Ai-Agent学习历程——Agent进阶篇
一、Agent的概念、组成和决策1. Agent的概念2. Agent的组成3. Agent的决策过程3.1 感知阶段3.2 推理阶段3.3 决策阶段3.4 执行阶段4. Agent和大模型的本质区别5. Agent的优势
Ai-Agent学习历程——Agent进阶篇
一、Agent的概念、组成和决策
1. Agent的概念
它通常可以通过感知环境进行决策并采取行动的系统。
主要特征:
- 感知:通过传感器感知环境信息。
- 推理:分析感知到的信息,根据设定的规则或者学习算法进行决策。
- 行动:智能体根据推理结果采取行动,影响环境或自身状态。
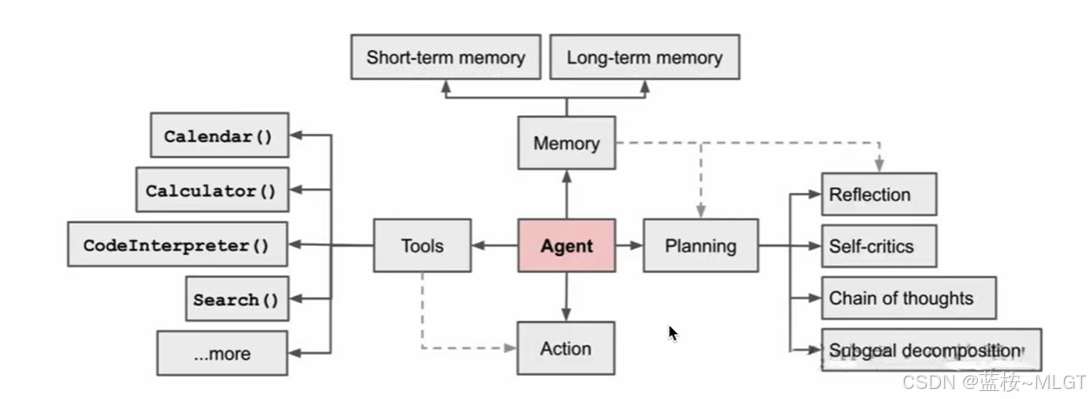
注意:这个图片是四步,有一个Tools(工具),这是因为目前的Agent大多数对于工具的应用比较重视,所以单独分出了一个步骤,如果你是给别人分享是基于理论,那可以是三步,但如果是基于实践则是四步。
2. Agent的组成
- 感知器:负责从
外界环境中获取信息,它可以是传感器、输入设置或者任何能收集环境信息数据的系统组件。 - 决策器:这是Agent的核心部分,负责分析从感知器获取的信息并
做出决策。 - 效应器:决策器给出具体的决策指令,而效应器就是具体执行的元件,也就是胳膊啊轮子啊之类的,专业一点就是
控制系统中的输出接口。
3. Agent的决策过程
3.1 感知阶段
这个阶段是数据输入的阶段,一般包含以下几种信息:
- 视觉信息
- 声音信息
- 位置信息
- 温度、湿度等
但是在当前我们更多研究的是工作流,这是目前的主流,而对于工作流来说,这些信息类似,只不过来源都是从网络上来的,比如一些图片、视频、其余网友的评价等等。
3.2 推理阶段
根据已有的知识库、规则等等来分析外界信息,然后做出决策
- 基于知识的推理
- 基于数据的推理
- 强化学习
3.3 决策阶段
- 基于规则的决策:使用预定义的规则做出决策,一般可以是智能家居为代表。
- 机器学习:通过数据训练和模型识别做出决策,只不过这种数据是基于外部环境的真实数据进行训练。
- 优化算法:应用数学优化技术(强化学习、遗传算法)进行决策。
3.4 执行阶段
根据决策采取行动
4. Agent和大模型的本质区别
- 大模型:理解为
一个大脑,拥有强大的算力,但是没有实际的执行能力。 - Agent:具有核心执行能力的
机器人,可以根据大脑的指令执行和操作。
