【文摘】DeepSeek本地部署与应用开发—基于工作流实现企业会议助手
【文摘】DeepSeek本地部署与应用开发—基于工作流实现企业会议助手
文章目录
本文节选自《DeepSeek本地部署与应用开发:政府与企业级实战案例解析》(北京大学出版社)第10章。若希望深入探讨相关内容,诚挚推荐您购买全书,深入阅读。
第10章 实战—基于工作流实现企业会议助手
前文已在本地完成 Dify 部署,并配置 DeepSeek 本地化模型,成功搭建 Dify AI 聊天室。同时,对 Dify 知识库功能展开初步实践,使 DeepSeek 模型能够基于预设知识库进行对话交互,为深度应用 Dify 奠定基础。
本章将基于Dify 和 DeepSeek 构建简易企业会议助手。通过这一实践,助力读者进一步掌握 Dify 平台的应用开发流程,全方位提升对 Dify 的理解与运用能力,推动其在企业会议场景中实现智能、高效的沟通协作。
10.1 依赖环境
在开始这个项目之前,需要确保系统中已经安装了相关的服务。如果不知道怎么安装这些服务,可以在前面的章节中找到安装教程。
- Ollama:用于本地化部署Deepseek模型
- Docker Compose:用于安装部署Dify服务
- Dify:使用Dify的工作流编排让DeepSeek完成多种复杂的功能
- 企业OA系统及开放的接口:让DeepSeek通过这些接口实现会议的预约、查询、取消。
10.2 创建Dify工作流应用
创建Dify工作流应用的具体操作步骤如下。
- 在Docker上启动了Dify服务后,进入Dify首页。
- 在Dify首页,选择创建空白应用,进入创建应用界面。
- 在创建应用页面,选择Chatflow这个应用类型,如图10.1所示.
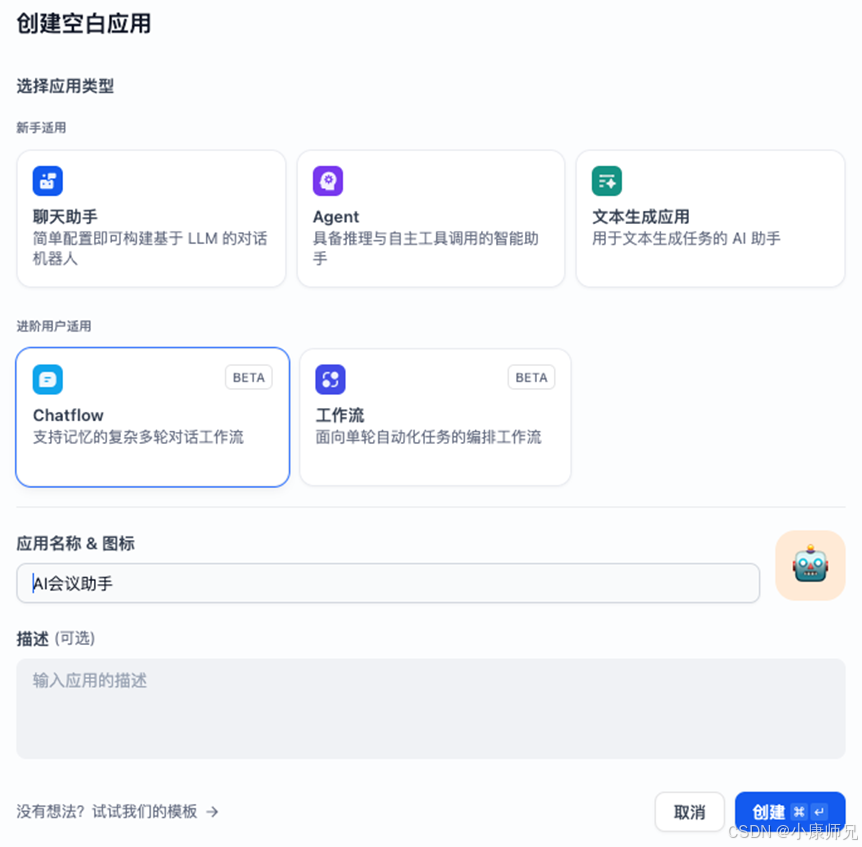
- 新建完应用后,进入应用页面,可以看到一个工作流的画布,画布上已经默认创建了3个节点,如图10.2所示,这三个节点分别为:
-
开始节点:它负责处理输入及采集相关变量。
-
LLM节点:即配置大模型进行相关问题的处理。
-
回复节点:将大模型的回答输出给用户。

除了这三个节点外,Dify还支持了许多的节点类型,比如问题分类、代码执行、http请求等。后面的功能都会在这个画布通过配置节点的方式完成,基于Dify的这个画布,就可以编排工作流来实现相关功能。
10.3 获取个人用户信息
10.3.1 获取Dify用户id
