VADv2和Hydra-MDP中的Planning Vocabulary生成方法
轨迹词表生成方法
·
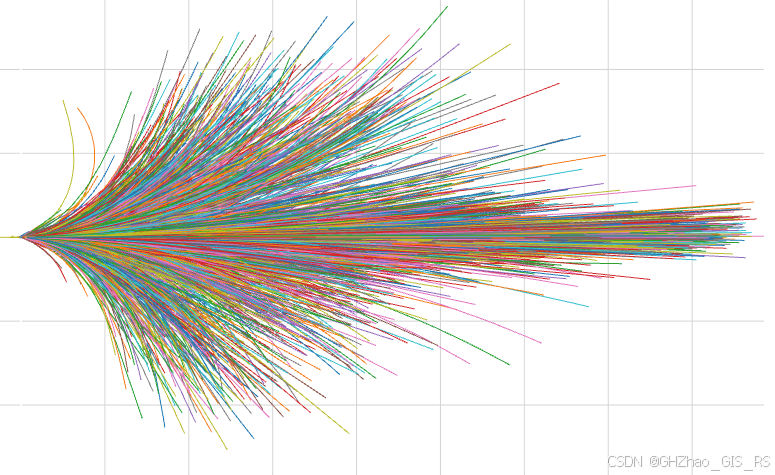
一、基于词表(vocabulary)的轨迹规划
在论文VADv2和Hydra-MDP中都使用轨迹词表作为先验来解决轨迹规划中的多模态问题。
这里记录一下通过采集的轨迹数据生成轨迹词表的方法。
二、轨迹聚类代码
import numpy as np
from sklearn.cluster import KMeans
def plan_cluster(ego_array,n_clusters=4096):
# # # 1. 展平轨迹数据
traj_num,future_T,channel = ego_array[...,:3].shape #只使用每个点的x,y,heading
X = ego_array[...,:3].reshape(traj_num, -1) #只使用x,y,heading做相似度判断
# 3. 使用KMeans聚类
print(f"开始进行{n_clusters}聚类")
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(X)
cluster_center = kmeans.cluster_centers_
cluster_center = cluster_center.reshape(n_clusters,future_T,channel)
#后处理
medoids = []
for i in range(n_clusters):
print(f"计算{i}类中心")
cluster_data = X[cluster_labels == i]
cluster_data_origin = ego_array[cluster_labels == i]
if len(cluster_data) > 0:
center_i = cluster_center[i].reshape(-1,future_T*channel)
# 找到距离该中心最近的实际点
distances = np.linalg.norm(cluster_data - center_i, axis=1)
medoid_idx = np.argmin(distances)
# medoids.append(cluster_data[medoid_idx])
medoids.append(cluster_data_origin[medoid_idx])
# else:
# medoids.append(birch.subcluster_centers_[i])
medoids = np.array(medoids)
print(medoids.shape)
cluster_center_npy = f"egotraj_kmeans_{n_clusters}_{t}s.npy"
np.save(cluster_center_npy,medoids)
traj_nmpy1 = "orign_ego.npy" #[N,pt,3] N:轨迹数,pt每条轨迹的点数,nuplan是预测了未来8s的轨迹,这里就是80,3:x,y,heading
ego_array1 = np.load(traj_nmpy1)
t = 5 #轨迹时长,
T = t*10 #频率10HZ,5s就有50个点
ego_array = ego_array1[:,:T]
plan_cluster(ego_array,8192)
# plan_cluster(ego_array,4096)
# plan_cluster(ego_array,2048)
# plan_cluster(ego_array,1024)
# plan_cluster(ego_array,512)
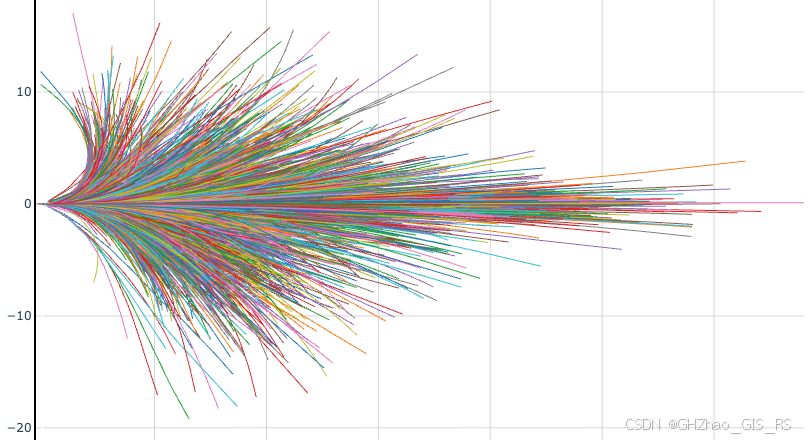
四、数据可视化效果
我们自己车辆采集的100万数据的可视化结果

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)