AI Agent 的架构与应用
AIAgent是一种基于大语言模型的智能代理系统,具备自主理解、规划决策和执行任务的能力。相比传统AI工具,AIAgent能够主动调用API和工具完成复杂任务,如旅行规划、实时信息查询等。其核心架构包括知识库、RAG检索增强生成、MCP工具调度和多智能体协同等技术模块。AIAgent通过自然语言理解、知识图谱推理和强化学习优化任务执行效果,并可通过提示词工程提升交互质量。这种"大脑+工具
一、AI Agent 是什么?
AI Agent 被翻译为智能代理或者智能体,是以大语言模型(LLM)为大脑驱动,具有自主理解、感知、规划、记忆和使用工具的能力,能自动化执行复杂任务的系统。
Agent 一词起源于拉丁语中的Agere,意思是“to do”,在LLM语境下,Agent可以理解为某种能自主理解、规划决策、执行复杂任务的智能体。
AI Agent,就是具有独立思考和行动能力的AI程序,它不仅告诉你“如何做”,更会帮你去做。
- 传统 AI 模型是一个“工具”:你给它一个明确的指令(比如“翻译这句话”、“写一首诗”),它执行这个具体的任务。它不会主动思考步骤,也不会自己去使用其他软件。
- AI Agent 是一个“自主的助手”:你给它一个目标(比如“帮我策划一个周末旅行”),它会自己思考,自己规划步骤,并且自己调用各种工具来完成任务。
假设你给ChatGPT和AI Agent分别下达同一个指令:“为我规划一个本周末在北京的两天一夜旅行,预算3000元。”
1. ChatGPT(作为工具)会怎么做? 它会基于训练数据,生成一段文本。内容可能包括推荐的景点、餐馆和大概的花费。但它提供的信息可能是过时的,它无法验证酒店是否还有空房,也无法告诉你具体的票价。它只是一个“信息整合器”。
2. AI Agent(作为助手)会怎么做? 它会像一个有经验的私人助理一样行动:
- 第一步:理解与规划(Thinking)
- 它的“大脑”(LLM)会理解你的目标:周末、北京、两天一夜、3000元预算。
- 然后它会自主规划出步骤:
1. 搜索北京周末值得去的景点 -> 2. 查询周六的酒店空房和价格 -> 3. 查询往返交通 -> 4. 制定一个详细的时间表 -> 5. 汇总成一份报告。
- 第二步:执行与工具使用(Tool Use)
- 它不会只停留在“想”,它会自动调用相应的工具或API去执行:
- 调用【搜索引擎工具】搜索“北京本周末艺术展览”。
- 调用【酒店预订API】查询周六晚价格在500元以下的酒店空房。
- 调用【地图API】计算景点之间的路线和时间。
- 调用【日历工具】为你生成一个详细的行程日历。
- 第三步:迭代与交付(Iteration)
- 它发现心仪的酒店订满了,它会自动调整计划,寻找附近同档次的酒店。
- 它发现预算超支了,会自动优化方案,比如更换一家餐馆。
- 最终,它交付给你的不是一段文本,而是一个可执行的、个性化的、信息准确的旅行计划,甚至已经为你生成了预订链接。
所以,AI Agent = 大型语言模型(大脑)+ 思考能力 + 工具使用能力。
1. AI Agent的组成
主要分为四个部分:规划决策、记忆、工具、行动
二、AI Agent智能搜索系统架构
1. 系统总体设计
智能搜索AI Agent通常由以下几个核心模块组成:
- 用户输入理解模块
- 使用NLP技术对用户查询进行意图识别与语义解析。
- 支持问答式、指令式以及多轮对话搜索。
- 知识表示与存储模块
- 利用知识图谱(Graph Database,如Neo4j)存储实体关系。
- 提供快速语义检索和推理能力。
- 搜索与推荐模块
- 集成传统搜索引擎(Elasticsearch、Lucene)与向量检索(FAISS、Milvus)。
- 根据查询意图选择合适的数据源并进行检索。
- 策略决策模块
- 强化学习或规则引擎决定搜索策略,如多轮检索、相关性排序、结果融合。
- 响应生成模块
- 将检索结果与上下文信息融合,通过自然语言生成(NLG)输出最终答案。
整体架构示意图如下:
用户输入 ->NLP理解 -> 检索策略 -> 向量检索/关键词检索 -> 知识图谱推理 -> 响应生成 -> 用户输出
2. Agent工程