在使用会议助手进行会议预定时,需要获取个人信息。因此,第一步需要让 DeepSeek 了解当前与之对话的用户的相关信息。然而,在 Dify 的工作流中,仅能获取当前登录 Dify 的用户 ID。
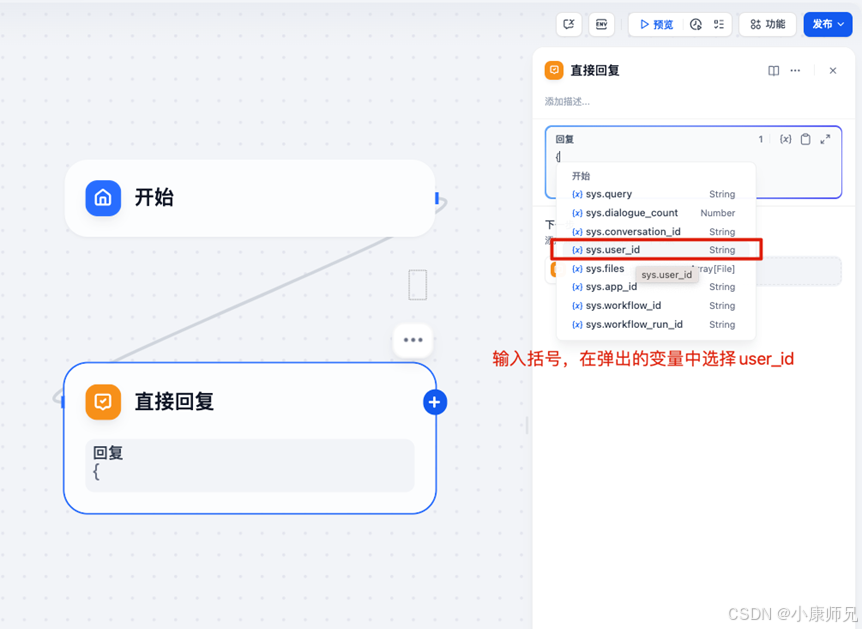
可以先查看该用户 ID 的具体格式。在原始工作流的基础上,先移除大语言模型(LLM)节点,然后在直接回复节点中直接输出用户 ID。如图 10.3 所示,在直接回复节点的配置中,可以看到来自开始节点的多个变量,其中 sys.user_id 即为所需的变量,它将输出当前用户的 ID。
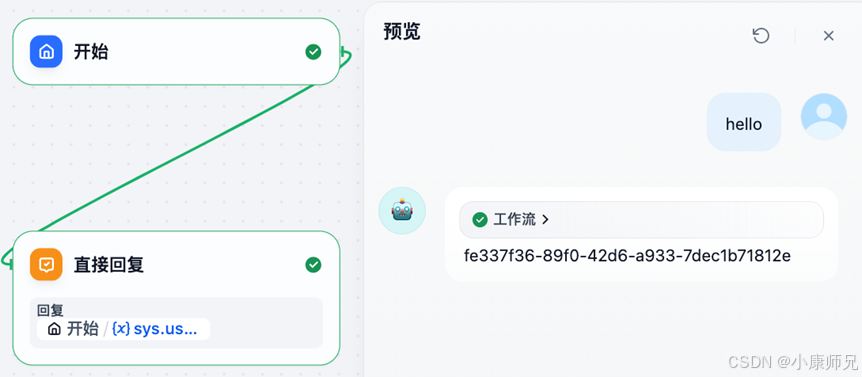
配置完直接回复节点的输出之后,选择预览,随便输入一个提问,工作流就会输出用户id,如图10.4所示,它输出了当前用户的id为705ca8e8-c86a-4eac-a267-f4404897d811,这个就是Dify的用户id。
10.3.2 绑定OA用户id
在实际业务场景里,员工的个人信息数据以及会议室相关信息大多存储于办公自动化(OA)系统中。所以,若要实现会议室助手功能,OA 系统内的用户信息必不可少。在 OA 服务体系下,需要将 Dify 平台的用户 ID 与 OA 系统中的用户信息进行绑定。而此操作的落地,离不开 OA 系统开发团队的技术支持。这就要求 OA 服务提供一个接口,方便工作流依据 Dify 用户 ID 获取对应的用户信息。
为此,我们需与公司的 OA 系统开发团队深入沟通、紧密协作,推动对方开发并提供契合需求的 HTTP 接口。该接口能够依据输入的 Dify 用户 ID,精准匹配并返回 OA 系统中与之关联的用户信息。接口的详细规范,如接口地址、请求方式、请求参数以及响应数据格式等关键信息,具体信息如图 10.5所示。借助这一接口,Dify 会议助手在发起 HTTP 请求时,只需携带 Dify 用户 ID,即可顺利获取 OA 系统用户信息,为后续会议预定等功能的实现筑牢数据基础。

10.3.3 获取OA用户id
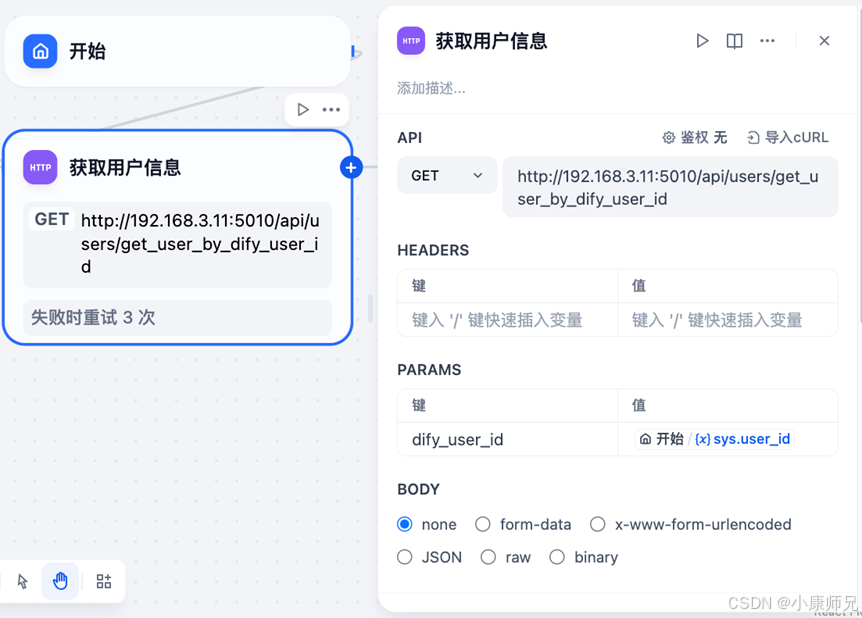
得到OA的用户信息接口后,便可在 Dify 的工作流画布中配置 HTTP 请求,以获取当前聊天用户的个人信息。具体操作是在开始节点之后新增一个 HTTP 请求节点,并进行相关配置。详细的配置情况如图 10.6 所示,其中配置了 OA 接口的请求地址,同时在 HTTP 参数中设置了 dify_user_id=${sys.user_id},以此实现将 Dify 的用户 ID 作为参数传递给 OA 接口,从而准确获取对应的用户个人信息。
