SLAM-Former:一个Transformer搞定SLAM-Former
同时课程详细介绍了。
SLAM-Former是清华大学提出的新型SLAM系统,将传统SLAM的前端实时跟踪与后端全局优化功能统一到一个Transformer模型中。该模型通过三种训练模式学习前后端能力,并利用全局注意力机制实现前后端协同优化,后端优化结果通过KV缓存反馈给前端,形成良性循环。实验表明,SLAM-Former在多个SLAM benchmark上轨迹精度和重建质量均优于现有方法,实现了SLAM系统架构的革新。
搞SLAM(即时定位与地图构建)的同学都知道,传统方法通常是个“流水线”作业,分成前端和后端两个模块。前端负责实时追踪相机位置、处理传感器数据,后端则负责优化轨迹、闭环检测,修正累积误差。这种分体式设计虽然经典,但也带来了模块间协作复杂、误差传递等问题。
今天,CV君要给大家聊一篇超酷的工作,来自清华大学等机构的研究者们提出了一个名为 SLAM-Former 的新东西,它的核心思想有点颠覆:把整个SLAM的功能,全都塞进一个Transformer里!
没错,你没听错,就是一个统一的模型,同时搞定前端的实时跟踪和后端的全局优化。听起来是不是很带感?我们一起来看看他们是怎么做到的。

- 论文标题:SLAM-Former: Putting SLAM into One Transformer
- 作者:Yijun Yuan, Zhuoguang Chen, Kenan Li, Weibang Wang, Hang Zhao
- 机构:清华大学
- 论文地址:https://arxiv.org/abs/2509.16909
- 项目地址:https://tsinghua-mars-lab.github.io/SLAM-Former/
传统SLAM的“分工”与SLAM-Former的“大一统”