2.1 Agent的九种设计模式
https://zhuanlan.zhihu.com/p/692971105
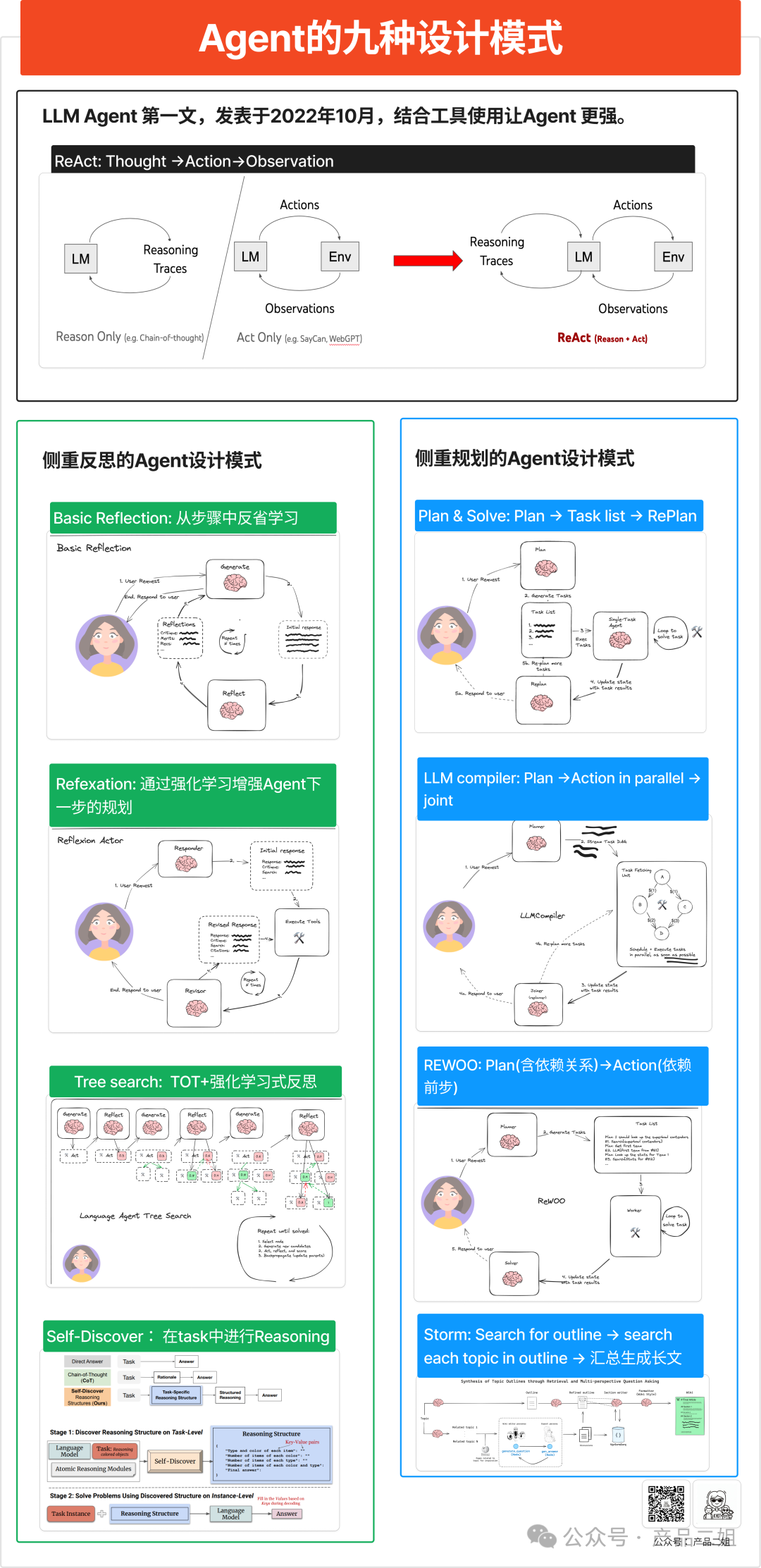
ReAct模式
ReAct 原理很简单,没有 ReAct 之前,Reasoning 和 Act 是分割开来的。
你让孩子帮忙去厨房里拿一个瓶胡椒粉,告诉 ta 一步步来(COT提示词策略):
- 先看看台面上有没有;
- 再拉开灶台底下抽屉里看看;
- 再打开油烟机左边吊柜里看看。
没有 React 的情况就是:
不管在第几步找到胡椒粉,他都会把这几个地方都看看(Action)。
有 React 的情况是:
Action1:先看看台面上有没有; Observation1:台面上没有胡椒粉,执行下一步; Action2:再拉开灶台底下抽屉里看看; Observation2:抽屉里有胡椒粉; Action3:把胡椒粉拿出来。
是的,就是这么简单,在论文的开头作者也提到人类智能的一项能力就是 Actions with verbal reasoning,即每次执行行动后都有一个“碎碎念(Observation”:我现在做了啥,是不是已经达到了目的。这相当于让 Agent 能够维持短期记忆。
两种模式的关键差异对比:
|
对比维度 |
侧重规划的 Agent 设计模式 |
侧重反思的 Agent 设计模式 |
|
核心目标 |
确保 “按预设路径高效达成明确目标” |
确保 “通过迭代优化适配动态需求 / 环境” |
|
决策时序 |
决策前置(执行前先规划路径) |
决策后置(执行后通过反思调整策略) |
|
数据依赖 |
依赖 “环境先验数据”(如地图、任务规则) |
依赖 “历史执行数据”(如用户反馈、日志) |
|
适用场景 |
无人配送、工业生产调度、固定流程任务 |
智能客服、个性化推荐、动态规则场景 |
|
核心风险 |
环境突变导致路径失效(如突发拥堵) |
初期执行效果差,需大量数据积累优化 |
不过这里有个问题:如果对话聊得久了,Agent 可能会忘事 —— 比如你刚说 “怕风险”,下一句问 “该买什么”,它转头推荐高风险股票。这时候就得教它 “记东西”,也就是上下文工程。
2.2 上下文工程
你跟朋友聊天时,不用反复说 “我喜欢低风险理财”—— 朋友会记住。但 Agent 默认 “记不住之前的话”,比如你刚说 “我怕风险”,下一句问 “该买什么基金”,它可能推荐高风险股票基金,这就是 “没管好上下文”。
上下文工程,就是 “教 Agent 怎么记信息、记多久、记哪些重点”,关键做 2 件事:
1.“控制记忆长度”:Agent 的 “记忆容量” 叫 “上下文窗口”,比如能记 1000 句话 —— 你要决定哪些话留(比如用户的风险偏好、关键需求),哪些话删(比如 “你好”“谢谢” 这种废话);
2.“抓重点记忆”:比如用户聊了 10 分钟理财,Agent 不用记每句话,只需要记住 “本金 5 万、能接受 3% 以内亏损、想存 1 年” 这 3 个核心信息。简单说,上下文工程就是 “给 Agent 装个‘记事本’,让它不用你反复说,也能记住关键信息”。
有了 “记忆”,Agent 就能记住你的需求了,但它不知道 “公司新产品参数”“行业政策” 这些外部信息 —— 总不能让它瞎编吧?这时候就得给它建个 “资料室”,也就是知识库。
2.3 知识库 & RAG
Agent 不是 “天生啥都懂”—— 比如你让它介绍 “公司新产品参数”,它没学过就会瞎编。这时候就要给它建个 “资料室”(知识库),里面存满产品手册、行业资料,让它能随时查。
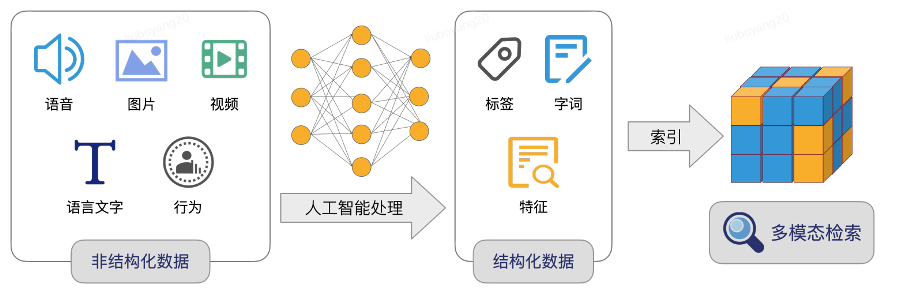
但资料多了,Agent 逐字读会很慢 —— 比如资料室有 1 万份文档,它查 “产品” 要读 1 小时,而 “向量化” 就是给文档编快速查找的‘指纹’”。下面用 “整理公司产品手册” 的例子,一步步讲明白:
2.3.1 向量化
第一步:先搞懂 “为啥要向量化?”—— 不搞这个,AI 找资料比你翻快递单还慢
常见向量化算法可详见:http://xingyun.jd.com/shendeng/article/detail/45796
