51c大模型~合集173
当 AI 不再局限于逐帧生成,而是具备了从整体出发的规划能力 —— 理解情节的推进、协调画面的连贯性、控制运动的节奏,长视频生成便迈出了从 “ 片段拼接” 走向 “统—表达” 的关键—步。借助其近实时的生成能力,创作者可以在快速反馈中不断调整与完善自己的构想,让创意更自由地流动。即便谷x歌x曾宣称其现在大约一半的代码都是 AI 编写的,但这一说法也备受质疑,一些开发者还曾表示谷x歌x可能把自动代码
我自己的原文哦~ https://blog.51cto.com/whaosoft/14135124
#这就是大厂的AI「氛围编程」
老工程师现身说法后,大家绷不住了
氛围编程(vibe coding),这个由 Andrej Karpathy 带火的热词,已经成为了一种相当流行的编程方式。但这种编程方式的流行程度究竟如何,目前还没有什么比较可靠的统计数据。不过,近日的一篇 Reddit 热帖,却可以让我们窥见一些端倪:看起来,氛围编程可能比我们预想的更受欢迎,FAANG 等大型科技公司也不乏 vibe coder—— 虽然人们对这个工作流程算不算是氛围编程存在很大争议。

这篇帖子发布在 r/vibecoding,发帖者 u/TreeTopologyTroubado 自称是一位拥有十多年工作经验的 AI 软件工程师,并且其有一半的时间都是在 FAANG(即 Meta、亚马逊、苹果、Netflix 和 Alphabet 五大科技巨头)工作。他职业生涯前半段是系统工程师,而不是开发者,不过他现在已有 15 年左右的编程经验了。
然后,他分享了使用 AI 开发产品代码的方法。简单来说,就是始终从可靠的设计文档和架构开始,然后在此基础上逐步构建。始终先编写测试。
更具体而言:
你仍然需要从技术设计文档开始。这是工作的主体。一开始,设计文档是一份提案文档。如果你能让足够多的利益相关者认同你的提案有价值,你就可以开始开发系统设计本身。这包括完整的架构、与其他团队的集成等等。
在开始开发工作之前进行设计评审。这指的是让高级工程师彻底揉碎评估团队的设计文档。这是个很好的做法。我认为这可以减轻开发过程中的痛苦。
如果通过审核,就可以开始开发工作了。最初的几周,我们会针对各个开发团队即将构建的各个子系统编写更多文档。
待办事项开发和冲刺规划。开发人员需要与项目经理和技术项目经理协作,确定各个开发人员需要处理的独立任务及其执行顺序。
软件开发。终于,我们可以拿起键盘,开始处理任务单了。这正是 AI 展现强大实力的地方。我们使用的方法是测试驱动开发(Test Driven Development),也就是让 AI 编程智能体先为要构建的功能编写测试。之后,我才会开始使用这个智能体来构建这个功能。
代码提交审核。在将代码合并到人工代码之前,我们会有两个开发人员进行审批。AI 在协助审核方面也展现出巨大的潜力。
在预发布版本中进行测试。如果预发布版本一切正常,我们就会将其推送到生产版本。
该帖在 Reddit 和 X 上都引起了广泛讨论。其中一个很大的讨论点是,FAANG 等大型科技公司竟然允许员工氛围编程!
即便谷歌曾宣称其现在大约一半的代码都是 AI 编写的,但这一说法也备受质疑,一些开发者还曾表示谷歌可能把自动代码补全的部分也算成 AI 生成的代码了,也有不少人质疑谷歌究竟在生产环境中部署了多少这些 AI 生成的代码。

不过,也有人认为,根据该帖子的描述,这个流程其实不能称之为「氛围编程」,因为其中依然有大量必须人类参与的环节 —— 这或许是该帖子最引人争议的地方。





Hyperbolic 联创 & CEO Yuchen Jin 也认为这样的工作流程对人类工作者来说很痛苦,不够 vibe。

同时,这也表明,即便有 AI 加持,大型科技公司繁琐的流程还是会拖延研发速度 —— 这似乎对独立创始人来说是好事。


尽管如此,也有不少开发者从中看到了可取之处。
比如开发者 Frank Lin 认为这可以成为使用 AI 的最佳实践,即详细的技术规格,在编程之前先审查解决方案,并首先编写测试代码。

而其中,编程是最轻松和乏味的阶段,工程师的价值则是体现在「设计、头脑风暴、编写规范、测试等」方面,也就是要弄清楚需要编写什么代码。

也有人分享了自己的经验。



对此,你怎么看?或者有什么经验与我们分享吗?
参考链接:
https://www.reddit.com/r/vibecoding/comments/1myakhd/how_we_vibe_code_at_a_faang/
https://x.com/Yuchenj_UW/status/1959661025319608603
https://x.com/rohanpaul_ai/status/1959414096589422619
.....
#田渊栋2025年终总结
救火Llama4但被裁,现任神秘初创公司联创
去年 10 月,Meta 人工智能部门的裁员波及到了一大波人,其中包括了知名华人科学家田渊栋及其团队成员。

就在这两天,田渊栋分享了自己的 2025 年终总结。


他首先透露了自己「救火」Llama 4 项目的经历以及之后被裁、未来的工作规划;接着回顾了 2025 年的主要研究方向,包括大模型推理和打开模型的黑箱;最后探讨了 AI 驱动下的社会变革、生产力重构以及个人价值的存续逻辑。
接下来为田渊栋知乎原文内容。
2025年终总结(一)
关于被裁
在 2025 年 1 月底被要求加入 Llama4 救火的时候,作为一直以来做强化学习的人,我事先画了一个 2x2 的回报矩阵(reward matrix),计算了一下以下四种可能(虽然在那时,因为来自上面的巨大压力,不同意是几乎不可能的):

当时想的是我们去帮忙的话,即便最后项目未能成功,也至少尽力而为,问心无愧。不过遗憾的是,最后发生的是没在计算之内的第五种可能,这也让我对这社会的复杂性有了更为深刻的认识。
尽管如此,在这几个月的努力过程中,我们还是在强化学习训练的核心问题上有一些探索,比如说训练稳定性,训推互动,模型架构设计,和预训练 / 中期训练的互动,长思维链的算法,数据生成的方式,后训练框架的设计等等。这个经验本身是很重要的,对我的研究思路也带来了不小的转变。
另外其实我也想过在公司十年多了,总有一天要离开,总不见得老死在公司里吧,但总是因为各种经济上和家庭上的原因还是要待下去。最近一两年的说话和做事方式,都是抱着一种 “公司快把我开了吧” 的心态,反而越来越放开。2023 年年末我休第一个长假的时候,其实几乎差点要走了,但最后没签字还是选择待在公司继续,所以说真要做出离开的决定也不容易。现在 Meta 帮我做了也挺好。
这次波折和今年一年的起起落落,也为接下来的小说创作提供了非常多的新素材。所谓 “仕途不幸诗家幸,赋到沧桑句便工”,生活太平淡,人生就不一定有乐趣了。还记得 2021 年年头上的时候,因为在年末工作总结里面写了几句关于” 为啥 paper 都没中 “的反思,喜提 Meet Most,有一种突然不及格的懵逼感。但想了想与其到处抱怨世道不公,不如就在大家面前装成自己刚刚升职吧,结果半年后果然升了职,而那篇 21 年头上无人问津的工作,在 21 年 7 月份中了 ICML Best paper honorable mention,成为一篇表征学习中还比较有名的文章。
10 月 22 号之后的一段时间,基本上我的各种通信方式都处于挤爆的状态,每天无数的消息和邮件,还有各种远程会议或者见面的邀请,实在是忙不过来了。一直到几周之后才渐渐恢复正常。这两个月非常感谢大家的关心和热情。如果那时有什么消息我没有及时回复,请见谅。
虽然最后有不少 offer,大家能想到的知名公司也都联系过我,但最后还是决定乘自己还年轻,去当一家新初创公司的联合创始人,细节暂时不公开,先安静地忙活一阵吧。根据 Linkedin 信息显示,他已经于去年 12 月在这家公司上任。

