首个大模型智驾方法AutoDrive-R²超过最强端到端SparseDrive方法:AutoDrive-R²在nuScenes数据集上L2误差优于SparseDrive
本文提出AutoDrive-R²框架,通过两阶段训练解决自动驾驶轨迹规划中的物理不可行和推理能力不足问题。创新性采用四步逻辑链(视觉分析、运动建模、逻辑推导、自验证)和物理约束奖励函数,仅需6K样本训练即实现SOTA性能。实验表明,在nuScenes数据集上平均L2误差降至0.19m(较SparseDrive降低67.24%),Waymo零样本误差降低33.3%-90.7%,首次实现大模型方法显著
方法总体架构图如下: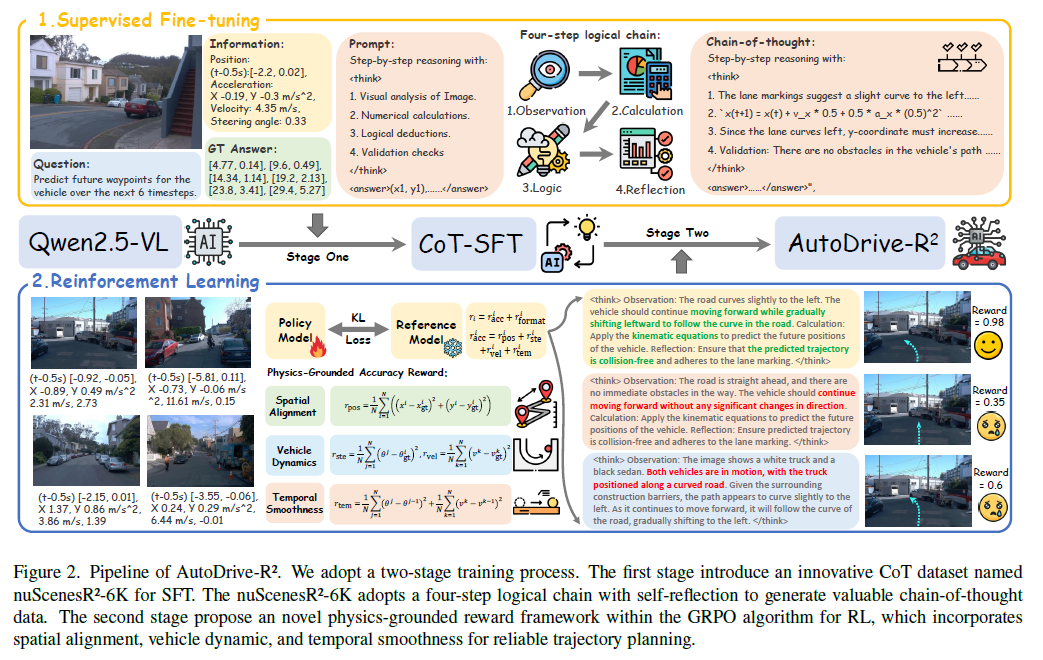
一、核心问题
当前基于视觉-语言-动作(VLA)模型的自动驾驶轨迹规划方法存在两大瓶颈:
物理不可行:生成的轨迹常违背车辆动力学约束(如转向角、加速度极限);
推理能力不足:缺乏对复杂场景的结构化推理和自验证机制,导致轨迹偏离实际需求。
二、方法框架:两阶段训练
第一阶段:监督微调(SFT)
数据集构建:提出 nuScenesR²-6K,首个包含四步逻辑链(CoT)与自验证的自动驾驶轨迹规划数据集。
四步推理链:
视觉分析:识别车道、障碍物、交通信号等;
运动建模:基于历史状态计算加速度、速度、位置预测;
逻辑推导:安全性检查(是否闯红灯、碰撞等);
自验证:反向验证轨迹的物理可行性与合理性。
模型训练:使用 Qwen2.5-VL 模型进行 SFT,建立输入(图像+状态)到输出(BEV轨迹)的认知桥梁。
第二阶段:强化学习(RL)优化
算法:采用 Group Relative Policy Optimization (GRPO),通过组内响应对比简化训练、提升效率。
物理驱动奖励函数:融合多维度约束:
空间对齐(rposr_{\text{pos}}rpos):轨迹点与真值的欧氏距离;
车辆动力学(rster_{\text{ste}}rste, rvelr_{\text{vel}}rvel):转向角与速度的一致性;
时间平滑性(rtemr_{\text{tem}}rtem):相邻时间步间转向与速度的变化惩罚。
