【从原理层面详细讲解comfyui工作流构建方法,以及部分常用节点讲解】
开头说过在comfyui中可以拼凑出人鱼或兽人,其实就是构建节点工作流的过程,它不像webui那样局限于给定的几种生成或改变图像的方式,方式完全可以由自己决定,它的样子可以像人鱼兽人那样猎奇,让人看上去头大(其实大部分节点流都是这样的),不同的节点与连接方式会有不同的甚至令人惊异的效果。我所讲解的内容只不过是comfyui的冰山一角,更多的需要读者自己去探索,自己去体会comfyui的优势。

前言
先来介绍一下comfyui,它是一个进阶版的SDwebui,ComfyUI 比 WebUI 更灵活,但正因为如此,它的使用门槛也相对高一些。下图正是comfyui的界面。
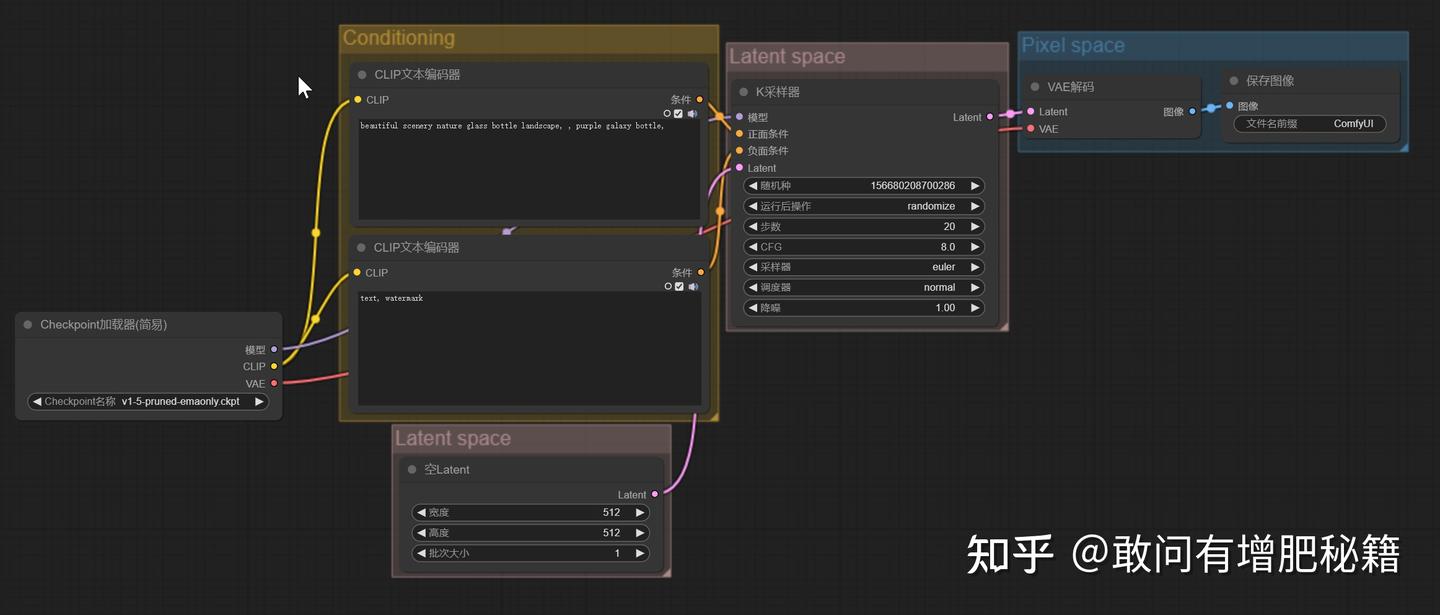
文生图基本工作流(自提供)
感到一阵晕眩是吧,这些深灰色的板块被类似电线的彩色线条连接,其实仔细一看从左往右板块的连接是有顺序的,它们的有序连接组成了comfyui中的工作流,此图展示的是最最基本的文生图工作流,无添加无污染。
如果把webui比做有血有肉有皮肤的活人,那么comfyui就是一个人体骨骼模型,露骨到不能再露的那种,不是说comfyui仅仅只是一个空架子,而是一种灵活性和可创新性。
上图列出的文生图的基本工作流相当于那个空架子,此时的它必然比不上有血有肉的webui,但是我们可以在文生图工作流中接入额外的节点,例如:外插vae节点、lora节点、controlnet节点等等,这些节点优化了文生图这个工作流,使得图片更好的呈现,这种接入节点的过程就如同把血肉拼凑到人体骨骼模型中,直到成为一个人的样子。comfyui的灵活度就在于你可以决定这个“人”的结构,是高是矮,是男是女,或拼凑成一个人鱼或者兽人,有点抽象了,还没理解我的意思别着急,后面还会讲到。
一、Comfyui节点工作流的基本概念
与传统的图像生成 UI 不同,ComfyUI 采用了节点系统。每个节点代表一个特定的操作,比如噪声生成、采样、模型加载等。
图片中那些深灰色的板块,或大或小,一个板块是一个“节点”,多个节点有序相连是一个工作流,有点像之前讲过的神经网络结构。
节点可以大致分为以下五类:
- 输入节点:负责输入数据到整个工作流中。例:clip文本编码器节点
- 模型节点:这些节点负责加载和处理生成模型。例:checkpoint加载器节点
- 处理节点:负责对中间数据进行操作或变换。例:vae编码节点
- 采样器节点:负责采样过程,控制图像生成的具体方式。采样器决定图像生成过程中,如何通过不同的算法迭代优化图像。例:k采样器节点
- 输出节点:负责输出最终生成的图像。这个节点会接收图像生成流程的最终结果,并将其显示或保存。例:保存图像节点
通过将不同节点连接起来,形成从生成图像到后期处理的完整流程。将一个节点的输出连接到下一个节点的输入,就能定义图像生成的每一步。
二、分别讲解基本文生图工作流中单一节点的作用
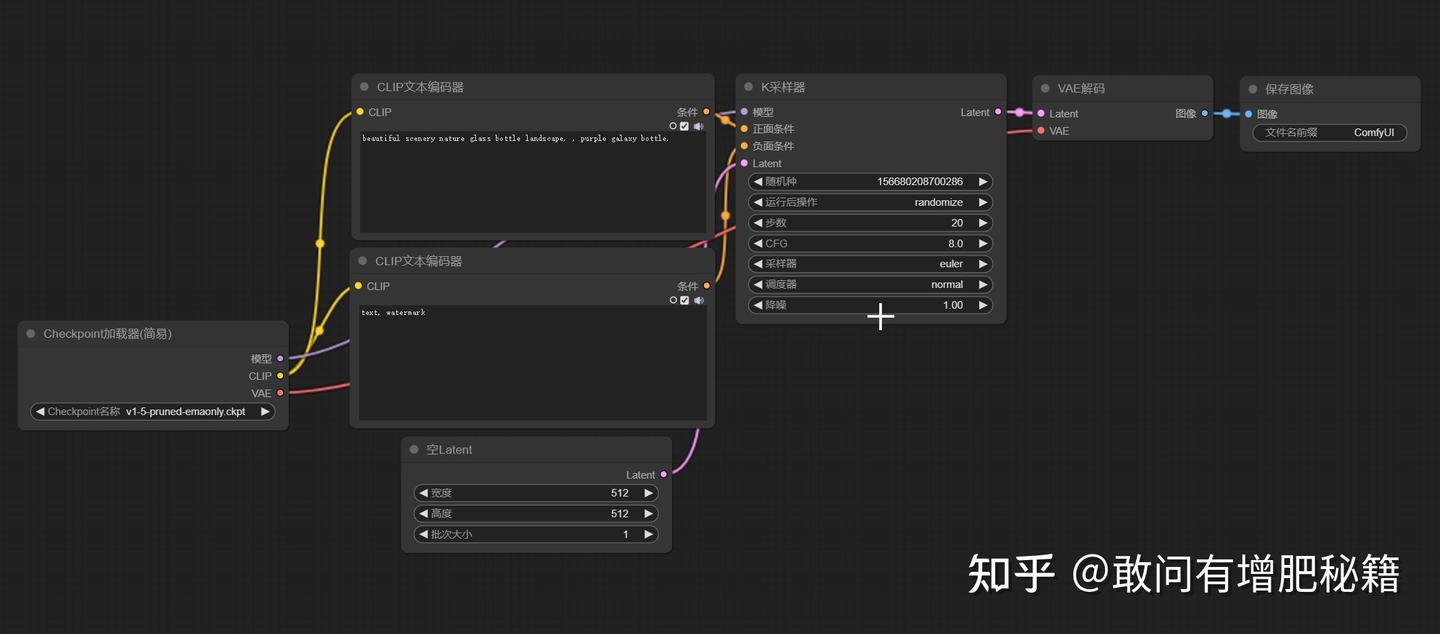
1. checkpoint加载器节点
checkpoint加载器节点示范图(自提供)
Checkpoint加载器和VAE为什么在同一个节点?
