复旦:根据问题难度调整LLM长度惩罚
我们能否教会语言模型在人类思维中“简单问题快速处理,困难问题深入分析”?论文提出了一种基于新型奖励函数的有效推理方法,该方法能够根据问题的难度调整长度惩罚,鼓励简单问题的简短回答,同时允许复杂问题的深入推理。
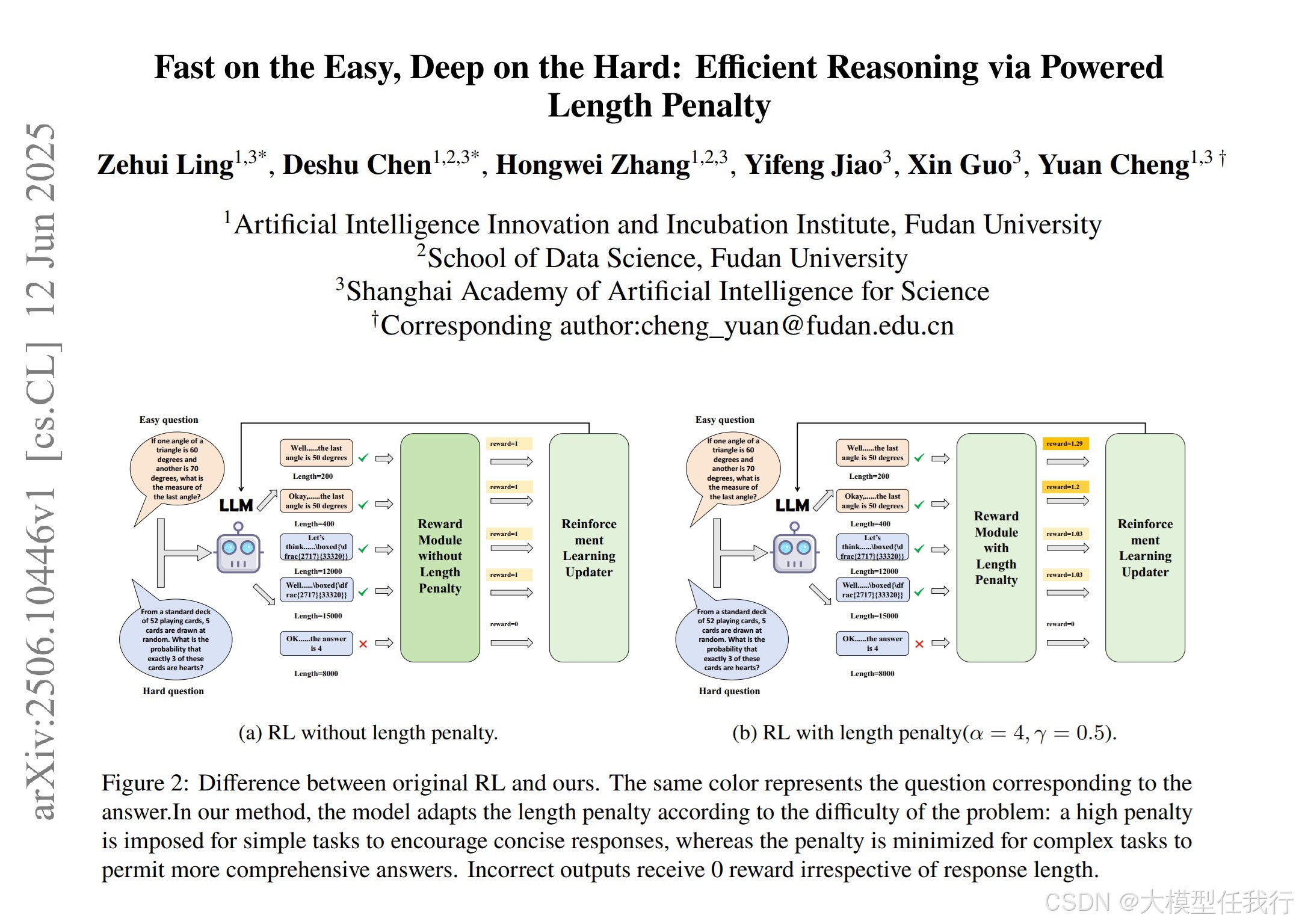
📖标题:Fast on the Easy, Deep on the Hard: Efficient Reasoning via Powered Length Penalty
🌐来源:arXiv, 2506.10446
🌟摘要
🔸大型语言模型 (LLM) 在推理能力方面取得了重大进展,在各种具有挑战性的基准测试中表现良好。已经引入了思维链提示等技术来进一步提高推理。然而,这些方法经常生成更长的输出,这反过来又增加了计算延迟。尽管一些方法使用强化学习来缩短推理,但它们通常应用统一的惩罚而不考虑问题的复杂性,从而导致次优结果。
🔸在这项研究中,我们试图通过促进更简单问题的简洁性来提高 LLM 推理的效率,同时为更复杂的问题保留足够的推理以获得准确性,从而提高模型的整体性能。具体来说,我们通过划分奖励函数并包括对输出长度的新惩罚来管理模型的推理效率。
🔸我们的方法在三个数据集的基准评估中产生了令人印象深刻的结果:GSM8K、MATH500 和 AIME2024。对于相对简单的数据集 GSM8K 和 MATH500,我们的方法在保持或提高准确性的同时有效地缩短了输出长度。在要求更高的 AIME2024 数据集上,我们的方法提高了准确性。
🛎️文章简介
🔸研究问题:我们能否教会语言模型在人类思维中“简单问题快速处理,困难问题深入分析”?
