颠覆影视圈!全球首个开源「无限时长」电影生成模型炸场:昆仑万维把视频生成卷到新时代
Prompt Adherence(提示词遵循):现有通用多模态大语言模型(MLLM)难以理解电影语法(如镜头构图、演员表情、摄像机运动),导致生成的视频不符合专业电影风格。Motion Dynamics(运动动态):现有方法在优化时往往牺牲运动质量以提升视觉质量,导致动态效果不足。Video Duration(视频时长):现有模型受限于分辨率优化,通常只能生成5-10秒的短视频,难以实现长视频合成

文章链接:https://arxiv.org/pdf/2504.13074
代码&模型链接:https://github.com/SkyworkAI/SkyReels-V2

SKyReels-V2 生产惊人的现实和电影的高分辨率视频几乎无限长度
亮点直击
全面的视频标注器,既能理解镜头语言,又能捕捉视频的通用描述,从而显著提升提示词遵循能力。
针对运动优化的偏好学习,通过半自动数据收集流程增强运动动态表现。
高效的扩散强制适配,支持超长视频生成和故事叙述能力,为时序连贯性和叙事深度提供稳健框架。
开源 SkyCaptioner-V1 及 SkyReels-V2 系列模型,包括扩散强制、文生视频、图生视频、导演模式和元素生视频模型,并提供多种参数量级(1.3B、5B、14B)。
总结速览
解决的问题
-
Prompt Adherence(提示词遵循):现有通用多模态大语言模型(MLLM)难以理解电影语法(如镜头构图、演员表情、摄像机运动),导致生成的视频不符合专业电影风格。
-
Motion Dynamics(运动动态):现有方法在优化时往往牺牲运动质量以提升视觉质量,导致动态效果不足。
-
Video Duration(视频时长):现有模型受限于分辨率优化,通常只能生成5-10秒的短视频,难以实现长视频合成。
-
Training Stability(训练稳定性):现有扩散模型和自回归模型结合方法(如Diffusion-forcing Transformers)存在噪声调度不稳定问题,影响收敛。
提出的方案
-
结构化视频表示(Structural Video Representation):结合通用MLLM描述和专家模型(如镜头类型、摄像机运动)的细粒度标注,提升电影风格生成能力。
-
统一视频标注模型(SkyCaptioner-V1):通过知识蒸馏整合通用MLLM和专家模型的标注能力,提高视频描述的准确性和专业性。
- 多阶段训练策略(Multi-stage Training):
-
渐进分辨率预训练(Progressive-resolution Pretraining):优化基础视频生成能力。
- 四阶段后训练增强(4-stage Post-training):
-
概念平衡的监督微调(SFT):提升基线质量。
-
基于强化学习的运动优化(RL Training):利用人工标注和合成失真数据优化动态效果。
-
扩散强制框架(Diffusion Forcing Framework):采用非递减噪声调度,降低搜索空间复杂度,支持长视频合成。
-
高质量SFT微调:进一步提升视觉保真度。
-
-
应用的技术
-
多模态大语言模型(MLLM):用于通用视频描述生成(如Qwen2.5-VL)。
-
专家模型(Sub-expert Models):针对电影语法(镜头、表情、摄像机运动)进行细粒度标注。
-
强化学习(RL):优化运动动态,减少人工标注成本(半自动偏好数据生成)。
-
扩散强制框架(Diffusion Forcing):结合扩散模型的高保真和自回归模型的时序一致性,支持长视频生成。
-
渐进训练(Progressive Training):从低分辨率到高分辨率逐步优化模型。
达到的效果
- State-of-the-art性能:
-
在V-Bench评测中排名第一(截至2025-02-24)。
-
在提示词遵循(尤其是电影语法)、运动质量和长视频生成方面表现最优。
-
-
支持无限时长视频生成:通过扩散强制框架和非递减噪声调度,突破传统5-10秒限制。
-
专业电影风格生成:能够生成符合电影语法(如镜头构图、摄像机运动)的高质量视频。
-
多样化应用:支持故事生成、图生视频、导演模式(Camera Director)、元素生成视频等。
方法
本节全面概述了本文的方法框架。下图2展示了训练流程。首先详述数据处理流程,接着解释视频标注器架构,随后描述多任务预训练策略,并在阐述后训练优化技术——包括强化学习、扩散强制训练以及高质量监督微调(SFT)阶段。还概述了训练与推理的计算基础设施。为验证方法有效性,进行了与前沿基线的系统对比,展示了模型的实际应用场景,包括故事生成、图生视频、导演模式和元素生视频生成。
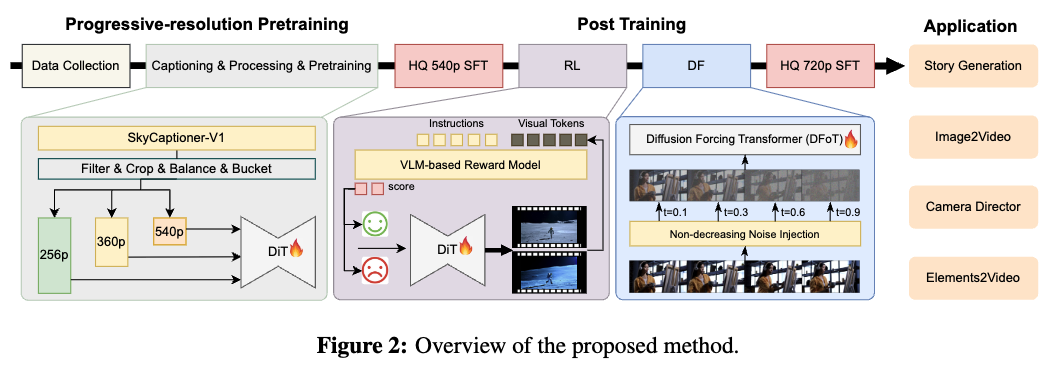
数据处理