在传统的视觉SLAM系统中,通常是这样的工作模式:
- 前端(Frontend):像个侦察兵,负责处理实时的图像流,快速估算相机每时每刻的相对运动,这个过程叫作视觉里程计(Visual Odometry)。它追求速度,但不可避免地会产生累积误差。
- 后端(Backend):像个指挥官,它会拿到前端的数据,进行全局分析。比如,当相机回到一个去过的地方时,后端需要识别出“哦,我来过这里”(闭环检测),然后通过全局优化(如Bundle Adjustment或姿态图优化)来修正整个轨迹和地图,消除前端的累积误差。
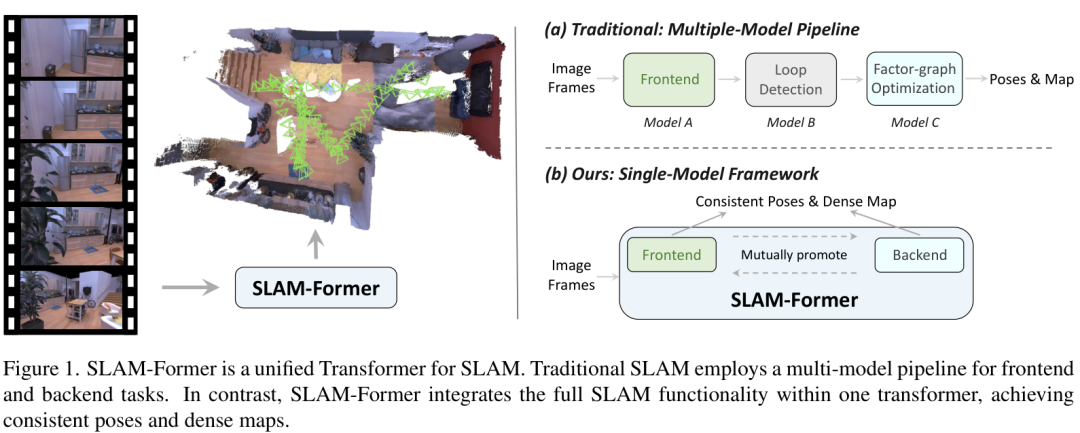
这种前后端分离的模式虽然有效,但就像两个部门协作,总需要数据交接和磨合。而SLAM-Former的目标就是打破这种隔阂,让整个系统成为一个有机的整体。
SLAM-Former:一个模型,两种角色
SLAM-Former巧妙地设计了一个统一的Transformer架构,让它能同时扮演前端和后端的角色,并且这两个角色还能“互相促进”。
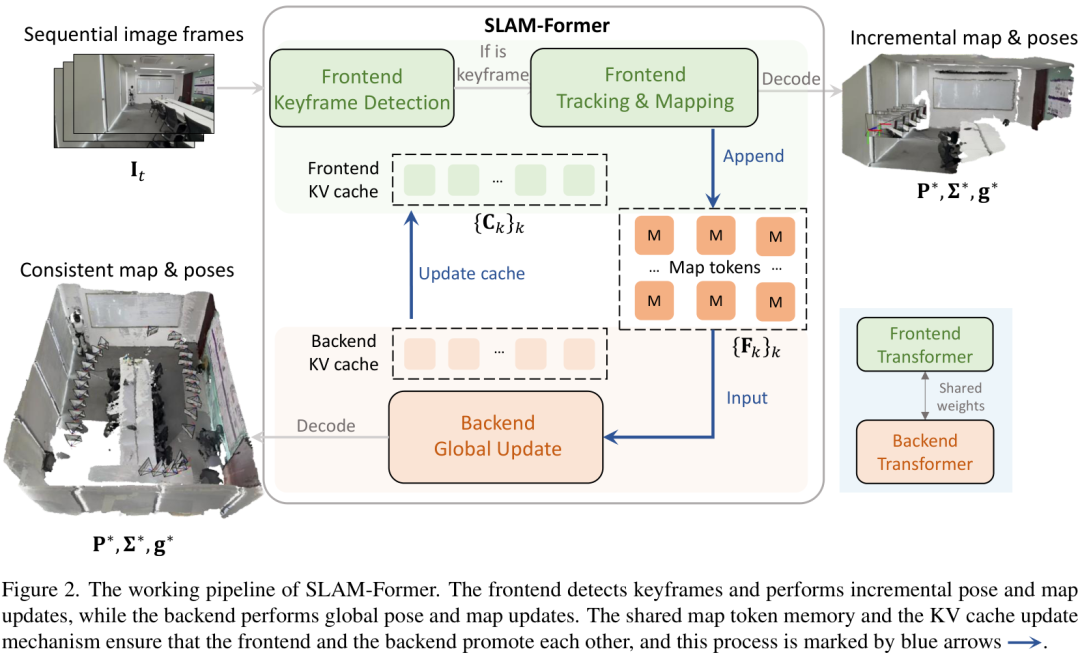
上图就是SLAM-Former的工作流程,我们可以看到:
- 输入:连续的图像帧(Sequential image frames)。
- 前端角色:当新的图像帧进来时,模型会进行关键帧检测,并执行增量式的跟踪和建图(Frontend Tracking & Mapping)。这个过程是实时的,保证了系统的效率。
- 后端角色:每隔一段时间(比如每T个关键帧),模型就会启动“全局更新”(Backend Global Update)。它会利用强大的全局注意力机制(Full Attention)来审视过去所有的关键帧和地图信息,进行一次彻底的优化,修正漂移,确保全局地图的一致性。
