$\mathbf{T}^{2}$-RAGBench: 用于评估检索增强生成的文本与表格基准
本文提出$\mathbf{T}^{2}$-RAGBench基准数据集,包含32,908个金融领域问题-上下文-答案三元组,用于评估检索增强生成(RAG)系统处理文本和表格混合数据的能力。不同于现有问答数据集依赖已知上下文,该基准要求模型先检索正确上下文再进行数值推理。作者将上下文依赖问题转换为独立格式,并全面评估主流RAG方法,发现混合BM25方法表现最佳。实验表明,即使最先进方法在该基准上仍具挑
Jan Strich 1 , 2 { }^{1,2} 1,2, Enes Kutay Isgorur 3 { }^{3} 3, Maximilian Trescher 3 { }^{3} 3, Chris Biemann 1 , 2 { }^{1,2} 1,2, Martin Semmann 1 , 2 { }^{1,2} 1,2
1 { }^{1} 1 汉堡大学语言技术组,德国
2 { }^{2} 2 汉堡大学HCDS组,德国
3 { }^{3} 3 dida Datenschmiede GmbH公司
通讯作者:jan.strich@uni-hamburg.de
摘要
尽管大多数金融文件都包含文本和表格信息的组合,但稳健的检索增强生成(RAG)系统对于有效访问和推理此类内容以执行复杂的数值任务至关重要。本文介绍了 T 2 \mathbf{T}^{2} T2-RAGBench,一个包含32,908个问题-上下文-答案三元组的基准数据集,旨在评估真实世界金融数据上的RAG方法。与典型的问答数据集在Oracle-context设置下操作不同,在这种设置中相关上下文是显式提供的, T 2 \mathrm{T}^{2} T2 RAGBench挑战模型首先检索正确的上下文,然后进行数值推理。现有的涉及文本和表格的问题通常包含依赖于上下文的问题,这些问题可能根据提供的上下文产生多个正确答案。为了解决这个问题,我们将这些数据集转换成独立于上下文的格式,从而实现可靠的RAG评估。我们对流行的RAG方法进行了全面评估。我们的分析确定了Hybrid BM25,这是一种结合密集和稀疏向量的技术,是处理文本和表格数据最有效的方法。然而,结果表明即使对于最先进的LLM和RAG方法, T 2 \mathrm{T}^{2} T2-RAGBench仍然具有挑战性。进一步的消融研究检查了嵌入模型和语料库大小对检索性能的影响。 T 2 \mathrm{T}^{2} T2-RAGBench为现有RAG方法在文本和表格数据上提供了一个现实且严格的基准。代码和数据集可在线获取 1 { }^{1} 1。
1 引言
包含文本和表格混合的文档广泛应用于各个领域,例如财务报告(Baviskar等,2021年),科学研究(Pramanick等,2024年)和组织文档(Rebman Jr等,2023年)。
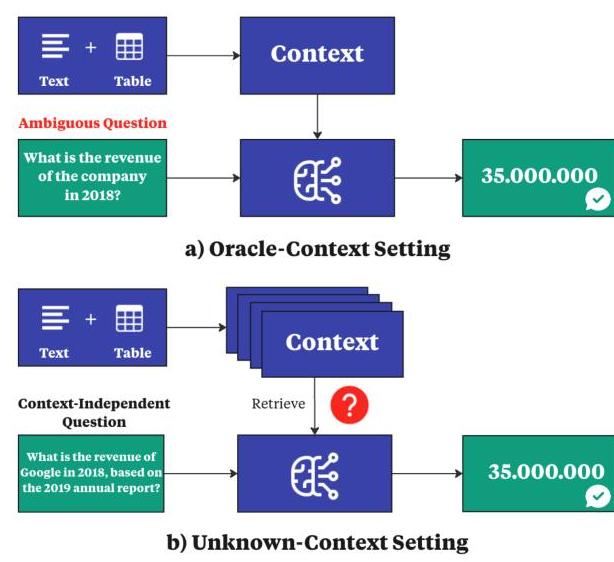
图1:当前最先进的方法概述。a) 大多数基准测试在Oracle-context设置下测试模型,(Zhu等,2021;Chen等,2021, 2022)。而我们的任务(b)针对未知上下文设置,要求从混合的文本和表格中检索后再回答。
最近大型语言模型(LLMs)的进步已经展示了在适当文档提供的情况下,回答数值和自由形式问答(QA)任务时表现出坚实的最先进(SOTA)性能(Nan等,2021;Chen等,2021, 2022;Zhu等,2021, 2022)。尽管LLMs的上下文窗口尺寸不断增加,由于计算约束和程序延迟,使用整个语料库仍然不切实际(Wang等,2024;Li等,2024)。因此,在现实应用中识别相关文档至关重要,因为回答问题所需的文档通常不是先验已知的,必须首先检索出来,如图1所示。
检索增强生成(RAG)(Lewis等,2020)已成为解决数值任务单跳问答的一种有前途的解决方案,提供了适当的上下文,并引发了该领域方法的大量涌现(Gao等,2023b;Nikishina等,2025)。虽然RAG在检索语义相似的文本方面很有效,但由于其结构复杂性和主要由数值组成的特点,嵌入表格数据仍然具有挑战性,缺乏语义背景(Khattab等,2022)。
然而,RAG方法的评估通常依赖于仅文本的数据集(Jiang等,2023;Lan等,2023;Wang等,2024),维基百科衍生的问答数据集(Pasupat和Liang,2015;Yang等,2018)在LLM预训练期间被广泛使用(Grattafiori等,2024),或特定领域的数据集(Sarthi等,2024;Yan等,2024),其中没有适合评估文本表格文档性能的数据集。现有的同时包含两者的数据集局限于oraclecontext设置,因为它们主要包含依赖于上下文的问题,这些问题根据上下文的不同会有多个正确答案,这限制了它们在评估RAG方面的有效性。
为了填补这一空白,我们提出了文本-表格检索增强生成基准(T²RAGBench),一个旨在评估RAG方法在文本表格检索和数值推理任务上的基准。我们的基准包括从现有数据集中提取的四个子集,总计32,908个问题-上下文-答案三元组(QCA)和9,095个真实世界的金融文档。每个三元组包括一个重新表述的、明确的问题,需要文本和表格信息,一个经过验证的答案,以及包含回答问题所需所有信息的相关上下文。我们将任务定义为检索和数值推理的组合,详见第3节。
我们的贡献如下:
- 我们引入了 T 2 \mathbf{T}^{2} T2-RAGBench,一个包含32,908个QCA三元组的基准数据集,来自设计用于评估RAG方法在文本和表格及数值推理上的财务报告。
-
- 我们在 T 2 \mathbf{T}^{2} T2-RAGBench上系统地评估了流行的RAG方法,证明它仍然是当前方法的一个具有挑战性和相关的基准。
-
- 我们比较了最先进的闭源和开源嵌入模型,并分析了语料库大小对有希望的RAG方法的影响。
2 相关工作
- 我们比较了最先进的闭源和开源嵌入模型,并分析了语料库大小对有希望的RAG方法的影响。
本节回顾了现有的基准数据集(如表1所示),讨论了已知的局限性,并概述了最近关于文本和表格RAG方法的研究。
2.1 文本和表格问答数据集
在常见的知识(Joshi等,2017;Chen等,2020;Nan等,2021)、金融文件(Chen等,2021,2022;Zhu等,2021)、学术论文(Dasigi等,2021;Pramanick等,2024)和其他专业领域(Katsis等,2022;Ding等,2023)等领域,已经引入了执行文本表格问答的数据集。
虽然大多数数据集最初主要关注表格(Nan等,2021;Katsis等,2022;Raja等,2023),将文本与表格结合起来对于有效地解析整个PDF文档变得至关重要。常见的知识问答数据集(Joshi等,2017;Nan等,2021)通常依赖维基百科内容;然而,这对RAG评估来说不太有用,因为预训练的LLMs已经在维基百科数据上进行了训练(Grattafiori等,2024),使得很难单独衡量检索器和生成器的性能。
在金融领域,FinQA(Chen等,2021)、ConvFinQA(Chen等,2022)和TAT-DQA(Zhu等,2022)都包含了来自财务报告的文本和表格数据。不过,这些数据集大多包含模糊的、依赖于上下文的问题。FinDER(Choi等,2025)声称解决了这个问题,但尚未公开。TableBench(Wu等,2025)提供了适用于多个领域的表格问答,适合在oracle-context设置下评估LLM性能。同样,UDA基准(Hui等,2024)整合了多个数据集,但两者仍面临依赖于上下文的限制。T²-RAGBench通过提供一个专注于文本和表格数据的基准来弥补这一差距,不依赖图像,并且只包含无歧义的问题。
2.2 文本和表格上的RAG
RAG在文本上有前景(Lewis等,2020),但在文本和表格上的评估有限。THoRR(Kim等,2024)通过基于标题的检索简化表格,补充了ERATTA(Roychowdhury等,2024),后者使用模块化提示和SQL进行企业数据处理。FinTextQA(Chen等,2024)评估完整的RAG流水线。FinTMMBench(Zhu等,2025)通过密集/图检索增加了多模态和时间RAG。Robust RAG(Joshi等,2024)通过基于图像的VLLMs连接文本、表格和视觉效果,尽管不如文本方法灵活。尽管取得了进展,但大多数作品(Asai等,2024;Gao等,2023a,b)只测试了几种RAG基线,限制了其通用性。
| 数据集 | 领域 | 文本 | 表格 | 视觉独立性 | 上下文独立性 | 可用性 | 问答对 |
|---|---|---|---|---|---|---|---|
| TriviaQA (Joshi et al., 2017) | 维基百科 | ✓ \checkmark ✓ | x \boldsymbol{x} x | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 650 K |
| HybridQA (Chen et al., 2020) | 维基百科 | x \boldsymbol{x} x | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 70 K |
| FeTaQA (Nan et al., 2021) | 维基百科 | x \boldsymbol{x} x | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 10 K |