数据处理是视频模型训练的基石。本文的框架整合了三个核心组件——数据源、处理Pipeline和人工循环验证——以确保严格的质控标准。如图3所示,处理Pipeline采用从宽松到严格的渐进过滤策略,在训练过程中逐步缩减数据规模的同时提升质量。该Pipeline首先处理来自多样化数据源的原始输入,随后通过自动化流程按不同过滤阈值控制样本质量。关键支柱是人工循环验证,其重点是对原始数据源及各阶段训练样本进行人工评估。通过在数据输入、Pipeline输出等关键节点进行系统化抽样检查,可识别并修正模糊、错误或非合规数据,最终保障模型训练所需的高质量数据。
数据源
针对电影生成模型的目标,多阶段质控框架整合了三类数据源:
-
通用数据集:整合开源资源如Koala-36M、HumanVid及网络爬取的额外视频;
-
自采影视库:包含28万+部电影和80万+集电视剧(覆盖120+国家,总时长预估620万+小时);
-
艺术资源库:来自互联网的高质量视频素材。原始数据规模达量级,各训练阶段按质量需求使用不同子集。我们还收集了概念平衡的图像数据以加速早期训练阶段的生成能力建立。
处理Pipeline
如下图3所示,为构建训练数据池,原始数据需经过两项预处理:镜头分割和标注,随后通过不同训练阶段的数据过滤器处理质量问题。
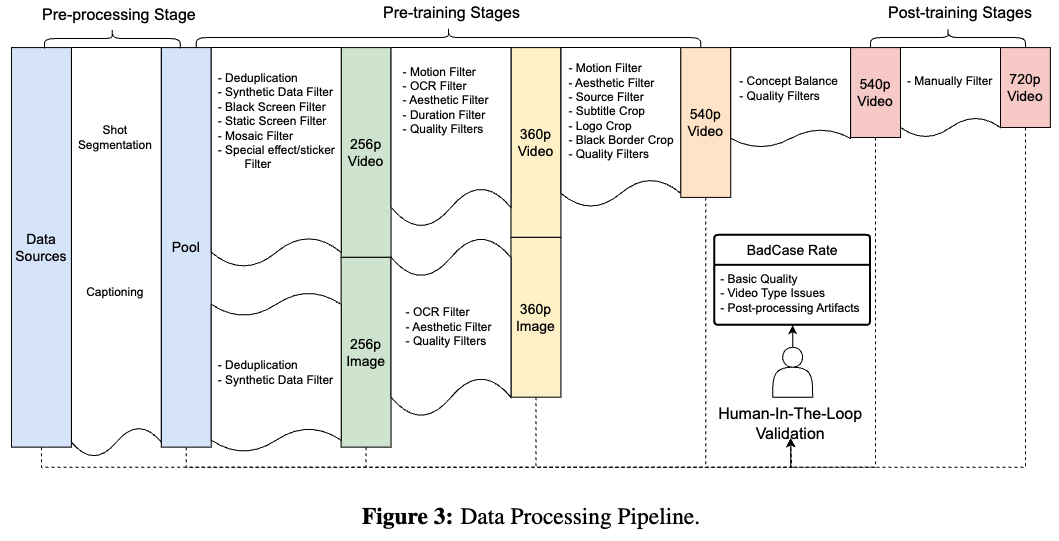
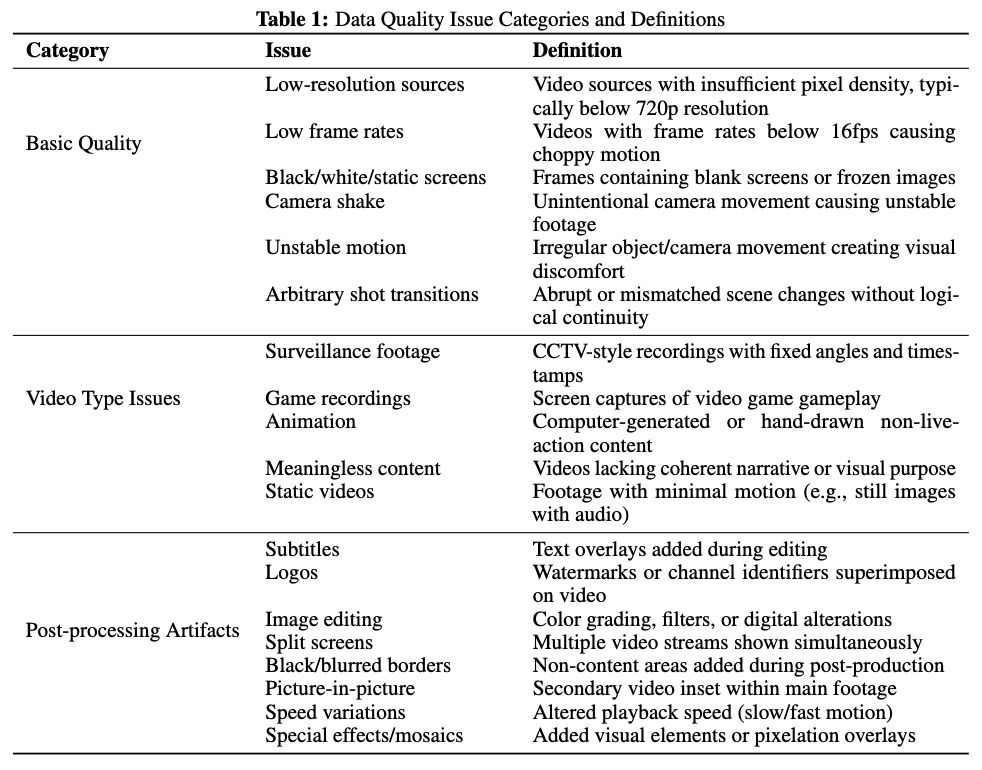
系统化分析将数据问题分为三类:
-
基础质量:低分辨率、低帧率、黑/白/静态画面、镜头抖动、运动不稳定、随意镜头切换;
-
视频类型问题:监控录像、游戏录屏、动画、无意义内容、静态视频;
-
后处理伪影:字幕、台标、图像编辑、分屏、黑/模糊边框、画中画、变速、特效/马赛克(详见下表1)。
使用数据裁剪器修复特定质量问题,并进行数据平衡以确保模型泛化性。预训练阶段生成多阶段预训练数据,后训练阶段生成后训练数据。
预处理阶段
包含两个流程:
-
镜头分割:所有原始视频通过PyDetect和TransNet-V2进行镜头边界检测,分割为单镜头片段;
-
标注:分割后的单镜头片段使用下面的层次化标注系统进行标注。
预处理完成后,训练数据池将经历多级数据过滤(各阶段阈值不同),同时引入数据裁剪器修复质量问题。
数据过滤器细节
本部分将阐述数据过滤器的分类及具体细节。数据过滤器由元素过滤器和质量过滤器组成,用于不同训练阶段的数据筛选。
元素过滤器
用于评估特定质量问题的严重程度,包括两类:
-
基于分类的过滤器:检测问题是否存在或分类;
-
基于评分的过滤器:根据质量需求设置不同阈值。
具体包括:
-
黑屏过滤器:使用启发式规则检测黑屏数据;
-
静态画面过滤器:通过光流计算得分检测静态画面;
-
美学过滤器:调用美学模型获取评分;
-
去重:利用拷贝检测嵌入空间的相似性消除感知冗余片段,提升预训练集多样性;
-
OCR过滤器:分析文本存在性并计算文本区域占比,根据训练阶段裁剪数据;
-
马赛克过滤器:训练专家模型检测马赛克区域;
-
特效/贴纸过滤器:训练专家模型识别特效或贴纸。
此外,还整合了多种质量过滤器,例如:
-
视频质量评估模型(VQA)
-
图像质量评估模型(IQA)
-
视频训练适用性评分(VTSS)
这些模型将在特定训练阶段后启用,并设置不同阈值进行数据筛选。图3展示了不同训练阶段中过滤器的应用情况。
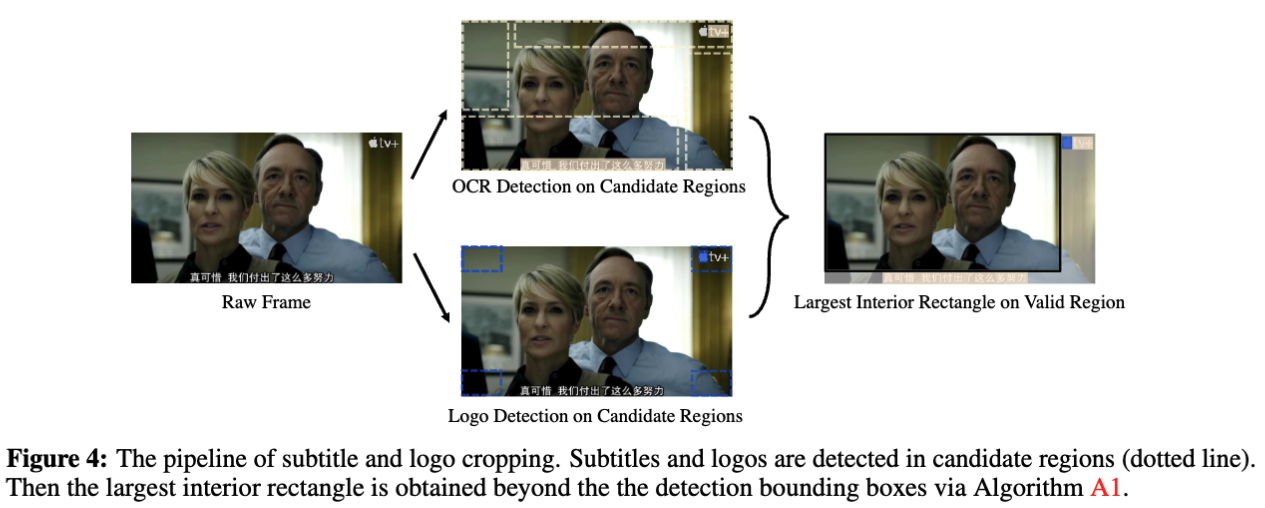
字幕与台标裁剪细节
大部分训练数据来自影视剧,可能包含影响生成质量的字幕和台标。直接丢弃此类数据会造成浪费,因此我们依次执行以下处理:
- 黑边裁剪(预处理):
-
基于启发式方法裁剪黑边,为字幕检测提供更干净的数据;
-
- 字幕检测:
-
定义四个候选区域(帧顶部20%、底部40%、左右各20%);
-
- 台标检测:
-
聚焦四角区域(各占帧宽/高的15%);
-
使用MiniCPM-o模型检测并记录台标坐标;
-
- 视频裁剪:
-
构建与视频帧尺寸匹配的二进制矩阵(字幕/台标区域标记为0,其余为1);
-
应用单调栈算法(详见算法A1)定位仅含1的最大内部矩形;
-
若该矩形覆盖原帧80%以上面积且宽高比接近原帧,则按坐标裁剪所有帧并保存为新片段,否则丢弃数据。
-
完整流程如图4所示。
后训练阶段的数据平衡
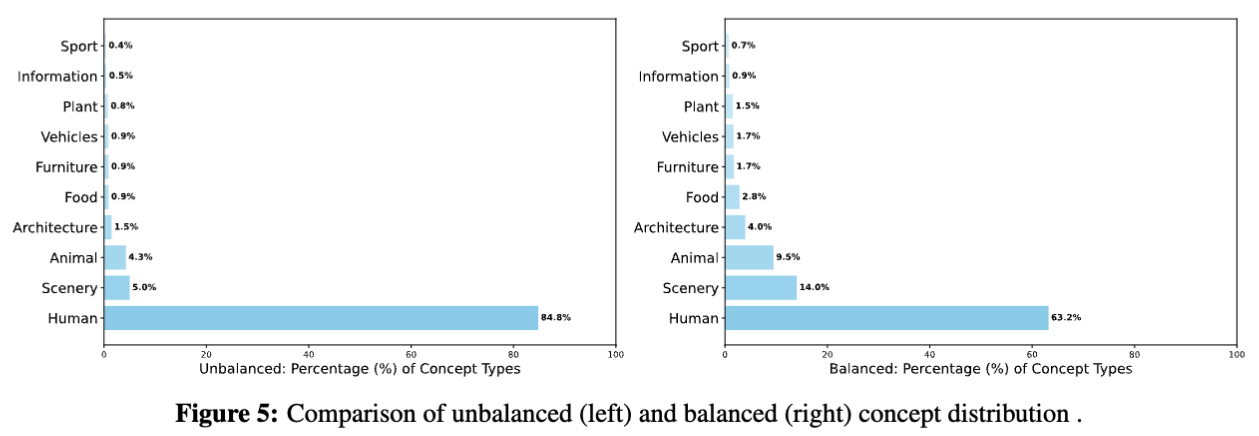
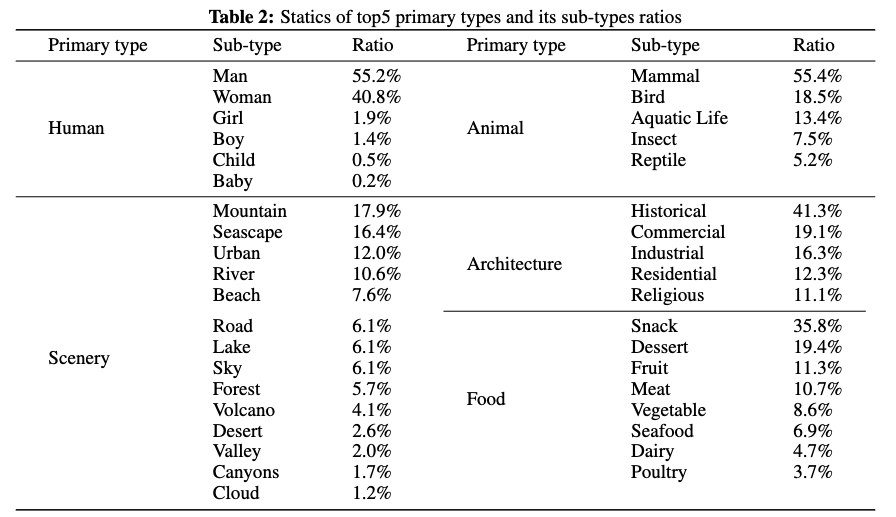
在后训练阶段,基于标注器的主语类别进行细粒度概念平衡,使数据量减少50%。下图5展示了平衡前后按主类别分组的概念分布对比。平衡后,还统计了每个主类别下子类别的分布情况。下表2详细列出了前五类主类别的子类别统计数据。
人工参与式验证
人工参与式验证(Human-In-The-Loop Validation)要求在数据生产的每个阶段——数据源(Data Sources)、镜头分割(Shot Segmentation)、预训练(Pre-training)和后训练(Post-training)——进行人工视觉检查,以确保模型训练所用数据的高质量。对于数据源,人工需主观评估原始数据是否适合使用。在镜头分割阶段,审核人员会检查样本,确保错误镜头(如错误转场)比例低于1%。预训练阶段会对数据进行过滤,并手动检查0.01%的样本(每10,000个样本检查1个),以满足严格限制:总体不良案例(如质量差、内容类型错误或处理问题)必须低于15%,其中子类别要求包括基础质量问题<3%、视频类型问题<5%和后处理缺陷<7%。后训练阶段采用相同的0.1%抽样率(每1,000个样本检查1个),但标准更严格:总不良案例需低于3%,包括基础质量<0.5%、视频类型问题<1%和后处理缺陷<1.5%。
