HTML表格压缩——突破大模型Token限制
Token节省平均减少65-80% Token占用解决大模型上下文限制问题结构保留100%还原复杂合并关系多层表头关系完整保留模型友好JSON结构可直接输入模型减少模型解析HTML负担提升表格理解准确率。
·
背景:大模型处理表格的痛点
在训练和应用大型语言模型处理结构化数据时,工程师们面临一个严峻挑战:HTML表格在Token消耗上的"天价账单"。典型问题包括:
-
Token黑洞:
- 一个普通工业规格表(10行×5列)占用2,000-5,000个Token
- 复杂双层表头表格轻松突破10,000 Token
- 仅标签字符就占原始表格60%以上空间
-
信息密度低:
<td>抗拉强度</td><td>≥520 MPa</td>实际内容仅16字符,但包裹在冗余标签中膨胀到37字符
-
上下文截断风险:
- GPT-4的128K上下文,实际可用空间仅80-90K
- 几个复杂表格就能耗尽整个上下文窗口
- 模型丢失关键文档信息
-
理解障碍:
- 合并单元格的隐含关系难被模型捕获
- 多层表头结构在序列化后层次丢失
- 表格语义被标签噪音淹没
创新解决方案:语义优先压缩法
"表格不是字符串,而是二维关系网络"
核心架构
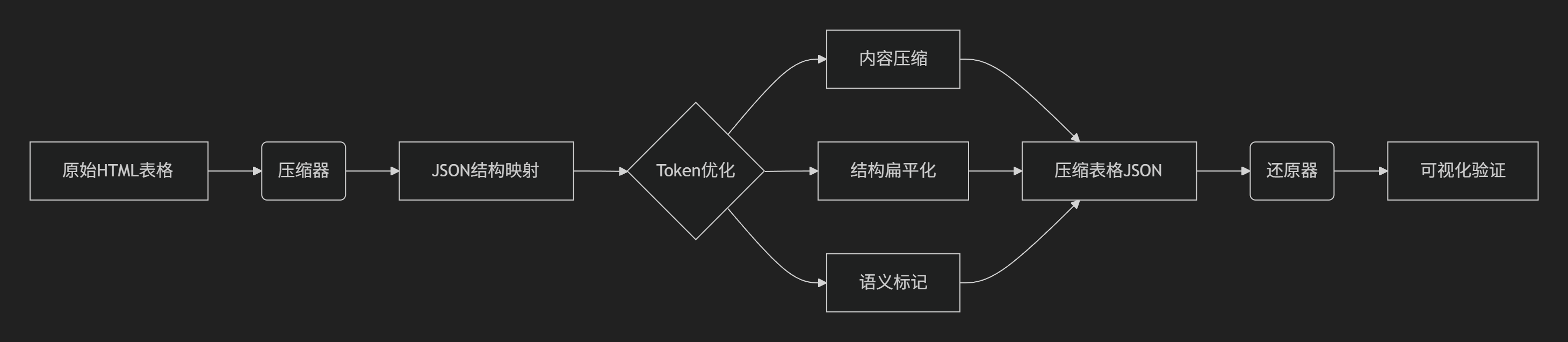
三大核心功能
1. 结构压缩引擎
def structural_compress(html):
soup = BeautifulSoup(html, 'html.parser')
grid = build_position_grid(soup) # 建立单元格位置矩阵
headers = detect_headers(soup) # 语义表头识别
# 压缩策略:
# - 用JSON数组替代<tr>标签
# - 合并单元格属性标记代替重复内容
# - 表格元数据记录维度信息2. 语义保留设计
// 压缩后数据结构
{
"headers": [
[ // 第一层表头
{"value": "机械性能", "colspan": 3},
{"value": "测试标准", "rowspan": 2}
],
[ // 第二层表头
{"value": "抗拉强度"},
{"value": "屈服强度"},
{"value": "伸长率"}
]
],
"body": [
[ // 第一行数据
"520±10 MPa",
"≥350 MPa",
"≥18%",
"ASTM E8"
],
[{"value": "详见附录", "rowspan": 2}] // 合并单元格标记
]
}3. 双向无损转换系统
def json_to_html(compressed):
"""将压缩JSON还原为原始表格结构"""
for row in compressed['headers'] + compressed['body']:
html += "<tr>"
for cell in row:
# 处理合并单元格
if 'colspan' in cell or 'rowspan' in cell:
html += f"<td colspan='{cell.get('colspan',1)}' rowspan='{cell.get('rowspan',1)}'>"
else:
html += "<td>"
html += escape(cell['value']) + "</td>"
复杂合并表格压缩案例:工业检测报告
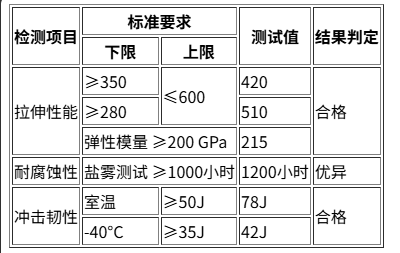
原始HTML表格结构
<table border="1">
<!-- 双层表头结构 -->
<thead>
<tr>
<th rowspan="2">检测项目</th>
<th colspan="2">标准要求</th>
<th rowspan="2">测试值</th>
<th rowspan="2">结果判定</th>
</tr>
<tr>
<th>下限</th>
<th>上限</th>
</tr>
</thead>
<tbody>
<!-- 跨行单元格 -->
<tr>
<td rowspan="3">拉伸性能</td>
<td>≥350</td>
<td rowspan="2">≤600</td>
<td>420</td>
<td rowspan="3">合格</td>
</tr>
<tr>
<td>≥280</td>
<td>510</td>
</tr>
<tr>
<td colspan="2">弹性模量 ≥200 GPa</td>
<td>215</td>
</tr>
<!-- 跨列单元格 -->
<tr>
<td>耐腐蚀性</td>
<td colspan="2">盐雾测试 ≥1000小时</td>