| Qasper (Dasigi et al., 2021) | NLP 论文 | x \boldsymbol{x} x | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | ✓ \checkmark ✓ | 5 K |
| SPIQA (Pramanick et al., 2024) | NLP 论文 | x \boldsymbol{x} x | ✓ \checkmark ✓ | x \boldsymbol{x} x | x \boldsymbol{x} x | ✓ \checkmark ✓ | 270 K |
| FinQA (Chen et al., 2021) | 金融 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | ✓ \checkmark ✓ | 8 K |
| ConvFinQA (Chen et al., 2022) | 金融 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | ✓ \checkmark ✓ | 14 K |
| TAT-DQA (Zhu et al., 2022) | 金融 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | ✓ \checkmark ✓ | 16 k |
| VQAonBD (Raja et al., 2023) | 金融 | x \boldsymbol{x} x | ✓ \checkmark ✓ | x \boldsymbol{x} x | x \boldsymbol{x} x | ✓ \checkmark ✓ | 1,531 K |
| FinDER (Choi et al., 2025) | 金融 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | 50 K |
| DocVQA (Tito et al., 2021) | 多领域 | x \boldsymbol{x} x | ✓ \checkmark ✓ | x \boldsymbol{x} x | x \boldsymbol{x} x | ✓ \checkmark ✓ | 50 K |
| TableBench (Wu et al., 2025) | 多领域 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | x \boldsymbol{x} x | ✓ \checkmark ✓ | ∼ 1 K \sim 1 \mathrm{~K} ∼1 K |
| UDA (Hui et al., 2024) | 多领域 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | x \boldsymbol{x} x | ✓ \checkmark ✓ | 30 K |
| T- RAGBench (Ours) | 金融 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 32 K |
表1:问答数据集的总结和比较。视觉独立性:上下文以文本形式呈现,不仅仅是图片。上下文独立性:没有上下文,问题只有一个明确的答案。
3 任务定义
为了澄清我们的基准所要解决的任务,我们定义了以下问题。
问题公式化。该基准评估检索函数 f f f 和推理模型 M M M,以优化未知上下文文本和表格问答中的答案准确性和效率。我们将用户的问题表示为 Q Q Q,相应的地面实况答案表示为 A A A。证据来自两种模式:一段文本内容和一个结构化的表格,我们将其视为一个单一的上下文实体,记作 C C C。因此,我们的整个上下文语料库定义为 C = { C i } \mathcal{C}=\left\{C_{i}\right\} C={Ci}。任务分为两个阶段:
检索:一个函数
f : C × Q ↦ [ C k ∗ ] k = 1 n f: \mathcal{C} \times Q \mapsto\left[C_{k}^{*}\right]_{k=1}^{n} f:C×Q↦[Ck∗]k=1n
从语料库 C \mathcal{C} C 中选择与给定问题 Q Q Q 最相关的前 n 个上下文实体。
答案提取:一个语言模型
M : ( [ C k ∗ ] k = 1 n , Q ) ↦ A ∗ M:\left(\left[C_{k}^{*}\right]_{k=1}^{n}, Q\right) \mapsto A^{*} M:([Ck∗]k=1n,Q)↦A∗
通过推理检索到的文本和表格生成答案 A ∗ A^{*} A∗。
数字匹配:数值推理使用一个新的度量标准进行评估。它允许微小的偏差和单位尺度变化。令 A ∗ A^{*} A∗ 和 A A A 分别为预测答案和地面实况答案,并将其绝对值记为 a ∗ = ∣ A ∗ ∣ a^{*}=\left|A^{*}\right| a∗=∣A∗∣ 和 a = ∣ A ∣ a=|A| a=∣A∣。
给定一个容错阈值 ε > 0 \varepsilon>0 ε>0,如果 a ∗ < ε a^{*}<\varepsilon a∗<ε 且 a < ε a<\varepsilon a<ε,或者 ∣ q − 1 ∣ < ε |q-1|<\varepsilon ∣q−1∣<ε 其中
q = a ∗ a ⋅ 1 0 − round ( log 10 ( a ∗ / a ) ) q=\frac{a^{*}}{a} \cdot 10^{-\operatorname{round}\left(\log _{10}\left(a^{*} / a\right)\right)} q=aa∗⋅10−round(log10(a∗/a))
这里,round 表示四舍五入到最接近的整数。这个度量确保了对舍入误差和数量级缩放的鲁棒性。
检索指标。让
D = { ( Q i , A i , C i ) } i = 1 N \mathcal{D}=\left\{\left(Q_{i}, A_{i}, C_{i}\right)\right\}_{i=1}^{N} D={(Qi,Ai,Ci)}i=1N
代表我们的数据集,其中每个元组 ( Q i , A i , C i ) \left(Q_{i}, A_{i}, C_{i}\right) (Qi,Ai,Ci) 包括一个问题 Q i Q_{i} Qi,其唯一的地面实况答案 A i A_{i} Ai,以及相应的唯一地面实况上下文 C i C_{i} Ci。定义检索输出:
R i = f ( C , Q i ) = [ C i , 1 ∗ , C i , 2 ∗ , … , C i , n ∗ ] R_{i}=f\left(\mathcal{C}, Q_{i}\right)=\left[C_{i, 1}^{*}, C_{i, 2}^{*}, \ldots, C_{i, n}^{*}\right] Ri=f(C,Qi)=[Ci,1∗,Ci,2∗,…,Ci,n∗]
真实排名由
r i = min { k ∣ C i , k ∗ = C i } r_{i}=\min \left\{k \mid C_{i, k}^{*}=C_{i}\right\} ri=min{k∣Ci,k∗=Ci}
给出
我们考虑的是平均倒数排名在 k k k(MRR@k),它关注前 k k k 个检索到的上下文的相关性。它定义为
MRR @ k = 1 N ∑ i = 1 N 1 r i ⋅ I ( r i ≤ k ) \operatorname{MRR} @ k=\frac{1}{N} \sum_{i=1}^{N} \frac{1}{r_{i}} \cdot \mathbb{I}\left(r_{i} \leq k\right) MRR@k=N1i=1∑Nri1⋅I(ri≤k)
其中 I ( ⋅ ) \mathbb{I}(\cdot) I(⋅) 是指示函数,当条件满足时(即 r i ≤ k r_{i} \leq k ri≤k)取值为1,否则为0。
| 子集 | 领域 | PDF 来源 | #文档 | #问答对 | 平均问题标记数 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 原始 | 提取 | 平均标记 | 原始 | 生成 | 原始 | 生成 | |||
| FinQA | 金融 | FinTabNet | 2,789 | 2,789 | 950.4 | 8,281 | 8,281 | 21.1 | 39.2 |
| ConvFinQA | 金融 | FinTabNet | 2,066 | 1,806 | 890.9 | 14,115 | 3,458 | 17.8 | 30.9 |
| VQAonBD | 金融 | FinTabNet | 48,895 | 1,777 | 460.3 | 1,531,455 | 9,820 | 45.3 | 43.5 |
| TAT-DQA | 金融 | TAT-DQA | 2,758 | 2,723 | 915.3 | 16,558 | 11,349 | 17.8 | 31.7 |
| 总计 | 金融 | 多来源 | 56,508 | 9,095 | 785.8 | 1,570,409 | 32,908 | 26.8 | 37.0 |
