万字长文,技术解读众智FlagOS v1.5四大新进展
首届FlagOS开放计算开发者大会上发布的众智FlagOS1.5版本在硬件兼容性、技术性能和应用场景等方面取得突破性进展。该系统支持20+芯片型号,实现跨架构统一能力;FlagScale框架实现大模型全流程优化,支持多种模型架构;通过分层设计和算法优化,通信效率提升2.3倍;创新性地引入AIAgent技术,算子开发效率提升4倍;并拓展至具身智能等新应用场景。FlagOS1.5显著降低了AI算力生态
9月26日首届FlagOS开放计算开发者大会上,众智FlagOS 1.5版本由18个共创团队共同发布,其在硬件兼容广度、技术性能、应用场景和AI赋能开发四个维度上取得关键进展,引起业内广泛关注,也加速了AI基础设施的协同演进。
今天,我们来解读一下众智FlagOS 1.5的关键进展。一起理清FlagOS是如何解决AI算力生态“碎片化”,如何显著降低模型在不同算力间的迁移与适配成本,又是如何构建开放AI算力、推动AI普惠进程的。

众智FlagOS 1.5新进展
01全面性:构建广泛的硬件生态,支持芯片数量增至20+
FlagOS 1.5版本已经发展成为“4+3“的模式,即四大核心开源技术库+三大开源工具平台。通过开源技术库和开源工具平台的相互支撑,提供了更广泛的硬件支持、和更完善的组件协同。
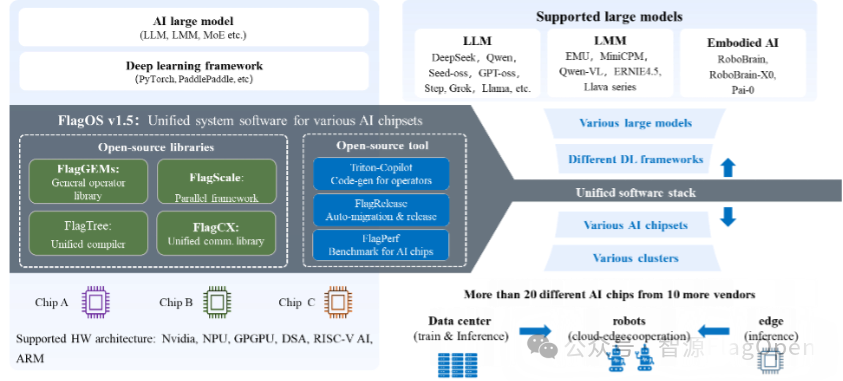
众智FlagOS 1.5 技术架构图
-
更广泛的硬件支持:FlagOS 1.5已支持国内外主流芯片厂商的20余种芯片型号,真正实现跨架构、跨芯片、跨后端的统一能力。
-
更完善的组件协同:从算子库(FlagGems)、编译器(FlagTree)到通信库(FlagCX)和并行框架(FlagScale),FlagOS 1.5的各个组件间协同更加紧密,为上层应用提供了稳定、一致的开发体验。
FlagGems已建成全球最大、支持芯片种类最多的大模型通用算子库,支持了16家芯片厂商的25款AI芯片,覆盖GPGPU、DSA、RISC-V AI、ARM等多种芯片架构。FlagTree编译器累计支持12+国内外主流芯片厂商的 20 余种芯片型号。FlagScale支持多种芯片、多种后端,支持同构集群、异构集群的训练和推理上自动调优。FlagCX统一通信库支持英伟达、寒武纪、昆仑芯、海光、华为昇腾、摩尔线程等8种芯片,支持IBRC、IBUC 、RoCE、Socket、UCX等5种网络协议,既支持PyTorch,也被原生集成到百度飞桨Paddle 3.0(正式发版中)。FlagRelease平台已实现对近6个月所有国内外主流开源大模型中,最具代表性大模型的持续适配发布,且覆盖范围显著提升,已经适配发布的模型13个,覆盖芯片11款。
-
更多模型架构支持:除了支持Transformer系列模型,FlagOS 1.5新增支持RWKV的rwkv-v7模型和Diffusion系列的Wan2.1-T2V、FLUX.1-dev、Qwen-Image等模型。
1.1 基于FlagScale训推一体框架能力,FlagOS 1.5实现大模型在多硬件、多任务场景下的全流程优化
FlagOS 1.5体系下的并行训推一体框架FlagScale升级到v0.9.0版本,采用“前端统一用户入口+中端多引擎协同+后端高性能支撑”的三层架构设计,覆盖大模型训练、微调、压缩、推理与服务部署的全生命周期所需功能。
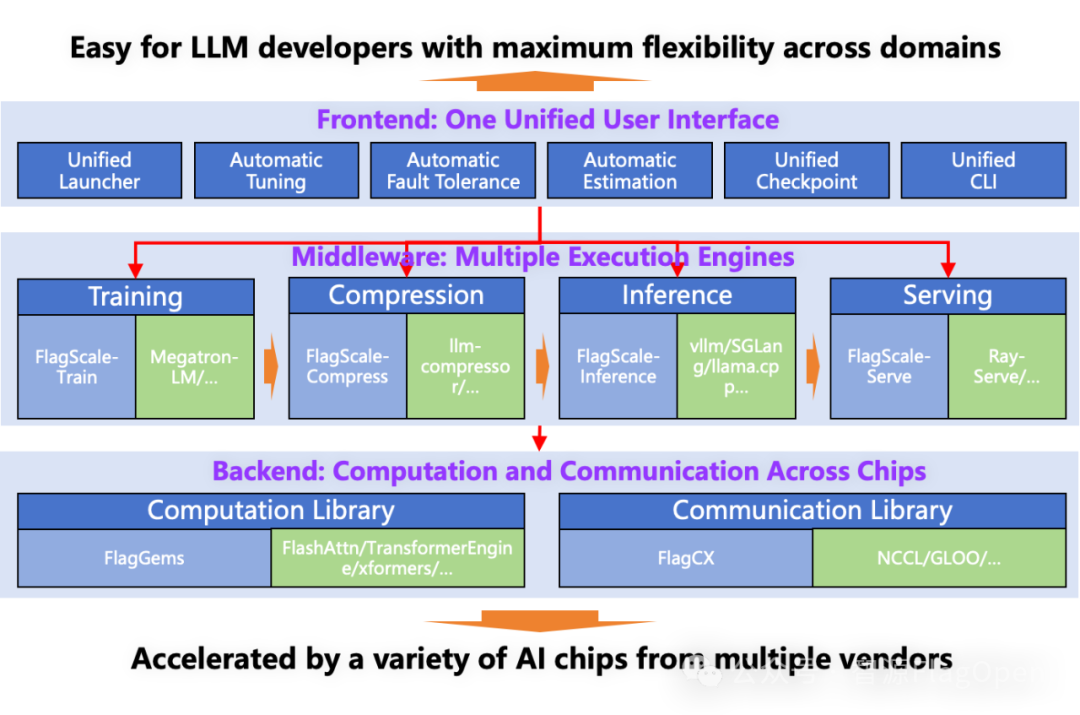
FlagScale技术架构图
前端层主要面向用户交互与系统控制,提供了统一的操作入口和任务管理能力。用户可通过“统一启动器”便捷发起不同场景下的任务,通过“自动调优”和“自动预估机制”可根据硬件环境与模型信息动态选择最优并行策略和优化策略。“自动容错机制”可在任务运行中实时检测异常并执行恢复,保障任务长稳运行、减少干预。此外,前端还支持“统一检查点”与“统一命令行接口”,简化用户操作、提升可维护性,实现从任务发起到执行监控的全流程统一管理。
