LLaMA-Factory 微调与部署详细流程:从入门到实践
时隔已久的 llama-factory 系列教程更新了。本篇文章是第七篇,之前的六篇,大家酌情选看即可。
介绍
时隔已久的 llama-factory 系列教程更新了。本篇文章是第七篇,之前的六篇,大家酌情选看即可。
因为llama-factory进行了更新,我前面几篇文章的实现部分,都不能直接用了。
我将为大家介绍如何使用 llama-factory Lora 微调模型、部署模型、使用python调用API。
llama-factory 安装
首先建议大家阅读一遍两份不错的文章:
- 官方readme: https://github.com/hiyouga/LLaMA-Factory/blob/v0.9.1/README_zh.md
- 官方推荐的知乎教程:https://zhuanlan.zhihu.com/p/695287607
- 官方文档: https://llamafactory.readthedocs.io/zh-cn/latest/
我这篇博客的与他们的不同在于,我按照我做实验的流程,给大家演示一遍。方便大家一看就懂,心里对大致的流程有个大概。
装包
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
LLaMA-Factory 默认是从Huggingface 下载模型,建议大家改为从国内下载模型。
如果您在 Hugging Face 模型和数据集的下载中遇到了问题,可以通过下述方法使用魔搭社区。
export USE_MODELSCOPE_HUB=1
Windows 使用set USE_MODELSCOPE_HUB=1
将 model_name_or_path 设置为模型 ID 来加载对应的模型。在魔搭社区查看所有可用的模型,例如 LLM-Research/Meta-Llama-3-8B-Instruct。
您也可以通过下述方法,使用魔乐社区下载数据集和模型。