表2:原始和生成的问答对、文档以及T2 2 { }^{2} 2-RAGBench子集的平均问题和上下文长度的比较。FinQA (Chen et al., 2021), ConvFinQA (Chen et al., 2022), 和 VQAonBD (Raja et al., 2023) 使用 FinTabNet (Zheng et al., 2020) 作为PDF来源,而 TAT-DQA (Zhu et al., 2022) 使用自己的数据集。平均标记数基于 Llama 3.3 标记器。
4 T²-RAGBench
为了构建一个适合RAG评估的文本-表格数据基准,我们首先调查了现有的数据集,如表1所示。由于没有一个完全符合我们的标准,我们选择了高质量的数据集并对其进行了重构,以适应我们基准的要求。具体来说,我们选择了FinQA (Chen et al., 2021),ConvFinQA (Chen et al., 2022),和TAT-DQA (Zhu et al., 2022),这些数据集主要缺乏上下文无关的问题。为了补充这些数据集,我们包含了一个过滤后的VQAonBD (Raja et al., 2023)子集,该子集仅包含表格数据,使我们能够分析缺失文本上下文对检索的影响。
对于所有选定的数据集,我们应用了定制的预处理步骤,并使用Llama 3.3-70B 2 { }^{2} 2重新表述问题,以确保上下文无关性。一个问题被认为是上下文无关的,如果它恰好有一个正确的答案,即使没有访问 C \mathcal{C} C也是如此。每个基准样本是一个三元组 ( Q , A , C ) (Q, A, C) (Q,A,C),其中 Q Q Q是一个问题, A A A是答案, C C C是由文本和表格组成的上下文。由于这些三元组来源于Oracle-context设置,我们假设所有回答 Q Q Q所需的信息都完全包含在 C C C中,并且仅在 C C C中。
表2详细列出了T2 2 { }^{2} 2-RAGBench的四个子集。虽然FinQA、ConvFinQA和VQAonBD基于FinTabNet,但TAT-DQA依赖于自己的来源。这些子集包含1,777至2,789个文档,每个包含3,458至11,349个问答对。
4.1 数据准备
所有子集都需要定制的预处理步骤,以符合我们基准的要求。FinQA是一个基于FinTabNet财务报告的数值问答数据集。我们在公司元数据的基础上标准化了所有答案格式。
元数据并标准化所有答案格式。ConvFinQA通过添加多轮问题扩展了FinQA。我们仅筛选了第一轮问题,并统一了答案格式。VQAonBD完全由表格问题组成,最初源于表格图像;我们将图像表格映射回其原始PDF,并筛选数据集以保留最难的类别。TAT-DQA是一个独立的数据集,包含多种答案类型。我们筛选后仅保留数值问题,并标准化答案格式。完整细节见附录A。
4.2 数据创建
在准备完所有问答数据集后,进行了上下文无关数据集的创建。首先,使用LLM重新表述问题,然后进行定量和定性分析,以确保重新表述的结果形成一个有用的基准。
问题重述。为了公平评估RAG方法,现有的依赖上下文的问题被重新表述为独立于上下文的问题,然而,这些重新表述的问题保留了相同的事实答案。对于32,908个样本中的每一个,使用Llama 3.3-70B 2 { }^{2} 2(温度=0.7)生成了一个新问题。生成过程通过结合元信息(如公司名称、行业和报告年份)进行,这些信息未包含在原始文档中。具体的提示模板见附录B。
定量分析。为了验证重新表述的问题是否保持事实正确,我们使用Llama 3.3-70B 2 { }^{2} 2和Oracle-Context对所有子集的原始问题和重新表述的问题进行了定量比较,如图2所示。由于上下文是给定的,
2 { }^{2} 2 kosbu/Llama-3.3-70B-Instruct-AWQ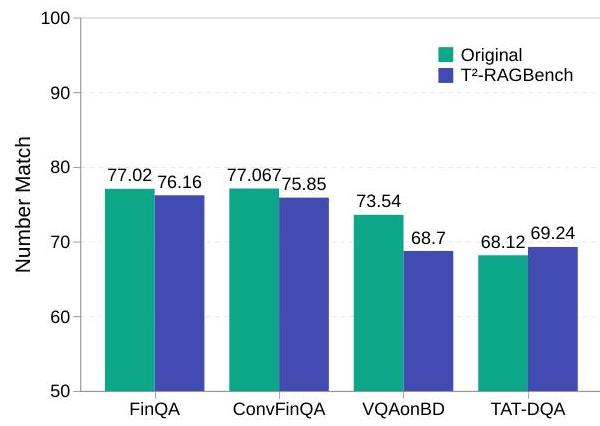
图2:我们新基准中每个子集(FinQA, ConvFinQA, VQAonBD, TAT-DQA)的原始问题与重新表述问题之间的Number Match比较。
MRR显然为100,所以仅使用Number Match作为比较指标。原始问题和生成问题之间的准确性显示出最小的偏差,所有情况下的差异均低于5%。这表明重新表述的问题保留了数值推理所需的基本信息,因为在重新表述之后,LLM仍然能够回答问题。同时,通过明确指定实体(公司名称和行业)和时间段(报告年份),问题现在变得上下文无关。
人工验证。 在进行定量分析后,结果显示LLM在Oracle-context下仍能回答问题,我们进一步调查了数据集的质量。因此,每个子集随机抽取100个QA对,通过自定义注释工具手动标注(附录C)。四位财务专家每人标注了两个不同子集的200个样本,评估原始问题是上下文相关还是上下文无关。计算Cohen’s Kappa以评估评分者间的一致性,总体值为0.58,表明一致性显著。结果如图3所示。
分析显示,原始数据集中只有7.3%的问题是上下文无关的,而在重新表述版本中达到了83.9%。这确保了大部分新创建的QCA三元组适合RAG评估,并且由于以下评估分析仅考虑方法间的相对性能差异,未满足假设的比例可以忽略不计。
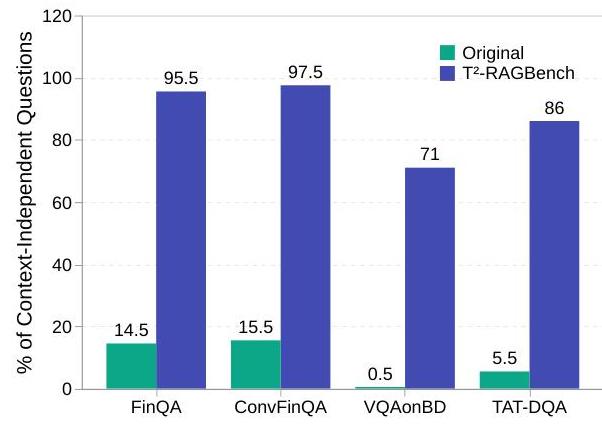
图3:每个子集(FinQA, ConvFinQA, VQAonBD, TAT-DQA)中100个随机选择的问题在原始问题与生成问题之间的人类一致性。
4.3 数据统计
表2展示了数据集的概览。它包含9,095个真实世界的文档,平均长度为785.8个标记。除VQAonBD外的所有子集平均每文档约900个标记;VQAonBD较短,因为它缺少周围文本,仅包含表格数据。
总的来说,T²-RAGBench由超过150万个问题中提取的32,908个问答对组成。平均问题标记数在重新表述后增加了大约10个标记,约为38%。这反映了附加语义信息的包含,如公司名称或报告年份,这使得RAG评估成为可能。FinQA、ConvFinQA和TAT-DQA中的重新表述问题一致更长,使其上下文无关。VQAonBD中由于原始问题中的冗余表格相关细节导致标记长度匹配。尽管进行了这些调整,数据集保留了其原始结构,保持了其评估数值推理和RAG方法的适用性。数据集样本可在附录D中找到。
5 评估
为了展示我们基准在评估RAG方法方面的适用性,我们使用以下模型和RAG方法报告了所有子集的结果。本节概述了第5.1节中进行的评估实验设置和第5.2节中比较的所有方法。接着概述了第5.3节中的评估指标和第5.4节中的综合性能概述,突出了Oracle context性能和当前SOTA RAG方法之间的巨大差距。为了更好地理解这种差异,我们进行了两项消融研究:首先分析不同嵌入模型的影响,其次检查随着上下文大小增加而导致性能下降的情况,这导致MRR@k分数降低。
5.1 实验设置
为了评估数据集,每个子集都被独立处理和评估。首先,所有上下文都是markdown格式,并使用multilingual e5large instruct模型 4 { }^{4} 4 创建的嵌入唯一存储在Chroma向量数据库 3 { }^{3} 3 中,该模型的嵌入大小为1024。除了Summarization之外的所有RAG方法都如此操作,其中汇总的上下文被嵌入。检索查询用于从指令模型中检索上下文(更多信息见附录E)。选择Top-3文档并在主评估中传递给生成器。作为生成器,我们采用了LLaMA 3.3 70B 2 ^{2} 2,这是一个最先进的解码器-only transformer,和QwQ-32B 5 { }^{5} 5,一个推理模型,用于评估跨不同模型架构的性能。提示模板在附录F中提供。所有实验都在两块NVIDIA H100上进行。
5.2 RAG 方法
下一节简要描述了所有评估的RAG方法,以展示 T 2 \mathrm{T}^{2} T2-RAGBench上的SOTA性能,按其检索复杂性和增强策略分类。
预训练-仅限和Oracle Context。在预训练-仅限设置中,不使用检索器,模型必须仅基于其预训练知识回答问题。相反,Oracle Context设置假设相关文档上下文已知,并直接提供给生成器。
基本RAG方法。此类别包括使用标准嵌入方法检索文档而不改变问题、答案或检索上下文的方法。Base R A G R A G RAG实现遵循原始RAG方法(Lewis等,2020),其中仅嵌入问题以检索top-k文档,然后不变地传递给生成器。Hybrid BM25(Gao等,2021)结合使用BM25的稀疏词汇
检索使用BM25与密集向量检索,利用这两种方法来提高召回率和相关性。此外,Reranker方法(Tito等,2021)在初始检索后应用交叉编码器模型 6 { }^{6} 6 对文档进行重新排序,以基于共享嵌入空间中的相关性。
高级RAG方法。此类别包括修改查询、转换检索上下文或采用迭代检索策略的方法。HyDE方法(Gao等,2023a)为每个问题生成假设答案,使用它们作为改进查询以检索更多相关文档(提示参见附录G)。Summarization通过使用LLM压缩每个检索到的上下文来减少噪声,专注于重要信息。SumContext应用类似的摘要步骤,但保留原始完整文档以生成,旨在减少干扰同时保留内容保真度(参见附录H)。
5.3 评估指标
我们使用Number Match和MRR@k作为主要指标(如第3节定义),但也报告Recall@1(R@1)和Recall@3(R@3)以提高可比性和透明度。Number Match评估数值预测是否密切匹配黄金数值答案。它使用相对容忍度 ( ϵ = 1 e − 2 ) (\epsilon=1 \mathrm{e}-2) (ϵ=1e−2) 比较预测值和真实值,考虑规模不变性。非数值预测或不匹配被视为错误。对于MRR,我们选择 k = 3 k=3 k=3,测量第一个相关文档是否出现在前三检索结果中,奖励更高排名。我们将评估限制在3个文档,因为平均文档标记长度为785.8个标记。使用更多会增加输入大小,减慢推理速度,并降低LLM性能,这在现实世界中不可行(Li等,2024)。
