Python--OCR(1)
OCR 是“图像到文本的转化技术”,通过计算机视觉(CV)和自然语言处理(NLP)技术,将印刷体、手写体文字的图像(如照片、扫描件、截图)转换为可编辑的文本字符串。其核心价值是打破 “图像文字不可编辑” 的壁垒,实现文字信息的数字化、可检索和自动化处理。
一、“调用外部 OCR 服务的存根函数” 全解析
1. 核心概念拆解
- OCR(Optical Character Recognition,光学字符识别):指通过计算机技术将图像中的文字信息转换为可编辑的文本格式的技术,核心是让机器 “看懂” 图像中的文字。
- 外部 OCR 服务:由第三方机构(如阿里云、百度智能云、Google Cloud 等)提供的 OCR 功能接口,开发者通过 API 调用实现文字识别,无需自建 OCR 模型。
- 存根函数(Stub Function):一种简化的 “模拟函数”,用于模拟真实接口的行为(如输入输出格式、返回逻辑),但不执行实际业务操作。在调用外部服务时,存根函数可替代真实 API 调用,用于开发调试、测试或接口适配。
2. 存根函数的作用与场景
当开发需要集成外部 OCR 服务时,直接调用真实服务可能面临 网络依赖、调用限额、费用消耗、稳定性风险 等问题。存根函数的核心价值是 “模拟替代,解耦依赖”,具体场景包括:
- 开发阶段:无需实际调用外部服务,用存根函数返回预设结果(如模拟识别成功 / 失败的响应),快速验证业务逻辑。
- 测试阶段:通过存根函数模拟极端情况(如超时、识别错误、特殊字符),验证系统容错能力。
- 接口适配:在外部服务 API 文档明确但未实际接入时,用存根函数先适配接口格式,待服务就绪后无缝切换。
3. 存根函数与真实调用的区别
| 维度 | 存根函数(Stub) | 真实外部 OCR 服务调用 |
|---|---|---|
| 本质 | 本地模拟函数,无网络请求 | 远程 API 调用,依赖网络和外部服务状态 |
| 数据来源 | 预设的模拟结果(硬编码或配置文件) | 外部服务对真实图像的识别结果 |
| 用途 | 开发调试、单元测试、接口格式验证 | 生产环境实际文字识别 |
| 优势 | 无网络依赖、零成本、结果可控 | 识别结果真实准确,支持复杂场景 |
| 局限性 | 无法模拟真实识别效果,仅用于流程验证 | 依赖网络稳定性、受 API 限额 / 费用限制 |
4. 实现示例:外部 OCR 服务存根函数
以 Python 为例,假设调用百度 OCR 的 “通用文字识别” API,其真实接口要求传入图像 Base64 编码,返回识别的文字列表。存根函数可模拟这一过程:
代码:
import re
from typing import Dict, List, Optional
def stub_baidu_ocr(image_base64: str, app_id: str, api_key: str) -> Dict:
"""
模拟百度通用文字识别API的存根函数,用于开发和测试阶段
:param image_base64: 图像的Base64编码字符串,应符合Base64格式
:param app_id: 外部服务的应用ID,非空字符串
:param api_key: 外部服务的API密钥,非空字符串
:return: 模拟的OCR识别结果字典,与真实API格式一致
成功时包含识别到的文字内容,失败时包含错误信息
"""
# 1. 参数校验(模拟真实API的校验逻辑)
errors = []
# 校验app_id
if not app_id or not isinstance(app_id, str):
errors.append({"error": "app_id不能为空", "error_code": 100})
# 校验api_key
if not api_key or not isinstance(api_key, str):
errors.append({"error": "api_key不能为空", "error_code": 101})
# 校验image_base64格式
if not image_base64 or not isinstance(image_base64, str):
errors.append({"error": "image_base64不能为空", "error_code": 102})
else:
# 简单验证Base64格式(真实场景可能更复杂)
base64_pattern = re.compile(r'^[A-Za-z0-9+/=]+$')
# 移除可能的data URI前缀
if 'base64,' in image_base64:
base64_data = image_base64.split('base64,')[1]
else:
base64_data = image_base64
if not base64_pattern.match(base64_data):
errors.append({"error": "image_base64格式不正确", "error_code": 103})
