【会议】中国空间智能大会
中国空间智能大会(ChinaSI 2025)在深圳召开,聚焦空间智能领域十大前沿问题,涵盖理论构建、数据获取、多模态融合、智能体协同等关键方向。武汉大学龚健雅教授探讨了时空智能大模型的发展挑战,指出语言大模型与地理空间认知存在三大矛盾。北京大学陈宝权教授分享了现实世界数据获取与增强仿真的最新研究,浙江大学章国锋教授介绍了高效三维场景重建技术。会议展示了我国在空间智能基础理论、技术突破与产业应用的最

7月19日,中国空间智能大会(ChinaSI 2025)在深圳开幕。
文章目录
空间智能领域十大前沿问题
十大问题涵盖了从基础理论到实践应用的多个关键维度,包括:
一、空间智能基础理论框架的构建
如何明确空间智能的内涵、外延与核心任务,构建空间智能领域理论框架,并验证其对增强通用人工智能能力的作用?
二、高质量空间数据的获取与利用
如何获取足够的高质量训练数据,并设计高效的数据利用方式,为空间智能数据缩放定律的实现以及模型训练与优化提供坚实基础?
三、空间智能的统一表征与建模
如何探索适合空间智能的三维表征形式,设计紧凑丰富的空间表达,实现融合长上下文、跨尺度、跨模态信息的端到端统一空间大模型?
四、多模态融合的4D世界模型构建
如何通过视觉、触觉、听觉等多模态数据的跨模态对齐与动态交互预测,捕捉温度、电磁等多维物理场中的空间特征,构建时空统一的4D世界模型?
五、智能体的空间记忆建模
如何突破空间记忆建模与多模态任务规划,建立智能体的空间定位与导航能力,构建智能体的短期、中期、长期空间记忆力?
六、满足物理一致性的时空因果推理
如何构建具备物理定律一致性的时空因果推理框架,使空间智能系统能够理解和预测复杂动态环境中的因果机制?
七、空间智能与具身智能的深度融合
如何构建空间感知、规划、控制一体化的具身大模型,促进空间智能与具身智能的深度融合,实现机器人在未知复杂环境中的自主运动?
八、多智能体的空间智能协同决策
如何通过主动探索与语义理解协同优化,实现多智能体在复杂场景中的协同感知、联合规划与高效执行?
九、大尺度空间智能引擎构建
如何解决城市等地理空间的空间智能系统面临的大规模三维重建生成、交互、决策等难题?如何构建面向极端场景(如深空、深海、深地)与垂直行业(如测绘、制造、采矿)的专用大范围空间智能引擎?
十、面向边缘智能的轻量化空间计算
如何设计轻量化架构、敏感数据可信计算及开放环境自进化机制,实现在机器人、无人机等端侧设备的空间智能模型高效部署?
一、时空智能大模型的发展与思考
来源:武汉大学 龚健雅

