我是如何玩转Claude100 万 Token上下文的?(附代码实战)
Claude 的 100 万 token 上下文窗口为开发者带来了新的工作流可能性。如果你需要全局代码分析,或想打造更智能的开发工作流,这次升级可以说是重要的基础。
进入8月后,Anthropic 推出了一个相当让开发者兴奋的更新!
那就是:Claude Sonnet 4 现在支持 100 万 token 的上下文窗口 —— 这相当于在一次对话中处理 75 万个单词,或 7.5 万行代码。(1个token相当于0.75个单词,1行代码大概10个单词长度。)
对一些开发者来说,这个概念可能有点抽象。我们可以这样理解:
一次性丢给Claude:一整本小说(大约 18 万 tokens)、一份配套的深入分析、研究资料,以及复杂的指令,完全不在话下,甚至还有很多的 token 空间等你开发。
这对于复杂、大规模的项目来说非常实用。
那究竟该怎么用这个新功能更新呢?小编帮各位整理了几种用法,希望能帮助到大家。
1.升级前后对比
- 之前的上限:200,000 tokens
- 现在的上限:1,000,000 tokens(提升 5 倍)
- 与竞品对比:比 OpenAI GPT-5(40 万 tokens)多 2.5 倍
- 实际能力:能处理完整代码库、全套文档,或多个相关文件
Google 的 Gemini 和 OpenAI 都有 100 万 token 的模型,所以看到 Anthropic 追上来是好事。但 Claude 的实现特别强调“有效上下文窗口”,也就是保证它能真正理解并利用你提供的大量信息。
2.Claude 的 100 万 Token 意味着什么?
和一些竞品在长上下文里出现注意力衰减不同,早期反馈显示 Claude 在扩展后的上下文范围内依然保持了稳定表现。
几个关键点:
- 完整项目理解你可以上传整个项目,Claude 会基于整体架构、代码风格和依赖关系,提供更契合的建议。
- 长周期自主任务Claude 能够处理复杂的多步骤开发任务,保持上下文记忆,不会忘记之前的决策。
- 更好的代码生成当你让 Claude 开发新功能时,它能看见整个应用结构,生成更合理、更集成的方案。
- 全面代码审查上传整个代码库进行分析、重构建议或安全审计。
3.入门:在应用中接入 Claude API
如果你准备好利用这个扩展上下文窗口,可以按照以下步骤操作。
前提条件
- 一个 Anthropic API key(在console.anthropic.com 获取)
- Node.js 16+ 或 Python 3.7+
- 基础 REST API 使用经验
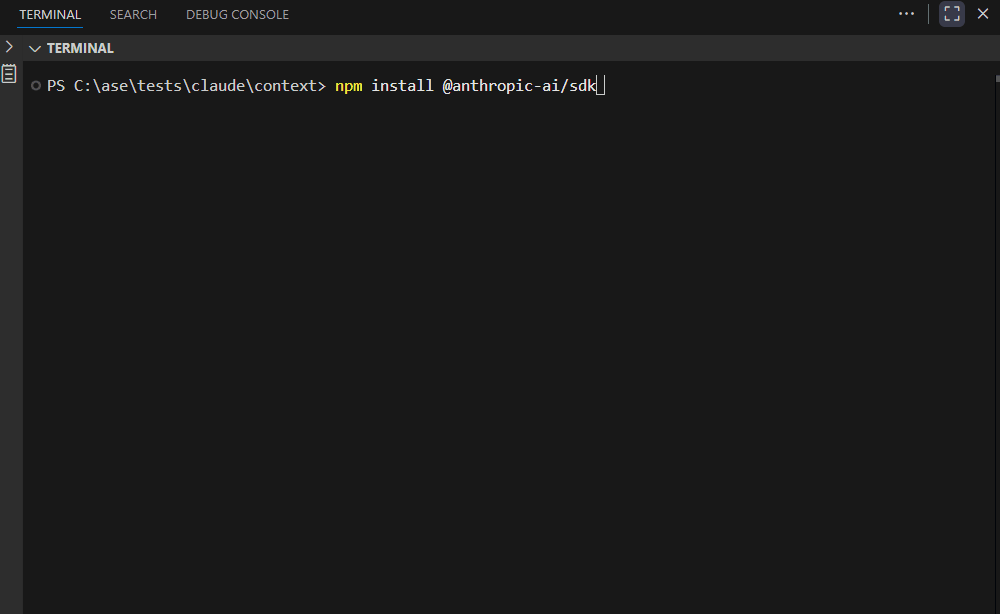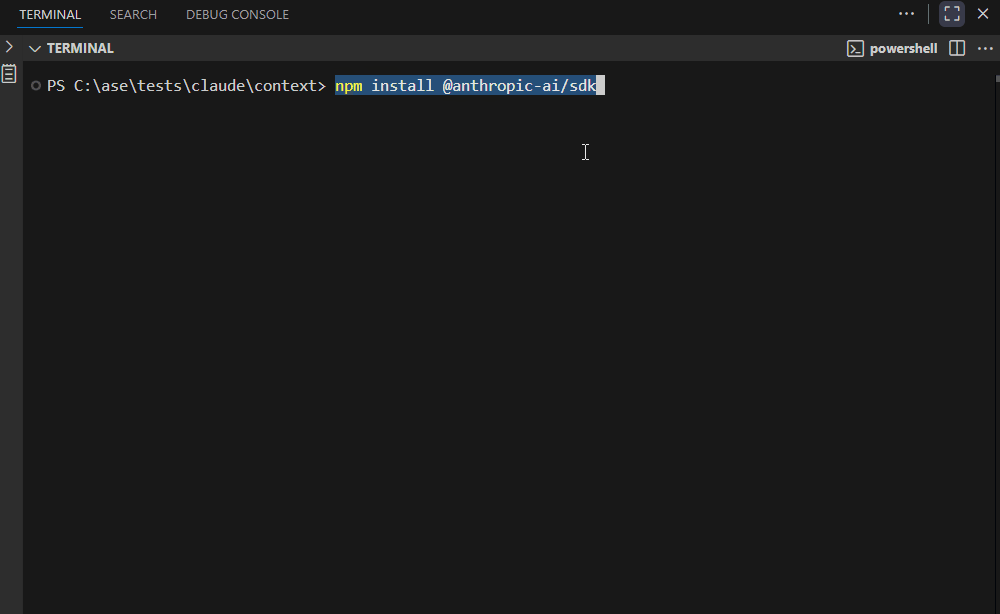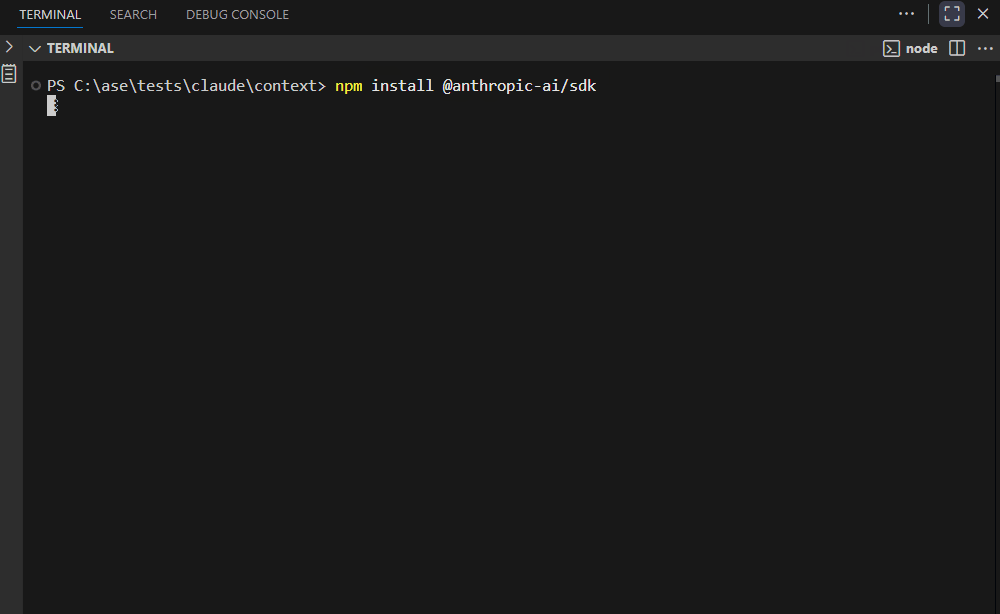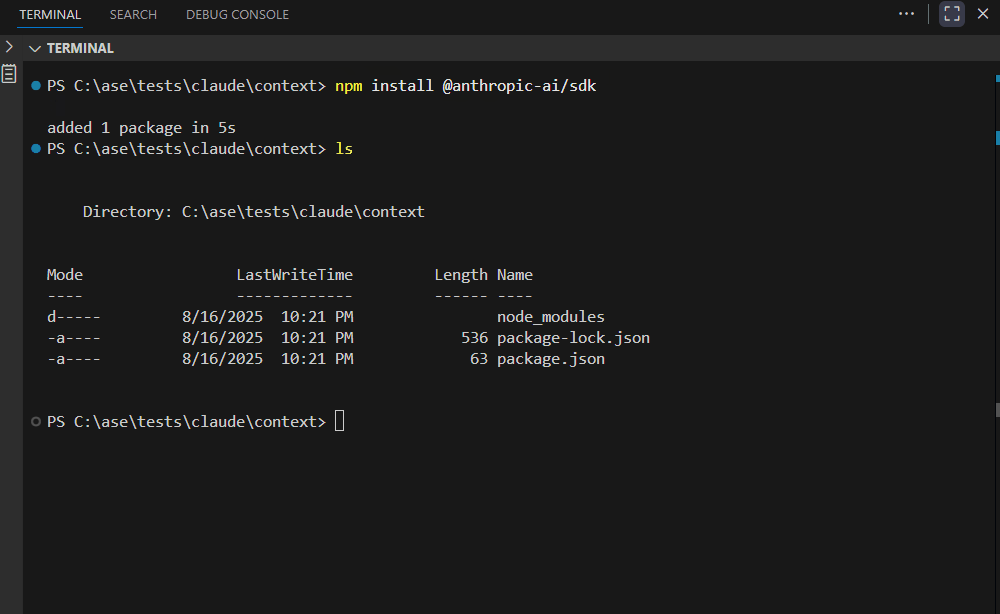
步骤 1:安装依赖
Node.js:
npm install @anthropic-ai/sdkPython:
pip install anthropic步骤 2:基础配置
Node.js 示例:
import Anthropic from '@anthropic-ai/sdk';
const anthropic = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
});Python 示例:
import anthropic
client = anthropic.Anthropic(
api_key="your-api-key-here"
)步骤 3:利用扩展上下文
Node.js 大型代码库分析:
async function analyzeCodebase(files) {