5.4 实验结果
Pretrained-Only和Oracle Context。Pretrained-Only设置的结果显示,在所有子集中,问题都无法直接从模型的预训练数据中回答。这强调了RAG的重要性以及需要专门的基准。虽然重新表述的问题可能类似于见过的内容,特别是因为大多数标普500公司的报告早于2023年,但这适用于基础模型和推理模型。
1
3 { }^{3} 3 www.trychroma.com/
4 { }^{4} 4 intfloat/multilingual-e5-large-instruct
5 { }^{5} 5 Qwen/QwQ-32B-AWQ
表3:两个模型在T²-RAGBench上的整体性能(Number Match (NM) 和 MRR@3)。Number Match表示基于其数值表示正确回答问题的百分比,而MRR@3是如第3节定义的平均倒数排名。加粗单元格表示所有RAG方法中的最高值,带下划线的单元格表示RAG方法类别中的最佳值。
相比之下,Oracle Context设置在所有子集和两个模型上均显示出高Number Match性能,突出显示了模型的强大数值推理能力和现代LLM在这种设置下完成任务的可行性。值得注意的是,Llama和QwQ之间没有显著的性能差异(<0.3%)。
基本RAG方法。在RAG方法的评估中,基准显示,对于所有最先进的方法来说,达到与Oracle-context类似的成绩仍然具有挑战性。然而,这个基准提供了精确比较不同方法的可能性。对于Base-RAG,MRR@3平均低于40%,这意味着相关的文档通常不在前3名中,导致Number Match显著下降。这种情况在TAT-DQA中尤为明显,尽管其文档数量与FinQA相似,但对于所有测试的方法来说,检索相关信息更加困难。Hybrid BM25在MRR@3和Number Match平均表现优于Base RAG,除了VQAonBD,在VQAonBD中Base RAG显示出稍高的MRR@3但较低的Number Match。有趣的是,Reranker的表现比Base和Hybrid BM25 RAG方法差,这表明reranking模型没有在文本和表格数据上进行训练。
高级RAG方法。提高RAG方法性能的一种方法是改进查询与上下文的链接。然而,HyDE在所有子集上的MRR@3表现甚至比Base-RAG还差。这可能是由于模型难以生成与文档格式匹配的良好结构内容,这些文档通常包括文本和表格。特别是在VQAonBD上,性能比Base-RAG差,可能是因为上下文平均较短,仅包含表格数据,这使得生成与嵌入上下文匹配的合成文档变得更加困难。
Summarization方法在FinQA和ConvFinQA上的MRR@3表现良好,通过浓缩相关信息并去除噪音。然而,它在VQAonBD和TATDQA上表现不佳,值得进一步研究。一般来说,这往往会导致NM下降,因为在总结过程中丢失了回答问题所需的关键信息。SumContext使用总结的上下文进行检索,但从原始上下文中生成答案。这种方法提高了MRR@3,同时保持了稳定的NM,平均NM分别为37.4%和36.7%。然而,性能并没有在所有子集上都有所改善,这表明对提示和数据集的高度敏感性。
| Embedding Model | R@1 | R@5 | MRR@5 |
|---|---|---|---|
| Stella-EN-1.5B | 2.7 | 6.5 | 4.0 |
| GTE-Qwen2 1.5B Instruct | 14.5 | 23.2 | 14.5 |
| Multilingual E5-Instruct | 29.4 | 53.3 | 38.6 |
| Gemini: Text-Embedding-004 | 32.5 | 52.8 | 41.4 |
| OpenAI: Text-Embedding-3 Large | 33.8 | 56.1 | 43.6 |
表4:使用Base-RAG方法和检索5个文档的T2 2 { }^{2} 2-RAGBench子集上的嵌入模型检索性能,评估Recall@1 (R@1)、Recall@5 (R@5)和MRR@5。分数是对所有子集的加权平均。模型描述见附录J。
5.5 消融研究
嵌入模型。我们使用Base-RAG方法评估各种嵌入模型,以评估它们对检索性能的影响。如表4所示,在开源模型中,Multilingual E5-Instruct表现最好,R@1为29.4%和MRR@5为38.6。闭源模型表现略好,OpenAI模型的R@1最高为33.8%和MRR@5为43.6。然而,无论模型大小如何,没有一种模型在R@1上的文本和表格设置中达到令人满意的性能,这表明检索正确的文档仍然是T2 2 { }^{2} 2-RAGBench的核心挑战。
文档数量。图4显示了Base-RAG和Summarization在5个随机百分比递增子集上的检索性能如何随文档数量变化。出现了两个主要发现:(1) 当文档数量达到3千时,MRR@3下降到50%以下,意味着正确文档仅有一半的时间出现在前3名中;(2) Summarization在FinQA和ConvFinQA上有所改进,在TAT-DQA上表现相似,但在VQAonBD上退化,因为总结表格内容更具挑战性。
5.6 主要结论
总体而言,我们的结果显示,即使是评估的最强RAG方法(Hybrid BM25)在NM上也比Oracle context性能低近30%。这一性能差距突出了基准量化检索效果的能力,并强调了使用RAG实现Oracle级别性能的剩余挑战。即使使用其他RAG方法如Hybrid BM25,平均MRR只能提高1%,NM则提高4%。我们进一步分析了其他因素的影响,并发现即使是最先进的检索模型,其MRR@5得分也低于50%,这表明文本和表格数据的RAG仍然具有挑战性;此外,仅使用3千个文档的检索性能表明,这项任务仍有很大的改进空间。
6 结论
在本文中,我们介绍了我们新创建的基准 T 2 \mathbf{T}^{2} T2-RAGBench,它包含32,908个问题-答案-上下文三元组。它包括来自9,000多篇文档的问题,旨在评估在UnknownContext Setting下文本-表格数据的数值推理的RAG方法。虽然其他数据集被定义为Oracle-Context setting,我们的基准使用上下文无关问题,使得首次评估RAG方法成为可能。我们通过对我们基准的定量分析和人工验证证明了这一点,展示了它如何满足其既定目标。我们在基准上测试了常见的RAG方法,发现结合密集和稀疏检索的Hybrid BM25表现最佳。此外,我们进行了消融研究,显示当前最先进的嵌入模型在文本和表格上下文上的R@5和MRR@5得分较低。通过T2 2 { }^{2} 2-RAGBench,我们旨在推动更适合文本和表格文档的RAG方法的发展。
在未来的工作中,我们想评估更多的RAG方法,以调查哪些因素对文本和表格数据的影响最大。添加来自其他领域的更多数据也是必要的一步,以使评估更加普遍化。
局限性
本节概述了与方法和数据集相关的主要局限性,这些可能会对所述结果的有效性和普遍性产生影响。
缺乏人类验证和真实性。基准中使用的问题是合成生成的,这可能导致失真,因为模型并不一定会生成真实用户会提出的问题类型。因此,转移到实际系统的效果可能会受到影响。虽然原始的问题-答案对由人类标注,但不能保证生成的问题将以允许其他模型同等回答的方式进行表述。
另一个点是,对基准问题的全面验证过程只是部分进行的。虽然我们在基准中用四个注释者验证了每个子集的100个样本,但基准满足我们提出的任务评估数据集的要求。然而,仍然可能存在一些不适合查找正确上下文的问题。
领域特定的应用。本文旨在展示一个可以测试不同文档类型和不同知识的文本-表格数据集的基准。然而,数据集仅由具有相同标准化结构、一致术语和领域特定内容的金融文档组成。因此,模型的性能是针对这个领域定制的,不能完全假设推广到其他类型的文档布局或内容类型,例如医疗报告、科学出版物或行政表格,其中表格和文本的关系可能大相径庭。尽管如此,鉴于财务报告标准的广泛应用,我们的工作对该特定领域做出了贡献。
使用量化模型。由于资源有限,所有评估都使用量化版本的模型进行,以获得更快的推理时间和执行大型开源模型的能力。虽然量化在计算效率方面有明显优势,但它通常是以降低数值精度和模型准确性为代价的。因此,性能可能低于全精度最先进的模型。然而,由于本文的重点更多在于合适的RAG方法的比较,我们认为这是可以忽略的。
参考文献
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through SelfReflection. In The Twelfth International Conference on Learning Representations, Vienna, Austria. ICLR.
Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, and Ketan V. Kotecha. 2021. Efficient Automated Processing of the Unstructured Documents Using Artificial Intelligence: A Systematic Literature Review and Future Directions. IEEE Access, 9:72894-72936.