具体区别如下:
- 互动性
- 大模型:通常是一次性处理信息,生成输出,
不具备和环境持续交互的能力,本质是静态的,无法主动执行动作或者学习。 - Agent:在任务执行过程中可以和
任务的环境持续进行交互,感知变化,然后做出最新的决策。
- 大模型:通常是一次性处理信息,生成输出,
- 目标导向
- 大模型:大多数是在一个特定的上下文中回答问题或
生成内容,它的目标是根据输入数据尽可能的给出最佳的输出,其实也可以理解为没有明确的目标。 - Agent:通常围绕某个明确的目标和任务展开,比如自动驾驶、机器人导航等,是一个
长期且明确的目标,同时在过程中会有学习和记忆的功能。
- 大模型:大多数是在一个特定的上下文中回答问题或
- 行动执行能力
- 大模型:结果是
虚拟且没有实际执行能力的文字、图像、视频等等。 - Agent:有
实际执行能力,能在现实世界中给出反馈,具有超强的推理和分析能力。
- 大模型:结果是
| 特性 | 普通大模型 | AI Agent |
|---|---|---|
| 核心功能 | 内容生成与对话(思考与回答) | 任务完成(感知、决策、行动) |
| 与环境交互 | 被动。只能处理用户提供的输入。 | 主动。可以自主感知并改变环境。 |
| 工具使用 | 无法直接使用。只能描述如何使用工具。 | 核心能力。可以自主调用API、数据库、软件等。 |
| 数据时效性 | 依赖于训练数据,存在信息滞后性。 | 可通过工具获取实时信息(如最新天气、股价)。 |
| 任务复杂度 | 适合单轮、知识型的问答任务。 | 适合多步骤、需要外部交互的复杂任务(如“分析我上月的开支并生成报告”)。 |
| 运作模式 | 一问一答。 | 自主循环。“感知-思考-行动”循环直至任务完成。 |
5. Agent的优势
-
自适应性:Agent能够根据实时感知到的信息调整行为,特别是在动态和不确定的环境中,能够自主做出调整。
-
长期目标驱动:Agent在行动时考虑长期目标而不仅仅是即时的反应。这使得它们能够处理复杂任务,比如策略游戏中的决策。
-
高效任务执行:通过实时交互与反馈机制,Agent能够迅速调整行动路径,减少不必要的重复工作,从而提高整体效率。
-
更强的学习能力:特别是在强化学习框架下,Agent可以通过与环境的交互,逐步优化自己的决策策略,变得更加高效。
-
自动化与智能化:智能体可以减少人工干预,并且在复杂系统(如工业自动化、医疗诊断、机器人控制等)中扮演至关重要的角色。