export USE_OPENMIND_HUB=1
Windows 使用set USE_OPENMIND_HUB=1
将 model_name_or_path 设置为模型 ID 来加载对应的模型。在魔乐社区查看所有可用的模型,例如 TeleAI/TeleChat-7B-pt。
下载模型
我喜欢使用可视化的网站页面下载模型权重。
llamafactory-cli webui
启动服务之后,进入主机对应的 ip 和端口就可以看到网页。
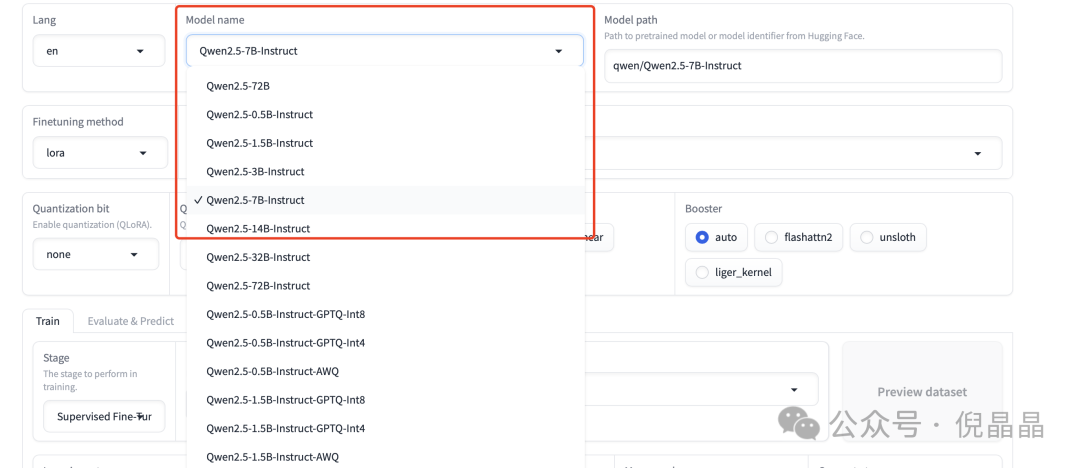
在 Model name 下拉框中挑选模型,选中之后,再点击下述的加载模型。如果模型权重没有下载,则会进行下载,然后加载进显存中。在下方就会出现对话框就可以与模型进行对话了。
微调模型
数据集
点击 Train 后, 就可以看到当前可用的很多数据集。
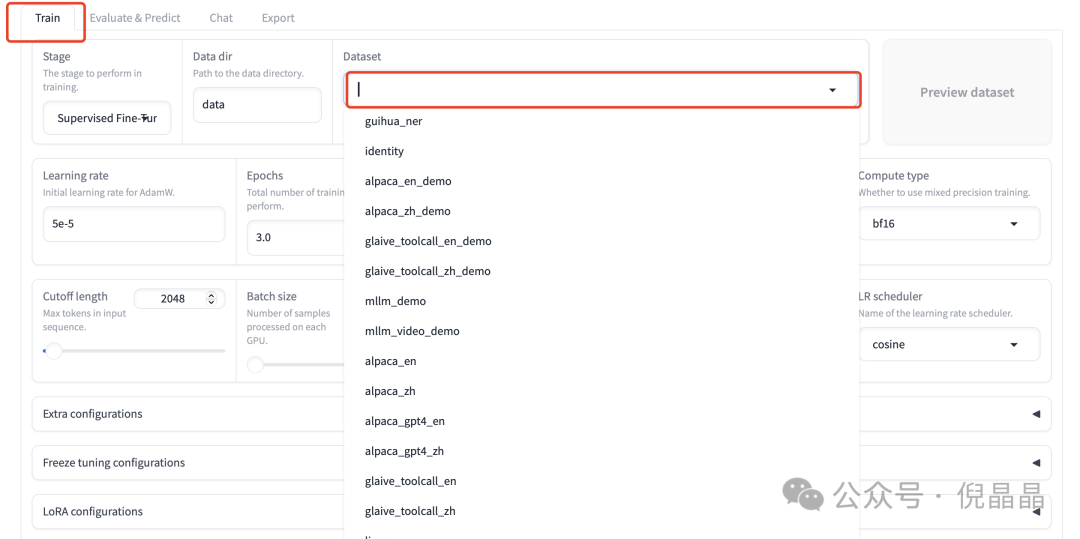
在选中数据集后,点击预览数据集,即可看到数据集的样例。如果我们想微调模型,也需要把数据集的样式给整理成上述格式。
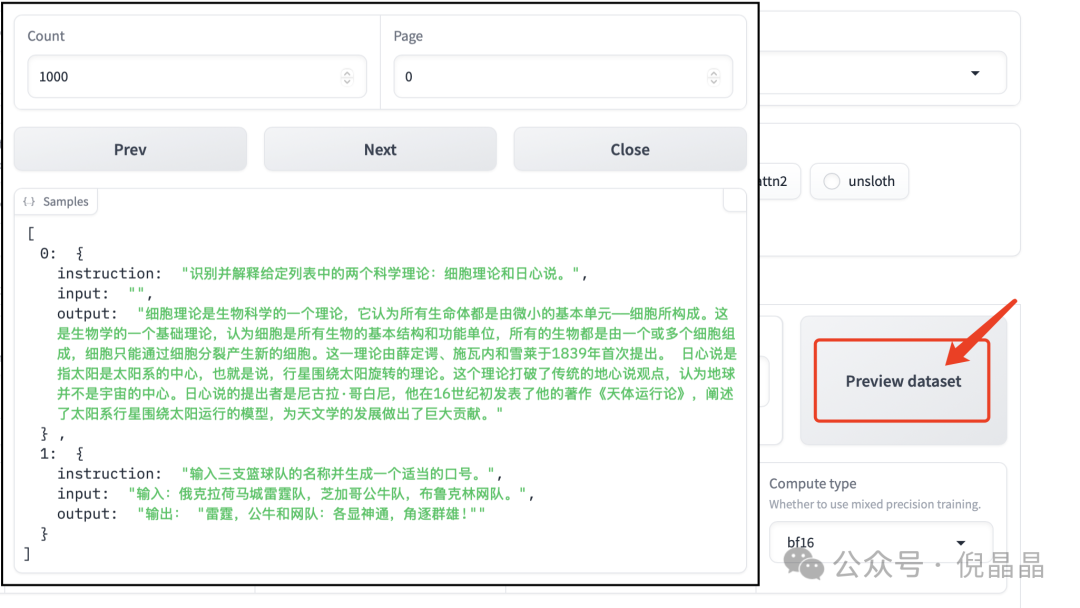
点击查看关于数据集的说明:https://github.com/hiyouga/LLaMA-Factory/tree/v0.9.1/data
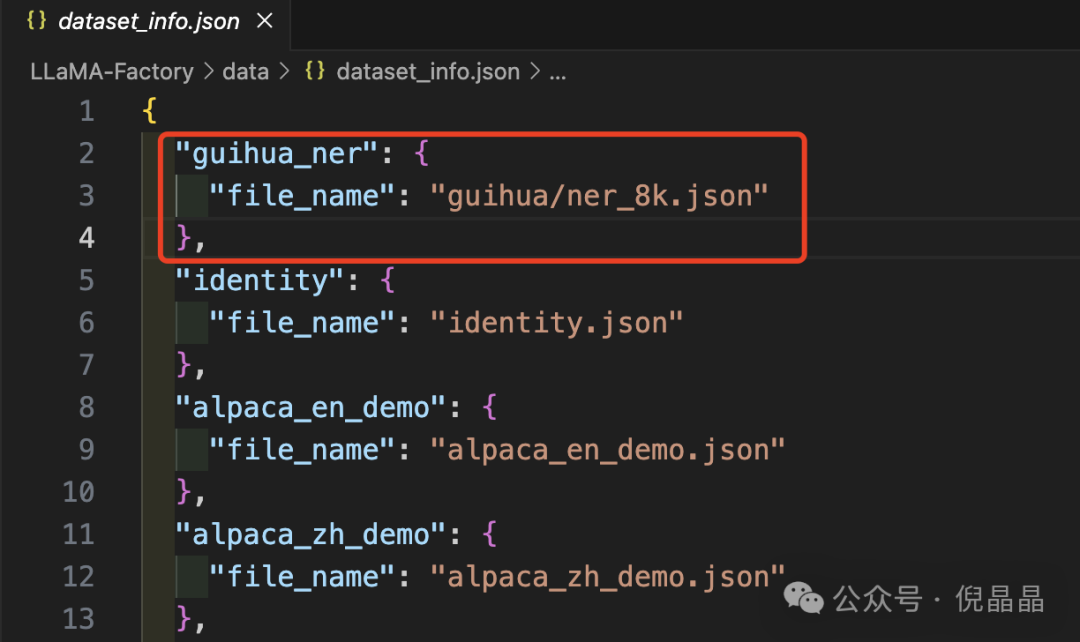
大家仿照alpaca_zh_demo.json的样式准备好数据集,然后在dataset_info.json完成数据集的注册。
注册数据集, 下图是我在dataset_info.json注册的guihua_ner数据集,然后就可以找到该数据集,并训练模型:
训练模型
可以直接点击可视化界面的 Start 按钮训练模型。也可点击预览命令查看在终端运行的命令。
我一般不使用可视化窗口训练模型。我喜欢直接运行训练模型的命令