Jian Chen, Peilin Zhou, Yining Hua, Loh Xin, Kehui Chen, Ziyuan Li, Bing Zhu, and Junwei Liang. 2024. FinTextQA: A Dataset for Long-form Financial Question Answering. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6025-6047, Bangkok, Thailand. Association for Computational Linguistics.
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. 2020. HybridQA: A Dataset of Multi-Hop Question Answering over Tabular and Textual Data. In Findings of the Association for Computational Linguistics, volume EMNLP 2020 of Findings of ACL, pages 1026-1036, Online Event. Association for Computational Linguistics.
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021. FinQA: A Dataset of Numerical Reasoning over Financial Data. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697-3711, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. 2022. ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, pages 6279-6292, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Chanyeol Choi, Jihoon Kwon, Jaeseon Ha, Hojun Choi, Chaewoon Kim, Yongjae Lee, Jy-yong Sohn, and Alejandro Lopez-Lira. 2025. FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation. arXiv preprint. ArXiv:2504.15800.
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. 2021. A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599-4610, Online. Association for Computational Linguistics.
Yihao Ding, Siwen Luo, Hyunsuk Chung, and Soyeon Caren Han. 2023. PDF-VQA: A New Dataset for Real-World VQA on PDF Documents. In Machine Learning and Knowledge Discovery in Databases: Applied Data Science and Demo Track - European Conference, volume 14174 of Lecture Notes in Computer Science, pages 585-601, Turin, Italy. Springer.
Luyu Gao, Zhuyun Dai, Tongfei Chen, Zhen Fan, Benjamin Van Durme, and Jamie Callan. 2021. Complementing Lexical Retrieval with Semantic Residual Embedding. arXiv preprint. ArXiv:2004.13969.
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023a. Precise Zero-Shot Dense Retrieval without Relevance Labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1762-1777, Toronto, Canada. Association for Computational Linguistics.
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023b. Retrieval-augmented generation for large language models: A survey. arXiv preprint. ArXiv:2312.10997.
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhari, Abhinav Pandey, Abhishek Kadian, Ahmad AlDahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and others. 2024. The Llama 3 Herd of Models. arXiv preprint. ArXiv:2407.21783.
Yulong Hui, YAO LU, and Huanchen Zhang. 2024. UDA: A Benchmark Suite for Retrieval Augmented Generation in Real-World Document Analysis. In Advances in Neural Information Processing Systems, volume 37, pages 67200-67217. Curran Associates, Inc.
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Augmented Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969-7992, Singapore. Association for Computational Linguistics.
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601-1611, Vancouver, Canada. Association for Computational Linguistics.
Aditya Gupta, Pankaj Kumar, and Manas Sisodia. 2024. Robust Multi Model RAG Pipeline For Documents Containing Text, Table & Images. In 2024 3rd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), pages 993-999, Salem, India. IEEE.
Yannis Katsis, Saneem A. Chemmengath, Vishwajeet Kumar, Samarth Bharadwaj, Mustafa Canim, Michael R. Glass, Alfio Gliozzo, Feifei Pan, Jaydeep Sen, Karthik Sankaranarayanan, and Soumen Chakrabarti. 2022. AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Track, pages 305-314, Hybrid: Seattle, Washington, USA + Online. Association for Computational Linguistics.
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP. arXiv preprint. ArXiv: 2212.14024.
Kihun Kim, Mintae Kim, Hokyung Lee, Seong Ik Park, Youngsub Han, and Byoung-Ki Jeon. 2024. THoRR: Complex Table Retrieval and Refinement for RAG. In Proceedings of the Workshop Information Retrieval’s Role in RAG Systems (IR-RAG 2024) co-located with the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, volume 3784 of CEUR Workshop Proceedings, pages 50-55, Washington DC, USA.