假设公司有 1000 份产品手册(每份几十页),用户问 “咱们的手机保修期多久?”。如果不做向量化,AI 得逐字读 1000 份手册,可能要等 10 分钟才出结果,比你翻一堆快递单找一个包裹还慢。
向量化的本质就是:把 “文字内容” 变成 “一串能代表意思的数字”(就像给每段话编个 “内容指纹”),后续找的时候不用读全文,只比对 “指纹” 就行,1 秒就能找到。
比如手册里 “手机保修期 2 年,支持全国联保” 这句话,向量化后会变成一串数字(比如 [0.3, 0.8, -0.2, 0.5…])—— 这串数字看着乱,但核心是 “意思越像的话,数字串越像(余弦相似度)”(比如 “平板保修期 1 年” 的数字串,会和上面的很接近)。
第二步:文档怎么变成 “数字指纹”?(向量化 3 步走,像整理资料柜)
有了文档(比如产品手册),向量化不是直接扔给 AI 就行,得先 “整理干净”,再 “编指纹”,最后 “存好”,分 3 步:
1. 先 “拆文档、去废话”—— 把厚手册拆成 “方便查的小卡片”
就像你整理资料时,不会把一本厚手册直接塞柜子,而是拆成 “手机型号 A”“手机型号 B”“保修政策” 等小章节,还会把里面 “的、了、啊” 这种没用的词删掉,只留关键信息。
AI 会做两件事:
• 拆分成 “小片段”:比如把 “手机手册” 拆成 “屏幕参数”“电池容量”“保修期” 等段落(每段 200-500 字,太长的话 “指纹” 会不准);
• 提关键信息:比如 “本公司生产的 X 型号手机,其保修期为 2 年,在此期间内,若因产品质量问题出现故障,可凭购买凭证享受全国联保服务”—— 会提炼成 “X 型号手机保修期 2 年,全国联保,需购买凭证”。
2. 再 “转数字”—— 用工具把 “小卡片内容” 变成 “指纹”
这一步是向量化的核心,不用你写代码,靠专门的工具(比如开源的 Sentence-BERT、百度的文心千帆,或者我们用的第三方工具)就能实现。
原理很简单:工具会 “读懂” 每段话的意思,然后给这个意思分配一串数字(一般是几百个数字组成的 “数字串”,比如 128 位、256 位)。
举个具体例子:
• 原文片段:“X 型号手机保修期 2 年,支持全国联保,需提供购买凭证”
• 向量化后:[0.28, 0.75, -0.12, 0.43, -0.09, 0.61…](共 256 个数字,这里只列几个)
• 关键特点:如果另一个片段是 “Y 型号平板保修期 1 年,全国联保需发票”,它的数字串会和上面的很像(因为都讲 “保修期、联保、凭证”);但如果是 “手机屏幕分辨率 2K”,数字串就会差很远 —— 这就是 “意思越像,数字越像”。
常见的向量化算法:
图片来源: https://zhuanlan.zhihu.com/p/701509875
3. 最后 “存起来”—— 把 “指纹” 放进专门的 “数字档案柜”(向量数据库)
普通文件夹存的是文字,没法快速比对 “数字指纹”,所以得用 “向量数据库”(比如 Milvus、vearch),它就像一个 “按指纹分类的档案柜”:
• 每个 “数字指纹” 都会对应原始的文档片段(比如 “X 型号保修期” 的数字串,会关联到 “手机手册第 5 章第 2 节”);
• 数据库会给这些 “指纹” 编索引(就像档案柜的标签),后续找的时候不用翻所有指纹,直接按索引定位,速度能快 100 倍。
2.3.2 RAG:让 Agent “会查资料再回答” 的关键技能
传统 AI Agent 若只靠自身参数记忆回答,容易出现 “记不准、答不全” 的问题,RAG 的核心价值就是通过内部知识库解决这些痛点;(若还需应对外部实时 / 跨领域需求,则需搭配工具调用)
答不全 “内部细节问题”:比如销售问 “咱们冰箱的保修政策包含上门服务吗?”—— 若 AI 只靠参数记忆,可能漏记手册里 “保修含 1 次免费上门” 的细节,而 RAG 能从内部知识库精准调出对应片段,避免说 “不知道”;
答不准 “专业领域问题”:比如客服被问 “咱们智能门锁的应急供电接口在哪?”—— 自家资料写了 “在底部 Type-C 口”,但 AI 可能乱答 “在顶部”,RAG 通过检索内部手册片段,能确保答案精准,减少用户投诉;