由于部分用户可能尚未完成 Dify 用户 ID 与 OA 系统的绑定操作,这可能导致无法获取其用户信息。针对这种情况,这里需要提醒用户联系 OA 管理员进行绑定。
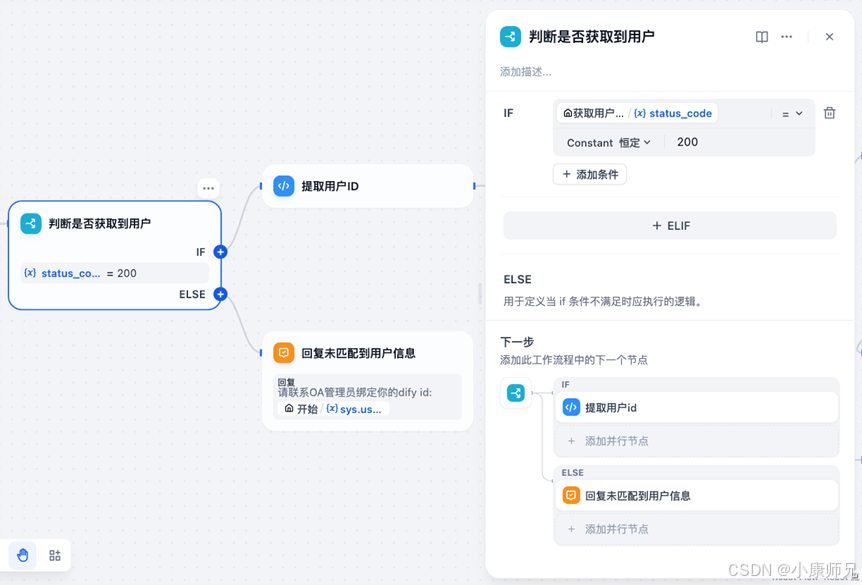
为实现该功能,需添加一个条件分支节点,用于判定是否能够成功获取用户信息。依据接口设计,仅在成功获取用户信息时,接口会返回 200 状态码。因此,可借助 HTTP 返回的状态码进行判断。
条件分支节点的下游连接着两个直接输出节点。若成功获取到用户信息,系统将直接输出该用户信息;若未能获取到,则会输出提醒信息,提示用户联系 OA 管理员完成用户 ID 绑定。
具体配置情况如图 10.7 所示,这里配置了一个条件分支节点,将 HTTP 状态码为 200 作为成功获取 OA 用户信息的判定条件。若状态码不为 200,则认为用户 ID 尚未绑定,系统会提醒用户联系 OA 管理员进行绑定操作。
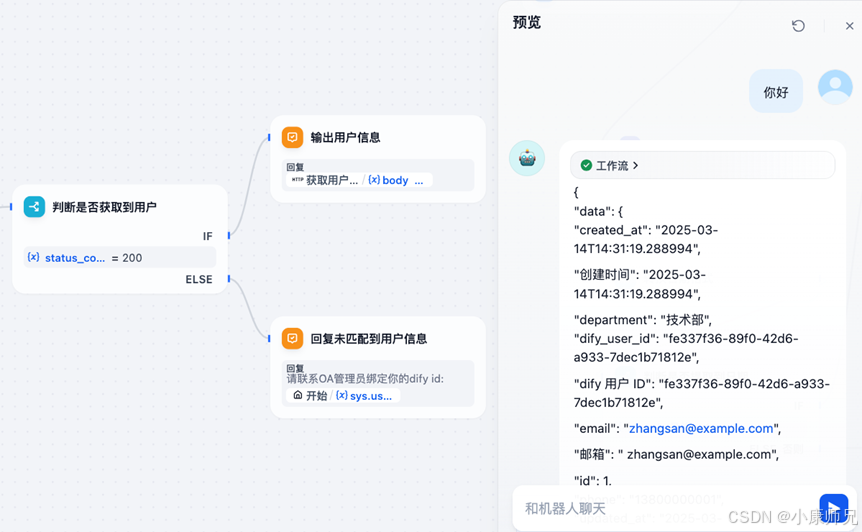
完成上述配置后,点击工作流画布右上角的“预览”按钮,便可尝试获取个人信息。从图 10.8 能够清晰看到,当用户 ID 尚未绑定 OA 系统时,工作流会自动触发提醒,告知用户需联系 OA 管理员完成绑定操作。而在完成绑定后,再次与系统进行对话,工作流则会准确返回用户的个人信息,实现了信息获取功能的正常运转。
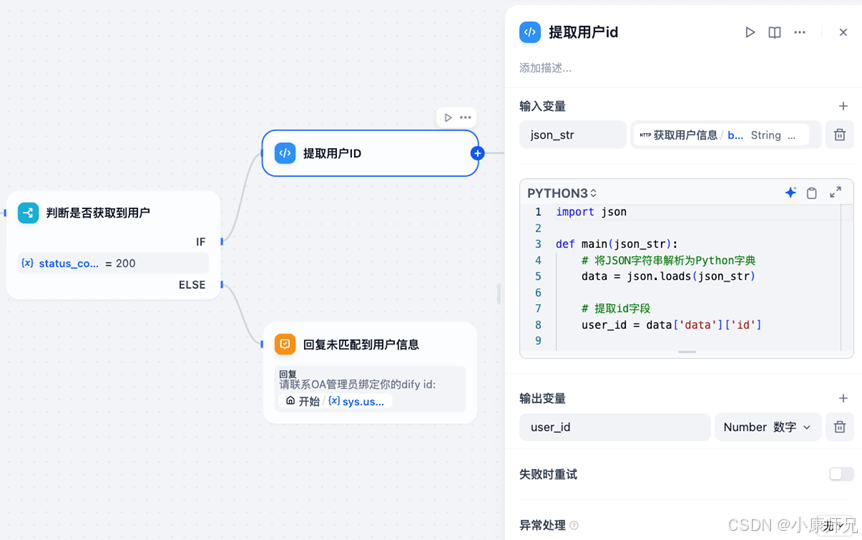
考虑到后续操作仅需使用用户 ID,因此有必要从获取的用户信息中提取该 ID。基于此,需将原本的输出节点替换为代码执行节点。Dify 平台的代码执行节点支持 Python 和 Node.js 两种编程语言,鉴于 Python 的简洁性与广泛适用性,此处选择使用 Python 代码实现信息提取。内容如代码10-1所示
代码10-1 提取用户ID示例
import json
def extract_id(json_str):
# 将JSON字符串解析为Python字典
data = json.loads(json_str)
# 提取id字段
user_id = data['data']['id']
return {"user_id":user_id}
代码执行节点配置如图10.9所示,方法入参来自于提取用户信息的节点返回的body信息,它是json格式,代码会对json进行解析然后提取json中的id最后在输出变量中配置为user_id供后续的节点使用。
