Agent学习Day1——产品拆解
AI Context Flow——让你不再需要向每个AI重复解释自己。注:本文作为Datawhale/动手学Agent应用开发课程的作业,旨在从需求发现、产品设计与开发、产品运营增长等角度,尝试拆解一个Agent产品/项目案例,提高对Agent开发的认知。
注:本文作为Datawhale/动手学Agent应用开发课程的作业,旨在从需求发现、产品设计与开发、产品运营增长等角度,尝试拆解一个Agent产品/项目案例,提高对Agent开发的认知。
本次拆解案例:AI Context Flow

目录
需求发现
需求场景
想象一下这个画面:
作为一个吃上了“AI红利”的计算机专业大学生,你已经熟练使用AI写论文、敲代码、学课程、
水一水PU校园活动这天,导师向你发来了一个新任务,带着一堆压缩包以及他的灵感来源——一篇微信公众号文章《重大突破!……》。
你满口答应,随后熟练地开启魔法,顺手打开浏览器收藏夹。“Claude、GPT、Gemini、Grok……太好了你们都在!”
你信心满满地开始拆解任务,针对每一步小目标上传文档、精确撰写需求Prompt,发现结果不错,继续开始下一个小目标。
一切顺利,直到你发现AI开始遗忘上下文、不得不换一个AI或者开启新对话时,噩梦开始了:
你将被迫向新的AI重新描述任务背景、要解决的问题,还要自己总结之前的对话,这些上下文往往被完整保留,因为提取出真正有用的部分是个额外的脑力活。
在经历过几次后,你的上下文就会逐渐变得冗长且混乱,最终在无数次复制粘贴、上传同样的文档后,看看手表,吼出那句