总奖励:racc=λposrpos+λsterste+λvelrvel+λtemrtemr_{\text{acc}} = \lambda_{\text{pos}} r_{\text{pos}} + \lambda_{\text{ste}} r_{\text{ste}} + \lambda_{\text{vel}} r_{\text{vel}} + \lambda_{\text{tem}} r_{\text{tem}}racc=λposrpos+λsterste+λvelrvel+λtemrtem,确保轨迹物理可行、平滑舒适。
三、关键创新
- 结构化推理与自验证:首次在自动驾驶中引入四步CoT+自验证机制,提升模型可解释性与错误纠正能力。
- 物理约束奖励设计:将车辆动力学、舒适性等实际约束嵌入奖励函数,避免生成不可行轨迹。
- 小数据高效训练:仅用6K样本(约为对比方法EMMA+的11.6%)实现SOTA性能,体现数据效率与泛化能力。
四、实验验证
数据集:nuScenes + Waymo(零样本泛化);
指标:L2误差(1s/2s/3s/平均);
结果:
在nuScenes上比EMMA+提升显著,平均L2误差降至0.19m;
在Waymo上零样本泛化性能优越,误差降低33.3%~90.7%;
消融实验:验证了四步推理、自验证、各奖励项的必要性。
下图为SparseDrive论文中L2 Error结果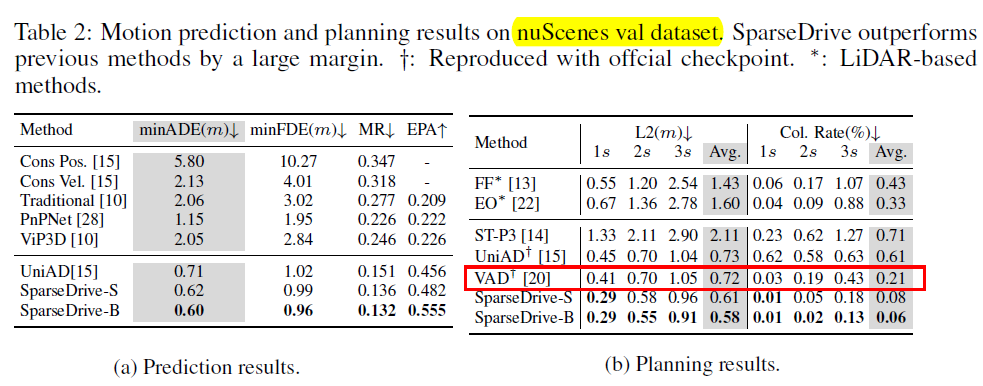
下图为AutoDrive-R²论文中结果,文中提及均在nuScene数据集中测试,可参考UniAD结果,证明基本可信,SparseDrive平均L2最小0.58,而AutoDrive-R²平均L2 0.19,误差降低了约67.24%,据个人目前所知应该是首个大模型方法大幅领先端到端方法。让我们恭喜AutoDrive-R²!!!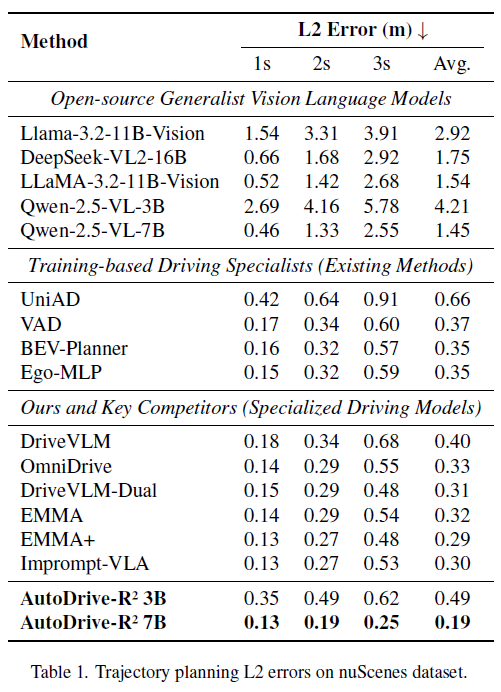

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)