二、子任务拆解——COT、TOT、GOT、ReAct
在智能体Agent的决策和操作过程中,子任务拆解是一个非常重要的步骤,它能将一个复杂的任务拆解为多个详细、更容易执行的小任务,这种 方式能大大提升任务的执行效率,同时也能更好的应对复杂的环境和长远的目标,分为多种处理形式,每一种形式都代表的不同的应用场景。
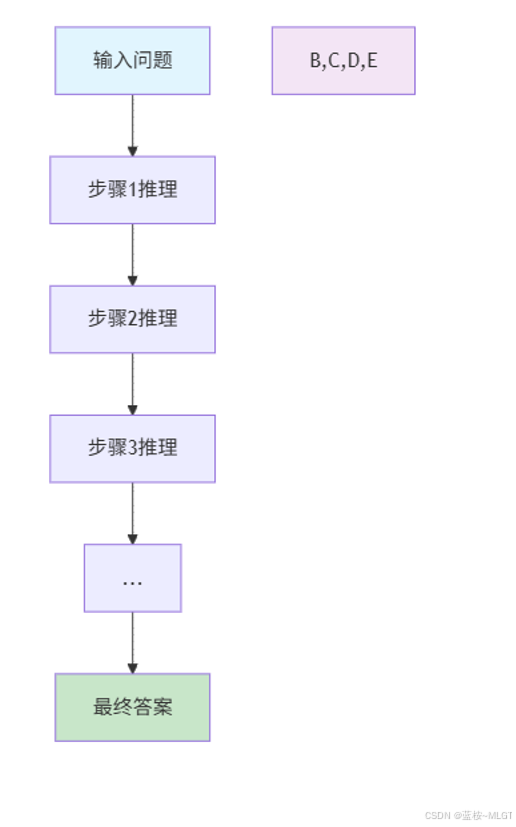
1. COT——思维链(Chain of Thought)
📌 COT是一种线性的推理方式,通过一步一步的推理和思考来达到目标,通常是通过一定的逻辑顺序进行,依次展开,核心特点是顺序性和连贯性,这个过程中注重每一步的连续推导和衔接。
COT的基本特征
- 线性过程:COT依赖于一个清晰的推理线条,每一个思维步骤都为下一步的推理提供依据。
- 逐步推导:COT的每一步都是基于前一步的结论进行思考。
- 简化过程:COT通过线性推理将复杂问题拆解,并解决每一个子问题。
COT的优势
- 简化复杂任务:通过分解任务来减少任务的难度。
- 易于理解与调试:每一个推理步骤都是明确的,便于理解和检查。
2. TOT——思维树(Tree of Thought)
通过字面意思可以理解,这是一个树形结构的思维过程,它同样会拆分成多个子任务,但是通过树状分支的形式展现出不同的解决路径。与COT不同的是,TOT允许多条思维路径并行发展,适用于多种解决方案或多任务的场景。
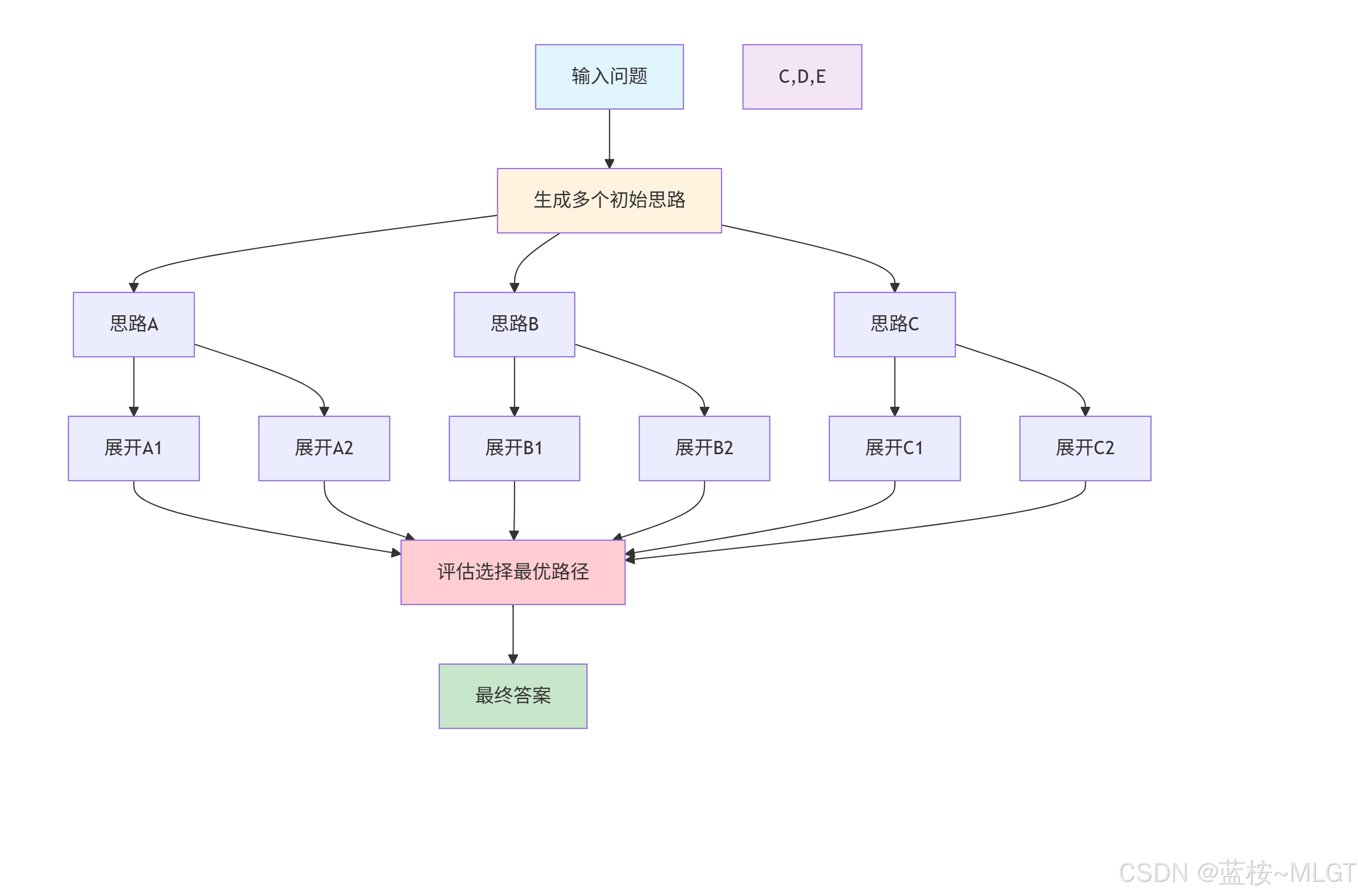
TOT的基本特征
- 分支性思维:TOT会形成一个树状的推理过程,存在多个解决方式的分支。
- 多任务处理:TOT允许并行处理多个子任务,并在不同的路径上尝试不同的思维方式。
- 递归结构:每个节点可以继续被拆解为更多的子任务,形成更深的树结构。
工作原理
- 思路生成:在当前的推理节点,模型会生成多个可能得下一步推理思路。
- 思路评估:模型或一个独立的评估器对这些思路的质量和前景进行评分。
- 搜索算法:根据评估分数,使用搜索算法(如广度优先、深度优先、最佳优先)决定下一步探索哪个节点(思路)。
- 决策:重复以上过程,直到某个路径得出令人满意的答案或达到搜索限制。
优势
- 适应复杂决策问题
- 并行推理
3. COT和TOT的区别及应用场景
| 特性 | Chain-of-Thought (CoT) | Tree-of-Thought (ToT) |