中端层是系统的核心执行层,承担模型生命周期中的主要计算任务,包括训练、微调、压缩、推理与服务等功能模块。训练引擎集成Megatron-LM、Verl等分布式训练框架,并进行定制优化,实现大模型的高效并行训练与微调;压缩引擎集成了llm-compressor 等组件,对模型进行硬件感知的量化、蒸馏和剪枝,以提升模型在多芯片上的推理与部署阶段的性能;推理引擎兼容了多种主流推理框架,如vLLM、SGLang和 llama.cpp 等,提供灵活高效的推理能力和多后端自动调优能力;服务引擎支持模型在线化部署与弹性伸缩,实现高并发、高可用的推理服务。通过多执行引擎的协同运行,中端层使模型从训练到部署形成闭环,确保全流程的一致性与高效性。
后端层作为系统的基础支撑层,为上层模块提供统一的跨芯片高性能计算与通信能力。算子库深度集成通用算子库FlagGems,也兼容FlashAttention、TransformerEngine、xFormers 等常用算子库,能实现跨芯片高性能计算。通信库深度集成异构统一跨芯通信库FlagCX,也兼容NCCL、GLOO等主流通信后端,实现跨芯、多卡环境下的高效通信。后端的统一化与模块化设计,保障了FlagOS系统在多场景、多硬件环境下的稳定性、可扩展性与高性能表现,为整个架构的高效运行提供了坚实基础。
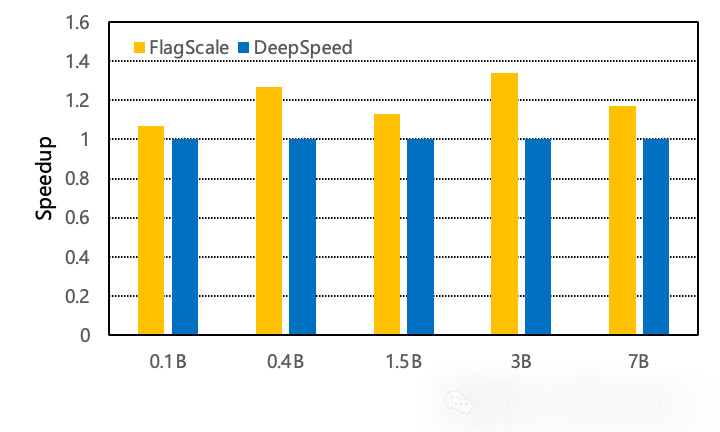
基于FlagScale能力,FlagOS在不同规模RWKV模型上的实验结果
本次FlagOS 1.5新增支持了RWKV类型模型。基于FlagScale能力,FlagOS 1.5完整实现了RWKV模型的迁移适配与训练验证。在不同规模的RWKV模型(0.1B、0.4B、1.5B、3B、7B)上的实验结果显示,FlagScale在各个规模下均实现了明显加速,其中最大加速比可达34%,平均加速比约为20%。充分体现了FlagOS对RWKV类高效大模型新架构的支持优势。
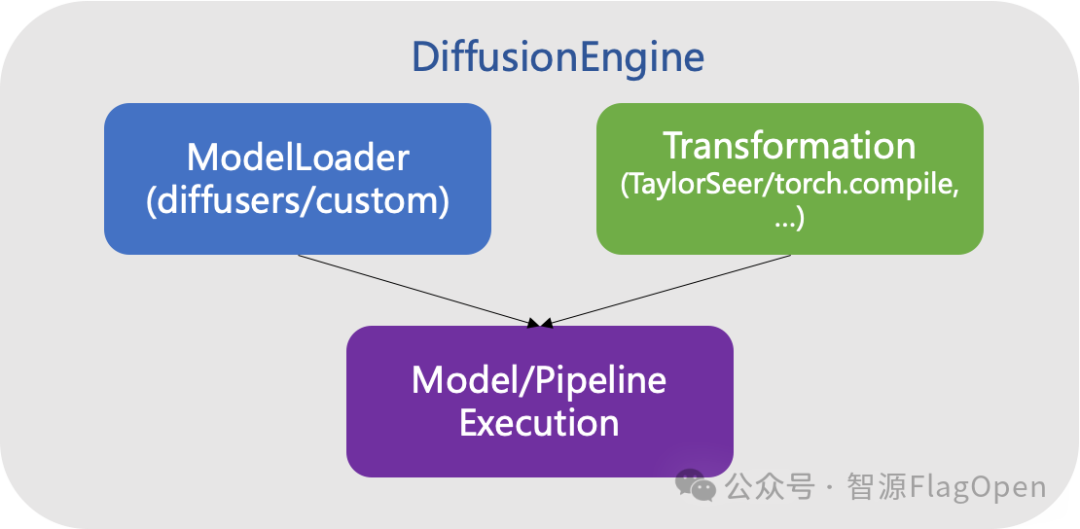
为了应对越来越多生成式多模态模型的需求,本次FlagOS 1.5新增了对Diffusion类模型的支持。FlagOS 1.5版本新增了DiffusionEngine模块,能够在保持模型与优化策略解耦的同时,秉持着非侵入式设计理念,用户可在无需修改模型结构的前提下,快速完成大模型的部署与调优,大幅降低使用门槛。
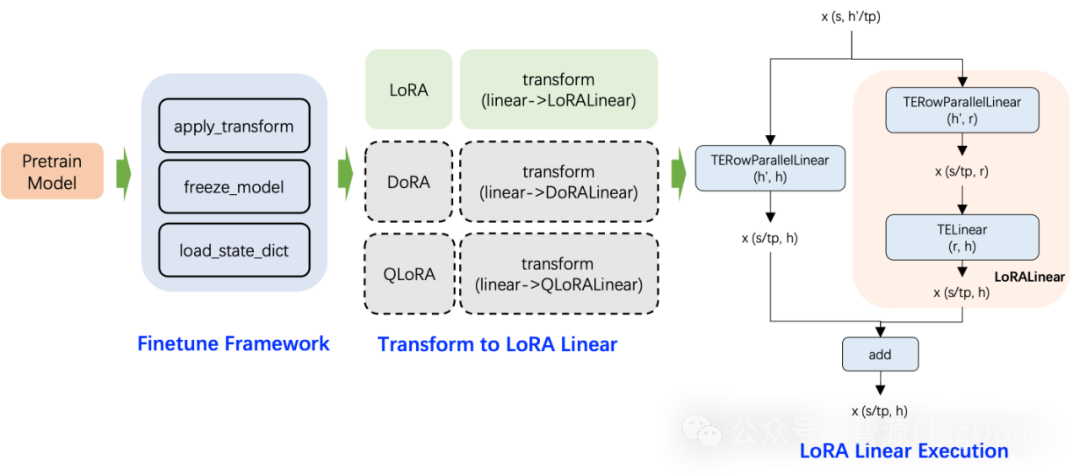
FlagOS 1.5新增LoRA功能,支持部分大规模参数高效微调
在全参微调基础上,FlagOS 1.5新增LoRA功能,支持部分大规模参数高效微调。新增的微调功能在预训练模型已有功能基础上,通过自动匹配并替换模型中线性层,添加低秩微调分支,无需修改模型核心结构,即可实现参数高效微调。此外,FlagScale为FlagOS 1.5搭建了完整的Finetuning框架,自动实现模型转换、参数冻结、权重加载等功能,除 LoRA 外,FlagOS 1.5也可扩展到DoRA、QLoRA等多种微调算法。
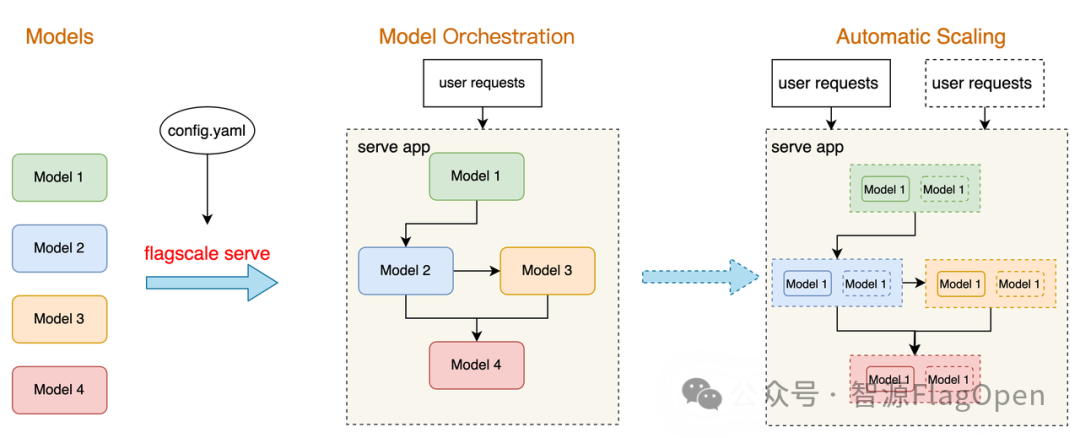
面向多模型应用的自动化编排与扩缩容能力
关于推理部署,FlagOS 1.5版本也提供面向多模型应用的自动化编排与扩缩容能力。在模型开发阶段,各模型独立构建为基础模块,通过配置文件描述模型间的依赖关系。FlagScale会根据该配置自动完成多模型流水线的编排,生成可直接服务化部署的应用,实现从用户请求到各模型协同工作的自动化流程。在运行过程中,系统可根据用户请求量和资源使用情况进行动态扩缩容,无需人工干预,自动增加或减少模型实例,确保服务在高负载下的稳定性和资源利用效率。该机制显著降低多模型服务部署和运维的复杂度,提高系统的易用性和可扩展性。
FlagOS 1.5版本的此次升级,实现了从用户交互、任务调度到底层计算的全链路优化,简化了大模型的开发与部署流程,构建了灵活可扩展的系统基础,为大模型在多硬件、多任务场景下的全流程优化提供了完整的解决方案。
1.2 FlagCX引入全新三层架构设计,提升FlagOS 1.5可扩展性、可移植性和开发者体验
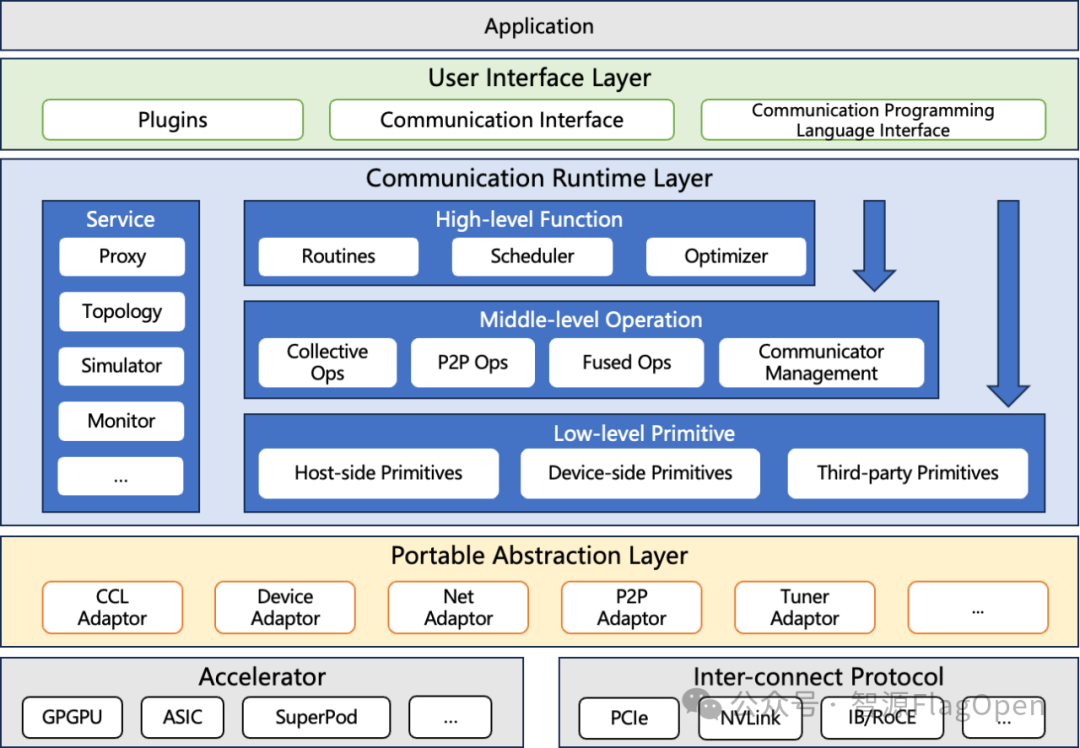