通过人工检查得出的不良案例率来确定数据源批次的可用性。若某批次的不良案例率超过预设阈值,将采取丢弃或进一步优化该批次等措施。此外,会根据不同数据源的特点调整过滤参数。例如,对于质量问题频发的数据源,会加强质量相关过滤条件。这种分阶段人工评估确保了数据质量始终维持在较高水平,从而助力模型高效训练。
视频描述生成器
本文的视频描述生成器(Video Captioner)旨在通过结合结构化描述格式与专业化子专家描述器,生成精确的视频描述。其目标包括:1)纠正多模态大语言模型(MLLM)的错误或幻觉信息;2)持续优化动态视频元素(如镜头信息、表情和摄像机运动);3)根据应用场景(文本生成视频或图像生成视频)动态调整描述长度。
本文设计了如下图6所示的结构化描述,从多维度提供不同视角的详细信息,包括:1)主体:主要和次要实体及其属性(如外观、动作、表情、位置、层级类别/类型,例如“动物→哺乳动物”);2)镜头元数据:镜头类型、镜头角度、镜头位置、摄像机运动、环境、光线等。我们使用基础模型Qwen2.5-VL-72B-Instruct生成这些初始结构化信息,但部分信息会被专家描述器的结果替换以获得更精准的描述。最终,我们通过融合结构化数据为不同模型生成最终描述:1)文本生成视频:生成密集描述;2)图像生成视频:聚焦“主体+时序动作/表情+摄像机运动”。每个描述字段遵循10%的丢弃率,以适应不同用户场景(用户可能无法精确描述每个字段)。

子专家标注器
镜头标注器
镜头标注器由三个子标注器组成,分别描述镜头的不同方面。包括镜头类型、镜头角度和镜头位置。将这些方面定义为分类问题。
1)镜头类型:特写镜头、极特写镜头、中景镜头、远景镜头和全景镜头。
2)镜头角度:平视镜头、高角度镜头、低角度镜头。
3)镜头位置:背面视角、正面视角、头顶视角、肩上视角、主观视角和侧面视角。
本文的训练方法采用精心设计的两阶段策略来开发强大的镜头分类器。第一阶段,使用网络图像训练初步分类器,以建立基线性能(使用类别标签作为触发词从网络抓取数据)。该低精度模型主要用于从我们的电影数据集中提取在所有目标类别中均衡的真实世界场景数据。第二阶段专注于通过对真实电影数据的人工标注来开发高精度专家分类器,每个类别包含2,000个精心标注的样本。
这些标注样本构成我们最终高精度分类器的训练集,这些分类器专门针对真实电影视频中的镜头类型、镜头角度和镜头位置分类进行了优化。这种多阶段训练方法既确保了训练数据集中类别的均衡,又保证了生产应用中的高分类精度。
为了评估三个分类器的性能:镜头类型、镜头角度和镜头位置。构建了一个包含每个标签100个人工标注样本的均衡测试集。评估结果显示,镜头类型分类的平均准确率为,镜头角度分类为,镜头位置分类为。尽管镜头位置分类器表现强劲,但镜头类型和镜头角度分类器在未来仍有提升空间,尤其是在增强数据均衡性和提高场景与角度分类任务的标注质量方面。
表情标注器
表情标注器提供对人类面部表情的详细描述,重点关注几个关键维度:
1)情绪标签:情绪分为七种常见类型,即中性、愤怒、厌恶、恐惧、高兴、悲伤和惊讶。
2)强度:情绪的强度被量化,例如“轻微愤怒”、“中度快乐”或“极度惊讶”,表示情绪的强度。 3)面部特征:构成情绪表达的物理特征,包括眼睛形状、眉毛位置、嘴角弯曲程度、皱纹和肌肉运动。
4)时间描述:捕捉情绪在时间上的动态变化,重点是情绪如何演变以及这些变化在视频中的时间点。
表情标注生成包含两个阶段:
1)首先检测并裁剪人脸,并使用情绪分类器对其情绪进行分类。
2)然后将情绪标签和视频帧输入VLM模型以生成详细的表情标注。适配了S2D 的框架,并使用约内部数据集对模型进行训练,聚焦于人类与非人类角色。对于VLM模型,使用InternVL2.5生成基于帧的描述,并将情绪标签作为先验,通过链式思维提示策略对描述进行优化,生成最终表情标注。
为了验证本文的情绪分类器性能,编制了一个包含1,200个视频的测试集。该分类器在所有情绪类别中的平均准确率为。对于表情标注器,收集了560个视频样本,并邀请人工标注人员从四个关键维度评估模型的有效性。标注器在情绪标签方面的准确率为,在情绪强度评估方面为,在面部特征识别方面为,在时间描述准确性方面为。这些结果突显了本文模型在捕捉视频内容中细腻情绪和表情细节方面的鲁棒性。
摄影机运动标注器
本文的框架通过一个三级处理管线整合“运动复杂度过滤”、“单类型运动建模”和“单类型运动数据整理”,采用分层分类策略对摄影机运动进行建模。
1)运动复杂度过滤:该阶段通过双重检测机制消除琐碎和过于复杂的运动。首先是一个二元静态镜头检测器(准确率)筛选出无动作片段,随后使用专门分类器处理不规则模式(手持抖动、对象跟踪、突变位移),这些分类器基于人工标注数据训练。通过筛选的片段被视为标准的单类型运动。