|---|---|---|
| 核心比喻 | 写下解题步骤 | 探索决策树 |
| 最佳场景 | 有明确、线性步骤的问题(数学计算、逻辑推理) | 开放式、需要创意或策略的问题(规划、写作、编程) |
| 复杂度/成本 | 低(一次生成) | 高(多次生成和评估) |
| 如何手动使用 | 在向大模型提问时,加上提示词:“让我们一步步地思考。” | 目前较难直接通过简单提示实现,通常需要编程框架支持。但可以手动模拟:要求模型"列出三种可能的解决方案,并分析每种方案的优缺点"。 |
| 在Agent中的作用 | 基础推理引擎。负责执行每个子任务内部的逻辑计算。 | 高级规划器。当遇到歧义或多个选择时,负责探索不同路径,制定最优计划。 |
基于上我们可以分析出,一个是专注于子任务处理的方式,一个则是多任务决策的方式,一般情况下两者都是配合使用的,先有TOT进行决策和分解,得到最优的解决思路,之后交由COT进行拆分执行。当然,一般的简单问题可以直接使用COT进行。
4. GOT——思维图谱(Graph of Thought)
GOT是一种基于图结构模式的思维方式,它通过图的节点和边来表示知识、任务、推理路径及其关系,每个节点代表一个思维元素(如子任务、结论、假设等),而节点之间的边表示他们之间的逻辑关系或者推理过程。这样能够捕捉复杂任务中多个思维元素之间的思维关系,从而让Agent能够以图的方式表示和探索任务的多种可能性。
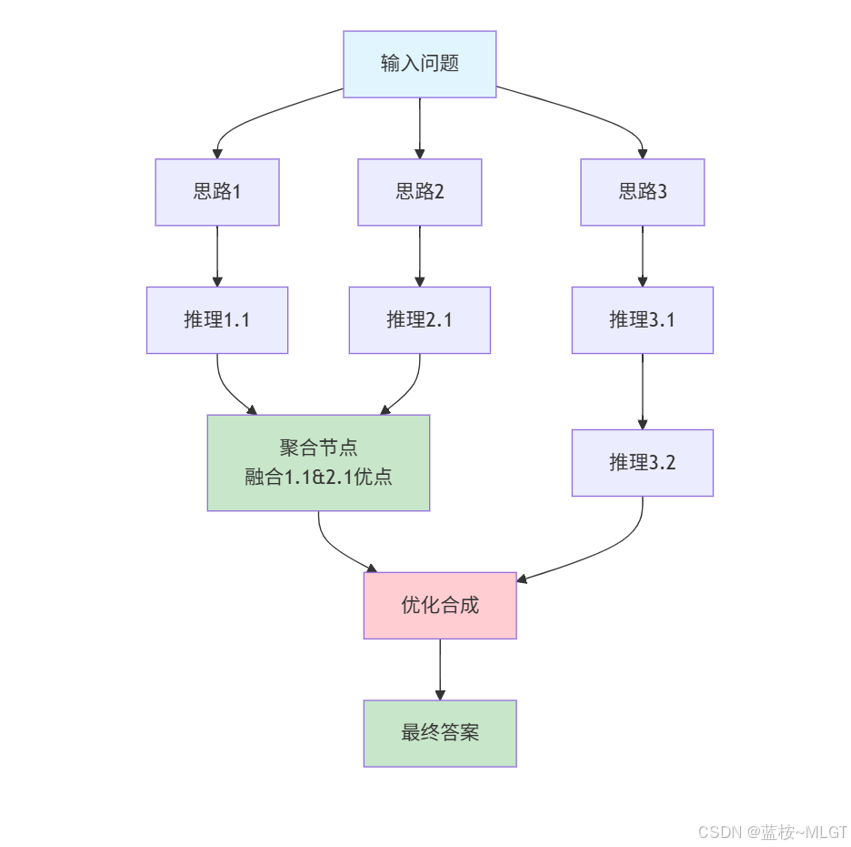
核心特征
- 灵活的推理路径:GOT在TOT的基础上还可以随机调整推理方向,而不像TOT一旦确认思路后就无法改变,并且不同思路之间不能进行交互,从而导致一些优秀的答案不能互相利用。
- 多维关系:GOT能捕捉到任务中多种因素之间的关系,比如目标的优先级、约束条件、任务的依赖关系等等。
应用实例
- 比如一个复杂的实验项目,GOT需要将不同步骤(如实验设计、信息收集、信息分析)等多个步骤之间的关系进行连接,动态的进行调整,当信息分析发现缺失数据时,就需要再次到上一个步骤中进行。
5. ReAct——推理与行动(Reasoning and Acting)
ReAct是一种推理和行动结合的框架,能够在推理的过程中快速的采取行动,和外界环境紧密相连,而不是死板的生成结果,在每次行动之后会再次进行推理,从而可以实时的收集到外界的环境信息。