FlagCX在FlagOS 1.5中升级到v0.5.0版本,其全新架构自上而下分为用户接口层、通信运行时层和可迁移抽象层。这种分层设计使得FlagCX能够既方便用户直接使用,又能高效支持不同硬件和网络环境的适配,兼顾灵活性与性能。
-
用户接口层:作为FlagCX架构的最上层,直接面向开发者与应用程序。它的目标是为用户提供简单、统一且高效的通信编程入口。用户接口层又细分为三类接口,分别是插件接口、通信功能调用接口和编程语言接口。插件接口用于向上对接不同训推框架,例如PyTorch、PaddlePaddle等。通信功能调用接口则允许用户显式地发起通信相关基础操作,包括通信域构建、点对点通信、集合通信等。通信编程语言接口负责为通信算子开发者提供轻量级接口,便于直接在C++/Python等编程语言中实现定制化通信算子以及通算融合算子开发,加速应用开发迭代。
-
通信运行时层:位于架构的中间,承担了通信任务实际执行过程中的核心职责。它由高层通信函数、中层通信操作、底层通信原语以及服务组件构成。其中,高层通信函数提供针对中层通信操作的编排功能,并具备自动路径选择和自适应优化能力。中层通信操作提供传统的集合通信和点对点通信操作实现以及(通算)融合算子的注册和调用,附加通信域管理等功能支持。底层通信原语则面向性能关键路径,提供高效的Host-side原语、Device-side原语和第三方原语,保证优秀的通信延迟与带宽性能。除上述三个核心组件外,通信运行时层还包括服务组件,负责支撑核心组件的运行,其中包含Proxy(代理机制,用于网络异步收发)、Topology(拓扑管理与优化)、Simulator(模拟与调试)、Monitor(性能监控与诊断)等模块。这些服务组件在不同场景下均可复用,为通信执行提供全局辅助能力。
-
可迁移抽象层:位于架构最底部,目标是隔离硬件与互联协议的差异性,为上层运行时提供一致的编程模型。其中,CCLAdaptor和DeviceAdaptor负责对不同类型的硬件进行统一抽象,包括GPGPU、ASIC、SuperPod等。它同时封装了各类设备运行时(如 CUDA、HIP等)及厂商原生通信库(如NCCL、RCCL等)。NetAdaptor和P2PAdaptor则负责屏蔽底层互联协议的实现细节,对IB/RoCE、PCIe、NVLink 等多种互联协议进行统一封装,既涵盖跨节点网络传输,也支持节点内高速互联。
三层设计自上而下清晰分工:用户接口层简化使用,通信运行时层提供核心通信支持,可迁移抽象层确保多芯支持和跨芯通信能力。
02 性能:全栈优化,媲美业界标杆
2.1 FlagGems算子性能提升
-
持续优化算子性能:部分性能低洼算子,性能超越CUDA算子30%以上

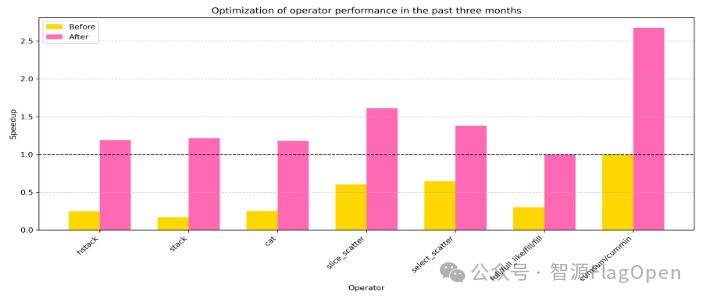
下面,以scan算子为例,具体阐述FlagOS的算子优化思路。
Scan算法和reduce关系紧密,比如cumsum可以分为块内cumsum加上前缀的sum的结果;cummin可以分为块内cummin和前缀min再取bianry min的结果。当batch维度足够大,仅在batch维度并行就足以占满设备SM时,使用分块迭代式的算法;当batch维度较小,甚至只有一个序列的时候,使用并行的scan算法。
通过Triton语言,我们实现了:
1)三种kernel版本的reduce-then-scan算法,整体读写量为2倍输入加1倍输出。
2)Decoupled lookback Scan算法,仅用一个kernel,读写量仅为1倍输入和输出,在 io 量上更为高效。并且该算法可以并行计算各个块的reduce和块内scan, 通过解耦的方式累积每块的前缀reduce结构,避免受限于通过global memory传递信息的延迟。
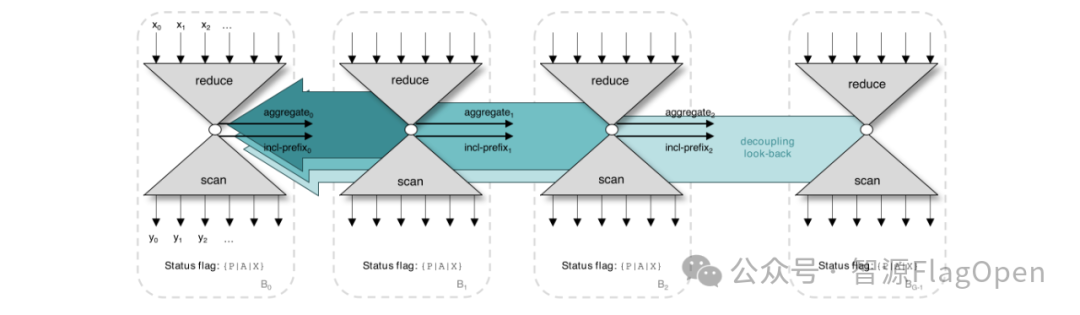
图片引用于论文 Single-pass Parallel Prefix Scan with Decoupled Look-back
-
重点模型100%覆盖FlagGems算子时,端到端推理性能持续提升:在重点模型上获得比原生Triton的3倍提速,逼近CUDA最佳性能

