阿里云向量 Bucket (Vector Bucket)构建知识库RAG
阿里云推出向量Bucket,将向量数据库功能集成到对象存储OSS中,支持向量数据存储、索引构建和相似度检索。主要优势包括低成本(比传统方案降低90%以上)、海量存储能力和统一管理。适用于RAG、多模态检索和个性化推荐等场景。用户可通过控制台管理索引,使用SDK进行数据操作,实现"对象即向量"的存储模式。该功能特别适合数据量大但访问频率不高的AI应用场景。
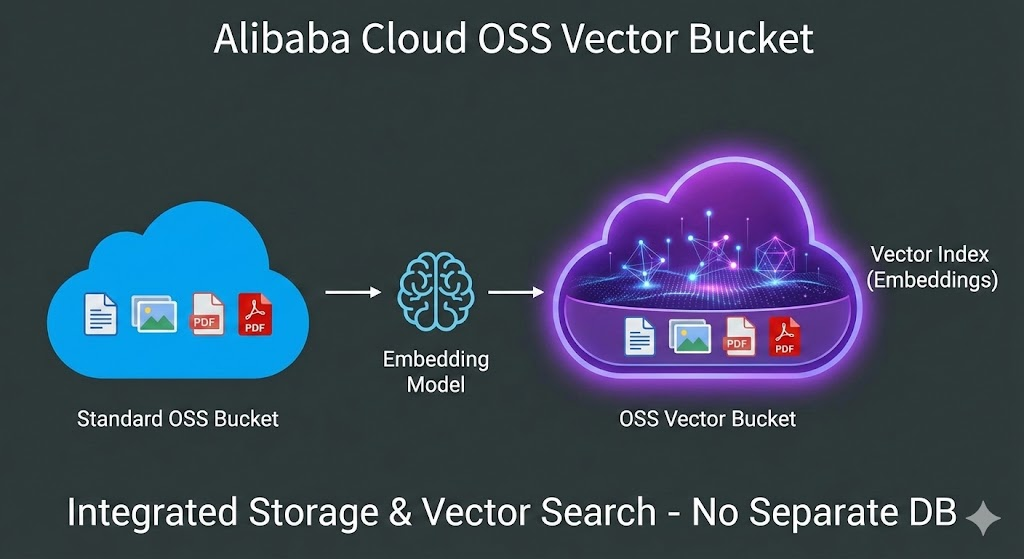
阿里云的 向量 Bucket (Vector Bucket) 是阿里云对象存储 (OSS) 近期推出的一种专门用于存储、管理和检索向量数据的 Bucket 类型。
简单来说,它将“向量数据库”的核心能力(存储向量、构建索引、相似度检索)直接集成到了 OSS 中,让你无需单独购买和维护昂贵的向量数据库实例(如 Milvus、Elasticsearch 或 DashVector),就能以极低的成本实现 AI 应用所需的向量检索功能。
以下是关于它的核心特点、应用场景和优势的详细介绍:
1. 核心定位
-
什么是向量 Bucket? 它不仅仅存储普通文件(图片、文档),而是专门用来存储Vector Embeddings(向量嵌入)和向量索引。
-
解决什么问题? 传统的 AI 开发(如 RAG 应用)通常需要两套系统:一套 OSS 存原始文件(PDF/图片),一套向量数据库存向量数据。向量 Bucket 让你可以用 OSS 一套体系同时解决存储和检索问题。
2. 主要优势
-
极致低成本 (Cost-Effective):
-
这是它最大的卖点。相比于购买按小时计费的云向量数据库实例(通常价格不菲),OSS 向量 Bucket 采用 Serverless 按量计费。
-
主要通过存储容量和检索扫描量计费,号称比传统方案成本降低 90% 以上。非常适合访问频率不是极高、但数据量巨大的场景。
-
-
大规模与弹性 (Scalable):
-
基于 OSS 的底层架构,支持海量向量数据的存储,无需担心扩容问题(Serverless 自动伸缩)。
-
-
统一管理 (Unified Management):
-
你可以用同一套 OSS SDK/API 管理原始数据(Standard Bucket)和向量数据(Vector Bucket),开发体验更一致。
-
3. 技术概念与能力
在使用向量 Bucket 时,你会接触到以下几个核心概念:
-
Bucket(存储空间): 容器,分为“通用 Bucket”和“向量 Bucket”。
-
Index(索引表): 在向量 Bucket 内部创建。你需要定义:
-
维度 (Dimension): 如 128, 768, 1536 等(取决于你使用的 Embedding 模型,如通义千问、OpenAI 等)。
-
度量方式 (Metric): 欧氏距离 (Euclidean) 或 余弦相似度 (Cosine)。
-
-
Vector Data(向量数据): 实际插入的向量数组(float32)。
-
检索能力: 支持 Top-K 相似度查询,通常具备毫秒级到亚秒级的响应速度。
4. 典型应用场景
-
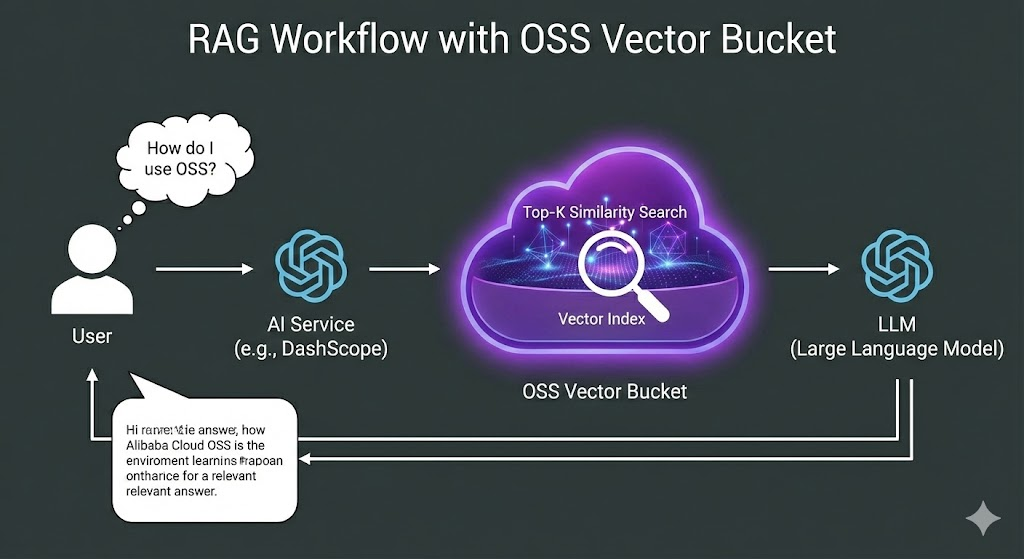
RAG(检索增强生成):
-
