(Arxiv-2025)Step1X-Edit:通用图像编辑的实用框架
本文提出Step1X-Edit框架,旨在缩小开源与闭源图像编辑模型的性能差距。通过构建包含11类编辑任务的大规模高质量数据集(生成100万+三元组),并引入多模态大语言模型与扩散模型结合的新架构,该模型在GEdit-Bench基准测试中显著超越现有开源方案,接近GPT-4o等闭源系统性能。关键创新包括可扩展的数据生成流水线、统一的条件编码方法及基于真实场景的评估基准,为通用图像编辑研究提供了新方向
Step1X-Edit:通用图像编辑的实用框架
paper title:Step1X-Edit: A Practical Framework for General Image Editing
paper是StepFun发布在Arxiv 2025的工作
Code:链接
Abstract
近年来,图像编辑技术取得了显著而迅速的发展。近期发布的前沿多模态模型,如GPT-4o和Gemini2 Flash,展示了极具前景的图像编辑能力。
这些模型在满足用户驱动的编辑需求方面表现出令人印象深刻的能力,标志着图像操作领域的一次重大飞跃。然而,开源算法与这些闭源模型之间仍存在巨大差距。为此,我们提出了一种最先进的图像编辑模型Step1X-Edit,旨在提供可与GPT-4o和Gemini2 Flash等闭源模型相媲美的性能。
更具体地说,我们采用多模态大语言模型来处理参考图像和用户的编辑指令。从中提取潜在嵌入,并将其集成到扩散图像解码器中,以生成目标图像。
为了训练该模型,我们构建了一个数据生成流水线,涵盖11种编辑任务,以生产高质量的数据集。用于评估时,我们开发了GEdit-Bench,这是一个基于真实世界用户指令的新型基准。
在GEdit-Bench上的实验结果表明,Step1X-Edit在很大程度上超越了现有的开源基线,并接近主流闭源模型的性能,从而在图像编辑领域做出了重大贡献。
1 Introduction
使用自然语言指令进行图像编辑,已成为视觉-语言研究中日益重要的任务。它为终端用户提供了直观的交互方式,同时也带来了独特的技术挑战:理解细微的语义、精确定位编辑区域以及保持图像保真度。尽管扩散模型 [42, 5, 7, 11, 41] 极大地提升了图像生成质量,但当前将文本编码器(如 CLIP [44] 和 T5 [45])与扩散变换器集成的设计,在遵循编辑指令以维持输入图像与编辑要求对齐方面仍存在困难,尤其是在编辑指令较为细致或组合性较强时。
近期在专有多模态基础模型方面的进展,如 GPT-4o [37]、Gemini2 Flash [15] 和 SeedEdit/Doubao [50],推动了基于指令的图像编辑前沿的发展。这些系统利用大规模的视觉-语言建模能力,在多种场景下执行高保真编辑。然而,其闭源特性限制了可复现性与透明度。与此同时,开源尝试如 OmniGen [61] 和 ACE++ [34] 致力于复现类似能力,但在整体泛化能力、编辑准确性以及生成图像质量方面仍有所欠缺。

图1:Step1X-Edit概览。Step1X-Edit是一个开源的通用图像编辑模型,具备全面的编辑能力,性能可与闭源模型相媲美。