内部资料更新效率低:比如新品参数更新后,若只靠重新训练 AI 来记忆,成本高、周期长,而 RAG 只需将新参数文档加入知识库,就能实时调用,不用反复训练模型。
若还需解决 “实时查竞品价、跨领域查兼容” 等外部需求,仅靠 RAG 不够,需在 RAG 基础上叠加工具调用(如对接电商 API、第三方官网接口)—— 比如想知道 “美的冰箱实时价”,工具调用能获取外部数据,再和 RAG 检索的自家价格结合,生成完整答案。
没有 RAG 的 Agent,就像 “没翻公司档案就回答内部问题”,容易漏细节、说错话;有了 RAG,Agent 回答内部问题时,能精准调用自家资料,既靠谱又能快速响应,特别适合企业客服、销售查产品、内部培训等场景。
但光靠咱们之前聊的内部知识库,其实还有 “罩不住” 的情况 —— 要是想查互联网上实时更新的信息,比如竞品当天的电商活动价、刚发布的行业新政策,这些内部库根本存不下(毕竟数据天天变,总不能实时往库里塞),这时候就需要个专门对接外部工具的 “帮手” 来补位了,它就是咱们接下来要细说的 MCP。
2.3.3 MCP 调度外部工具
RAG 就像 “自家档案柜 + 查档工具 + 资料整理员”,能把内部资料用得很溜,但要是遇到 “得查互联网实时更新的数据”—— 比如 “今天竞品在电商平台的最新价”“刚发布的行业新政策”,仅靠 RAG 的内部知识库就像 “巧妇难为无米之炊”,这时候就得给 AI 加个新帮手:MCP(模型上下文协议)。
简单说,MCP 就是 “AI 的外部工具调度员”—— 它能帮 AI 规范、安全地调用外面的各种工具(比如电商 API、官网检索工具、政策查询接口),让 AI 不用只盯着自家资料,还能实时抓互联网上的新鲜数据,再和 RAG 的内部知识凑一起,把答案答得又全又新。
可能有人会问:“直接让 AI 调用京东 API 查价格不行吗?为啥要多 MCP 这一步?” 其实 MCP 的作用就像 “给 AI 的工具调用立规矩”,解决 3 个关键问题:
怕 AI 乱调用:要是没 MCP 管着,AI 可能随便调用不安全的工具(比如泄露企业数据的接口),或者重复调用同一个工具浪费资源;MCP 会先列好 “可用工具清单”,AI 只能从里面选,还得按格式申请,避免瞎折腾。
怕工具不兼容:不同工具的调用方式不一样(比如京东 API 要传 “商品 ID”,天猫 API 要传 “SKU 码”),没 MCP 的话,AI 得学每种工具的用法,很麻烦;MCP 会给所有工具定 “统一调用格式”,比如不管查京东还是天猫,AI 都只用传 “商品名称 + 平台”,剩下的 MCP 来转译,省事儿多了。
怕数据不安全:调用外部工具时,难免要传一些信息(比如查自家产品在京东的销量,得传产品 ID),没 MCP 的话,这些信息可能泄露;MCP 会加 “安全过滤”,只传必要的信息,还会记录调用日志,出问题能溯源。
MCP 怎么帮 AI 查实时互联网数据?
1.先明确 “内部不够,需要外部”:
RAG 从内部知识库查到 “X 型号手机官方价 2999 元”,但用户问的是 “比竞品 A、B 今天便宜多少”—— 竞品价是实时变的,内部库没有,这时候 AI 就会告诉 MCP:“我需要调用电商价格工具,查竞品 A、B 今天的售价。”
1.MCP 调度工具,按规矩调用:
◦第一步:MCP 先查 “可用工具清单”,找到 “京东价格查询工具” 和 “天猫价格查询工具”,确认这两个工具能正常用;
◦第二步:MCP 按统一格式,把 AI 的需求转成工具能懂的指令,比如给京东工具传 “商品名称:竞品 A 手机,查询时间:今天”,不用 AI 自己凑 API 参数;
◦第三步:工具执行后,把结果返回给 MCP(比如 “竞品 A 今天京东活动价 3199 元,明天结束”“竞品 B 天猫日常价 3099 元”),MCP 再把这些数据整理成 AI 能直接用的格式(去掉没用的广告信息,只留价格和活动时间)。
2.结合 RAG 出最终答案:
MCP 把实时竞品价交给 AI,AI 再结合 RAG 查到的内部官方价,整合出答案:“现在买 X 型号手机官方价 2999 元,比竞品 A(今天京东活动价 3199 元)便宜 200 元,比竞品 B(天猫日常价 3099 元)便宜 100 元,注意竞品 A 的活动明天结束哦。”
MCP 还能帮 AI 做啥?
