使用Gradio简单实现ElasticSearch RAG多路召回
带您从0快速搭建一个基于Elastic Search的多路召回RAG,前端使用Gradio快速生成
·
Elasticsearch 自7.3版本之后引入向量检索功能,支持高维向量字段类型、向量相似性函数以及用于暴力搜索的密集向量脚本函数
为什么采用ES作为向量数据库?
1.ES 结合了传统全文检索和向量检索的优势,支持混合查询。用户可以在同一个请求中执行语义搜索和全文搜索任务,无需调用多个系统。
2.ES后端开发比较熟悉,上手快
RAG多路召回流程图
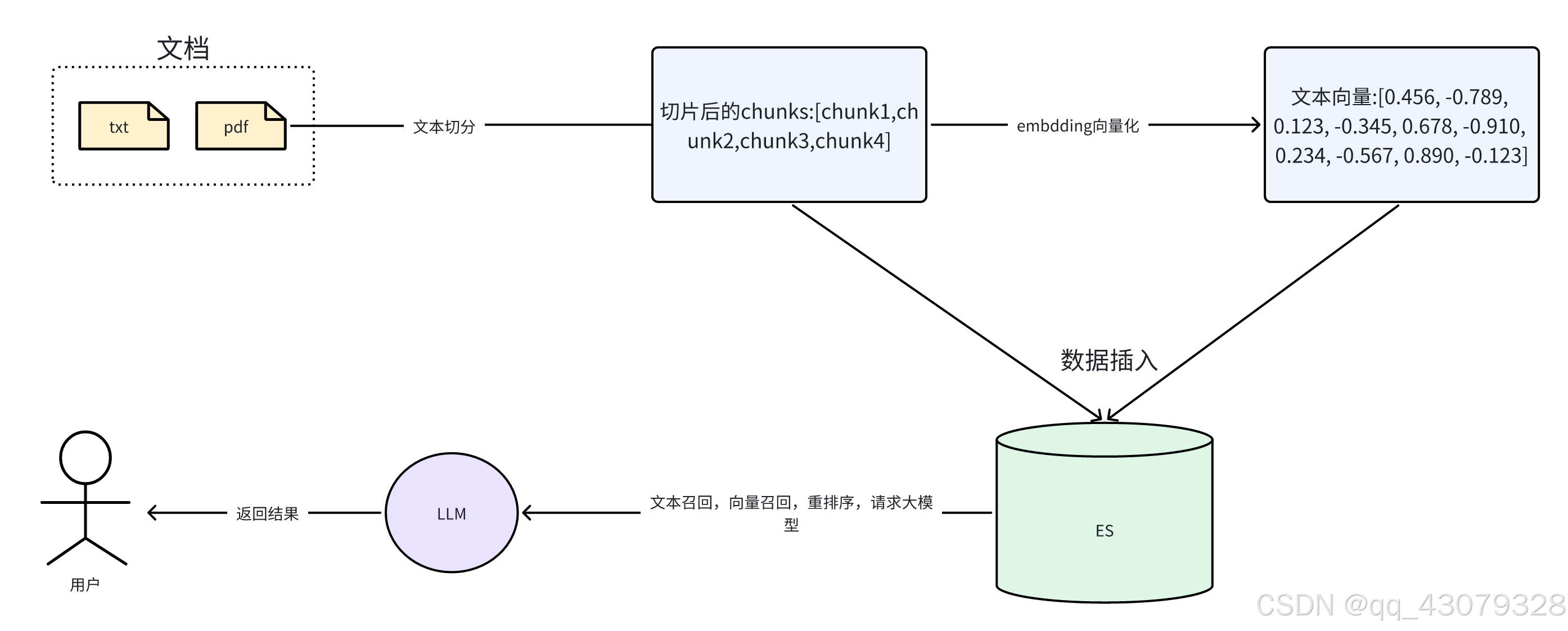
本地环境:
1.ElasiticSearch =8.1
2.python =3.12
3.huggingface_hub
python依赖包
gradio
requests
elasticsearch
spacy
langchain
langchain-community
langchain-openai
jieba
sentence-transformers
numpy
PyMuPDF
easyocr
代码部分:
下载BGE模型,huggingface命令下载bge-base-zh
huggingface-cli download --resume-download BAAI/bge-base-zh --local-dir ./bge-base-zh
代码流程图:
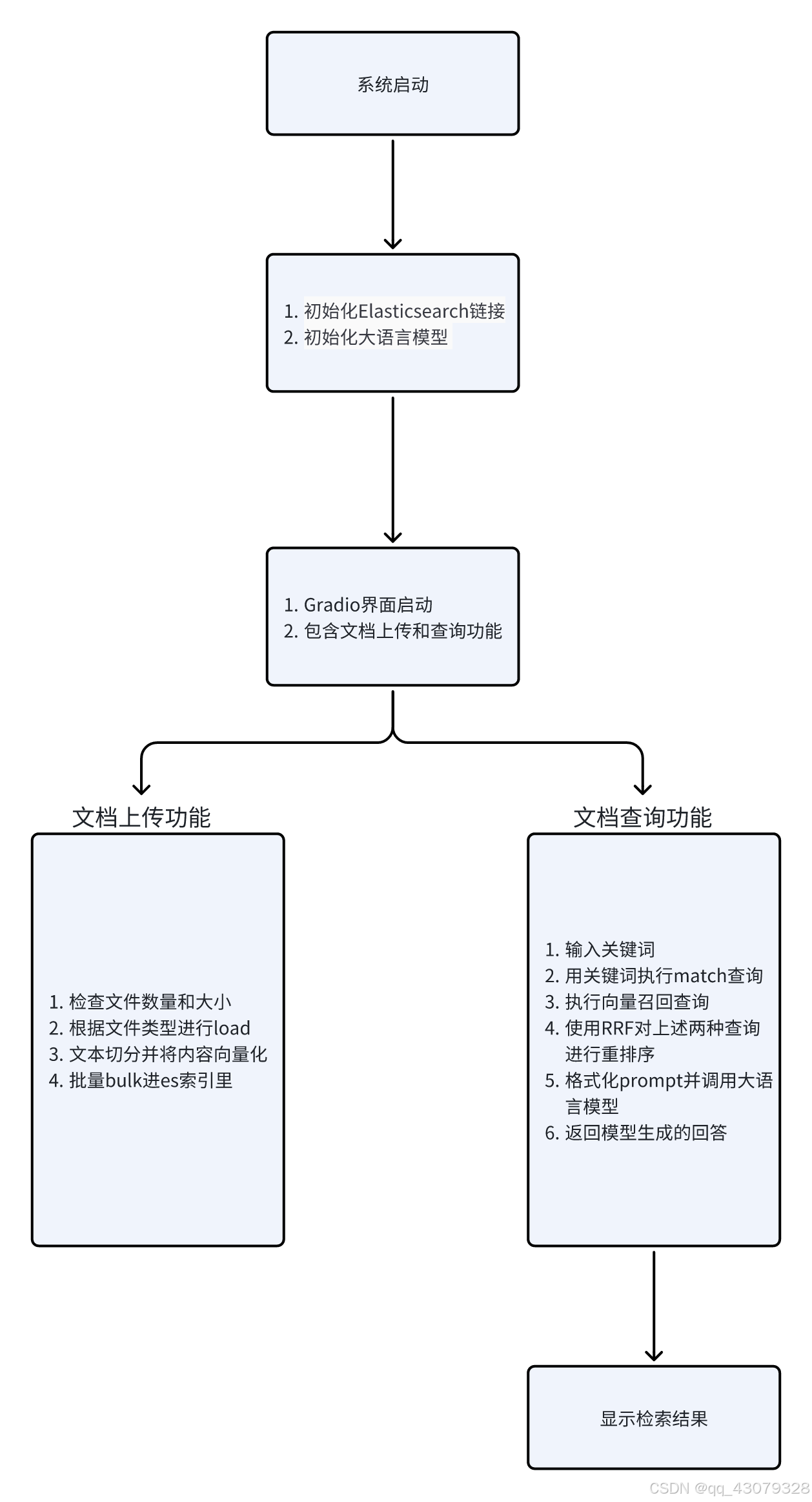
导包
# 导入所需的库
import gradio as gr # 用于创建交互式界面
import requests # 用于发送HTTP请求
from elasticsearch import Elasticsearch, helpers # Elasticsearch客户端和批量操作助手
import spacy # 自然语言处理库
from langchain.document_loaders import TextLoader # 用于加载文本文件
from langchain_community.document_loaders import PyPDFLoader # 用于加载PDF文件
from typing import List # 类型注解
import jieba # 中文分词库
from langchain.text_splitter import RecursiveCharacterTextSplitter # 用于切分文本
from sentence_transformers import SentenceTransformer # 用于文本嵌入
import numpy as np # 数学计算库
import json # JSON操作
from collections import defaultdict # 用于创建默认字典
import fitz # 用于处理PDF文件
import os # 操作系统接口
import easyocr # 用于OCR文字识别
from langchain_openai import ChatOpenAI # 用于调用OpenAI模型
初始化ES和大模型
# 初始化SentenceTransformer模型,使用中文版本的BGE模型
model = SentenceTransformer('BAAI/bge-base-zh')
# 配置Elasticsearch连接
# 注意:这里的URL和认证信息需要根据实际情况替换
es = Elasticsearch("http://es-cn-20ek2eedl.elasticsearch.aliyuncs.com:9200",
basic_auth=("elastic", "pm5rPoNGrCq1Yw7y7z"))
es_index = "liyu_content_vec_768" # Elasticsearch索引名称
创建Gradio界面并运行
# 创建Gradio界面
with gr.Blocks() as demo:
gr.Markdown("文档上传并索引到Elasticsearch")
# 文档上传组件
with gr.Row():
file_upload = gr.Files(label="上传文档", type="filepath")
upload_button = gr.Button("上传并索引")
result_output = gr.Textbox(label="上传结果")