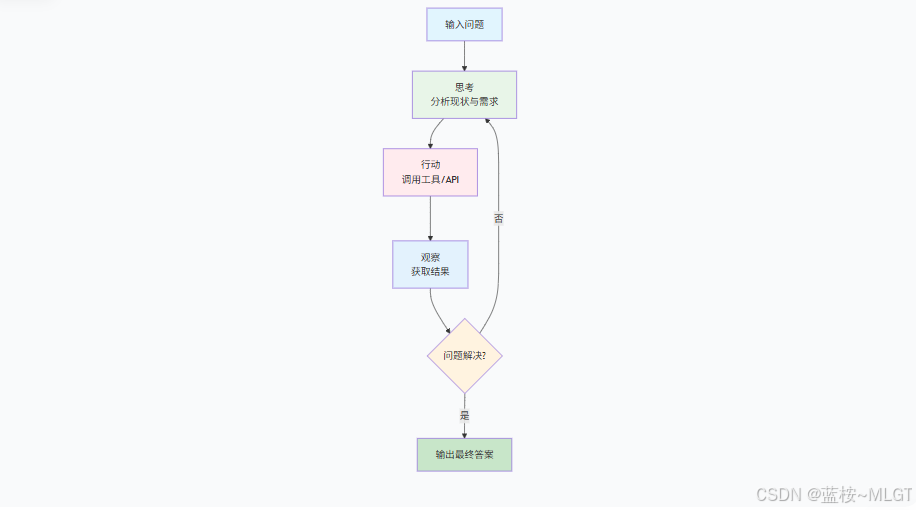
核心思想
- 交替推理和行动:Agent分析当前环境和任务,在行动阶段,Agent基于推理采取行动,之后通过反馈调整决策。
- 及时反馈和调整:每一次的行动都会影响下一步的推理和决策,能非常好的适应环境的变化。
- 动态决策:ReAct允许在不断的推理和行动中优化策略,而不是按照预先制定的决策采取行动。
6. 整体对比和总结
| 维度 | CoT | ToT | GoT | ReAct |
|---|---|---|---|---|
| 结构比喻 | 直线链条 | 决策树 | 神经网络 | 自治循环系统 |
| 核心能力 | 顺序推理 | 多路径搜索 | 合成优化 | 与环境交互 |
| 灵活性 | ⭐☆☆☆☆ | ⭐⭐☆☆☆ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐☆ |
| 计算成本 | 低 | 中高 | 高 | 取决于任务复杂度 |
| 典型应用 | 数学解题 逻辑推理 |
创意生成 策略规划 |
复杂问题解决 创新设计 |
自动化任务 实时信息处理 |
这四种方式分别对应了不同的场景,但Agent最终的主要核心还是ReAct形式的交互,因为我们的智能体不会仅仅停留在文字、图片和视频的处理,一个能感知外界环境,理解人类情绪和表情的超强智能体才是我们所追求的最终目标。
三、Agent记忆
记忆是智能体(无论是人类还是人工智能)用于获取、存储、保留以及后续检索信息的能力。它是智能体形成连贯的自我认知、与环境有效交互以及进行复杂推理和学习的基石。没有记忆,每一次交互都将从零开始,智能体将无法实现真正的“智能”。
1. 生活中的记忆机制
短期记忆与长期记忆
- 短期记忆: 在短时间内存储的信息,通常保持时间在20-30秒,容量有限。
- 长期记忆:可以存储几年-几十年或者终生,进一步分为
- 显式记忆:主动回忆的记忆,比如一些历史事件或者你的亲身经历。
- 隐式记忆:不需要有意识的会议,比如骑车或者敲击键盘等。
记忆的编码、存储和提取
- 编码:外部信息通过感官进入大脑后,经过处理(感知、思考、理解),转化为可存储的信息。
- 存储:信息会被存储到大脑的不同地方,例如语言和语义相关的会存储在大脑的语言区域,视觉信息存储在视觉皮层区域。
- 提取:从记忆中提取信息,能够回忆成功取决于信息在大脑中的存储质量和提取线索的有效性。