1.研究背景




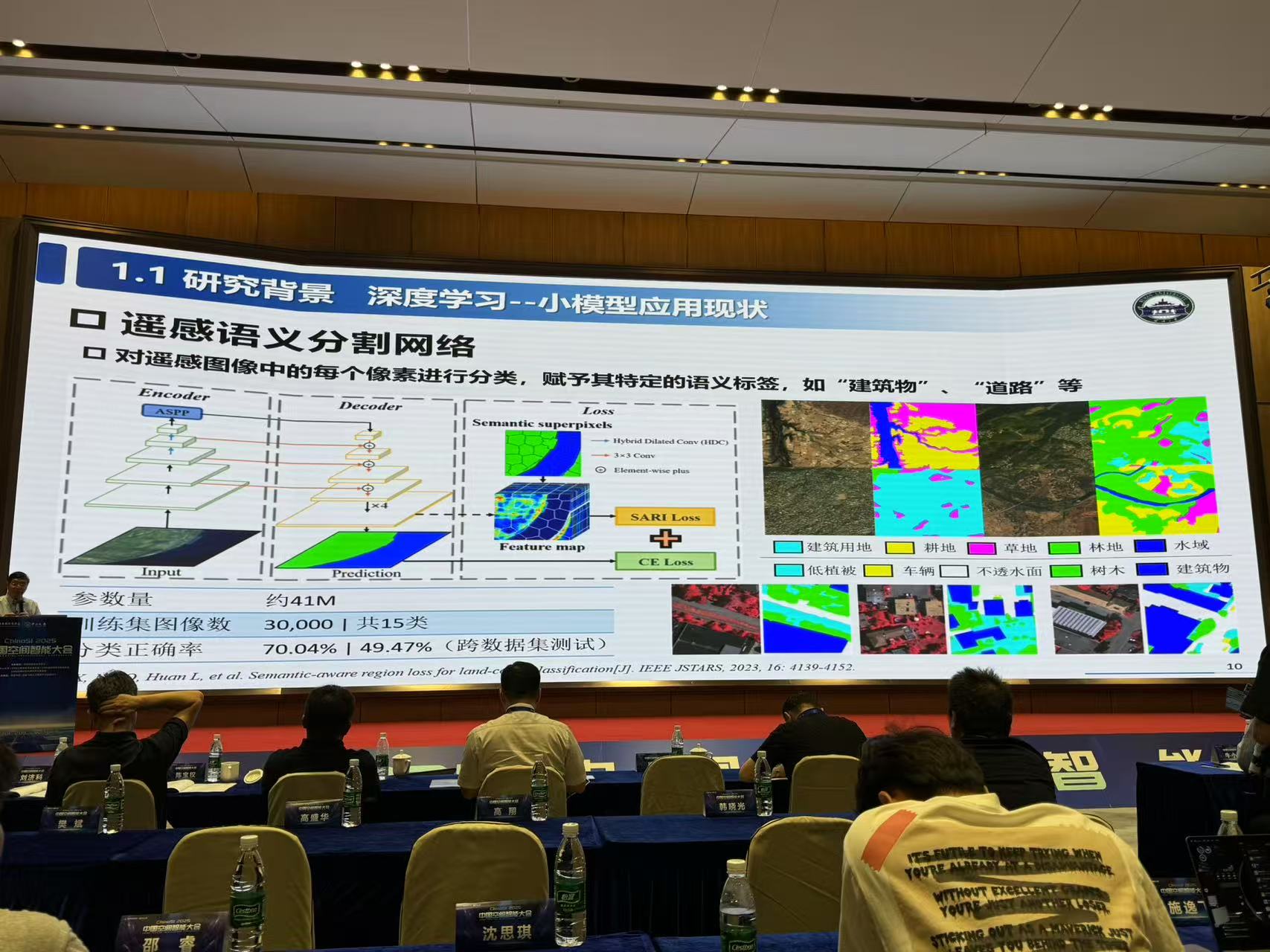


2.语言大模型现状
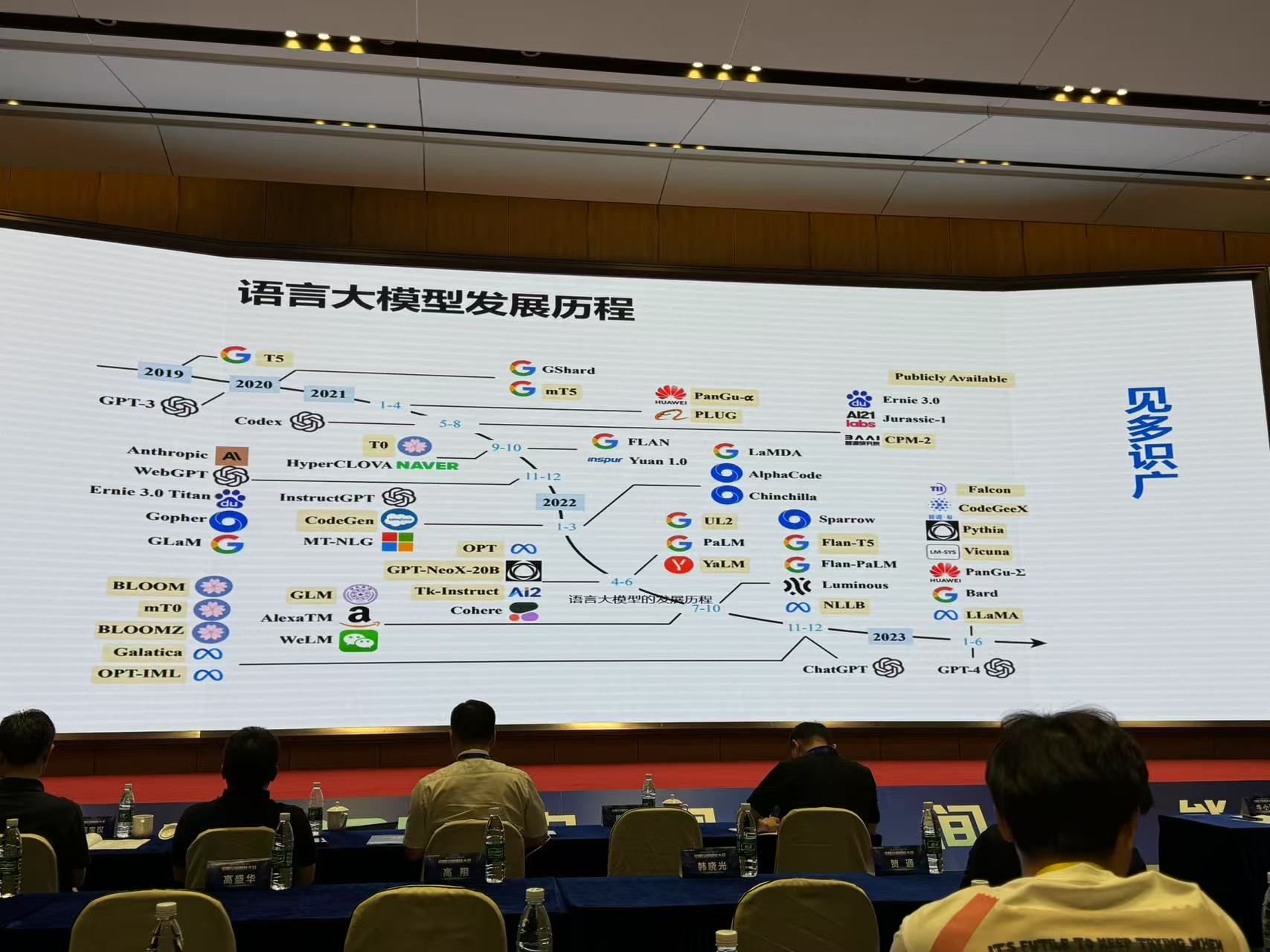
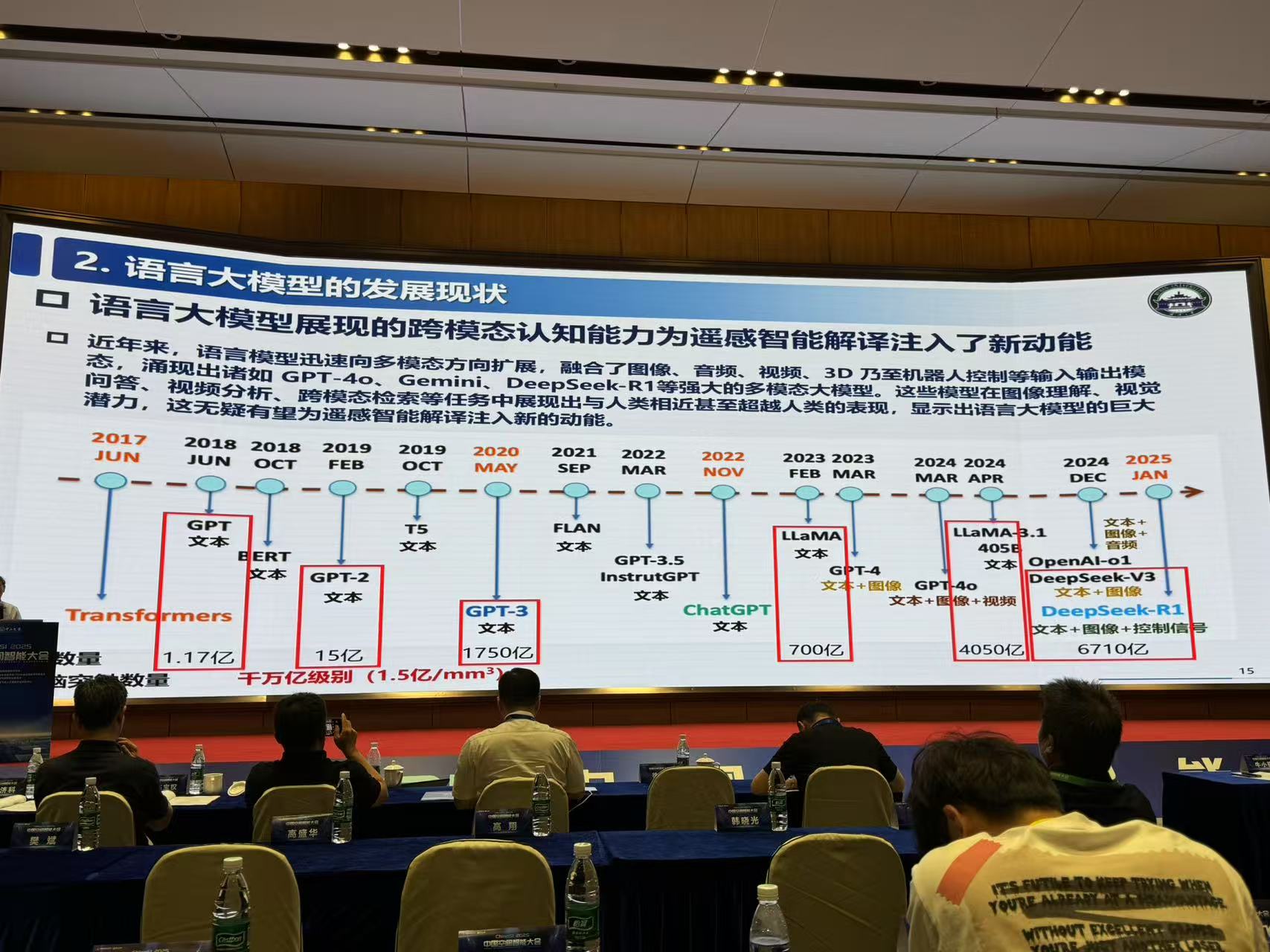
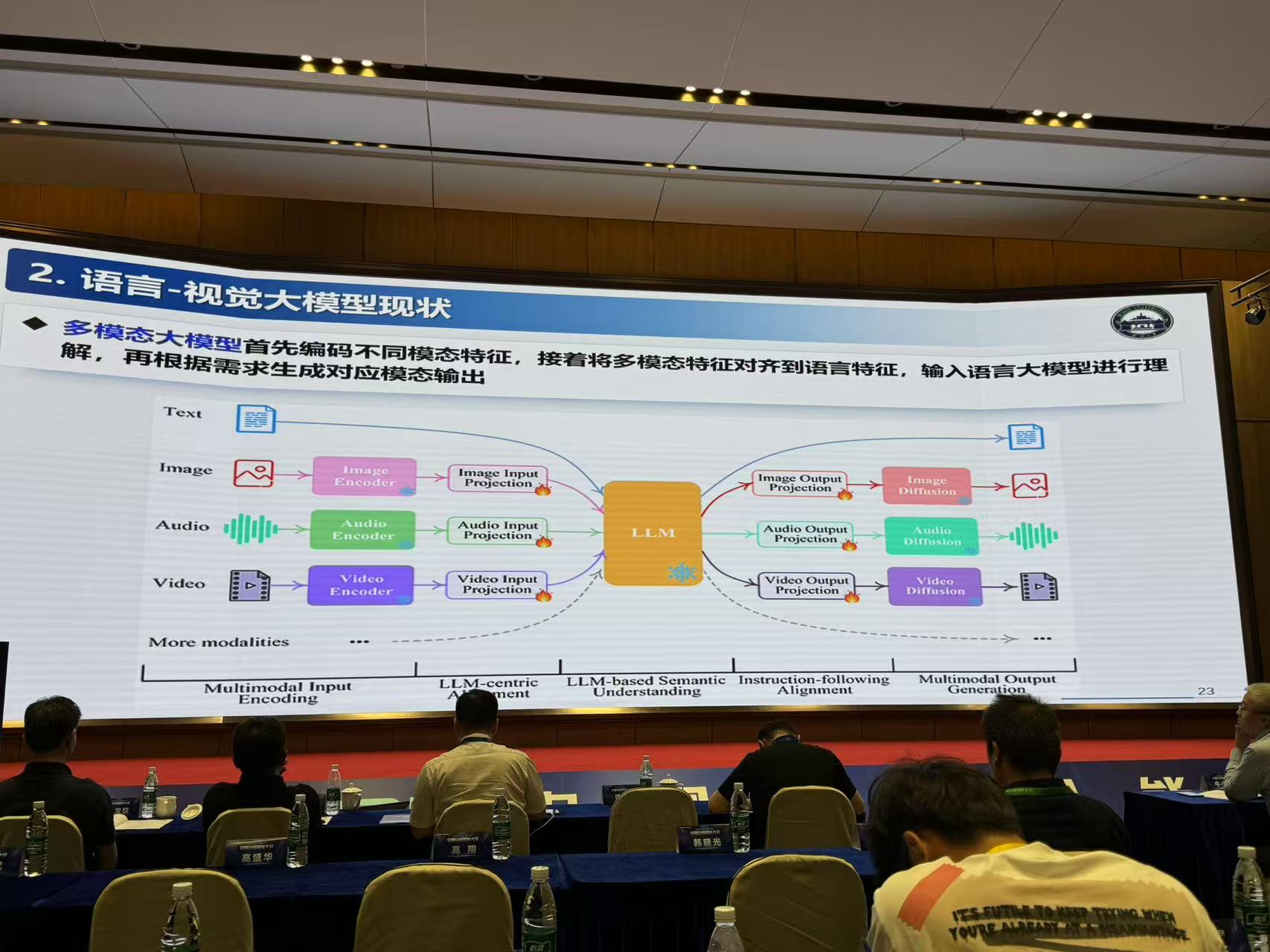
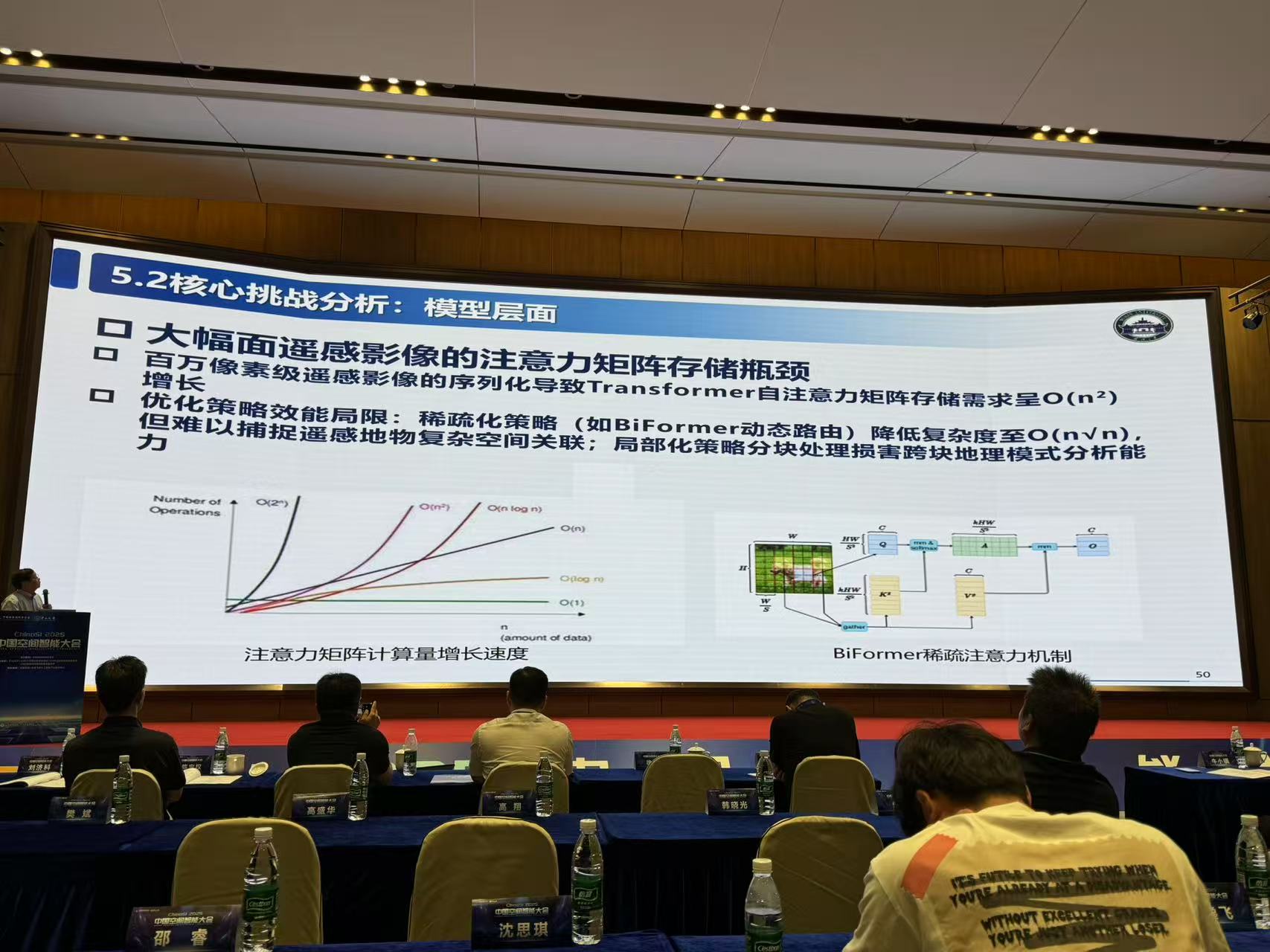
3.语言大模型与遥感时空信息之间的核心矛盾
- 空间离散化矛盾:将连续地理空间分割为序列化图像块的处理方式破坏地物目标的整体性与拓扑关联(如交通/水系网络的结构特性)
- 位置编码适配矛盾:传统位置编码方案难以匹配地理坐标系的非线性特性导致空间距离语义失真,模型对地理实体空间关系的建模能力受限口
- 认知范式矛盾:自然语言处理的统计关联范式与地理空间的物理规律(地形/水文机制)存在根本性冲突,数据驱动方法难以保障地理逻辑严密性
关键难点
如何构建既保持语言大模型语义理解优势,又符合地理空间认知规律的新型计算范式?