Tian Lan, Deng Cai, Yan Wang, Heyan Huang, and Xian-Ling Mao. 2023. Copy is All You Need. In The Eleventh International Conference on Learning Representations, Kigali, Rwanda.
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, virtual.
Xinze Li, Yixin Cao, Yubo Ma, and Aixin Sun. 2024. Long Context vs. RAG for LLMs: An Evaluation and Revisits. arXiv preprint. ArXiv:2501.01880.
Linyong Nan, Chia-Hsuan Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kryscinski, Nick Schoelkopf, Riley Kong, Xiangru Tang, Murori Mutuma, Benjamin Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, and Dragomir R. Radev. 2021. FeTaQA: Freeform Table Question Answering. Transactions of the Association for Computational Linguistics, 10:35-49.
Irina Nikishina, Özge Sevgili, Mahei Manhai Li, Chris Biemann, and Martin Semmann. 2025. Creating a Taxonomy for Retrieval Augmented Generation Applications. arXiv preprint. ArXiv:2408.02854.
Panupong Pasupat and Percy Liang. 2015. Compositional Semantic Parsing on Semi-Structured Tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, pages 1470-1480, Beijing, China. The Association for Computer Linguistics.
Shraman Pramanick, Rama Chellappa, and Subhashini Venugopalan. 2024. SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, Vancouver, BC, Canada.
Sachin Raja, Ajoy Mondal, and C. V. Jawahar. 2023. ICDAR 2023 Competition on Visual Question Answering on Business Document Images. In Document Analysis and Recognition, pages 454-470, Cham, Germany. Springer Nature Switzerland.
Carl M Rebman Jr, Queen E Booker, Hayden Wimmer, Steve Levkoff, Mark McMurtrey, and Loreen Marie Powell. 2023. An Industry Survey of Analytics Spreadsheet Tools Adoption: Microsoft Excel vs Google Sheets. Information Systems Education Journal, 21(5):29-42. Publisher: ERIC.
Sohini Roychowdhury, Marko Krema, Anvar Mahammad, Brian Moore, Arijit Mukherjee, and Punit Prakashchandra. 2024. ERATTA: Extreme RAG for Table To Answers with Large Language Models. arXiv preprint. ArXiv:2405.03963.
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. In The Twelfth International Conference on Learning Representations, Vienna, Austria. The Association for Computational Linguistics.
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. 2021. Document Collection Visual Question Answering. In 16th International Conference on Document Analysis and Recognition, volume 12822 of Lecture Notes in Computer Science, pages 778-792, Lausanne, Switzerland. Springer.
Xindi Wang, Mahsa Salmani, Parsa Omidi, Xiangyu Ren, Mehdi Rezagholizadeh, and Armaghan Eshaghi. 2024. Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models.
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, Tongliang Li, Zhoujun Li, and Guanglin Niu. 2025. TableBench: A Comprehensive and Complex Benchmark for Table Question Answering. In Association for the Advancement of Artificial Intelligence, pages 25497-25506, Philadelphia, PA, USA. AAAI Press.
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. 2024. Corrective Retrieval Augmented Generation. arXiv preprint. ArXiv:2401.15884.
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369-2380, Brussels, Belgium. Association for Computational Linguistics.
Xinyi Zheng, Doug Burdick, Lucian Popa, Xu Zhong, and Nancy Xin Ru Wang. 2020. Global Table Extractor (GTE): A Framework for Joint Table Identification and Cell Structure Recognition Using Visual Context. arXiv preprint. ArXiv:2005.00589.
Fengbin Zhu, Wenqiang Lei, Fuli Feng, Chao Wang, Haozhou Zhang, and Tat-Seng Chua. 2022. Towards Complex Document Understanding By Discrete Reasoning. In MM '22: The 30th ACM International Conference on Multimedia, pages 4857-4866, Lisboa, Portugal. ACM.
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and TatSeng Chua. 2021. TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 3277-3287, Virtual Event. Association for Computational Linguistics.
Fengbin Zhu, Junfeng Li, Liangming Pan, Wenjie Wang, Fuli Feng, Chao Wang, Huanbo Luan, and Tat-Seng Chua. 2025. FinTMMBench: Benchmarking Temporal-Aware Multi-Modal RAG in Finance. arXiv preprint. ArXiv:2503.05185.
A 数据准备
FinQA. FinQA数据集基于人工标注的关于FinTabNet文档的问题,FinTabNet是一个包含标普500公司年度报告的大PDF文件语料库。除了现有数据外,还添加了公司特定信息,如成立年份、部门和报告年份。由于答案要么是公式,要么是数值,所有的公式都被解析并转换为数值,因为观察到了公式与其数值解之间的差异。此外,大约150个是非问题的答案通过分别将答案转换为0和1进行标准化。
ConvFinQA. ConvFinQA数据集也基于FinTabNet,并丰富了额外的元数据。与FinQA类似,答案通过将公式和数字响应转换为统一格式进行标准化。为了减少任务复杂性和消除潜在的混淆因素,仅包含每段对话的第一个问题。这将数据集大小从14,115减少到3,458个问答对。
VQAonBD. VQAonBD数据集同样基于FinTabNet,并补充了额外的元数据。最初,该数据集完全由显示表格的图像组成,没有任何周围的文本。为了检索原始数据,将表格ID与原始FinTabNet PDF匹配,这些PDF也可在JSON格式中找到。初始数据集包含五个难度各异的类别共一百万多个问题。由于挑战赛的基线模型在提供上下文时取得了很好的结果,因此只选用了最难的类别进行分析,将数据集大小减少到9,820个问答对。
TAT-DQA. TAT-DQA是一个基于公开可用财务报告的独立数据集。原始数据集包括四种答案类型:Span、Multi-span、Arithmetic和Count。为了与其他仅关注数值推理的数据集保持一致并维持统一的评估提示,删除了Multi-span问题。此外,通过删除符号如$和%并转换“million”或“billion”等词为数字等价物来标准化Span答案。日期也被重新格式化为美国标准。这些过滤步骤后,数据集大小从16,558减少到11,349个问答对。
B 重构提示
用于重构问题以使其与上下文无关的提示如图5所示
系统提示
你是一位金融教育助手。你的任务是改写问题,基于财务文档中的特定表格。目标是确保问题:
- 指代仅在此特定上下文中才有意义的细节
-
- 不要使用像"根据上面的数据"或"根据表格"这样的通用短语
-
- 无法用任何其他财务文档或上下文回答
-
- 保持原始答案正确
-
- 听起来自然、精确且无歧义
-
- 尽量删去不必要的词语和短语
- 还会为你提供文档的元数据(例如公司名称、报告标题、年份、章节)。
- 使用这些元数据进一步将问题置于上下文中。
- 解释必须:
-
- 描述到达答案所需的推理步骤
-
- 提及表格中的特定值、标签、行或关系
-
- 显示答案对此表是唯一有效的,并且与元数据/上下文相关
-
输出格式:
- 问题:
- 答案:
- 解释:
图5: 重构问题的系统提示。
C 注释工具
财务专家的注释是通过一个简单的网页工具完成的,如图6所示。对于每个问题,注释员可以看到原始问题、重构问题和数据集中提供的上下文。
原始问题
问题
从2015年初到2016年底,总携带金额的增长百分比是多少?