一些研究的方向
2025 年的主要方向,一个是大模型推理,另一个是打开模型的黑箱。
自从 2024 年末我们的连续隐空间推理(coconut,COLM’25)工作公开之后,25 年在这个研究方向上掀起了一股热潮。大家探索如何在强化学习和预训练中使用这个想法,如何提高它的训练和计算的效率,等等。虽然我们组随后就被拉去 llama 干活,没能再继续花很大力气往下挖,但这个让我觉得非常欣慰。尽管如此,我们还是在上半年发了一篇理论分析(Reasoning by Superposition,NeurIPS‘25)的文章,展示连续隐空间推理有优势的地方究竟在哪里,获得了不少关注。
另外是如何提高大模型的推理效率。我们的 Token Assorted(ICLR’25)的工作,先通过 VQVAE 学出隐空间的离散 token,再将所得的离散 token 和 text token 混在一起进行后训练,减少了推理代价的同时提高了性能。我们的 DeepConf 通过检测每个生成 token 的自信程度,来决定某条推理路径是否要被提前终止,这样推理所用的 token 减少了很多,但在 majority vote 的场景下性能反而更好。ThreadWeaver 则是通过制造并行推理的思维链,并在其上做后训练,来加快推理速度。另外我们也在 dLLM 上用 RL 训练推理模型(Sandwiched Policy Gradient),也有在小模型上学习推理的尝试(MobileLLM-R1)。
在可解释性方面,Grokking(顿悟)这个方向我大概两年前就在关注了。因为之前我做表征学习(representation learning)的分析,虽然能分析出学习的动力学过程,看到模型出现表征塌缩的原因,但究竟学出什么样的表征,它们和输入数据的结构有什么关系,能达到什么样的泛化能力,还是个谜团,而通过分析 Grokking 这个特征涌现的现象,从记忆到泛化的突变过程,正好能解开这个谜团。一开始确实非常难做没有头绪,2024 年先做了一篇 COGS(NeurIPS‘25,见求道之人,不问寒暑(十)),但只能在特例上进行分析,我不是很满意。在一年多的迷茫之后,在和 GPT5 大量互动之后,最近的这篇 Provable Scaling Laws 的文章应该说有比较大的突破,能分析出之前的线性结构(NTK)看不到的东西,并把特征涌现的训练动力学大概讲清楚了。虽然说分析的样例还是比较特殊,但至少打开了一扇新的窗口。详细解释请看田渊栋的想法。
年末的这篇 The path not taken 我很喜欢,对于 RL 和 SFT 的行为为何会如此不一致,在权重的层面给出了一个初步的答案。SFT 造成过拟合和灾难性遗忘(catastrophic forgetting),其表层原因是训练数据不够 on-policy,而深层原因是权重的主分量直接被外来数据大幅修改,导致 “根基” 不稳,模型效果大降。而 RL 则因为用 on-policy 的数据进行训练,权重的主分量不变,改变的只是次要分量,反而能避免灾难性遗忘的问题,而改变的权重其分布也会较为稀疏(特别在 bf16 的量化下)。
关于可解释性的信念
很多人觉得可解释性,或者 “AI 如何工作得那么好” 这个问题不重要,但我却觉得很重要。试想之后的两种场景:
- 场景一:如果我们仅仅通过 Scaling 就达到了 AGI 乃至 ASI,全体人类的劳动价值都降为零,AI 作为一个巨大的黑盒子帮我们解决了所有问题,那如何让 AI 作为一个超级智能,一直行善,不欺骗不以隐秘的方式作恶,就是当务之急,要解决这个问题就要做可解释性。
- 场景二:如果 Scaling 这条路最终失效,人类在指数增长的资源需求面前败下阵来,必须得要寻求其它的方案,那我们就不得不去思考 “模型为什么有效,什么东西会让它失效”,在这样的思考链条之下,我们就必须回归研究,可解释性就是目所能及的另一条路了。
在这两种情况下,最终都需要可解释性来救场。就算最终 AI 是个全知全能全善的神,以人类好奇和探索的天性,必然还是会去研究 AI 为什么能做得好。毕竟 “黑盒” 就意味着猜疑链的诞生,在大模型技术爆炸,开始达到甚至超过人类平均水平的今天,《三体》中 “黑暗森林” 的规则,也许会以另一种方式呈现出来。
目前打开训练好模型的黑箱,去找到电路(circuit),还是处于比较初步的阶段。可解释性真正的难点,在于从第一性原理,即从模型架构、梯度下降及数据本身的固有结构出发,解释为什么模型会收敛出这些解耦、稀疏、低秩、模块化、可组合的特征与回路,为什么会有大量不同的解释,这些涌现出来的结构和模型训练的哪些超参数相关,如何相关,等等。等到我们能从梯度下降的方程里,直接推导出大模型特征涌现的必然性,可解释性才算真正从生物式的证据收集走向物理式的原理推导,最终反过来指导实践,为下一代人工智能的模型设计开辟道路。对比四百年前的物理学,我们现在有很多 AI 版的第谷(收集数据),一些 AI 版的开普勒(提出假说),但还没有 AI 版的牛顿(发现原理)。
等到那一天来临的时候,我相信,世界一定会天翻地覆。
2025年终总结(二)
未来会是什么样子
抛开前公司里每三个月一次的组织架构重组不谈,2025 年一年的变化本身已经很大。25 年年初的 Deepseek-R1 的发布,现在想来几乎已经算是上个世纪的事情了。带思维链的推理模型的巨大成功,让强化学习(RL)又回到了 AI 的主流视野之中,也带动了 AI4Coding 及 AI Agent 的发展,而后两者让大模型有了大规模落地,大幅度提高生产力的切实可能。
以前做项目,招人是很重要的一环,但现在脑中的第一个问题是 “还需不需要人?” 几个 Codex 进程一开,给它们下各种指令,它们就可以 24 小时不间断干活,速度远超任何人类,而且随便 PUA 永远听话毫无怨言。和 AI 工作,我最担心的是工作量有没有给够,有没有用完每天的剩余 token 数目。这也是为什么各家都在试验让 AI Agent 做几个小时连续不断的工作,看 AI 的能力上界在哪里。因为人的注意力永远是最昂贵的,人要休息,要度假,要允许有走神、睡觉和做其它事情的时间。减少人的介入,让 AI 自己找到答案,干几个小时活之后再回来看看最好。
这每个月交给 OpenAI 的 20 块钱,一定要榨干它的价值啊。
我突然意识到,就因为这区区 20 块钱,我已经成为了 “每个毛孔里都滴着血” 的肮脏资本家。我能这么想,全世界最聪明和最富有的头脑,也一定会这么想。
所以请大家丢掉幻想,准备战斗吧。
在帮忙赶工 Llama4 期间,我经常在加州时区晚上 12 点接到东部时区的组员消息,在伦敦的朋友们更是永不下线,熬夜折腾到凌晨四五点是寻常事,但大模型越来越强,辛勤劳动最终达到的结果,是看到大模型达到甚至超越我们日常作事的水准。
这应该说是一种陷入囚徒困境之后的无奈。
人类社会的 “费米能级”
如果以后以 AI 为中心,那还需要人么?
如果考虑劳动力的投入 - 回报模型,传统思维会告诉你,工作经验积累越多,人的能力越强,回报也越大,是个单调上升的曲线。这就是为什么大厂有职级,职级随年限晋升,越老越香。但现在的情况已经不同了。职级已经没有意义,过去的经验也没有意义,人的价值从按照 “本人产出的劳动数量及质量” 来评估,变成了是否能提高 AI 的能力,人加 AI 要大于 AI 本身的产出,这样才行。

这样就让投入 - 回报曲线从一个单调递增曲线变成了一个先是全零,再在一定阈值之后增长的曲线(也即是 soft-thresholding 的曲线)。一开始人的能力是比不过 AI 的,而 AI 的供给只会越来越便宜,所以在很长一段成长期内,人本身是没有价值的。只有在人的能力强到一定程度之后,能够做到辅助 AI 变强,才开始变得有价值起来。

并且,在跨越阈值之后,厉害人对 AI 的加成,会高于普通人很多很多,因为普通人只会对 AI 的一两条具体产出花时间修修补补,而厉害的人在看了一些 AI 存在的问题之后,能提出较为系统性和普遍性的解决方案,结合手上的各类资源(GPU 和数据等),可以进一步让 AI 变得更强,而这种效应随着 AI 的广泛部署,会被几何级数地放大。“一骑当千” 这种小说笔法,将很快变成现实。
在这样一个非常两级分化的投入 - 回报模型之下,如果把人 + 所有个人能获取的 AI 当成一个智能体,整体来看,它的能力分布会和电子能级在材料里的分布很像:低于或达到某个水准线的智能体遍地都是,求着客户给它活干,以证明自己还是有用的;而高于这个水准线的智能体则指数级地变少,获取和使用它非常花钱,还常常排不到。

这个水准线,就是 AI 洪水的高度,就是人类社会的 “费米能级”。低于费米能级的职业,可能在一夜之间就被颠覆掉,就像一场洪水或者地震一样,前一天还是岁月静好,后一天整个行业被端掉了。
随着时间变化,这条水准线还会一直往上走。其进展的速度,和它能获取到的,比它更强的数据量成正比。如果大模型的训练过程没有特别大的进展,那和自动驾驶无人车一样,越往上走,有用的数据是越来越少的,进展也会越慢,最顶尖的那部分人,还能在很长时间内保有自己的护城河。如果训练过程有突破,比如说找到新的合成数据手段,乃至新的训练算法,那就不好说了。
当然以上的判断是假设有无限的 GPU 和能源的供给,并没有考虑到各种资源短缺的情况。能源短缺,芯片产能短缺,内存短缺,整个地球能否满足人类日益疯狂增长的 AI 需求还是个未知数,这方面深究下去,或许可以做一篇论文出来。
遍地神灯时代的独立和主动思考
那么,接下来会怎么样呢?
未来的世界,或许不再是传统故事里描绘的那样 —— 人们为了争夺稀缺的武功秘籍,或是千辛万苦寻找唯一的阿拉丁神灯、集齐七颗龙珠而展开冒险。相反,这将是一个 “遍地神灯” 的时代。每一个 AI 智能体都像是一个神灯,它们能力超群,渴望着实现别人的愿望,以此来证明自己的价值。
在这种环境下,真正稀缺的不再是实现愿望的能力,而是 “愿望” 本身,以及将愿望化为现实的那份坚持。
然而,在这个 AI 能力极其充沛的时代,巨大的便利往往伴随着巨大的陷阱。大模型提供了极其廉价的思考结果,在当前信息交互尚不充分的市场中,这些结果甚至可以直接用来交差并获取经济价值(例如那些一眼就能看出的 “AI 味” 文案)。这种唾手可得的便利,会让许多人逐渐失去思考的动力,久而久之丧失原创能力,思想被生成式内容和推荐系统所绑架和同化。这就是新时代对 “懒人” 的定义:不再是因为体力上的懒惰,而是精神上没有空闲去思考,没有能力去构思独特的东西。
最终,变成一具空壳,连许愿的能力都失去了。
那我们该如何保持独立思考?如何不被 AI 同化?战术上来说,我们需要学会不停地审视 AI 的答案,挑它的毛病,并找到它无法解决的新问题。未来的新价值将来源于三个方面:(1)新的数据发现;(2)对问题全新的深入理解;(3)新的路径,包括可行的创新方案及其结果。利用信息不对称来套利只是暂时的。随着模型越来越强,社会对 AI 的认知越来越清晰,这种机会将迅速消失。如果仅仅满足于完成上级交代的任务,陷入 “应付完就行” 的状态,那么在 AI 泛滥的今天,这种职位极易被取代。
就拿 AI Coding 来说,用多了,我会觉得它虽然可以很快弄出一个可以跑的代码库满足需求,但随着代码越来越长,屎山也越来越高,它贡献的代码也就越来越不如人意,还是需要人来做大的设计规划。如何调教它让它更快达成自己的长远目的,这个会成为人类独有价值的一部分。如果只是盲目地命令它做这个做那个,而不自己去思考如何做才能和它配合做得更好,那就会和大部分人一样停留在应用层面,而无法理解得更深入,就更不用说独一无二了。
战略上来说,无论主动还是被动,每个人都将面临从 “员工” 角色向 “老板” 或 “创始人” 角色的转变。这种转变的核心在于 “目标感”。如果心中有一个坚定的目标,并愿意动用一切手段(包括将大模型作为核心工具)去达成它,那么主动思考就是自然而然的结果。目标越远大,触发的主动思考就越多,激发的潜力就越大。

因此,如果将来的孩子立志要去土卫六开演唱会,或者想在黑洞边缘探险,千万不要打压这样看似荒诞的志向。因为这份宏大的愿望,或许正是他们一辈子充满前进动力,主动思考的根本源泉,也是让他们始终屹立于 “费米能级” 之上的关键。
- 知乎原文链接 1:https://zhuanlan.zhihu.com/p/1990809161458540818
- 知乎原文链接 2:https://zhuanlan.zhihu.com/p/1991073922217709984
.....
#Paper2Any
科研人福音!一键生成PPT和科研绘图,北大开源Paper2Any,全流程可编辑
你是否经历过这样的至暗时刻: 明明实验数据已经跑通,核心逻辑也已梳理完毕,却在面对空白的 PPT 页面时陷入停滞; 明明脑海里有清晰的系统架构,却要在 Visio 或 Illustrator 里跟一根歪歪扭扭的线条较劲半小时; 好不容易用 AI 生成了一张精美的流程图,却发现上面的文字是乱码,或者为了改一个配色不得不重新生成几十次……
在内容生产的过程中,“写” 往往只占了一半,而将文字转化为结构图、流程图,再整理成演示用的 PPT,这个过程繁琐、耗时,且极度考验设计感。为什么我们不能让 AI 像理解文字一样,理解我们的逻辑,并自动帮我们要展示的 “视觉物料” 准备好?
为了解决这一痛点,北京大学 DCAI 课题组 基于自动化数据治理 Agent 框架 DataFlow-Agent,推出了全新的多模态辅助平台 —— Paper2Any。