2)单类型运动建模:使用六自由度(6DoF)坐标对运动进行参数化(平移x/y/z;旋转滚转/俯仰/偏航),每个轴被离散化为负(-)、中性(0)或正(+)状态。再结合三种速度级别(慢:,中:,快:帧位移/秒),共形成种不同的运动组合。训练数据由人工标注与合成样本共同组成。
3)单类型运动数据整理:实施五轮主动学习以实现高效的标注扩展。以人工标注样本作为初始训练,迭代预测未标注数据,平衡采样预测结果用于验证,然后通过微调精化模型。该流程最终产出高置信样本,并额外补充在运动轴上均衡的合成数据。合成数据确保每个自由度轴的正/负状态具有相等代表性。所有数据用于训练基于分类的标注器以实现运动识别。
在视频测试集上的评估结果为:单类型运动预测准确率为,复杂运动中手持运动为,跟随对象为,突变位移为,静态镜头检测准确率为。
SkyCaptioner-V1:结构化视频描述模型
SkyCaptioner-V1作为最终用于数据标注的视频描述模型,该模型基于基础模型Qwen2.5-VL-72B-Instruct的描述结果和子专家描述器在平衡视频数据上进行训练。平衡视频数据集是从1000万初始样本池中精心筛选出的约200万视频样本,旨在保证概念平衡与标注质量。
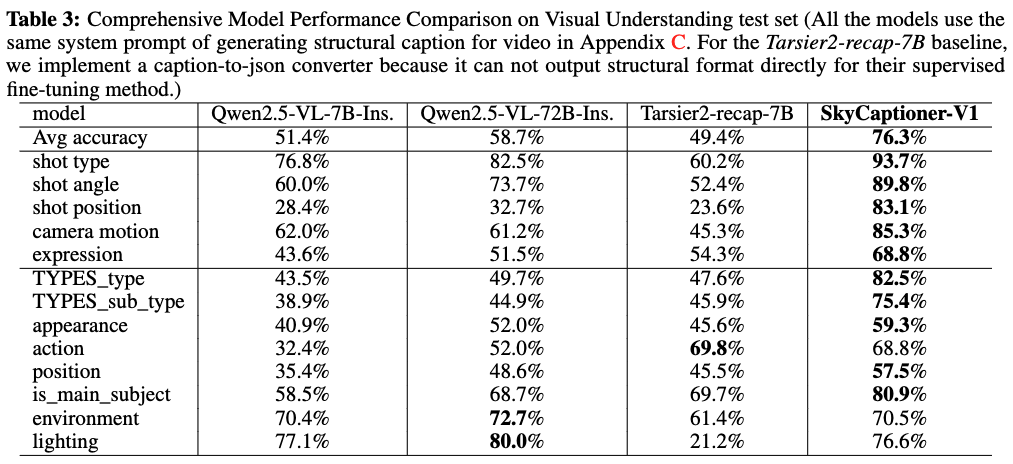
基于Qwen2.5-VL-7B-Instruct模型构建的SkyCaptioner-V1经过微调,以增强在特定领域视频描述任务中的表现。为与现有最先进模型(SOTA)进行性能对比,在1000个样本的测试集上进行了跨不同描述领域的人工准确率评估。下表3展示了结构化描述中各领域的详细准确率指标。所提出的SkyCaptioner-V1在基线模型中取得了最高平均准确率,并在镜头相关领域展现出显著优势。
训练细节
采用Qwen2..5-VL-7B-Instruct作为基础模型,使用全局批次大小512进行训练,该批次分布在64块NVIDIA A800 GPU上,采用4个微批次大小和2步梯度累积。模型使用AdamW优化器进行优化,学习率设为1e-5,训练2个epoch,并根据测试集的综合评估指标选择最佳检查点。此训练配置在保证大规模视频描述任务计算效率的同时,确保了模型稳定收敛。
多阶段预训练
本文采用Wan2.1的模型架构,仅从头训练DiT(Diffusion Transformer),同时保留VAE和文本编码器等组件的预训练权重。随后,使用流匹配框架训练视频生成模型。该方法通过连续时间概率密度路径将复杂数据分布转换为简单高斯先验,支持通过常微分方程(ODE)实现高效采样。
训练目标
给定潜在表示(图像或视频),从logit-normal分布中采样时间步t∈[0,1]。初始化噪声,通过线性插值构建中间潜在:
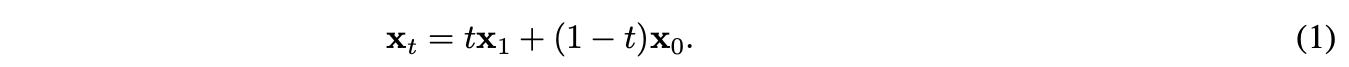
计算真实速度向量为:

模型预测速度场θ,该场在文本嵌入c(如512维umT5特征)的调节下,通过最小化损失函数L引导样本向移动:
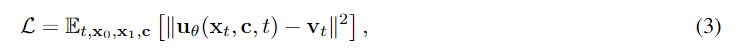
基于此训练目标,首先设计双轴分桶框架和FPS标准化方法对数据进行归一化处理,随后执行分辨率逐步提升的三阶段预训练。
双轴分桶框架与FPS标准化 基于数据处理流程,通过双轴分桶框架解决视频数据的时空异质性问题。该框架沿两个正交维度组织训练样本:时间长度分箱(划分)和空间宽高比分类(划分),形成的互斥分桶矩阵。为优化GPU内存利用率并防止内存溢出(OOM),通过经验分析实施自适应批量调整——根据时长和宽高比为每个分桶分配不同的最大批次容量。在数据预处理阶段,样本被映射至最近邻分桶。模型训练过程中,分布式计算节点采用随机分桶采样动态组合小批量,确保输入分辨率和时间跨度的持续变化。
在双轴分桶系统(时间分箱×空间宽高比分类)基础上,通过时频适配扩展框架。视频通过余数感知下采样协议实现FPS标准化:针对每个样本,计算相对于目标频率(16/24 FPS)的模数余差,选择余差最小的频率作为重采样基准。该数学公式表示为: (original_fps mod f) 确保在保持运动语义的同时实现最优时间对齐。重采样视频随后使用已建立的时长-宽高比矩阵进行分桶处理。
为解耦帧率依赖性,在DiT架构中引入可学习频率嵌入,这些嵌入与时间步嵌入进行加性交互。这些可学习频率嵌入将在高质量SFT阶段仅使用FPS-24视频数据后被弃用。
预训练阶段1
首先在低分辨率数据(256p)上进行预训练以获取基础生成能力。本阶段提出联合图像-视频训练方案,支持不同宽高比和帧长。我们实施严格数据过滤以去除低质量和合成数据,并通过去重保证数据多样性。该低分辨率阶段帮助模型从大量样本中学习低频概念。此阶段训练的模型展现出基础视频生成能力,但生成视频仍较模糊。
预训练阶段2
本阶段继续联合图像-视频训练,但将分辨率提升至360p。应用更复杂的数据过滤策略,包括时长过滤、运动过滤、OCR过滤、美学过滤和质量过滤。此训练阶段后,生成视频清晰度显著提升。
预训练阶段3