原始问题标签
(1) 依赖上下文
无歧义
生成的问题
生成
Cadence Design Systems在2015年初到2016年底期间,商誉总携带金额的增长百分比是多少?考虑到收购和外汇换算的影响,如2016年合并财务报表中所报告的。
生成的问题标签
□ 依赖上下文
(2) 无歧义
提交注释
上下文
运营结果和已确认资产和负债的估计公允价值记录在收购日的合并财务报表中。
完成财政年度2016期间业务组合的模拟运营结果并未呈报,因为这些收购对Cadence 2019年的财务结果的影响在个别和总体上都不重大。
收购无形资产和承担的负债的公允价值是使用市场中不可观察的重要投入确定的。
有关这些公允价值计算的更多说明,请参见合并财务报表附注中的第16项。
一个受益于lip-ba tan(Cadence的总裁、首席执行官和董事)子女的信托基金持有不到2%(2%)的rockstick technologies Rd股份,这是被收购公司之一,tan先生和他的妻子担任共同受托人并放弃对信托的经济利益。
Cadence董事会审查了交易并得出结论,认为推进交易符合Cadence的最佳利益。
tan先生在董事会2019年关于rockstick technologies Rd估值的讨论中退出。
一家财务顾问就交易向Cadence提供了公平意见。
在财政年度2014期间,Cadence收购了位于加州山景城的私人持有的正式分析解决方案提供商Jasper Design Automation, Inc.(简称Jasper)。
所收购的技术补充了Cadence 2019年的系统设计和验证平台。
扣除某些成本调整和Jasper在交割时持有的现金2870万美元后,Jasper的总现金对价为13940万美元。
Cadence还将根据继续履行的条件和摊销及其他条件,向某些员工支付到财政年度2017第三季度为止的款项。
图6:标注重新表述问题的工具。
D 数据集样本
以下是我们为每个数据集子集提供的两个示例,包括原始问题、重新表述的问题及其对应的上下文。由于页面宽度有限,我们不得不对上下文文本进行换行。
[h] 数据集 / ID:
train_finqa2516
问题:
从2010年到2011年净收入的增长率是多少?
重新表述:
Entergy公司在2010年到2011年间净收入的变化百分比是多少?考虑市值变动税务结算分摊、零售电力价格调整等因素,如2011年财务讨论与分析中所述?
上下文:
entergy louisiana , llc及其子公司管理层的财务讨论与分析计划剥离公用事业的传输业务,请参见能源公司及其子公司的财务讨论与分析的“计划剥离公用事业的传输业务”部分,以讨论此事,包括债务和优先证券的计划退休。经营业绩净利润 2011年与2010年相比,净利润增长了24250万美元,主要是由于与电力购买合同的市值税收待遇有关的IRS结算带来的42200万美元所得税收益。净利润效应部分被19900万美元的监管费用抵消,该费用减少了净收入,因为一部分收益将与客户共享。有关结算和收益共享的详细讨论,请参见财务报表附注3。2010年与2009年相比,净利润略有下降了140万美元,主要是由于更高的其他运营和维护费用、更高的有效税率和更高的利息支出,几乎全部被更高的净收入抵消。净收入 2011年与2010年相比,净收入由运营收入减去以下内容组成:1)燃料、燃料相关费用和转售的天然气,2)购电费用,3)其他监管费用(信用)。以下是2011年与2010年净收入变化的分析。金额(百万美元)._|
| 金额(百万美元)
||—😐:---------------------------------|:------------------------| | 0 | 2010年净收入 | $ 1043.7 || 1 | 市值税务结算分摊 | -195.9 (195.9) || 2 | 零售电价调整 | 32.5 || 3 | 体积/天气 | 11.6 || 4 | 其他 | -5.7(5.7) || 5 | 2011年净收入 | $ 886.2 |_市值税务结算分摊方差来自于一项监管费用,因为与电力采购合同的市值税务待遇有关的与国税局达成的结算的一部分收益将与客户共享,从2011年10月开始摊销该费用的部分。有关结算和收益共享的详细讨论,请参见财务报表附注3和8。零售电价方差主要归因于2011年5月生效的公式费率计划增加。请参阅财务报表附注2以讨论公式费率计划的增加。 . .
数据集 / ID:
train_finqa518
问题:
截至2008年12月31日,为此计划收购的总负债是多少(以百万计)
改写:
截至2008年12月31日,Republic Services为其BFI退休医疗计划收购的总负债是多少,如其2008年合并财务报表中披露的那样?
背景:
预计未来十年内根据该计划支付的养老金福利(以百万计)如下:预计未来付款:.| | 2009 | $
14.9 ||—😐:-----------------|---------:|| 0 | 2010 | 15.9 || 1 |
2011 | 16.2 || 2 | 2012 | 19.2 || 3 | 2013
| 21.9 || 4 | 2014 至 2018 | 142.2 |_bfi 退休医疗计划 我们在收购Allied公司时获得了BFI退休医疗计划下的义务。该计划为某些前雇员在退休后继续提供医疗保障,包括一些集体谈判协议覆盖的雇员。该计划的资格仅限于那些在1998年12月31日之前有10年以上服务年限且年龄在55岁或以上的某些雇员,以及在2005年12月31日或之前聘用并在55岁或以上退休且至少有三十年服务年限的某些加利福尼亚州雇员。该计划的负债在收购日和2008年12月31日分别为120万美元和130万美元。我们根据涵盖工会代表员工的集体谈判协议,向25个多方雇主养老计划供款。这些计划通常根据参与者的服务年限向参与者提供退休福利。我们不管理这些多方雇主计划。一般来说,这些计划由一个受托人委员会管理,工会任命某些受托人,其他供款雇主任命某些成员。我们一般不在受托人委员会中。我们没有从计划的管理员那里获得当前的财务信息,但根据我们掌握的信息,有可能我们供款的一些多方雇主计划资金不足。2006年8月颁布的《养老金保护法案》要求资金不足的养老金计划在规定的间隔内根据其资金不足的程度提高资金比率。在计划受托人制定出所需的融资改善计划或康复计划之前,我们无法确定我们可能需要承担的评估金额(如果有的话)。因此,目前我们无法确定《养老金保护法案》可能对我们合并财务状况、经营成果或现金流量产生的影响。此外,根据关于多方雇主福利计划的现行法律,任何资金不足的多方雇主养老金计划的终止、我们的自愿退出,或所有供款雇主的大规模退出将要求我们支付我们应占的该多方雇主计划未分配权益负债的比例份额。未来几年内可能会发生雇主对这些计划的大规模退出,或者这些计划可能会终止。我们可能会调整这些事项的估计值,这可能会对我们合并的财务状况、经营成果或现金流量产生重大影响。我们对多方雇主计划的养老费用分别为2180万美元、1890万美元和1730万美元,截至2008年、2007年和2006年12月31日。Republic Services, Inc.及其子公司合并财务报表附注 %
|00027|yes|no|02/28/2009 21:12|0|0|页面有效,无图形–颜色:d| .
Dataset / ID:
TatQA 8e642bdce983286cbaffa9661d24157a
问题:
2019年期间归属的限制性股票单位(RSUs)的总内在价值是多少?
改写:
Microchip Technology Inc.在截至2019年3月31日的一年中归属的限制性股票单位(RSUs)的总内在价值是多少?