除了查实时电商价,只要是互联网上能通过接口获取的实时数据,它都能帮 AI 搞定:
1.查行业新政策:调用国家发改委官网工具,实时获取 “家电能效新国标”,避免 RAG 按老政策回答;
2.查跨品牌兼容性:调用小米开发者平台工具,查 “X 型号手机能不能连小米智能家居”,不用人工翻小米官网;
3.查实时天气 / 交通:要是做旅游规划 AI,MCP 能调用天气工具查目的地未来 3 天天气,调用交通工具查高铁票余票,让规划更精准。
简单说,MCP 就是 AI 的 “外部工具管家”—— 当 RAG 的 “自家档案柜” 装不下实时互联网数据时,MCP 能帮 AI “规矩地找外部帮手”,安全、高效地拿到最新数据。有了 RAG+MCP 的组合,AI 既能把自家事儿说清楚,又能实时跟上外面的变化,不管是销售比价、客服跨品牌咨询,还是查新政策,都能应对得更靠谱。
但如果遇到复杂活,比如 “做一次 3 天 2 晚的旅游规划”,单个 Agent 又查机票、又算预算、又写行程,容易忙不过来、出错 —— 这时候就需要多个 Agent “组队干活”,也就是多智能体协同。
2.3.4 多智能体协同
单个 Agent 能力有限 —— 比如 “做一次旅游规划”,需要查机票、算预算、订酒店、写行程,一个 Agent 干起来又慢又容易错。这时候就需要 “多智能体协同”:让多个 Agent 分工合作,像一个小团队。
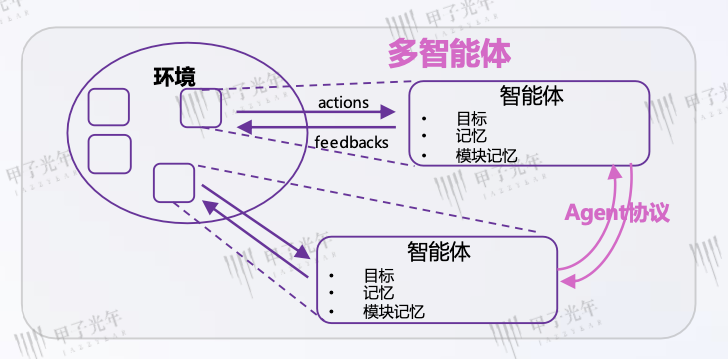
核心是 “明确分工”,比如旅游规划团队可以有 3 个 Agent:
1.信息收集 Agent:负责查机票价格、酒店 availability、景点开放时间;
2.分析计算 Agent:根据用户预算(比如 5000 元),算机票 + 酒店 + 门票的总费用,避免超支;
3.输出整理 Agent:把收集到的信息整理成 “3 天 2 晚行程表”,用清晰的格式发给用户。它们之间还能 “沟通”—— 比如信息 Agent 查到机票涨价了,会告诉分析 Agent “预算要加 500 元”,分析 Agent 再调整酒店选择,最后输出 Agent 更新行程。简单说,多智能体协同就是 “给 Agent 找‘同事’,分工合作干复杂活,比单个 Agent 效率高 10 倍”。
3. 核心算法研究
3.1 自然语言理解(NLU)
NLU模块主要任务包括:
|
核心任务 |
目标 |
关键技术 |
输出与下游作用 |
|
意图识别 |
判断用户想做什么(动作) |
-分类模型: BERT, RoBERTa -少样本/零样本学习: 使用DeBERTa等模型应对新意图 -大模型提示: 使用GPT-4等直接进行意图分类 |
|
|
实体识别 |
找出动作涉及的关键信息(对象) |
-序列标注: BiLSTM-CRF, BERT-CRF -分词与POS标注: Jieba, SpaCy -大模型提示: 直接抽取实体 |
|
|
语义向量化 |
将文本转化为机器可理解的数学表示 |
-句子编码: Sentence-BERT, SimCSE -上下文编码: OpenAI |
|
- 场景:用户向智能音箱发出指令 明天早上北京的天气怎么样?