在最终预训练阶段将分辨率扩展至540p,专注于视频目标。我们实施更严格的运动、美学和质量过滤标准以确保高质量训练数据。此外,引入源过滤以去除用户生成内容,同时保留影视级数据。该方法提升生成视频的视觉质量,显著增强模型生成具有优秀纹理和电影级质量的真实人类视频的能力。
预训练设置
优化方面,在所有预训练阶段均采用AdamW优化器。阶段1中初始学习率设为1e-4,权重衰减为0。当损失收敛至稳定范围后,将学习率调整为5e-5并引入1e-4权重衰减。阶段2和阶段3中,学习率进一步降至2e-5。
后训练阶段
后训练是提升模型整体性能的关键阶段,后训练包含四个子阶段:540p高质量监督微调(SFT)、强化学习、扩散强制训练以及720p高质量监督微调。出于效率考量,前三个后训练阶段采用540p分辨率执行,最终阶段则在720p分辨率下进行。540p高质量SFT利用平衡数据集提升整体性能,为后续阶段奠定更优的初始化状态。为增强运动质量,我们将采用强化学习替代标准扩散损失方法。此阶段我提出半自动化流程,通过人机协同方式收集偏好数据。本文提出扩散强制训练阶段,将全序列扩散模型转化为应用帧级噪声水平的扩散强制模型,从而具备可变长度视频生成能力。最后通过720p高质量SFT阶段,将生成分辨率从540p提升至720p。
强化学习
受大语言模型(LLM)领域成功经验启发,本文提出通过强化学习增强生成模型性能。具体聚焦于运动质量优化,因为我们发现当前生成模型的主要缺陷在于:1)对大规模形变运动处理不佳(如图下7.a、图7.b);2)生成视频可能违反物理定律(如图7.c)。

为避免文本对齐度与视频质量等其他指标退化,确保偏好数据对的文本对齐度和视频质量具有可比性,仅保留运动质量差异。这种要求在人类标注成本较高的现实条件下,对获取偏好标注数据提出了更大挑战。为此,我们设计了结合自动生成运动对与人工标注结果的半自动化流程。这种混合方法不仅扩展了数据规模,更通过质量管控提升了与人类偏好的对齐度。基于该增强数据集,我们首先训练专用奖励模型捕捉配对样本间的通用运动质量差异,该学习到的奖励函数随后指导直接偏好优化(DPO)的样本选择过程,从而提升生成模型的运动质量。
人工标注偏好数据
通过对生成视频运动伪影的严格分析,建立了系统性故障模式分类体系:包括运动幅度过大/不足、主体形变、局部细节损坏、物理定律违反及非自然运动等。此外,记录与这些故障模式对应的提示词,并通过大语言模型生成同类提示词。这些生成的提示词涵盖从人机交互到物体运动等各类场景,包含上述所有运动故障类型。每个提示词使用预训练模型的历史检查点池生成四个样本。
样本采集完成后,相同提示词生成的样本被系统性地配对成样本对。邀请专业标注人员对这些样本对进行偏好评分。标注流程遵循两个主要步骤:1)数据过滤:样本将在两种情况下被排除:首先是内容/质量不匹配——若两个样本描述不同文本内容或存在显著视觉质量差异,以确保聚焦运动质量分析;其次是标注标准失效——若配对样本中任一视频未满足主体清晰度、画面内主体尺寸充足或背景构图简洁三项标准。经验表明该过程将过滤约80%的数据对。2)偏好选择:标注人员根据运动质量标准为每个样本对分配"更好/更差/平局"标签。人工标注的运动质量评价细则详见表A2,其中列明了所有运动质量故障类型的描述。每个故障类型被赋予加权分数,通过计算两个视频的总分实现对比。
自动生成偏好数据
在严格质量要求下,人工标注的高成本严重限制了数据集规模。为扩展偏好数据集,本文设计了自动化偏好数据生成流程,包含两个核心步骤:
1)真实数据采集 使用生成提示词在现有数据集查询语义相似提示词(基于CLIP特征的余弦相似度计算)。筛选获得语义匹配的真实参考视频作为优选样本,拒绝样本通过以下步骤生成以形成偏好对。
2)渐进失真构建 基础观察发现:最先进视频生成模型的运动质量仍逊色于真实视频。通过对真实视频施加可控失真来系统模拟运动缺陷。每个真实视频附带文本描述和首帧(静态参考),在保持视觉结构的同时实现动态缺陷分析。创建三种失真样本变体:V2V(噪声潜变量直接反转,最低失真)、I2V(首帧引导重建,中等失真)、T2V(文本描述再生,最高失真)。同时,采用不同生成模型([5,18,17])和模型参数(如时间步长)构建不同运动质量等级,保持样本多样性。前图7展示了通过该自动化流程构建的三个案例。
除标准流程外,本文还探索了创新技术以诱发特定视频质量问题。可在时域调控帧采样率:增加或降低采样率以产生运动幅度过度/不足效果,或交替采样率制造异常运动。通过Tea-Cache方法调节参数并注入噪声以破坏视频帧局部细节。针对汽车行驶或飞鸟等场景,通过视频倒放创建配对样本,挑战模型辨别物理运动正误的能力。这些方法能有效模拟视频生成中的各类异常案例,精确复现运动异常、局部细节丢失、违反物理定律等生成过程中可能出现的缺陷场景。
奖励模型训练 遵循VideoAlign方法,基于Qwen2.5-VL-7B-Instruct构建运动质量奖励模型。训练数据来源于上述数据收集流程,共形成3万个样本对。由于运动质量与上下文无关,样本对不包含提示词。模型采用含平局扩展的Bradley-Terry模型(BTT)训练:
![]()
其中i > j、i < j、i=j分别表示样本i优于/劣于/等同于样本j。
