Transformer到底有啥层数?搞懂这个,才算摸到大模型门道!
Transformer架构通过自注意力机制解决了传统RNN处理序列转换(Seq2Seq)问题的局限性。其核心包括:1)多头自注意力层捕捉序列全局依赖关系,2)前馈神经网络进行非线性特征变换,3)残差连接和层归一化防止梯度消失。Decoder采用掩码机制实现自回归生成,并通过交叉注意力整合Encoder的语义信息。这种架构显著提升了机器翻译、对话系统等Seq2Seq任务的性能,成为大模型的基础框架。
当你与DeepSeek对话,它能够理解问题并给出恰当回答时,你是否想过这种"理解"是如何实现的?
这背后源于一个经典问题:如何让机器将一个序列转换为另一个序列?,也就是Seq2Seq(Sequence-to-Sequence)问题,以及解决这个问题的经典架构——Transformer。
Seq2Seq本质上是一类问题的抽象描述,而不是特定的模型架构,就像"分类问题"描述的是从输入到类别标签的映射,"Seq2Seq问题"描述的是从一个序列到另一个序列的转换。
机器翻译中将Hello翻译为你好,文本摘要将长文章压缩为核心要点,对话系统理解问题并给出回答,代码生成将自然语言描述转化为程序代码,都是Seq2Seq问题的应用。
在Transformer出现之前,业界主要使用基于RNN的Encoder-Decoder架构:
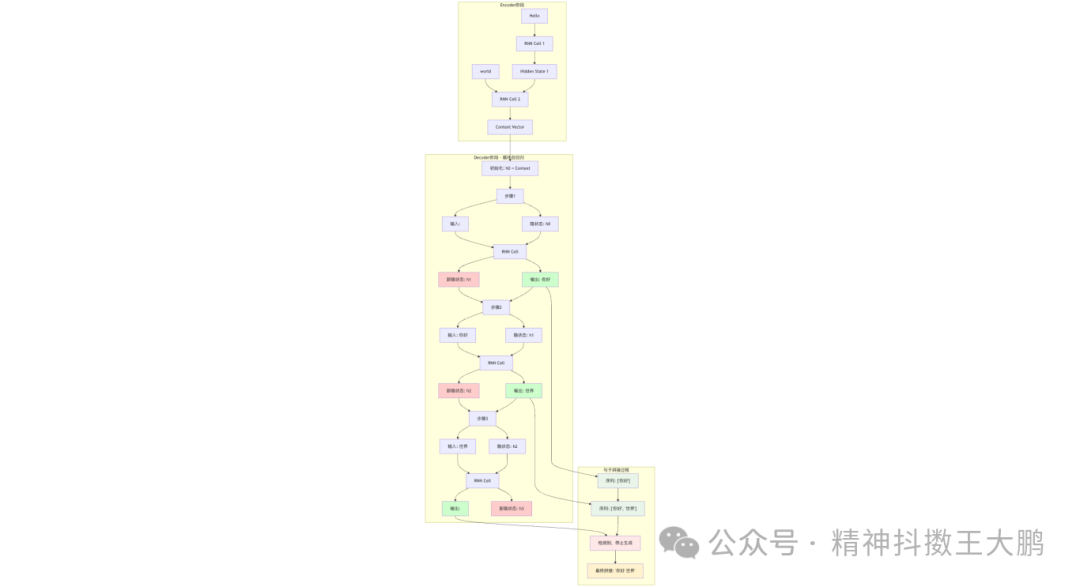
以翻译任务举例,这种方法的思路很直观:从一个起始状态开始,每一步基于当前的理解状态(隐状态)和已生成的内容,预测并生成下一个词,然后更新理解状态,如此循环直到生成完整的文本。
但RNN方案存在根本性问题:Encoder阶段需要把所有信息都要压缩到固定长度的向量中,由于串行处理的梯度消失问题,RNN无法捕捉到长距离的依赖关系。
2017年,《Attention Is All You Need》提出了完全基于注意力机制的Transformer架构,Transformer沿用了经典的Encoder-Decoder结构,但不再是时间步长的依赖。