它不再是一个简单的 “文生图” 工具,而是一整套自动化的内容视觉化 Workflow。从阅读资料、理解逻辑,到生成图像、切割元素,最终输出完全可编辑的 PPT 和 SVG 文件,Paper2Any 正在试图重塑我们准备 Presentation 的方式。
- 本地部署方式:https://github.com/OpenDCAI/Paper2Any?tab=readme-ov-file#-linux-% E5% AE%89% E8% A3%85
- 网页体验地址:http://dcai-paper2any.nas.cpolar.cn/
- 文章多模态工作流 Paper2Any:https://github.com/OpenDCAI/Paper2Any
一、 核心突破:打破 “不可编辑” 的魔咒
目前市面上的 AI 绘图工具虽然效果不错,但在科研与办公等场景下有一个致命缺陷:生成的图片是 “死” 的。 文字无法修改,模块无法拖拽,风格难以统一。

工作流实现逻辑

生成示例PPT绘图
Paper2Any 的核心差异在于它实现了从逻辑到结构化元素的映射。
系统内置的智能体首先对输入的文章或文本进行语义分析,提取核心贡献与思路。接着,它不仅生成视觉图像,更进一步对草稿图进行图文内容分割 —— 自动识别其中的文字、图表、结构模块、图标,并记录每个元素的元数据。
这意味着,你拿到的不再是一张不可直接修改的 PNG,而是一组独立、分层、可操作的图文块。用户可以在 PPT 中自由移动、编辑、替换、重新布局。(Paper2PPT 和 PPTPolish 功能暂时仅支持输出 PDF,可通过 PDF2PPT 功能将其结果转为可编辑 PPTX)
二、 功能全景:从草稿到演示的自动化闭环
Paper2Any 目前支持的功能主要涵盖以下四大核心场景,旨在解决从 “输入素材” 到 “最终汇报” 的最后一公里问题。
Paper2Figure:智能科研绘图,草图变精图
,时长00:18
用户无需从零学习复杂的矢量绘图软件。Paper2Figure 支持多模态输入(PDF、文本、甚至随手画的草图截图),系统便能自动识别你的意图。
- 模型架构图: 上传论文或描述,系统自动梳理模块连接关系,生成清晰的架构图。支持生成 SVG 和 可编辑 PPTX,图里的方框、线条都能动。
- 技术路线图: 无论是中文还是英文,系统能根据方法论自动绘制流程与逻辑步骤。
- 实验数据图: 扔给它一堆实验数据文本或表格,它能自动转化为可视化的对比柱状图或折线图。
Paper2PPT:文章结构化解析与 PPT 生成
,时长00:39
这是为 “赶进度” 的研究者和职场人准备的救星。Paper2PPT 不仅仅是简单的摘要生成,它利用算法对文档结构进行深度语义分析,提取背景、方法论、关键图表。
- 三种输入模式: 直接上传 PDF 论文、粘贴长文本、或者仅仅输入一个研究 Topic(系统会自动深度搜索)。
- 自定义设置: 支持用户自定义幻灯片页数、风格及自由选择中英文语言;支持逐页生成 PPT,用户可自由调整每页 PPT 的大纲。
- 超长 PPT 支持:首次支持制作超过 40 页的超长 ppt,无论是综述的演示还是深入研究某个主题都能一次满足!
- 中文适配与呈现: 可解决大模型生成 PPT 字体怪异及表达僵硬问题。输出结果采用标准中文字体与规范的排版,文案逻辑自然流畅,可减少 “AI 痕迹”,满足正式场合演示需求。

PDF2PPT:让静态文档可编辑

你是否遇到过这种情况:手里只有一份 PDF 格式的讲义或报告,却需要对其进行修改和汇报?
PDF2PPT 模块利用 MinerU 与 SAM (Segment Anything Model) 模型,像 “拆积木” 一样对版面进行高精度解析,将原本锁死的 PDF 页面还原为可编辑的 PPTX。
- 黑科技加持: 系统集成了 Gemini Nano 模型进行图像内补(Inpainting)。当系统将文字提取出来后,会自动修复文字覆盖区域的背景,实现 “去字留影”,最大程度还原原始底图的视觉效果。
PPTPolish:交互式美化专家
如果你的 PPT 内容已经写好,但排版却有些简陋,PPTPolish 可以接手后续的美化工作。系统会自动分析页面并生成美化提示词,用户可以逐页修改提示词来微调美化方向。
,时长00:15
三、 示例高能时刻:从输入到输出的 “视觉魔法”
空口无凭,我们来看看 Paper2Any 的实际表现。
科研绘图:拯救手残党
- 模型架构图生成:
1. 论文 PDF → 符合论文主题的架构图

2. 科研配图 / 示意图截图 → 可编辑 PPTX

3. 论文摘要文本 → 可编辑架构图

- 技术路线图智能梳理:
1. 论文 PDF → 符合论文主题的技术路线图

2. 论文摘要文本 → 符合论文主题的技术路线图

- 实验数据可视化:
1. 论文 PDF → 自动提取实验数据绘制 PPT


不同类型与不同风格的生成图示例
2. 论文实验表格文本 → 自动整理实验数据绘制 PPT

PPT 智能生成与美化
从文档到演示,Paper2Any 提供了全链路的解决方案。
- Paper2PPT:









与 Gemini 3 Pro、NotebookLM 相比,Paper2Any 生成的 PPT 有以下优势:
- 结构化图表生成能力强
- 中文文字表达与字体呈现效果更自然
- 可读性更好,干货更多,排版布局更具专业感与人工感
- PDF2PPT:

- PPTPolish:
1. PPT 增色美化

2. PPT 润色拓展

原始 PPT 只是简单的文字罗列;润色后,系统自动添加了科技感背景、可视化图标、以及逻辑图示,瞬间提升汇报档次。
四、 如何使用与部署
Paper2Any 提供两种使用方式:
1. 本地部署(开发者推荐)
如果你希望深入研究、二次开发或本地运行,可以基于 Github 仓库进行本地部署。
- Github 仓库: https://github.com/OpenDCAI/Paper2Any
- 快速开始指引: https://github.com/OpenDCAI/Paper2Any?tab=readme-ov-file#-linux-% E5% AE%89% E8% A3%85
参考 Readme 文档启动 Web 前端即可。
2. 网页版快速体验
团队已推出可视化的 Web 前端,支持拖拽上传与实时进度展示。新用户可免费注册,登录后可查看历史使用记录。
- 访问地址: http://dcai-paper2any.nas.cpolar.cn/
结语:让配图成为一种「自动获得的附加值」
Paper2Any 的愿景,是希望建立一条新的科研与工作惯例:写文章 + 一键配图 + 一键生成 PPT + 一键展示。
在未来,课题组计划陆续支持 Paper2Rebuttal(论文返修)、Paper2Idea(创新点生成)和 Paper2Poster(文章海报生成)等更多的多模态功能。我们相信,工具的价值在于释放人类的创造力,让你从繁琐的格式调整中解脱出来,将宝贵的时间投入到那些真正闪光的 Idea 之中。
欢迎大家关注使用 DCAI 的开源项目并与我们进行技术交流,如果觉得好用也请在 GitHub 仓库点一个 star ~
Data-centric AI 开源项目:
文章多模态工作流 Paper2Any: https://github.com/OpenDCAI/Paper2Any
自动化数据治理 Agent 框架 DataFlow-Agent: https://github.com/OpenDCAI/DataFlow-Agent
LLM 数据准备系统 DataFlow (1.9k star): https://github.com/OpenDCAI/DataFlow
DataFlow 技术报告(#1 of the Hugging Face daily paper): https://arxiv.org/abs/2512.16676
LLM 数据训练系统 DataFlex (基于 LLaMA-Factory): https://github.com/OpenDCAI/DataFlex
.....
#为什么给耳机装上「眼睛」后AI范式变了?
从「被动」到「主动」~
先行一步
Sam Altman 与 Jony Ive 联手探索的无屏 AI 硬件,正在被逐步揭开。供应链信息显示,这款产品并没有选择屏幕,而更像是一种可穿戴设备:体积接近 iPod Shuffle,可以放入口袋或随身佩戴;内置麦克风与摄像头,持续感知用户所处的真实环境,与之并肩工作,主动给出建议。
在「无屏、主动式 AI」这条路径上,中国公司其实已经先行一步。
12 月底,光帆科技在北京发布了 Lightwear AI 全感穿戴设备。这是一套由 AI 耳机、智能手表以及设计独特的充电盒组成的组合式终端。其中,AI 耳机也是全球首款具备视觉感知能力的主动式 AI 耳机。
三款设备实时协同,扮演一个「始终在场」的 AI 助理 ,与你一同观察世界,并主动参与日常生活与决策。

Lightwear AI 全感穿戴设备,这是一个由 AI 耳机、智能手表以及设计独特的充电盒组成的套装。
「喂,晓帆。」一名戴着耳机的女孩在超市里购物,拿起一瓶饮料,随口喊了一句。发布会现场,出现了这样一个场景。
「在呢。」 隐身在耳机里的 AI 助理被唤醒。
「这个在网上咋卖?」女孩问。AI 「看」了一眼她手中的商品:识别出商品名称,随即在网上搜索同款价格 ——500 毫升 15 瓶,57.9 元,更便宜。
在女孩的确认下,AI 直接完成下单。

耳机黑色部分就是 AI 的眼睛,为 AI 提供视觉感知的摄像头。
类似的主动能力,并不只体现在购物场景中。耳机盒内置 GPS,当用户快到家时,晓帆会主动提醒有快递要取。
在另一个更长任务的演示中,用户只用表达需求,AI 主动把事情完成,并告诉你结果,中间沟通个一两次就行。
整个流程从一句「XX 问你什么时候有空和王总吃饭」开始。晓帆自动检查日程冲突,发现约饭时间与一场产品会议重叠后,按用户要求调整了会议安排。
随后,它继续主动询问是否需要一并处理机票和酒店:机票按照「再早一点」的要求重新预订;酒店则直接按「常住的那一家」定了两晚。
这些场景,都映射出光帆科技试图呈现的主动式 AI 雏形。
发布会之后,这家创业公司也迅速受到关注。其创始人董红光是小米早期员工(第 89 号),长期负责操作系统与智能化相关核心工作,几乎贯穿了小米多个关键技术阶段。成立仅一年多时间,光帆科技便吸引了一批颇具分量的投资机构入局,也为这条「无屏、主动式 AI」路径增添了更多现实注脚。