- 意图识别:模型分析整个句子的语义,将其分类到预定义的“查询天气”类别。
- 实体识别:序列标注模型识别出“明天早上”是时间实体
@date,“北京”是地点实体@city。 - 语义向量化:将句子映射为一个高维空间中的向量,例如
[ -0.05, 0.8, ... , 0.2 ]。
示例Python代码:
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 用户查询与文档
query ="人工智能在搜索引擎中的应用"
documents =["AI在搜索引擎中的应用包括语义搜索和推荐系统",
"深度学习用于图像识别和自然语言处理"]
# 转化为向量
query_vec = model.encode(query, convert_to_tensor=True)
doc_vecs = model.encode(documents, convert_to_tensor=True)
# 计算相似度
cos_scores = util.pytorch_cos_sim(query_vec, doc_vecs)print("相似度评分:", cos_scores)
3.2 知识图谱推理
知识图谱通过关系推理提升搜索结果的深度理解。常用算法包括:
|
核心任务 |
目标 |
关键技术/算法 |
输出与下游作用 |
|
符号推理:路径查询 |
通过明确的路径查找,发现实体间的直接或间接关系。 |
-查询语言:SPARQL, Cypher, Gremlin -规则引擎:Jena Rules, OWL推理机 -图算法:最短路径、全路径查询 |
明确的关系路径或推理结果。用于深度问答、关系探查和合规审查,提供可解释的推理链条。 |
|
表示学习:图嵌入 |
将实体和关系映射到低维向量空间,捕获其潜在语义。 |
-平移模型:TransE, TransH, TransR -旋转模型:RotatE -深度学习模型:ComplEx, DistMult, Node2Vec |
实体和关系的低维向量。用于链接预测、相似度计算和推荐系统,作为机器学习模型的输入。 |
|
神经网络推理:GNN |
利用图神经网络聚合邻域信息,进行端到端的图结构学习与预测。 |
-图卷积网络:GCN, GraphSAGE -图注意力网络:GAT -知识图谱专用GNN:R-GCN |
融合了图结构信息的节点/图级别表示。用于节点分类、关系预测,擅长处理不完整或嘈杂的图谱数据。 |
|
规则推理与知识融合 |
基于预定义的逻辑规则推导新知识,并解决多源数据冲突。 |
-本体推理:OWL, RDFS -概率软逻辑:PSL -冲突解决策略:置信度融合、投票机制 |
新的知识三元组或统一/消歧后的实体。用于知识图谱补全、数据清洗和构建统一的知识视图 |
- 场景:金融风控Agent分析企业关联风险。
- 路径查询:通过多跳查询,明确发现目标公司A通过5层持股,最终被一个已失信企业B控制。这个过程清晰、可追溯,形成强证据链。
- 图嵌入:计算所有公司的向量,发现公司A与一批已知的皮包公司在向量空间中非常接近,从而提示其行为模式高度相似,存在潜在风险。
- GNN推理:将整个股权关系图输入GNN模型,模型综合所有邻接公司的信息和关系,直接预测出公司A的“风险评级”为“高”。
- 规则推理:应用预定义的金融风控规则(如“一旦被失信主体控制,则标记为高风险”),自动推导出新的事实,并写入知识图谱。
示例Python代码(Neo4j):
from neo4j import GraphDatabase
uri ="bolt://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j","password"))
deffind_related_entities(entity):
with driver.session()as session:
result = session.run(
"MATCH (e:Entity {name: $name})-[:RELATED_TO]->(r) RETURN r.name",
name=entity
)
return[record["r.name"]for record in result]
related = find_related_entities("人工智能")print("相关实体:", related)
3.3 强化学习策略优化
在多轮搜索场景中,AI Agent通过强化学习不断优化搜索策略:
|
核心要素 |
在搜索场景中的具体内涵 |
实例与常用技术 |
|
状态 |
Agent对当前搜索“情境”的理解。 |
-当前查询:查询字符串、意图分类。 -用户上下文:历史搜索/点击记录、长期兴趣画像、地理位置、设备。 -会话状态:在当前多轮搜索中,这是第几轮、之前讨论了什么。 |
|
动作 |
Agent可以执行的决策,即“如何响应搜索请求”。 |
-检索策略:选择哪个召回模型(如BM25, DPR, 向量模型)。 -排序策略:调整排序模型的权重(如Learning-to-Rank模型)。 -结果呈现:决定结果的多样性、新颖性、是否插入特定类型内容(如知识卡片、视频)。 |
|
奖励 |
对Agent动作好坏的即时或延迟反馈。 |
-短期奖励:点击率、停留时长、跳过率、翻页行为。 -长期奖励:用户回访率、会话成功率、最终转化率(如购买、下载)。 -人工反馈:显式的满意度评分、差评报告。 |
- 场景:用户输入查询“适合初学者的微单相机”
- 状态感知:Agent将当前查询、用户的历史行为(如该用户过去常看手机摄影内容)等整合为当前状态
s_t。 - 策略决策:根据内部策略
π,Agent选择一个动作a_t。例如,动作A是使用一个倾向于“高性价比和入门知识”的排序模型;动作B是使用一个倾向于“品牌旗舰和专业评测”的排序模型。 - 环境执行:Agent执行动作,将排序后的结果列表呈现给用户。
- 奖励反馈:系统观察用户行为:
- 如果用户点击了多个结果并长时间停留,则产生正奖励 (+R)。
- 如果用户直接跳过所有结果或重新搜索,则产生负奖励 (-R)。
- 策略优化:这个
(s_t, a_t, R)的经验被存储起来。通过大量这样的交互,RL算法(如DQN, PPO)会逐步更新策略π,使得在类似状态下,选择能获得高奖励动作的概率越来越大。
简单示例(Q-Learning伪代码):
import numpy as np
# 状态空间和动作空间
states =["初始查询","二轮查询"]
actions =["关键词检索","向量检索"]
Q = np.zeros((len(states),len(actions)))
alpha =0.1
gamma =0.9
# 更新Q值defupdate_Q(state_idx, action_idx, reward, next_state_idx):
Q[state_idx, action_idx]+= alpha *(reward + gamma * np.max(Q[next_state_idx,:])- Q[state_idx, action_idx])
三、提示词应该如何写?
