从零开始理解 Embedding,掌握向量检索的核心技术
Embedding 的工作原理是啥
什么是 Embedding
1.1 一句话解释
Embedding(嵌入)= 把文字转换成数字向量
1.2 形象理解
想象你要给每个人建立档案
传统方式(文字)

Embedding 方式(向量)
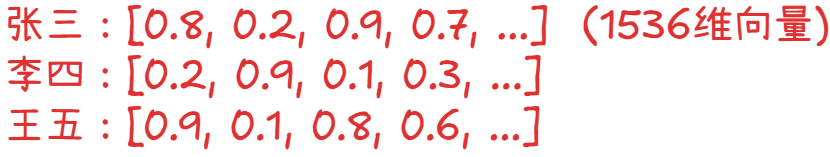
这些数字向量包含了所有信息,而且相似的人向量会更接近。
1.3 核心特点
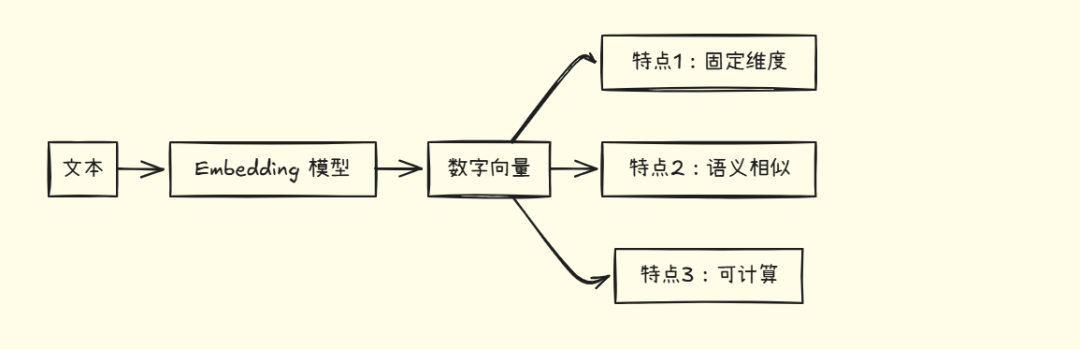
三个核心特点
- \1. 固定维度:无论文本长短,都转换为固定长度的向量(如 768 维、1536 维)
- \2. 语义相似:意思相近的文本,向量也相近
- \3. 可计算:可以用数学方法计算相似度