在本研究中,我们旨在缩小开源与闭源图像编辑系统之间的性能差距,同时推动更实用、以用户为中心的编辑评估边界。尽管已有研究开源了编辑数据集,如 AnyEdit [64] 和 OmniEdit [59],但我们认为这些数据集在质量和多样性方面仍不足以支撑达到 GPT-4o 等闭源算法的表现。因此,为了解决图像编辑问题,我们首先构建了一个大规模高质量的训练数据集。更具体地,我们基于常用的编辑指令归纳出11类主要编辑任务。以此分类为指导,我们开发了一套可扩展且灵活的数据生成流水线,生成超过100万条高质量训练数据。这些图像-指令对涵盖了广泛的编辑操作,包括对象操作、属性修改、布局调整和风格化处理,确保了对真实编辑场景的全面覆盖。
在该数据集基础上,我们提出了Step1X-Edit,一个统一的图像编辑模型,结合了多模态大语言模型(MLLM,如 Qwen-VL [3])的强大语义推理能力与DiT风格扩散架构。参考图像与编辑提示将由MLLM处理,以生成目标图像的潜在条件,该条件将与扩散模型集成以输出最终图像。我们的方法在参考图像重建与编辑指令跟随之间保持了良好的平衡。
在训练模型方面,我们以文本到图像模型为起点,以保留图像美学质量和视觉一致性,该模块可以轻松替换为现有的文本到图像模型,如SD3 [11]、FLUX [5, 7, 26]、HiDream-I1 [18] 和 Flex [38]。
为了评估现有编辑模型,我们引入了一个新基准——GEdit-Bench。通过精心收集图像和编辑指令,GEdit-Bench确保了编辑需求的真实性和指令的多样性。在GEdit-Bench上的实验结果表明,Step1X-Edit以较大优势超越现有开源基线,并接近领先闭源模型(如GPT-4o)的性能。
总结来说,我们的工作有以下三点贡献:
-
我们将开源Step1X-Edit模型,缩小开源与闭源图像编辑系统之间的性能差距,推动图像编辑领域的进一步研究。
-
我们设计了一套数据生成流水线,用于生成高质量图像编辑数据。该流水线确保数据集的多样性、代表性和质量,支持高效图像编辑模型的开发。该流水线的可用性也为类似项目的研究人员和开发者提供了宝贵资源。
-
我们开发了一个名为GEdit-Bench的新基准,基于真实使用场景,用于支持更真实和全面的评估。该基准经过精心策划,反映了用户实际编辑需求和多种编辑场景,使图像编辑模型的评估更加真实和全面。
2 Related Work
2.1 Controllable Image Generation and Edit
自回归(Autoregressive, AR)模型通过将图像建模为离散标记序列,已被广泛研究用于可控图像生成与编辑。诸如ControlAR [29]、ControlVAR [27] 和 CAR [63] 等工作,将边缘、分割掩码和深度图等空间与像素级引导信息引入解码过程,实现了局部化和结构化的控制。扩展方法如 Training-Free VAR [58]、M2M [48] 和 Instruct-imagen [20] 进一步提升了编辑灵活性并拓宽了应用场景。UniFluid [12] 探索了连续视觉标记下统一的自回归生成与理解。然而,由于依赖离散标记和序列长度限制,AR模型在生成高分辨率和逼真图像(尤其是复杂场景)方面常常存在困难。
扩散模型已成为高保真图像合成的主流方法,具备强大的写实性、结构一致性与多样性能力。从DDPM [19] 和 DDIM [51] 起步,再到 Latent Diffusion [47, 42] 的推进,扩散模型通过在潜空间中运行提升了扩展性。随着 DiT 架构 [41] 的引入,扩散模型在泛化能力、图像质量与知识容量方面取得显著进展,成为现代图像生成中的主流架构 [1, 5, 7]。基于上述文本到图像模型,ControlNet [67] 与 T2I-Adapter [36] 将空间或任务特定的控制信号注入生成过程。BrushNet [23]、PowerPaint [73] 和 FLUX-Fill [6] 进一步提升了图像修复的质量与通用性。尽管取得诸多进展,扩散模型仍然依赖静态提示或固定条件,缺乏多轮推理能力与灵活语言对齐,限制了其在开放式编辑场景中的应用。