DPO训练 应用文献[46]提出的流式直接偏好优化(Flow-DPO)来提升生成模型的运动质量。其损失函数定义为:

扩散强制训练
本节介绍扩散强制Transformer(Diffusion Forcing Transformer),该架构赋予模型生成长视频的能力。扩散强制是一种训练与采样策略,其中每个标记(token)被分配独立噪声水平。这使得训练后的模型可根据任意单标记调度方案进行去噪。从概念上,该方法相当于部分掩码(partial masking)机制:零噪声标记完全解除掩码,完全噪声标记则完全掩码。扩散强制训练模型利用较干净的标记作为条件信息,指导含噪标记的恢复。本文扩散强制Transformer可根据前段视频的末帧实现无限长视频生成。需注意,同步全序列扩散是扩散强制策略的特例——所有标记共享相同噪声水平。这种关联性使能够通过全序列扩散模型微调得到扩散强制Transformer。
受AR-Diffusion启发,本文采用面向帧的概率传播(FoPP)时间步调度器进行扩散强制训练,流程包含以下步骤:
1.均匀采样:首先生成帧索引f∼U(1,F)与对应时间步t∼U(1,T),确保时间步均匀分布于所有视频帧。
2.概率传播动态规划:基于条件,使用动态规划计算帧f前后各帧时间步的概率分布。
3.状态转移方程定义:定义为帧i以时间步j起始的有效时间步序列数量(满足非递减约束),通过状态转移方程计算:
边界条件设定为且
4.访问概率计算:对于f之后的帧,时间步k的访问概率为:
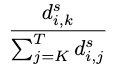
类似地,对于f之前的帧,定义并计算概率:
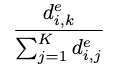
5.时间步采样:基于计算概率逐帧采样前后帧的时间步。
在推理阶段,采用支持自适应视频生成(同步自回归与异步生成)的自适应差分(AD)时间步调度器。该调度器将相邻帧间时间步差作为自适应变量。对于连续帧时间步与,约束条件为:
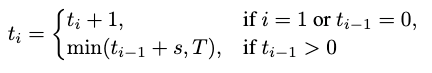
当先前帧不存在或已去噪完成时,当前帧聚焦自去噪;否则以时间步差s进行去噪。值得注意的是,同步扩散(s=0)与自回归生成(s=T)均为特例。较小的s值使相邻帧更相似,较大的s值提升内容多样性。
本文的条件机制通过利用更干净的历史样本作为条件实现自回归帧生成。在此框架下,信息流具有固有方向性:含噪样本依赖前序历史确保一致性。这种方向性表明双向注意力非必要,可替换为更高效的因果注意力。在采用双向注意力完成扩散强制Transformer训练后,可通过上下文因果注意力微调提升效率。推理阶段,该架构支持历史样本K、V特征的缓存,消除冗余计算并显著降低计算开销。
高质量监督微调(SFT)
在540p与720p分辨率分别实施两阶段高质量监督微调(SFT)。初始SFT阶段在预训练完成后立即执行,但在强化学习(RL)阶段之前。该阶段作为概念均衡训练器,基于仅使用fps24视频数据的预训练基础模型,战略性地移除FPS嵌入组件以简化架构。采用高质量概念平衡样本训练,为后续训练建立优化初始化参数。完成扩散强制训练后,在720p分辨率执行二次SFT,采用相同损失函数与人工筛选的高质量概念平衡数据集。此最终精炼阶段聚焦分辨率提升,实现视频质量的整体增强。
基础设施
本节介绍训练与推理阶段的基础设施优化方案。
训练优化
训练优化聚焦保障高效稳健的训练过程,包括内存优化、训练稳定性与并行策略三方面:
内存优化
注意力模块的fp32内存受限操作主导GPU内存占用。我们通过高效算子融合减少内核启动开销,同时优化内存访问与利用率。梯度检查点(GC)技术通过仅存储transformer模块输入的fp32状态最小化内存;将其转换为bf16格式可降低50%内存且精度损失可忽略。激活卸载技术通过异步将临时张量转移至CPU进一步节省GPU内存。鉴于8块GPU共享CPU内存与过度卸载导致计算重叠受限,我们策略性结合GC与选择性激活卸载实现最优效率。
训练稳定性
提出智能自愈框架,通过三阶段修复实现自主故障恢复:实时检测隔离受损节点、动态资源重分配(使用备用计算单元)、任务迁移与检查点恢复确保训练连续性。
并行策略
预计算VAE与文本编码器结果。使用FSDP分布式存储DiT权重与优化器状态以缓解大模型GPU内存压力。在720p分辨率训练时,因大尺寸临时张量导致严重GPU内存碎片化问题(即使内存充足仍触发torch.empty_cache())。为此采用序列并行[72]技术缓解激活内存压力。
推理优化
推理优化核心目标是在保证质量前提下降低视频生成延迟。虽然扩散模型能生成高保真视频,但其推理过程需30-50步多步采样,5秒视频生成耗时超5分钟。实际部署中通过显存优化、量化、多GPU并行与蒸馏实现优化:
显存优化 部署采用RTX 4090 GPU(24GB显存)服务140亿参数模型。通过FP8量化与参数级卸载技术组合,在单GPU实例上实现720p视频生成并保持完整模型能力。