在webui中,checkpoint加载器和VAE是分开的概念,但在comfyui中他们的关系可以更紧密。
这里checkpoint和VAE的概念已在《鱼跃式讲解stable diffusion原理》中详细讲解到了,还不知道的读者们可以移步至该推文,待理解SD原理和相关专有名词的概念后再来学习本文章,此处不再赘述。
在comfyui中,checkpoint加载器通常会加载stable diffusion的完整模型,而这个模型实际上包括了两部分:
1.U-Net模型,负责在latent space(潜空间)中进行图像生成的迭代。
2.VAE解码器,负责将latent space中的表示解码为最终的图像
这就是checkpoint加载器和VAE共处同一个结点的原因,并且整合成同一个节点也是方便使用者的应用。
不过,在一些更复杂的工作流中,使用者也可以单独加载VAE进行解码,例如引入自己事先准备好的VAE文件(如同webui中的外挂VAE),可以添加VAE节点来进行操作。
2. clip文本编码器节点
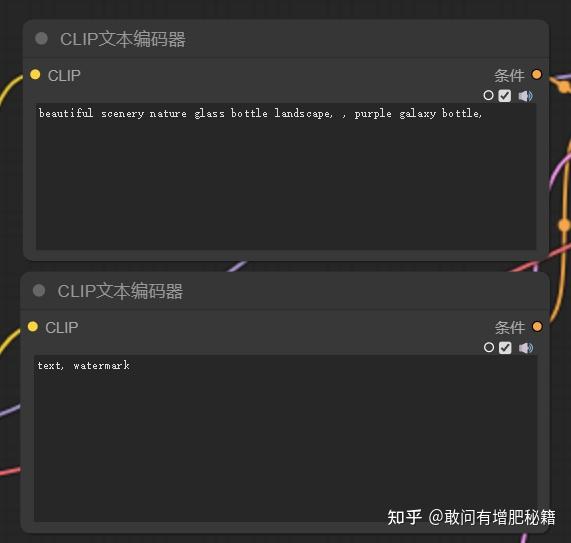
clip示范图(自提供)
与webui一致,两个clip文本编码器节点分别表示正向提示词和反向提示词,它们均作为条件影响着图片的生成
3. k采样器节点
不管是webui中的采样器还是comfyui中的k采样器此前都没有讲过,在此统一进行讲解
采样器
采样器负责指导生成过程中的噪声去除,它会根据给定的提示词条件,通过一系列迭代步骤逐渐从初始的随机噪声中生成符合提示词条件的图像,本质是一种噪声去除的数学算法。
采样器的种类有很多例如:DPM、PLMS、Euler、LMS
每一种采样器使用不同的数学方法处理latent space中的数据,决定了图像生成过程的去噪方式,选择的采样器不同,生成的图片质量、风格、速度也会不同。
至于采样器应该如何选择,这就要看你用的是什么模型,一般提供模型的平台都会在他们的模型简介中标明推荐使用的采样器算法。
在comfyui中,采样器前面多了一个“k”,这个“k”意思是karras,使用过webui的读者对这个词一定很熟悉,karras正是调度类型(类似于采样器背后的规划处理器)中的一种,它是由Tero Karras提出的改进的采样策略,适合用在稳定扩散模型中。