AI 硬件大爆发,被动式 AI 面临挑战
在光帆科技压轴登场之前,仅在 2025 年这一年里,全球范围内就已密集涌现出一批 AI 硬件产品。阿里推出夸克 AI 眼镜,字节加码 AI 耳机、AI 手机,同时还有 AI Pin、戒指、项链、手环等更具「脑洞」的新形态。
AI 正在加速脱离屏幕,为自己寻找新的「肉身」。而这场 「物种大爆发」,并非偶然。
一方面,大模型能力持续跃迁,终于能够支撑复杂场景的理解,以及长链路任务的稳定执行(如 AI Agent);响应速度也被拉进「1 秒俱乐部」,交互体感开始逼近真人对话。
另一方面,推理与部署成本持续下探,再叠加中国在制造与供应链上的系统性优势,让中国玩家在这一轮 AI 硬件竞赛中显得尤为活跃。
但问题,也同样清晰。
大多数 AI 硬件已经足够贴身,却并不「始终在场」;看起来随时可用,却仍在等待一道清晰的命令。这依然是一种被动式智能,存在认知摩擦。
比如,你需要先掏出手机、打开 App,再用近乎「产品经理式」的方式,把真实需求拆解成一段段包含关键词的 Prompt;又或者,只有在你主动提问「这是什么?」时,AI 眼镜才会启动识别并给出反馈。至于耳机,更是高度依赖语音唤醒和明确指令。
主动式智能正试图消除的就是这种负担。它会持续进行云端计算,感知、理解用户所处的情境(「你现在在超市」)+ 记忆(「你记得要买果汁」),在合适的时机(「你路过商店」),在你尚未开口之前主动介入 ——「别忘了,顺手买果汁。」
事实上,谷歌的 Project Astra 一直在尝试构建这样一个主动的 AI 助手:拥有眼睛、耳朵和声音,能够与你共处、理解你正在经历的世界。这与光帆科技所追求的、带有「活人感」的 AI 助理 —— 全天候、全感知、主动智能 —— 在理念上高度一致。

只不过,Project Astra 尚未脱离手机;而光帆科技的选择,是让 AI 不再依附于手机、建立新的交互范式。但是,这样的 AI 硬件,究竟该如何搭建?
他们先从「AI 需要感知什么、怎么感知」出发,逐步决定是否要做加法、怎么加。
「看得见」,是主动智能的门票
在硬件形态上,光帆科技没有选择已有手机做加法,或是更为主流的眼镜,而是对耳机进行「改造」,在上面装上摄像头。看似反直觉的选择背后,隐藏着他们的清晰认知:视觉感知,是主动智能的门票。
而要做到随时看、随时听、随时跟用户说话,手机和眼镜很难满足。
手机,是为触控交互而生,依赖显式唤醒、依赖用户主动将注意力集中到一块屏幕上,从根本上限制了 AI 的「持续观察力」。而且,手机大部分时间都放在口袋里,无法主动感知,用户也无法随时与之交流。
眼镜似乎更为自然,包括 AI 大厂和初创都很看好,但从长期来看,也并非「最优解」。
首先,在用户接受度上就不太友好,尤其是很多非近视人群根本没有戴眼镜的习惯,而且重。技术层面,精密结构下,电池容量、重量、功耗(尤其叠加 AR 后)之后,很难平衡。而一旦进入「持续视觉扫描」状态,摄像头正对路人,隐私与伦理压力几乎不可避免。
耳机就不同了。用户体量大、接受度高、佩戴自然,选择给耳机装上摄像头,并非简单的硬件堆砌,而是一套围绕感知能力的重构 —— 在耳机已有听觉感知的基础上,在左右耳塞各置一枚 200 万像素摄像头,实现双目视觉感知,并配合充电盒进行辅助定位。

这里的摄像头拍摄,不是给人看,是让 AI「看」,用以理解物理世界的空间与物体,支持「阅后即焚」,不必担心隐私问题。
只有 200 万像素,其实是蕴含着一个重要的「低像素哲学」:更强调「语义理解」而非「光学美感」,AI 无需欣赏 4K 画质的电影,只需要能分辨出用户手中拿的是橙汁、咖啡,还是药品,就足够了。

真正的关键在于 —— 只叠加了一个「视觉感知」,一切都因此而变得不同,因为,视觉是「主动性」的唯一基石。
主动智能的本质,在于主动感知环境、理解上下文并预测行动时机。而这一能力首先依赖对真实世界空间结构、物体关系与动态变化的持续感知,这些关键信息只有视觉能够提供。
而耳机「双目」的视觉高度,恰好与人类视野持平 —— 你看到什么,它就看到什么。于是,AI 可以实时理解你所处的情境,建立稳定的世界模型,判断你的关注焦点,形成「共同注意力」。
没有视觉,AI 无法真正理解世界;没有世界模型,就不可能有真正的主动协作。语音、记忆、推理,只有嵌入视觉框架,才会产生质变。
比如,当用户在路过超市时,AI「看到」用户所处的环境,其「记忆」模块才能被激活,主动发出提醒,「该买橙汁了。」
当用户看到心仪餐厅,想要进一步了解,发出「帮我看下这家餐厅怎么样」的提问指令时,AI 只有「看到」餐厅后,才能启动实现个性化口味比对、附近更优餐厅推荐、餐厅位置准确告知等。

从单兵作战到多感官协同
主动智能的必经之路
要实现真正的主动式 AI,只「薅」一个硬件显然不够。
哪怕是最核心的耳机,也会不可避免地面临感知盲区 —— 比如身体出现异常,AI 根本无从得知。
更现实的问题是,人在睡觉、洗澡、刚起床等场景下,并不会持续佩戴耳机;一些关键信息,也很难长期依赖记忆来维持。
只有走向多感官协同,主动智能才可能真正成立,并逐步逼近全天候、全感知的状态。基于这一判断,在为耳机补上视觉能力之外,光帆科技还为系统引入了一块手表:耳机负责「听」和「看」,手表负责「显示」和「触控」。

首先,手表补齐了语音交互的短板。
那些并不适合通过声音完成的信息交互 —— 例如购物验证码、导航定位、简单提示 —— 可以直接在屏幕上呈现,降低打扰,也提升效率。
更关键的是,手表本身是一枚持续工作的身体传感器。
如果 AI 想要更主动、更贴近个体,就必须理解「人」的状态,而不仅仅是环境。通过持续采集心率、血氧、睡眠、压力等数据,AI 才能感知身体变化,并在合适的时刻给出针对性的提醒与建议。例如在运动中心率异常升高时,主动介入。

与此同时,光帆科技还对耳机充电盒进行了功能重构。
它内置 2020mAh 电池, eSIM 卡与定制化 AI 通信协议,可脱离手机直接联网,还内置高精度 GPS;同时集成算力、独立麦克风和扬声器,即便不佩戴耳机,也可以通过语音与 AI 进行交互。


充电盒上的独立麦克风。
因此,在洗澡、起床、阅读等「不想戴耳机」的场景下,用户依然可以与 AI 保持基本互动,例如询问当天的天气或日程安排。
这种分布式协作的思路,并非个案。
在 Meta 的 Orion 项目中,除了眼镜本体,还配套了一个手势追踪腕带,以及一个遥控器大小的计算模块,三者通过无线方式协同工作。其中,腕带用于读取与手势相关的神经信号,帮助 AI 更精准地理解用户意图。
从这个角度看,手表、耳机、眼镜,乃至充电盒,并不是彼此替代的竞争关系,而是在不同位置、不同维度,分别承担 AI 助理的「感官」与「分身」。它们分工协作、彼此补位,最终目标是一件事:让 AI 真正「在场」,并主动融入生活。
再往远处看,设备的边界只会持续模糊。光帆科技对主动智能的判断是:未来一定是多设备联动,由一个统一的 AI 大脑进行调度。基于自研操作系统,他们后续还将接入更多形态的终端 —— 例如脖挂、眼镜、项链等。
无人区的艰难跋涉
主动智能,不属于某一件硬件,而属于一个协同运作的分布式系统。
而做这样一套分布式 AI 硬件,并不是把耳机、手表、充电盒简单叠加,而是一场关于算力如何分配、设备如何低功耗通信,以及人机工程学如何取舍的极限运动。
其中最核心、最根本的问题是:如何让一个只有几克重的设备,承载起接近大模型的「灵魂」?
光帆科技的解法,是自研一套端云结合的操作系统:Lightware OS,不是把所有能力都塞进单一设备,而是建立一种类似「生物神经系统」的层级分工与调度机制。

最「聪明」、算力最强的大脑,放在云端,负责调用不同的大模型,完成语音与图像理解、意图识别,以及复杂推理与决策。
比如,结合你的位置、你看到的招牌,以及历史评价等信息,判断这是一家什么类型的餐厅、口碑如何、值不值得走进去 —— 这些都交给云端完成。
随身携带的充电盒,同样具备算力,但它并不负责「深度思考」,而是反应足够快、兜底足够稳。
内置 4G eSIM 保证「永不掉线」。它是流量的调度站,在毫秒级内判断请求类型(是查地图还是听歌),瞬间将音视频流推向云端。同时,在网络波动时利用本地算力进行「行为缓冲」,避免 AI 变成「人工智障」。
至于耳机,更像是全天候的「感官末梢」,负责「听」和「看」,只跑最轻量的 AI 任务(如语音唤醒、低像素物体轮廓识别),让这些能力在后台长时间「静默运行」,以极低功耗换取随时在场的体验。
另一个同样棘手的问题,是如何恰如其分地与用户交互。
一个缺乏分寸感的 AI 助手,很快就会从「贴心」变成「打扰」,最终被用户关闭。
因此,在 Lightware OS 中,系统层必须具备对场景的判断能力:用户是否忙碌?当前是否适合打断?这一次介入是否真的有价值?这种对「干扰优先级」的判断,无法只靠给大模型写一段 Prompt 解决,而必须被写进系统的底层逻辑中。
如何让这套分布式硬件长期、可靠地作为一个整体运行,同样是一道工程难题。
哪怕只看端侧,多设备之间的实时通信本身就已经足够复杂;更现实的是,单个设备内部往往也不止一颗芯片,芯片之间如何高效协作,直接决定了系统稳定性。这不是「写好一个程序」就能解决的问题,而是必须在硬件层、驱动层、通信层同时成立。
还有硬件工艺上的「极限平衡」。在耳机这样极度受限的形态中加入摄像头,意味着必须同时权衡体积、重量、续航、散热与佩戴舒适度。
最终,加入摄像头和更大电池后,单只耳机重量被控制在 11g,远低于常见智能眼镜约 40g 的重量,佩戴舒适度和行业头部的耳挂式耳机相当,并无明显不适和异物感。
这几年,CES 一直是「杀手级 AI 硬件」想象力的集中展示场。在众多方向中,个人穿戴与随身设备始终是焦点。而耳机这一高频入口,也正在被重新定义。
2026 年 1 月 6-9 日,光帆科技将携全球首款主动式 AI 耳机亮相 CES。下一代 AI 硬件的方向,或许正藏在这些看似熟悉、却正在被重新塑造的随身设备之中。
.....
#Claude Code创建者的13条独家实战秘籍爆火
500万人在线围观
2026 新年第三天,Claude Code 创建者、负责人 Boris Cherny 开展「线上教学」,亲自示范他自己使用这个 AI 编程工具的工作流。
他表示,自己的配置可能出乎意料地「素」(即简单)!Claude Code 开箱即用非常出色,所以他个人并没有做太多自定义。
使用 Claude Code 没有所谓的「标准答案:在设计时就希望它是可定制、可 Hack 的。用户完全可以按自己的喜好来使用。事实上,Boris 团队里的每个人用它的方式都大不相同。