1.“说清楚任务”:比如让 Agent 算理财收益,要明确 “本金 10 万,年化 4%,存 3 年,算复利”,别只说 “算收益”;
2.“给例子参考”:如果要 Agent 模仿你的写作风格,就给它一段你写的文字,说 “按这个语气写”;
3.“加约束条件”:比如 “回答不能超过 3 句话”“不用专业术语,说给老人听”。简单说,提示词工程就是 “教你怎么跟 Agent‘好好说话’,避免它‘会错意’”。
1. AI提示词工作原理及组成
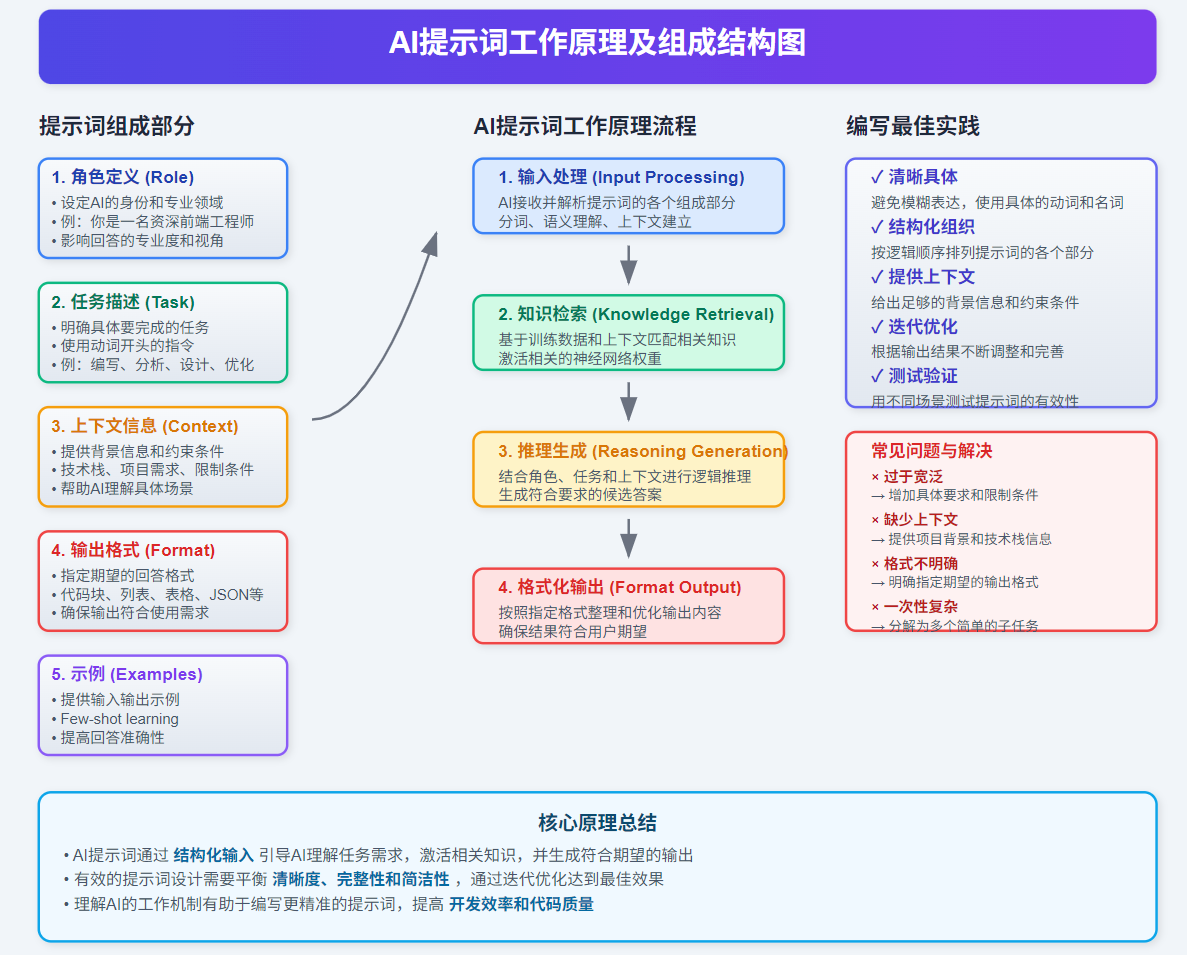
2. 组成部分详解
|
组成部分 |
重要程度 |
详细说明 |
示例 |
使用建议 |
|
角色设定 |
核心 |
定义 AI 扮演的角色身份,包括专业背景、经验水平、性格特点等,为后续对话建立基础框架。 |
|
• 角色要具体明确,避免模糊 • 包含相关的专业背景 • 考虑添加经验年限 • 可以包含性格特征 |
|
任务描述 |
核心 |
清晰说明希望 AI 完成的具体任务,包括目标、范围、要求等关键信息。 |
|
• 使用动作词开头(分析、创建、优化) • 明确具体的交付物 • 设定清晰的边界和范围 • 避免过于宽泛的描述 |
|
上下文信息 |
重要 |
提供任务相关的背景信息、约束条件、现有资源等,帮助 AI 更好地理解情况。 |
|
• 提供技术栈信息 • 说明限制条件 • 描述现有资源 |
|
输出格式 |
重要 |
指定期望的回答格式、结构、长度等要求,确保输出符合使用需求。 |
|
• 明确文档格式(JSON、表格、列表) • 指定结构要求 • 设定长度限制 |
|
示例参考 |
重要 |
提供具体的示例或模板,通过 Few-shot 学习帮助 AI 理解期望的输出风格和质量。 |
|
• 提供 1-3 个高质量示例 • 展示期望的风格和深度 • 包含正确和错误的对比 |
|
约束条件 |
重要 |
明确指出不能做什么、避免什么,设定明确的边界和限制条件。 |
|
• 明确技术限制 • 指出禁止事项 • 考虑合规要求 |
|
思维链引导 |
辅助 |
引导 AI 展示思考过程,通过分步推理提高回答的准确性和可理解性。 |
|
• 使用"一步步"、"首先...然后" • 要求展示推理过程 • 适用于复杂问题 |
|
质量要求 |
辅助 |
设定输出质量的具体标准,包括准确性、完整性、实用性等要求。 |
|
• 设定可验证的标准 • 要求完整性和准确性 • 考虑实用性要求 |
|
交互方式 |
辅助 |
定义对话的交互模式,包括提问方式、反馈机制、迭代改进等。 |
|
• 鼓励主动提问 • 设定反馈机制 • 支持迭代改进 |
3. 提示词模板参考
