Deepseek-R1中 Grpo的策略模型的奖励函数
deepseek R1复现中的reward奖励机制函数
·
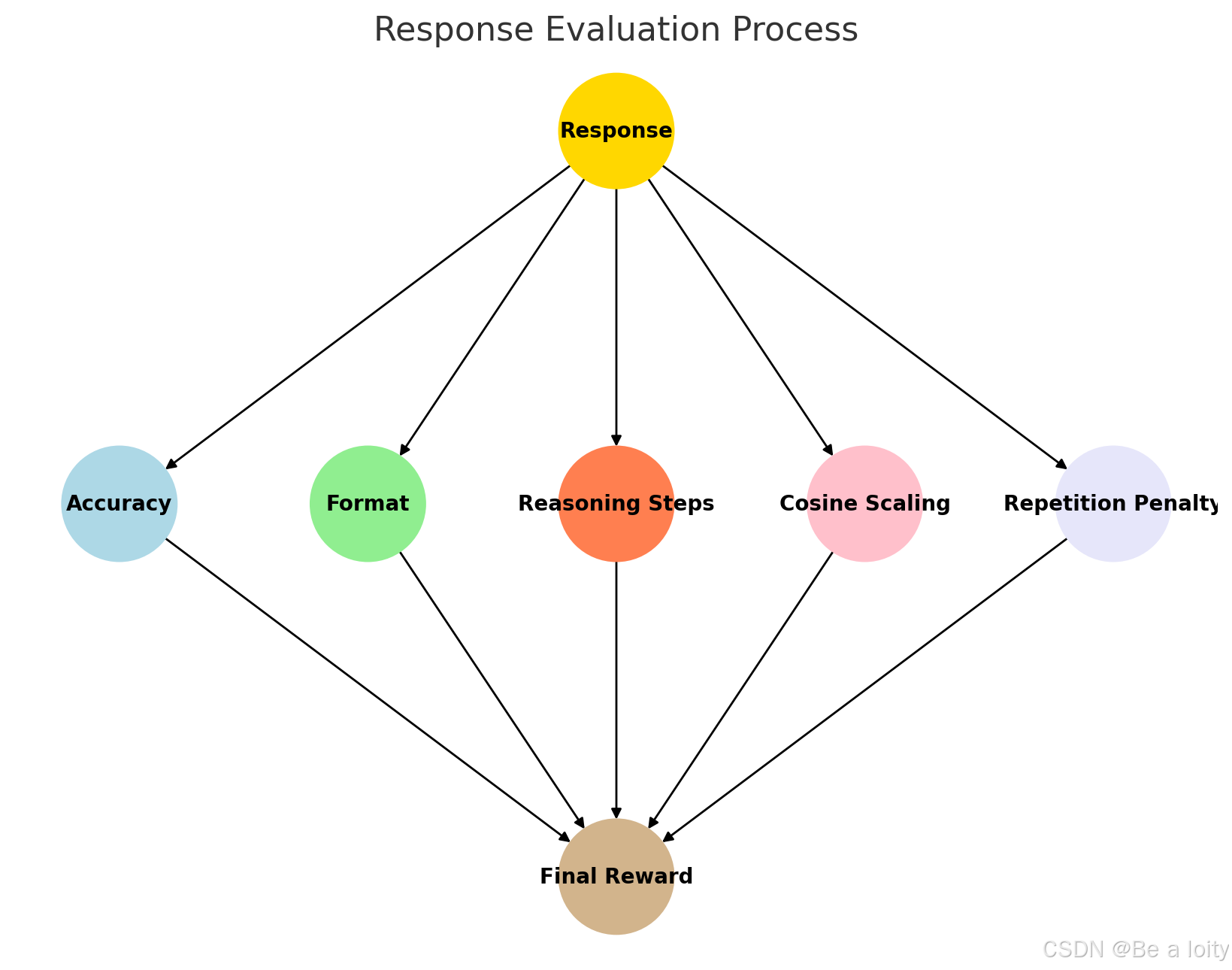
-
Accuracy (is the answer correct?)
准确性(答案正确吗?) -
Format (are the
<think>and<answer>tags used properly?)
格式(<think>和<answer>标签正确使用?) -
Reasoning Steps (is the logic clear?)
推理步骤(逻辑清楚吗?) -
Cosine Scaling (is the response concise?)
余弦缩放(响应简洁吗?) -
Repetition Penalty (is there unnecessary repetition?).
