OpenAudio S1 - 媲美专业配音演员的AI语音生成软件 支持50系显卡 语音克隆、文本转语音 本地一键整合包下载
OpenAudio S1 是Fish Audio 近日正式推出其的最新一代语音生成模型,以其高度自然的声音、丰富的语气控制和强大的指令跟随能力,号称达到专业配音演员的表现力和自然度。多语言支持: 得益于200万小时的音频训练数据,OpenAudio S1在语音生成的质量和多样性上取得了显著突破,覆盖英语、中文、日语、韩语、法语、德语、阿拉伯语、西班牙语等13种语言,展现了强大的多语言能力。强大的指
 OpenAudio S1 是Fish Audio 近日正式推出其的最新一代语音生成模型,以其高度自然的声音、丰富的语气控制和强大的指令跟随能力,号称达到专业配音演员的表现力和自然度。这一模型在TTS-Arena排行榜中荣登第一,成为文本转语音(TTS)领域的新标杆。
OpenAudio S1 是Fish Audio 近日正式推出其的最新一代语音生成模型,以其高度自然的声音、丰富的语气控制和强大的指令跟随能力,号称达到专业配音演员的表现力和自然度。这一模型在TTS-Arena排行榜中荣登第一,成为文本转语音(TTS)领域的新标杆。
今天分享的OpenAudio S1基于官方开源的 OpenAudio S1 mini模型,拥有0.5B的参数量,满足大部分消费级显卡使用。更好的商业版模型效果可以到官网体验:https://fish.audio/zh-CN/
核心特点
高度自然的声音: 生成的声音流畅、逼真,几乎与人类配音无异,适用于专业场景如视频配音、播客和游戏角色语音。
丰富的语气控制: 支持超过50种情绪和语气标记,如(愤怒)、(高兴)、(悲伤)、(低语)、(同情)等,用户可通过自然语言指令灵活调整语音表达。
强大的指令跟随能力: 通过简单的文本指令,用户可以控制语音的语速、音量、停顿甚至笑声等细节,打造高度个性化的语音输出。
多语言支持: 得益于200万小时的音频训练数据,OpenAudio S1在语音生成的质量和多样性上取得了显著突破,覆盖英语、中文、日语、韩语、法语、德语、阿拉伯语、西班牙语等13种语言,展现了强大的多语言能力。
应用领域
多媒体内容创作 适用于视频配音、有声读物、播客等,提供高质量且情感丰富的语音输出
游戏与虚拟交互 为游戏角色生成逼真语音,或用于虚拟助手、虚拟人等交互场景
教育与客户服务 在多语言教育工具或智能客服系统中,提供自然且富有情感的语音支持
轻量化部署 S1-mini版本适合本地设备或资源有限的应用,如移动端语音生成
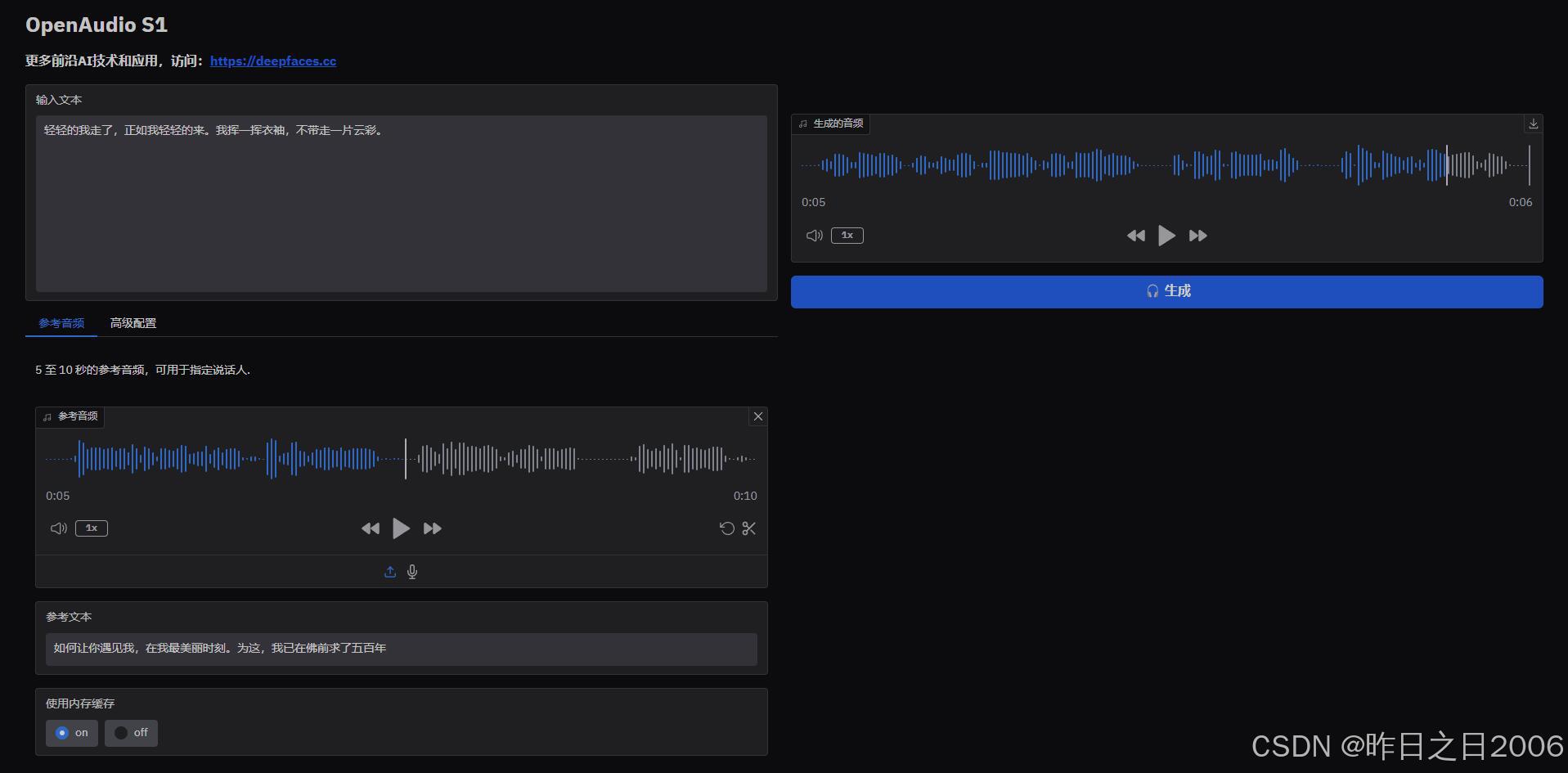
使用教程:( 建议N卡,显存6G起。支持50系显卡,基于CUDA12.8 )
1、直接输入需要转换的文本,点生成,可以随机生成一种音色合成
2、上传参考音频、输入参考文本,输入合成文本,点生成,即可生成克隆音色音频

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)