2026 SIGMOD ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
ST-Raptor提出了一种基于大语言模型(LLM)的半结构化表格问答框架,通过创新的层次正交树(HO-Tree)表示法解决复杂表格布局处理难题。该框架将表格构建为元数据树和主体数据树,设计了流水线式问答机制,将复杂问题分解为原子操作步骤,并引入两阶段验证确保可靠性。实验在新构建的SSTQA数据集上进行,结果显示ST-Raptor比现有方法最高提升20%的准确率。该研究为金融、医疗等领域的半结构化
论文基本信息
- 题目: ST-Raptor: LLM-Powered Semi-Structured Table Question Answering (ST-Raptor: 基于大语言模型的半结构化表格问答)
- 作者: Zirui Tang, Boyu Niu, Xuanhe Zhou*, Boxiu Li, Wei Zhou, Jiannan Wang, Guoliang Li, Xinyi Zhang, Fan Wu
- 机构: Shanghai Jiao Tong University, Tsinghua University, Renmin University of China, Simon Fraser University
- 发表: arXiv预印本 (arXiv:2508.18190v3 [cs.AI]), 2025年9月2日
- 关键词与术语定义:
- Semi-Structured Table (半结构化表格): 一种数据结构,常见于Excel、PDF和Word中,具有灵活复杂的布局,如层次化表头、合并单元格等。
- Question Answering (QA): 基于给定的上下文(此处为半结构化表格)回答自然语言问题的任务。
- Hierarchical Orthogonal Tree (HO-Tree): 论文提出的一种树状结构模型,用于捕获半结构化表格复杂的布局、层次和内容关系。
- Pipeline-based QA: 一种问答策略,将复杂问题分解为一系列简单的子问题,并为每个子问题生成相应的操作流水线来执行。
摘要(详细复述)
- 背景: 半结构化表格(如财务报表、病历)在现实世界中广泛应用,但其复杂的布局(如层次化表头、合并单元格)给自动化问答带来了巨大挑战。现有方法,如将表格转换为结构化数据的NL2SQL或多模态大语言模型(LLM),在处理这些复杂布局时会遭遇信息丢失或理解困难的问题。
- 方案概述: 为此,论文提出了一个名为ST-Raptor的框架,这是一个基于树模型的半结构化表格问答系统。首先,ST-Raptor引入了层次正交树 (Hierarchical Orthogonal Tree, HO-Tree) 模型,该模型能有效捕获表格的复杂布局和隐含关系,并设计了相应的构建算法。其次,定义了一套基础树操作,以指导LLM执行常见的QA任务。当用户提问时,ST-Raptor会将其分解为更简单的子问题,生成相应的树操作流水线,并通过操作-表格对齐来确保执行的准确性。最后,该框架集成了一个两阶段验证机制(前向验证检查执行步骤,后向验证通过重构问题评估答案可靠性),以提升鲁棒性。