“K!还不如我自己做”
产品定位
我相信很多人也有同样的经历。始终困扰AI使用者的问题是:AI明明很强,却记不住事,而且不同的AI无法共享上下文,我们不得不像教婴儿说话一样不断向它们重复,白白浪费时间。
AI世界急需一个共享记忆的大脑!
AI Context Flow抓住了这个需求
让我们看看开发者的产品介绍:

总结为一句话就是
“Context is all you need”
竞品比较
事实上,有很多同类产品尝试解决上下文问题,主要通过两种方式:
- 知识库管理:腾讯旗下的ima是典型代表,尽管这类产品实际上是为了让AI结合知识库回答问题,但笔者也常用它来生成更加精准的提示词,以尝试间接地压缩上下文。
- 多代理协作:Sider是这类产品的佼佼者,它允许你调遣多个AI回答一个问题,以实现共享对话记忆。
然而,这两种方式都不能彻底解决问题。
知识库管理与其说是一个记忆层,不如说是个图书馆,因为它的使用体感太过脱节,主导“记忆调取”这一步的依然是你而不是AI。
多代理协作虽然能让我们一次性和多个AI互动,但依然不能跨对话保持记忆。此外,显然这样的平台不可能由谷歌、OpenAI或者哪个AI大厂官方出品,我们将失去使用官方功能(比如Gemini的Convas画布)的机会。
总而言之,行业内已经有不少开发者和公司关注到了“AI记忆”的问题,但它们大多还停留在“外挂软件”的层面,用户与AI交流的割裂感依然很重。
AI Context Flow则融合了以上几种方案,在知识库管理的基础上,借助插件形式在原生AI应用内使用。