2.2 FlagTree编译器性能提升
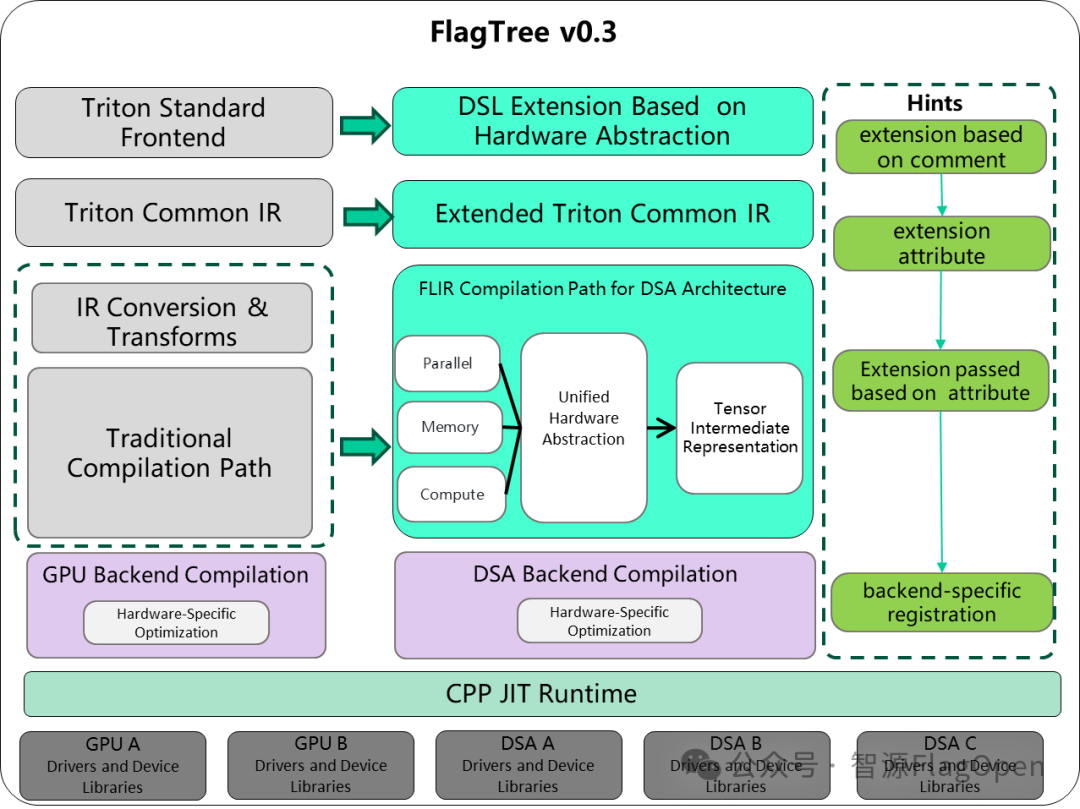
FlagTree技术架构图
特性一:基于硬件感知的编译优化技术Hints
通过注释嵌入硬件优化提示,指导硬件相关优化,提升算子性能。已在英伟达、华为昇腾和Arm China AIPU构建编译链路,其中部分重点算子在华为昇腾提速10%以上。
特性二:CPP JIT Runtime提升算子速度
Python开发算子提升易用性,CPP运行时提升性能。基于CPP语言的运行时包装机制,降低运行时开销,应用于20余个算子,平均性能提升20%以上。该技术已支持英伟达、天数和华为昇腾。
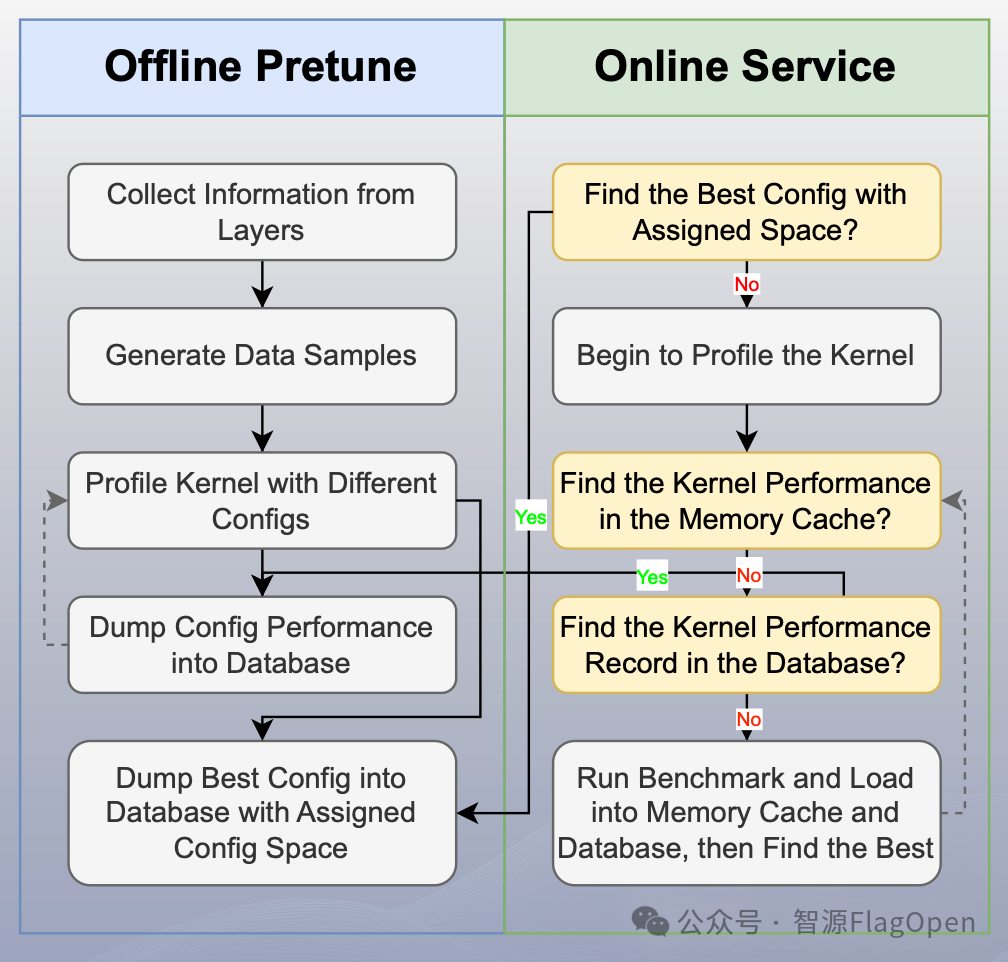
特性三:PreTune 离线搜寻最优内核配置
通过预执行自动调优提升效率,彻底消除运行时开销;持久化存储使PreTune结果可复用、可共享、便于分发;借助多级缓存加速自动调优,即使缓存部分未命中也能节省时间。经验证,在Qwen2.5-7B-Instruct模型上推理性能提升40%。
针对以上三个特性,下文会逐一介绍FlagOS 1.5是如何实现的。
2.2.1 基于硬件感知的编译优化技术Hints
整体设计上,Hints在前端层扩展Triton抽象语法树解析,将flagtree_hints编码为MLIR属性。中间层,基于 flagtree_hints属性设计优化过程,以增强优化效果。后端层,使硬件供应商能够基于flagtree_hints选择性地注册 pass。
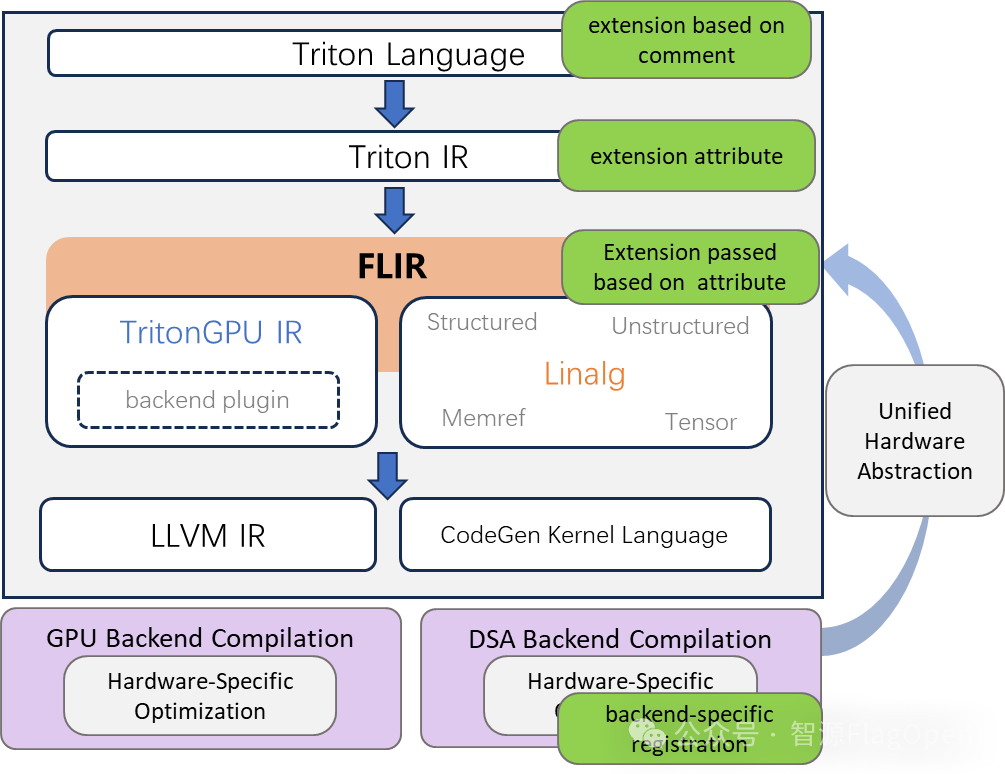
基于硬件感知的编译优化技术Hints
(1)前端语言扩展
语法: #@hints: 后面紧跟着注释指导内容,需要为特定的字符串

注释分为两类:1)硬件单元映射有关:指导数据存储、并行分配等,如:共享内存的分配;2)编译优化有关:帮助编译器选择合适的优化策略、优化参数等,如:pipeline阶段数
(2)AST 解析扩展
hints识别:解析#@hints注释,建立语法节点与对应提示之间的映射关系
hints前端验证:初步进行合法性检查,如:验证hints与目标架构是否匹配。静默忽略无效提示,以确保编译成功
(3)TTIR Attribute 扩展
扩展TTIR Dialect,将hints内容作为attribute带入TTIR,后续pass将进行对应的优化或继续传递hints attribute
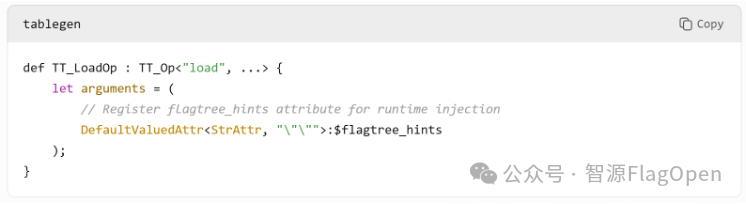
(4)中端实现一系列hints驱动的优化pass
具体流程:对照已有pass,注册hints有关的pass;在每个pass进行优化前,备份原始mod;根据hints和unified haredware内容进行优化和下降,及时进行合法性检查,若遇错误则返回备份的mod
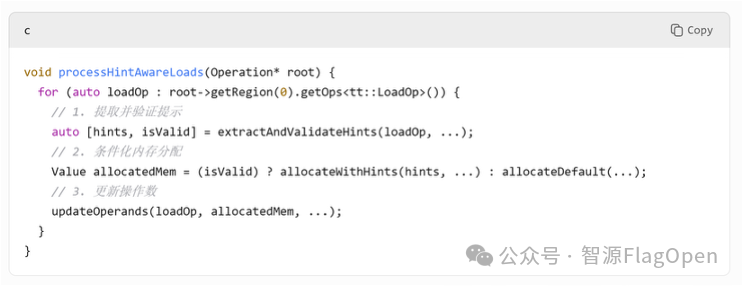
(5)后端组织相关pass,并注册Unified Haredware
基于Hints技术,FlagOS 1.5已经在华为昇腾、ARM China 周易NPU和英伟达实现全链路,具备一些基础的编译指导能力,为社区提供开发规范,持续完善编译指导能力。
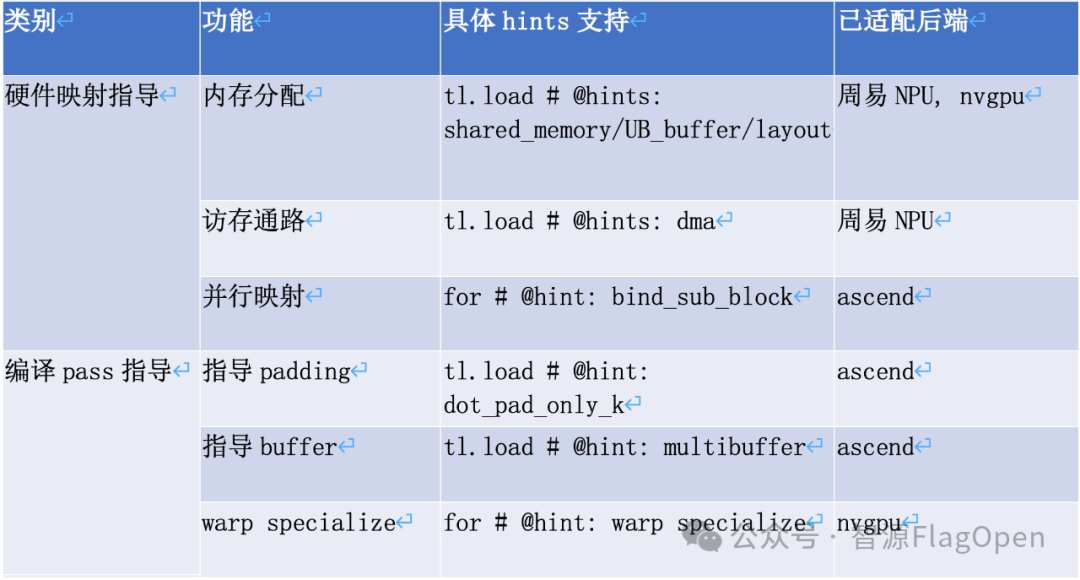
已支持的编译指导信息
2.2.2 基于 CPP JIT Runtime 的算子封装层,提升算子速度
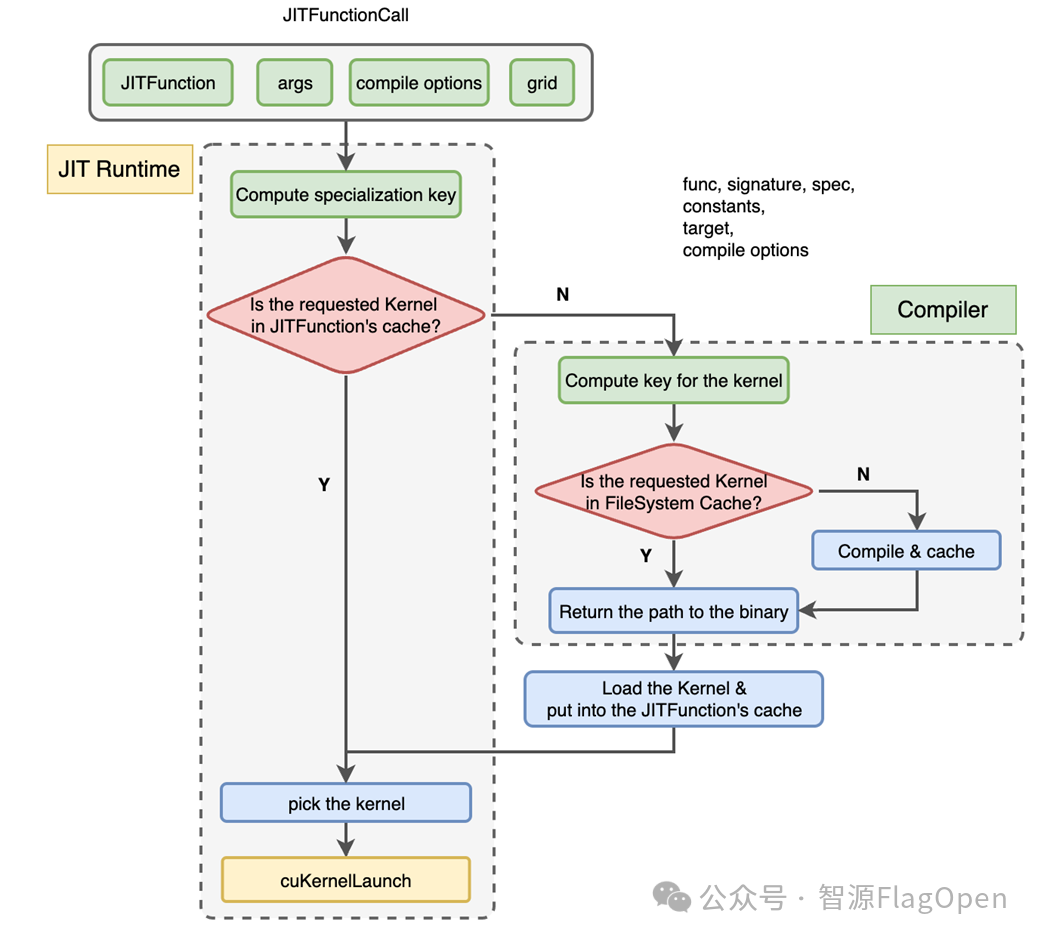
整体的思路是将运行时和编译器解耦合,采用C++重构运行时,同时复用编译器;采用可变参数模板与折叠表达式来实现核心计算的特化处理和参数路由机制(为内核精准筛选参数);单个 TritonJITFunction类即可支持多种 Triton 内核(无需为每个函数创建子类或生成额外代码)。
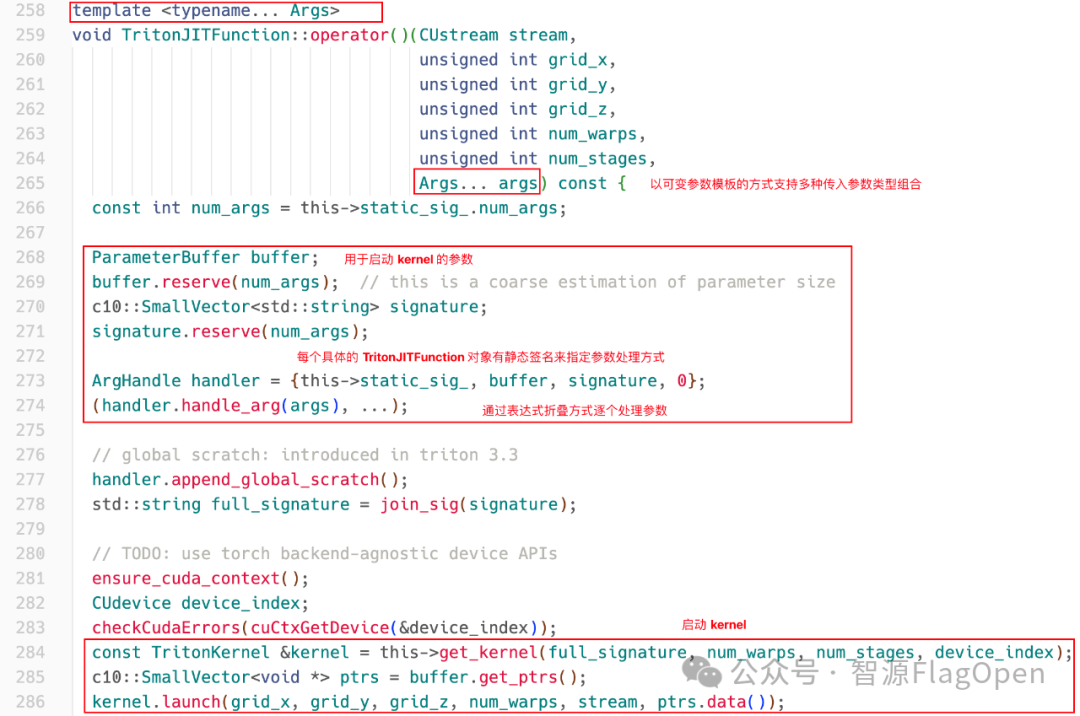