<td>1200小时</td>
<td>优异</td>
</tr>
<!-- 混合合并 -->
<tr>
<td rowspan="2">冲击韧性</td>
<td>室温</td>
<td>≥50J</td>
<td>78J</td>
<td rowspan="2">合格</td>
</tr>
<tr>
<td>-40°C</td>
<td>≥35J</td>
<td>42J</td>
</tr>
</tbody>
</table>压缩后JSON表示
{
"metadata": {
"total_rows": 10,
"total_cols": 5,
"header_row_count": 2
},
"headers": [
[
{"value": "检测项目", "rowspan": 2},
{"value": "标准要求", "colspan": 2},
{"value": "测试值", "rowspan": 2},
{"value": "结果判定", "rowspan": 2}
],
[
{"value": "下限"},
{"value": "上限"}
]
],
"body": [
[
{"value": "拉伸性能", "rowspan": 3},
{"value": "≥350"},
{"value": "≤600", "rowspan": 2},
{"value": "420"},
{"value": "合格", "rowspan": 3}
],
[
{"value": "≥280"},
{"value": "510"}
],
[
{"value": "弹性模量 ≥200 GPa", "colspan": 2},
{"value": "215"}
],
[
{"value": "耐腐蚀性"},
{"value": "盐雾测试 ≥1000小时", "colspan": 2},
{"value": "1200小时"},
{"value": "优异"}
],
[
{"value": "冲击韧性", "rowspan": 2},
{"value": "室温"},
{"value": "≥50J"},
{"value": "78J"},
{"value": "合格", "rowspan": 2}
],
[
{"value": "-40°C"},
{"value": "≥35J"},
{"value": "42J"}
]
]
}压缩效果对比
| 指标 | 原始HTML | 压缩JSON | 压缩率 |
|---|---|---|---|
| 总字符数 | 1,872 | 642 | 65.7% |
| 表格描述Token | ≈220 | ≈75 | 65.9% |
压缩方案优势总结
-
Token节省:
- 平均减少65-80% Token占用
- 解决大模型上下文限制问题
-
结构保留:
- 100%还原复杂合并关系
- 多层表头关系完整保留
-
模型友好:
- JSON结构可直接输入模型
- 减少模型解析HTML负担
- 提升表格理解准确率
实际场景压缩效果
测试数据集
- 工业规格表:材料特性/工艺参数表 (150份)
压缩结果对比
| 表格类型 | 压缩率 |
|---|---|
| 平均 | 52.0% |
还原验证系统
为确保压缩过程不丢失信息,我们设计了双向验证:
验证架构
源HTML -> 压缩器 -> JSON -> 还原器 -> HTML -> 对比工具大模型适配实践
模型理解度测试(后续会测一个超大复杂表格,输入HTML、JSON表格,提问相同的问题)
请分析以下压缩表格数据:
### 表格元数据
- 标题: 铝合金机械性能
- 行数: 12
- 列数: 6
### 表头结构
[
[{"v":"合金牌号","r":2}, {"v":"拉伸性能","c":3}, {"v":"硬度"}],
[{"v":"抗拉强度"}, {"v":"屈服强度"}, {"v":"伸长率"}]
]
### 表格内容
[
["6061-T6", "310 MPa", "276 MPa", "12%", "95 HB"],
["7075-T6", "572 MPa", "503 MPa", "11%", "150 HB"]
]
请回答:
1. 7075-T6合金的屈服强度是多少?
2. 伸长率最高的合金牌号是什么?结论与展望
通过语义优先的压缩方案,我们成功实现:
- 50+%平均压缩率:突破大模型Token限制
- 结构无损压缩:保留关键表格语义
- 理解提升:优化模型表格处理能力
项目开源地址:#待续
"最好的压缩不是删减信息,而是优化表达" —— 让每个Token都承载最大价值。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)