这些局限性促使研究者越来越关注统一图像编辑框架的发展,该类模型试图结合AR模型的符号控制能力与扩散模型的生成保真度。目标是在单一架构中紧密结合指令理解、空间推理与逼真图像合成,提供更灵活、通用且可由用户控制的图像编辑能力。
2.2 Instruction-based Image Editing Models
基于指令的图像编辑模型旨在弥合语义指令理解与精确视觉操作之间的鸿沟。早期方法如 InstructEdit [55]、InstructPix2Pix [8]、MagicBrush [66] 和 BrushEdit [28] 采用模块化流程,利用多模态大语言模型(MLLM)生成提示、空间引导或合成的指令-图像对,以指导基于扩散的编辑过程。
近期研究趋向于在指令与生成之间实现更紧密的整合。SmartEdit [21]、X2I [33]、RPG [62]、AnyEdit [64] 和 UltraEdit [71] 通过改进的模型架构、任务感知路由和细粒度编辑能力,提升了多模态交互性和指令忠实性。与此同时,统一生成与编辑框架如 OmniGen [61]、ACE [16]、ACE++ [34] 和 Lumina-OmniLV [43] 将多种视觉任务整合于单一架构下。方法如 Qwen2VL-Flux [31]、DreamEngine [9] 和 MetaQueries [39] 进一步探索了高效控制整合方式,以及在 MLLM 与扩散解码器之间的潜空间级融合。此外,HiDream-E1 [17] 引入指令与编辑后图像描述作为输入,使编辑信息更加详尽。同时,也有部分研究专注于提高编辑性能的同时降低训练成本。例如,ICEdit [70] 采用 LoRA-MoE 混合微调方式并寻找更优的初始噪声分布;SuperEdit [35] 利用更高质量的训练数据并引入对比监督信号。
更普遍而言,Gemini [15] 和 GPT-4o [37] 等模型通过联合视觉-语言训练展现出强大的视觉流畅性,在理解和生成一致、具备上下文感知的图像方面表现出极大潜力。这些进展总体上反映出从松散耦合系统向紧密集成、指令驱动编辑框架的演变趋势。
然而,现有方法仍面临一些关键限制。大多数方法具有任务专属性,缺乏通用的编辑能力;它们通常不支持增量编辑、细粒度区域对应或指令反馈优化。此外,在许多设计中,架构耦合仍较浅,无法将指令理解与图像生成统一为一个整体框架。
这些挑战促使我们提出 Step1X-Edit,它将基于 MLLM 的多模态推理与基于扩散的可控图像合成紧密结合,实现了可扩展、可交互且忠实指令的图像编辑,适用于多种编辑目标。
3 Step1X-Edit
3.1 Data Creation
3.1.1 Data Pipeline
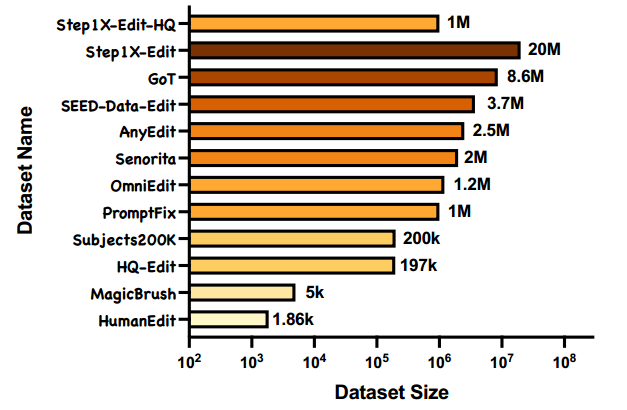
图2:数据量比较。
在现有文献中,当前的图像编辑数据集在规模或数据质量上均受到限制。为弥补这一空白,本报告致力于构建一个专为图像编辑任务设计的大规模高质量数据集。