10.4 实现预定会议功能
10.4.1 获取预定会议接口
获取个人信息后,便可着手进行会议室预定工作流的配置。在此之前,有必要进行模拟分析。若由真人秘书负责会议室预定工作,需向其提供一系列关键信息。首先,会议时间必不可少,同时要明确参会人员名单,此外,阐述会议内容、提出对会议室的特定要求,能助力秘书顺利完成预定工作。
AI 秘书执行会议室预定任务时,需调用 OA 系统提供的会议预定 HTTP 接口。该接口要求传入会议时间、地点、任务以及会议内容等信息。因此,需构建一套工作流,借助 DeepSeek 的自然语言处理能力,从用户输入中提取这些关键信息。为确保 DeepSeek 准确提取信息,精心设计提示词至关重要。
在设计提示词前,需全面了解 OA 系统会议室预定接口的具体要求。如图 10.10 所示,该接口采用 POST 请求方式,请求时需携带 room_id、user_id、title、start_time、end_time、participantor 等信息。

10.4.2 获取接口所需信息
预定会议的接口参数中,user_id在前面获取用户信息时已经拿到了,room_id则需要通过用户给出的会议室描述信息去接口获取,其他信息则需要从用户的提问中让DeepSeek来提取。下面是让deepseek提取会议信息的提示词:
你是一个智能会议助手,负责处理与会议相关的用户请求。现在用户会向你提出预定会议的要求,请你从他的请求中提取出具体的时间范围,会议需要拉上哪些人,哪间会议室,会议主题,最终以纯粹的json格式输出,不要带上任何其他符号,也不要输出你的思考过程。如果用户只说了某个时间点,默认会议时长一个小时。如果用户没有提到哪间会议室,会议室的内容先放空,如果用户的请求中没提到会议主题,也放空。但用户必须说出会议的时间点和参会人员,如果用户请求中没有这些信息,告诉他缺少了哪些信息,需要补充。如果用户提问了和预订会议室无关的问题,直接回答:"我是企业会议助手,只负责帮忙预定和取消会议室或者查看你的会议信息,其他问题帮不到你,抱歉"
### 范例1
用户提问:帮我预定14号下午2点的会议室,叫上张三、李四,会议主题是讨论这个季度的工程预算,会议室就定三楼那间小会议室
你需要回答:
{
"start_time": "2025-03-14 14:00:00",
"end_time": "2025-03-14 15:00:00",
"participantor": [
"张三",
"李四"
],
"title": "本季度工程预算",