# 如果有错误,返回第一个错误
if errors:
return {
"error": errors[0]["error"],
"error_code": errors[0]["error_code"],
"results": [],
"log_id": f"error_{errors[0]['error_code']}_{hash(image_base64)}"
}
# 2. 模拟不同场景的识别结果
# 根据图像内容的不同模拟不同结果(通过base64的哈希值来决定)
image_hash = hash(image_base64)
# 场景1: 空白图像(10%概率)
if image_hash % 10 == 0:
return {
"log_id": f"stub_{abs(image_hash)}",
"words_result_num": 0,
"words_result": [],
"error_code": 0,
"error_msg": "success"
}
# 场景2: 包含英文文本(30%概率)
elif image_hash % 10 in [1, 2, 3]:
return {
"log_id": f"stub_{abs(image_hash)}",
"words_result_num": 3,
"words_result": [
{"words": "Hello, World!"},
{"words": "This is a test document."},
{"words": "OCR recognition works well."}
],
"error_code": 0,
"error_msg": "success"
}
# 场景3: 包含中文文本(30%概率)
elif image_hash % 10 in [4, 5, 6]:
return {
"log_id": f"stub_{abs(image_hash)}",
"words_result_num": 2,
"words_result": [
{"words": "这是一个测试文档"},
{"words": "百度OCR识别效果很好"}
],
"error_code": 0,
"error_msg": "success"
}
# 场景4: 包含混合文本和数字(20%概率)
elif image_hash % 10 in [7, 8]:
return {
"log_id": f"stub_{abs(image_hash)}",
"words_result_num": 4,
"words_result": [
{"words": "订单编号: #20230518001"},
{"words": "产品名称: 智能手表"},
{"words": "数量: 2 个"},
{"words": "总价: ¥599.00"}
],
"error_code": 0,
"error_msg": "success"
}
# 场景5: 模拟API调用失败(10%概率)
else:
return {
"log_id": f"stub_{abs(image_hash)}",
"error": "服务器内部错误",
"error_code": 500,
"results": []
}
def extract_text_from_ocr_result(ocr_result: Dict) -> Optional[List[str]]:
"""
从OCR识别结果中提取文字内容
:param ocr_result: OCR识别结果字典
:return: 提取的文字列表,如果识别失败则返回None
"""
if not ocr_result or not isinstance(ocr_result, dict):
return None
# 检查是否有错误
if ocr_result.get("error_code", 0) != 0:
print(f"OCR识别失败: {ocr_result.get('error', '未知错误')}")
return None
# 提取文字内容
return [item.get("words", "") for item in ocr_result.get("words_result", [])]
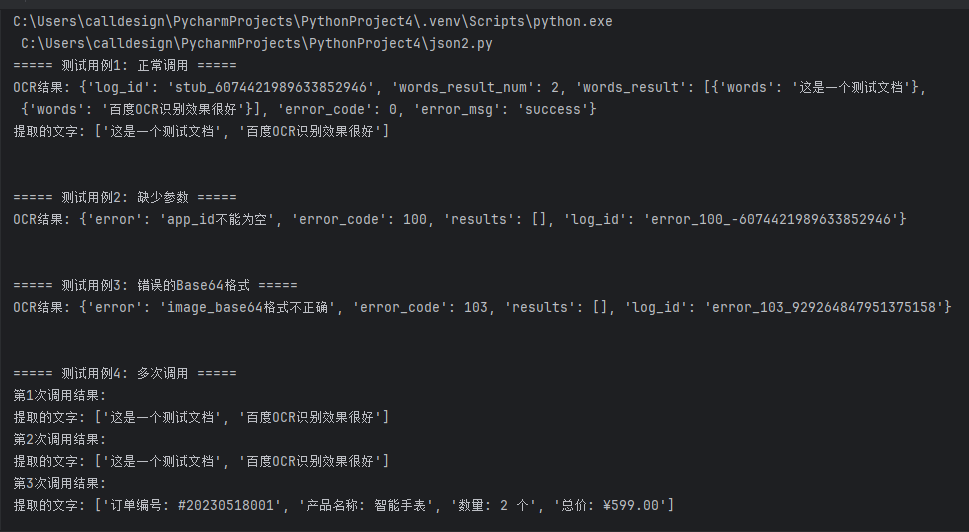
if __name__ == "__main__":
# 测试用例1: 正常调用(带data URI前缀)
print("===== 测试用例1: 正常调用 =====")
test_image_1 = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mNk+P+/HgAFeAJ5gMmAAAAABJRU5ErkJggg=="
result_1 = stub_baidu_ocr(
image_base64=test_image_1,
app_id="test_app_123",
api_key="test_key_456"
)
print("OCR结果:", result_1)