在Chrome插件市场,它介绍自己的优势在于:
🧠 持久的 AI 内存:一次保存您的项目详细信息、客户注释、技术堆栈或品牌声音。
⚡ 一键提示优化:立即注入正确的上下文,无需重新输入冗长的指令。
🌐 跨 AI 可移植性:适用于 ChatGPT、Claude、Gemini、Grok、Perplexity 等。
🗂️ 有组织的上下文:为了清晰起见,将个人项目、客户项目和工作项目分开。
💰 节省令牌和时间:减少重复指令并获得更清晰、更一致的输出。
🔒 隐私第一:端到端加密,从不用于 AI 训练,未经同意不会读取数据。
轻量而优雅地实现AI记忆,这就是它最特别、最成功之处。
产品设计与开发
老实说,我并不喜欢这个“与”字,因为设计“与”开发完全是两个概念,这就像是你向前端工程师扔了一个figma设计稿,它离真正的实现还差得远。
因此,这里分两个小标题来剖析该产品。
产品设计
首先,再明确一下产品需求“跨代理共享的AI记忆层”
第一步,决定产品的形态,它应该是网页端应用、桌面端应用还是移动应用云云。很显然,将AI Context Flow做成Chrome插件绝对是个好主意,快速开发、良好生态、激励政策,也最符合目标客户的使用习惯。
第二步,决定产品的功能,既然是共享记忆,就要独立存储;既然是独立存储,就要易与管理;既然服务于AI代理,就要证明“这不是一个单纯用于保存信息的数据库,而是一个能够管理记忆的Agent”。核心目标是将用户的原始提示词作为检索输入,输出带精准上下文的优化提示词。
(注意!!!要与PromptProt这类提示词优化平台做区分,关键在于“带精准上下文”)