一、五线并行
在终端里同时运行 5 个 Claude 窗口,给这些标签页排上 1 到 5 号,并开启系统通知,这样当某个 Claude 需要他输入指令时,便会立刻收到提醒。

二、多端无缝衔接
除了本地终端,他还会同时在网页端(http://claude.ai/code)运行 5 到 10 个 Claude 任务。
在终端写代码时,他经常用 & 把本地会话交给后台,或者直接在 Chrome 里启动新会话。有时还会使用 --teleport 命令在两者之间「传送」进度。
每天早上甚至会用手机(iOS 版 Claude App)启动几个会话,之后再回电脑上查看进度。

三、全力投入 Opus 4.5
他会给所有任务开启 Opus 4.5 (带 Thinking 模式),这是他用过的最强编程模型。
虽然它比 Sonnet 更大、更慢,但同时它更聪明、更擅长调用工具,不需要费心去引导它,所以从结果来看,它通常反而比小模型更快完成任务。
四、共享知识库:CLAUDE.md
团队共用一个 CLAUDE.md 文件。他们把它存放在 Git 仓库里,团队成员每周都会多次更新。只要发现 Claude 哪里做错了,他们就把规矩写进 CLAUDE.md,确保它下次不再犯同样的错误。

五、持续复利:代码评审
在代码评审(PR)时,他经常会 @.claude,让它把同事 PR 中的一些规范沉淀到 CLAUDE.md 中。他们通过 /install-github-action 安装了 Claude Code 的 GitHub Action。这就是他们版本的「复利工程」(Compounding Engineering)。

六、谋定而后动:Plan 模式
大多数任务都从 Plan 模式开始(连按两次 Shift+Tab)。如果目标是写一个 PR,他会先在 Plan 模式下反复和 Claude 沟通,直到认可它的方案。
之后,他会切换到自动接受修改模式(auto-accept edits),Claude 通常能直接「一波带走」。一个好的方案至关重要!

七、打造自己的斜杠命令(Slash Commands)
他会把每天重复多次的 “内环” 工作流都封装成斜杠命令。这让他免于重复输入提示词,也让 Claude 能直接调用这些流程。这些命令存放在 .claude/commands/ 下并提交到 Git。
比如,他和 Claude 每天会用几十次 /commit-push-pr。这个命令利用内联 Bash 预先计算 Git 状态等信息,运行极快,避免了反复对话。

八、善用子智能体(Subagents)
他经常使用特定的子智能体:比如 code-simplifier 用来在完成后简化代码,verify-app 用来端到端测试。和斜杠命令一样,子智能体本质上是把 PR 中最常见的流程自动化。

九、自动代码美化
他们使用了 PostToolUse 钩子来格式化代码。虽然 Claude 写的代码格式已经很好了,但这个钩子能搞定最后 10% 的细节,避免在 CI(持续集成)阶段报错。

十、权限管理
他不用 --dangerously-skip-permissions(危险跳过权限提示)。相反会用 /permissions 预先授权一些在当前环境下安全的常用 Bash 命令。这些配置保存在 .claude/settings.json 中,团队共享。

十一、工具全家桶
Claude Code 会帮他操作所有工具,经常通过 MCP 服务器搜索并发送 Slack 消息,运行 bq 命令行执行 BigQuery 查询,或者从 Sentry 抓取报错日志。Slack 的 MCP 配置保存在 .mcp.json 中供团队使用。

十二、长时间任务
对于耗时较长的任务,他会:
- 让 Claude 在完成后启动一个后台智能体进行验证;
- 使用 Stop 钩子进行确定性检查;
- 使用 ralph-wiggum 插件。 在这种情况下,使用 --permission-mode=dontAsk 或在沙盒环境中使用跳过权限模式,这样 Claude 就能心无旁骛地「输出」,不会被权限弹窗卡住。

最后:构建反馈闭环
最后一点,也是拿到高质量结果的关键:给 Claude 一个验证自己工作的途径。如果有反馈闭环,结果的质量能提升 2 到 3 倍。 Claude 在更新网页版代码时,会通过 Chrome 插件测试每一个改动:它会自动打开浏览器,测试 UI,不断迭代,直到代码跑通且交互体验丝滑。
验证方式因领域而不同:可能是运行一段 Bash 脚本、跑测试套件,或者在模拟器里运行 App。请务必花精力把「验证流程」做得坚如磐石。
感兴趣的开发者,可以在日常使用 Claude Code 时,以 Boris Cherny 的做法作为一个参考。
原推链接:https://x.com/bcherny/status/2007179832300581177
.....
#FastDriveVLA
小鹏联合北大,专为VLA模型定制视觉token剪枝方法,让端到端自动驾驶更高效
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
小鹏汽车联合北京大学计算机科学学院多媒体信息处理国家重点实验室发表论文《FastDriveVLA》,不仅为自动驾驶 VLA 模型中的高效视觉 token 剪枝建立了新的范式,也为特定任务的剪枝策略提供了有价值的洞察。
受人类驾驶员主要关注前景区域而非背景区域的启发,研究团队做出假设:对于自动驾驶而言,与前景信息相关的视觉 token 比与背景内容相关的视觉 token 更有价值。为了验证这个假设,研究团队构建了大规模自动驾驶标注数据集 nuScenes-FG(包含来自 6 个摄像头视角的、带有前景区域标注的 24.1 万个图像 - 掩码对),通过 MAE 风格的像素重建策略和新颖的对抗性前景 - 背景重建策略,训练出了一个适用于不同 VLA 模型的、可以即插即用的视觉 token 剪枝器 ReconPruner。
实验结果显示,在不同剪枝比例下,FastDriveVLA 在 nuScenes 开环规划基准测试中均取得了 SOTA 性能。FastDriveVLA 也非常高效,当视觉 token 数量从 3249 减少至 812 时,FastDriveVLA 的 FLOPs 直降约 7.5 倍;在 CUDA 推理延迟方面,FastDriveVLA 将预填充(prefill)时间减少了 3.7 倍、将解码(decode)时间减少了 1.3 倍,显著提升了推理效率。
该篇论文被 AAAI 2026 录用。
- 论文标题:FastDriveVLA: Efficient End-to-End Driving via Plug-and-Play Reconstruction-based Token Pruning
- 论文链接:https://arxiv.org/pdf/2507.23318
研究背景与问题
端到端自动驾驶最近展现出巨大潜力,有望彻底改变未来的交通系统。与传统的模块化自动驾驶系统不同,端到端方法在一个统一的框架中学习整个驾驶流程,这种设计不仅减少了模块之间信息传递时的误差,还增强了系统的简洁性。
然而,现有的 VLA 模型通常将视觉输入转换为大量的视觉 token,这种方法导致了巨大的计算开销和推理延迟的增加,对真实场景的车端部署提出了重大挑战,因为计算资源和推理速度都受到严重限制。
已经有大量研究尝试通过减少视觉 token 来加速 VLM 的推理,但在自动驾驶场景中都具有局限性:引入新设计的多模态投影器需要重新训练整个模型,基于注意力的剪枝策略容易受到无关信息的影响,基于相似性的剪枝策略会错误保留与驾驶无关的信息。
为了解决这些挑战,我们专为端到端自动驾驶 VLA 模型定制了一个新型的、基于重建的视觉 token 剪枝框架 FastDriveVLA。

图 1:不同视觉 token 剪枝策略的对比,(c)为基于重建的剪枝策略
方法与创新
nuScenes-FG 数据集
受人类驾驶员主要关注前景区域而非背景区域的启发,我们首先对自动驾驶场景中的「前景区域」进行了明确定义。这些区域包括行人、道路、车辆、交通标志(含交通信号灯)以及交通障碍物(如位于车道上或紧邻车道的障碍物)等对驾驶决策具有直接影响的元素。相比之下,建筑物、天空、行道树等背景区域即使被完全遮挡,通常也不会显著影响人类驾驶员的判断。然后,借助 Grounded-SAM 对 nuScenes 场景进行细粒度、语义一致的前景分割,构建了 nuScenes-FG 数据集。

图 2:nuScenes-FG 数据集,为 nuScenes 场景提供了 24.1 万个前景分割标注。
基于重建的剪枝器 ReconPruner
我们提出了一种轻量级的、可即插即用的剪枝器 ReconPruner,主要目标是让 ReconPruner 能够有效识别并选择包含有意义前景信息的视觉 token,因此借鉴 Masked Image Modeling(掩码图像建模)方法设计了 MAE 风格的像素重建策略。在训练过程中,我们选取 ReconPruner 预测的可获得高分的视觉 token 子集,用于掩码前景重建。该子集上的重建误差作为监督信号,鼓励 ReconPruner 为真正对应前景内容的视觉 token 打高分。

图 3:FastDriveVLA 框架。在训练阶段,提出了一种新颖的「前景 - 背景对抗重建」策略,以增强 ReconPruner 对前景视觉 token 的感知能力;在推理阶段,ReconPruner 可直接嵌入自动驾驶 VLA 模型,用于 token 剪枝。
对抗性前景 - 背景重建策略
但若仅仅依赖前景重建,ReconPruner 可能会采取捷径,不加区分地为所有视觉 token 打高分。我们从生成对抗网络(GANs)中汲取灵感,提出了对抗性前景 - 背景重建策略。具体来说,ReconPruner 还需要使用获得低分的视觉 token 来重建背景区域。这种对抗性设置增强了 ReconPruner 区分前景 token 和背景 token 的能力。
实验结果
实验设置
我们采用 Impromptu-VLA 作为视觉 token 剪枝的基础模型,在专为城区自动驾驶设计的大规模基准测试数据集 nuScenes 上对不同剪枝方法进行了评估。nuScenes 数据集包含 1000 个驾驶场景、每个场景约持续 20 秒。测试时,我们总计使用了 6019 个测试样本,并通过 L2 轨迹误差、碰撞率、路外率三个指标来评估开环规划的性能。
我们使用余弦调度器以 2e-5 的学习率训练 FastDriveVLA,总计进行了 10 轮训练,仅在两块 H800 GPU 上运行 3 小时就完成了训练。
不同剪枝方法在 nuScenes 数据集上的对比

FastV、SparseVLM 是基于注意力的基线,DivPrune、VisPruner 是基于相似性的基线。
- 当剪枝 25% 时,FastDriveVLA 在所有评估指标上均表现最佳,尤其在 L2 轨迹误差和碰撞指标上分别比未剪枝的原始模型低了 0.1% 和 1.0%,这证明了聚焦于与前景相关的视觉 token 是提升自动驾驶性能的关键。
- 当剪枝 50% 时,FastDriveVLA 在碰撞指标上的表现优于剪枝 25%。
- 当剪枝 75% 时,FastDriveVLA 在路外率指标上的表现优于剪枝 50%。
总体来看,FastDriveVLA 在各种剪枝比例下均优于现有方法。特别值得注意的是,当剪枝 50% 时,FastDriveVLA 在所有指标上的表现都更加均衡。因此,我们建议,在实际部署自动驾驶系统时采用 50% 这一剪枝比例,以实现性能与效率的最佳平衡。
效率分析
为了展示 FastDriveVLA 的高效,我们从 FLOPs 与 CUDA 延迟的角度对不同剪枝方法进行了效率分析。当视觉 token 数量从 3249 减少至 812 时,FastDriveVLA 的 FLOPs 直降约 7.5 倍。在 CUDA 推理延迟方面,FastDriveVLA 将预填充提速 3.7 倍、解码提速 1.3 倍,实际推理效率显著提升。