extracted_text_1 = extract_text_from_ocr_result(result_1)
print("提取的文字:", extracted_text_1)
print("\n")
# 测试用例2: 缺少参数
print("===== 测试用例2: 缺少参数 =====")
result_2 = stub_baidu_ocr(
image_base64=test_image_1,
app_id="", # 空app_id
api_key="test_key_456"
)
print("OCR结果:", result_2)
print("\n")
# 测试用例3: 错误的Base64格式
print("===== 测试用例3: 错误的Base64格式 =====")
result_3 = stub_baidu_ocr(
image_base64="invalid_base64_content", # 无效的Base64
app_id="test_app_123",
api_key="test_key_456"
)
print("OCR结果:", result_3)
print("\n")
# 测试用例4: 多次调用查看不同结果
print("===== 测试用例4: 多次调用 =====")
test_image_4 = "data:image/jpg;base64,ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/="
for i in range(3):
print(f"第{i + 1}次调用结果:")
result = stub_baidu_ocr(
image_base64=test_image_4 + str(i), # 每次略有不同
app_id="test_app_123",
api_key="test_key_456"
)
print("提取的文字:", extract_text_from_ocr_result(result))
运行结果:
二、OCR 技术全解析(权威版)
1. OCR 核心定义与价值
OCR 是 “图像到文本的转化技术”,通过计算机视觉(CV)和自然语言处理(NLP)技术,将印刷体、手写体文字的图像(如照片、扫描件、截图)转换为可编辑的文本字符串。其核心价值是 打破 “图像文字不可编辑” 的壁垒,实现文字信息的数字化、可检索和自动化处理。
2. OCR 技术核心流程
OCR 识别全流程可分为 5 个关键步骤,存根函数通常模拟的是最终 “返回识别结果” 的环节:
| 步骤 | 核心作用 | 技术难点 |
|---|---|---|
| 1. 图像输入 | 获取待识别的图像(支持 JPG、PNG、PDF 等格式) | 图像质量检测(模糊、倾斜、低对比度) |
| 2. 预处理 | 优化图像质量,降低识别难度 | 去噪、倾斜校正、文字区域分割(ROI 提取) |
| 3. 文字检测(Detection) | 定位图像中的文字区域(如行、单词、字符) | 复杂背景下的文字定位(如验证码、艺术字) |
| 4. 文字识别(Recognition) | 将图像中的文字区域转换为文本字符 | 字体多样性、模糊文字、手写体识别 |
| 5. 后处理 | 优化识别结果(纠错、格式规整) | 上下文语义纠错、排版还原(如表格、公式) |
3. OCR 主流技术路线
随着 AI 技术发展,OCR 已从传统的 “基于规则” 演进为 “深度学习主导”,主流技术路线包括:
- 传统技术(已淘汰):基于模板匹配、特征工程(如边缘检测、轮廓分析),仅适用于固定字体和简单场景。
- 深度学习技术(当前主流):
- 检测阶段:用 CNN(卷积神经网络)或目标检测模型(如 YOLO、Faster R-CNN)定位文字区域。
- 识别阶段:用 “CNN+RNN+CTC” 或 Transformer 模型(如 Vision Transformer)将图像特征转换为文字序列。
- 优势:支持多字体、复杂背景、模糊图像,手写体识别准确率大幅提升。
4. 外部 OCR 服务的核心能力
第三方外部 OCR 服务(如百度、阿里、Google)通常封装了上述技术,提供开箱即用的 API,核心能力包括:
- 通用文字识别:识别印刷体文字(支持多语言)。
- 专项场景识别:身份证 / OCR、发票识别、车牌识别、手写体识别、表格识别等。
- 高级功能:图文排版还原、PDF 转文字、多模态识别(结合图像语义)。
5. 存根函数在 OCR 集成中的关键价值
在集成外部 OCR 服务时,存根函数是 “降低开发成本、提升稳定性” 的关键工具:
- 隔离外部依赖:开发时无需等待外部服务就绪,用存根函数即可验证 “图像上传→调用 OCR→解析结果” 的全流程。
- 模拟极端场景:通过存根函数返回 “超时响应”“识别错误”“空结果” 等,测试系统的容错逻辑(如重试机制、降级策略)。
- 节省资源成本:避免开发阶段因频繁调用外部 API 产生的费用(部分服务按调用次数收费)或触发限流。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)