K采样器可以在减少采样步骤的情况下保持较高的图像质量,而且k方法可以结合不同的采样算法使用,例如DPM、Euler等(其实这一点在高版本的秋葉包webui中也做到了)。
调度器
其中karras就是调度器的一种,它决定了每次迭代时噪声该如何调整,以及每一步需要的噪声量。
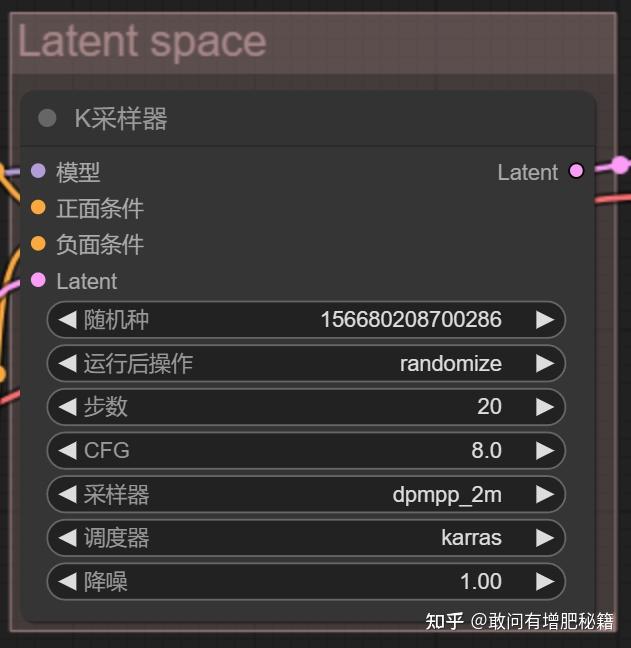
k采样器节点示范(自提供)
可以看到在此节点中有很多选项,我将以从上往下的顺序进行讲解。
- 随机种,其实他就是webui中的seed
- 运行后操作,此“运行”指的是生成图片,“操作”是指对随机种进行的操作,randomize(随机)则指的是操作方法,人话就是在每次生成完图片后都将对随机种进行改变,因为一张图对应一个种子,改变的方式有randomize(随机)、increment(增加)、decrement(减少),当然还有一种选择fixed(固定),就是常说的固定种子,关于其应用我在《AI绘画修手经验与心得》里面讲过了。
- 步数,即webui中的迭代步数step
- CFG,翻译为提示词引导系数,与webui作用一致
- 降噪,数值是1,说明图像由噪声图像变成最终我们看到的具有清晰画面的图像时,降噪程度是100%,当然这个数值可以改变,调小会影响画面的清晰度,实际应用不大。
4. 空latent节点
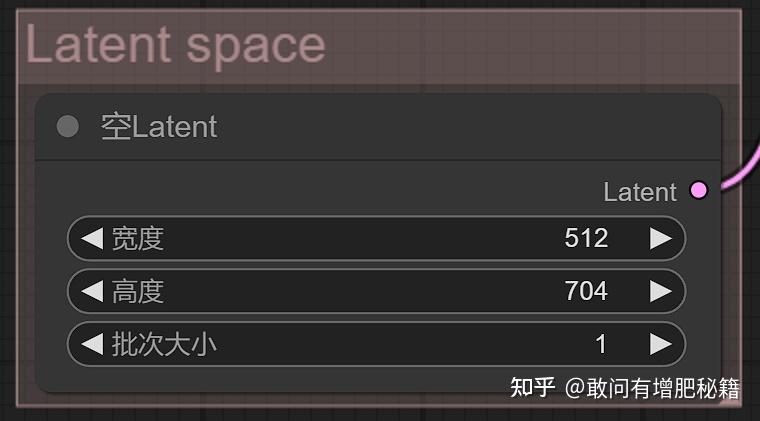
空latent节点示范(自提供)
它在生成图像的工作流中创建了一个空白的latent空间,就像画师在绘画前需要准备画布一样。
在这个节点里我们可以调整这张画布的长度和宽度,以及画布的数量,即批次大小
三、根据SD原理划分文生图工作流中的节点
为了更好地理解工作流的运行,我会像讲解SD原理一样,把工作流分为Pixel space、latent space、conditioning三部分,如下图
文生图工作流三空间分类(自提供)
两个clip文本编码器节点
latent space:
空latent节点和k采样器节点
pixel space:
Vae解码节点、保存图像节点
唯独checkpoint加载器节点没有被划分到任何空间中。Checkpoint加载器节点不直接属于这三个空间,它可以被看作是模型初始化的一部分,它为u-net和vae等模型提供了权重和结构,是整个生成流程的基础准备阶段,所以他是一个独立的准备节点,提供计算基础。