🔸主要贡献:论文提出了一种基于新型奖励函数的有效推理方法,该方法能够根据问题的难度调整长度惩罚,鼓励简单问题的简短回答,同时允许复杂问题的深入推理。
📝重点思路
🔸设计了一种引导模型生成简短直接推理路径的强化学习框架,利用奖励函数来对简短高效回答给予更高的奖励,同时对复杂问题采取更宽松的奖励策略。
🔸采用“Powered Length Penalty”(PLP)策略,根据问题的难度动态调整长度惩罚,简单问题给予较高惩罚以促使简洁回复,而困难问题则减少惩罚以支持详细推理。
🔸通过使用REINFORCE框架,简化了模型的内存开销,避免了传统PPO算法带来的复杂性及额外资源需求。
🔎分析总结
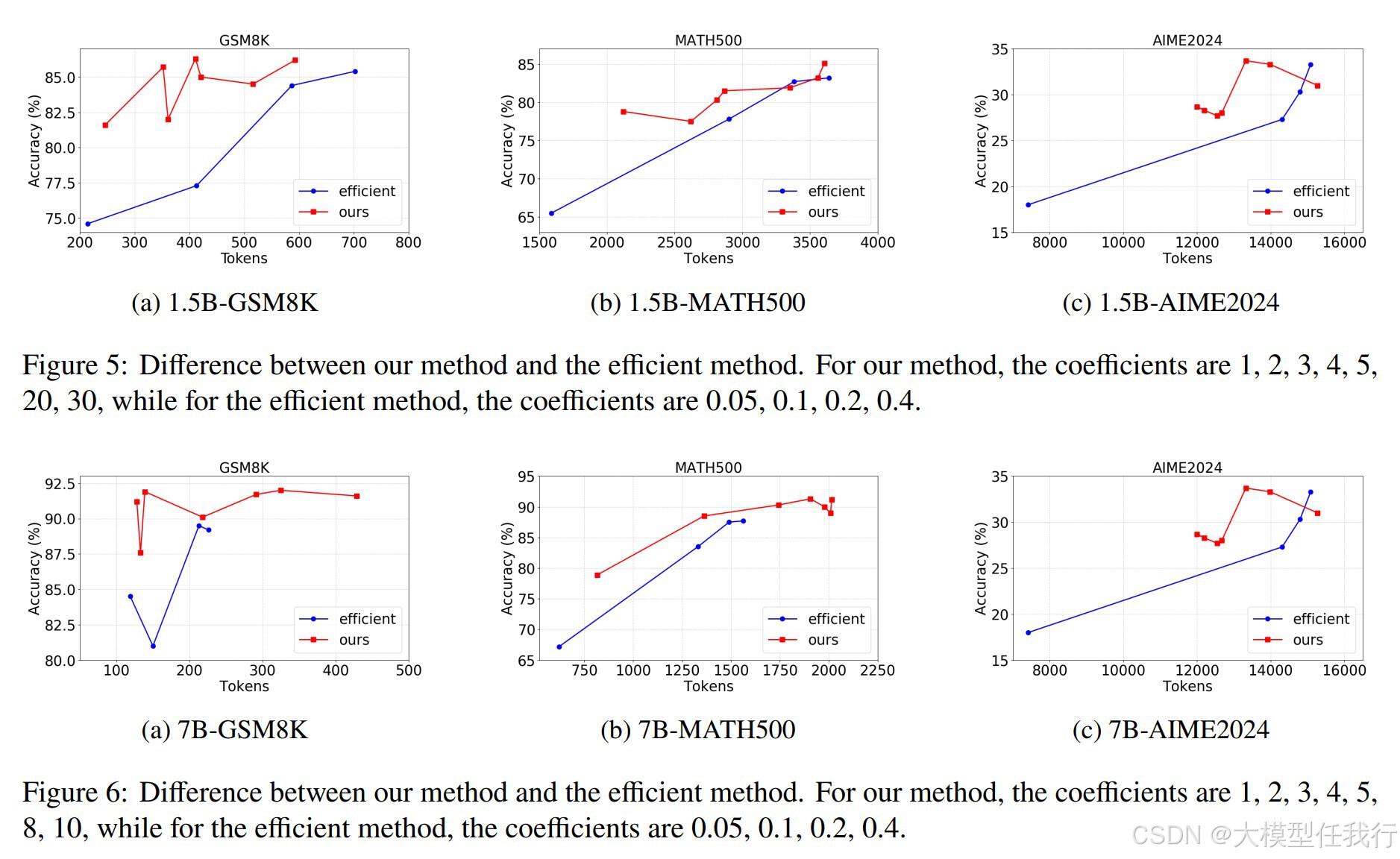
🔸通过对GSM8K、MATH500和AIME2024三个不同难度的数据集进行实验,证明了该方法能减少模型的输出token数量。1.5B模型在GSM8K数据集上减少了输出token数量40%,准确率提高了10%。
🔸对于7B模型,尽管在简单数据集中准确率略有下降,但token数量减少了近90%。在挑战性更高的AIME2024数据集上,准确率基本维持不变,同时token使用量减少了20%。
🔸与传统的长度惩罚方法相比,PLP方法能更有效地区分复杂问题和简单问题的响应长度。
💡个人观点
论文核心是根据问题复杂性调整长度惩罚,提高了生成模型在处理不同难度问题时的效率。
🧩附录


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献305条内容
已为社区贡献305条内容

所有评论(0)