4.遥感大模型发展现状





5.挑战



二、现实世界获取与增强仿真
来源:北京大学 陈宝权












三、基于新型连续表达的智能仿真
来源:北京大学 楚梦渝






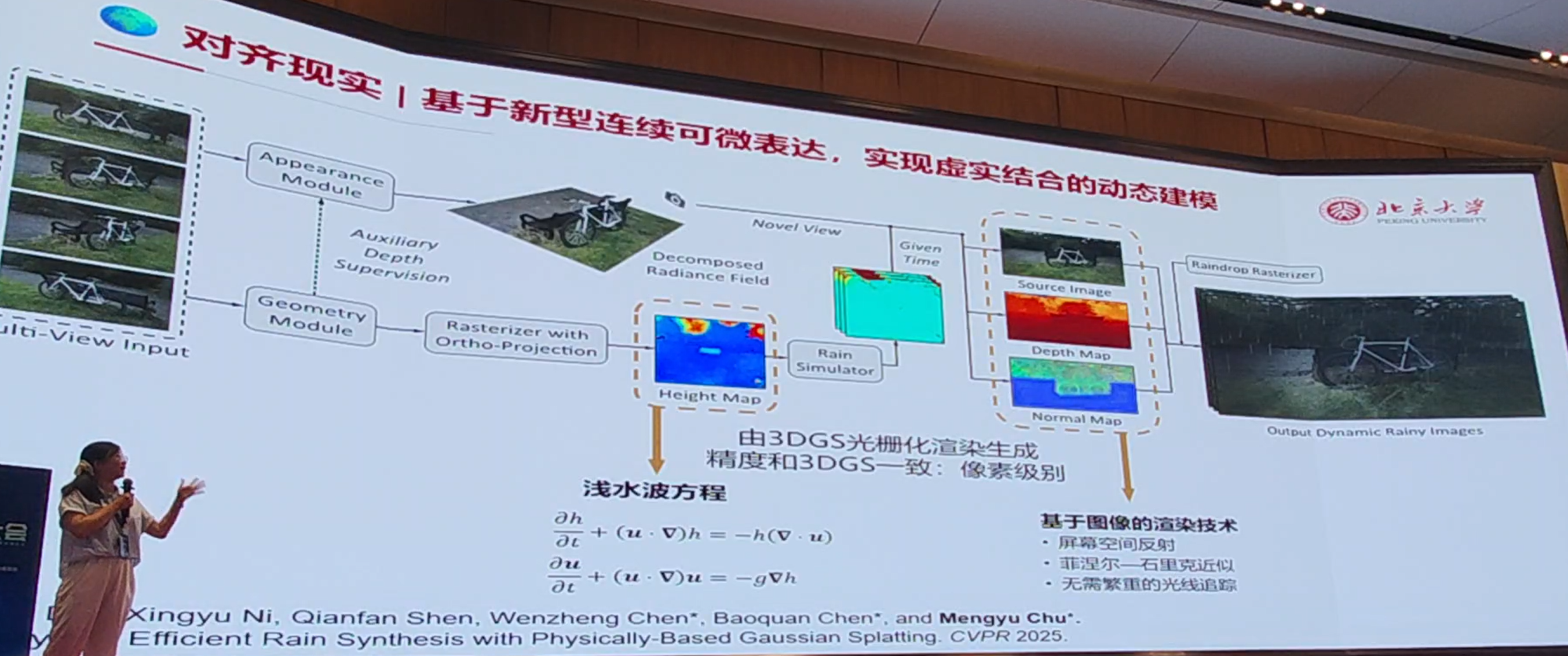








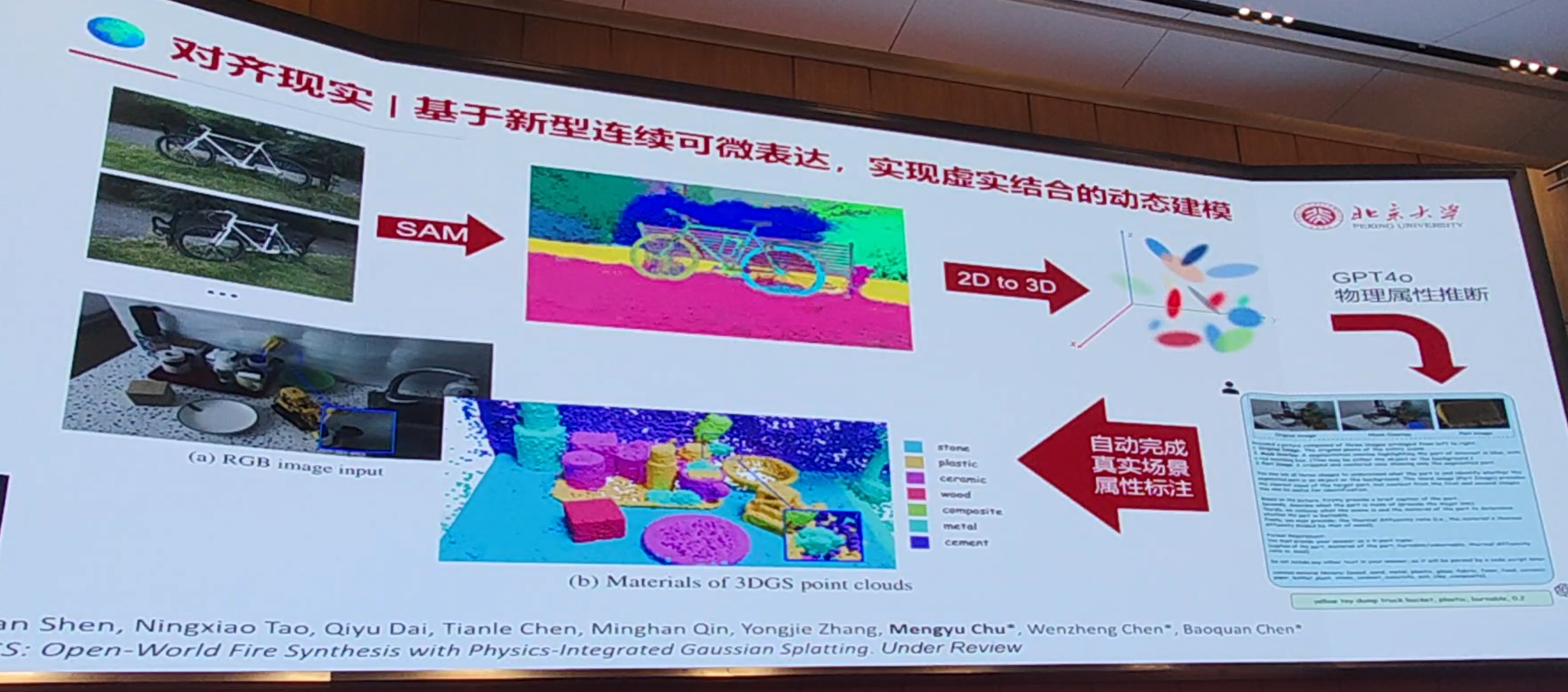
VFX调用了传统仿真工具belnder:




流体的速度场表达:精度自适应



路径通过自动微分,获得速度:添加长程的物理约束:



四、从视频生成走向生成式世界模型
来源:北京大学 袁粒




SORA用了3D VAE vs 小波变换的频域压缩:
cuda vs CANN(升腾)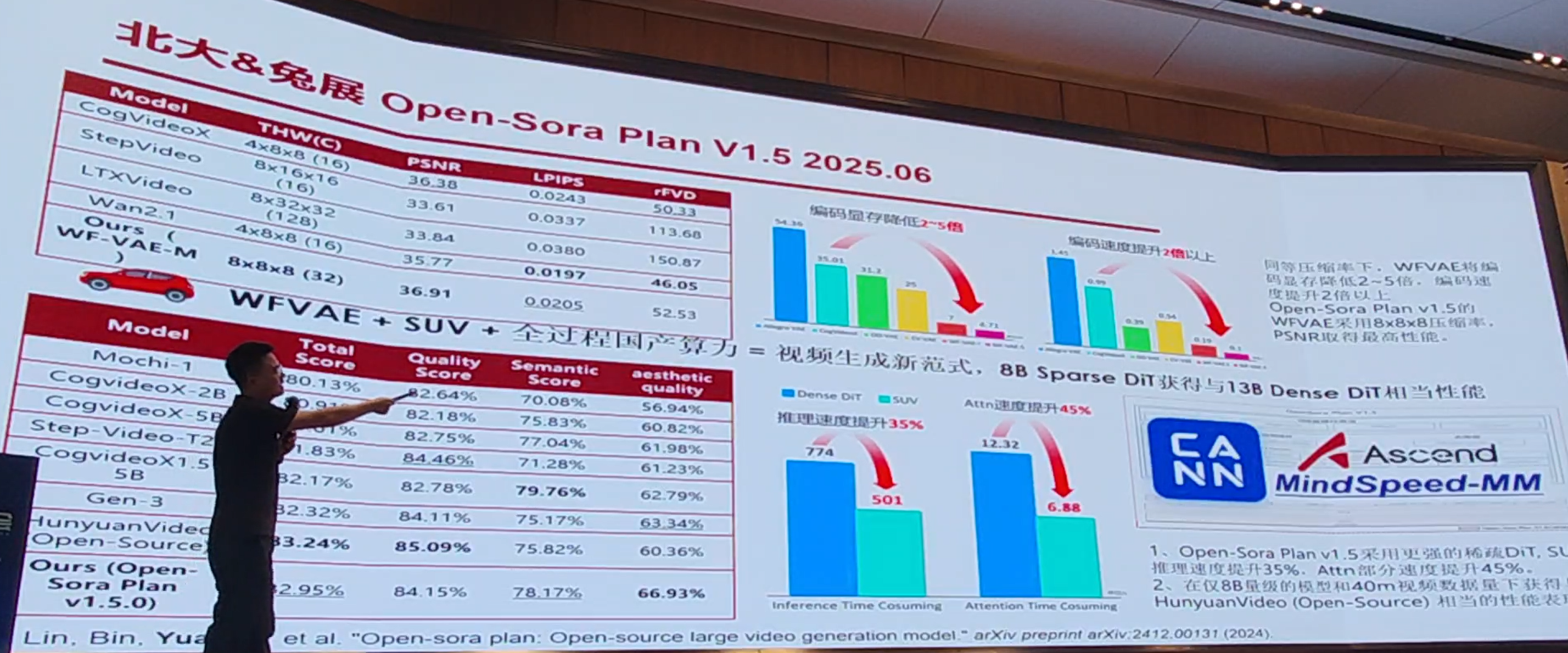



多模态语言模型:Auto Regression
生成模型:Diffusion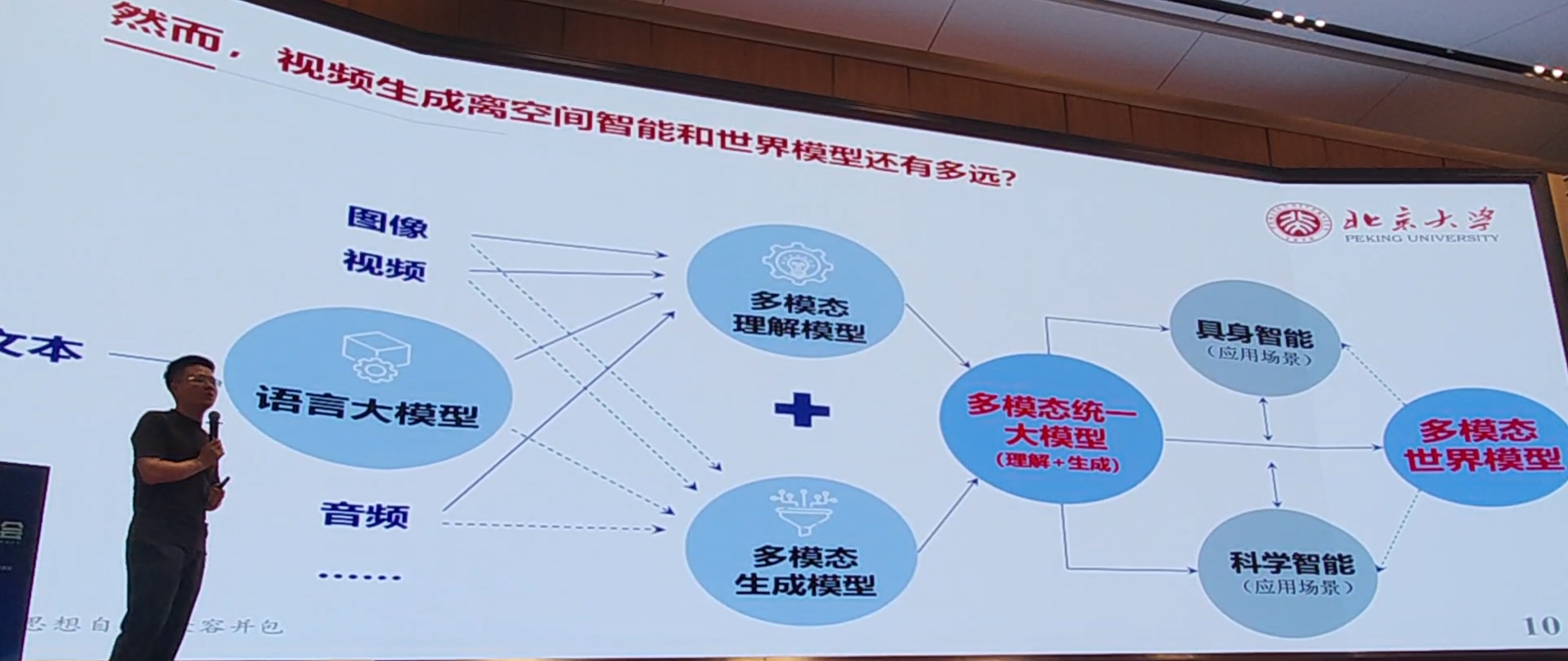
视频生成离空间智能和世界模型还有多远?
- 1.视频生成模型不具备理解能力(非理解和生成统一架构)
- 2.3D新视角生成能力差,视频生成模型缺乏显式的场景3D先验
- 3.4D新视角动态生成能力差,视频生成模型缺乏显式的4D先验
- 4.视频生成透视视图场景信息不足、空间记忆一致性差、相机位姿注入难统