第三步,决定产品的交互,这里做为插件并没有太多要考虑的,只需要注意可视化、一键式的记忆管理即可,确保与网页端AI应用UI的契合度、在不同应用中行为的一致性。
现在,恭喜你得到了AI Context Flow的概念雏形,它将大概长这样(再夸一夸它的UI设计,真的很简洁易懂):

产品开发
这里就涉及到核心技术了,笔者显然不能逆向出来,因此贴一个Producthunt上作者回复的原理解释(手动翻译):
我们已经构建了一个复杂的多层内存索引系统,可以模仿人类记忆的实际工作方式。
以下是我们如何索引不同的内存上下文:
1. 三层记忆(类似于人类记忆)
- 短期记忆:我们逐字保留最后 3 次对话的轮次 - 这是您的“工作记忆”,可以保持直接上下文的新鲜感
- 中期记忆:使用 LLM 智能总结较旧的对话,提取关键事实、决策和实体 - 将其视为您的大脑在睡觉时整合信息
- 长期记忆:所有上传的文档和上下文都转换为语义向量(使用 BGE-large-en-v1.5 进行 1024 维嵌入)并存储在 AWS S3 中以供检索
2. 智能查询-数据分离
在索引之前,我们使用 LLM 分析用户输入并将其分离为:
查询:他们正在询问什么
数据:他们正在提供什么
这防止了"记忆污染",即问题与你想记住的实际信息混合在一起。
3. 多用户隔离
每个记忆都使用分层元数据进行索引:
userId → profileId →上下文/文件→块
这意味着每个用户的记忆是完全隔离的,按用户和配置文件区分(就像为不同项目使用不同的笔记本)。
4. 语义分块与检索