- 主要结果/提升: 为了评估模型性能,论文构建了一个新的基准数据集SSTQA,包含102个真实世界的半结构化表格和764个问题。实验结果显示,ST-Raptor在SSTQA上的答案准确率比九个基线模型最高提升了20%。
- 结论与意义: ST-Raptor框架通过新颖的树状表示和流水线化的问答机制,显著提升了在复杂半结构化表格上进行问答的准确性,为自动化处理这类数据提供了有效的解决方案。
研究背景与动机
-
学术/应用场景与痛点:
- 半结构化表格是金融、医疗、电商等领域的主要数据载体,例如,高达80%的电子病历(EMR)系统中的患者记录是半结构化表格。
- 人工解读这些表格成本高昂且效率低下。自动化问答(Table QA)旨在解决这一问题,但半结构化表格的“灵活和复杂的布局”(如层次化表头、合并单元格)是核心痛点。这些布局使得机器难以像理解传统关系型数据库一样理解表格的结构和语义。
-
主流路线与局限: 现有方法主要分为三类,但都存在明显局限。
| 方法类别 | 代表工作/技术 | 优点 | 局限与不足 |
|---|---|---|---|
| NL2SQL (自然语言转SQL) | ReAcTable, OpenSearch-SQL | 在结构化数据上表现良好,逻辑推理能力强。 | 1. 信息丢失: 强制将半结构化表格转换为扁平的关系表会丢失大量的层次和布局信息。 2. 转换困难: 转换过程本身就非常复杂且容易出错。 |
| NL2Code (自然语言转代码) | - | 可以利用代码(如Python Pandas)进行灵活的数据操作。 | 1. 结构理解失败: 难以理解复杂的嵌套和合并单元格,导致信息检索不准。 |
| VLM (视觉语言模型) | TableLLaVA, mPLUG-DocOwl1.5 | 能直接处理表格图像,保留了原始的二维布局信息。 | 1. 精度损失: Table2image转换可能导致文本信息模糊或丢失。 2. 泛化能力差: 需要在大量QA任务上进行微调。 3. 尺寸限制: 难以处理超过100行的大型表格。 |
问题定义(形式化)
给定一个半结构化表格 TTT 和一个用自然语言表达的问题 QQQ,半结构化表格问答(Semi-Structured Table QA)任务的目标是生成一个准确的答案 AAA。
该任务可以被形式化地定义为一个映射:
(T,Q)→A (T, Q) \rightarrow A (T,Q)→A
其中:
- TTT: 一个具有多层组织结构的半结构化表格。
- QQQ: 一个可能引用 TTT 中一个或多个子表的自然语言问题。
- AAA: 最终的答案,通过识别与 QQQ 相关的子表 {Tsub∣Tsub⊆T}\{T_{sub} | T_{sub} \subseteq T\}{Tsub∣Tsub⊆T} 并进行推理得出。
评测目标: 模型的性能主要通过答案准确率 (Answer Accuracy, Acc) 来衡量。对于摘要类问题,还会使用 ROUGE-L 作为辅助评价指标。
创新点(逐条可验证)
-
提出HO-Tree表示法: 论文设计了层次正交树 (HO-Tree),一种新颖的数据结构,专门用于表示半结构化表格。