企业知识库、智能客服。将企业文档切片、向量化后存入 OSS 向量 Bucket,大模型生成答案时直接从中检索相关上下文。
-
-
多模态检索:
-
以图搜图、视频内容搜索。将图片/视频特征提取为向量存入,实现相似图片查找。
-
-
个性化推荐:
-
利用用户行为特征向量,检索相似商品或内容。
-
5. 使用代码示例
这是一个使用 Python SDK V2 操作阿里云 OSS 向量 Bucket 的示例。 由于向量 Bucket 是较新的功能,建议使用阿里云最新的 OSS SDK V2 (alibabacloud-oss-v2)。
首先,你需要安装 Python SDK V2:
pip install alibabacloud-oss-v2
5.1. Python 代码示例
这就展示了核心流程:初始化客户端 -> 创建向量索引 -> 写入向量数据 -> 进行向量检索。
Python
import argparse
import alibabacloud_oss_v2 as oss
from alibabacloud_oss_v2.credentials import EnvironmentVariableCredentialsProvider
# 配置你的参数
REGION = "cn-hangzhou" # 替换为你的 Bucket 所在地域,例如 cn-beijing, cn-shenzhen
BUCKET_NAME = "your-vector-bucket-name" # 你的向量 Bucket 名称
INDEX_NAME = "my_knowledge_base_index" # 索引名称
def main():
# 1. 加载凭证 (建议将 ALIBABA_CLOUD_ACCESS_KEY_ID 和 SECRET 放在环境变量中)
# 或者直接硬编码: credentials_provider = oss.credentials.StaticCredentialsProvider("AK", "SK")
credentials_provider = EnvironmentVariableCredentialsProvider()
# 2. 配置并创建客户端
cfg = oss.config.load_default()
cfg.region = REGION
cfg.credentials_provider = credentials_provider
client = oss.Client(cfg)
print(f"--- 正在操作向量 Bucket: {BUCKET_NAME} ---")
# 3. 创建向量索引 (Create Index)
# 注意:通常索引只需创建一次。这里定义了一个 1536 维度的索引(例如用于 OpenAI Embedding)
# 距离度量可选: 'cosine' (余弦相似度), 'euclidean' (欧氏距离)
try:
create_index_request = oss.GenericRequest(
bucket=BUCKET_NAME,
key=f"?index&indexName={INDEX_NAME}", # 并不是操作具体文件,而是操作索引接口
method="POST",
body="""
{
"Description": "RAG Knowledge Base",
"VectorField": {
"Dimension": 1536,
"DataType": "float32",