2. 为什么需要 Embedding
2.1 计算机不懂文字
问题: 计算机如何判断两段文字是否相似?
错误方法:字符串匹配

正确方法:Embedding + 向量相似度

2.2 应用场景

2.3 实际案例对比
场景:在知识库中搜索
用户问题: “如何重置密码?”
知识库中的文档:
- \1. “忘记密码怎么办”
- \2. “修改登录凭证的方法”
- \3. “公司年会时间安排”
传统关键词搜索:
- • 搜索 “重置密码”
- • 结果:无匹配 (因为知识库中没有"重置"这个词)
Embedding 语义搜索:
-
• 计算问题的 embedding
-
• 与所有文档的 embedding 计算相似度
-
• 结果:
-
- • 文档1:“忘记密码怎么办” - 相似度 0.89
- • 文档2:“修改登录凭证的方法” - 相似度 0.76
- • 文档3:“公司年会时间安排” - 相似度 0.12
3. Embedding 的工作原理
3.1 从词向量到句子向量
早期:Word2Vec(词向量)
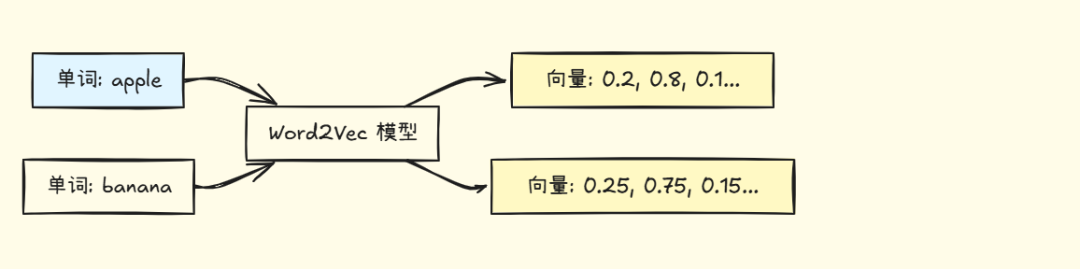
特点:
- • 只能处理单个词
- • 相似的词向量相近(apple 和 orange)
现代:Transformer(句子向量)
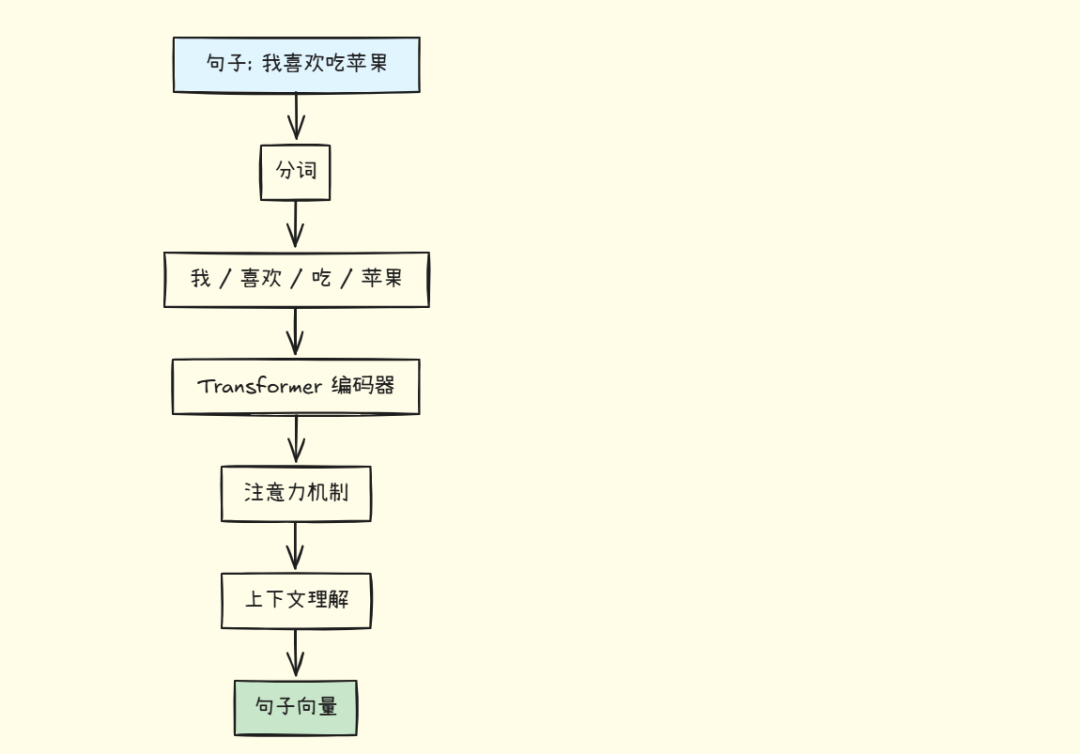
特点:
- • 可以处理整个句子/段落
- • 理解上下文关系
- • 捕捉语义信息
3.2 Embedding 模型的训练
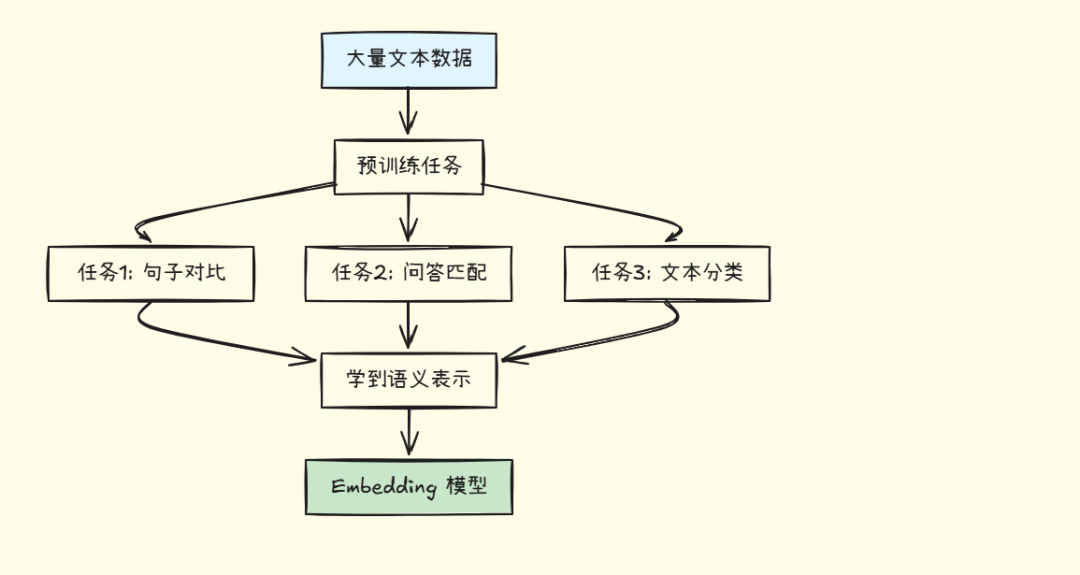
训练方式举例:
-
\1. 对比学习
-
- • 正样本对:
"天气真好" <-> "今天天气不错"→ 向量要接近 - • 负样本对:
"天气真好" <-> "我喜欢编程"→ 向量要远离
- • 正样本对:
-
\2. 问答对训练
-
- • 问题:
"如何学习 Python?" - • 答案:
"可以从基础语法开始..." - • 目标:问题和答案的 embedding 要接近
- • 问题:
3.3 维度的意义
为什么是 768 维或 1536 维?
每一维可以理解为捕捉某种语义特征:

直观比喻:
- • 1 维:只能表示"大小"(一条线)
- • 2 维:能表示"长宽"(一个平面)
- • 3 维:能表示"长宽高"(一个空间)
- • 1536 维:能表示 1536 种不同的语义特征(超空间)
4. 向量相似度计算
4.1 三种常见相似度算法
余弦相似度(最常用)
公式:

图示:
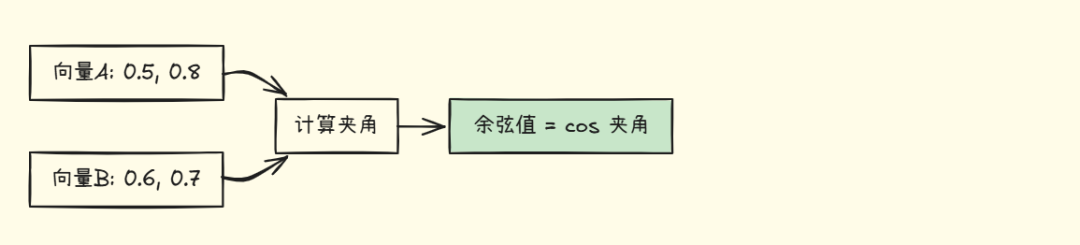
优点:
- • 不受向量长度影响
- • 只关注方向
- • 适合文本相似度
欧氏距离

点积(内积)

对比
余弦相似度:文本语义比较、文档检索排序、内容推荐系统(多数场景用的都是这个)
欧氏距离:空间位置测量、聚类分析、异常检测
点积相似度:快速初步筛选、计算资源有限场景(说白了,就是比较拉)
4.2 实际例子