- 如何做: HO-Tree将表格分解为元数据树(MTree,表示表头结构)和主体数据树(BTree,表示内容),并通过指针将两者关联。这种设计能够显式地建模层次化表头、合并单元格和正交子表等复杂关系。
- 为什么有效: 与将表格序列化为一维文本或图像的方法相比,HO-Tree保留了完整的二维结构和语义信息,避免了信息丢失,为后续的精确操作和推理奠定了基础。
-
设计流水线化的QA框架与原子操作: 论文提出了一个将复杂问题分解并以操作流水线形式执行的QA框架。
- 如何做: 框架包含一套预定义的原子树操作(如数据检索、操作和对齐)。LLM首先将复杂问题分解为子问题,然后为每个子问题生成一个由原子操作构成的流水线。
- 为什么有效: 这种分解-执行的模式降低了任务的复杂度,使得LLM可以专注于生成简单的、可执行的步骤,而不是一次性解决整个复杂问题。这提高了操作的准确性和整体的推理可靠性。
-
引入两阶段验证机制: 框架中包含一个前向和后向相结合的验证模块,用于确保执行的正确性和答案的可靠性。
- 如何做: 前向验证在每一步操作后检查其结果是否符合逻辑(如非空、与问题相关)。后向验证则基于最终答案反向生成一个新问题,并将其与原始问题进行比较,以评估答案的可靠性。
- 为什么有效: 该机制能有效过滤掉由LLM幻觉或错误推理产生的中间错误,防止错误累积,显著提升了最终答案的鲁棒性和可信度。
方法与核心思路(重点展开)
ST-Raptor的整体框架遵循一个模块化的处理流程,旨在将复杂的半结构化表格理解与问答任务解耦。
整体框架
ST-Raptor 包含四个核心模块:Table2Tree, Question2Pipeline, AnswerGenerator, 和 AnswerVerifier。
!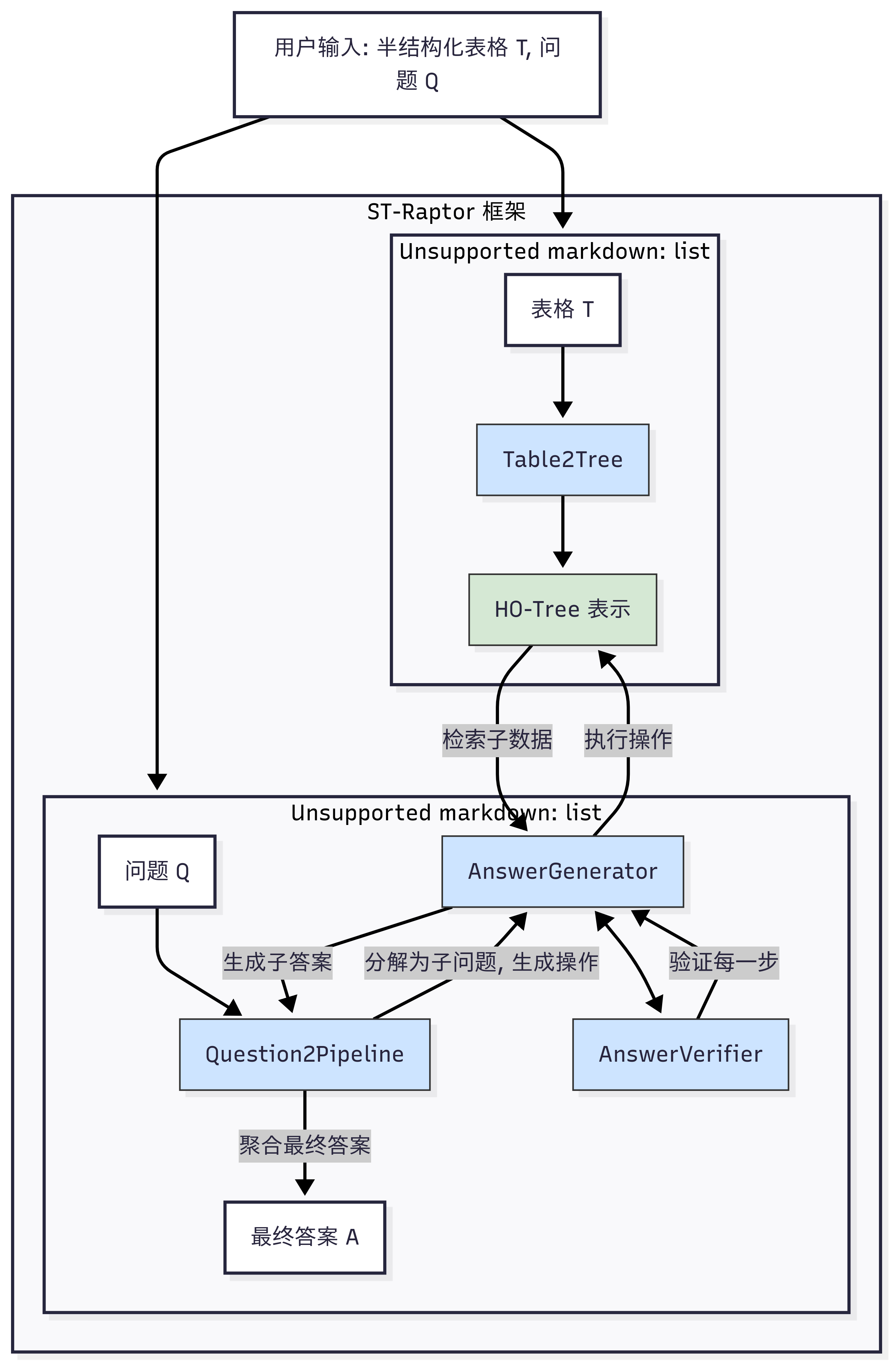
- Table2Tree: 将输入的半结构化表格(如Excel文件)转换为HO-Tree表示,并将其序列化存储。这个过程对于同一张表格只需执行一次。
- Question2Pipeline: 接收用户问题,将其分解为一系列更简单的子问题,并为每个子问题生成一个操作流水线。
- AnswerGenerator: 根据流水线中的指令,在HO-Tree上执行具体的操作(如查找、过滤、计算),并生成中间结果或最终答案。
- AnswerVerifier: 在整个执行过程中进行监控,通过两阶段验证机制确保每一步操作的正确性和最终答案的可靠性。
步骤 1: HO-Tree 构建 (Table2Tree模块)
这是方法的基础,旨在为复杂的表格结构建立一个精确的数学模型。构建过程分为三步:
-
元信息检测 (Meta Information Detection):
- 机制: 使用一个混合方法。首先,将表格渲染成HTML并截图,输入给一个视觉语言模型(VLM,如InterVL2.5)来初步识别所有可能的表头单元格。然后,使用嵌入模型(如Multilingual-E5-Large)计算这些候选表头与表格中所有单元格的语义相似度,超过阈值的单元格被确认为最终的元信息(即表头)。
- 目的: 准确地区分表头和数据内容,这是理解表格结构的关键第一步。
-
表格分区 (Table Partition):
- 机制: 基于识别出的表头位置,应用三条原则对表格进行递归分割:
- 顶层表头识别: 如果一个合并单元格跨越整行或整列,它被视为一个高级表头,其下方或右侧的区域被视为子表。
- 表头-内容区分: 当同时存在顶部对齐和左侧对齐的表头时,选择包含更多单元格的一方作为元数据树(MTree)的主干,另一方则整合进数据树(BTree)。
- 正交表格识别: 如果检测到多个并列的、结构独立的子表,则将它们分割开,并对每个子表递归地进行处理。
- 目的: 将一个复杂的大表格分解为若干个结构更简单的基本布局单元。
- 机制: 基于识别出的表头位置,应用三条原则对表格进行递归分割:
-
基于DFS的树模型构建 (DFS-based Tree Model Construction):
- 机制: 对每个分区后的子表,根据其布局类型(L.1-L.4)构建HO-Tree。使用深度优先搜索(DFS)算法,自顶向下构建MTree,自左向右构建BTree。在DFS的回溯阶段,将子表的HO-Tree作为节点值嵌入到父表的BTree中,从而重构出完整的、嵌套的HO-Tree。
- HO-Tree 定义:
- Meta Tree (MTree): 表示表头的结构和内容。从根到叶的每条路径代表一个列的抽象描述。
- Body Tree (BTree): 表示表格主体的结构和内容。每个节点是一个单元格值,从根到叶的每条路径代表一行数据。
- 关联: MTree的每个叶节点指向BTree中的一个层级,将表头(元数据)和列(数据)精确地关联起来。
- 伪代码 (Algorithm 1: HO-Tree Construction)
Algorithm 1: HO-Tree Construction (HOTC) Input: A Semi-Structured Table T Output: Extracted HO-Tree HOTree 1: MetaInfo ← MetaInfoDetect(T); 2: T_list ← TablePart(T, MetaInfo); 3: HOTree_list ← []; 4: for T_sub in T_list do 5: switch type(T_sub) do 6: case L1, L2, L4 do 7: HOTree_list.push_back(ConsTree(T_sub)); 8: case L3 do 9: HOTree_list.push_back(HOTC(T_sub)); // 递归调用 10: end 11: end 12: return ConsTree(HOTree_list);- 伪代码描述: 算法首先检测元信息,然后根据元信息将表格分区。接着,遍历所有子表,对于简单布局(L1, L2, L4)直接构建树,对于正交布局(L3)则递归调用自身进行构建。最后,将所有子树合并成一个完整的HO-Tree。
步骤 2: 问题分解与流水线生成 (Question2Pipeline模块)
-
问题分解 (Question Decomposition):
- 机制: 利用LLM的语义理解能力,将一个复杂的多跳问题(multi-hop question)分解为多个相互依赖的单步子问题。例如,问题“A和C部门评级高于A的员工有多少人?”会被分解为:
- SQ1: A部门评级高于A的员工有多少人?
- SQ2: C部门评级高于A的员工有多少人?