upload_button.click(upload_and_index_documents, inputs=file_upload, outputs=result_output)
# 对话组件
gr.Markdown("对话框")
with gr.Row():
query_input = gr.Textbox(label="输入问题")
query_button = gr.Button("查询")
query_output = gr.Markdown(label="查询结果")
query_button.click(handle_query, inputs=query_input, outputs=query_output)
# 运行Gradio应用
demo.launch(server_port=8112, server_name='0.0.0.0')
文档上传
# 将PDF文件转换为字符串数组
def pdf2StrArray(file_path):
"""
将PDF文件转换为字符串数组,支持OCR文字识别。
:param file_path: PDF文件路径
:return: 返回一个包含文本片段的列表
"""
doc = fitz.open(file_path) # 加载PDF文档
mat = fitz.Matrix(2, 2) # 定义矩阵,用于调整图片分辨率
image_dir = "exact" # 保存图片的目录
if not os.path.exists(image_dir):
os.makedirs(image_dir) # 创建目录
page_count = len(doc) # 获取文档页数
for i, page in enumerate(doc): # 遍历每一页
pix = page.get_pixmap(matrix=mat) # 将页面转换为图片
pix.save(f"{image_dir}/image_{i+1}.png") # 保存图片
doc.close() # 关闭文档
reader = easyocr.Reader(['ch_sim']) # 初始化OCR读取器,支持中文简体
all_results = [] # 存储所有页面的识别结果
for i in range(page_count): # 遍历所有图片
image_path = f"{image_dir}/image_{i+1}.png"
page_content_list = reader.readtext(image_path, detail=0) # 识别文字
page_content = ' '.join(page_content_list) # 合并识别结果
# 切分文本为小片段
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50, # 每个片段的大小
chunk_overlap=0, # 片段重叠部分
length_function=len,
separators=["\n\n"]
)
docs = text_splitter.split_text(page_content)
all_results.extend(docs) # 将片段添加到结果列表
return all_results
# 将文本文件转换为字符串数组
def text2Array(file_path):
"""
将文本文件转换为字符串数组。
:param file_path: 文本文件路径
:return: 返回一个包含文本片段的列表
"""
loader = TextLoader(file_path) # 加载文本文件
documents = loader.load() # 加载文档内容
# 切分文本为小片段
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=0,
length_function=len
)
docs = text_splitter.split_documents(documents)
# 确保返回的是一个包含字符串的列表
return [doc.page_content for doc in docs]
# 上传文档并索引到Elasticsearch Gradio绑定方法
def upload_and_index_documents(files):
"""
上传文档并将其内容索引到Elasticsearch。
:param files: 文件路径列表
:return: 返回上传结果信息
"""
results = [] # 存储上传结果
max_files = 3 # 最大文件数量
max_file_size = 10 * 1024 * 1024 # 最大文件大小(10MB)