Diffusion、flow:补充连续模态丢失的信息; AR作为backbone是因为计算机特性


与腾讯合作的新视角生成模型: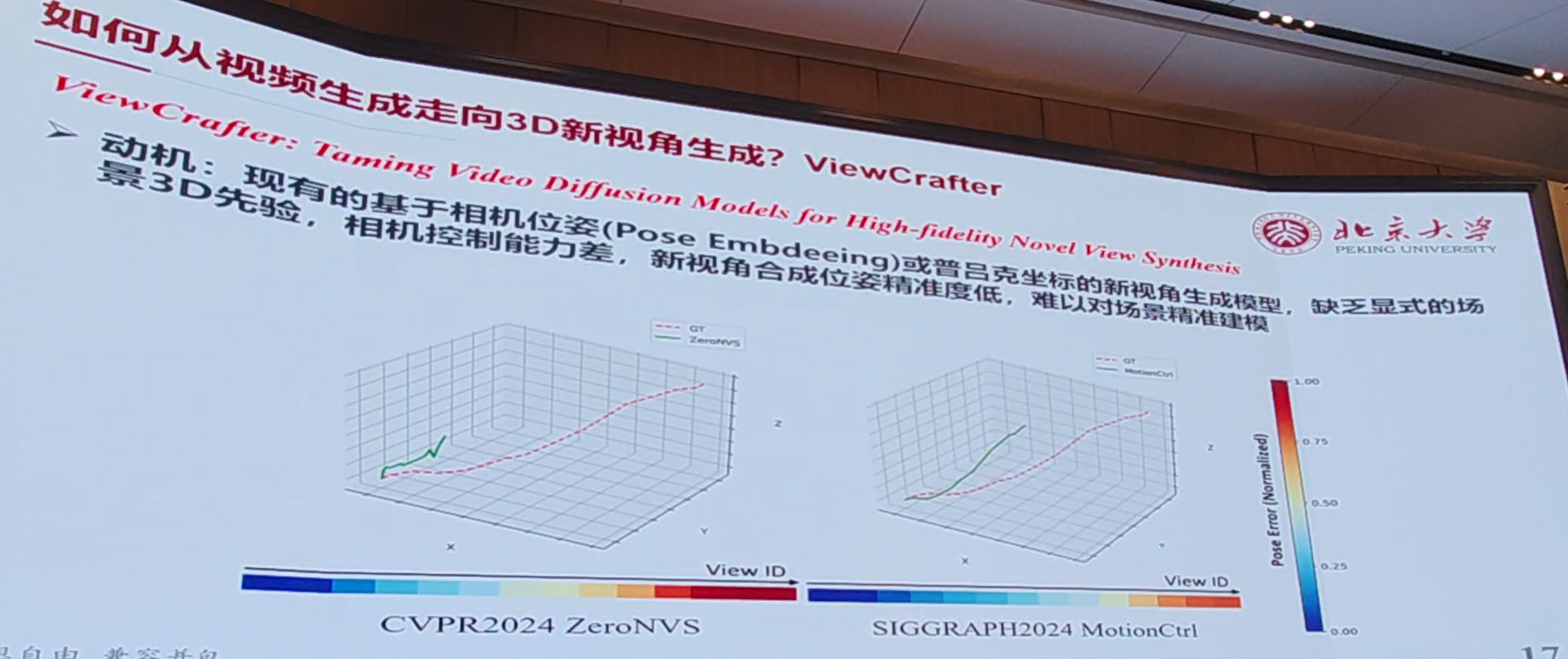







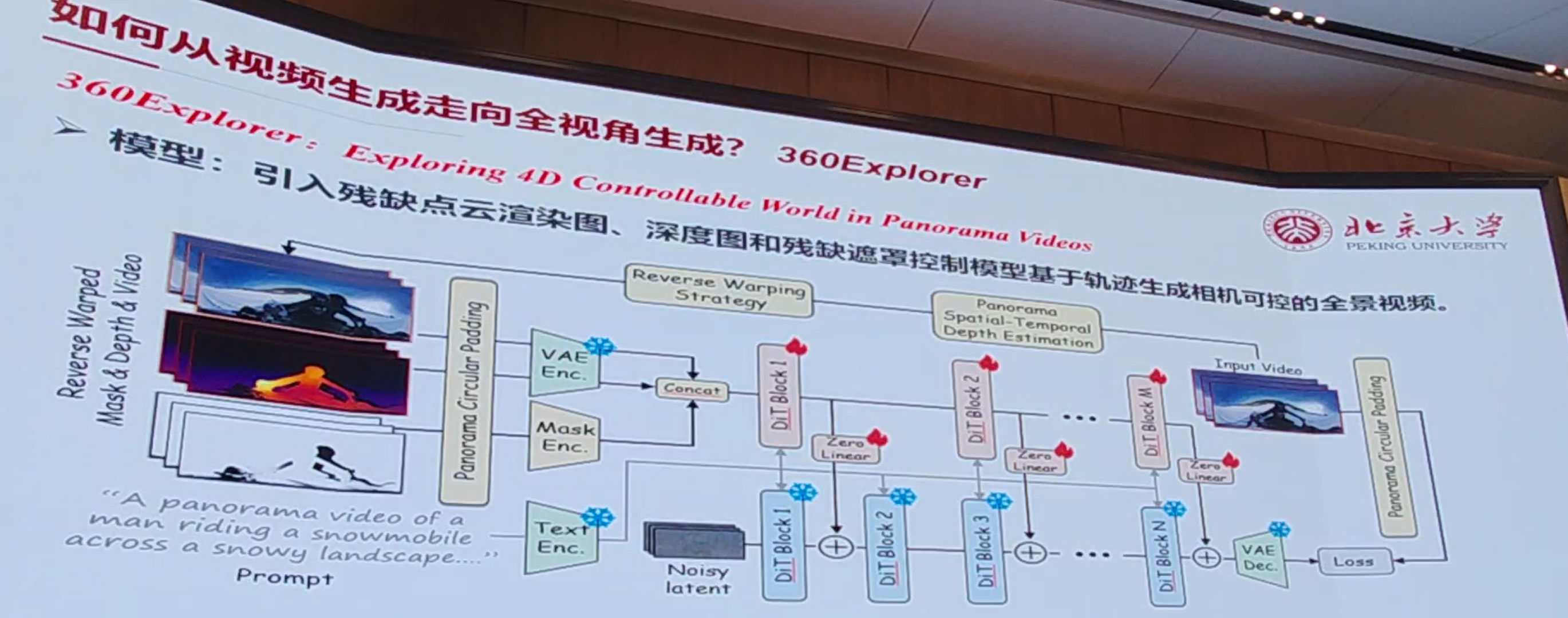



挑战:
- 视频生成是世界模型基础,空间智能是世界模型在视觉维度的投影;
- 视频生成离空间智能和生成式世界模型距离都还很远
- 空间智能走向世界模型,不能只有视觉模态,语言模态+视觉模态原生统一是核心;
- 现有挑战:视频生成和理解未统一、空间感知(理解)不足、透视视图场景信息不足、空间记忆一致性差、相机位姿注入难统一等;
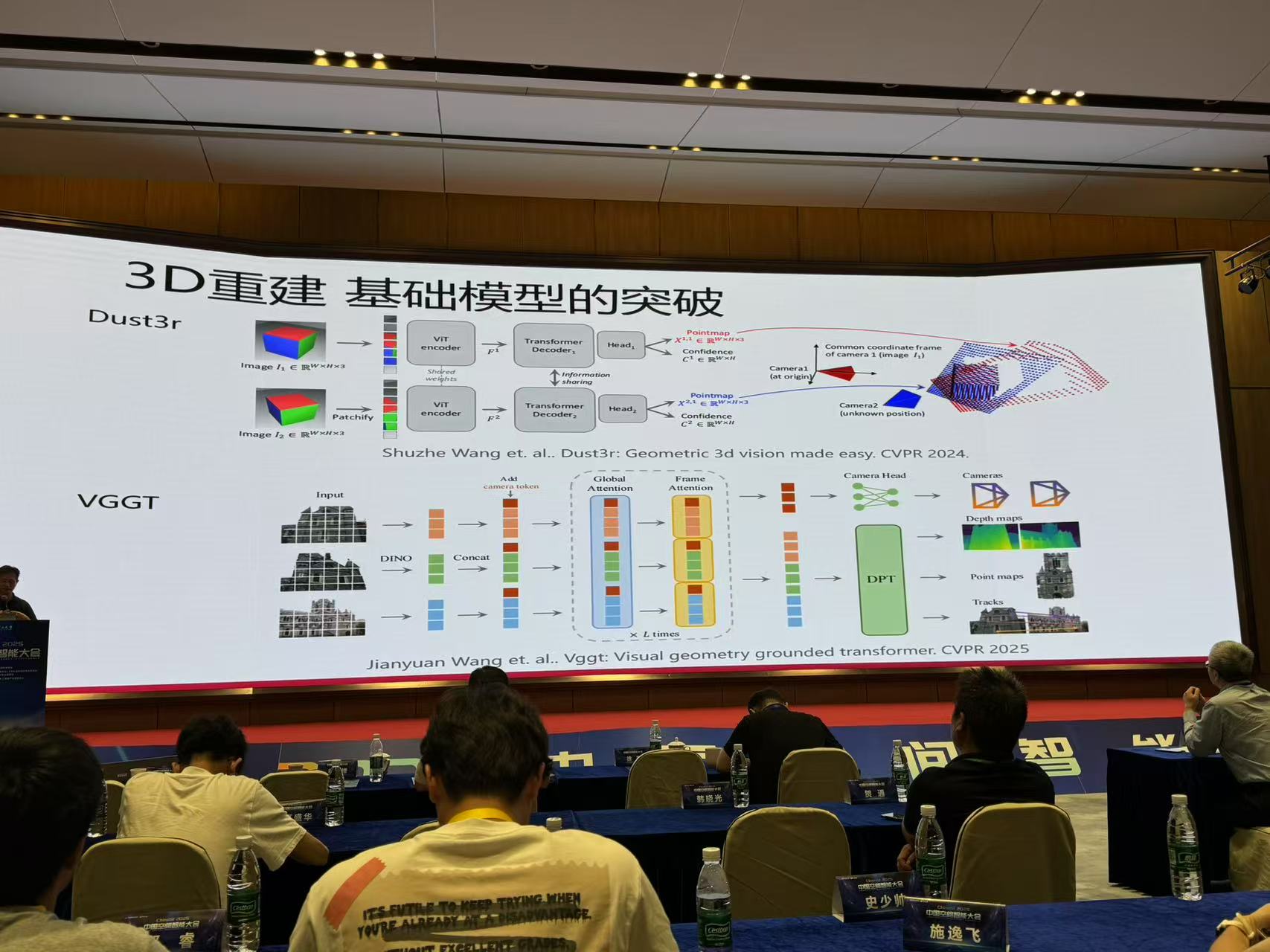
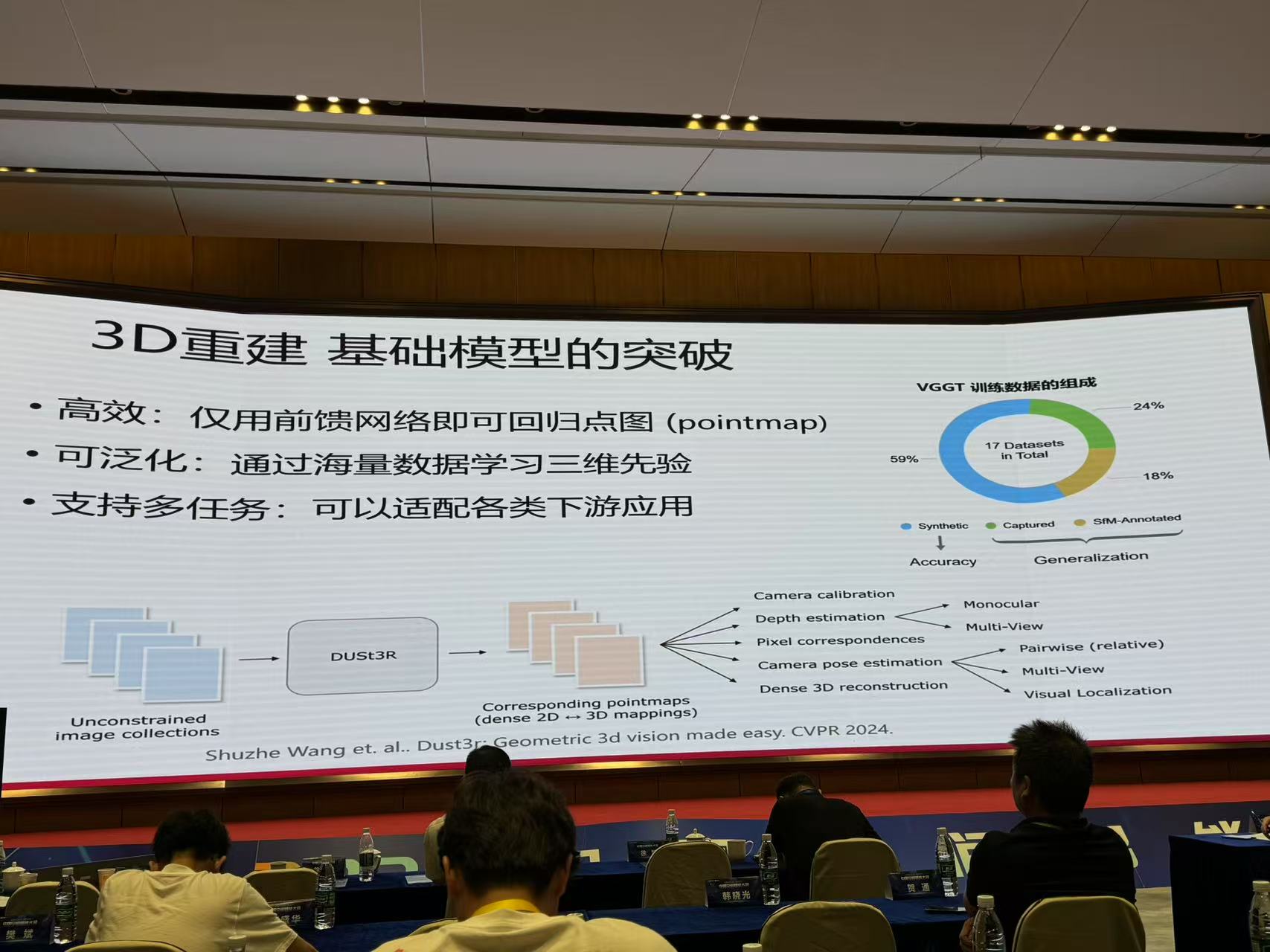
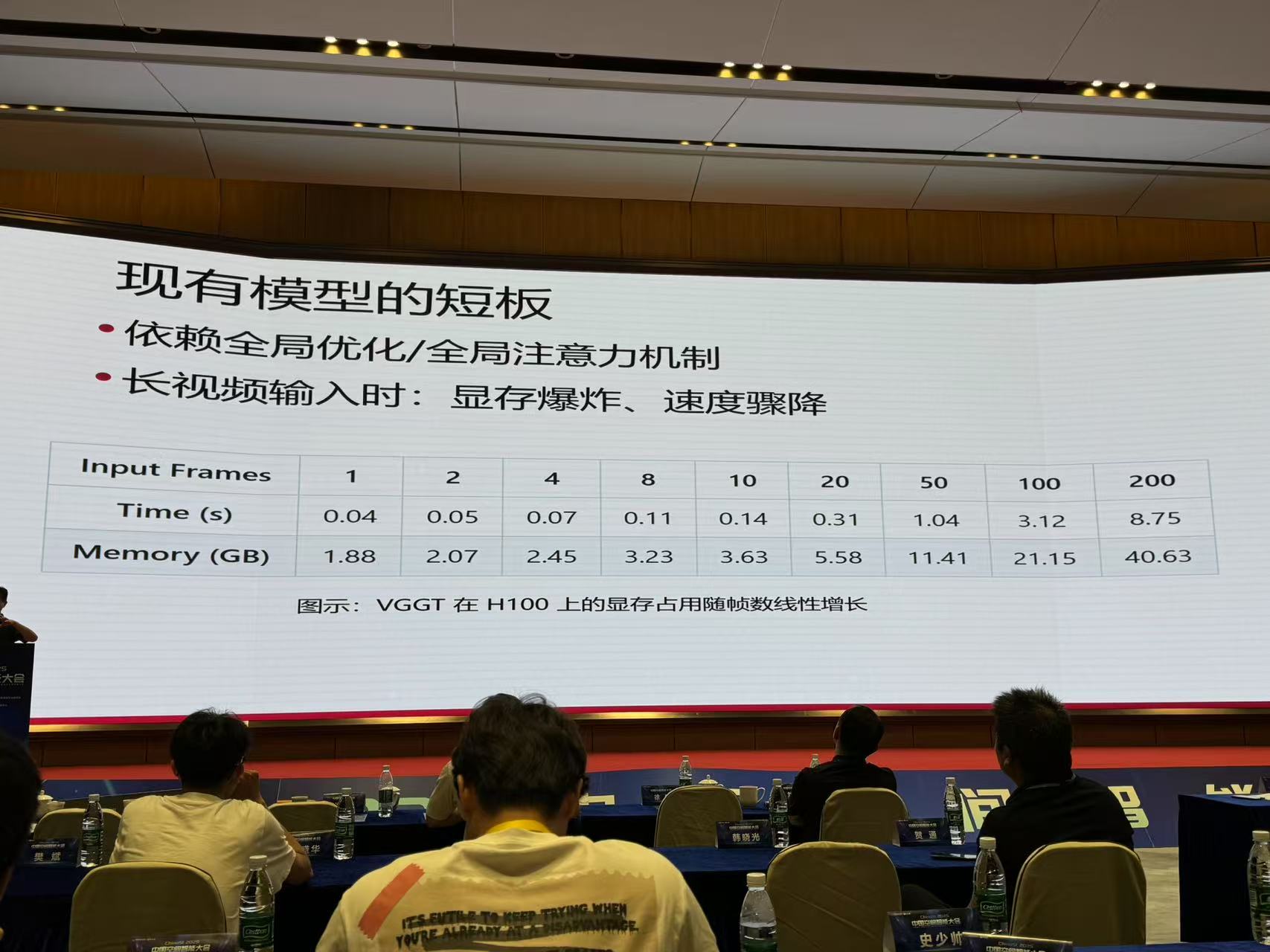
五、高效可控的三维场景重建与生成
来源:浙江大学 章国锋