- SQ3: 将SQ1和SQ2的结果相加。
- 目的: 降低每个步骤的推理难度,使之能被一个简单的操作流水线解决。
- 机制: 利用LLM的语义理解能力,将一个复杂的多跳问题(multi-hop question)分解为多个相互依赖的单步子问题。例如,问题“A和C部门评级高于A的员工有多少人?”会被分解为:
-
流水线生成 (Pipeline Generation):
- 机制: 对每个子问题,LLM会从一个预定义的原子操作集中选择并组合操作,形成一个执行流水线。
- 原子操作集 (Table 3):
- 数据检索:
Children(V)(获取子节点),Father(V)(获取父节点),Value(V1, V2)(交叉取值)。 - 数据操作:
Condition(D, Func)(过滤),Calculation(D, Func)(计算),Compare(D1, D2, Func)(比较)。 - 对齐与推理:
Align(P, HO-Tree)(将参数与表格内容对齐),Reason(Q, D)(基于检索到的数据D回答问题Q)。
- 数据检索:
- 示例 (SQ1): “A部门评级高于A的员工有多少人?”对应的流水线可能为:
Cond([Department]->, == 'A'): 筛选出“Department”为“A”的行。Cond([Level]->, > 'A'): 在上一步结果中,筛选出“Level”大于“A”的行。Math([name]->, count()): 对最终结果中的“name”列进行计数。
步骤 3: 答案生成与验证 (AnswerGenerator & AnswerVerifier模块)
-
执行与检索 (AnswerGenerator):
- 机制: AnswerGenerator 负责执行流水线中的每个操作。它采用top-down(从表头到内容)和bottom-up(从内容到表头)相结合的检索策略。通常先尝试top-down,如果失败(如问题中未明确提及表头),则切换到bottom-up。
- 对齐操作: 在执行前,
Align操作会使用嵌入模型将操作中的参数(如 “Department”)与HO-Tree中最相似的节点进行匹配,确保操作对象正确。
-
两阶段验证 (AnswerVerifier):
- 前向验证 (Forward Verification): 在每个操作执行后,验证其中间结果是否有效(例如,不为空,与子问题相关)。如果结果无效或不充分,系统会重新生成操作或终止流水线并返回“无法回答”。这可以有效减少LLM的幻觉。
- 后向验证 (Backward Verification): 在得到最终答案后,系统会基于该答案生成几个新的、语义相似的问题。然后,它会为这些新问题生成操作流水线,并计算这些新流水线与原始流水线的相似度。高相似度意味着原始的推理路径是可靠的。
复杂度分析
- 时间复杂度:
- HO-Tree构建:主要开销在于VLM和嵌入模型的调用,以及遍历表格所有单元格进行分区的过程。对于一个有 NNN 个单元格的表格,该过程大致为 O(N)O(N)O(N)。
- 问答过程:主要耗时在于多次调用LLM进行分解、生成操作和推理。设问题被分解为 kkk 个子问题,每个子问题平均需要 ccc 次LLM调用,则复杂度与 k×ck \times ck×c 相关。树操作本身非常快。
- 空间复杂度:
- HO-Tree:最坏情况下需要存储表格中所有单元格的内容和结构关系,空间复杂度为 O(N)O(N)O(N)。
实验设置
- 数据集:
- SSTQA (新提出): 包含102个来自19个真实场景(如行政、财务管理)的半结构化表格和764个问答对。表格具有深度嵌套和结构不规则的特点。
- WikiTQ-ST: WikiTQ的子集,包含符合半结构化定义的表格。
- TempTabQA-ST: TempTabQA的子集,专注于时序问题的半结构化表格。
| 数据集 | 嵌套深度 (Avg) | 合并率 (Avg) | 单元格数 (Avg) | 单元格内容长度 (Avg) |
|---|---|---|---|---|
| SSTQA | 2.5196 | 0.0544 | 147.4608 | 2.7287 |
| WikiTQ | 1.2970 | 0.0091 | 178.3564 | 1.9568 |
| TempTabQA | 2.0000 | 0.1780 | 44.8350 | 3.6696 |
-
对比基线:
- NL2SQL: OpenSearch-SQL
- 基础模型: GPT-4o, DeepSeekV3
- 微调模型: TableLLaMA, TableLLM
- Agent方法: ReAcTable
- VLM方法: TableLLaVA, mPLUG-DocOwl1.5
-
评价指标:
- Answer Accuracy (Acc): 答案的精确匹配率,使用LLM辅助判断语义等价性。
- ROUGE-L: 用于评估摘要类问题的答案质量。
-
实现细节:
- VLM: InterVL2.5 26B