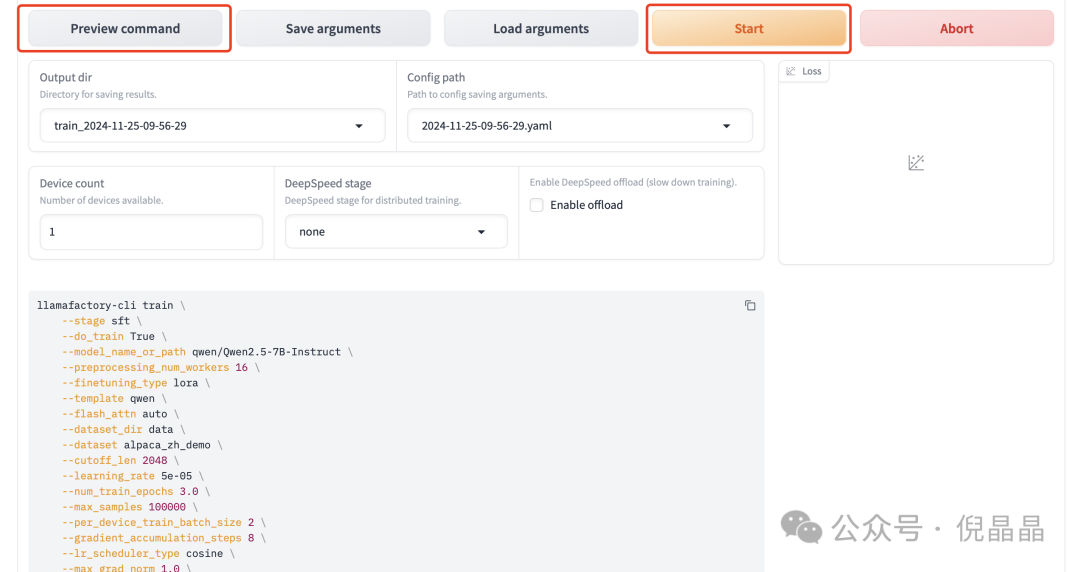
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path qwen/Qwen2.5-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_zh_demo \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-7B-Instruct/lora/train_2024-11-25-09-56-29 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
除了使用上述的命令行方式训练模型外,llama-factory还提供了使用 yaml 文件训练模型的方式。
在example文件夹下可看到很多训练和推理的 yaml 文件,针对其中的参数就行修改,即可使用。
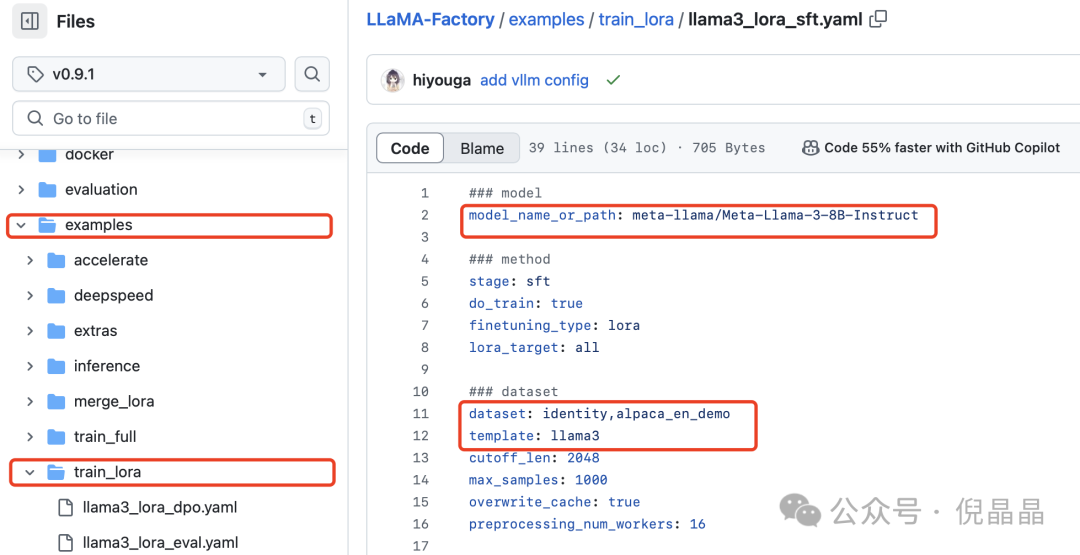
我以微调qwen/Qwen2.5-7B-Instruct为例:
qwen2.5-7B-ner.yaml文件内容:
### model
model_name_or_path: qwen/Qwen2.5-7B-Instruct
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: guihua_ner
template: qwen
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/qwen2.5-7B/ner_epoch5
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 5.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