- 核心机制:互相促进:最妙的地方在于,前端和后端不是孤立的。后端优化后的结果(比如更准确的地图信息)会通过更新共享的KV缓存(KV cache)反馈给前端。这样,前端在处理新图像时,就有了更精确的先验知识,从而能更准确地进行跟踪。反过来,前端提供的连续、有序的帧信息也帮助后端更好地理解场景的拓扑结构,进行更有效的优化。
统一模型的训练策略
为了让一个模型同时学会前端和后端两种能力,作者设计了三种训练模式,并在一次迭代中交替进行:
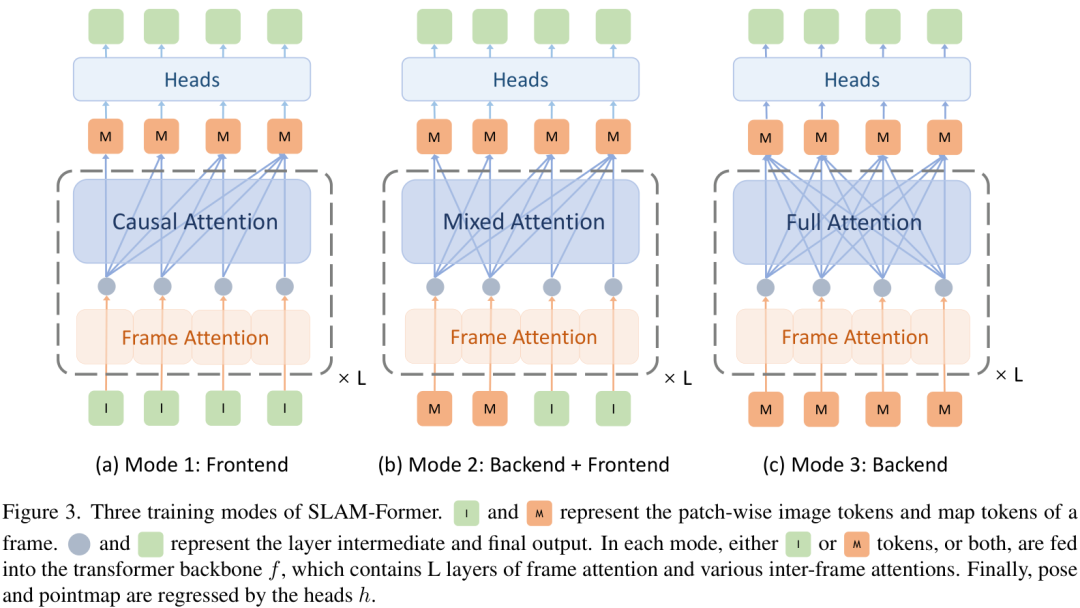
- 模式1:前端训练(Causal Attention):模拟在线跟踪场景,模型只能看到当前和过去的帧,不能“预知未来”。
- 模式2:后端+前端协同训练(Mixed Attention):一部分信息使用全局注意力(模拟后端优化),另一部分新来的信息使用因果注意力(模拟前端利用后端优化结果进行跟踪)。
- 模式3:后端训练(Full Attention):模型可以“纵览全局”,对所有输入信息进行无限制的注意力计算,专注于全局一致性的优化。
通过这种联合训练,SLAM-Former学会了在不同模式下无缝切换,实现了“一机两用”。
实验效果:精度与质量齐飞
理论说得再好,还得看疗效。作者在多个主流的SLAM benchmark上进行了测试,包括TUM RGB-D、7-Scenes和Replica。
轨迹精度(ATE)
在轨迹精度方面,SLAM-Former展现了非常强的竞争力。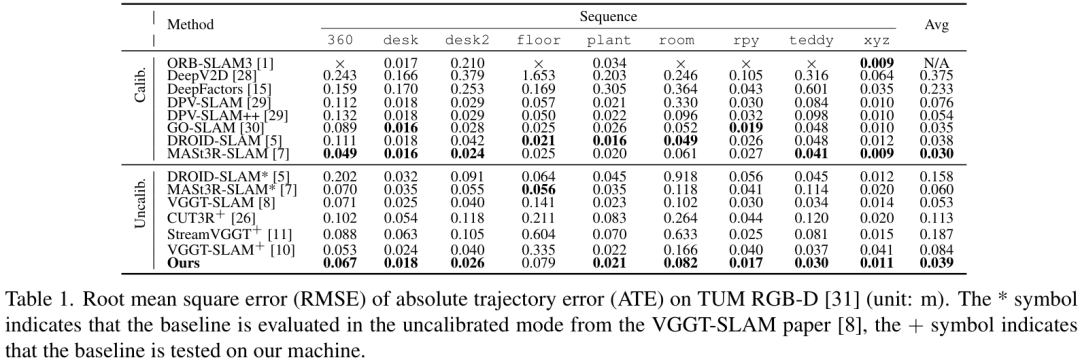 在TUM RGB-D数据集上,SLAM-Former的平均ATE(绝对轨迹误差)达到了 0.039m,优于很多SOTA方法。
在TUM RGB-D数据集上,SLAM-Former的平均ATE(绝对轨迹误差)达到了 0.039m,优于很多SOTA方法。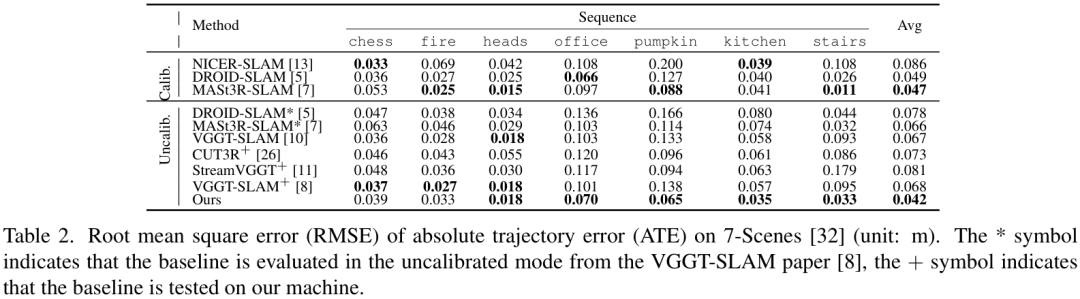 在更具挑战性的7-Scenes数据集上,它的表现同样出色,平均ATE为 0.042m,全面超越了对比的基线模型。