背景:
与Microsemi收购相关的股权奖励
2018年5月29日,公司收购了Microsemi,并承接了某些限制性股票单位(RSUs)、股票增值权(SARs)和由Microsemi授予的股票期权。假设的奖励在收购日基于估算的公允价值进行计量,总计为17540万美元。其中一部分公允价值,即代表员工为Microsemi提供预收购服务的部分,共计5390万美元,被计入作为收购部分转移的总考虑中。截至收购日,这些奖励的公允价值剩余部分为12150万美元,代表收购后基于员工在剩余归属期内提供的服务而确认的股权激励费用。截至截至2019年3月31日的一年中,公司因收购Microsemi而确认了6520万美元的股权激励费用,其中350万美元已资本化为库存,1720万美元是由于某些Microsemi员工离职时加速归属所致。
与Atmel收购相关的股权奖励
2016年4月4日,公司收购了Atmel,并承接了某些由Atmel授予的RSUs。假设的奖励在收购日基于估算的公允价值进行计量,总计为9590万美元。其中一部分公允价值,即代表员工为Atmel提供预收购服务的部分,共计750万美元,被计入作为收购部分转移的总考虑中。截至收购日,这些奖励的公允价值剩余部分为8840万美元,代表收购后基于员工在剩余归属期内提供的服务而确认的股权激励费用。
综合激励计划信息
2004计划下的RSU股份活动如下: | 股份数量 | 加权平均授予日期
| 公允价值 ||---------------------------|----------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------…(未完待续)
参考论文:https://arxiv.org/pdf/2506.12071
-
6 { }^{6} 6 Cross-encoder/ms-marco-MiniLM-L-6-v2
| 模型 | RAG方法 | FinQA | | ConvFinQA | | VQAonBD | | TAT-DQA | | W. Avg Total | |
| — | — | — | — | — | — | — | — | — | — | — | — |
| | | NM | MRR@3 | NM | MRR@3 | NM | MRR@3 | NM | MRR@3 | NM | MRR@3 |
| Llama 3.3-70B
+ Multilingual E5-Large Instruct | + Pretrained-Only
+ Oracle Context | 7.9 79.4 \begin{aligned} & 7.9 \\ & 79.4 \end{aligned} 7.979.4 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 2.8 75.8 \begin{aligned} & 2.8 \\ & 75.8 \end{aligned} 2.875.8 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 1.54 68.7 \begin{aligned} & 1.54 \\ & 68.7 \end{aligned} 1.5468.7 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 3.7 69.2 \begin{aligned} & 3.7 \\ & 69.2 \end{aligned} 3.769.2 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 3.9 72.3 \begin{aligned} & 3.9 \\ & 72.3 \end{aligned} 3.972.3 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 |
| | + Base-RAG
+ Hybrid BM25
+ Reranker | 39.5 41.7 32.4 \begin{aligned} & 39.5 \\ & 41.7 \\ & 32.4 \end{aligned} 39.541.732.4 | 38.7 40.0 29.0 \begin{aligned} & 38.7 \\ & 40.0 \\ & 29.0 \end{aligned} 38.740.029.0 | 47.4 50.3 37.3 \begin{aligned} & 47.4 \\ & 50.3 \\ & 37.3 \end{aligned} 47.450.337.3 | 42.2 43.5 32.3 \begin{aligned} & 42.2 \\ & 43.5 \\ & 32.3 \end{aligned} 42.243.532.3 | 40.5 42.2 34.8 \begin{aligned} & 40.5 \\ & 42.2 \\ & 34.8 \end{aligned} 40.542.234.8 | 46.9 43.8 39.3 \begin{aligned} & 46.9 \\ & 43.8 \\ & 39.3 \end{aligned} 46.943.839.3 | 29.6 37.4 27.0 \begin{aligned} & 29.6 \\ & 37.4 \\ & 27.0 \end{aligned} 29.637.427.0 | 25.2 29.2 22.8 \begin{aligned} & 25.2 \\ & 29.2 \\ & 22.8 \end{aligned} 25.229.222.8 | 37.2 41.3 31.8 \begin{aligned} & 37.2 \\ & 41.3 \\ & 31.8 \end{aligned} 37.241.331.8 | 36.9 37.8 30.3 \begin{aligned} & 36.9 \\ & 37.8 \\ & 30.3 \end{aligned} 36.937.830.3 |
| | + HyDE
+ Summarization
+ SumContext | 38.4 27.3 47.2 \begin{aligned} & 38.4 \\ & 27.3 \\ & 47.2 \end{aligned} 38.427.347.2 | 35.4 47.3 47.3 \begin{aligned} & 35.4 \\ & 47.3 \\ & 47.3 \end{aligned} 35.447.347.3 | 44.8 35.2 55.5 \begin{aligned} & 44.8 \\ & 35.2 \\ & 55.5 \end{aligned} 44.835.255.5 | 39.8 52.1 52.1 \begin{aligned} & 39.8 \\ & 52.1 \\ & 52.1 \end{aligned} 39.852.152.1 | 35.1 10.6 32.5 \begin{aligned} & 35.1 \\ & 10.6 \\ & 32.5 \end{aligned} 35.110.632.5 | 39.2 35.1 35.4 \begin{aligned} & 39.2 \\ & 35.1 \\ & 35.4 \end{aligned} 39.235.135.4 | 26.7 14.6 29.1 \begin{aligned} & 26.7 \\ & 14.6 \\ & 29.1 \end{aligned} 26.714.629.1 | 20.8 24.7 24.8 \begin{aligned} & 20.8 \\ & 24.7 \\ & 24.8 \end{aligned} 20.824.724.8 | 34.0 18.8 37.4 \begin{aligned} & 34.0 \\ & 18.8 \\ & 37.4 \end{aligned} 34.018.837.4 | 32.0 36.5 36.5 \begin{aligned} & 32.0 \\ & 36.5 \\ & 36.5 \end{aligned} 32.036.536.5 |
| QwQ-32B
+ Multilingual E5-Large Instruct | + Pretrained-Only
+ Oracle Context | 7.5 72.4 \begin{aligned} & 7.5 \\ & 72.4 \end{aligned} 7.572.4 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 2.4 85.4 \begin{aligned} & 2.4 \\ & 85.4 \end{aligned} 2.485.4 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 1.7 69.6 \begin{aligned} & 1.7 \\ & 69.6 \end{aligned} 1.769.6 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 4.4 71.1 \begin{aligned} & 4.4 \\ & 71.1 \end{aligned} 4.471.1 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 | 4.2 72.5 \begin{aligned} & 4.2 \\ & 72.5 \end{aligned} 4.272.5 | 0 100 \begin{aligned} & 0 \\ & 100 \end{aligned} 0100 |
| | + Base-RAG
+ Hybrid BM25
+ Reranker | 39.6 41.8 30.8 \begin{aligned} & 39.6 \\ & 41.8 \\ & 30.8 \end{aligned} 39.641.830.8 | 38.7 39.8 29.0 \begin{aligned} & 38.7 \\ & 39.8 \\ & 29.0 \end{aligned} 38.739.829.0 | 48.7 51.6 37.5 \begin{aligned} & 48.7 \\ & 51.6 \\ & 37.5 \end{aligned} 48.751.637.5 | 42.4 43.6 32.7 \begin{aligned} & 42.4 \\ & 43.6 \\ & 32.7 \end{aligned} 42.443.632.7 | 41.7 43.5 34.6 \begin{aligned} & 41.7 \\ & 43.5 \\ & 34.6 \end{aligned} 41.743.534.6 | 46.9 43.5 39.2 \begin{aligned} & 46.9 \\ & 43.5 \\ & 39.2 \end{aligned} 46.943.539.2 | 27.9 25.6 25.6 \begin{aligned} & 27.9 \\ & 25.6 \\ & 25.6 \end{aligned} 27.925.625.6 | 25.2 29.3 22.9 \begin{aligned} & 25.2 \\ & 29.3 \\ & 22.9 \end{aligned} 25.229.322.9 | 37.1 41.7 30.8 \begin{aligned} & 37.1 \\ & 41.7 \\ & 30.8 \end{aligned} 37.141.730.8 | 36.9 37.8 30.3 \begin{aligned} & 36.9 \\ & 37.8 \\ & 30.3 \end{aligned} 36.937.830.3 |
| | + HyDE
+ Summarization
+ SumContext | 36.8 26.9 45.6 \begin{aligned} & 36.8 \\ & 26.9 \\ & 45.6 \end{aligned} 36.826.945.6 | 35.4 47.2 47.3 \begin{aligned} & 35.4 \\ & 47.2 \\ & 47.3 \end{aligned} 35.447.247.3 | 45.7 35.6 56.9 \begin{aligned} & 45.7 \\ & 35.6 \\ & 56.9 \end{aligned} 45.735.656.9 | 39.9 52.2 52.2 \begin{aligned} & 39.9 \\ & 52.2 \\ & 52.2 \end{aligned} 39.952.252.2 | 35.9 10.7 33.1 \begin{aligned} & 35.9 \\ & 10.7 \\ & 33.1 \end{aligned} 35.910.733.1 | 38.4 35.4 35.4 \begin{aligned} & 38.4 \\ & 35.4 \\ & 35.4 \end{aligned} 38.435.435.4 | 24.7 13.9 27.3 \begin{aligned} & 24.7 \\ & 13.9 \\ & 27.3 \end{aligned} 24.713.927.3 | 20.7 24.7 24.7 \begin{aligned} & 20.7 \\ & 24.7 \\ & 24.7 \end{aligned} 20.724.724.7 | 33.3 18.5 36.7 \begin{aligned} & 33.3 \\ & 18.5 \\ & 36.7 \end{aligned} 33.318.536.7 | 31.7 36.4 36.5 \begin{aligned} & 31.7 \\ & 36.4 \\ & 36.5 \end{aligned} 31.736.436.5 | ↩︎

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)