# 检查文件数组是否为空
if files is None:
return "文件数组不能为空"
# 检查文件数量是否超过上限
if len(files) > max_files:
return f"文件数量不能超过{max_files}个"
for file in files:
file_name = file.split('/')[-1] # 提取文件名
file_size = os.path.getsize(file) # 获取文件大小
# 检查文件大小是否超过上限
if file_size > max_file_size:
return f"文件{file_name}大小超过{max_file_size / (1024 * 1024)}MB"
# 根据文件类型处理内容
if file.lower().endswith('.txt'):
docs = text2Array(file) # 处理文本文件
elif file.lower().endswith('.pdf'):
docs = pdf2StrArray(file) # 处理PDF文件
else:
return f"不支持的文件类型: {file}"
# 生成Elasticsearch批量操作
actions = [
{
"_index": es_index, # 索引名称
"_id": i, # 文档ID
"_source": {
"title": file_name, # 文件名作为标题
"content": doc, # 文档内容
"content_vector": model.encode(doc).tolist() # 文本嵌入向量
}
}
for i, doc in enumerate(docs)
]
# 执行批量索引操作
helpers.bulk(es, actions)
results.append(f"文档 {file_name} 上传并索引成功")
return "\n".join(results)
文档查询
# 计算RRF(Rank Reciprocal Fusion)得分
def calculate_rrf_score(rank_lists, k=60):
"""
计算RRF得分,用于融合多个排名列表。
:param rank_lists: 多个排名列表,每个列表包含文档信息
:param k: RRF公式中的常数
:return: 返回一个字典,键为文档ID,值为RRF得分
"""
rrf_scores = defaultdict(float) # 创建一个默认值为0的字典
for rank_list in rank_lists: # 遍历每个排名列表
for rank, doc in enumerate(rank_list, start=1): # 遍历排名列表中的文档
doc_id = doc["_id"]
rrf_scores[doc_id] += 1 / (k + rank) # 累加RRF得分
for doc_id in rrf_scores: # 调整RRF得分
rrf_scores[doc_id] = 1 / rrf_scores[doc_id]
return rrf_scores
# 使用RRF对两个响应结果进行重排序
def rerank_responses_rrf(response1, response2, k=60):
"""
使用RRF对两个Elasticsearch响应结果进行重排序。
:param response1: 第一个响应结果
:param response2: 第二个响应结果
:param k: RRF公式中的常数
:return: 返回重排序后的响应结果
"""
hits1 = response1["hits"]["hits"] # 提取第一个响应的文档列表
hits2 = response2["hits"]["hits"] # 提取第二个响应的文档列表
combined_hits = hits1 + hits2 # 合并两个文档列表
# 使用字典去重,键为文档ID,值为整个文档字典
unique_hits_dict = {hit["_id"]: hit for hit in combined_hits}
unique_hits = list(unique_hits_dict.values()) # 将字典的值转换回列表
# 计算RRF得分
rrf_scores = calculate_rrf_score([unique_hits], k)
# 按RRF得分排序
unique_hits.sort(key=lambda x: rrf_scores[x["_id"]], reverse=True)
# 创建新的重排序响应结果
reranked_response = {