2. 智能体中的记忆机制
智能体(Agent)的记忆机制与人类的记忆机制相似,但由于智能体通常是计算机程序或机器人系统,它们的记忆更多是基于数据结构和算法来实现的。智能体的记忆机制可以分为感知记忆、工作记忆和长期记忆等。
感知记忆
- Agent从环境中获取的信息,是
最短期的记忆,通常用于实时的决策和反应。 - 一般存储的都是最原始的数据,随着时间的推移会被新的感知记忆所替代。
- 例如自动驾驶系统中,感知记忆就是实时从外界获取的环境信息,随着汽车的前进随时进行更替。
工作记忆
- 工作记忆类似人类的短期记忆,相当于Agent处理和操作信息的内存。
- 工作记忆通常存储的是
正在执行任务所需的信息,可能包含当前的位置、目标位置、当前的环境状态等信息。 - 工作记忆在任务的执行过程中会
不断更新(优点类似感知记忆的机制),并且会在任务完成后被清空或者说转化为长期记忆。
长期记忆
- 长期记忆是Agent存储长期任务和经验的地方,也就是每次执行任务所学习的内容,能提高Agent的学习和适应能力。
- 比如一些
奖励机制和奖励结果进行存储,这样方便后期进行更好的决策。 - 其中,
经验回放是一种长期记忆管理的方式,智能体会通过回放历史经历来加速学习过程。
增量学习与记忆
增量学习机制允许Agent在学习过程中持续不断的更新记忆,而不需要重新训练整个模型,通过持续积累的信息和旧信息进行结合,在执行任务过程中不断调整行为。- 例如:在机器人中,新的传感器数据、环境信息与其他智能体的交互经验会不断的被存储,以便在后续的任务中使用。
记忆的更新和删除
- 与人类的记忆相似,智能体的记忆也需要定期的更新和删除,Agent需要去除过时的、无关的或者误导的信息,防止记忆过载。
遗忘机制可以帮助智能体主动丢弃不需要的信息,或者根据信息的相关性来加以保留。
记忆在多智能体系统中的应用
-
在多智能体系统中,每个智能体都可能拥有自己的记忆库,通过交换信息和经验,智能体之间可以协作和协调决策。例如,智能体之间可以共享部分长期记忆(如过去成功的策略),以帮助共同达成目标。
-
共享记忆或集体记忆是一种常见的概念,多个智能体通过协作与交流,积累集体的知识,以提高系统的整体表现。
总结
这是关于一些Agent的进阶知识,通常有助于我们在后续的编码中选择合适的方式,是非常重要的一部分知识。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)