四、模型安装方法
大模型的下载可以观看下面的视频,内含comfyui的安装方式和comfyui与webui共用模型的操作方法(放心comfyui和webui生成图像的原理均为SD,两者的模型是可以做到兼容的),至于此前没有接触过webui的读者,我建议在了解使用webui后再来学习comfyui。
第二种下载方式:可以把大模型直接手动放入既定模型文件夹,不仅限于大模型,Lora、controlnet、vae同样可以用这种方式来装载模型,以下是对应的既定文件夹
打开comfyui根目录(就是你当初你下载comfyui时,装进你电脑盘里面的那个文件夹)打开models文件夹
大模型放进checkpoints文件夹中
Lora就放进loras文件夹中
Controlnet专用模型就放入controlnet文件夹
以此类推,如果你有想要在comfyui中装载的模型,在models中找到对应文件名,再把模型拖入文件夹即可(如果此前你已下载webui及其模型,我并不推荐你这么做,模型文件会占用你两倍的内存空间)。
还有一种在comfyui中内置下载模型的方法,可自行搜索,此处不做讲解
五、comfyui工作流原理性讲解
当我们配置好大模型后,可以试一试点击“执行队列”按钮,此处展示的工作流即默认工作流,你会看到与我一致的工作流运行轨迹。
在最开始会有一个绿色的线框包围住checkpoint加载器节点、随后线框将按此顺序进行转移:clip节点、k采样器节点、vae解码节点、保存图像节点,整个过程很快,用时不到十秒,绿色线框在时间内依次进行跳跃,其表达的含义正是图片生成时,各节点的工作顺序
00:08
详细过程讲解:
首先checkpoint加载器节点会最先加载对应模型及其计算权重,其次clip编码器会依据文本框里的内容对图像的生成进行导向,随后k采样器根据当前的潜在向量进行采样,并迭代去噪,生成图像的潜在表示,最后经过vae解码将生成的潜在图像解码成一个实际图像,进行保存。
此过程中绿色线框并未经过空latent节点,因为该节点只是用于储存和传递潜在空间数据,并不进行实际的计算或生成操作,类似于“中转站”的作用。如同SD原理图中的latent space的作用。
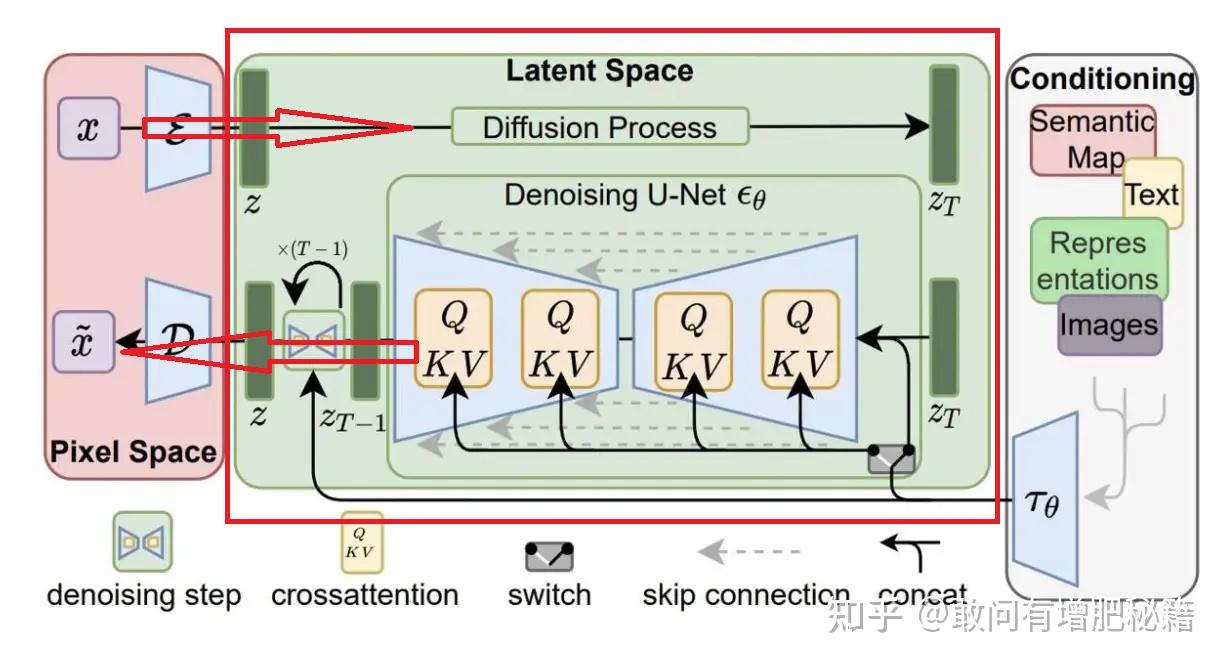
SD原理图(来源网络)