"room_location": "三楼小会议室"
}
### 范例2
用户提问:帮我预定14号下午2点的会议室,叫上李四
你需要回答:
{
"start_time": "2025-03-14 14:00:00",
"end_time": "2025-03-14 15:00:00",
"participantor": [
"张三",
"李四"
],
"title": "",
"room_location": ""
}
### 范例3
用户提问:帮我预定明天的会议室
你需要回答:请告诉我具体明天几点,需要拉上哪些人,会议主题以及需要哪间会议室
### 范例4
用户提问:帮我预定15号早上10点的会议
你需要回答:请告诉我需要哪些人员参会,会议主题以及需要哪间会议室
### 范例5
用户提问:今天的天气怎么样
你需要回答:我是企业会议助手,只负责帮忙预定和取消会议室或者查看你的会议信息,其他问题我帮不到你了,抱歉
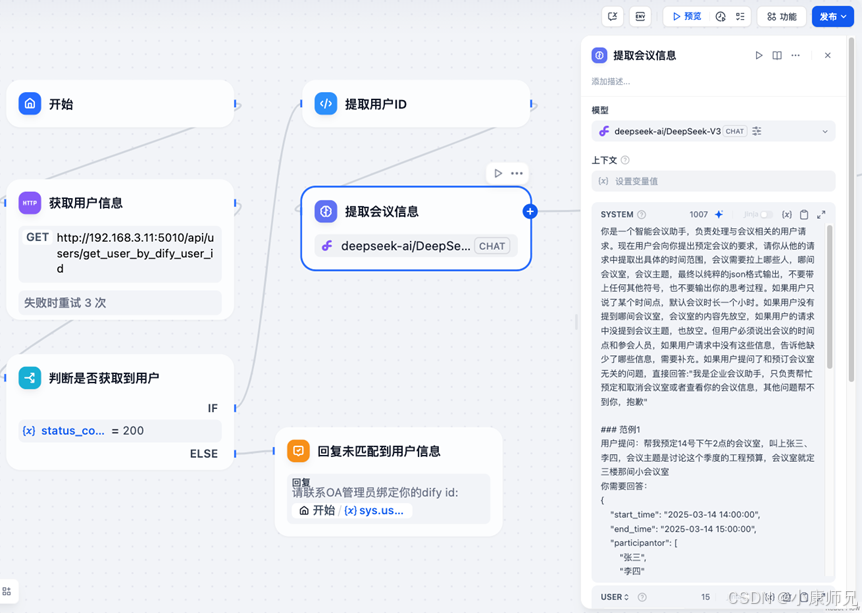
有了这个提示词后,就可以在提取用户id节点后新增一个LLM节点,如图10.11所示,配置Deepseek给我们提取关键信息,然后在System的输入框填上上面的提示词,再新增一个User框配置用户的请求,也就是sys.query变量。
此时,DeepSeek 会提取出一个 JSON 字符串。然而,由于尚未获取到 room_id,因此需要对该 JSON 字符串进行进一步处理。为此,需在大语言模型(LLM)节点之后新增一个代码执行节点,该节点的主要功能为判断 DeepSeek 是否成功提取到相关信息,并对部分数据进行补全。例如,若用户未提及会议内容和所需会议室,代码执行节点将对这些缺失信息进行相应处理。执行上述操作的 Python 代码如代码10-2所示代码10-2 提取用户ID示例
import json
def main(result: str) -> dict:
empty_result = {
"start_time": "",
"end_time": "",
"participantor": [
],
"title": "",
"room_location": "",
"is_ok": 0
}
try:
# 尝试解析字符串为JSON
data = json.loads(result)
except Exception:
# 如果解析失败,返回0
return empty_result
if data.get("title", "") == "":
data["title"] = "暂无主题"