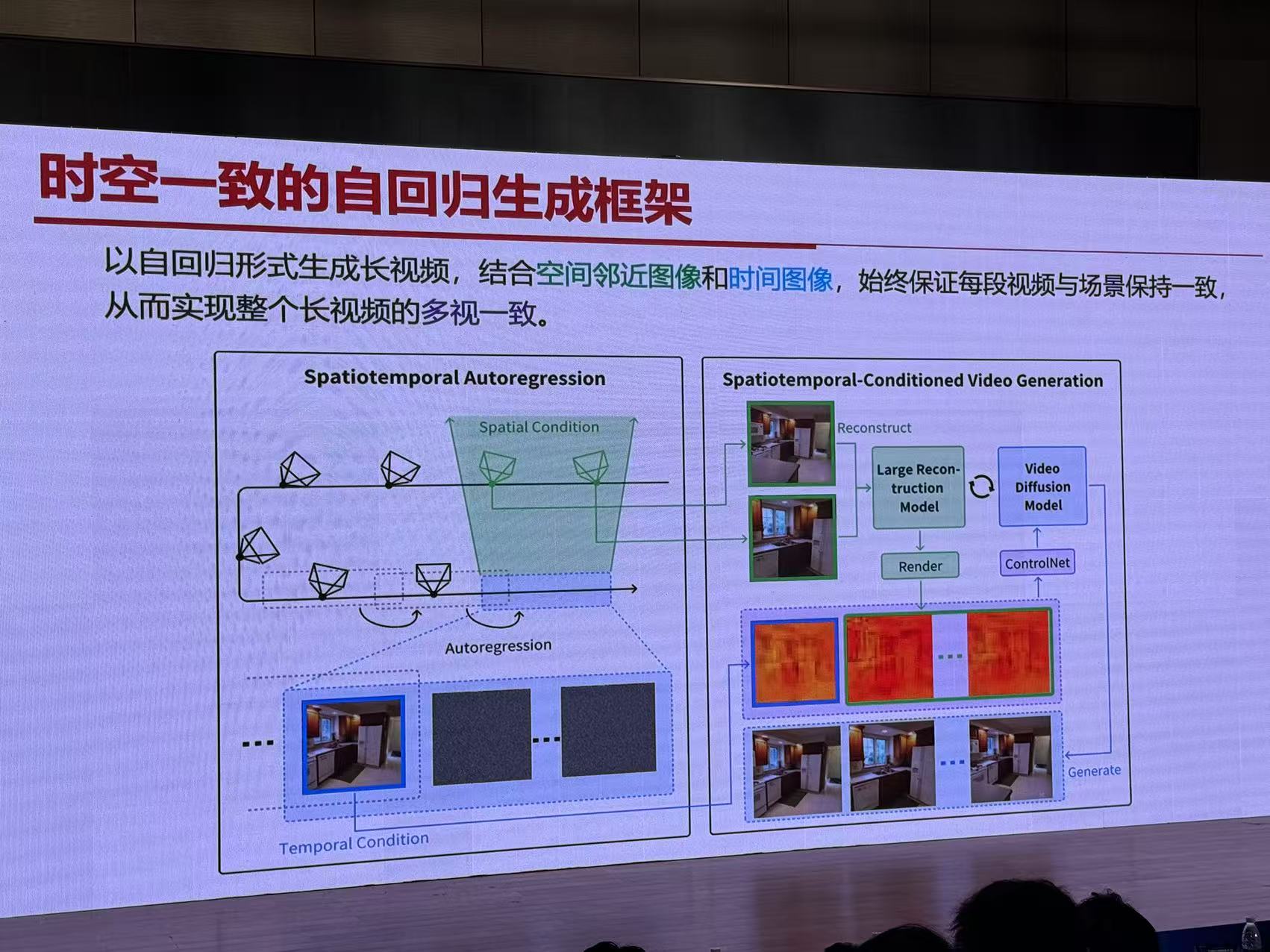
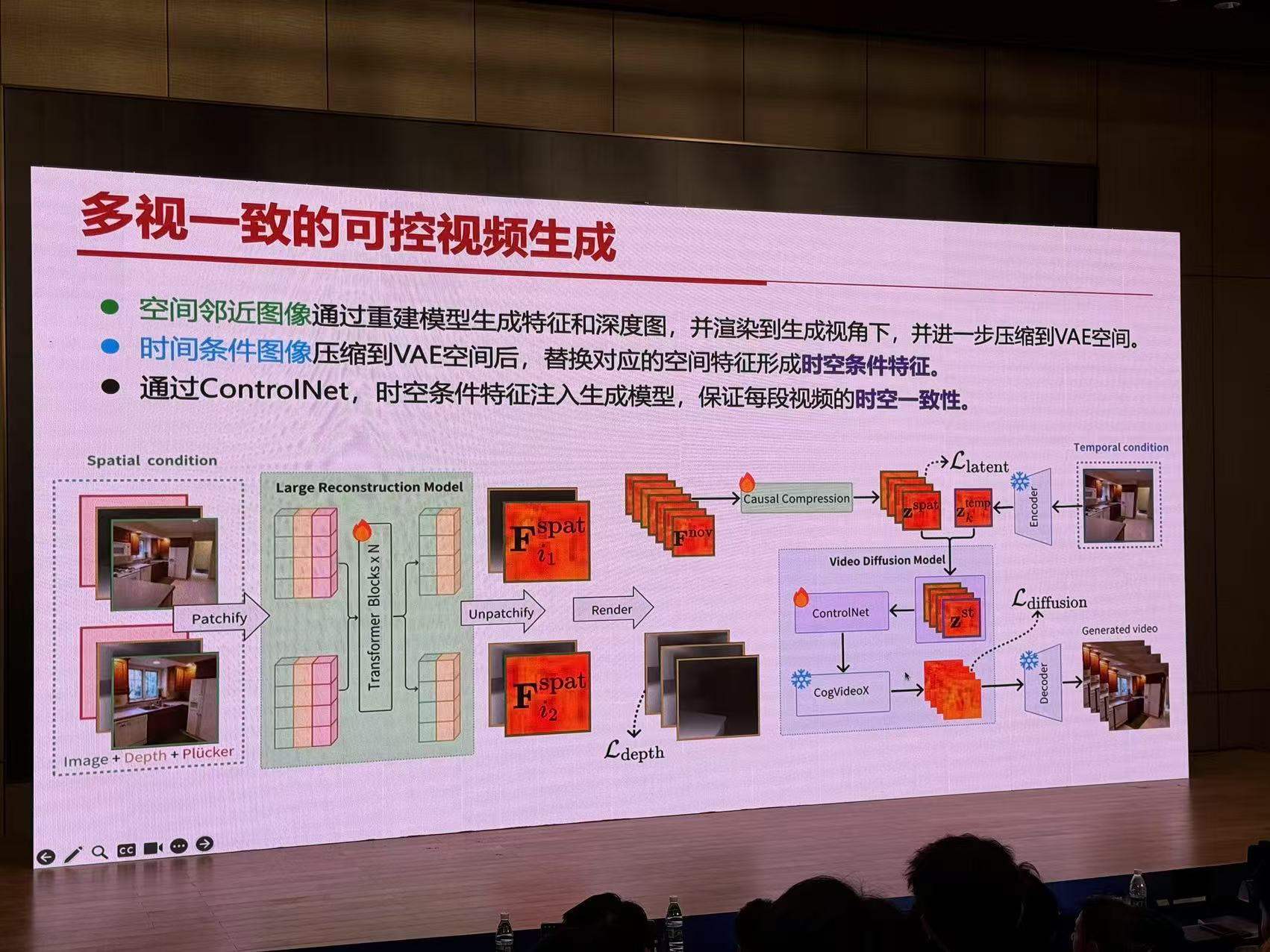