我们首先通过网络爬虫从互联网上收集多样化的图像编辑示例。通过对这些示例的深入分析,我们将图像编辑问题系统性地划分为11个不同的类别,其中部分分类参考了 [64, 40]。这些类别旨在全面覆盖实际中绝大多数图像编辑需求。图3展示了这11个类别的概览及详细的数据收集流程。
为收集大规模高质量的三元组数据(由源图像、编辑指令和目标图像组成),我们设计了一条复杂的数据生成流水线,使我们能够生成超过2000万条指令-图像三元组。在经过多模态大语言模型(如 step1o [52])和人工标注员的严格筛选后,我们保留了超过100万条高质量三元组。图2展示了我们与所有现有编辑数据集 [13, 14, 74, 59, 65, 53, 22, 66, 2, 64] 的并列比较。我们的 Step1X-Edit 数据集在规模上超越了所有其他数据集。即使在20:1的高强度筛选比例下,Step1X-Edit-HQ 子集在绝对数量上仍可与其他数据集相媲美。每个子任务的完整数据收集流程如下所示。

图3:数据构建管道和子任务分布。
主体添加与移除:对于主体添加(subject-add)与主体移除(subject-remove)任务,我们首先利用 Florence-2 [60] 对自有数据集进行标注,该工具支持多种语义粒度、空间层级和注释类型,如目标检测与分类。随后使用 SAM2 [46] 进行图像分割,并采用 ObjectRemovalAlpha [30] 执行图像修复(inpainting)。编辑指令由 Step-1o 模型 [52] 与 GPT-4o 联合生成,并经过人工审查以确保数据有效性。
主体替换与背景更换:此类别的预处理步骤与主体添加/移除类似,均包括使用 Florence-2 [60] 进行标注以及使用 SAM-2 [46] 进行图像分割。然而,在这些任务中,我们使用 Qwen2.5-VL [3] 和 Recognize-Anything Model [69] 来识别目标对象或关键词,随后采用 Flux-Fill [6] 进行内容感知的图像修复。编辑指令由 Step-1o 自动生成,并由人工进行验证。
颜色改变与材质修改:在检测图像中的对象后,我们使用 Zeodepth [4] 进行深度估计,以理解对象的几何结构。根据识别出的目标转换(例如颜色或材质变化),我们结合 ControlNet [67] 与扩散模型 [1] 生成新的图像,在保持对象身份的同时改变其外观属性,如纹理或颜色。
文字修改:对于文本编辑任务,我们区分有效与无效的文本编辑。我们使用专注于识别正确字符的 PPOCR [10] 与 Step-1o 模型,来判别文本中的正确与错误区域。基于此分类,我们生成相应的编辑指令。所有输出均通过人工后处理(例如手动润色文本)进行最终确认。
运动变化:为处理与运动相关的变换,我们利用 Koala-36M [56] 数据集中的视频,提取帧对作为输入。使用 BiRefNet [72] 和 RAFT [54] 进行前景-背景分离与光流估计。具体来说,我们计算前景光流模的平均值与背景光流平均值的模,从而鲁棒地选择仅前景发生运动的帧对。最后使用 GPT-4o 对帧间运动变化进行标注,生成编辑指令。
人像编辑与美化:数据主要来源于两类:(a) 来自公开资源的人像美化图像对。通过人脸检测并传入 Step-1o 判断布局与背景一致性;(b) 人工编辑的人像美化数据,我们邀请编辑者对收集图像进行美化操作。所有数据均由人工验证。
风格迁移:风格化操作根据目标视觉域的不同分为两个方向:对于宫崎骏风格、水墨画、3D 动漫等风格,从风格化图像生成写实图像具有更好的一致性。我们从风格图像中提取边缘,并使用受控扩散模型 [67, 1] 生成写实图像;相反,对于油画、像素艺术等风格,我们从写实图像出发,通过相同的边缘到图像流程生成风格化结果。