量化 分析表明注意力与线性层是DiT主要计算瓶颈。我们对全架构实施FP8量化:线性层采用FP8动态量化结合FP8 GEMM加速,在RTX 4090上相比bf16基准实现1.10×加速;注意力操作部署sageAttn2-8bit,同平台实现1.30×推理加速。
并行策略 采用内容并行(Content Parallel)、CFG并行与VAE并行三策略加速单视频生成。实际部署中,从4卡扩展至8卡RTX 4090时整体延迟降低1.8×。
蒸馏 采用DMD蒸馏技术加速视频生成。移除回归损失,使用高质量视频数据(替代纯噪声)作为学生生成器输入加速收敛。同时采用双时间尺度更新规则确保伪评分生成器跟踪学生生成器输出分布,以及DMD多步调度方案。如公式所示,梯度用于更新学生生成器G:
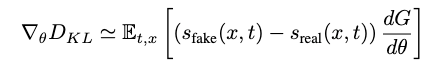
其中x为学生生成器生成的视频,与分别为伪评分生成器与真实评分生成器的评估分数。设定伪评分生成器与学生生成器的更新比例为5,采用4步生成器配合流匹配框架调优的指定调度。蒸馏阶段发现,小学习率与大批次组合对稳定训练至关重要。通过上述蒸馏过程,可显著缩短视频生成时间。
性能表现
为了全面评估本文提出的方法,构建了用于人工评估的 SkyReels-Bench,并利用开源的 V-Bench 进行自动化评估。这使我们能够将本文的模型与当前最先进的(SOTA)基线模型进行比较,包括开源和专有模型。
SkyReels-Bench
在人工评估方面,设计了 SkyReels-Bench,包括 1,020 条文本提示,系统性地评估三个维度:指令遵循性、运动质量、一致性和视觉质量。该基准旨在评估文本生成视频(T2V)和图像生成视频(I2V)模型,在不同生成范式下提供全面的评估。
指令遵循性
评估生成视频与所提供文本提示之间的匹配程度。
1)动作指令遵循性:对指定动作或移动的准确执行;
2)主体指令遵循性:对描述主体和属性的正确表达;
3)空间关系:主体之间正确的位置和交互;
4)镜头遵循性:指定镜头类型(特写、广角等)的正确实现;
5)表情遵循性:情绪状态和面部表情的准确描绘;
6)摄影机运动遵循性:摄影机动作(平移、俯仰、变焦等)的正确执行;
7)幻觉:不存在提示中未指定的内容。
运动质量
评估视频中主体的时间动态特性。
1)运动多样性:动作的多样性和表现力;
2)流畅性和稳定性:运动的平滑性,无抖动或不连续;
3)物理合理性:遵循自然物理规律和真实运动模式。
一致性
评估视频帧之间的一致性。
1)主体一致性:视频中主要主体的外观稳定性;
2)场景一致性:背景、地点和环境元素的连贯性。
对于图像生成视频(I2V)模型,我们另外评估:
3)首帧保真度:生成视频与输入图像的一致性,包括色彩保持、主体身份保留以及场景元素的连续性。
视觉质量
评估生成内容的空间保真度。
1)视觉清晰度:视觉元素的锐度和清晰度;
2)色彩准确性:色彩平衡合适,无过饱和现象;
3)结构完整性:主体和背景无失真或损坏。
该全面评估框架使我们能够系统性地比较不同模型的视频生成能力,并识别出各模型在视频质量各方面的特定优势与弱点。
在评估中,由20位专业评估员使用1-5评分量表对每个维度进行评分,评分标准详见下表4。

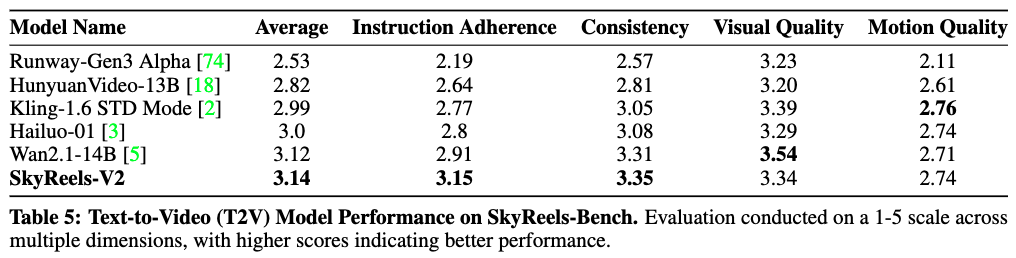
最终结果汇总于下表5。评估结果显示,本文的模型在指令遵循性方面相较基线方法取得了显著提升,同时在运动质量方面保持了竞争力,且未牺牲一致性。为确保公平,所有模型均在默认设置下以一致分辨率进行评估,且未应用任何后处理滤波操作。
模型基准测试与排行榜
为了客观比较 SkyReels-V2 与其他领先开源视频生成模型的性能,利用公共基准 VBench1.0 进行了全面评估。
本文特别采用了该基准中的长版本提示。在与基线模型公平对比时,我们严格遵循其推理推荐设置。同时,本文的模型在生成过程中使用了50次推理步数和6的引导尺度,与常规实践保持一致。
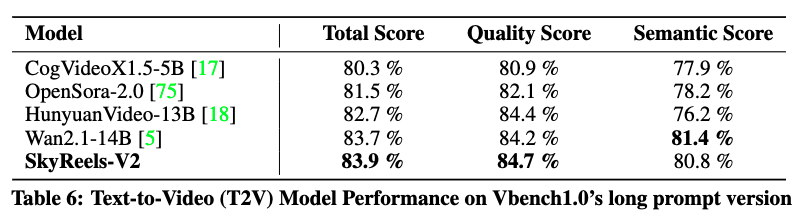
VBench 结果(下表6)显示,SkyReels-V2 在所有基线模型中表现最优,包括 HunyuanVideo-13B 和 Wan2.1-14B,取得了最高的总得分(83.9%)和质量得分(84.7%)。在此次评估中,语义得分略低于 Wan2.1-14B,但在此前的人工评估中优于 Wan2.1-14B,这一主要差距可归因于 V-Bench 在镜头语义遵循性方面评估不充分。
应用
故事生成
本文训练的扩散强制变换器支持生成理论上无限长度的视频。该模型采用滑动窗口方法生成长视频。除首次迭代仅依赖文本提示外,每次迭代均基于前 帧和文本提示生成接下来的 帧。
然而,视频长度的扩展可能导致错误积累。本文采用一种稳定化技术,对先前生成的帧施加轻微噪声标记,从而防止错误积累并进一步稳定长视频生成过程。
在下图8中,展示了将长镜头视频扩展至超过30秒的示例,证明了在增强时间长度的同时维持视觉连贯性的能力。

本文的模型不仅支持时间延展,还能够生成具有引人入胜叙事的长镜头视频。通过一系列叙事文本提示的引导,能够协调一段多动作、具有视觉一致性的视频叙述。该能力确保了场景之间的平滑过渡,使动态叙事成为可能,同时不影响视觉元素的完整性。