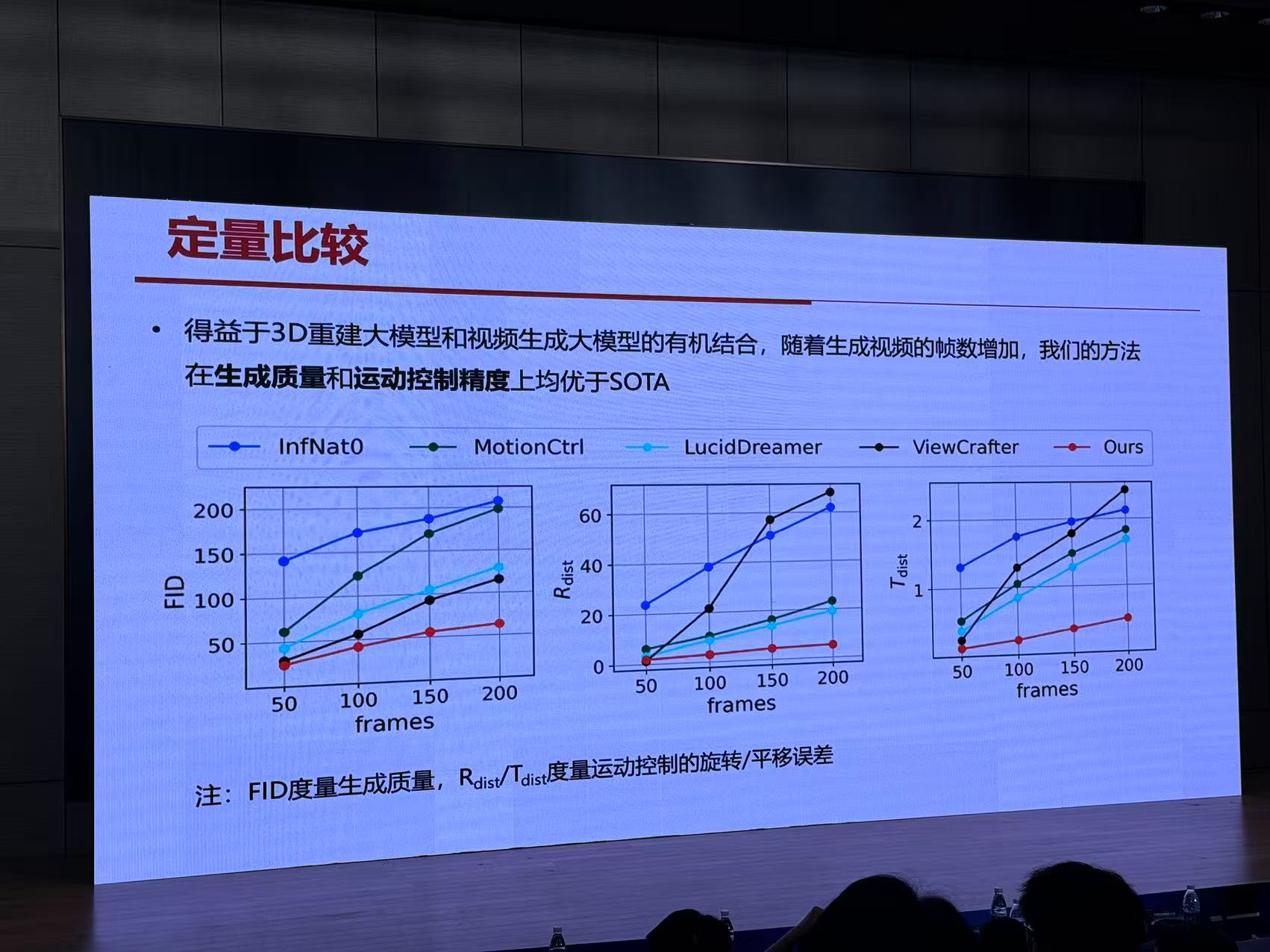

总结与展望
随着大模型的发展,重建与生成任务已开始融合
- Free360:利用生成大模型补全不可见区域,实现极度稀疏视角的三维重建:
- StarGen:利用重建大模型重建并渲染作为控制条件,实现时空一致的长视频生成
未来发展趋势
- 重建与生成进一步融合,最终实现同时具备重建与生成能力的原生三维大模型
- 如何在移动端实时,芯片化和端云协同将是一个趋势
六、可重光照三维高斯点云重建几何优化与光线追踪
来源:南京大学 姚遥


报告提纲:
1.光流匹配大模型先验的3DGS几何重建(Flow Distillation Sampling)


2.基于一体化摄影测量大模型的3DGS稀疏重建(Matrix3D)







3.可重光照3DGS点云重建(Relightable 3DGS)

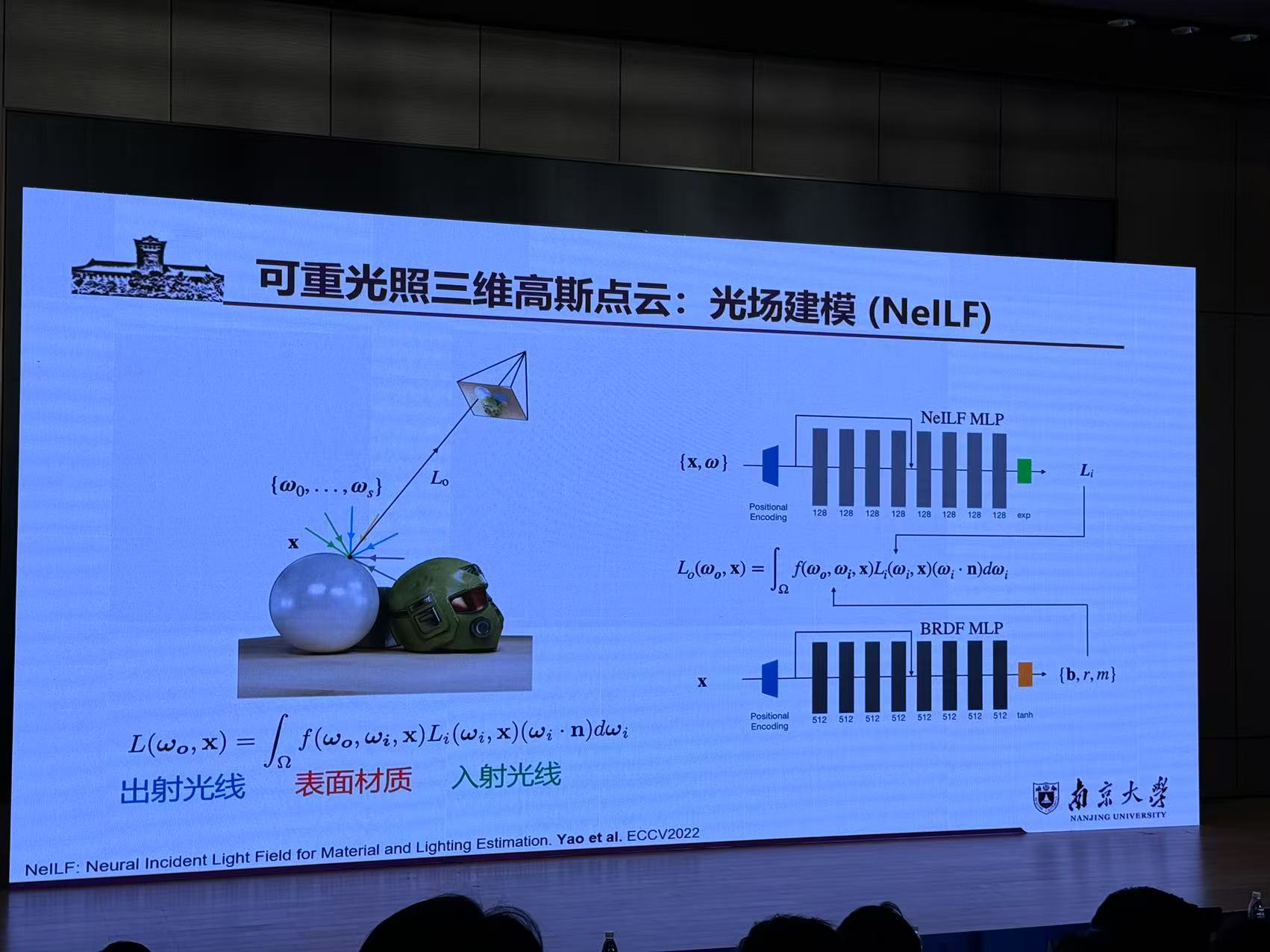

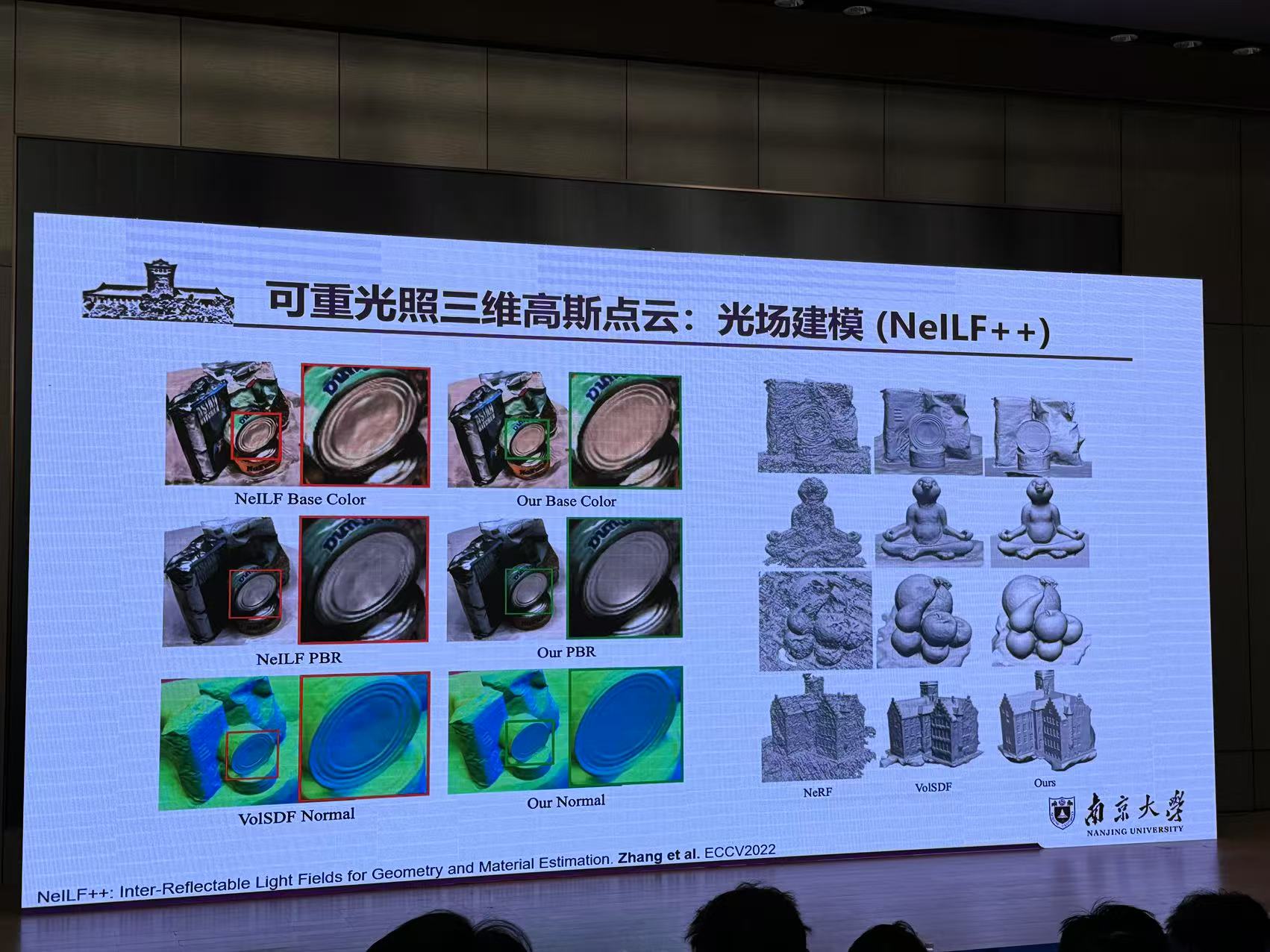
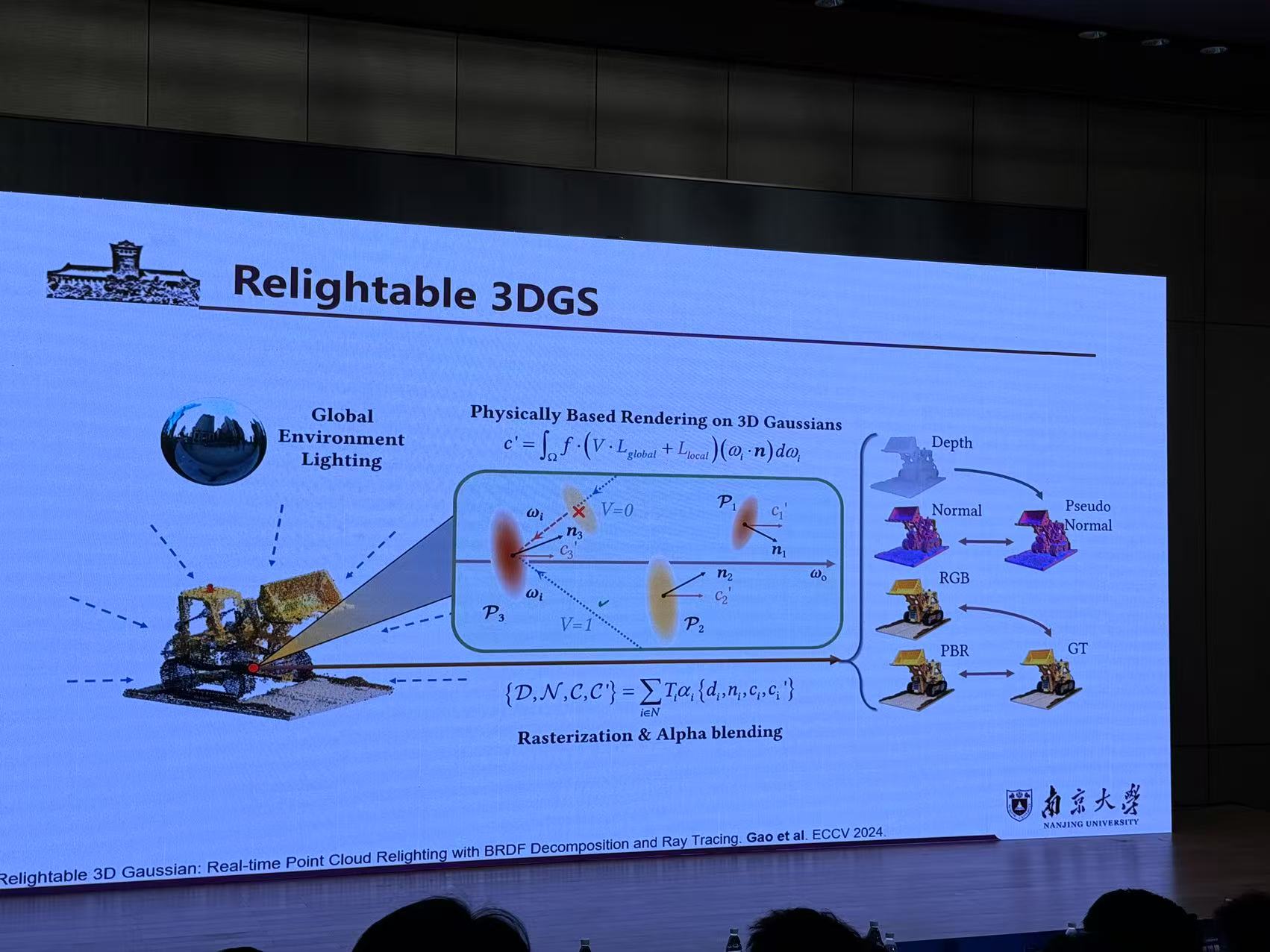