进而,封装设备驱动 API 以调用编译后的二进制文件(可扩展支持其他后端)
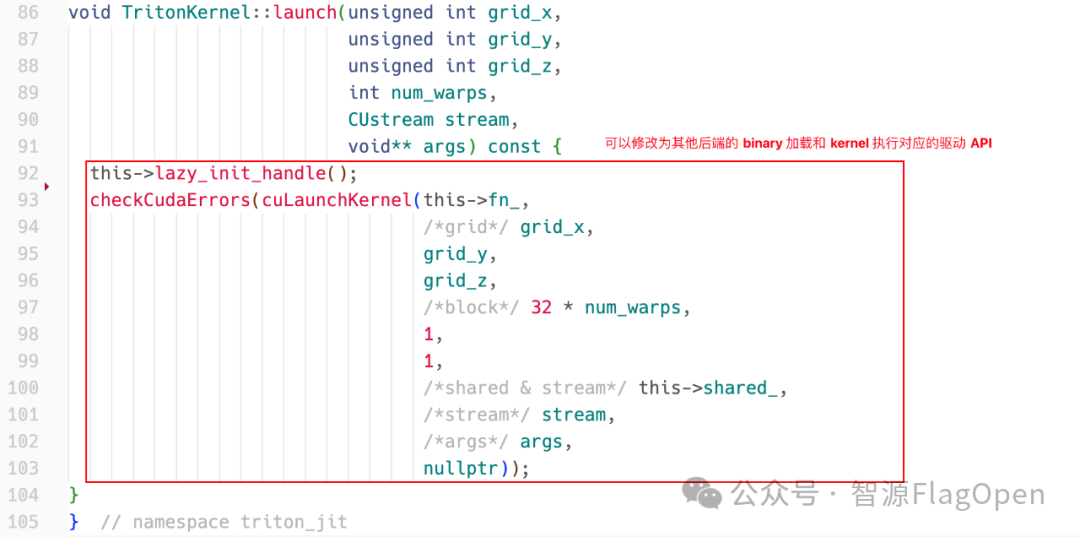
2.2.3 PreTune 离线搜寻最优内核配置
-
基于SQL的存储架构赋予PreTune结果多级缓存与离散化键值存储优势,既加速查询又简化数据分析。
-
智能性能优化通过懒加载实现,仅在缓存未命中时查询,启动时无需加载整个数据库。
-
SQL驱动的并发能力通过多线程与多进程提升自动调优效率,完美适配现代推理框架的工作流程。
2.3 训练与推理加速
FlagOS 1.5进一步提升了自动并行策略与调度算法的优化能力。在典型大模型任务中,实现了最高36.8%的自动训练加速与20%的推理加速。训练方面,升级版FlagOS 1.5增加了对专家并行和非均匀流水线并行的搜索支持,并结合更细粒度的代价建模,不仅支持dense模型,也能在不同硬件上高效完成sparse模型的自动调优。
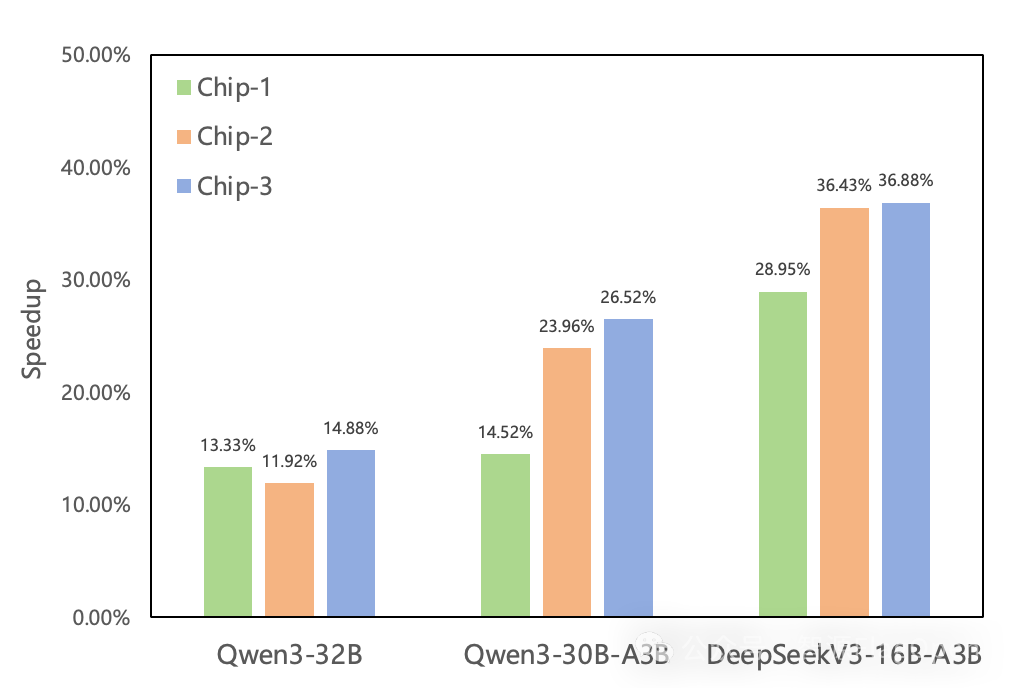
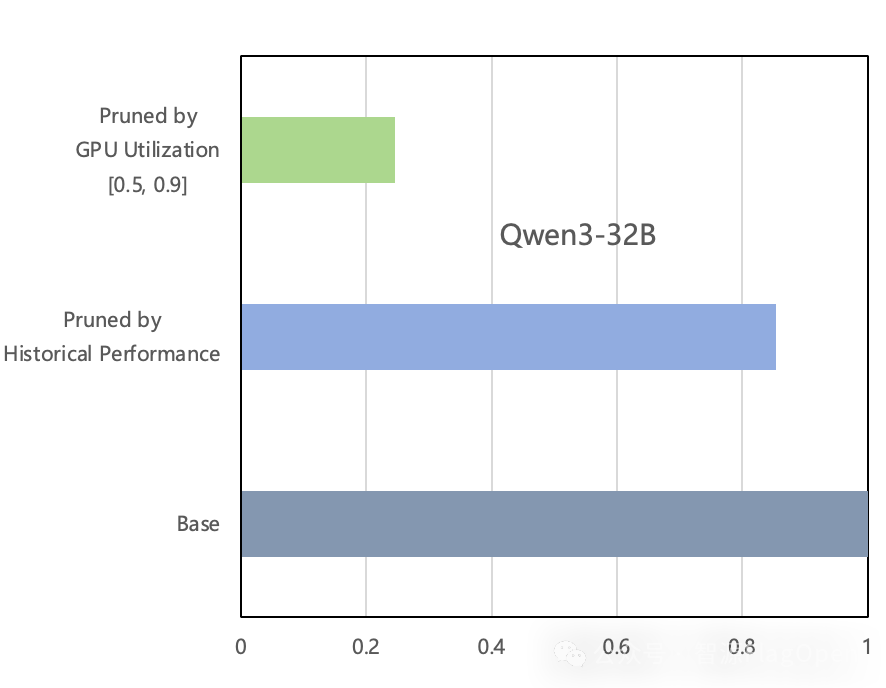
升级版FlagOS 1.5还发布了跨芯片异构混训自动调优功能,旨在充分释放异构资源潜能,实现多硬件协同下的大模型高效训练。FlagScale引入了基于规则的预剪枝算法,通过在搜索初期对低效策略进行快速筛除,大幅压缩了搜索空间规模,避免了因异构硬件组合带来的搜索空间爆炸问题,从而显著缩短了最优配置的搜索时间。依托 FlagCX 提供的统一跨芯通信能力,系统能够在多类芯片间实现高效通信,为异构并行策略的高效执行提供坚实支撑。
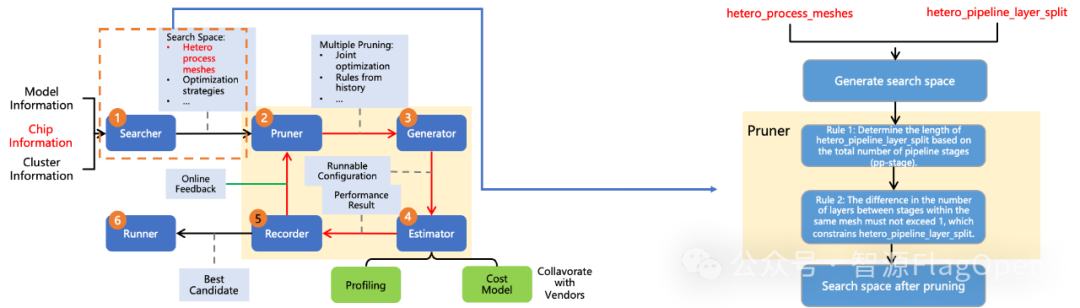
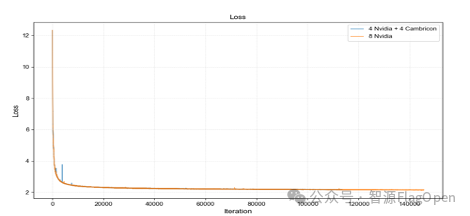
在实际测试中,FlagScale异构自动调优功能在由4台英伟达GPU与4台寒武纪芯片构成的混合集群上展现出性能优势和提升了易用性,并在与8台同构英伟达设备的训练结果对比显示,异构混训在收敛速度和收敛趋势上保持一致,充分验证了跨芯片场景的稳定性与有效性。
在推理方面,FlagOS 1.5也推出了自动调优功能,旨在满足多硬件、多模型、多场景下的大模型高效部署需求。在单实例场景下,FlagOS能够快速搜索时延最低的策略与参数配置,从而最大化单任务执行效率。同时,通过FlagScale引入的实例级调优机制,FlagOS能在固定计算资源总量的前提下,自动平衡并行策略与实例并发数量,动态搜索出吞吐量最优的运行方案。
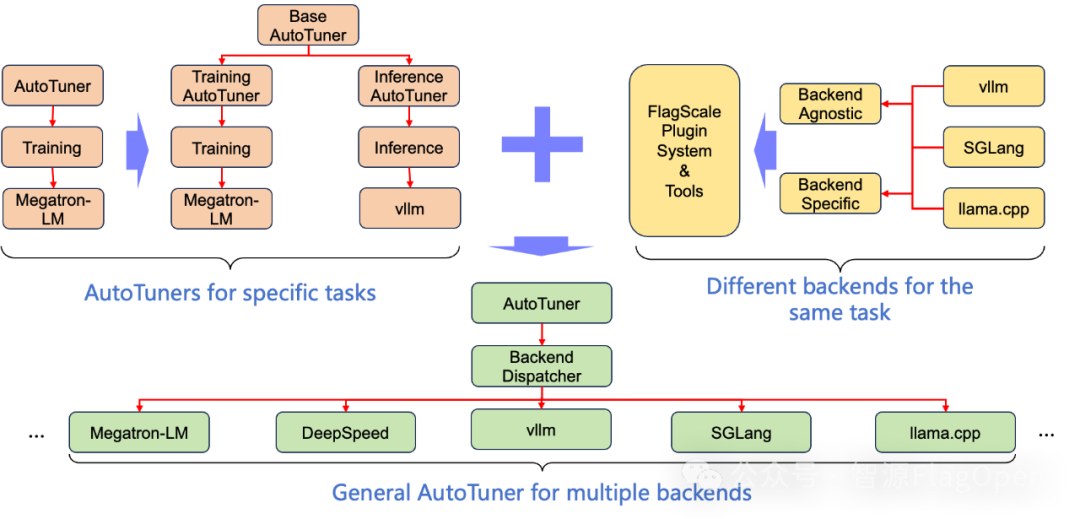
在基于训练与推理的多场景自动调优基础上,FlagOS 1.5还创新性提出了推理多后端自动调优技术,目前已支持在SGLang、vLLM 与 llama.cpp等多种主流推理后端上进行统一调优,能够针对同一推理任务自动搜索不同后端的最优执行配置,并基于性能评估结果自动选择全局最优方案。这一机制有效提升了模型在多硬件多后端环境中的可移植性与部署灵活性,显著降低了人工调参成本与跨平台适配难度。在典型大模型任务中,与专家经验配置相比,均能实现不同程度的推理加速,最高可达20%。
2.4 通信效率优化
针对大规模集群中至关重要的通信环节,通过深度优化Pipeline,新版FlagCX的通信效率实现了最高2.3倍的增长,并率先支持了跨芯片的异构混合训练。
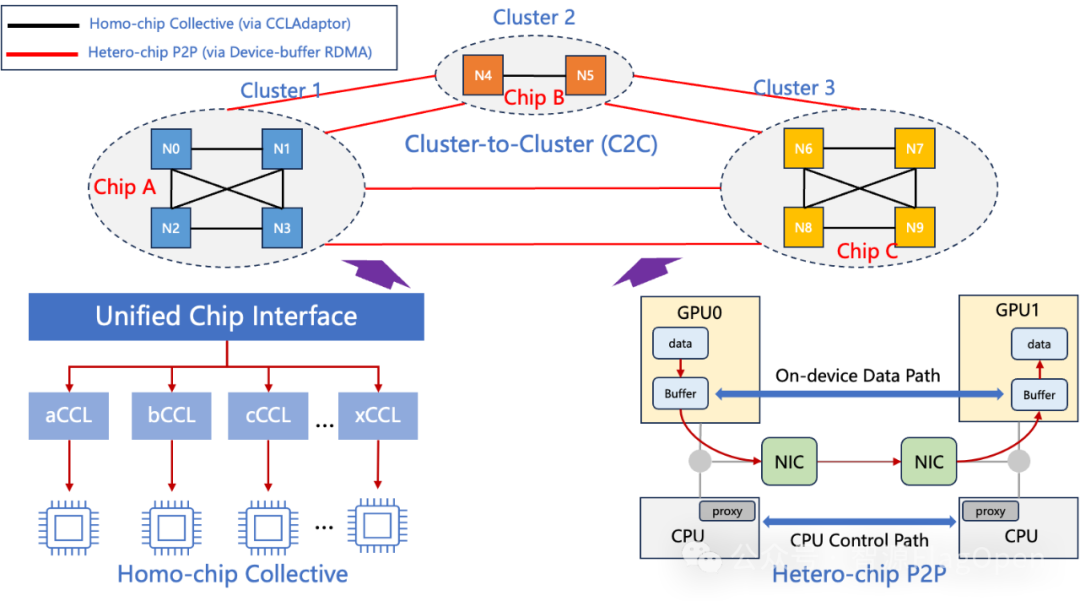
统一通信库FlagCX所创新提出的跨芯集合通信Cluster-to-Cluster(C2C)算法迎来进一步升级。假设我们把Cluster定义为一个由同构机器构成的集群,而C2C算法则是一种基于Cluster的分层算法。如下图所示,C2C算法将单次集合通信操作过程分为三个阶段:1)Pre阶段,用于Cluster内部调用同构集合通信算法(Homo-chip Collective)进行通信数据预处理;2)Inter阶段,用于执行跨Cluster通信(Hetero-chip P2P)和Cluster内部调用同构集合通信算法进行跨芯rank间的数据同步;3)Post阶段,用于Cluster内部调用同构结合通信算法进行通信数据后处理。以C2C AllGather和C2C AllReduce通信操作为例,其Pre、Inter、Post阶段分别可被映射成不同通信操作:
-
C2C AllReduce:Pre{Homo ReduceScatter} + Inter{Hetero Send/Recv + Homo AllReduce} + Post{Homo AllReduce}
-
C2C AllGather: Pre{Homo AllGather} + Inter{Hetero Send/Recv} + Post{Homo Broadcast}
可以看到,上述实现的主要性能瓶颈在于Pre、Inter和Post阶段被完全串行处理,实际上这里存在优化空间。我们通过引入流水线并线,来实现Pre、Inter、Post三个阶段任务的重叠,如下图所示:
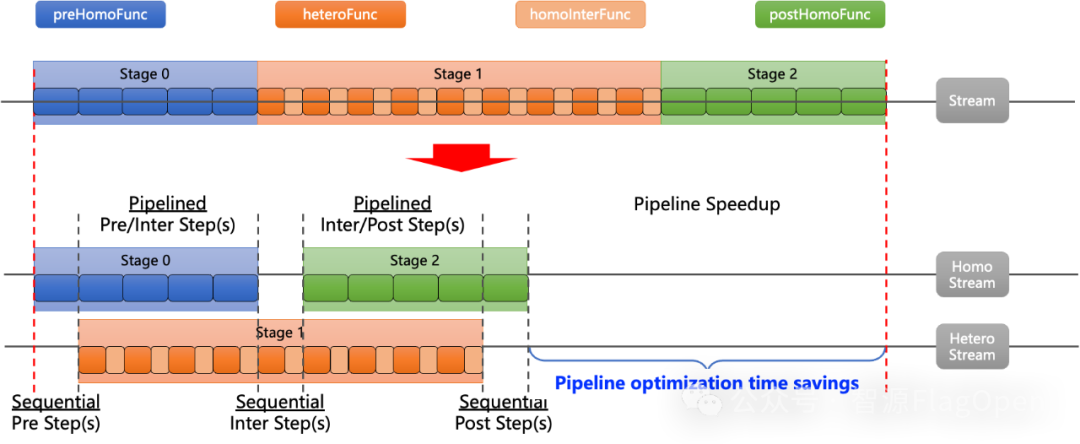
C2C算法流水线并行的实现细节可以概括为两点:1)传输数据多Chunk切分,从而实现细粒度流水;2)多Stream并行,从而实现Pre/Post和Inter阶段的重叠。
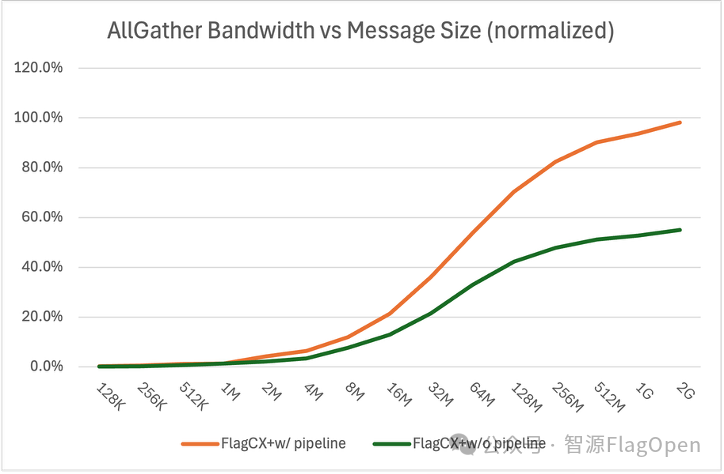
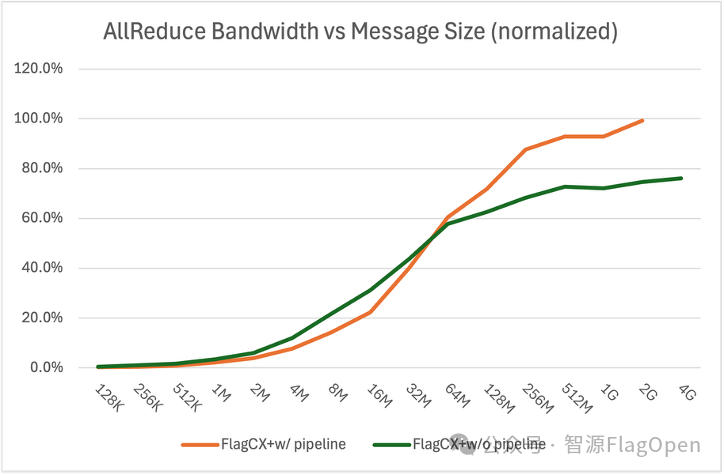
我们通过实测ChipA 2机16卡对比了AllGather和AllReduce通信操作的原生C2C算法和流水线并行C2C算法的性能数据(128K - 2G),如下图所示:
-
C2C AllGather算法使用流水线并行后相比原生算法带宽平均提升1.7x,最大提升2.0x。
-
C2C AllReduce算法使用流水线并行后相比原生算法带宽在大通信量上(>=128M)平均提升1.3x,最大提升1.3x。
此外,FlagCX所提出的Device-buffer RDMA技术同样迎来进一步升级,通过支持zero-copy在小通信量场景下获得大约300%性能提升。FlagCX将Device-buffer RDMA技术进行了zero-copy支持,如下图所示,在初始化阶段通过直接注册User-buffer,避免实际通信过程中的D2D拷贝调用,从而允许网卡直接在User-buffer上进行数据读取和写入操作。
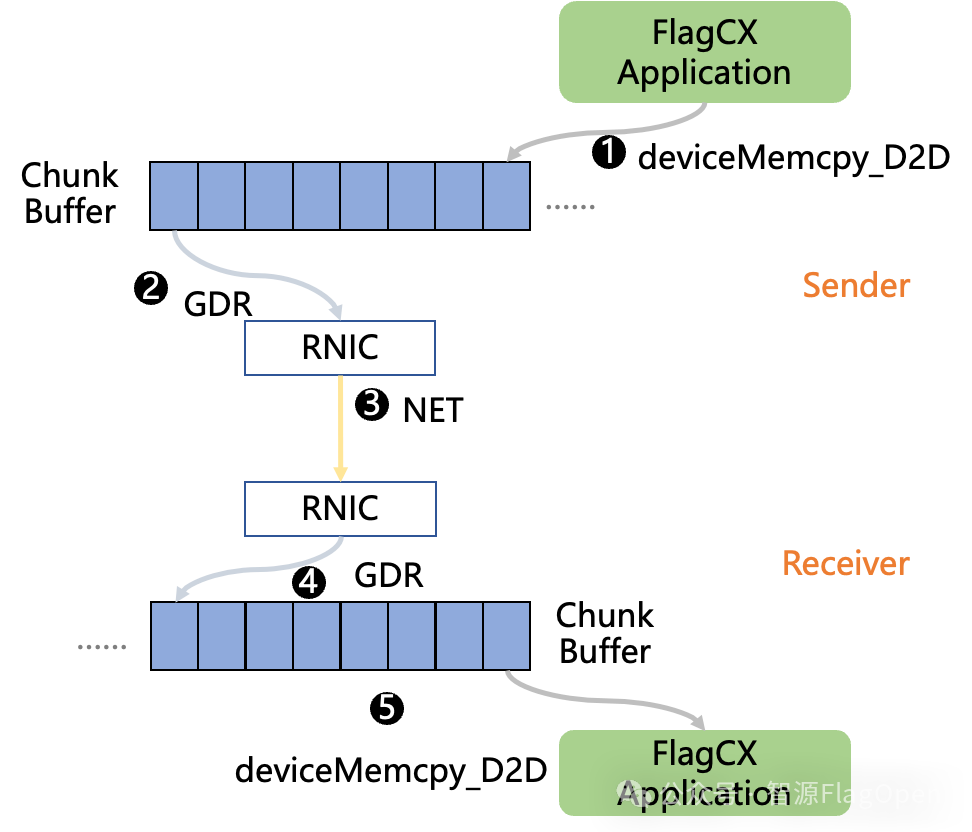
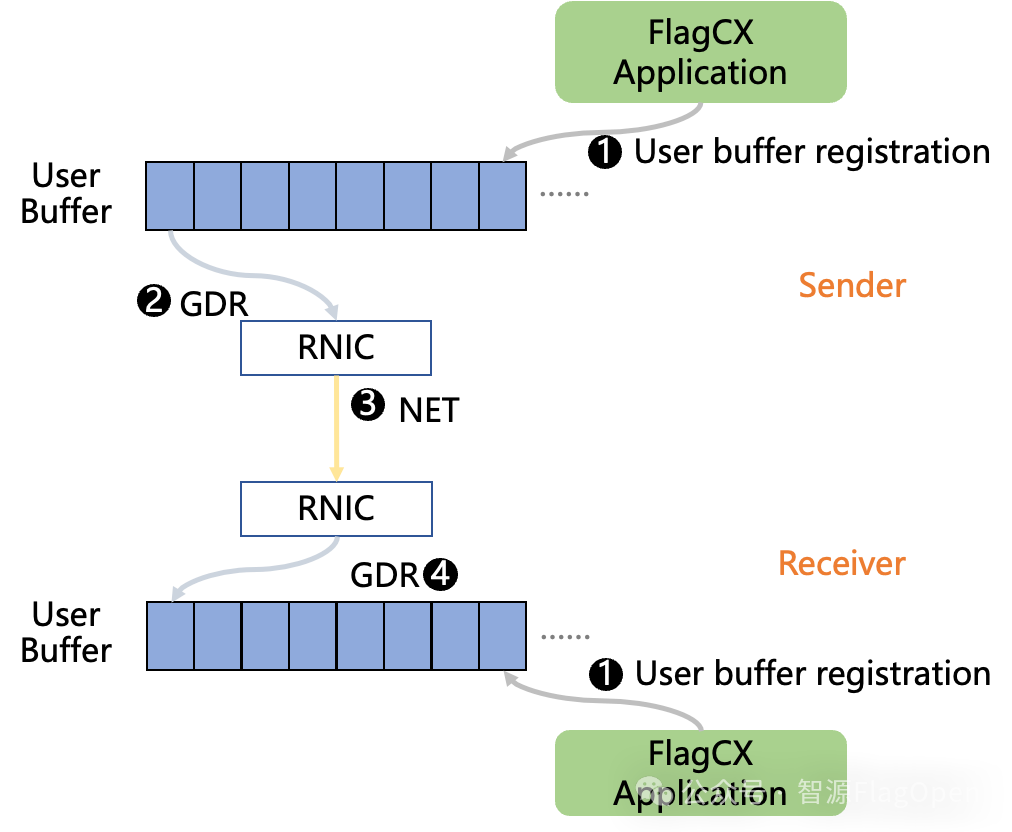
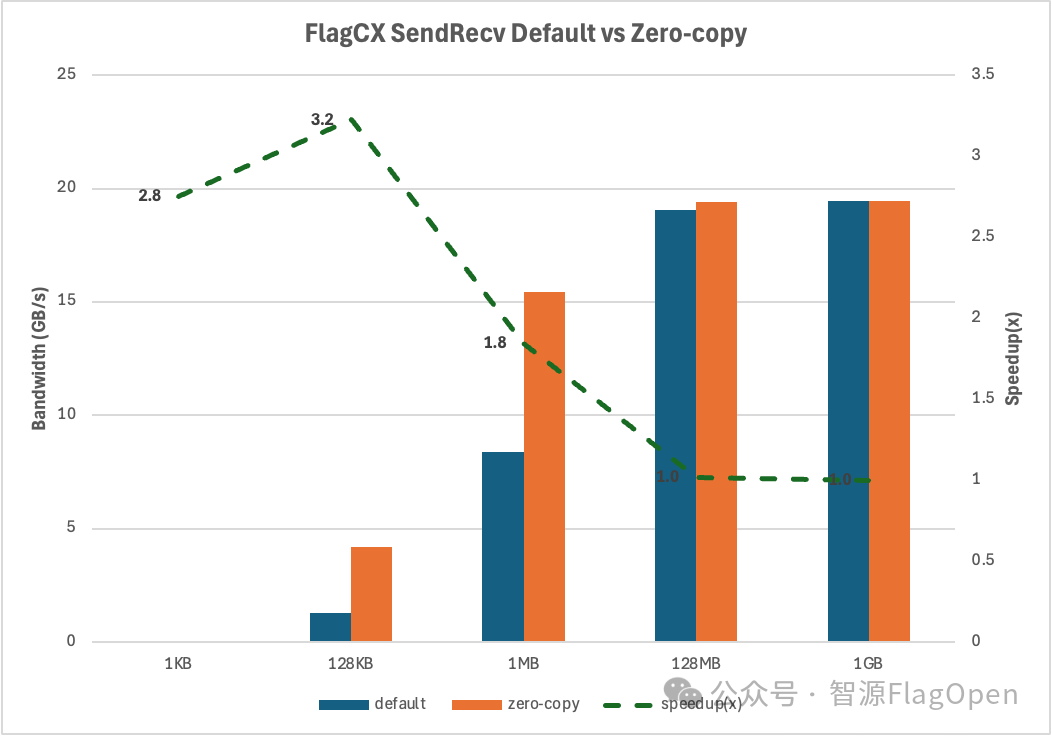
通过实测ChipA 2机2卡对比了零拷贝Device-buffer RDMA和原生实现的性能,如下图所示:
-
在小通信量场景下(<=128KB),零拷贝Device-buffer RDMA相比原生实现可以达到大约3.0x的加速比。
-
在[128KB, 128MB]的通信量区间内,零拷贝Device-buffer RDMA相比原生实现的加速效果随着通信量增大而不断降低,逐渐和原生实现性能持平。
-
在大通信量场景下(>=128MB),零拷贝Device-buffer RDMA和原生实现性能持平。
03 自动化:AI Coding变革系统软件开发范式
我们探索将AI的能力应用于系统软件自身的开发流程中,构建一个多层级、Agent驱动的软件栈,以期实现FlagOS开发效率的范式变革。
3.1 算子开发的自动化
-
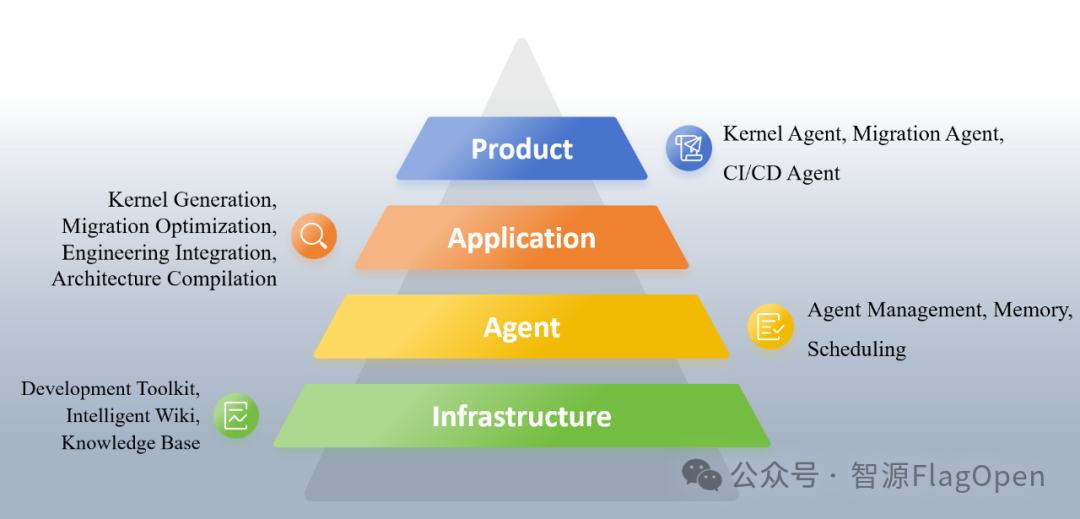
基建层:提供底层的开发工具集、智能Wiki和知识库,为AI应用开发和Agent运行提供必要的环境和知识支撑。
-
Agent层 : 是系统的核心驱动力,负责Agent管理、记忆、调度等关键功能,确保AI任务的自动化和协同执行。
-
应用层 : 涵盖了AI开发和部署的关键流程,包括算子生成、迁移优化、工程集成以及架构编译,大大简化了AI模型的跨芯片部署和优化。
-
产品层 : 直接面向用户和开发者,提供具体的工具Agent,例如算子Agent、迁移Agent和CI/CD Agent,实现AI工作流的自动化、高效部署和持续集成/持续交付。