定性可视化分析
ReconPruner 几乎完整留下了前景 token ,把背景压成极稀疏的色块,重建画面依旧清晰,证明它能在减少 token 冗余的同时保留关键信息,如图 4 所示。
再把 FastV(基于注意力)、DivPrune(基于相似性)和 FastDriveVLA 放到图 5 中进行对比,可以看到:我们的点密密麻麻落在车道、车道线和车身;FastV 几乎漏掉了车辆;DivPrune 虽然撒点更多,却几乎没往车道线上靠。

.....
#Vision Function Layer in Multimodal LLMS
VFL:揭秘 MLLM 内部“分工”机制!仅需 20% 数据即可达成 98% 性能,中山&港大联合提出
现在的多模态大语言模型(MLLM)在处理视觉任务上已经表现得非常出色,从简单的图像描述到复杂的 OCR 和空间推理都能应对自如 。但对于研究人员来说,这些模型内部究竟是如何处理视觉信号的,仍然是一个未解的“黑盒” 。
为了打破这个黑盒,来自 中山大学和香港大学 的研究团队基于大量实验发现了一个惊人的现象:MLLM 并非均匀地处理视觉信息,而是存在特定的 Vision Function Layer (VFL) ,即不同的视觉功能(如识别、计数、OCR)是在特定的、狭窄的层级中完成的 。
基于这一发现,团队提出了一种新的分析框架和应用策略,不仅解释了 MLLM 的内部工作机制,还实现了更高效的微调(LoRA)和数据筛选——仅需 20% 的数据即可达到全量数据 98% 的性能 。
- 论文标题: Vision Function Layer in Multimodal LLMS
- 作者: Cheng Shi, Yizhou Yu, Sibei Yang
- 机构: 中山大学, 香港大学
- 论文地址: https://arxiv.org/abs/2509.24791
- 代码仓库: https://github.com/ChengShiest/Vision-Function-Layer
- 会议/期刊:NeurIPS 2025
MLLM 内部的“流水线”:分工明确,层级分明
以往的研究大多关注如何设计更好的视觉编码器或连接器,却很少探究 LLM 主干网络内部是如何处理视觉 Token 的 。本研究通过深入探究,揭示了 MLLM 内部精细的 视觉功能层(VFL) 机制:
- 功能高度集中: 特定的视觉功能(如计数、OCR、定位)通常只由 2-3 个特定层 负责 。例如在 Qwen2.5-VL 中,计数功能集中在 14-16 层,而 OCR 则集中在 22-24 层 。
- 一致的层级顺序: 无论模型架构(LLaVA 或 Qwen)或规模(3B 到 70B)如何变化,VFL 的排列顺序惊人地一致且符合人类认知:物体识别(Recognition)最先发生,接着是计数(Counting)和定位(Grounding),最后才是 OCR 。
- 冗余性: 许多层对于特定任务是冗余的。对于像 MMMU 这样的任务,去掉这些非功能层甚至能保持或提升性能 。
(图注:左侧展示了通过微小的图像差异来探测特定功能;右侧展示了 Vision Token Swapping 机制,通过在特定层交换 Token 来观察输出变化 。)
如何定位 VFL?独创“手术刀”式探针
为了精准定位这些功能层,研究团队提出了一套新颖的评估框架,包含两种策略:
1. Visual Token Swapping (视觉 Token 交换)
这是定位单一视觉功能的“手术刀”。研究者构建了针对 OCR、计数、识别和定位的成对图像数据集(差异极小,仅目标功能不同)。在解码过程中,将源图像的视觉 Token 在特定层替换为目标图像的 Token 。
- 原理: 通过计算“变化率”(Change Rate),即交换后模型输出发生改变的比例,来精准锁定该功能在哪些层起作用 。
2. Visual Token Dropping (视觉 Token 丢弃)
针对复杂的综合任务(如 MMMU, ScienceQA),无法简单构造对立图像。团队采用了逐步丢弃视觉 Token 的策略 。
- 原理: 分析从某一层开始丢弃视觉 Token 后的性能下降情况,从而反推该层对特定任务的重要性 。
(图注:实验结果显示,OCR、计数和定位功能的“变化率”峰值出现在极其狭窄的特定层,例如 Qwen2.5-VL 的 OCR 功能在第 22 层达到 92.8% 的峰值,验证了 VFL 的存在 。)
VFL 的实战威力:更强、更快、更省
这一发现不仅仅是理论上的突破,更在实际应用中展现了巨大的潜力。研究团队基于 VFL 提出了两种应用策略:
1. Vision-Function-LoRA (VFL-LoRA):精准微调
传统的 LoRA 微调通常均匀地应用在所有层,但这往往是次优的 。既然我们知道了计数功能只在特定层,为什么还要微调其他层呢?
- 方法: 仅针对目标功能对应的 VFL 层进行 LoRA 微调 。
- 效果: 实验显示,VFL-LoRA 仅需 全量 LoRA 1/3 的可训练参数 ,不仅在域内任务上表现持平,更重要的是,它有效避免了灾难性遗忘,在域外(Out-of-Domain)任务上的泛化能力显著优于全量 LoRA 。
2. VFL-Select:超越人类专家的数据筛选
面对海量的训练数据,如何挑选出对提升模型能力最有用的数据?
- 方法: 利用 VFL 机制计算样本在特定层的依赖程度(R_k 分数),以此判断数据主要激活哪种视觉功能,从而进行针对性筛选 。
- 效果: 这是一个令人印象深刻的成果。VFL-Select 策略筛选出的 20% 数据,就能让模型达到全量数据训练 98% 的性能 。 在同等数据量下,其效果始终优于随机筛选和人类专家筛选策略 。
(图注:在不同数据量级下,VFL-Select 策略(VFL)均优于随机(Random)和专家(Expert)策略,特别是在知识密集型任务上优势明显 。)
写在最后
这项研究通过“Vision Function Layer”这一全新视角,为理解多模态大模型的黑盒机制打开了一扇窗 。它证明了 MLLM 并非混沌的神经网络,而是进化出了类似人类大脑的层级化功能分区 。
对于开发者而言,VFL 的发现意义重大:它意味着我们可以通过 剪枝冗余层 来加速推理,通过 针对性微调 来降低显存开销,通过 科学的数据筛选 来减少训练成本 。在追求大模型“降本增效”的今天,VFL 无疑提供了一个极具价值的新思路 。
.....
#谷歌联手Meta要让TPU支持PyTorch
英伟达危!谷歌联手Meta要让TPU支持PyTorch,击穿CUDA护城河
谷歌正在推进一项代号为「TorchTPU」的战略行动,核心是让全球最主流的 AI 框架 PyTorch 在自家 TPU 芯片上跑得更顺畅。这项行动不仅是技术补课,更是一场商业围剿。作为 PyTorch 的掌控者,Meta 也深度参与其中,两家巨头试图联手松动英伟达的垄断地位。对于谷歌而言,卖芯片不再是终点,降低开发者的迁移门槛,才是真正介入战争的开始。
谷歌正在发起一项代号为「TorchTPU」的新行动,试图以此打破英伟达在 AI 算力市场的长期垄断。
据知情人士透露,这项计划的核心在于让谷歌自研的 AI 芯片(TPU)能够更顺滑地运行 PyTorch,这是目前全球最主流的 AI 软件框架。
这是谷歌激进战略拼图中的关键一块,他们希望将 TPU 打造为英伟达 GPU 的有力替代者。
随着谷歌急需向投资者证明其巨额 AI 投入的回报能力,TPU 的销售已然成为谷歌云营收增长的重要引擎。
但光有硬件是不够的。
知情人士指出,「TorchTPU」旨在消除那道长期阻碍 TPU 普及的无形围墙,也就是让那些早已习惯在 PyTorch 环境下搭建技术架构的客户,能够无痛迁移到谷歌的硬件上。
甚至有消息称,为了加速这一进程,谷歌正考虑将部分软件开源。
相较于过往对 PyTorch 的零星支持,这一次谷歌投入了前所未有的组织关注度和战略资源。
这一转变的背后,是越来越多渴望采用 TPU 的企业发出的呼声。对他们来说,芯片是个好东西,但软件栈却成了瓶颈。
在硅谷,PyTorch 是 AI 模型开发者的通用语言,而它的最大支持者正是 Meta。
在这个行业里,极少有开发者会去为英伟达、AMD 或谷歌的芯片逐行编写底层代码,他们依赖的是像 PyTorch 这样的工具库来自动化处理开发任务。
自 2016 年发布以来,PyTorch 的成长史几乎就是一部与英伟达 CUDA 生态的绑定史。
华尔街分析师普遍认为,CUDA 才是英伟达抵御竞争对手最坚固的盾牌。
多年来,英伟达的工程师们不仅造芯片,更致力于确保 PyTorch 开发的模型在其硬件上跑得又快又好。
相比之下,谷歌此前走了一条截然不同的路。
他们拥有庞大的内部软件军团,使用一套名为 Jax 的代码框架,并通过 XLA 工具来优化 TPU 的运行效率。
谷歌自身的 AI 软件栈和性能优化大多围绕 Jax 构建,这种「圈地自萌」的做法,拉大了谷歌芯片与外部客户实际使用习惯之间的鸿沟。
面对路透社的询问,谷歌云发言人虽未对该项目细节置评,但确认了这一战略方向。
他表示,无论是 TPU 还是 GPU 基础设施,需求都在加速爆发,谷歌的重心是提供足够的灵活性和规模,无论开发者选择在何种硬件上构建应用。
从自用到外售
TPU 的角色演变
曾几何时,谷歌将绝大多数 TPU 产能视为「私藏珍品」,仅供内部使用。
这一局面直到 2022 年才发生改变,谷歌云部门成功争取到了 TPU 的销售主导权。
此后,谷歌云大幅增加了对外分配的 TPU 额度,试图在客户对 AI 兴趣激增的当下,通过扩大产能和销售来抢占市场。
然而,供需之间存在错位。
全球大多数 AI 开发者使用的是 PyTorch,而谷歌芯片最擅长的却是 Jax。
这意味着,想要使用谷歌芯片并获得比肩英伟达的性能,开发者必须进行大量额外的工程适配。
在分秒必争的 AI 竞赛中,这种时间和资金的消耗是企业难以承受的。
如果「TorchTPU」计划成功,它将显著降低企业寻找英伟达 GPU 替代方案时的转换成本。
英伟达之所以难以撼动,不仅在于硬件性能,更在于 CUDA 生态已经深深嵌入 PyTorch,成为训练和运行大模型的默认选项。
知情人士表示,企业客户曾反复向谷歌反馈,TPU 虽好,但接入门槛太高,因为历史上它强迫开发者放弃通用的 PyTorch,转而学习谷歌内部偏好的 Jax。
盟友 Meta
敌人的敌人就是朋友
为了加速开发进程,谷歌找来了一位关键盟友,即 PyTorch 的创造者和守护者 Meta。
据知情人士透露,这两大科技巨头正在商讨协议,让 Meta 获得更多 TPU 的使用权。此前《The Information》也曾报道过这一动向。
在早期合作中,谷歌主要以托管服务的形式向 Meta 提供支持。
Meta 使用谷歌设计的芯片运行谷歌的软件和模型,并由谷歌提供运营维护。
对 Meta 而言,推动软件适配 TPU 具有极高的战略价值,它不仅能降低推理成本,更能通过硬件基础设施的多元化来减少对英伟达的依赖,从而在谈判桌上获得更多筹码。
Meta 方面对此拒绝置评。
今年以来,谷歌已开始将 TPU 直接出售给客户的数据中心,而不再局限于自家的云服务。
组织架构也在随之调整,谷歌老将 Amin Vahdat 本月被任命为 AI 基础设施负责人,直接向 CEO 桑达尔·皮查伊(Sundar Pichai)汇报。
这套基础设施对谷歌至关重要,它不仅要支撑包括 Gemini 聊天机器人和 AI 搜索在内的自家产品,也要服务于像 Anthropic 这样依赖谷歌云 TPU 算力的外部独角兽。
参考资料:
.....
#Yoshua Bengio成历史被引用最高学者
超97万:何恺明进总榜前五
全世界、所有科学领域都算上,现在最热门的方向就是 AI 了。
图灵奖得主 Yoshua Bengio,近日成为了有史以来被引用次数最多的科学家:他的总被引用量高达 973,655 次,近五年引用量达到 698,008 次。
这项统计来自 AD Scientific Index,这是一个全球性的学术排名和分析平台,旨在评估和展示科学家、研究人员以及学术机构的科研表现和影响力。
参与这次排名的共计 2,626,749 名科学家,分布在 221 个国家和地区,隶属 24,576 家机构。排名依据总引用量和近五年的引用指数进行排序。值得一提的是,这次排名不止 AI 领域,还包括医学等 13 个主要学科和 221 个学术细分学科。
我们再回到 Bengio 的研究。从学术主页来看,Bengio 2014 年提出的 「生成对抗网络(Generative Adversarial Nets)」 引用量已突破 10 万次,甚至超过了他与 Yann LeCun 和 Geoffrey Hinton 合著的经典论文 「Deep Learning」,不过,后者的引用量同样也超过 10 万次。
来源:https://scholar.google.com/citations?user=kukA0LcAAAAJ&hl=en
排名第二的是 2024 诺奖得主、AI 领域先驱 Geoffrey Hinton,他的总被引用量为 95 万 +,近五年引用量为 57 万 +。
其中,Hinton 和学生 Alex Krizhevsky、Ilya Sutskever 合作的 AlexNet 引用量高达 18 万 +。这篇论文发表于 2012 年,其在 ImageNet 大规模视觉识别挑战赛(ILSVRC 2012)上取得压倒性胜利,标志着深度学习在计算机视觉领域的突破性进展。
来源:https://scholar.google.com/citations?view_op=list_works&hl=en&hl=en&user=JicYPdAAAAAJ
位列第三、第四的研究者来自医疗领域:
何恺明排名第五,单篇论文《Deep Residual Learning for Image Recognition》引用量超过 29 万次。这篇论文提出的 ResNet 成为现代深度学习的基础,几乎所有视觉模型都借鉴了残差思想。
来源:https://scholar.google.com/citations?user=DhtAFkwAAAAJ&hl=en
值得一提的是,今年四月,据 Nature 统计 ResNet 是 21 世纪被引量最多论文,单篇 29 万次,经典论文可以说是当之无愧了。可参考「何恺明的 ResNet,成为 21 世纪被引量最多论文,Nature 最新统计」。