余弦相似度计算:
 image-20251123230640603
image-20251123230640603
4.3 相似度阈值设置

5. 常见的 Embedding 模型
5.1 国际主流模型

5.2 国内主流模型

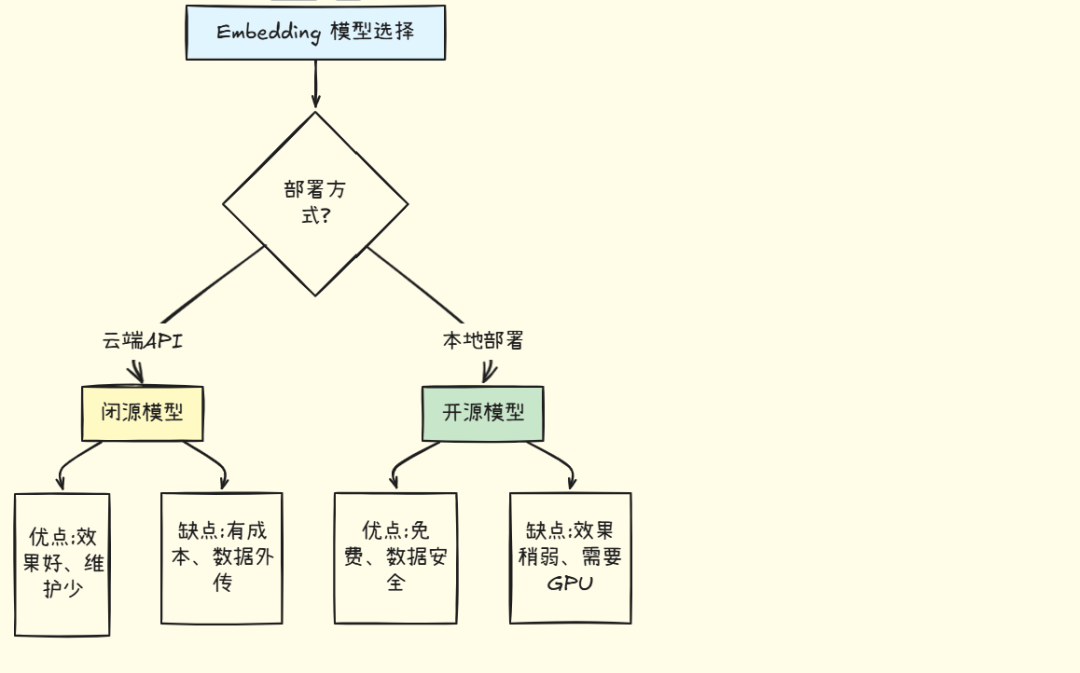
5.3 开源 vs 闭源
5.4 模型性能对比
中文检索任务 Benchmark:

推荐选择:
- • 中文 RAG:阿里 text-embedding-v4
- • 预算有限:bge-large-zh(开源)
- • 英文为主:OpenAI text-embedding-3-small
6. 向量数据库介绍
6.1 为什么需要向量数据库?
问题: 假设你有 100 万个文档的 embedding
暴力搜索:

向量数据库:

6.2 常见向量数据库对比

6.3 Milvus 架构
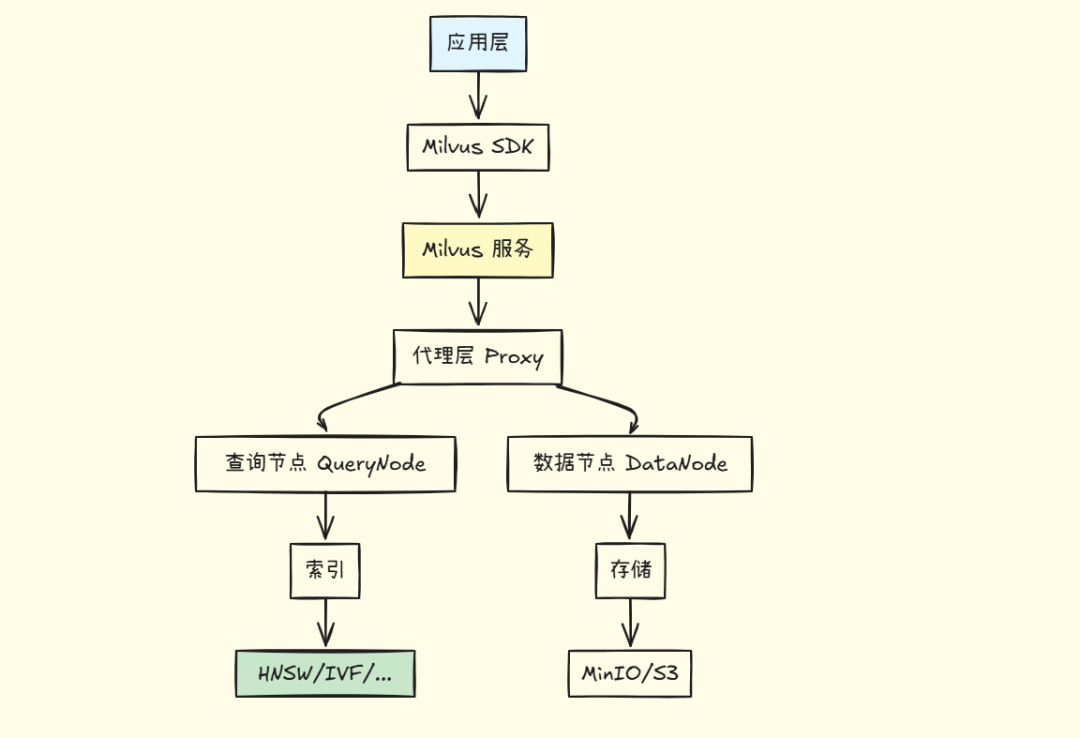
核心概念:
-
\1. Collection(集合)
-
- • 类似关系型数据库的"表"
- • 存储同一类型的向量
-
\2. Field(字段)
-
- • 向量字段:存储 embedding
- • 标量字段:存储元数据(ID、文本、标签等)
-
\3. Index(索引)
-
- • HNSW:高性能,内存占用大
- • IVF_FLAT:平衡性能和内存
- • DiskANN:处理超大规模
-
\4. Partition(分区)
-
- • 按业务逻辑分区(如按日期、类别)
- • 提高查询效率
6.4 向量检索流程
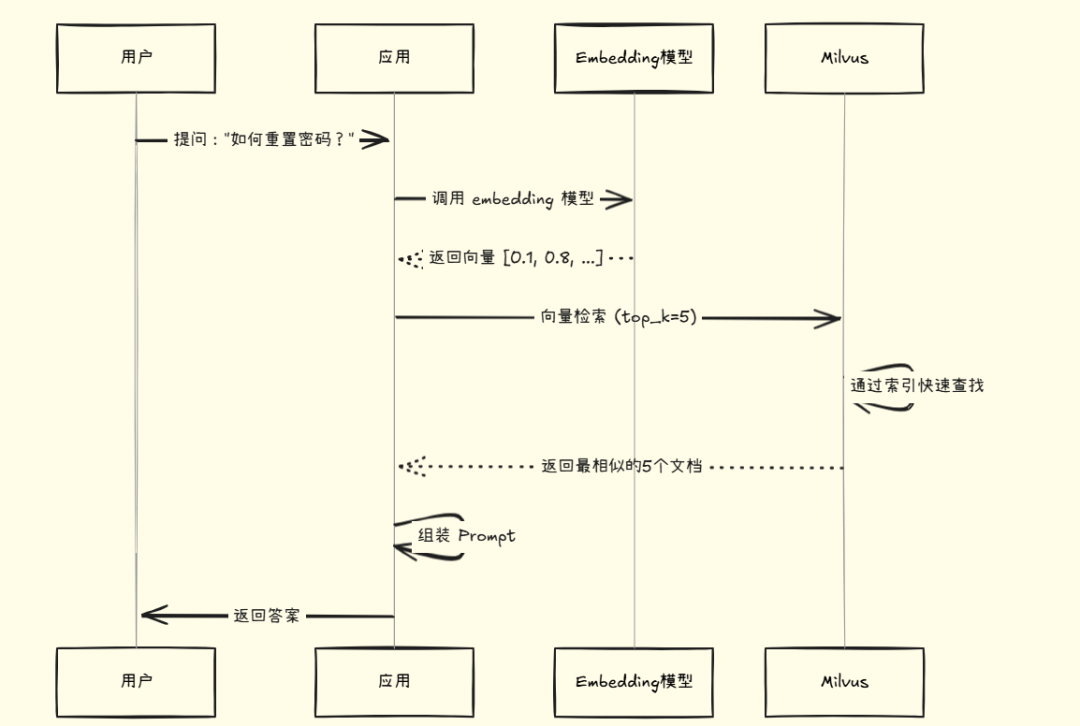
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献260条内容
已为社区贡献260条内容

所有评论(0)