六、图生图基本工作流
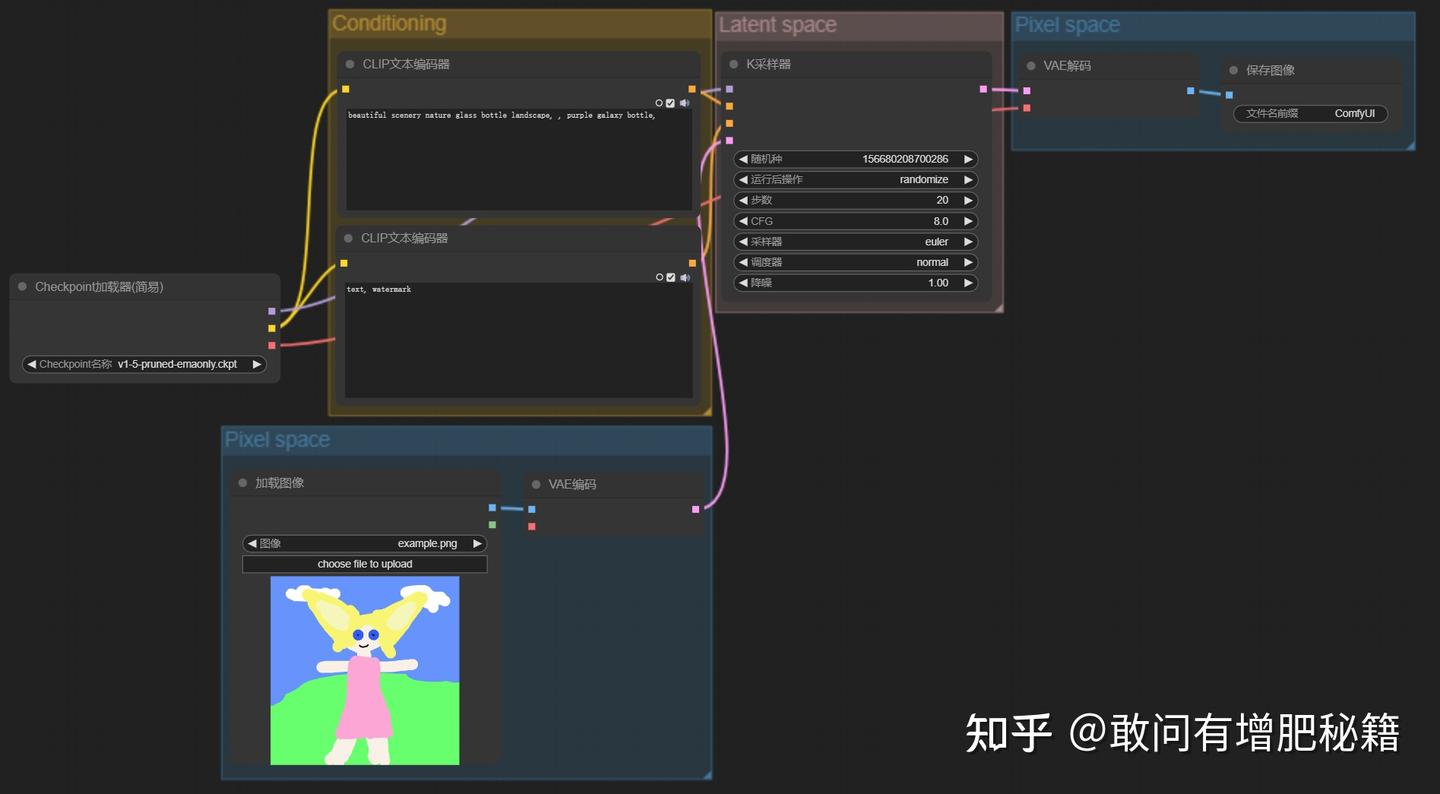
图生图基本工作流示范(自提供)
与文生图不同,原来的空latent节点换成了加载图像节点和vae编码节点。
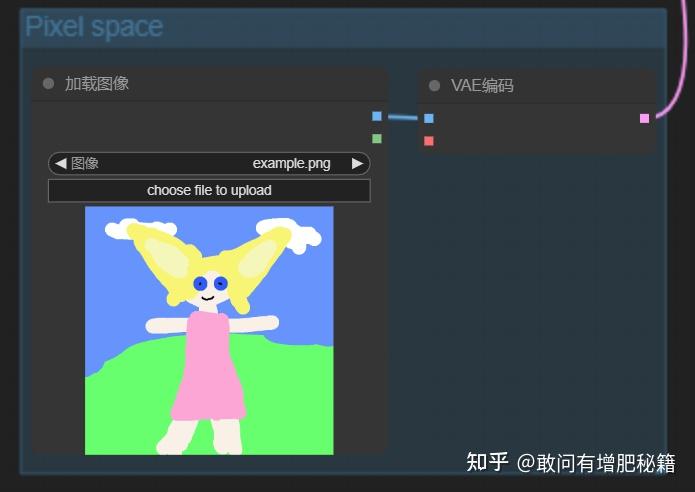
差别点(自提供)
其实很好理解,在文生图工作流讲解时我们把空latent节点比作成了一张画布,用来承载图像;来到图生图这里,初始加载的图像就成了那张“画布”,因为图生图生成图像的过程即,在原图像的基础上先进行加噪处理,变成一张噪声图像,再根据条件向量的导向去噪生成最终图像。
额外增加一个vae编码节点的原因则是,我们加载的这个图像是属于pixel space,只有进入到latent space中才能进行采样器采样,所以需要vae将图像降维(压缩)到latent space,再进行采样。
因此,在基本图生图中生成图像的尺寸和你所提供的图像尺寸是一样的,如果想要调节尺寸可以在加载图像节点和vae编码节点之间添加一个图像剪裁节点,如图。
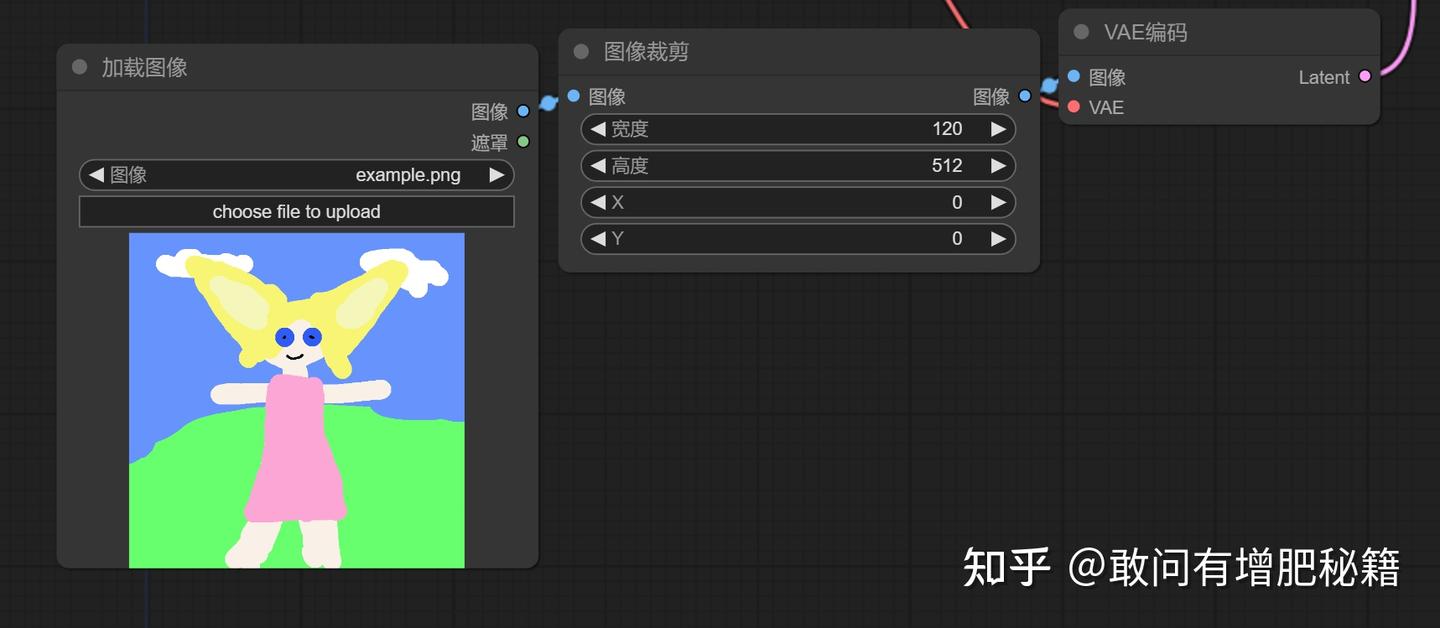
尺寸调节示范(自提供)
在使用时你需要根据原图像的尺寸计算好你所需要的图像尺寸,图像剪裁和空latent的宽高单位均为像素。不只是图像剪裁,图像缩放,SD放大都可以这么用。
至于找到它们,有些麻烦,comfyui的节点很多,一不小心就会在茫茫节点中迷失自我无法自拔。
在空白处鼠标右键
新建节点——图像——放大——图像缩放、SD放大
图像——变换——图像裁剪
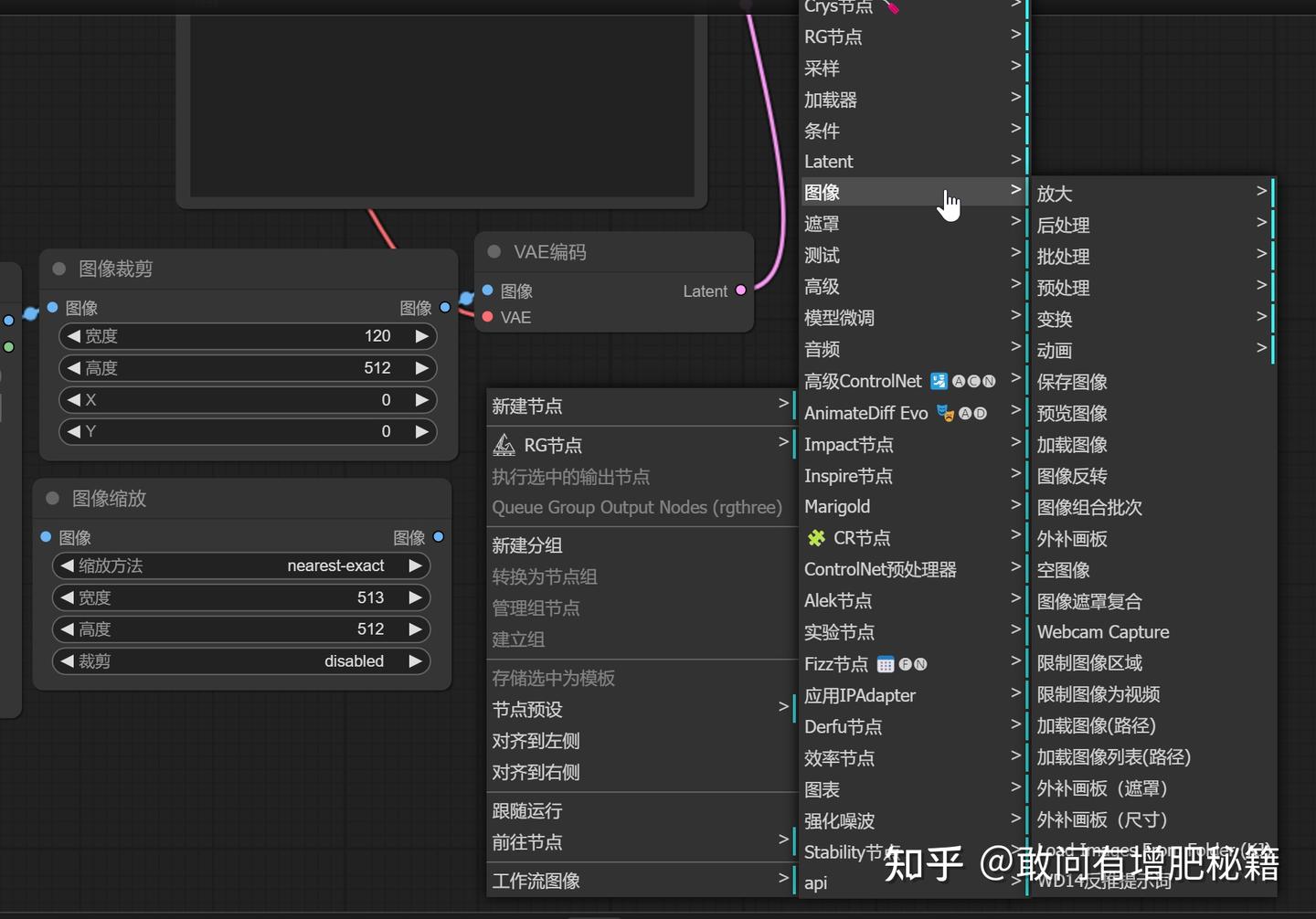
寻找节点(自提供)
七、几类常用节点的添加
1、 Lora节点
此前使用过webui的读者应该知道在webui中添加lora模型的操作,是选中Lora模型到文本提示词中,并输入Lora触发词,此时可以看到文本框中出现了类似这样的东西:<lora:chika fujiwara s3-lora-nochekaiser:1>,其中冒号后面的数字1是该模型的权重。
那么在comfyui中Lora单独作为一个节点存在,如下图。
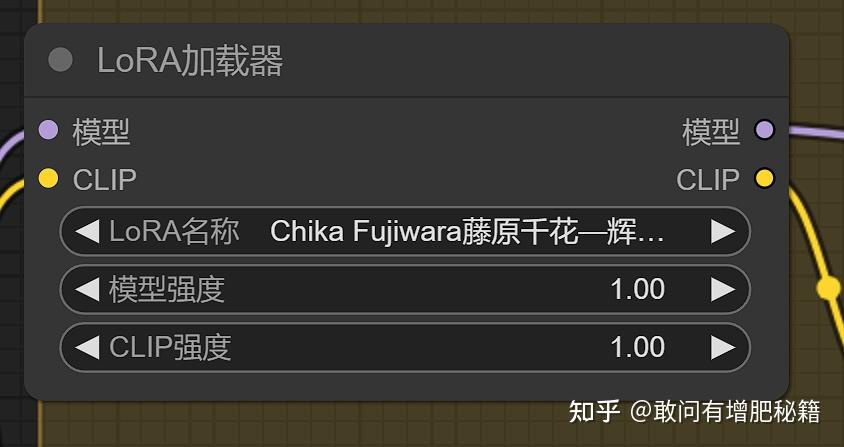
Lora节点示范(自提供)