if data.get("room_location", "") == "":
data["room_location"] = "任意会议室"
# 检查JSON中是否包含startTime、endTime、participator字段
if all(key in data for key in ["start_time", "end_time", "participantor"]):
data["is_ok"] = 1
return data
else:
return empty_result
该代码接收Deepseek返回的内容,然后尝试进行json解析,如果解析失败说明用户请求缺少关键信息,is_ok=0用来标识这种情况。
如果数据解析正常,用户没指定会议主题和会议室的情况下,代码也会给出一些默认值,最后设置is_ok=1。因此,is_ok字段可以用于判断是否采集到需要的数据,能不能进行下一步处理,该代码执行节点配置如图10.12,这里需要将提取到的相关变量转成输出变量。
代码返回的是一个json数据,下面的输出变量就需要从json对象的key中提取,然后才可以转为输出变量供后面的节点使用。
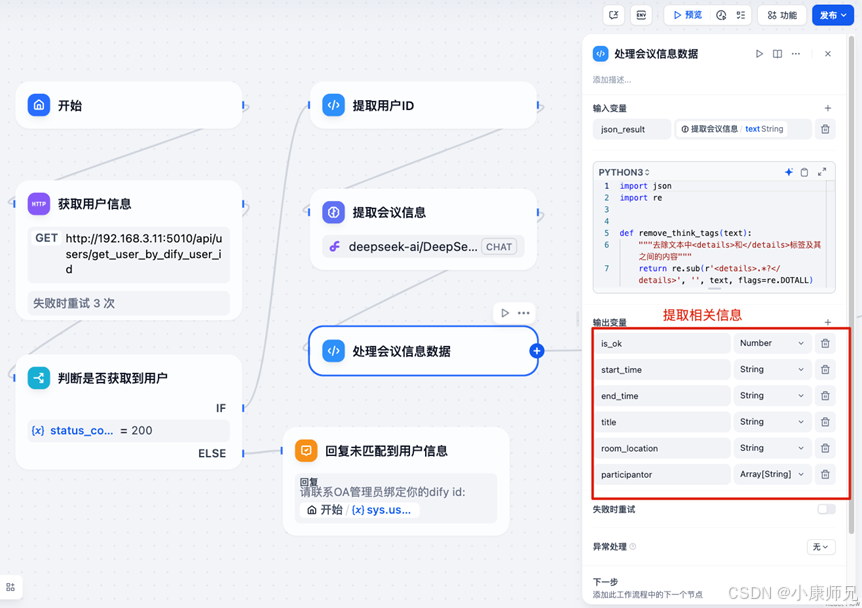
完成数据提取后,除 room_id 外,已获取预定会议接口所需的全部信息。接下来,将依据上述代码执行块输出的 room_location 来获取 room_id。此过程需要借助 OA 系统提供的一个接口,该接口用于获取全部会议室的信息,随后利用 DeepSeek 从这些信息中找出与 room_location 对应的 id。
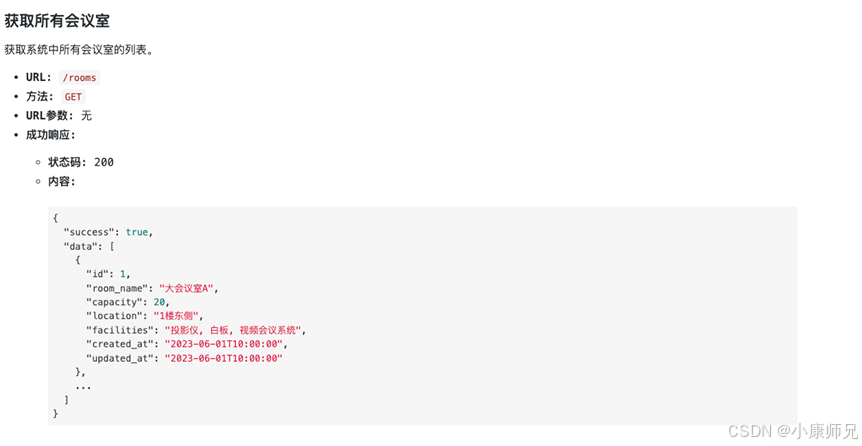
以下是 OA 系统提供的查询所有会议室的接口信息,如图 10.13 所示。该接口采用 GET 请求方式,无需传递任何参数,调用后将返回所有会议室的列表信息。
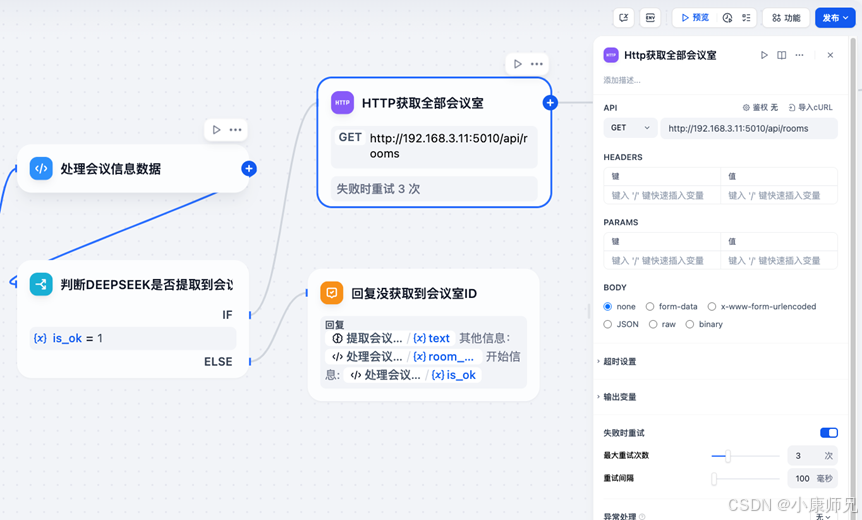
接上面的代码执行节点,我们继续添加条件判断,is_ok=1时接Http请求接口,is_ok=0时直接输出,具体配置如图10.14,在http请求节点中输入接口地址即可
10.4.3 请求接口预定会议
获取到所有空闲会议室信息,将它传递给Deepseek,让Deepseek提取出会议室id。这里需要设计一下给DeepSeek的提示词:
你是一个智能会议助手,负责处理与会议相关的用户请求。用户会向你提问会议室名称或者描述,你需要从会议室信息中提取出id返回给用户。如果遇到用户给出的会议室描述比较模糊,就取匹配到的任意一个会议室id返回。如果用户的提问和会议室信息都完全不匹配,比如会议室分布只有1-3楼,而用户提了4楼的会议室,需要返回"不好意思,咱们公司在10楼好像没有会议室,目前我们只有1-3楼有会议室,您是不是说错楼层了"。如果用户提了和会议室信息完全无关的问题,返回"我是企业会议助手,只负责帮忙预定和取消会议室或者查看你的会议信息,其他问题帮不到你,抱歉"
### 全部会议室信息
{这里填充上游http节点返回会议室信息}
### 范例1
用户提问:1楼东侧的大会议室A
你需要回答:1
### 范例2
用户提问: 2楼的会议室
你需要回答:5
### 范例3
用户提问: 随便哪个楼层的大会议室
你需要回答:1
### 范例4
用户提问: 任意会议室
你需要回答:4
### 范例5
用户提问:10楼的小会议室
你需要回答:不好意思,咱们公司在10楼好像没有会议室,目前我们只有1-3楼有会议室,您是不是说错楼层了。
### 范例6
用户提问:今天天气怎么样
你需要回答:我是企业会议助手,只负责帮忙预定和取消会议室或者查看你的会议信息,其他问题帮不到你,抱歉
基于这个提示词,继续添加一个LLM节点来进行会议室id提取,如图10.15,在LLM节点的配置中记得带上所有会议室的信息。
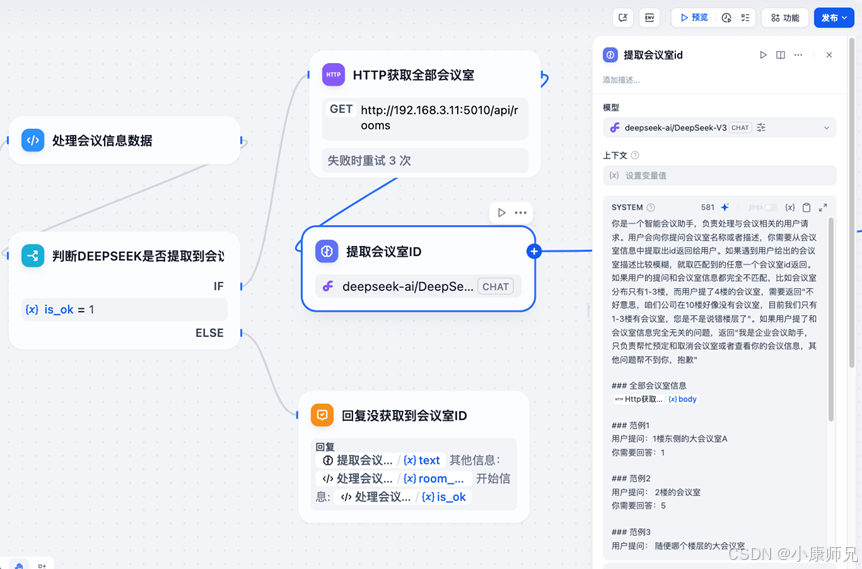
拿到会议室id后,预定会议接口所需的全部参数已经准备完毕。下面就可以使用预定会议室接口了。将之前的回复节点替换成http请求节点,进行配置填充,如图10.12所示,将前面获取到的相关信息都填充到http请求节点的参数中,同时配置http的请求头的ContentType为Application/json。
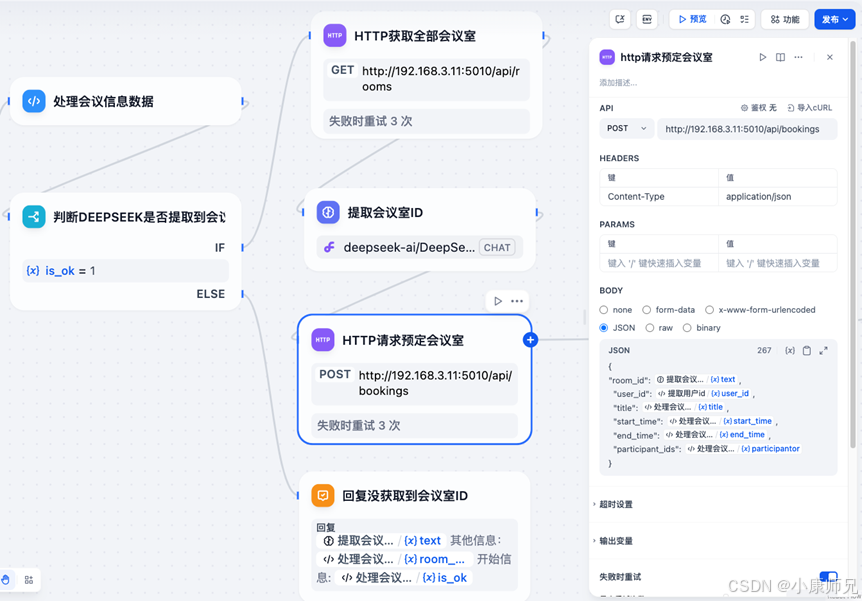
最后,新增一个代码执行节点对预定的结果进行数据提取,判断是否预定成功。内容如代码10-3所示
代码10-3 提取会议预定结果示例
import json
def main(json_str) -> dict:
try:
data = json.loads(json_str)
main_data = data.get("data")
success = data.get("success", False),
if not success or not main_data:
return {"output": data.get("message", "会议预定失败")}