4.高真实感3DGS场景组合(Compositional 3DGs)







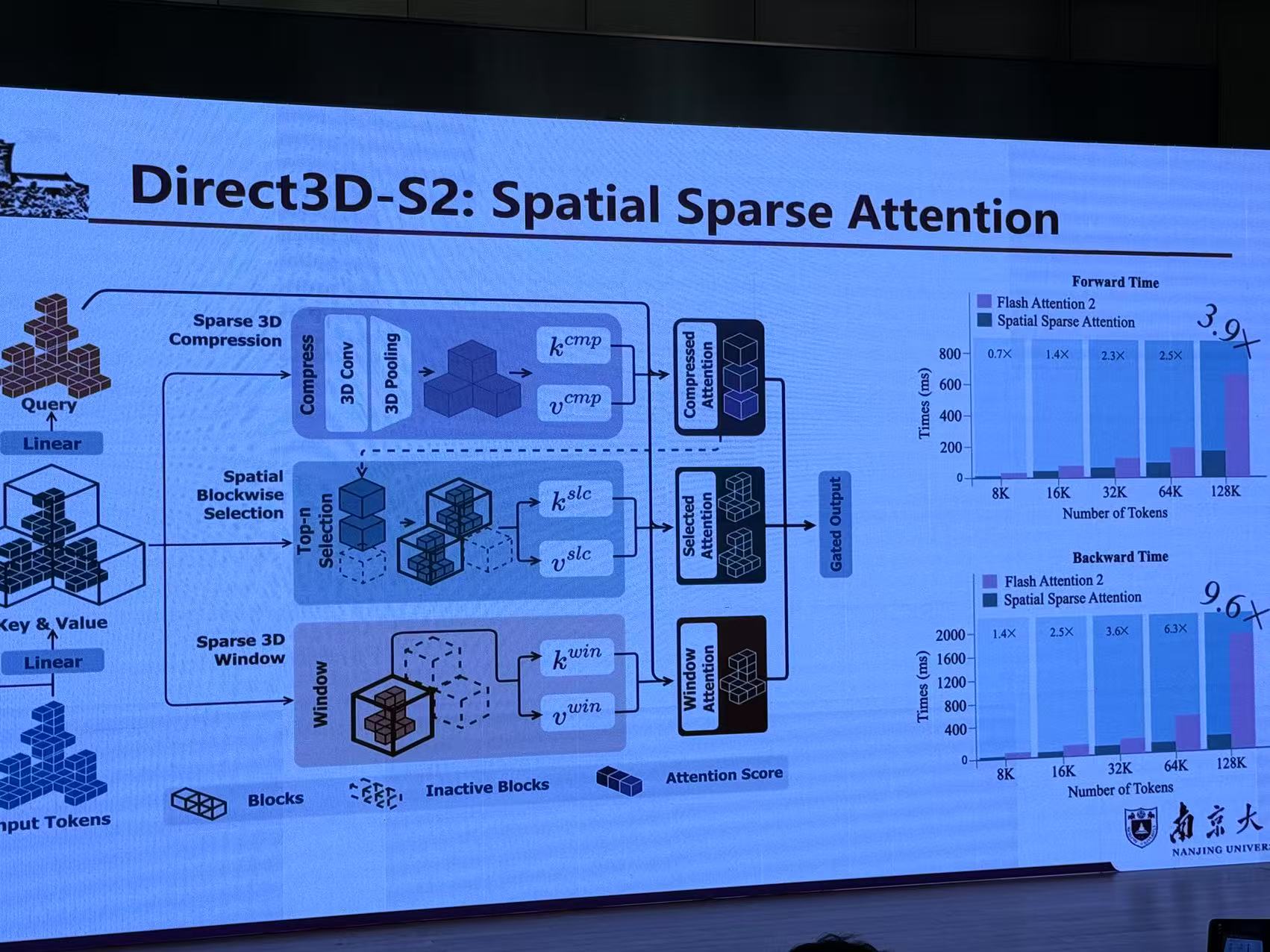


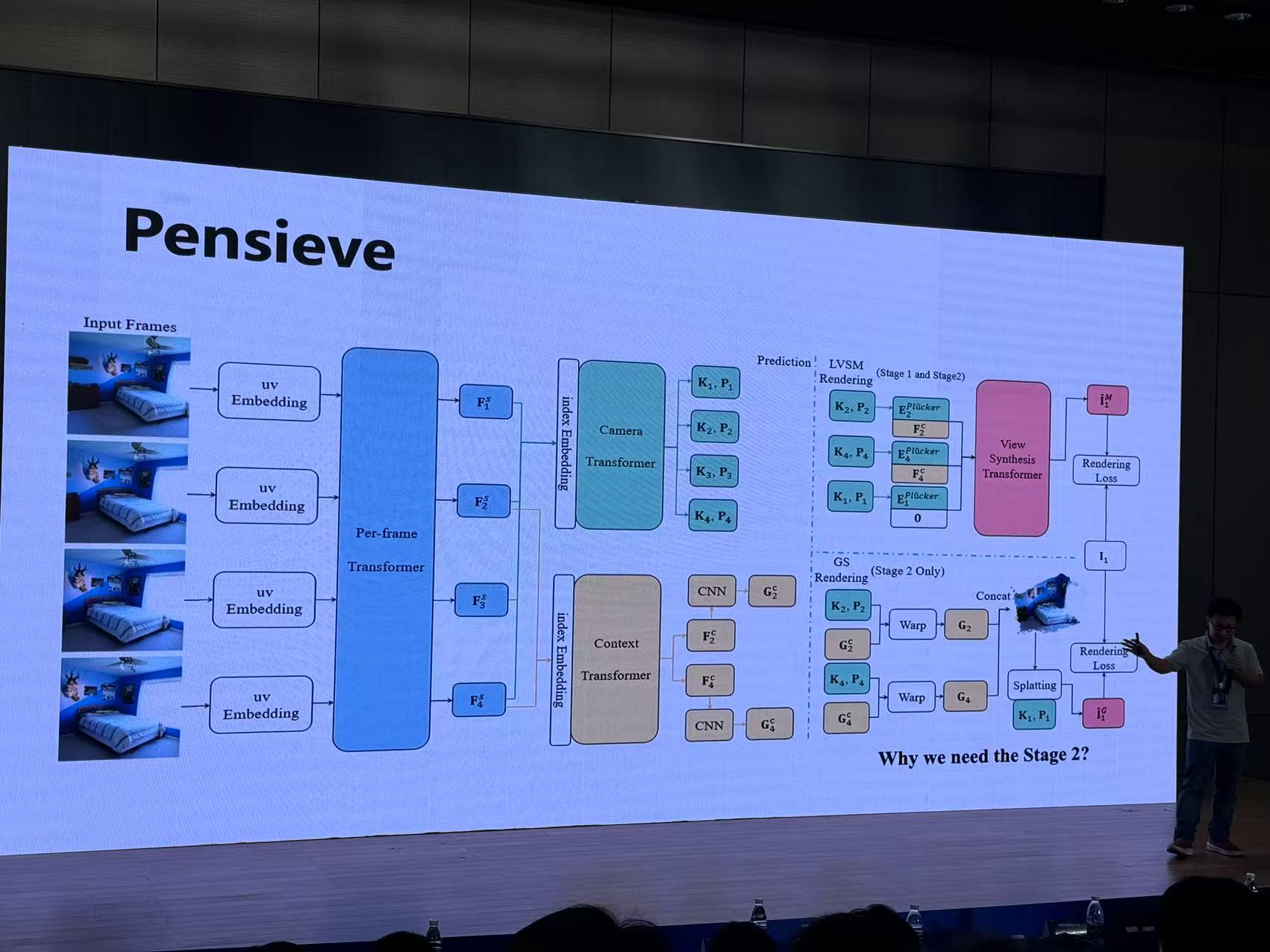
七、Recollection from Pensieve:Novel Synthesis via Learning from Uncalibrated Videos
来源:香港大学 高盛华