在更具挑战性的7-Scenes数据集上,它的表现同样出色,平均ATE为 0.042m,全面超越了对比的基线模型。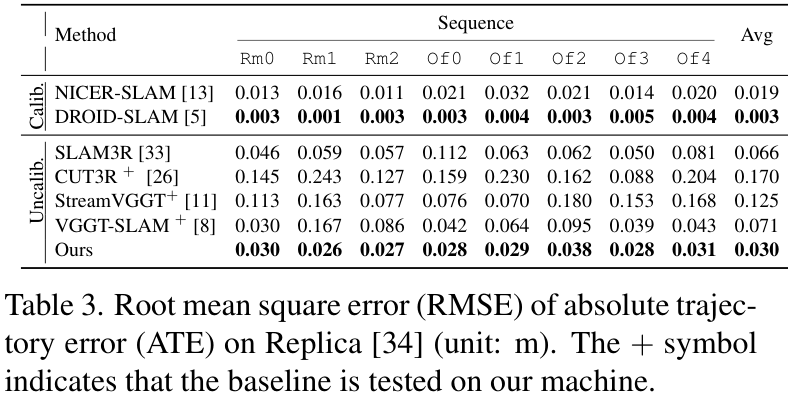 在Replica合成数据集上,也取得了极具竞争力的结果。
在Replica合成数据集上,也取得了极具竞争力的结果。
重建质量
除了轨迹精度高,建图的质量也非常关键。

从上图的定性比较可以看出,像StreamVGGT和VGGT-SLAM等方法在重建的场景中出现了明显的结构错误和错位(红框部分),而SLAM-Former得益于其全局一致性优化,重建的结构非常完整和准确。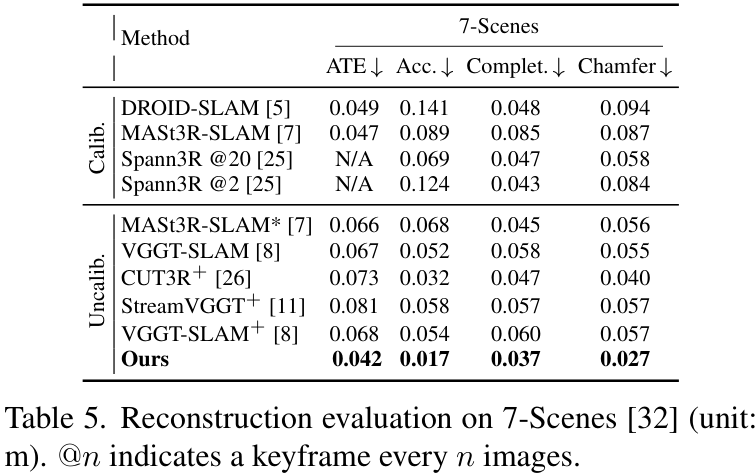 0.017m,比其他方法高出约 50% 。
0.017m,比其他方法高出约 50% 。
前后端协同作用的威力
为了证明前后端“互相促进”的有效性,作者做了一个消融实验。
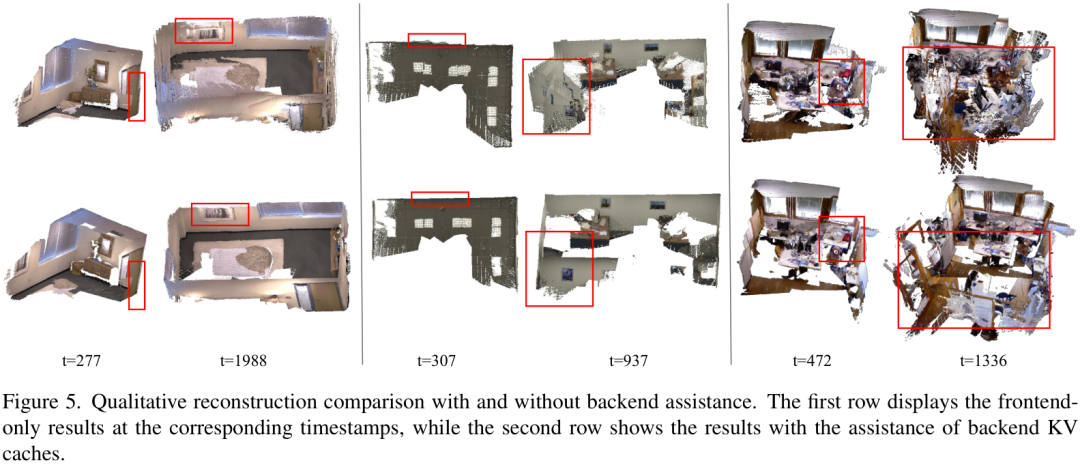
上图展示了有无后端辅助的重建效果对比。第一行是只有前端工作时的结果,可以看到随着时间推移,模型累积了误差,导致重建结果(如墙面)严重变形。而第二行加入了后端优化后,重建的场景始终保持着良好的一致性和准确性。

同样,如果只给后端一堆无序的关键帧(不带前端提供的时序信息),像VGGT和Pi3这样的模型会产生混乱的重建结果。而SLAM-Former的后端因为利用了前端的隐式顺序,能够生成更连贯、准确的地图。
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献200条内容
已为社区贡献200条内容

所有评论(0)