色调转换:该类别关注全局色调调整,包括色彩分级、去雾、去雨和季节变化。这些变换主要由算法工具和自动滤镜驱动,以模拟真实的环境变化。
3.1.2 Caption Strategy
为了获得高质量且细粒度的编辑指令-图像对,我们采用以下标注策略:
冗余增强标注(Redundancy-Enhanced Annotation):鉴于视觉语言模型(VLMs)存在诸如背景描述模糊、易产生幻觉等已知问题,我们采用多轮标注策略。具体而言,上一轮的标注结果作为上下文输入传递给下一轮。这种递归式的细化流程增强了语义一致性,并显著缓解了幻觉相关问题。通过重复确认强化确定性信息,从而确保最终标注结果的可靠性更高。
风格化标注(Stylized Annotation via Contextual Examples):在生成描述过程中,我们为标注人员(或模型)提供大量风格一致的示例作为上下文参考。这些示例在语气、结构与粒度上提供引导,从而确保整个数据集中标注格式的一致性与风格化。
中英双语标注(Bilingual Annotation, Chinese-English):我们所有的标注均以中文与英文双语形式进行。这不仅提升了数据在不同语言社群中的可用性与通用性,也为多语言模型的训练与评估奠定了基础。
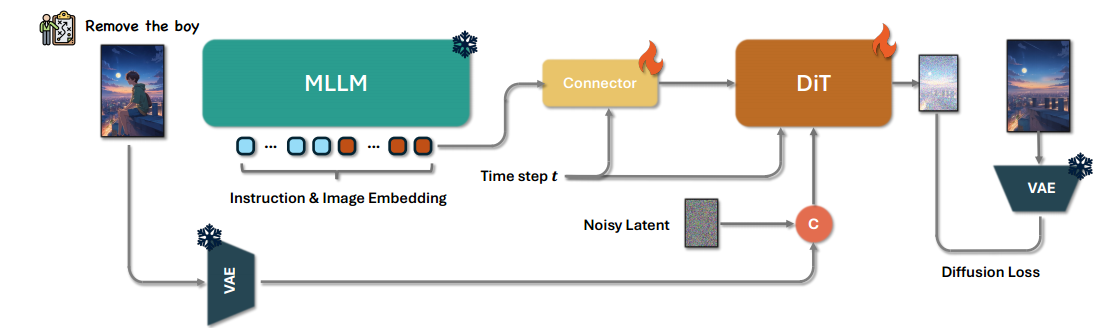
图4:Step1X-Edit框架。Step1X-Edit 利用多模态大语言模型(MLLMs)的图像理解能力解析编辑指令并生成编辑标记,随后通过基于DiT的网络将其解码为图像。
3.2 Our Method
如图4所示,我们的算法包含三个关键组件:多模态大语言模型(Multimedia Large Language Model, MLLM)、连接器模块(connector module)和基于变换器的扩散模型(Diffusion in Transformer, DiT)[41]。输入的编辑指令与参考图像首先被送入 MLLM,例如 QwenVL [3](以下简称为 Qwen)。结合系统前缀,这些输入通过 MLLM 的一次前向传递被联合处理,使模型能够捕捉指令与视觉内容之间的语义关系。为了提取并强调与编辑任务相关的语义信息,我们有选择地丢弃与前缀相关的标记嵌入(token embeddings)。这一筛选过程仅保留与编辑信息直接相关的标记嵌入,从而确保后续处理过程精准聚焦于编辑需求。
提取的嵌入随后被送入一个轻量级的连接器模块,例如 token refiner [32, 24]。该模块将嵌入重构为更紧凑的多模态特征表示,并作为多模态嵌入输入传递给下游的 DiT 网络。此外,我们对 Qwen 输出的有效嵌入取均值,并通过一个线性层进行投影,生成全局引导向量(global guidance vector)。通过这种方式,图像编辑网络能够利用 Qwen 增强的语义理解能力,从而实现更准确且具备上下文感知的编辑操作。
为有效训练 Token Refiner 并实现丰富的跨模态条件控制,我们精心设计了特征聚合策略。与 FLUX-Fill [6] 使用通道拼接的方式不同,或如 SeedEdit [50] 引入额外因果自注意力机制的方法相比,我们借鉴 OminiControl [53] 的策略,采用 token 拼接方式,以更好地在响应编辑指令与保留细粒度图像细节之间取得平衡。在训练过程中,参考图像首先通过 VAE 编码器进行编码,其潜在特征被线性投影为参考图像 token。如图5所示,图像 token(绿色框标注)与噪声图像 token 在 token 长度维度上拼接,构成最终的视觉输入。