下图9展示了用户通过顺序文本提示操控“小女孩的动作”“女人的表情”以及“引擎状态”等属性的实例。

图像生成视频(I2V)合成
在本文的框架下,有两种方法可用于开发图像生成视频(I2V)模型: 1)全序列文本生成视频(T2V)扩散模型的微调(SkyReels-V2-I2V):参考 Wan 2.1 的 I2V 实现,我们在 T2V 架构基础上引入第一帧图像作为条件输入。输入图像被填充至目标视频长度,并通过 VAE 编码器获得图像潜变量。
这些潜变量与噪声潜变量和4个二值掩码通道(第一帧为1,其余为0)拼接,使模型能够利用参考帧进行后续生成。为了在微调过程中保留原始 T2V 能力,我们对新增的卷积层和交叉注意力中的图像上下文至值投影进行零初始化,而其他新组件(如图像上下文至键投影)采用随机初始化,以最小化性能突变。
此外,I2V 训练利用第3.2节所述的字幕生成框架生成的 I2V 特定提示。值得注意的是,该方法在 384 张 GPU 上仅使用 10,000 次训练迭代即可取得具有竞争力的结果。
2)带首帧条件的文本生成视频扩散强制模型(SkyReels-V2-DF):本文的另一种方法直接利用扩散框架的条件机制,通过将第一帧作为干净参考输入,无需显式重新训练模型,同时通过潜变量约束保持时间一致性。
使用 SkyReels-Bench 评估套件对 SkyReels-V2 与领先的开源和闭源图像生成视频模型进行评估(见下表7)。评估结果显示,无论是 SkyReels-V2-I2V(3.29)还是 SkyReels-V2-DF(3.24),都在开源模型中达到了最先进性能,显著超越 HunyuanVideo-13B(2.84)和 Wan2.1-14B(2.85)在所有质量维度上的表现。
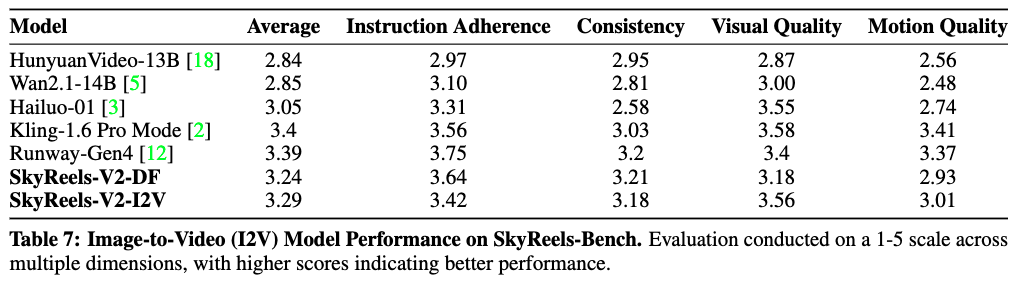
SkyReels-V2-I2V 的平均得分为 3.29,与专有模型 Kling-1.6(3.4)和 Runway-Gen4(3.39)相当。基于这一有前景的结果,我们已公开发布 SkyReels-V2-I2V 模型,以推动图像生成视频合成的社区研究。
摄影导演模块
尽管 SkyCaptioner-V1 在注释摄影机动作方面表现稳健,实现了主体分布的良好平衡,但摄影机动作数据本身的不均衡性对进一步优化电影摄影参数构成挑战。
为解决这一限制,本文从监督微调(SFT)数据集中特别策划了约100万个样本,确保基本摄影机动作及其常见组合的均衡代表性。在此增强数据集基础上,使用384张GPU进行了3,000次迭代的图像生成视频模型微调实验。
该专项训练显著提升了摄影机运动的电影表现力,尤其是在流畅性和多样性方面。
元素生成视频(E2V)
当前视频生成模型主要处理两项任务:文本生成视频(T2V)和图像生成视频(I2V)。T2V 利用 T5 或 CLIP 等文本编码器从文本提示生成视频,但往往因扩散过程的随机性而产生不一致性。
I2V 则从静态图像及可选文本生成运动,但通常受限于对初始帧的过度依赖。
在先前的工作中,提出了一种元素生成视频(E2V)任务,并发布了 SkyReels-A2,一个可控的视频生成框架,能够根据文本提示将任意视觉元素(如人物、物体、背景)合成为连贯视频,同时确保每个元素参考图像的高度保真度。
如下图10所示,SkyReels-A2 能够生成高质量、时间一致的视频,并支持多元素的可编辑组合。

A2-Bench,一项用于全面评估 E2V 任务的新型基准测试,其结果与人工主观评价表现出统计学显著相关性。
未来计划发布一个统一的视频生成框架,支持更多输入模态,如音频和姿态。该框架将基于我们此前在音频驱动和姿态驱动人像动画的研究成果 SkyReels-A1 构建,旨在支持更丰富、多样的输入形式。
通过这一扩展,该框架的应用范围将显著扩大,涵盖但不限于短剧制作、音乐视频和虚拟电商内容创作等场景。
结论
SkyReels-V2模型,这是一种新颖的视频生成框架,能够在无限长度范围内生成视频,同时保持对镜头场景提示的高度遵循、优质视频输出和强健运动质量。
主要提升通过以下方面实现:
1)提示遵循性:通过 SkyCaptioner-V1 模块增强,该模块结合了通用多模态大语言模型(MLLM)与专用镜头专家模型的知识蒸馏,从而实现与输入提示的精准对齐;
2)视频质量:通过多样化数据源和多阶段训练管pipeline著提升,确保视觉一致性和高保真度输出;
3)运动质量:在半自动数据生产 pipeline支持下,通过强化学习后训练优化,进一步提升动态一致性与流畅性;
4)无限长度生成:由扩散强制框架支持,可无显式长度约束地无缝扩展视频内容。
尽管取得了这些进展,扩散强制框架仍在生成过程中存在错误积累的问题,限制了高质量视频输出的实际时长。未来工作将重点解决该问题,以进一步提升模型的可扩展性与可靠性。
参考文献
[1] SkyReels-V2: Infinite-length Film Generative Model

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)