在 llamafactory-cli train 后,填入 yaml 文件的路径:
llamafactory-cli train config/qwen2.5-7B-ner.yaml
然后就会开始训练模型,最终训练完成的模型保存在output_dir: saves/qwen2.5-7B/ner_epoch5。
在输出文件夹路径中,可以找到训练过程的损失值变化图片。
微调后的模型推理
在完成模型的微调后,测试一下模型的微调效果。对于微调模型推理,除原始模型和模板外,还需要指定适配器路径 adapter_name_or_path 和微调类型 finetuning_type。
lora_vllm.yaml的文件内容如下:
model_name_or_path: qwen/Qwen2.5-7B-Instruct
adapter_name_or_path: ../saves/qwen2.5-7B/ner_epoch5
template: qwen
finetuning_type: lora
infer_backend: vllm
vllm_enforce_eager: true
运行下述命令,就可以看到下图的对话窗口:
llamafactory-cli webchat lora_vllm.yaml
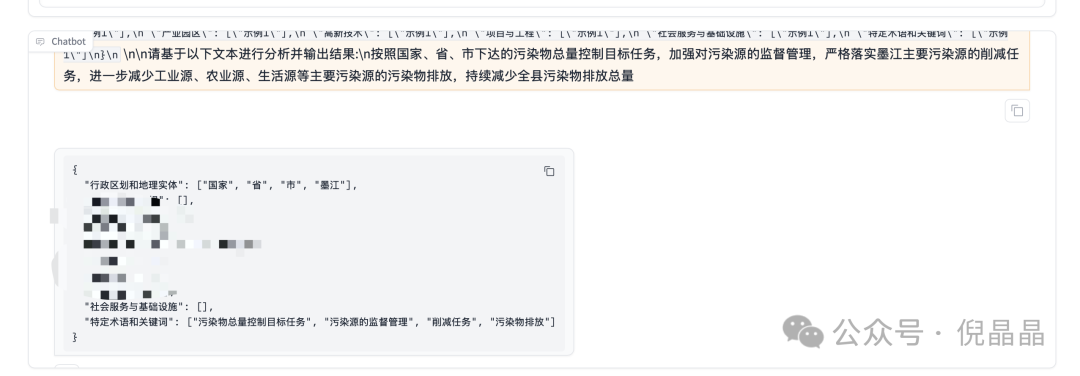
根据上图命名实体识别的输出,可以发现微调模型确实有效果。
除了网页聊天的部署之外,还可通过下述多种方式进行部署:
# llamafactory-cli chat xxx.yaml
# llamafactory-cli webchat xxx.yaml
# API_PORT=8000 llamafactory-cli api xxx.yaml我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献476条内容
已为社区贡献476条内容

所有评论(0)