// Combine multiple files into a single prompt
const combinedContent = files.map(file =>
`// File: ${file.path}\n${file.content}\n\n`
).join('');
const message = await anthropic.messages.create({
model: "claude-sonnet-4-20250514",
max_tokens: 4000,
messages: [{
role: "user",
content: `Please analyze this entire codebase and provide:
1. Architecture overview
2. Potential improvements
3. Security considerations
4. Performance optimization opportunitiesHere's the codebase:
${combinedContent}`
}]
});
return message.content[0].text;
}Python 长文档处理:
def process_large_documentation(doc_content):
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4000,
messages=[{
"role": "user",
"content": f"""
Please create a comprehensive technical summary and implementation guide
based on this extensive documentation:{doc_content}
Focus on:
- Key implementation steps
- Code examples
- Best practices
- Common pitfalls to avoid
"""
}]
)
return message.content[0].text步骤 4:处理文件上传
Web 应用可用 Express.js + Multer 处理多文件上传,并交给 Claude 分析。
示例代码:
const multer = require('multer');
const fs = require('fs').promises;const upload = multer({ dest: 'uploads/' });
app.post('/analyze-project', upload.array('files'), async (req, res) => {
try {
const files = [];
for (const file of req.files) {
const content = await fs.readFile(file.path, 'utf-8');
files.push({
path: file.originalname,
content: content
});
}
const analysis = await analyzeCodebase(files);
res.json({ analysis });
} catch (error) {
res.status(500).json({ error: error.message });
}
});步骤 5:管理成本
扩展上下文意味着价格调整:
- 输入超 20 万 tokens:每百万输入 $6 / 输出 $22.5
- 输入少于 20 万 tokens:每百万输入 $3 / 输出 $15
还可用简单的 Token 估算函数来预估成本。这里有个使用示例。
function estimateTokenCount(text) {