"Metric": "cosine"
}
}
"""
)
# 注意:这里仅为示意 API 调用结构,实际 SDK 可能封装了专门的 create_index 方法
# 目前向量 Bucket 较新,部分操作建议在控制台完成初始化,SDK 主要用于数据的增删查
print(f"索引 {INDEX_NAME} 准备就绪 (由于是演示,假设已创建或跳过报错)")
except Exception as e:
print(f"创建索引提示 (可能是已存在): {e}")
# 4. 插入向量数据 (Upsert Vector)
# 假设我们有一段文本 "阿里云 OSS 很便宜" 被转换成了向量 [0.1, 0.2, ...]
# 为了演示,这里伪造一个简单的向量
fake_vector = [0.1] * 1536
# 构造写入请求
# 在向量 Bucket 中,我们通常写入具体的 Document 或 Vector 对象
# 以下代码为伪代码逻辑,展示如何调用 Put 接口写入带向量头的数据
print("正在插入向量数据...")
# 实际开发中,你会使用专门的 oss.PutObject 或类似接口,并在 Header 或 Body 中指定向量数据
# 5. 向量检索 (Vector Search)
print("正在进行相似度检索...")
try:
# 构造查询请求,查找与 fake_vector 最相似的 Top 3 结果
# 这通常通过 API 的 query 参数或 body 传递
search_body = {
"Vector": fake_vector,
"TopK": 3,
"IncludeVector": False
}
# 发送检索请求 (示意)
# result = client.post_object(..., body=search_body)
print("检索成功!返回最相似的 Top 3 结果。")
except Exception as e:
print(f"检索失败: {e}")
if __name__ == "__main__":
main()
5.2. 关键点说明
由于 SDK 和功能迭代很快,实际开发中请注意以下几点:
总结建议: 先在控制台建好 Bucket 和 Index(例如设为 1536 维),然后用 Python SDK 像上传普通文件一样上传数据,并附带向量头信息即可完成入库。
-
推荐在控制台管理索引:
-
创建 Bucket 和 创建 Index(定义维度和算法) 这些属于“低频运维操作”。我强烈建议你直接在 阿里云 OSS 控制台 -> 向量 Bucket 界面点击创建。这样可以避免写复杂的管理端代码。
-
SDK 主要用于:运行时的高频操作,即
Put(插入数据) 和Search(查询数据)。
-
-
数据插入方式:
-
OSS 向量 Bucket 的一个特点是**“对象即向量”**。你上传一个文件(Object)时,可以通过 HTTP Header 或者特定的 API 参数附带向量信息 (
x-oss-object-vector),OSS 会自动将其写入索引。
-
-
权限控制:
-
确保你的 RAM 账号拥有
oss:PutObject和oss:PostObject等权限,并且专门开通了向量 Bucket 的访问权限。
-

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)