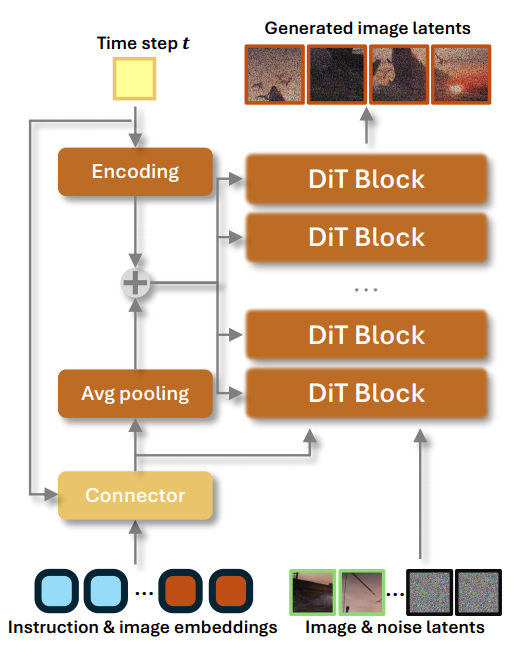
图5:DiT模块详细信息。
近期研究也探索了其他增强跨模态理解的方法,主要依赖 MLLM。例如,Qwen2VL-FLUX [31] 提出了一种创新方法,用 MLLM 替代 DiT 系列文本到图像模型中传统的 T5 [45] 文本编码器,从而增强多模态理解与生成能力。然而,该方法仍保留 T5 [45] 用于文本编码,限制了其实现全面跨模态推理的能力。相较而言,DreamEngine [9] 利用 Qwen 对图像与文本模态进行对齐,并将其特征作为外部条件输入,供 SD3.5 [1] 进行图像生成。该方法建立了一个共享表示空间,促进了更一致的生成与理解流程。但在 DreamEngine 中,仅使用 MLLM 特征仍难以完全捕捉参考图像中的细粒度信息。
相比之下,我们的模型不仅保留了跨模态理解能力,还增强了图像细节的提取能力。通过在统一框架中结合结构化视觉语言引导、细致的视觉条件以及强大的预训练骨干网络,我们的方法大幅提升了系统在多样化用户指令下进行高保真、语义对齐图像编辑的能力。在训练过程中,我们仅基于 diffusion loss 联合优化连接器与下游 DiT,采用 rectified flow [11] 公式进行训练。此外,我们的方法无需依赖 mask loss 技巧即可实现稳定训练,这一点区别于 OmniGen [61]。学习率固定为 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5,以在训练稳定性与收敛速度之间取得良好平衡。
4 Benchmark and Evaluation
4.1 GEdit(Genuine Edit)-Bench
为评估图像编辑模型的性能,我们收集了一个新的基准数据集,名为 GEdit(Genuine Edit)-Bench。该基准的主要动机是收集真实世界的用户编辑实例,用于评估现有图像编辑算法在实际编辑指令下的适用性。更具体地,我们从互联网(如 reddit)收集了超过 1000 条用户编辑实例,并手动将这些编辑指令划分到11个类别中。为保持基准的多样性,我们过滤掉了那些编辑目的相似的指令。最终,我们获得了606个测试样例,这些样例的参考图像均来自真实场景,使其在应用层面上更具真实性。基于 GEdit-Bench,我们评估了现有的开源图像编辑算法(如 ACE++ 与 AnyEdit),以及闭源算法(如 GPT-4o 与 Gemini2 Flash)。
为保障隐私,我们在基准构建过程中实施了全面的去标识化协议。如图6所示,对于每张原始用户上传图像,我们采用多策略的反向图像搜索方法,跨多个公开搜索引擎查找图像,旨在寻找那些在视觉上相似且语义上与原图一致的可公开获取图像,以便与相应的编辑指令无缝对齐。若通过此方法无法找到合适的公开图像替代,我们将系统性地调整编辑指令。这些修改经过精心设计,以最大程度地保持匿名图像-指令样例与原始用户意图之间的一致性。该方法不仅确保了基准数据集的伦理合规性,同时也保留了图像编辑模型评估所需的核心特征,保证了评估的准确性与有效性。

图6:去标识化流程。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)