// Rough estimation: 1 token ≈ 4 characters for English text
// For code, it's often closer to 1 token ≈ 3 characters
return Math.ceil(text.length / 3.5);
}function estimateCost(inputTokens, outputTokens) {
const inputCost = inputTokens > 200000
? (inputTokens / 1000000) * 6
: (inputTokens / 1000000) * 3;
const outputCost = outputTokens > 200000
? (outputTokens / 1000000) * 22.50
: (outputTokens / 1000000) * 15;
return inputCost + outputCost;
}
4.高级用例
- 多文件重构
按需求整体重构项目。
async function refactorProject(files, requirements) {
const prompt = `
Refactor this entire project according to these requirements:
${requirements}Current codebase:
${files.map(f => `// ${f.path}\n${f.content}`).join('\n\n')}
Please provide the refactored files with explanations.
`;
// Process with Claude...
}- 测试套件生成自动生成完整单测、集成测试和边界测试。
def generate_test_suite(codebase_files):
combined_code = "\n\n".join([
f"# File: {file['path']}\n{file['content']}"
for file in codebase_files
])
prompt = f"""
Generate a comprehensive test suite for this entire codebase.
Include unit tests, integration tests, and edge cases.Codebase:
{combined_code}
"""
# Send to Claude API...- 自动化文档生成一次性生成完整的、一致的项目文档。
5.最佳实践
- 结构化提示:即使是 100 万 tokens,也要逻辑清晰。
- 使用分隔符:帮助 Claude 分辨不同部分。
- 明确指令:上下文越大,越要清楚告诉 Claude 你要什么。
- 监控成本:尤其在生产环境下。
- 缓存:针对重复分析的内容考虑缓存策略。
6.竞品对比
这次升级让 Anthropic 在上下文长度上超越了 GPT-5,也让 Claude 成为大规模复杂项目的理想选择。
虽然 Google Gemini 提供 200 万 tokens,Meta Llama 4 Scout 宣称 1000 万 tokens,但 Anthropic 的“有效上下文窗口”更强调 Claude 对内容的真实理解力。
7.写在最后
Claude 的 100 万 token 上下文窗口为开发者带来了新的工作流可能性。如果你需要全局代码分析,或想打造更智能的开发工作流,这次升级可以说是重要的基础。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献98条内容
已为社区贡献98条内容

所有评论(0)