在webui中lora是出现于文本框之中的,固然Lora加载器节点应划分到conditioning中,下图为该节点接入工作流的方式。
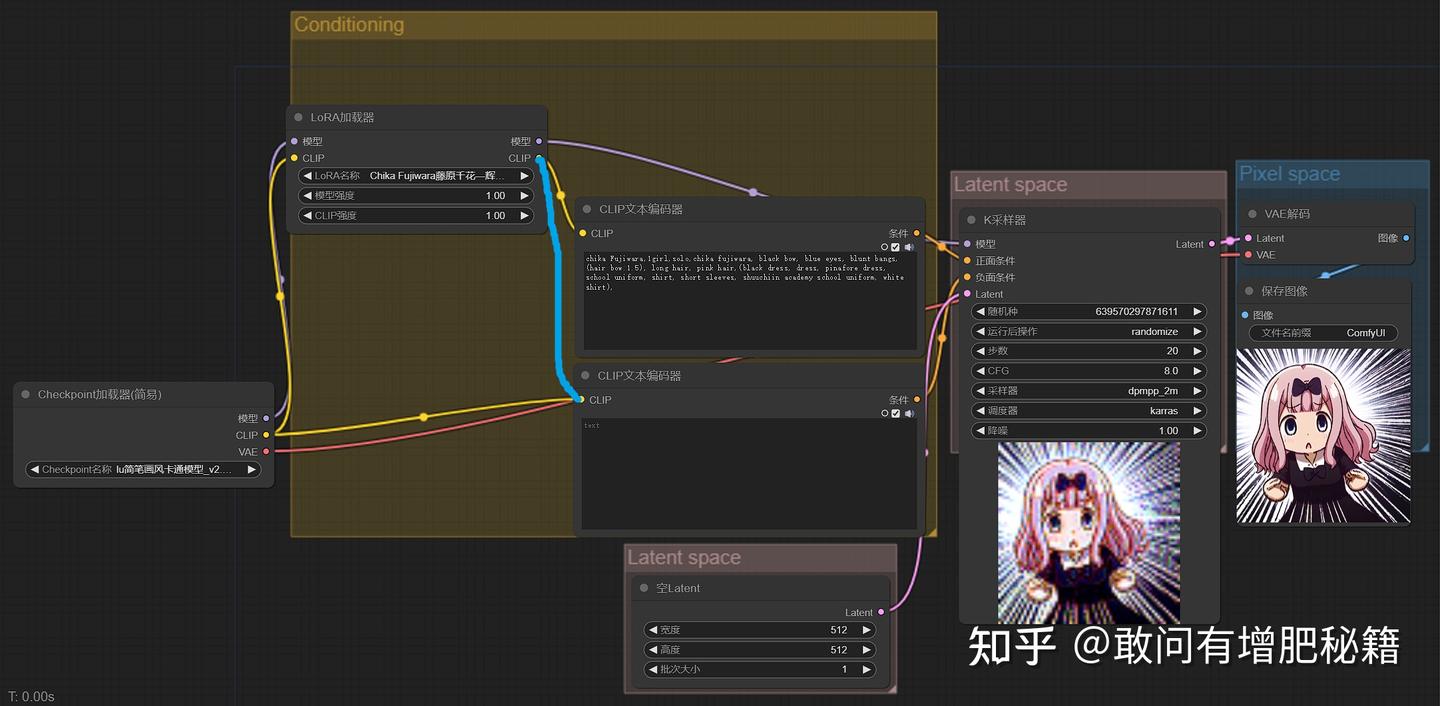
加入Lora的工作流(自提供)
**注:**经实践得,Lora加载器节点的clip输出点接或不接反提示词文本节点都可,对结果没有丝毫的影响(我用比较醒目的蓝线画出来了,这条蓝线可有可无)。
2、 controlnet节点
有关controlnet的使用分为两部分:
1、预处理器:对输入的辅助图像或参考图进行预处理,将其转化为模型可用的格式
2、controlnet专用模型:在SD大模型的基础上迭代了可以理解并利用预处理器生成地控制信号的能力(与预处理器直接相关)
二者缺一不可,以openpose为例(从输入图像中提取人体的关节和姿势关键点),可以理解成预处理器优先提取加载图像的人体姿势为下图右侧预览图片中的人体骨骼图,后面专用模型会专门接收人体骨骼这些信息产生信息导向向量并导入k采样器。所以整个controlnet组分划入conditioning部分影响着工作流的运行。
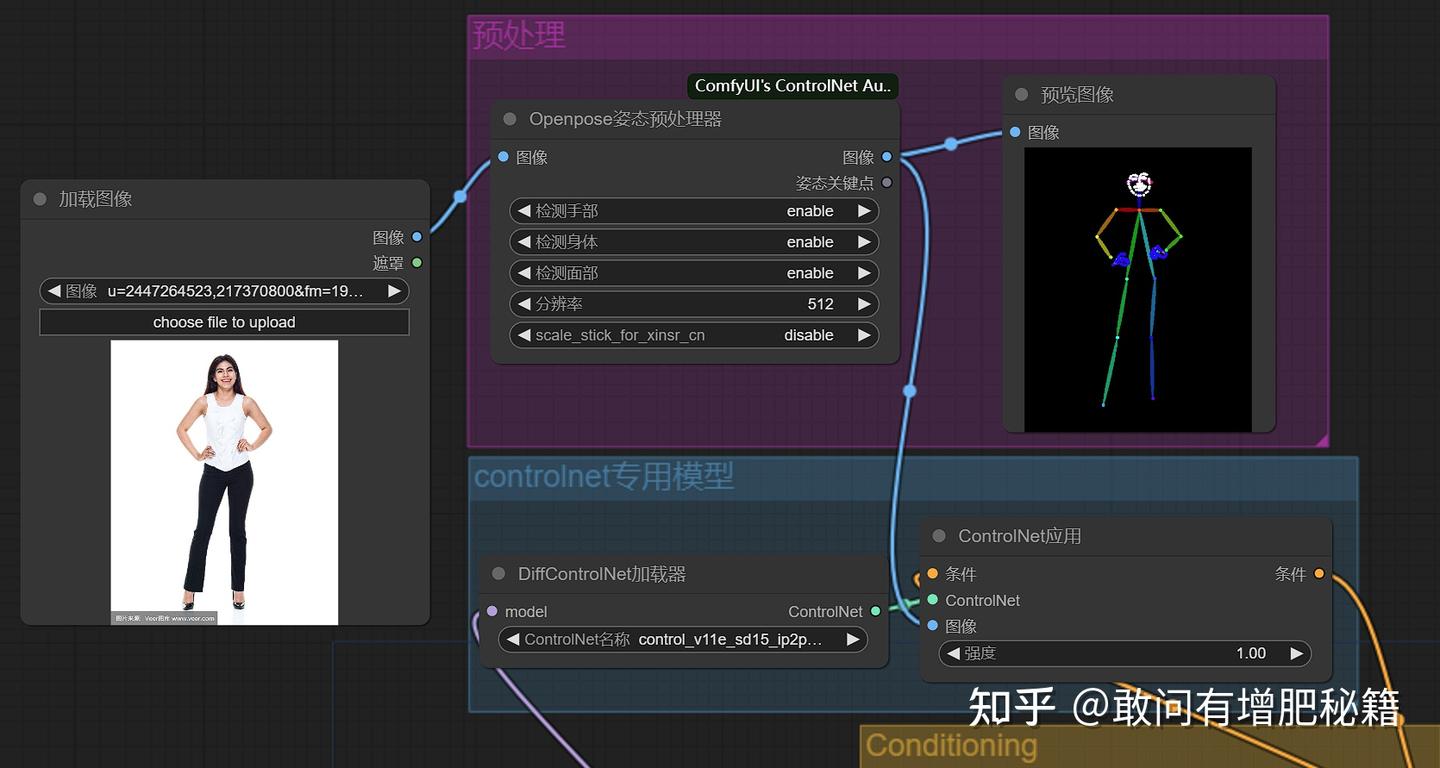
controlnet小组示范(自提供)
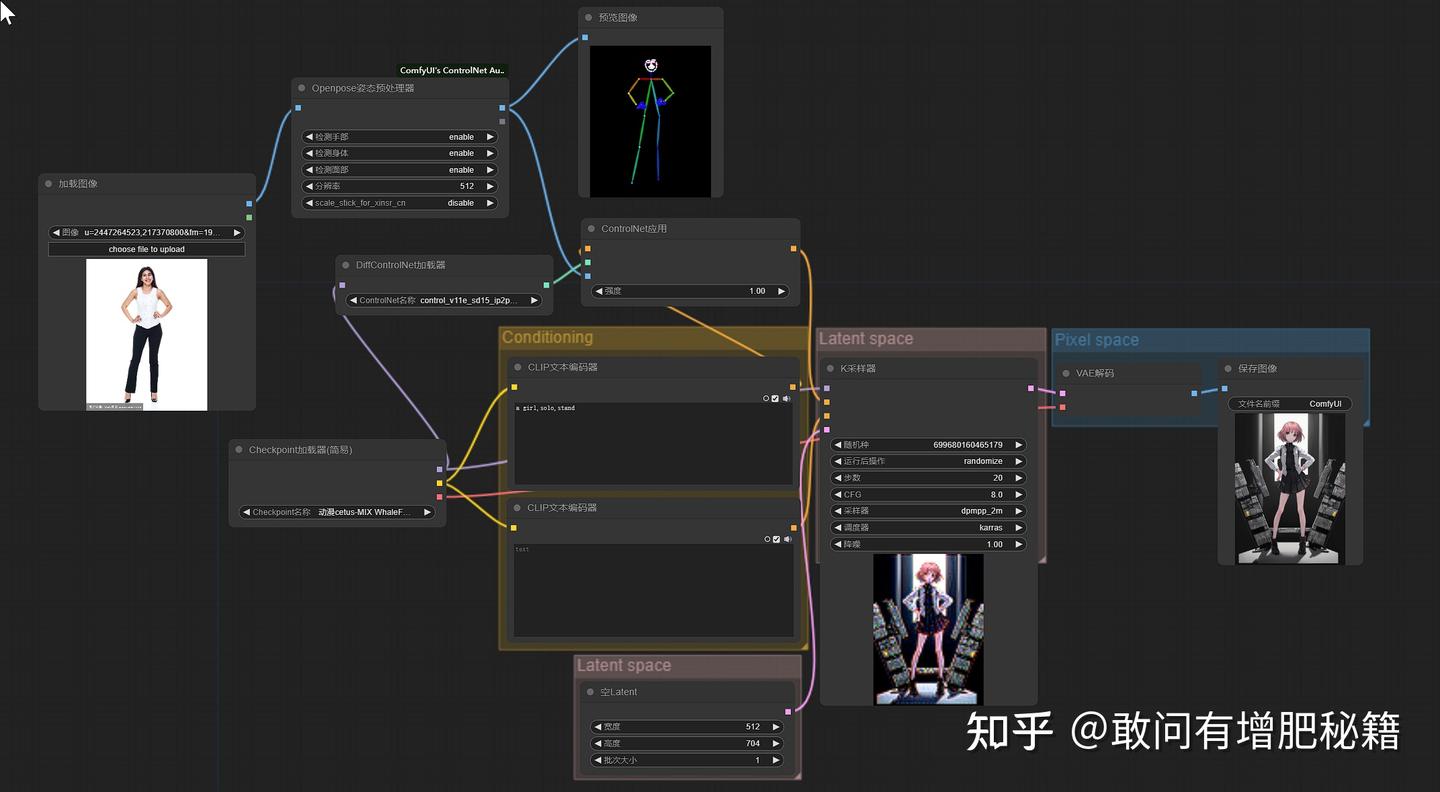
添加controlnet后的工作流(自提供)
节点的寻找
comfyui里面的节点有很多,秋葉包集合了大部分常用的节点,免去了再到github等其他网站下载节点的麻烦,如果你是从github下载的原版comfyui,那么你的UI最初只有零星几个节点,需要学会自行下载。
在此简单讲解一下模型怎么找。
第一个方法是双击背景,此时界面弹出搜索框,你可以在这里搜索你没有找到的节点(前提是你的UI已经下载了该节点),有个弊端是你需要输入节点的英文名字,你需要提前知道某个节点的原名,例如:
你想要找到k采样器节点,就输入“ksampler”
输入“k采样器”是不会有任何结果的
另一个方法就是肉眼把节点翻出来,其实并不难,此前我一直着重讲解各个节点应该划分到哪个部分,这里就应用到了。以翻找controlnet节点为例,可以对照下图查看。
openpose预处理器属于controlnet预处理器,应到“controlnet预处理器”去寻找
加载图像、预览图像、保存图像等一系列与图像有关的,可以到“图像”去寻找
