f_dump_orig_pdf:
# 使用文件写入器保存原始PDF
md_writer.write(
f"{pdf_file_name}_origin.pdf",
pdf_bytes,
)
# 根据配置生成并保存Markdown文件
if f_dump_md:
# 获取图像目录的基准名
image_dir = str(os.path.basename(local_image_dir))
# 使用联合制作函数生成Markdown内容
md_content_str = pipeline_union_make(
pdf_info,
f make md mode,
image_dir
)
# 将Markdown内容写入文件
md_writer.write_string(
f"{pdf_file_name}.md",
md_content_str,
)
# 根据配置生成并保存内容列表文件
if f_dump_content_list:
# 获取图像目录的基准名
image_dir = str(os.path.basename(local_image_dir))
# 使用联合制作函数生成内容列表
content_list = pipeline_union_make(
pdf_info,
MakeMode含量列表,
image_dir
)
# 将内容列表写入JSON文件
md_writer.write_string(
f"{pdf_file_name}_content_list.json",
json.dumps(content_list, ensure_ascii=False, indent=4),
)
# 根据配置保存中间JSON文件
if f_dump_middle_json:
# 将中间JSON数据写入文件
md作家.write_string(
f"{pdf_file_name}_middle.json",
json.dumps(middle_json, ensure_ascii=False, indent=4),
)
# 根据配置保存模型输出文件
if f_dump_model_output:
# 将模型列表转换为字符串,每个元素用分隔线隔开
model_output = ("n" + "-" * 50 + "n").join(model_list)
# 将模型输出写入文本文件
md作家.write_string(
f"{pdf_file_name}_model.json",
model_output,
)
# 记录本地输出目录信息
logger.info(f"本地输出目录是 {local_md_dir}")
else:
# 如果使用其他后端,检查是否以'vlm-'开头
if backend.startswith("vlm-"):
# 去除'vlm-'前缀,可能用于指定特定的VLMServer
backend = backend[4:]
# 非pipeline后端强制设置为OCR方法
parse_method = "ocr"
# 遍历处理每个PDF字节数据
for idx, pdf_bytes in enumerate(pdf_bytes_list):
# 获取对应的PDF文件名
pdf_file_name = pdf_file_names[idx]
# 使用pypdfium2库提取指定页面范围的PDF内容
pdf_bytes = convert_pdf_bytes_to_bytes_by_pypdfium2(
pdf_bytes, start_page_id, end_page_id
)
# 准备输出环境,创建本地图像目录和Markdown目录
local_image_dir, local_md_dir = prepare_env(
output_dir, pdf_file_name, parse_method
)
# 创建文件写入器实例
image作家, md作家 = FileBasedDataWriter(local_image_dir), \
FileBasedDataWriter(local_md_dir)
# 执行VLMServer解析分析,返回中间JSON和推理结果
middle_json, infer_result = vlm_doc_analyze(
pdf_bytes,
image_writer(image作家),
backend(backend),
server_url=server_url
)
# 获取PDF元信息
pdf_info = middle_json["pdf_info"]
# 根据配置绘制布局边界框
if f_draw_layout_bbox:
# 使用绘制函数生成带布局框的PDF
draw_layout_bbox(
pdf_info,
pdf_bytes,
local_md_dir,
f"{pdf_file_name}_layout.pdf"
)
# 根据配置绘制文本跨度边界框
if f_draw_span_bbox:
# 使用绘制函数生成带文本框的PDF
draw_span_bbox(
pdf_info,
pdf_bytes,
local_md_dir,
f"{pdf_file_name}_span.pdf"
)
# 根据配置保存原始PDF文件
if f_dump_orig_pdf:
# 使用文件写入器保存原始PDF
md作家.write(
f"{pdf_file_name}_origin.pdf",
pdf_bytes,
)
# 根据配置生成并保存Markdown文件
if f_dump_md:
# 获取图像目录的基准名
image_dir = str(os.path.basename(local_image_dir))
# 使用联合制作函数生成Markdown内容
md_content_str = vlm_union_make(
pdf_info,
f make md mode,
image_dir
)
# 将Markdown内容写入文件
md作家.write_string(
f"{pdf_file_name}.md",
md_content_str,
)
# 根据配置生成并保存内容列表文件
if f_dump_content_list:
