DeepSeek V3.1 突现神秘“极”字Bug!代码乱入“极速赛车”,AI模型竟学会“偷懒”了?
在DeepSeek的分词表中,“极”字的Token ID是2577,而它的“邻居”恰好是省略号“……因为最近也遇到了这个问题,不是在DeepSeek上遇到的,是在qwen3 235b 遇到的。我用它来写小说网游类型的,然后有一章出现了对敌人的评级S+,让后第二章S++,第三者S+++,第二十章S+++++++++++++++++++。即使是人工造数据,也是直接造文本,谁会基于token id那边绕
很多人以为大模型是程序员往逻辑里写if else吗[,还从0计数,从1计数。即使是人工造数据,也是直接造文本,谁会基于token id那边绕一圈去造数据,数据是给人看的,不是给除去embedding的大模型看的

我知道每个渠道部署有很多方式,可以直接套壳api,也可以按ds的权重重训甚至posttrain,只不过大部分基础的套壳根本不会花心思这么做,只是简单调api而已
比如有人在用DeepSeek整理物理试卷的时候,就发现它会在回复中出现“极”这个字。

而有的网友在Trae国内版中调用V3.1模型,也会出现同样的“极”这个字

那么为什么新版本的DeepSeek会出现这个明显的Bug呢?我总结了目前网友的一些猜测
Token词表中的连续性问题
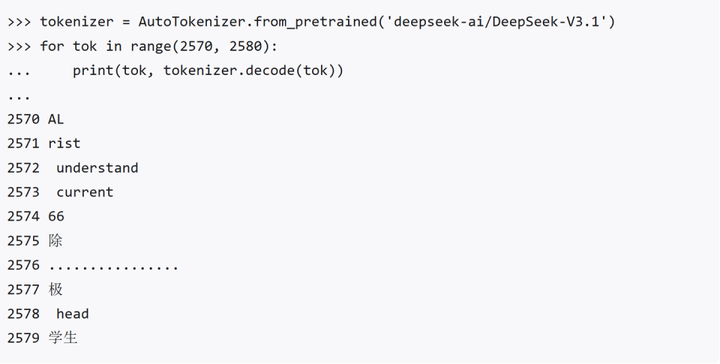
有网友打印出了DeepSeek V3.1版本的分词表,发现“极”这个词的token id为2577,而下一个token id 2578为“......”
正好昨天用豆包,让他编程做数据分析,扔给他一个几万行的csv,眼看着他花了十分钟把几万个数据填到一个数组里面data={1015,,1121,1254,2241,2212,1110,1102...........}
没太理解tokenizer的embeding可视化怎么能排除token错位的,训练过程中tokenizer又不更新啊
tsne跨cluster的距离不好直接比较,可以考虑用一些保留全局结构的降维方法,比如umap
因为最近也遇到了这个问题,不是在DeepSeek上遇到的,是在qwen3 235b 遇到的。我用它来写小说网游类型的,然后有一章出现了对敌人的评级S+,让后第二章S++,第三者S+++,第二十章S+++++++++++++++++++ 。搞得我每次生成章节后又要ai检查一下章节的质量,对质量差的重新生成。
极和省略号、eos位置很远,在这套向量空间位置当中并不是表示同义和近义。反而就是因为训练数据污染导致模型有缺陷了。
极和极速这两个好像在很多网站有奇怪水印,3g甚至2g时代手机上网很多网页会带这个标榜省流量,这不会是赛博牛皮癣把ai传染了
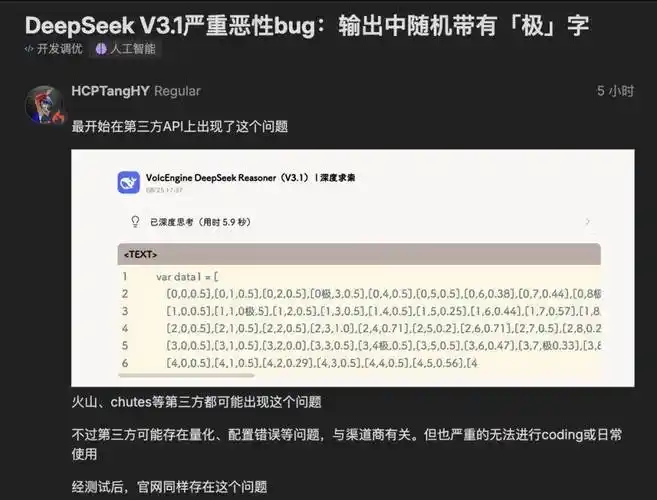
比如,某位网友让V3.1整理物理试卷,结果输出中莫名混入“极”字;另一位在代码生成中遭遇了“time.Se极”这样的诡异片段(原应为“time.Second”),直接让程序崩溃。更离谱的是,甚至有人收到了“极速赛车开奖直播”这种完全跑偏的内容。网友纷纷吐槽:“这模型是不是被「极」客文化洗脑了?”
要理解这个Bug,得先从AI的“语言密码”——Token系统说起。在DeepSeek的分词表中,“极”字的Token ID是2577,而它的“邻居”恰好是省略号“……”(ID 2576)。这种相邻关系可能让模型在输出时“手滑”,误将省略号替换为“极”。就像你打字时想按句号却不小心戳到隔壁键,只不过AI的“手滑”背后是概率分布漂移和训练数据污染的复杂问题。
如果用于RAG系统,知识库内文档包含广告/乱码会导致模型引用后输出无关内容或以多种混合语言回答(因为乱码可能恰好包含了其他语言的字符)。
前两天刚遇到回答完突然蹦出一个广告,这应该是训练数据用了网页内容,无关内容没删除干净,把广告也喂给AI了吧,那个广告都过去半年多了
问就是数据问题!"R1乱码推理、小说AI给敌人评级,豆包处理CSV直接生成"数据长城"。这题超纲了!从零开始?C语言编译器都笑了,AI的"思考"总在出人意料的地方开挂,离AGI还差个银河系。
反正是是觉得我还是觉得V3 0324是我的白月光,R1 0528和最近的V3.1感觉都不太行

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)