重复处罚(是否有不必要的重复?)。
def accuracy_reward(completions, solution, **kwargs): """ Reward function to check if the model's response is mathematically equivalent to the ground truth solution. Uses latex2sympy2 for parsing and math_verify for validation. """ # Extract responses contents = [completion[0]["content"] for completion in completions] rewards = [] for content, sol in zip(contents, solution): # Parse the ground truth solution gold_parsed = parse(sol, extraction_mode="first_match", extraction_config=[LatexExtractionConfig()]) if gold_parsed: # Check if parsing was successful # Parse the model's answer with relaxed normalization answer_parsed = parse( content, extraction_config=[ LatexExtractionConfig( normalization_config=NormalizationConfig( nits=False, malformed_operators=False, basic_latex=True, equations=True, boxed="all", units=True, ), boxed_match_priority=0, try_extract_without_anchor=False, ) ], extraction_mode="first_match", ) # Reward 1.0 if correct, 0.0 if incorrect reward = float(verify(answer_parsed, gold_parsed)) else: # If ground truth cannot be parsed, assign neutral reward (0.5) reward = 0.5 print("Warning: Failed to parse gold solution:", sol) rewards.append(reward) return rewards# Implement Format Reward Function def format_reward(completions, **kwargs): """ Reward function to check if the completion has the correct format: <think>...</think> <answer>...</answer>. """ # Define the regex pattern for the desired format pattern = r"^<think>.*?</think>\s*<answer>.*?</answer>$" # Extract the content from each completion completion_contents = [completion[0]["content"] for completion in completions] # Check if each completion matches the pattern matches = [re.match(pattern, content, re.DOTALL | re.MULTILINE) for content in completion_contents] # Reward 1.0 for correct format, 0.0 otherwise return [1.0 if match else 0.0 for match in matches]def reasoning_steps_reward(completions, **kwargs): r""" Reward function to encourage clear step-by-step reasoning. It looks for patterns like "Step 1:", numbered lists, bullet points, and transition words. """ # Regex pattern to find indicators of reasoning steps pattern = r"(Step \d+:|^\d+\.|\n-|\n\*|First,|Second,|Next,|Finally,)" # Extract completion contents completion_contents = [completion[0]["content"] for completion in completions] # Count the number of reasoning step indicators in each completion matches = [len(re.findall(pattern, content, re.MULTILINE)) for content in completion_contents] # Reward is proportional to the number of reasoning steps, maxing out at 1.0 # We're using a "magic number" 3 here - encourage at least 3 steps for full reward return [min(1.0, count / 3) for count in matches]# Implement Cosine Scaled Reward Function def get_cosine_scaled_reward( min_value_wrong: float = -0.5, max_value_wrong: float = -0.1, min_value_correct: float = 0.8, max_value_correct: float = 1.0, max_len: int = 1000, ): """ Returns a cosine scaled reward function. This function scales the accuracy reward based on completion length. Shorter correct solutions get higher rewards, longer incorrect solutions get less penalty. """ def cosine_scaled_reward(completions, solution, accuracy_rewards, **kwargs): """ Cosine scaled reward function that adjusts accuracy rewards based on completion length. """ contents = [completion[0]["content"] for completion in completions] rewards = [] for content, sol, acc_reward in zip(contents, solution, accuracy_rewards): gen_len = len(content) # Length of the generated answer progress = gen_len / max_len # How far we are to max length cosine = math.cos(progress * math.pi) # Cosine value based on progress if acc_reward > 0.5: # Assuming accuracy_reward gives ~1.0 for correct answers min_value = min_value_correct max_value = max_value_correct else: # Incorrect answer min_value = max_value_wrong # Note the swap! max_value = min_value_wrong # Cosine scaling formula! reward = min_value + 0.5 * (max_value - min_value) * (1.0 + cosine) rewards.append(float(reward)) return rewards return cosine_scaled_reward
def get_repetition_penalty_reward(ngram_size: int = 3, max_penalty: float = -0.1):
"""
Returns a repetition penalty reward function. Penalizes repetitions of n-grams
in the generated text.
"""
if max_penalty > 0:
raise ValueError(f"max_penalty {max_penalty} should not be positive")
def zipngram(text: str, ngram_size: int):
"""Helper function to generate n-grams from text."""
words = text.lower().split() # Lowercase and split into words
return zip(*[words[i:] for i in range(ngram_size)]) # Create n-grams
def repetition_penalty_reward(completions, **kwargs) -> float:
"""
Repetition penalty reward function.
"""
contents = [completion[0]["content"] for completion in completions]
rewards = []
for completion in contents:
if completion == "": # No penalty for empty completions
rewards.append(0.0)
continue
if len(completion.split()) < ngram_size: # No penalty for short completions
rewards.append(0.0)
continue
ngrams = set() # Use a set to store unique n-grams
total = 0
for ng in zipngram(completion, ngram_size): # Generate n-grams
ngrams.add(ng) # Add n-gram to the set (duplicates are ignored)
total += 1 # Count total n-grams
# Calculate scaling factor: more repetition -> higher scaling
scaling = 1 - len(ngrams) / total
reward = scaling * max_penalty # Apply penalty based on scaling
rewards.append(reward)
return rewards
return get_repetition_penalty_reward
中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)