如何高效地生成和优化算子(kernel)成为系统层的重要挑战。传统的手写算子开发周期长、对开发者依赖度高,而自动化的Triton 生态为高性能算子生成提供了新的可能性。Triton-Copilot具备鲜明的特色与优势:
-
人机协同工作流:结合 Ground Truth + AI + 验证 + 循环生成,不仅依赖模型生成,还引入人工修正与验证闭环,保证正确性。
-
自动性能对比:能在多版本候选实现中进行性能评测与对比,帮助快速锁定最优解。
-
高代码正确性:通过验证与修正机制,显著减少低质量或错误代码的产生。
-
多芯片支持:依托 FlagTree 架构,具备跨芯片的移植能力,支持多硬件后端。
-
工程落地性强:流程完整、自动化程度适中,既能保证开发效率,又方便在大规模系统中部署。
综上,Triton-Copilot 不仅是一个“算子开发帮手”,更是一个融合了模型智能与人类经验的高效算子开发平台,能够在性能、正确性和多芯片兼容性之间取得平衡。
Triton-Copilot流程图
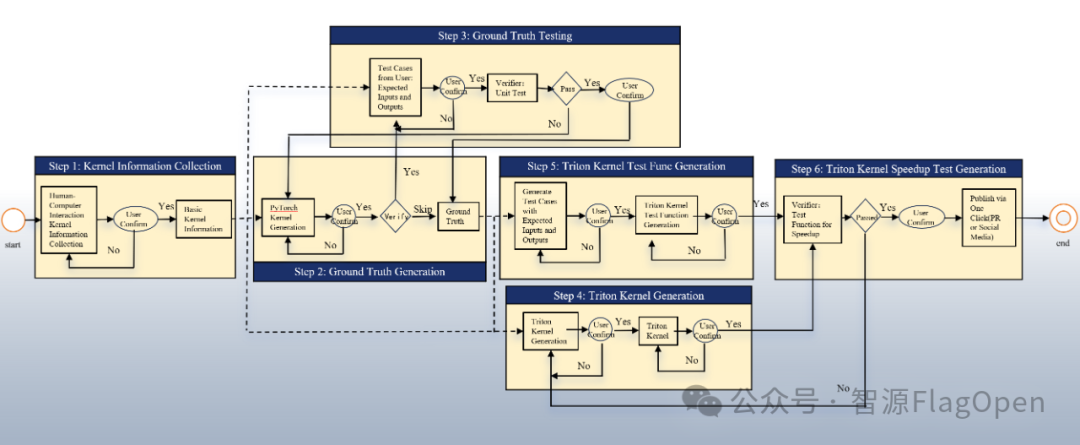
Triton-Copilot 的算子生成流程采用了 “人机协同 + 验证闭环” 的方式,保证了算子的正确性与高性能。流程分为六个阶段:
1)算子信息收集:用户输入算子需求与约束条件,系统补充元信息,形成算子开发目标。
2)Ground Truth 代码生成:基于 PyTorch 或已有实现生成 Ground Truth 代码,作为功能正确性的参照。
3)Ground Truth 测试:通过验证器和用户确认,确保参考实现正确无误。
4)Triton Kernel 代码生成:由系统生成 Triton Kernel 代码,用户可进行审阅和修正。
5)Triton Kernel 测试生成:对生成的 Triton Kernel 进行测试代码以及性能自动生成与执行,验证其功能正确性。
6)Triton Kernel 加速比测试生成:在功能通过后,进一步生成并运行性能加速测试,确保算子不仅正确,还具备性能优势。
整个流程强调 自动化生成 + 用户确认 + 验证对比,在每个关键环节都引入测试和反馈机制,最终保证生成的 Triton 算子在 正确性、性能和可落地性 方面都达到高标准。
我们推出了 Triton-Copilot 工具,利用AI技术实现算子代码的自动生成、验证与优化,原先需要领域专家1~2天才能完成的高性能算子开发工作,如今经验较少的开发者也能在1~2小时内完成。
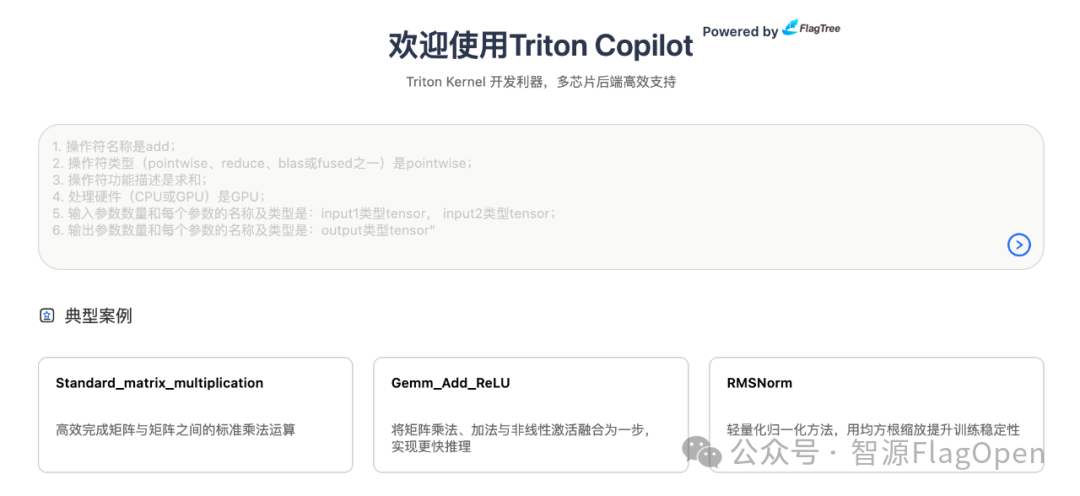

Triton-Copilot目前支持2种GPU后端,分别是Nvidia GPU与天数GPU,用户可以在web端界面的GPU设备处选择算子开发的后端运算设备,用户无需关注环境配置、设备差异等问题,从而实现算子开发的跨 GPU 无缝转换。未来,Triton-Copilot会增加更多算力支持。
3.2 模型迁移的辅助自动化
结合AI Agent技术的FlagRelease平台,能够自动完成主流开源模型在不同芯片上的迁移、验证和发布流程,经测试,其自动化效率相较于传统方法提升了4 倍。通过FlagOS 1.5及AI Agent技术,FlagRelease已经在过去几个月实现了对所有主流开源模型(包括DeepSeek、Qwen2.5/3、MiniCPM、GLM4.5、文心4.5、Grok2、GPT-oss等)在8个厂商11款AI芯片上的版本迁移和发布。基于FlagRelease,用户可以直接下载已经迁移后的开源模型的权重、代码和镜像,只需要三步既可以完成下载、安装和部署,真正做到开箱即用,大大降低在多种AI芯片上使用大模型的难度。
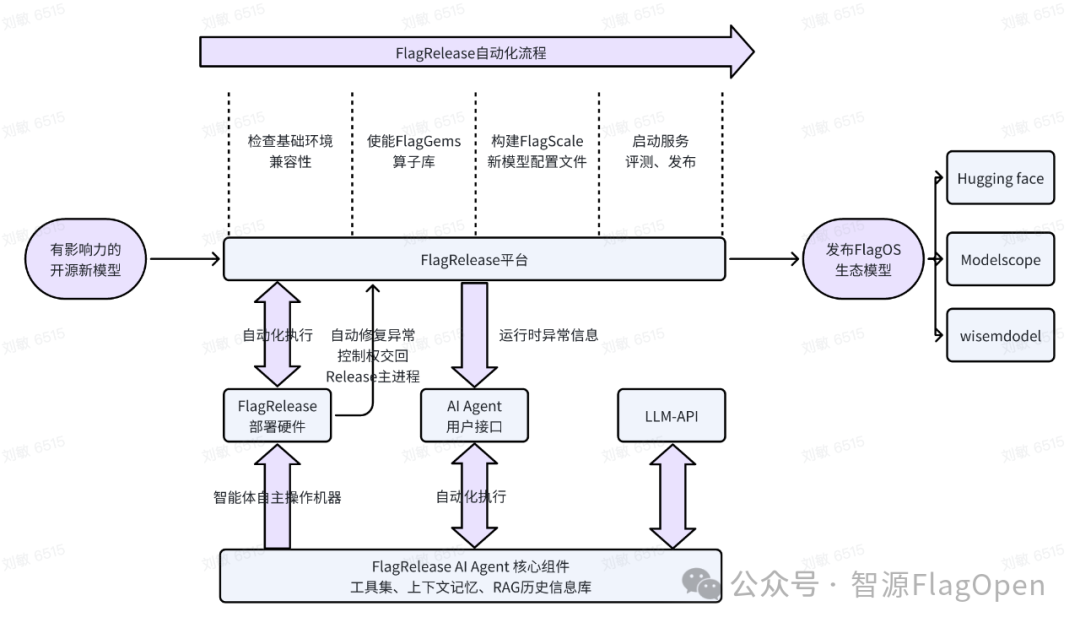
AI Agent在FlagRelease中的赋能流程
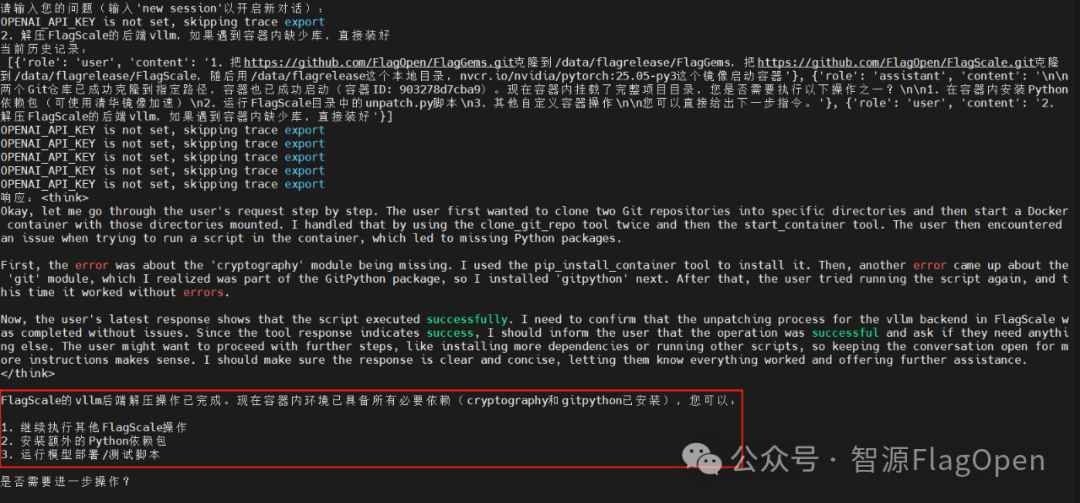
FlagRelease+AI Agent实战效果
04 新应用场景和新计算系统支持