controlnet加载器、Lora加载器、checkpoint加载器等与加载器有关的,可以到“加载器”去寻找
而这个名叫controlnet应用的节点我们按照“controlnet作为条件影响工作流运行”的道理,可以到“条件”去寻找
根据此方法你还可以找到clip文本编码器等其他节点。
此点足以证明想要用好comfyui你必须要搞清楚其原理及其相关专有名词的含义
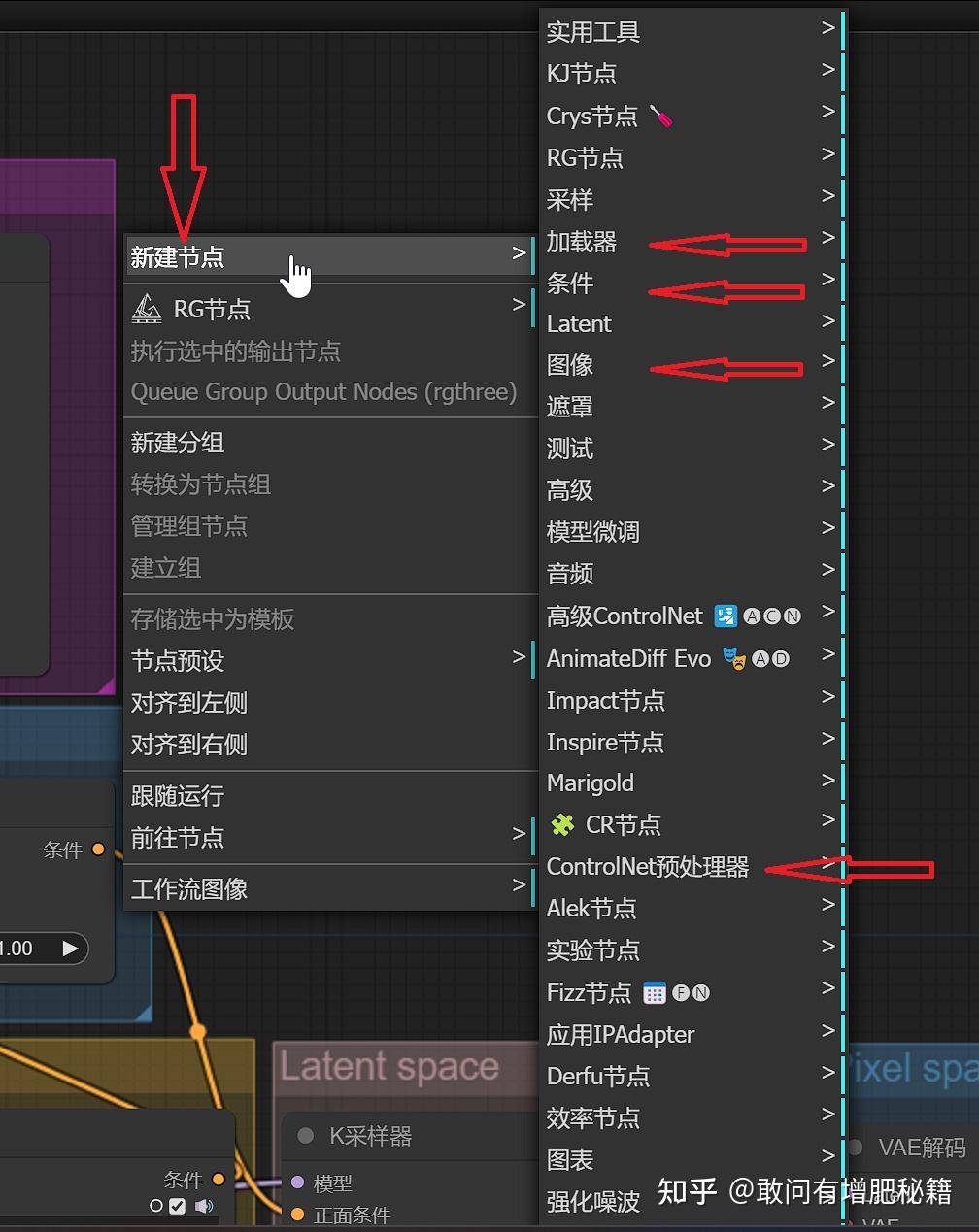
寻找节点(自提供)
八、在初次使用comfyui时遇到的问题和一些思考总结
Comfyui比webui的文本提示词有了很大的改变,在初次使用comfyui时我加载了一个自己经常用的模型,输入一段自己常用的通用提示词,但生成后的图像并没有呈现模型原本的画风,起初我以为是模型加载的问题,后来又对比着webui做了几次对照试验,发现并不是模型的问题,是comfyui对文本的提取权重和理解能力都改变了,comfyui受提示词的影响更大了,这意味着comfyui无法像webui那样一股脑输入一大堆有关画质效果的正面描述或反面描述,例如:
(masterpiece:1,2),best quality, masterpiece, highres,original,extremely detailed wallpaper,perfect lighting,(extremely detailed CG:1.2), drawing,paintbrush,glowing special effects, dynamic, highly detailed, ultra-high resolutions, 32K UHD, best quality, masterpiece
这样往往会使comfyui生成图像的原模型风格遭到崩坏(有时还会影响Lora的表现效果),并且也不需要这么多有关画面质量的描述,节点工作流的自由度完全可以轻松解决这些问题。并且comfyui也不局限于提示词,使用者可以输入完整的一句话或描述的整个画面,comfyui对于文本的理解能力有着很大的提升。
在这过程中我还发现了一点,comfyui图像基础呈现能力比webui好。