文档不是以原始文本形式存储的 ,我们进行了以下处理:
- 将其分割为语义块
- 生成向量嵌入(捕捉语义,而不仅仅是关键词)
- 使用余弦相似度进行检索(查找概念上相关的内容,即使措辞不同)
5. 基于上下文的优化
我们根据以下因素动态优化内存使用:
- 令牌预算(避免用过多历史信息压垮 AI)
- 语义相关性(仅提取对当前查询有意义的记忆)
- 对话连贯性(在效率和上下文保留之间取得平衡)
神奇之处在哪里?不同于传统的关键词搜索,我们使用基于向量的索引理解语义。
例如:当你询问“我的 Python 代码中用于用户认证的部分是什么?”它就能找到你的登录实现,即使你提供的原始文档中从未使用过“用户认证”这个词。
它是无服务器的,可以自动扩展,因为我们使用的是 AWS S3 Vectors,所以无需管理基础设施。
产品运营增长
通过查看producthunt平台上该应用的历史评论与版本。可以总结出以下几点运营策略(按照短期目标到长期目标排序):
1. 扩展支持的AI应用与服务平台:
- 从GPT、Claude逐步拓展到Gemini、Grok
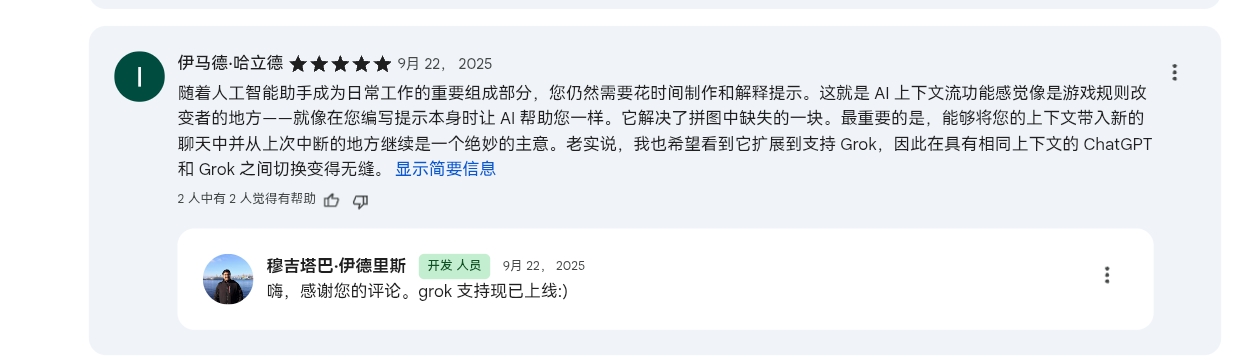
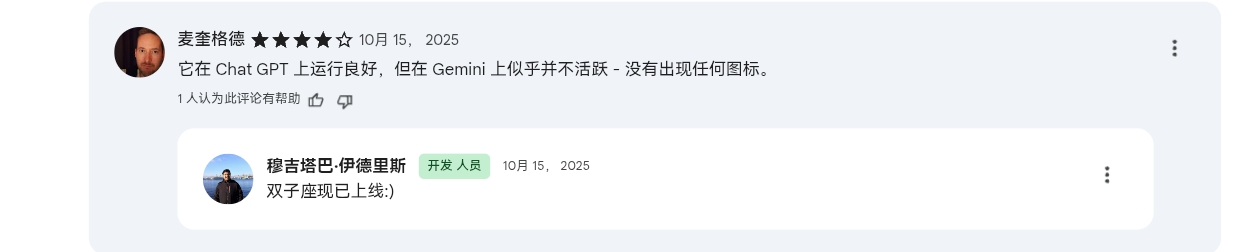
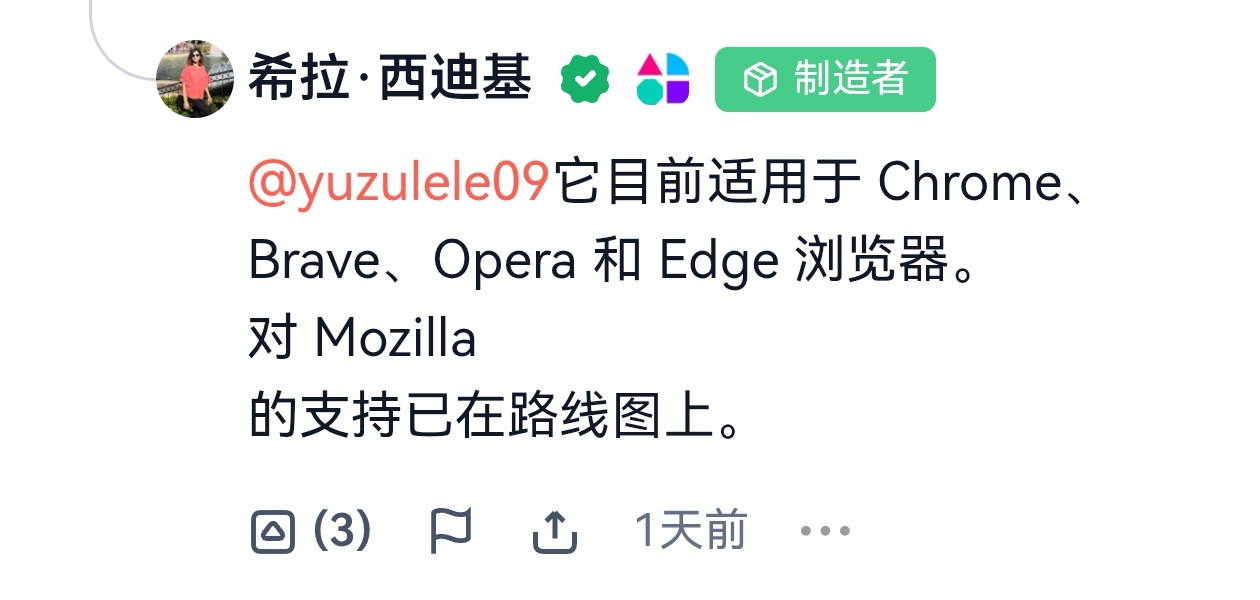
- 从Chrome、Edge逐步拓展到Mozilla
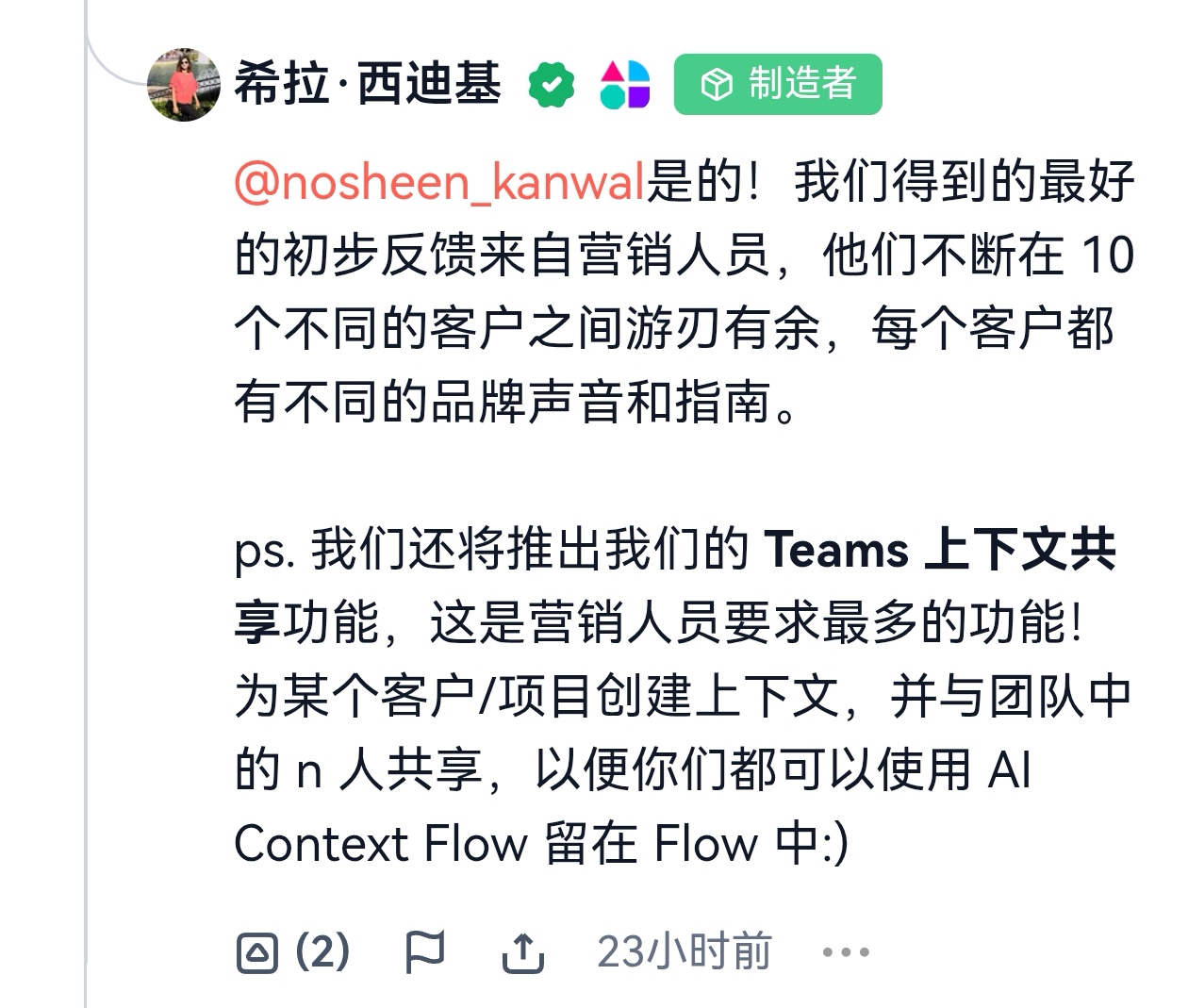
2. 推出不同级别的免费、付费计划:
3. 尝试与AI原生协议集成:开发MCP 服务,使其成为 AI 系统可调用、可感知、可交互的上下文扩展模块。
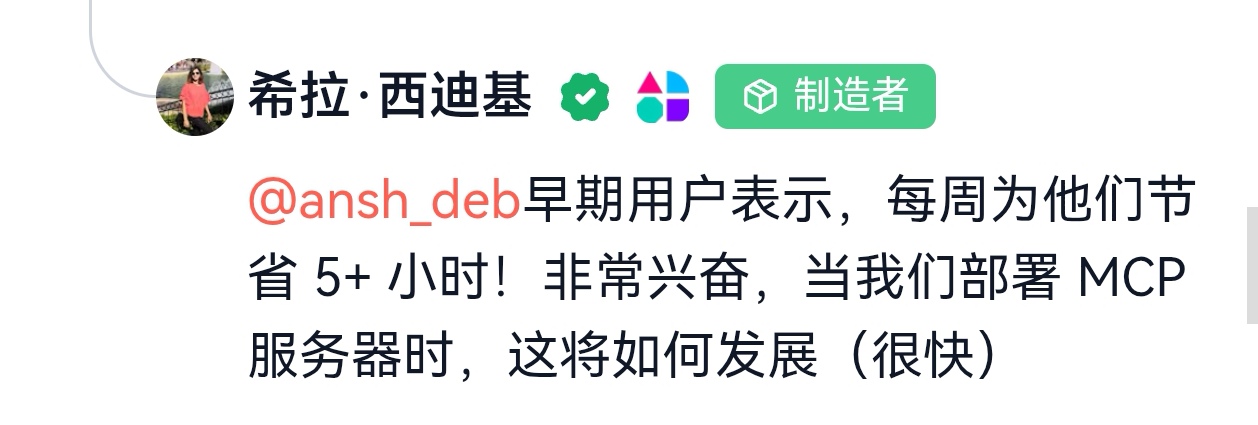
4. 以组件形式服务于更大的生态:作为实现更远大愿景的跳板,吸引关注、合作与投资。
总体上,很符合课程举出的cursor的发展历程,可以看出其从浅水区一路走到行业标杆的野心。
笔者也试图找寻该产品的发展轨迹,但它似乎在第一个公开发布的版本内就如此出色(至今全部满分评价),我只能认为在其公司的宏大愿景下,这是一个已经筹备许久、测试充分的项目。
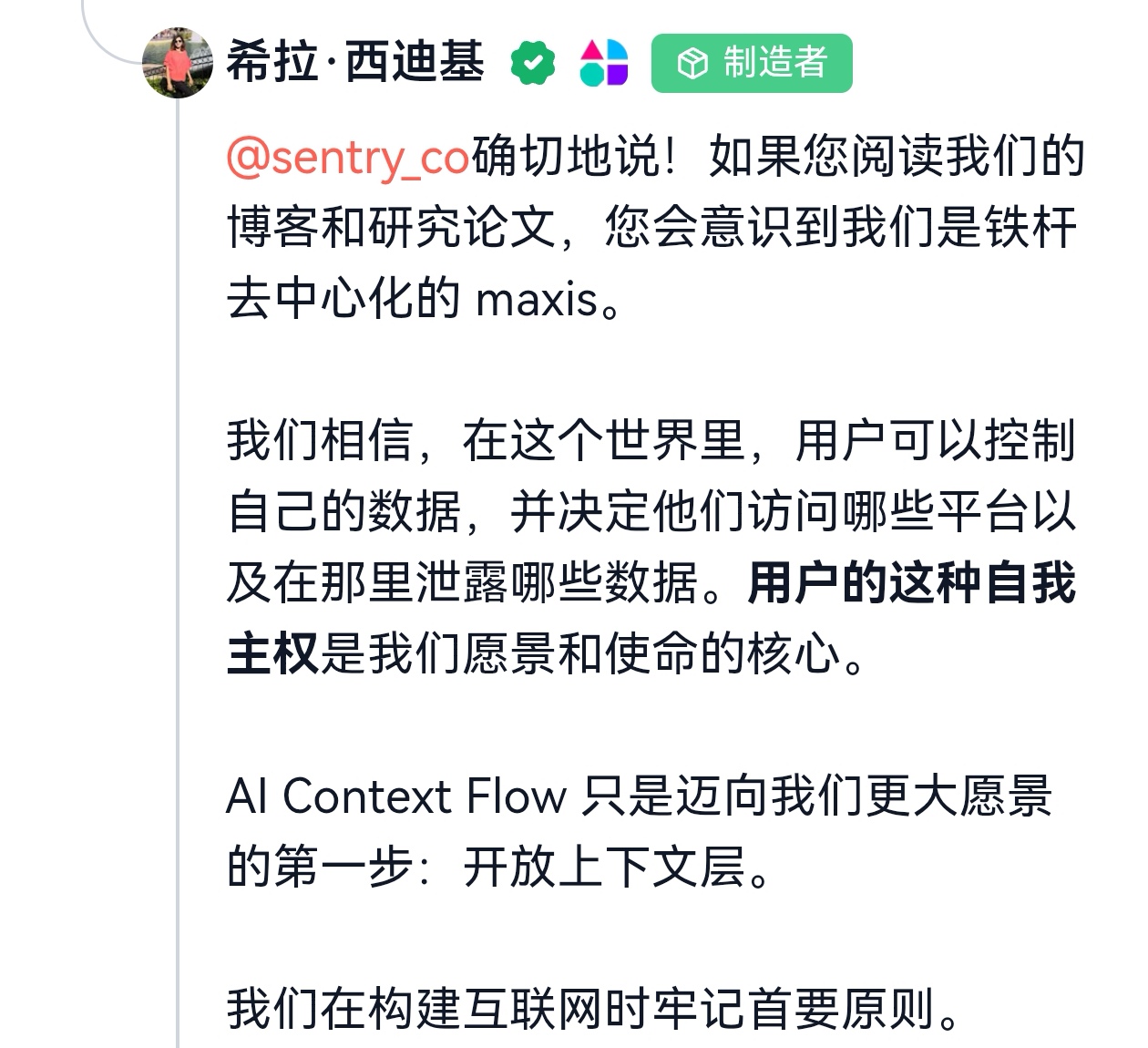
最后再来看一下Plurality Network公司的愿景,它的确令人期待:
我们的愿景是创造一个这样的世界:
- 上下文跟踪跨应用程序和代理的用户
- AI 助手记住并适应您的风格和目标
- 用户控制谁可以看到什么、何时以及如何看到
- 个性化和隐私在设计上取得了平衡
这是 Agentic Web 的支柱,这是与个人而不是平台保持一致的人工智能系统的未来。
小结
开发一个“好评如潮”Agent应用的技巧,可以总结如下:
- 用户的需求找的准
- 解决的问题价值大
- 应用的发展路线稳
AI Context Flow可谓是相当不错的实践,笔者已经开始猛猛用了🤞,感谢Datawhale的作业让我发现了这么好的工具
特别鸣谢:
同系列文章

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)