### 角色设定 你是一位[具体角色描述,包含专业背景和经验] ### 任务描述 请[具体动作词][详细任务描述],重点关注[关键要点] ### 上下文信息 - 技术栈:[具体技术栈]- 约束条件:[限制条件]- 现有资源:[可用资源]- 时间要求:[时间限制] ### 输出格式 请以[格式要求]回答,包含: 1. [结构要求 1]2. [结构要求 2]3. [结构要求 3] ### 示例参考 [提供 1-3 个具体示例] ### 约束条件 - 不要[禁止事项 1]- 必须[必要要求 1]- 避免[需要避免的情况] ### 质量要求 - [质量标准 1]- [质量标准 2]- [验收标准] ### 交互方式 [定义交互模式和反馈机制]
3.1 使用 ICIO 框架(Instruction-Context-Input-Output)
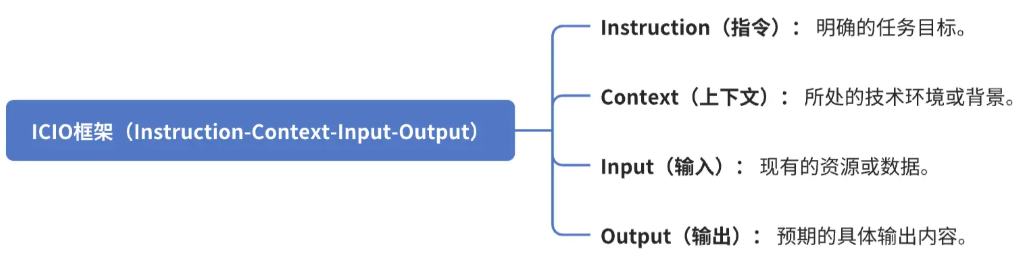
Instruction:
开发一个可复用的数据表格组件
Context:
- Vue 3 + TypeScript
- Element Plus UI库
- 响应式设计要求
Input:
- 数据接口: /api/tableData
- 字段定义: {id, name, age, status}
- 现有utils工具函数
Output:
- 组件代码
- 单元测试覆盖率>80%
- 支持自定义列配置
- 响应时间<200ms
3.2 使用BRTR 框架(Background-Role-Task-Response)
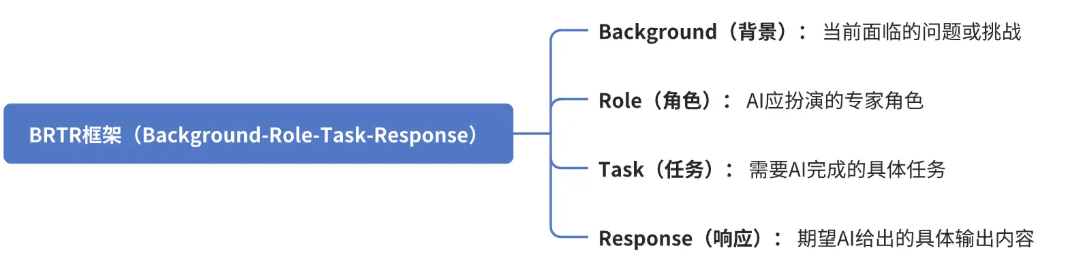
Background: 平台面临性能优化问题,首页加载时间超过3秒,影响用户体验 Role: 资深前端性能优化专家,具有5年以上大型电商平台开发经验,精通Vue性能优化 Task: 优化首页加载性能,实现以下目标: - 首屏加载时间降至1.5秒以内 - 首页核心内容优先加载 - 保持现有功能完整性 Response: 提供: - 性能优化方案设计 - 代码实现示例 - 性能检测指标 - 优化效果对比数据
3.3 使用CRISPE 框架(Context-Request-Information-Specifics-Purpose-Expectation)
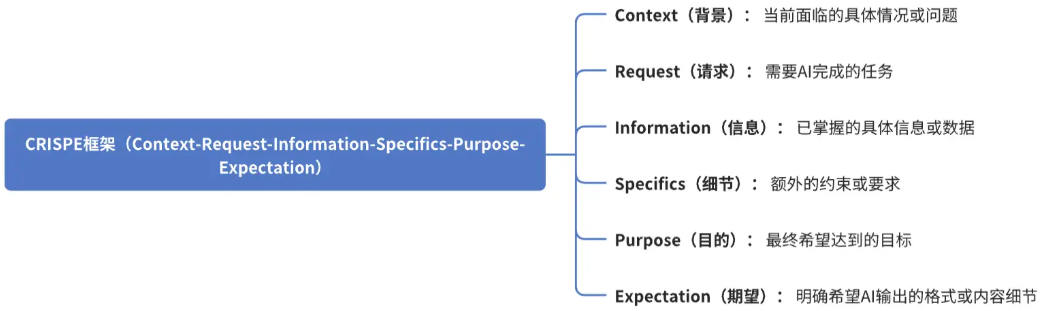
Context: 大数据分析平台的实时数据可视化模块,基于Vue3+ECharts开发, 当前图表更新卡顿,大量数据渲染时浏览器响应慢 Request: 优化数据可视化组件,实现大数据量下的流畅渲染和实时更新 Information: - 现有图表组件代码 - WebSocket实时数据接口文档 - 性能分析报告 - 服务器推送频率配置 Specifics: - 使用Vue3 + ECharts5 - 实现数据分片处理 - 添加防抖/节流机制 - 优化内存占用 - 支持动态缩放 Purpose: 提供流畅的数据可视化体验,确保大数据量下的实时展示效果, 辅助用户快速发现数据趋势和异常 Expectation: - 高性能图表组件代码 - 数据处理优化方案 - 内存管理策略 - 性能测试报告

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)