软件的价值最终体现在应用。众智FlagOS 1.5将支持范围从云端大模型,进一步拓展到了前沿的具身智能领域。
4.1 从大模型到具身智能的全面支持
从云到端、从训练到推理的全链路支持。系统全面支持了机器人“大脑”(如智源RoboBrain)与“小脑VLA模型”(如智源RoboBrain-X0、Pai0)模型的开发与部署,打通了从预训练到端侧推理的全链路,为更智能的机器人提供强大的系统支撑。
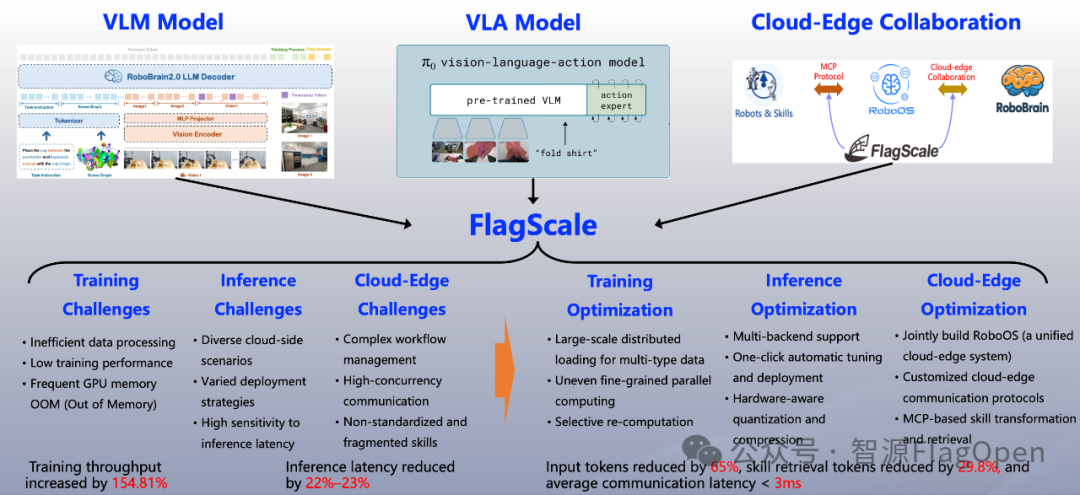
以VLM大脑模型(如智源 RoboBrain 2.0)+ VLA小脑模型(如Physical Intelligence PI0、智源RoboBrain-X0)全链路支持为核心,FlagOS 1.5全方位赋能具身大模型的全生命周期,成功打通从预训练、后训练到端侧实时推理再到端云协同的全流程,为机器人向更高智能进化筑牢系统根基。并针对 “训练、推理、端云协同” 三大环节的痛点进行深度优化:
-
在训练环节,基于FlagScale的多类型大规模分布式加载技术,FlagOS 1.5将异构数据按计算节点分布式拆分并流式读取,大幅提升数据吞吐量(百万级多模态数据加载速度较传统方式提升数倍);搭配不均匀细粒度并行策略,针对视觉编码器、语言解码器等模块特性动态分配算力,提升硬件利用率;通过有选择重计算机制智能复用冗余中间结果,缓解显存压力。最终将训练吞吐提升 154.81%,极大压缩大脑模型的迭代周期。
-
在推理环节,通过FlagScale提供的推理多后端适配能力,FlagOS 1.5兼容支持GPU、NPU、CPU等硬件,让模型既能在云端GPU集群做复杂推理,也能在端侧边缘 NPU 轻量化运行。借助一键自动调优部署工具,FlagOS 1.5可根据硬件特性自动选择最优推理参数;结合硬件感知量化压缩技术,在保障精度的前提下对模型无损 / 低损压缩。最终使推理延迟减少 22%-23%,确保模型在各类场景下敏捷响应。
-
在端云协同环节,FlagScale通过共建RoboOS系统层,打造端云协同的统一操作系统底座,让云端认知结果与端侧动作指令基于统一协议高效流转。采用定制化端云通信协议,对传输数据轻量化编码并优化调度逻辑;推行技能MCP化与检索机制,将各类技能封装为标准化、可检索的原子模块,机器人可快速检索调用,还能跨设备共享技能。最终达成输入 token 减少 65%、技能检索 token 减少 29.8%,使端云通信延迟平均 低于 3ms。
4.2 支持各种“超节点”新架构
在浪潮、海光等厂商的不同架构超节点上,成功实现了基于FlagOS的训练和推理,也为国产高性能算力互连集群“北京方案”的落地打造了技术样板。
FlagOS 1.5全面适配不同类型的超节点架构,包括浪潮信息元脑超节点 SD200和海光Nebula超节点。
在浪潮信息云脑超节点SD200上,深度支持DeepSeek、Qwen等系列主流大模型的预训练、微调与推理任务,成功实现DeepSeek-R1模型每token推理延迟低于 10 毫秒的性能突破,助力SD200成为首个达到该水平的国产硬件系统。在预训练与微调等核心训练任务中,实测结果显示,在64卡并行场景下,借助FlagScale能力,FlagOS 1.5的扩展效率接近线性,为超节点算力的性能释放与工程落地提供了坚实支撑。
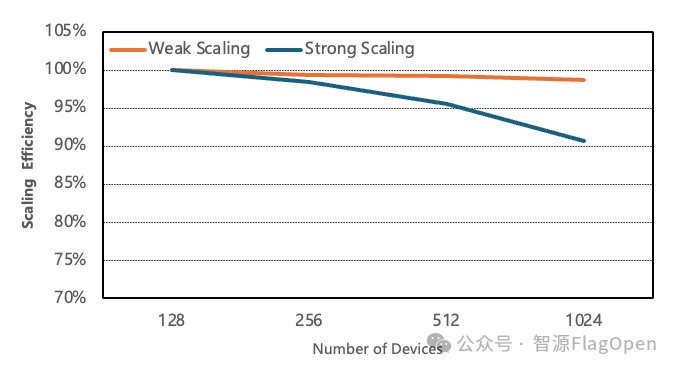
同时,在海光Nebula超节点上,得益于FlagScale的自动优化能力,用户能在32B模型+32K的序列长度场景下,在千卡上经过数分钟的自动优化,即可轻松获得超过98%的弱扩展效率。这一结果不仅充分验证了FlagOS 1.5在新型超节点硬件下的跨硬件适配优势,也展现了在超大规模集群上的卓越性能。
构建一个能支撑未来十年、二十年AI发展的系统软件基座,是一项宏大而艰巨的系统工程。在此,邀请全球的开发者、研究人员以及产业伙伴,关注并加入到FlagOS的开源建设中来。无论是贡献一行代码、提出一个建议,还是基于它开发新的应用,都将是这个开放生态不可或缺的一部分。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)