在与webui做对比实验时,确保comfyui与webui的采样器和调度器的设置一样,不加外挂vae,不加任何额外的模型,同样的提示词,同样的图像尺寸,在这里我连seed也固定为同一个,运行得到的结果是这样的:
拼接后图片,图片上半为comfyui下半为webui(自提供)
注:webui的种子在最右下角被选中的部分

生成图像后拼接,左comfyui,右webui(自提供)
可以很明显的发现comfyui生成的图像整体更加清晰,没有webui的画面那么模糊。
至于为什么在相同的种子下没有生成相同的图像,可能与两UI的某些细节差异有关,例如输入的文本提示词处理方式、图像预览的处理等。此处没有讨论的价值。
九、推荐的分享工作流网站
到这里你应该就能体会到comfyui与webui的区别了,像图生图、lora、controlnet等等这些工作流都是在基本文生图工作流的基础上演变来的,当然基本构架不只有文生图,还有很多有趣的工作流等着大家去学习开发。
如果你初次使用comfyui感到对工作流非常迷茫,我建议可以先去体验一下其他人分享的工作流,下面是来源网站。
OPENart flow(https://openart.ai/home)需要科学上网
Comfy Workflows(https://comfyworkflows.com)可正常访问(本人一直在用)
civital(https://civitai.com)有模型有工作流
esheep(https://www.esheep.com)国内平台
当你初次在自己的UI中加载了一个陌生的工作流,往往某些节点会显示红色报错,这是节点缺失的意思,你需要在界面右下角找到“管理器”,在那里面安装缺失的节点(一键安装,非常方便)。
同时你还可以关注ArXiv、github、twitter平台有关comfyui的咨询,以获得最新消息。
写在最后
开头说过在comfyui中可以拼凑出人鱼或兽人,其实就是构建节点工作流的过程,它不像webui那样局限于给定的几种生成或改变图像的方式,方式完全可以由自己决定,它的样子可以像人鱼兽人那样猎奇,让人看上去头大(其实大部分节点流都是这样的),不同的节点与连接方式会有不同的甚至令人惊异的效果。
我所讲解的内容只不过是comfyui的冰山一角,更多的需要读者自己去探索,自己去体会comfyui的优势
本文章到此结束,感谢阅读!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)