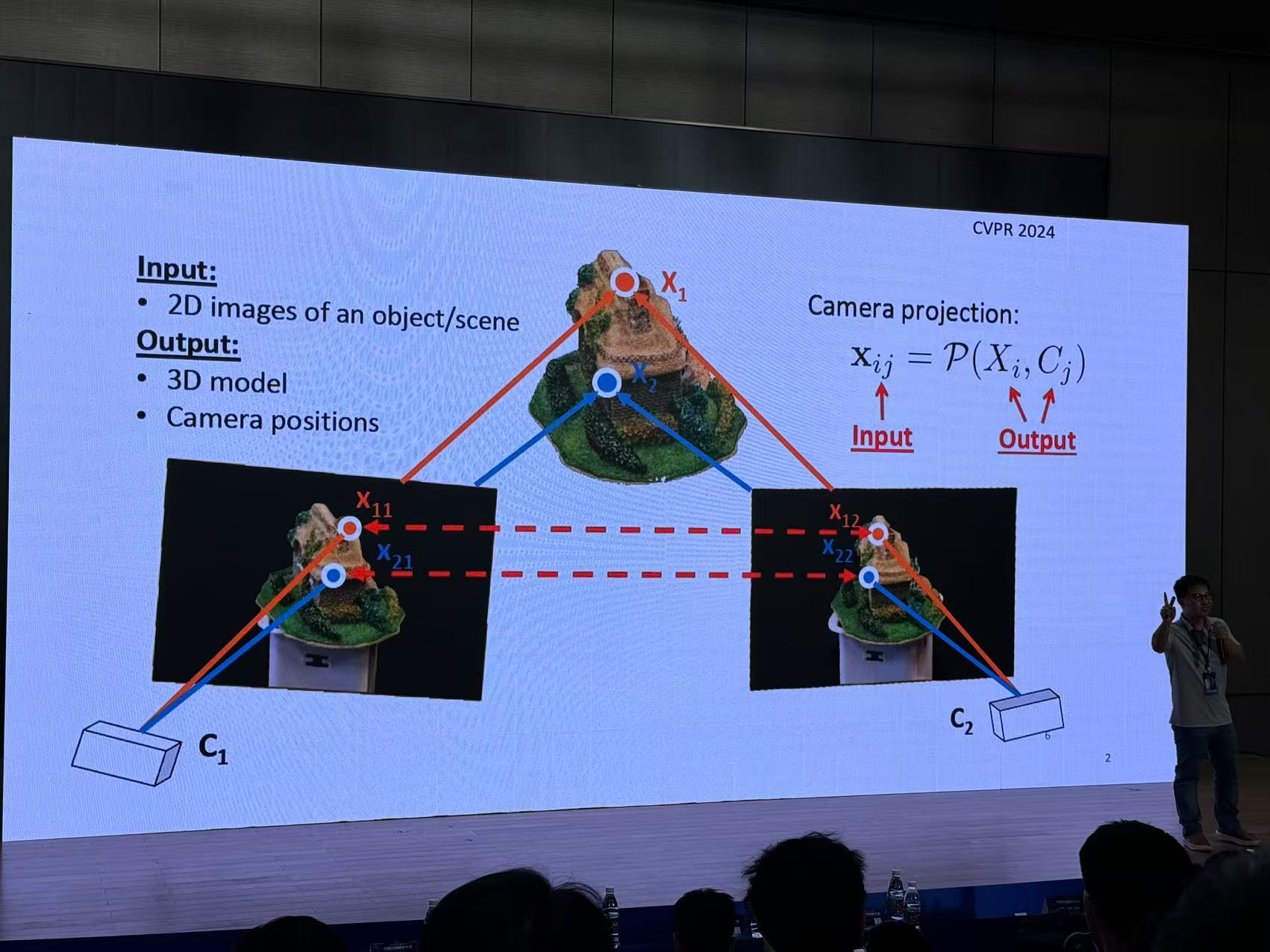

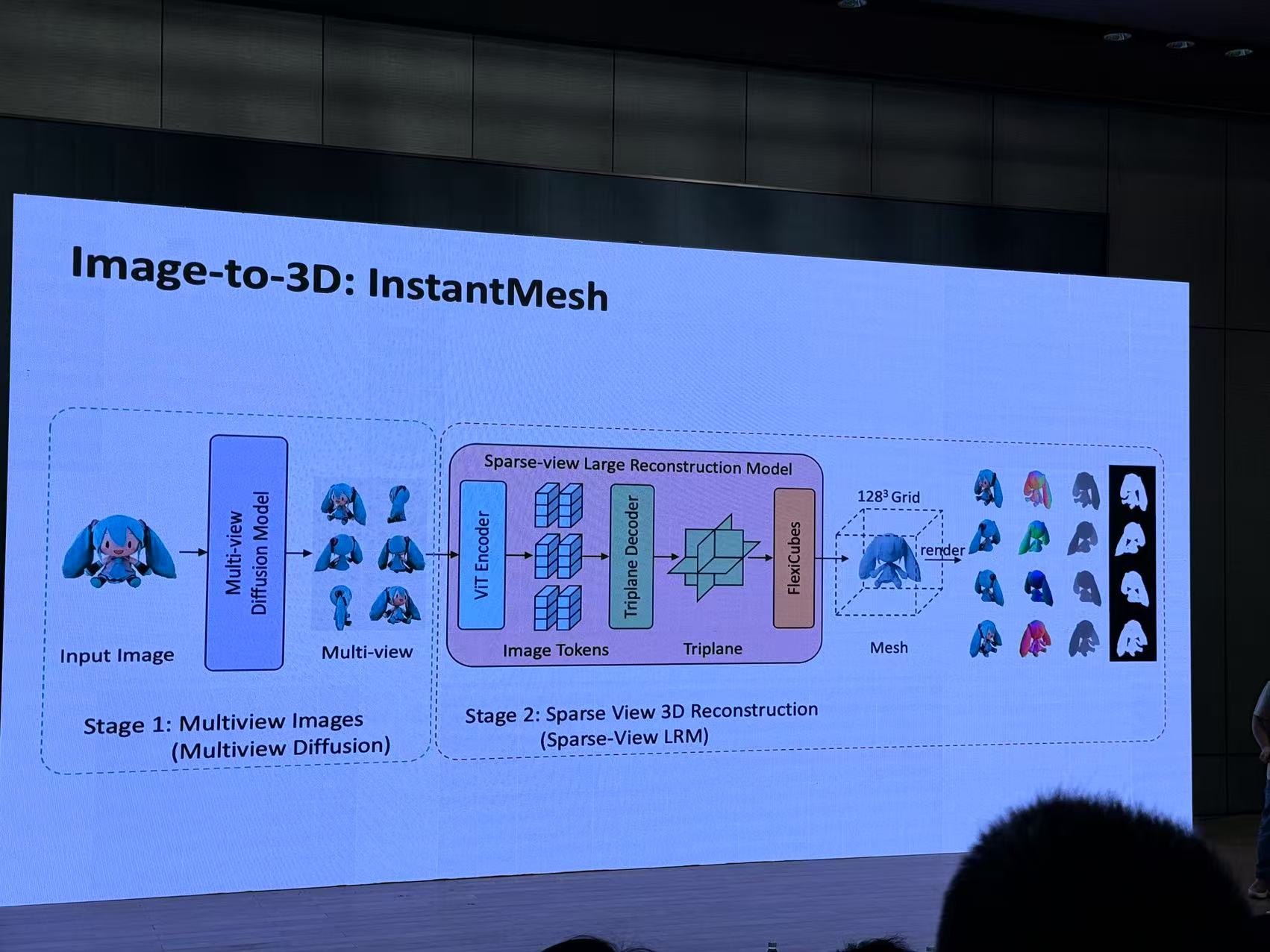


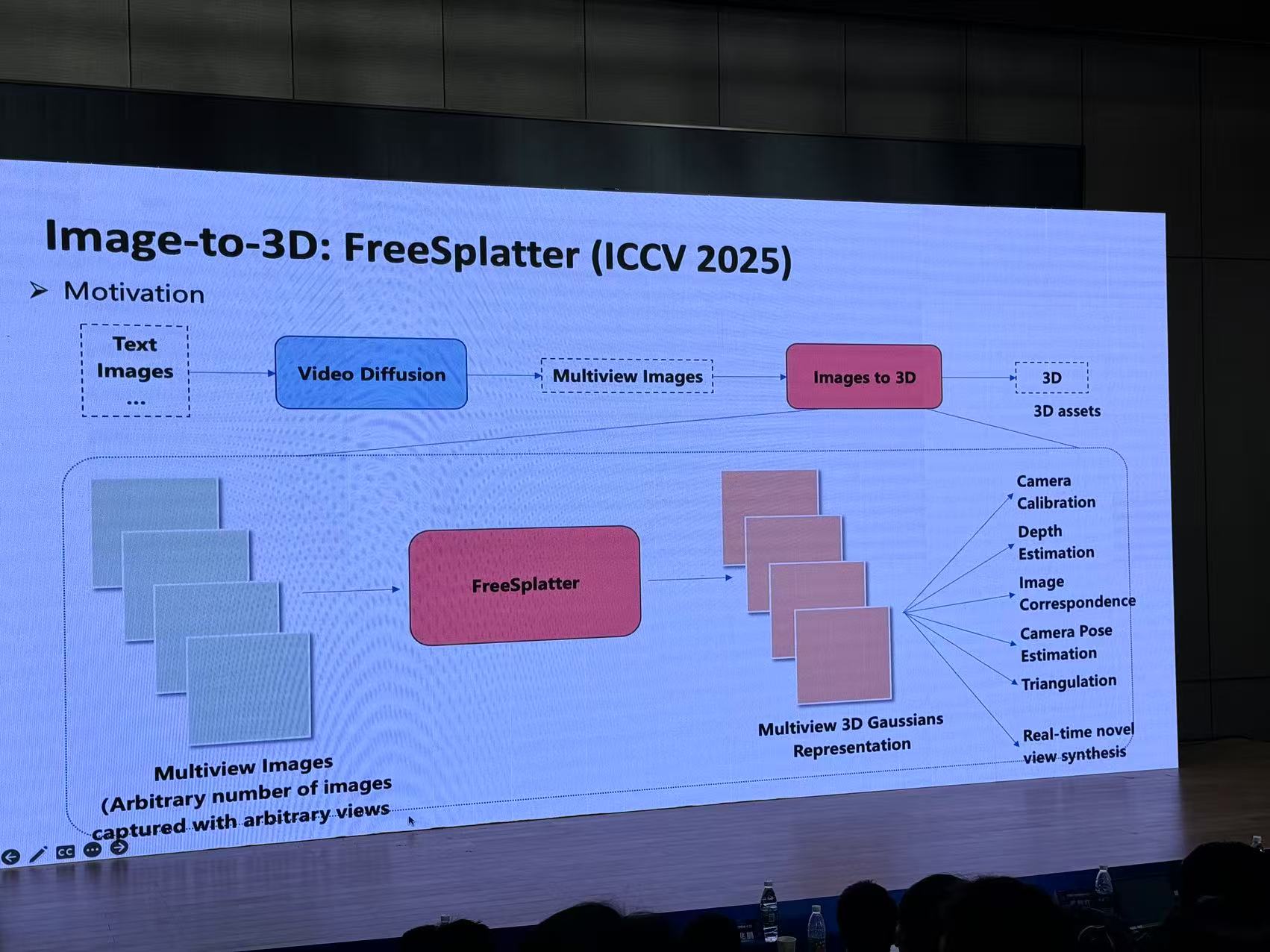
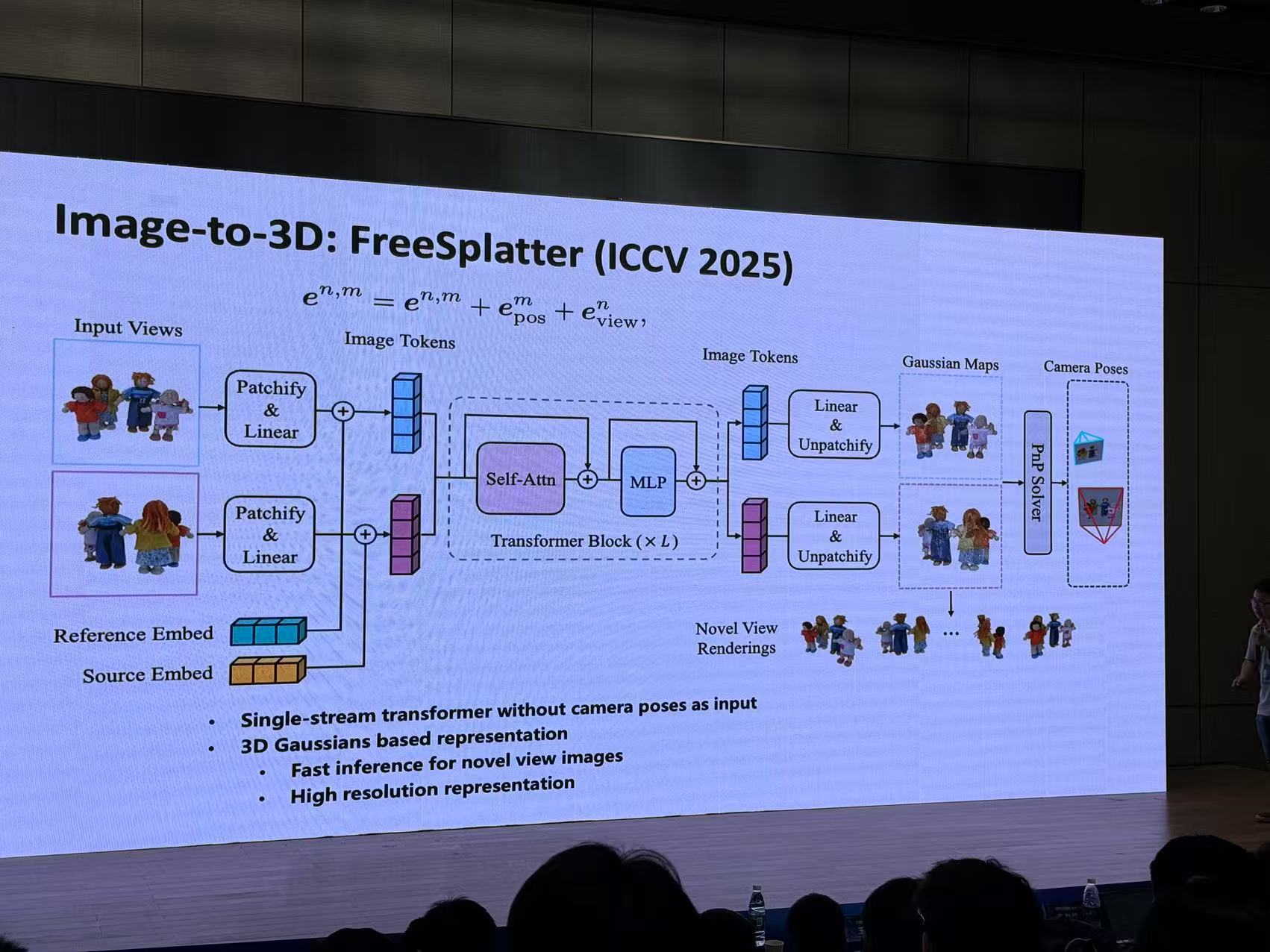



八、建筑物自动建模:从判别式到生成式
待更新
#pic_center =50%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)