- 通用LLM: Deepseek-V3
- 嵌入模型: Multilingual-E5-Large
- 推理耗时: ST-Raptor处理每个问题平均约30秒(不考虑网络延迟),平均包含2.89个流水线操作。
实验结果与分析
主结果表
ST-Raptor在所有三个基准测试中均显著优于其他所有基线模型,尤其是在复杂的SSTQA数据集上。
| 方法 | WikiTQ-ST (Acc) | TempTabQA-ST (Acc) | SSTQA (Acc) | SSTQA (ROUGE-L) |
|---|---|---|---|---|
| OpenSearch-SQL (NL2SQL) | 38.89 | 4.76 | 24.00 | 23.87 |
| ReAcTable (Agent) | 68.00 | 35.88 | 37.24 | 7.49 |
| TableLLM (Finetune) | 62.40 | 9.13 | 7.84 | 2.93 |
| TableLLaVA (VLM) | 20.41 | 6.91 | 9.52 | 5.92 |
| GPT-4o (Foundation) | 60.71 | 74.83 | 66.45 | 43.86 |
| DeepSeekV3 (Foundation) | 69.64 | 63.81 | 63.22 | 46.17 |
| ST-Raptor (Ours) | 71.17 | 77.59 | 72.39 | 52.19 |
- 分析:
- 在最复杂的 SSTQA 数据集上,ST-Raptor 的准确率(72.39%)比第二好的基础模型 GPT-4o(66.45%)高出近 6%,比其他专用模型(如ReAcTable)高出超过 35%,展示了其在处理真实世界复杂表格上的巨大优势。
- 在 TempTabQA-ST 上,ST-Raptor(77.59%)也超过了表现强劲的GPT-4o(74.83%),说明其结构化建模对特定类型问题(如时序)同样有效。
- 传统的NL2SQL和VLM方法在半结构化任务上表现不佳,验证了背景分析中的局限性。
消融实验
为了验证ST-Raptor中各个模块的贡献,论文进行了消融实验(在SSTQA上)。
| 模型配置 | Acc (下降) | ROUGE-L (下降) | 作用分析 |
|---|---|---|---|
| Full Model (ST-Raptor) | 72.39% | 52.19% | - |
| w/o Table2Tree | 57.24% (-15.15%) | 41.55% (-10.64%) | 证明HO-Tree是框架的基石,没有它,模型无法理解复杂布局,性能急剧下降。 |
| w/o Question Decomposition | 68.06% (-4.33%) | 48.09% (-4.10%) | 表明问题分解对处理多跳推理至关重要,否则模型难以形成正确的推理链。 |
| w/o Data Manipulation Operation | 65.09% (-7.30%) | 47.13% (-5.06%) | 说明很多问题需要过滤、计算等操作,仅靠检索和纯推理无法解决。 |
| w/o Answer Verifier | 66.10% (-6.29%) | 47.46% (-4.73%) | 验证了自验证机制在检测和纠正执行错误、提升输出可靠性方面的关键作用。 |
| w/o Operation-Table Alignment | 71.07% (-1.32%) | 50.86% (-1.33%) | 显示显式的对齐操作能进一步提升精度,但LLM本身也具备一定的隐式对齐能力。 |
复现性清单
- 代码/数据:
- 代码已在GitHub上开源:
https://github.com/weAIDB/ST-Raptor - SSTQA数据集也随代码一同发布。
- 代码已在GitHub上开源:
- 模型权重: 论文依赖于公开的LLM和VLM模型(Deepseek-V3, InterVL2.5, Multilingual-E5-Large),无需提供特定权重。
- 环境与依赖: 未详细说明具体的库版本,但提到了使用的模型框架。
- 运行命令/配置文件: 未在论文中提供。
- 评测脚本: 开源项目中应包含。
结论与未来工作
- 结论: 论文成功地提出了ST-Raptor,一个基于HO-Tree表示和流水线化问答的框架,有效解决了半结构化表格问答中的核心挑战。实验证明,该方法通过精确的结构建模、模块化的问题分解和可靠的验证机制,在处理复杂真实世界表格方面显著优于现有SOTA方法,准确率最高提升了20%。
- 未来工作:
- 局限性: ST-Raptor可能难以处理某些不规则的布局模式,例如将水平合并的内容单元格错误地识别为表头。
- 后续方向: 对于需要极复杂流水线(类似多层嵌套SQL查询)的问题,性能仍有提升空间,未来可以研究专门针对此类问题的LLM微调技术。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)