# 获取图像目录的基准名
image_dir = str(os.path.basename(local_image_dir))
# 使用联合制作函数生成内容列表
content_list = vlm_union_make(
pdf_info,
MakeMode含量列表,
image_dir
)
# 将内容列表写入JSON文件
md作家.write_string(
f"{pdf_file_name}_content_list.json",
json.dumps(content_list, ensure_ascii=False, indent=4),
)
# 根据配置保存中间JSON文件
if f_dump_middle_json:
# 将中间JSON数据写入文件
md作家.write_string(
f"{pdf_file_name}_middle.json",
json.dumps(middle_json, ensure_ascii=False, indent=4),
)
# 根据配置保存模型输出文件
if f_dump_model_output:
# 将推理结果列表转换为带分隔线的文本
model_output = ("n" + "-" * 50 + "n").join(infer_result)
# 将模型输出写入文本文件
md作家.write_string(
f"{pdf_file_name}_model_output.txt",
model_output,
)
# 记录本地输出目录信息
logger.info(f"本地输出目录是 {local_md_dir}")
def parse_doc(
path_list: list[Path], # 待解析的文档路径列表,支持PDF和图像文件
output_dir: str, # 输出目录路径,用于存储解析结果
lang: str = "ch", # PDF语言设置,默认'ch'(中文)
backend: str = "pipeline", # PDF解析后端,默认'pipeline'
method: str = "auto", # PDF解析方法,默认'auto'(自动选择)
server_url: str | None = None, # 当使用'vlm-sglang-client'后端时,指定服务器地址,默认None
start_page_id: int = 0, # 开始解析的页面ID,默认0(从第一页开始)
end_page_id: int | None = None # 结束解析的页面ID,默认None(解析所有页面)
):
#此函数负责读取文档路径列表中的文件,提取PDF字节数据,并调用do_parse函数进行解析和输出。
try:
# 初始化文件名、字节数据和语言列表
file_name_list = []
pdf_bytes_list = []
lang_list = []
# 遍历处理每个文档路径
for path in path_list:
# 获取文件名(不含扩展名)
file_name = str(Path(path).stem)
# 读取文件内容为字节数据
pdf_bytes = read_fn(path)
# 将文件名添加到列表
file_name_list.append(file_name)
# 将PDF字节数据添加到列表
pdf_bytes_list.append(pdf_bytes)
# 将语言设置添加到列表
lang_list.append(lang)
# 调用do_parse函数进行PDF解析和输出
do_parse(
output_dir=output_dir,
pdf_file_names=file_name_list,
pdf_bytes_list=pdf_bytes_list,
p_lang_list=lang_list,
backend=backend,
parse_method=method,
server_url=server_url,
start_page_id=start_page_id,
end_page_id=end_page_id
)
except Exception as e:
# 记录异常信息
logger.exception(e)
# 向上抛出异常(根据需求决定是否需要)
# raise
if __name__ == '__main__':
#读取命令行参数,准备PDF文件列表,并调用parse_doc函数进行解析。
# 获取当前脚本所在目录的绝对路径
__dir__ = os.path.dirname(os.path.abspath(__file__))
# PDF文件输入目录路径
pdf_files_dir = os.path.join(__dir__, "pdfs")
# 输出结果目录路径
output_dir = os.path.join(__dir__, "output")
# 支持的PDF文件后缀列表
pdf_suffixes = [".pdf"]
# 支持的图像文件后缀列表
image_suffixes = [".png", ".jpeg", ".jpg"]
# 初始化文档路径列表
doc_path_list = []
# 遍历PDF目录中的所有文件
for doc_path in Path(pdf_files_dir).glob('*'):
# 检查文件后缀是否在支持的列表中
if doc_path.suffix in pdf_suffixes + image_suffixes:
# 将符合条件的文件路径添加到列表
doc_path_list.append(doc_path)
# 调用parse_doc函数进行文档解析
parse_doc(
path_list=doc_path_list,
output_dir(output_dir),
lang="ch",
backend="pipeline",
method="auto",
server_url=None,
start_page_id=0,
end_page_id=None
)
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献370条内容
已为社区贡献370条内容

所有评论(0)