"hits": {
"total": {"value": len(unique_hits), "relation": "eq"},
"max_score": unique_hits[0]["_score"] if unique_hits else None,
"hits": unique_hits,
}
}
return reranked_response
# 初始化大语言模型
glm_model = ChatOpenAI(
model='glm-4-flash', # 模型名称
openai_api_base="https://open.bigmodel.cn/api/paas/v4/", # API地址
openai_api_key="e616ba26d769ddda249683860a5e07b5.Z7rbsETeXvqmazOM", # API密钥
max_tokens=500, # 最大生成长度
temperature=0.7 # 温度参数
)
# 定义RAG的prompt模板
prompt = '''
任务目标:对检索出的文本数组内容进行重排序,请根据你的理解对其进行重排序,使得与问题相关性高的答案排在前面,每个元素都是以_id开头。
任务要求:
1. 文档排序时把直接相关例如检索文本完全一致的放在前面,间接相关排到后面。
2. 在回答问题时,应尽量引用文档中的关键信息和数据,以增强回答的可信度和准确性。
3. 回答应条理清晰、逻辑严谨,避免语义模糊或表述不清的情况出现。
4. 无关联的答案可以不用返给我了。
5. 希望结果以json结构返回一个对象数组,对象包括_id,content字段,title字段,和相关描述字段(description)等。
6. 帮我把返回对象的字段映射成中文名,映射关系:_id:ID,content:文本内容,title:文本来源,description不变。
用户问题:
{}
检索出的文档数组:
{}
'''
# 处理用户查询 Gradio绑定方法
def handle_query(search_word):
"""
处理用户查询,执行检索并调用大语言模型生成回答。
:param search_word: 用户输入的查询词
:return: 返回大语言模型生成的回答
"""
if not search_word:
return "查询词不能为空"
# 执行Elasticsearch的match查询
term_response = es.search(index=es_index, body={
"query": {
"match": {
"content": search_word
}
},
"size": 5 # 返回的文档数量
})
# 将查询词转换为向量
query_vector = model.encode(search_word)
# 执行Elasticsearch的向量召回查询
cosine_response = es.search(index=es_index, body={
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.content_vector, 'content_vector') + 1.0",
"params": {
"content_vector": query_vector
}
}
}
},
"size": 5
})
# 使用RRF对两个查询结果进行重排序
reranked_response = rerank_responses_rrf(term_response, cosine_response)
# 提取重排序后的文档内容
search_results = [
f"_id: {hit['_id']}\ntitle: {hit['_source'].get('title', 'No Title')}\nContent: {hit['_source']['content']}"
for hit in reranked_response["hits"]["hits"]
]
# 如果没有找到结果,返回提示信息
if not search_results:
return "没有找到相关结果。"
# 格式化prompt并调用大语言模型
format_str = prompt.format(search_word, ' '.join(search_results))
res = glm_model.invoke(format_str)
return res.content

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)