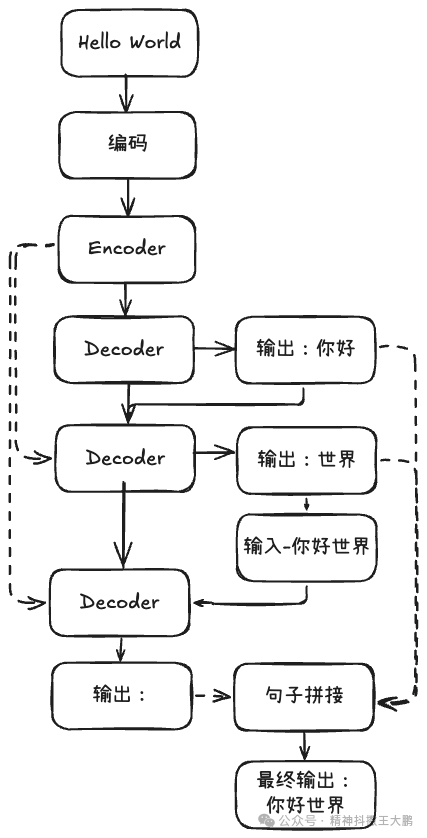
Encoder的任务是理解输入序列,将其转换为富含语义信息的表示。每个Encoder层包含两个核心组件:多头自注意力+前馈神经网络。

自注意力机制让每个位置都能"看到"序列中的所有其他位置。以句子"The cat sat on the mat"为例:理解"cat"时,模型会关注"The"(确定是哪只猫),理解"sat"时,模型关注"cat"(谁在坐)和"on the mat"(坐在哪里)。
多头注意力进一步扩展了这种能力:每个头都有自己独立的参数矩阵,用来关注不同类型的关系,所有头并行计算,最终将多个头的结果合并。以句子"大鹏在北京的工作是计算机"为例,句子中会包含多种关系,"大鹏"和"工作"是主谓关系,"北京"和"工作"是地点关系,"工作"和"计算机"是性质关系,每个头关注不同的关系,最终合并。
数学表达式为:Attention(Q,K,V) = softmax(QK^T/√d_k)V,QK^T来计算查询和键的相似度,除以√d_k用于缩放,避免梯度消失。softmax转化为概率分布,最终乘以V根据注意力权重加权求和。
在每个注意力层之后,都有一个前馈神经网络(FFN)。这个组件流程很简单:放大->筛选->压缩。在GPT3中,FFN将12288维向量放大4倍至49152维,应用ReLU激活函数进行非线性变换,重新压缩回12288维。通过在放大过程中提取丰富特征,在压缩过程中保留有用信息。这里有个trick点是:当我们知道需要完成某种复杂的信息变换来做提取,但不知道具体的数学公式时,可以使用神经网络来学习这种变换。
残差连接是为了解决深层网络训练中的梯度消失问题,表达式为:output = LayerNorm(x + SubLayer(x)),在梯度计算时:∂output/∂x = ∂(x + SubLayer(x))/∂x = 1 + ∂SubLayer(x)/∂x,即使∂SubLayer(x)/∂x 变得很小(接近0),总梯度也不会完全消失,因为至少还有1存在。