output = ""
output += "会议预定成功,以下是会议相关信息:\n"
output += f"会议时间段:{main_data.get('start_time', '')}-{main_data.get('end_time', '')}\n"
output += f"参会人员:{', '.join([p.get('user', {}).get('username') for p in main_data.get('participants', [])])}\n"
output += f"会议主题:{main_data.get('title', '')}\n"
output += f"会议地址:{main_data.get('room', {}).get('location', '')} - {main_data.get('room', {}).get('room_name', '')}"
return {
"output": output
}
except Exception as e:
return {"output": str(e)}
这段代码主要是对预定会议室接口返回的数据进行处理。预定会议室返回的数据是json类型,代码会先判断是否预定成功,预定失败则直接返回错误信息。预定成功则提取相关信息输出给用户。如图10.17所示,这里接收了上游http请求节点的返回body为入参,然后进行相关处理。
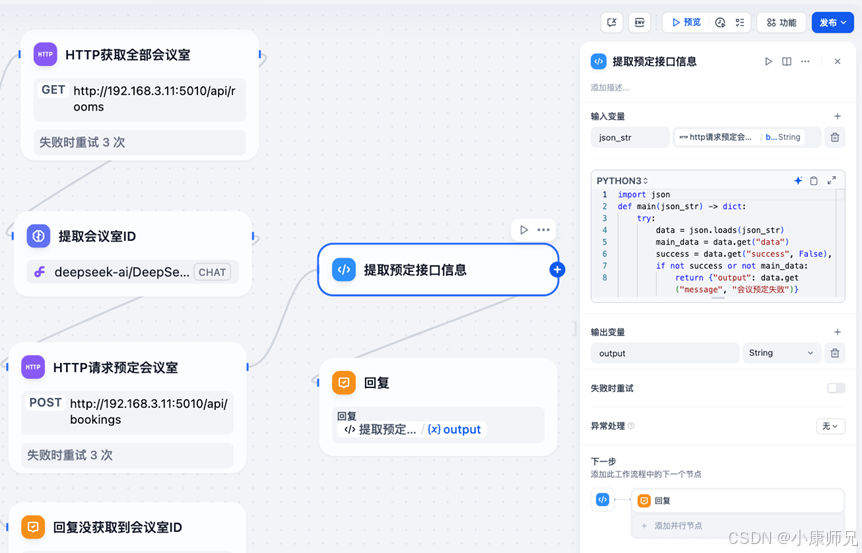
到这里,预定会议的工作流基本已经配置完毕。需要发布给其他用户使用的话,可以点击右上角的发布,然后点击运行,就可以进入聊天室开始让AI秘书进行会议室的预定。最终效果如图10.18所示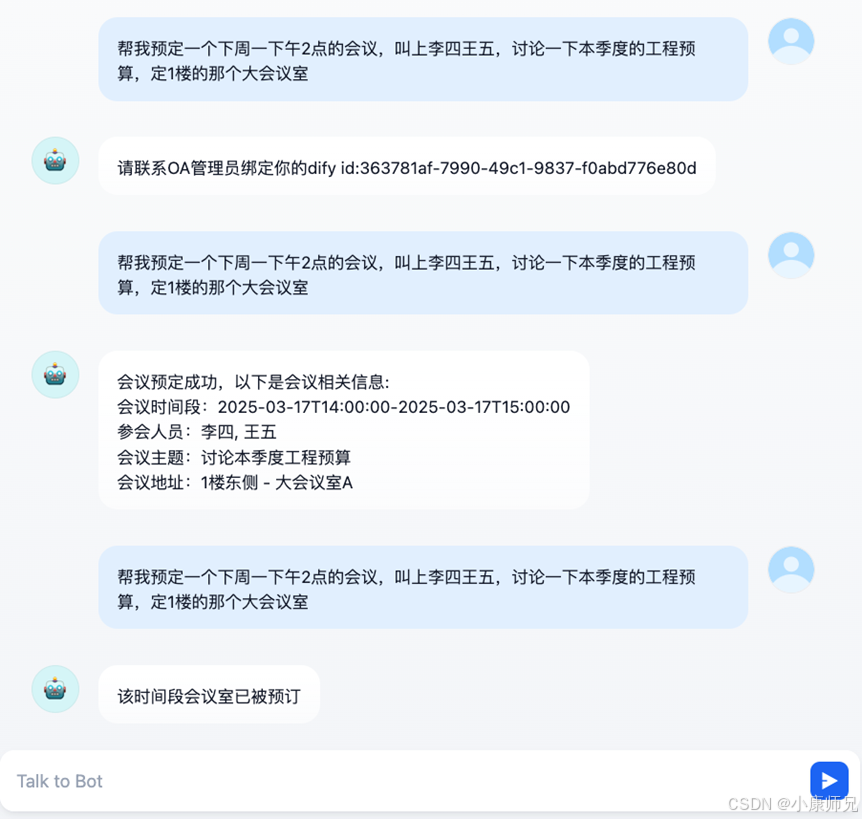
10.5 实现会议查询功能
篇幅有限,更多精彩,敬请购阅全书。
10.6 实现会议取消功能
篇幅有限,更多精彩,敬请购阅全书。
10.7 实现会议纪要功能
篇幅有限,更多精彩,敬请购阅全书。
10.8 实现各个功能汇总
篇幅有限,更多精彩,敬请购阅全书。

本文节选自《DeepSeek本地部署与应用开发:政府与企业级实战案例解析》(北京大学出版社)第10章。若希望深入探讨相关内容,诚挚推荐您购买全书,深入阅读。
若觉得文章对你有帮助,随手『点赞』、『收藏』、『关注』,也是对我的支持。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)