层归一化在残差连接之后执行,层归一化会先将输入标准化为均值0、标准差1,然后通过可学习参数调整到最适合的分布,避免梯度消失或爆炸。层归一化的公式为:LN(x) = γ * (x - μ) / σ + β,反向传播的梯度计算时:∂LN/∂x = γ/σ * (1 - 1/d - (x-μ)²/(d*σ²)),1确保了梯度不会完全消失,-1/d防止梯度因为均值计算被过度缩放,-(x-μ)²/(d*σ²)用来减小梯度,防止输入值偏离均值大。
Decoder的结构相比Encoder更加复杂,因为它不仅要理解,还要生成,它主要有三个核心组件:掩码多头注意力+多头交叉注意力+前馈神经网络。

在生成任务中,模型不能"偷看"未来的信息。掩码机制确保每个位置只能关注当前及之前的位置,这使得Decoder特别适合生成任务。掩码注意力在标准的自注意力实现中加上了掩码:MaskedAttention(Q,K,V) = softmax((QK^T + Mask)/√d_k)V,掩码矩阵会用负无穷来填充,这样经过softmax函数,掩码位置在注意力中的权重就为0,不会对结果造成影响。通过掩码模拟了真实的生成过程,即使训练时有完整的目标序列,也要模拟逐步生成的过程,位置i只能关注位置i前面的。推理时本就逐步生成,天然满足掩码的约束。
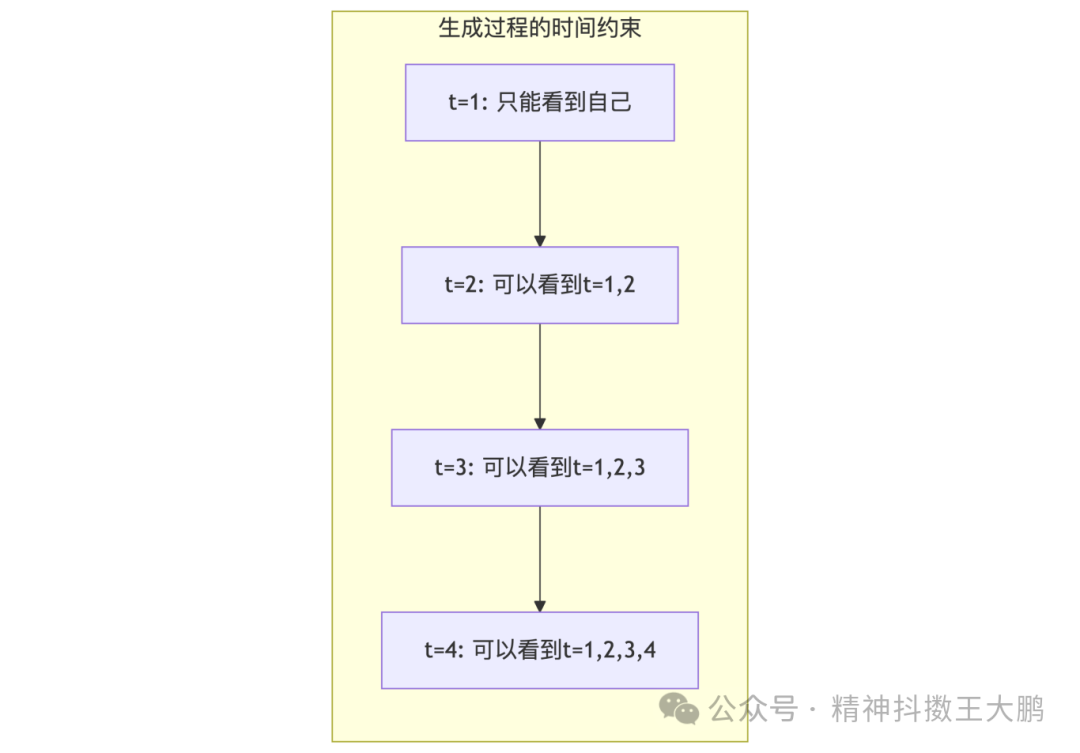
交叉注意力让Decoder能够关注Encoder的输出,实现了理解到生成的信息传递:
CrossAttention(Q_decoder,K_encoder,V_encoder)=softmax(Q_decoder × K_encoder^T/√d_k) × V_encoder,但要注意交叉注意力存在于早期的Encoder-Decoder架构,现代的Decoder-Only模型(GPT3)舍弃了交叉注意力的模块,只使用掩码机制。
在GPT3中,Decoder就堆叠了96层,每层完整的结构是:多头自注意力->残差连接+归一化->前馈神经网络->残差连接+归一化。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献760条内容
已为社区贡献760条内容

所有评论(0)