在 top 10 名单中,我们也看到了 Ilya Sutskever 的身影,总引用量 67 万 +,排名第 7,单篇论文最高引用量 18 万 + 。
来源:https://scholar.google.com/citations?user=x04W_mMAAAAJ&hl=en
我们不难发现,这些高被引研究不仅在当时引发了学术界的广泛关注,更在随后的十几年里持续产生深远影响。
完整排名列表请参考:
https://www.adscientificindex.com/citation-ranking/
.....
#Macro-from-Micro Planning( MMPL )
突破长视频生成瓶颈:南大、TeleAI推出全新AI生成范式MMPL,让创意一镜到底
向迅之,南京大学 R&L 课题组在读博士生,导师是范琦副教授。研究聚焦图像/视频生成与世界模型等 AIGC 方向。
你是否曾被 AI 生成视频的惊艳开场所吸引,却在几秒后失望于⾊彩漂移、画面模糊、节奏断裂? 当前 AI 长视频⽣成普遍⾯临 “高开低走 ” 的困境:前几秒惊艳夺⽬ ,之后却质量骤降、细节崩坏;更别提帧间串行生成导致的低效问题 —— 动辄数小时的等待,实时预览几乎难以企及。
这—行业难题,如今迎来突破性解法!
南京大学联合 TeleAI 推出长视频自回归生成新范式——Macro-from-Micro Planning( MMPL),重新定义 AI 视频创作流程。
灵感源自电影工业的 “分镜脚本 + 多组并行拍摄” 机制,MMPL 首创 “宏观规划、微观执行 ” 的双层⽣成架构:
- 先谋全局:在宏观层面统—规划整段视频的叙事脉络与视觉—致性,确保剧情连贯、风格统—;
- 再精细节:将长视频拆解为多个短片段,并通过并行化⽣成管线⾼效填充每—帧细节,大幅提升速度与稳定性。
成果令人振奋:
- 实现分钟级⾼质量长视频稳定生成,告别 “虎头蛇尾”;
- ⽣成效率显著提升,结合蒸馏加速技术,预览帧率最高可达约 32 FPS ,接近实时交互体验;
- 在色彩—致性、 内容连贯性上全⾯超越传统串行生成方案。
MMPL 不仅是—项技术升级,更是向 “AI 导演” 迈进的重要—步 —— 让机器不仅会 “拍镜头” ,更能 “讲好—个故事”。
- 论文标题:Macro-from-Micro Planning for High-Quality and Parallelized Autoregressive Long Video Generation
- 作者:Xunzhi Xiang, Yabo Chen, Guiyu Zhang, Zhongyu Wang, Zhe Gao, Quanming Xiang, Gonghu Shang, Junqi Liu, Haibin Huang, Yang Gao, Chi Zhang, Qi Fan, Xuelong Li
- 机构 :南京大学;中国电信人工智能研究院;上海交通大学;香港中文大学(深圳);中国科学院大学
- 论⽂地址:https://arxiv.org/abs/2508.03334
- 项⽬主页:https://nju-xunzhixiang.github.io/Anchor-Forcing-Page/

传统困境:逐帧⽣成的两大瓶颈
在长视频生成领域,随着时长从几秒扩展到数十秒甚至一分钟以上,主流自回归模型面临两个根本性挑战:
1. 时域漂移(Temporal Drift)
由于每—帧都依赖前—帧生成,微小误差会随时间不断累积,导致画面逐渐 “跑偏”:人物变形、场景错乱、色彩失真等问题频发,严重影响视觉质量。
2. 串⾏瓶颈(Serial Bottleneck)
视频必须逐帧⽣成,⽆法并⾏处理。⽣成 60 秒视频可能需要数分钟乃⾄数⼩时,难以⽀持实时预览或交互式创作。
,时长00:27
这些问题使得当前 AI 视频仍停留在 “ 片段级表达” ,难以胜任需要长时连贯性的叙事任务。
创新突破:导演式双层生成框架 MMPL
为解决上述问题,我们提出 Macro-from-Micro Planning( MMPL) —— — 种 “先规划、后填充” 的两阶段生成范式,其核心思想是:
先全局规划,再并行执行。
这—理念借鉴了电影工业中 “导演制定分镜脚本 + 多摄制组并行拍摄” 的协作模式,将长视频生成从 “接龙式绘画” 转变为 “系统性制片 ”。
MMPL 的核心优势在于实现了三大突破:
- 长时⼀致性:通过宏观规划抑制跨片段漂移;
- 高效并行性:各片段可独立填充细节,支持多 GPU 并行;
- 灵活调度性:采用流水线机制,进—步提升资源利用率。
最终,系统可在保证高质量的前提下,实现分钟级、节奏可控的稳定⽣成,结合蒸馏加速方案,预览速度可达 ≥32 FPS ,接近实时交互体验。
效果呈现:更稳、更长 、更快
在统—测试集上,MMPL 显著优于现有方法(如 MAGI 、SkyReels 、CausVid 、Self Foricng 等),在视觉质量、时间—致性和稳定性方面均取得领先。
- 更稳:无明显色彩漂移、 闪烁或结构崩坏,长时间生成仍保持高保真;
- 更长: 支持 20 秒、30 秒乃至 1 分钟的连贯叙事,片段衔接自然;
- 更快:得益于并行填充与自适应调度,长视频生成整体吞吐量大幅提升。
,时长00:28
,时长00:52
技术解析:两阶段协同工作机制
MMPL 的成功源于其精心设计的 “规划 — 填充” 双阶段架构。整个流程分为两个层次:微观规划( Micro Planning) 和宏观规划( Macro Planning),随后进行并行内容填充(Content Populating)。
第⼀阶段:双层规划,构建稳定骨架

1. Micro Planning: 片段内关键帧联合预测
我们将长视频划分为多个固定长度的片段(例如每段 81 帧)。对每个片段,模型不直接生成所有帧,而是基于首帧
![]()
,联合预测⼀组稀疏的关键未来锚点帧,包括:
- 早期邻近帧
-

- 中部关键帧
-

- 末端结束帧
-

记锚点集合为

,其生成过程建模为:

这些锚点在同—去噪过程中联合生成,彼此之间语义协调、运动连贯;且均以首帧为条件单步预测,避免了多步累积误差。它们共同构成了该片段的 “视觉骨架” ,为后续填充提供强约束。
2. Macro Planning:跨片段叙事⼀致性建模
为了确保整个视频的连贯性,我们将各片段的 Micro 计划串联成—个⾃回归链:第 s 段的末端锚点作为第 s + 1 段的起始条件。设第 s 段的锚点集合为
![]()
,首帧为
![]()
,则全局规划可表示为:

这种 “分段稀疏连接” 的设计,将误差累积从 T 帧级别降低至 S 段级别( S ≪ T),从根本上缓解了长程漂移问题。
第二阶段:并行填充,释放计算潜能

1. Content Populating:基于锚点的并行细节生成
在所有片段的锚点

就绪后,即可并行填充各⽚段内的中间帧。
以第 i 个片段为例,其内容被划分为两个子区间:

条件概率分解如下:

由于每个片段的填充仅依赖本片段的锚点
![]()
,与其他片段无关, 因此所有片段的内容填充可完全独立:

这意味着: 多个片段可以同时在不同 GPU 上并行⽣成,极大提升效率。
2. Adaptive Workload Scheduling:动态调度,实现流水线加速
为进—步提升资源利用率,我们引入自适应工作负载调度机制,实现 “规划” 与 “填充” 的重叠执行:
当片段 s 的锚点生成后,即可:
- 立即启动下—片段 s + 1 的 Micro 计划;
- 同时,片段 s 自身可提前开始中间帧填充,无需等待全局规划完成。
该机制的形式化表达为:

其中,下—片段的起始帧

可选择为

或

, 由此衍⽣出两种运行模式:
最小内存峰值模式
选用

作为

,跳过当前片段末尾部分

的填充。
- 优势:降低峰值内存占用与单段延迟;
- 缺点:引入帧重用 ,影响吞吐量。
最大吞吐量模式
选用

作为

,完整生成当前片段所有中间帧。
- 优势:消除冗余,最大化流水线效率;
- 缺点:每段计算负载更高。
这两种策略可在内存、延迟与吞吐量之间灵活权衡,适配不同部署场景。
结语:从 “会画” 到 “会拍”,AI 开始有了导演思维
当 AI 不再局限于逐帧生成,而是具备了从整体出发的规划能力 —— 理解情节的推进、协调画面的连贯性、控制运动的节奏,长视频生成便迈出了从 “ 片段拼接” 走向 “统—表达” 的关键—步。我们希望,MMPL 能为视频创作提供—种更稳定、更高效的技术路径。借助其近实时的生成能力,创作者可以在快速反馈中不断调整与完善自己的构想,让创意更自由地流动。
也许真正的 “所见即所得” 尚在远方 ,但至少,我们正朝着那个方向,稳步前行。
.....
#全球开源大模型
前十五名全是中国的
国产开源力量的集中爆发。
都在说国内大模型正在驰骋开源领域,具体的情况如何?
近日,随着新一代大语言模型(LLM)的一波更新,开源大模型再次成为了热门讨论话题。软件工程师、自媒体 Rohan Paul 发现了一个惊人的现象:Design Arena 排行榜上排名前十几位开源 AI 模型全部来自中国。

Design Arena 是目前全球最大规模的众包 AI 生成设计 Benchmark 平台,它的核心机制是让真实的人类用户进行评测,基于 Elo Rating(类似于国际象棋评分体系)等级分制度进行模型对战。
用户在平台上会被随机展示两段由不同模型生成的回答,然后进行投票选择「哪一个更好」。每一次投票都会影响对应模型的 Elo 分数,进而形成动态的排行榜。Elo 核心原理是,高分选手击败低分选手,得分会很少,而低分选手爆冷战胜高分选手时,得分会很多。因此用对弈的角度来看的话,这是一个相对公平、符合认知的评分系统。
因此,不同于 MMLU、SWE-Bench 这类客观指标,Design Arena 更贴近于「用户真实体验」。新模型一上线,就能迅速通过对战获得口碑分数。
在 Design Arena 上,如果把条件设定为「开源」,可见现在的前 15 名是清一色的国产开源大模型:

排名第一的是 DeepSeek-R1-0528,智谱的 GLM-4.5 和阿里的 Qwen 3 Coder 480B 紧随其后。
再往下我们能看到 DeepSeek、Qwen、GLM 的各种型号,Kimi 在 7 月份开源的 K2 模型…… 一直到第 16 名才是 OpenAI 最近开源的 GPT OSS 120B。

在前 15 名中,各家大模型厂商上榜的模型数量依次如下:
- 阿里:6 款
- DeepSeek:5 款
- 智谱:3 款
- Kimi:1 款
最近一段时间,国内 AI 公司不断发布新一代开源大模型,正在开拓 AI 技术的前沿。甚至对于国内科技公司来说,开源已经成为了最近一两个月发布的主旋律。
在 Hugging Face 发布的中国 AI 社区 7 月开放成果中,包括阿里、智谱、昆仑万维、月之暗面、腾讯、阶跃星辰等在内的多家厂商先后开源了 33 款大模型。
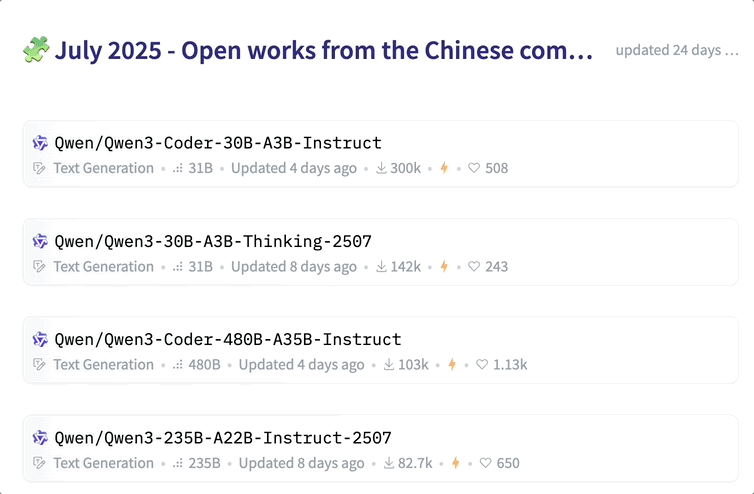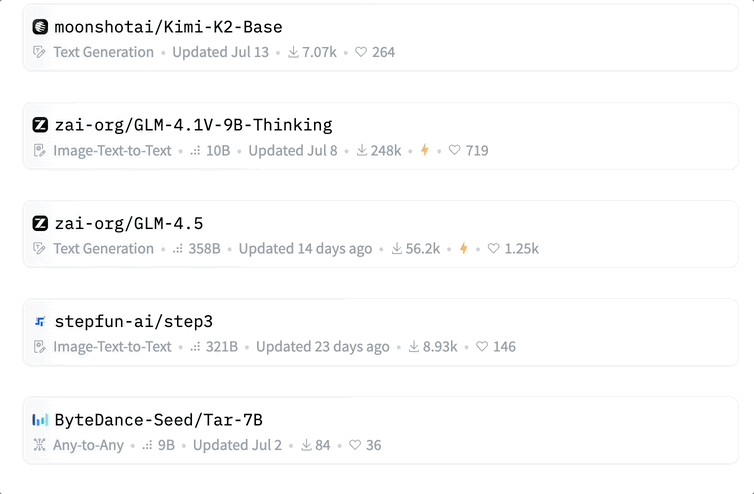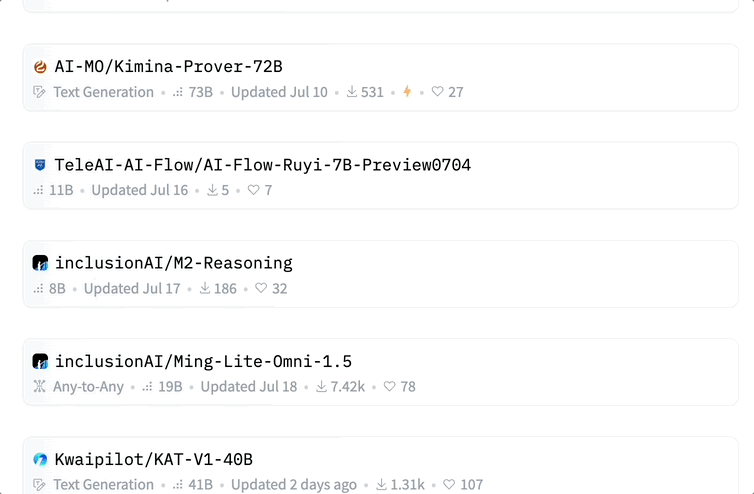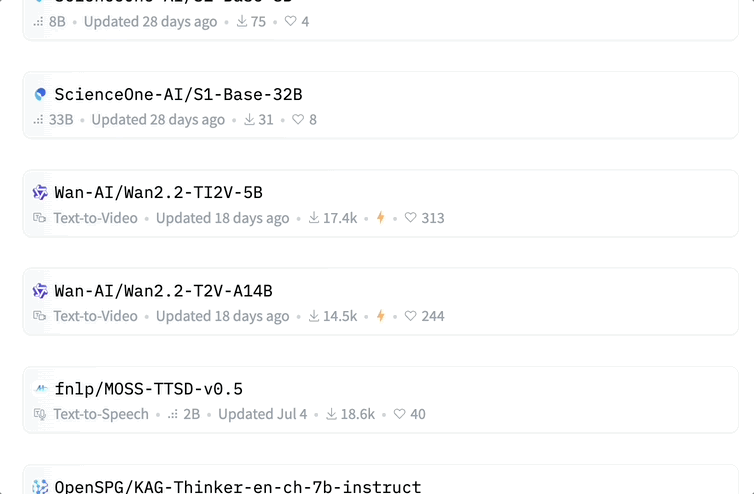
此前还有机构 Interconnects(深度聚焦前沿 AI 研究的高质量内容平台)汇总了国内顶尖的 19 家开源模型实验室,包括 DeepSeek 这样的顶级机构,以及一些通过技术报告和小众模型崭露头角的新兴学术实验室。

这 19 个开源玩家依次是:DeepSeek、Qwen、Moonshot AI (Kimi)、Zhipu / Z.AI、StepFun、Tencent (Hunyuan)、RedNote (Xiaohongshu)、MiniMax、OpenGVLab / InternLM、Skywork、ByteDance Seed、OpenBMB、Xiaomi (MiMo)、Baidu (ERNIE)、Multimodal Art Projection、Alibaba International Digital Commerce Group、BAAI 以及 inclusionAI、Pangu (Huawei)。
在大模型领域里,技术和性能领先的一直是以 GPT 系列为代表的闭源大模型。但随着 Llama 系列兴起,越来越多的开源模型逐渐成为了推动技术向前进步的重要动力。近一年多时间里,国产大模型集群式的崛起,则重塑了全球 AI 版图。
现在说起开源的大模型,大多数人的第一反应早已不是 Llama,而是 Qwen 和 DeepSeek。有人认为,正是 DeepSeek 等开源大模型能够与闭源顶尖模型分庭抗礼,才让众多应用端公司得以转变工作重点,把精力放在模型调优和应用优化的工作上来,进而加速了 AI 技术的落地。
或许这样的趋势也会扭转 AI 研究社区的趋势,让未来最先进模型的开源成为必选项。
最后,在外网也有人在为中国的 AI 模型崛起寻找深层原因。这位 Illya Gerasymchuk 是数学专业的硕士,他认为原因在于数学基础 —— 目前东亚人在数学领域上已经占据了主导地位。

这是否和我们一直以来的印象已经有些不一样了?
参考链接:
https://www.designarena.ai/
https://x.com/rohanpaul_ai/status/1959710355208499692
https://x.com/interconnectsai/status/1957105950201950715
.....
#Speed Always Wins
唯快不破:上海AI Lab 82页综述带你感受LLM高效架构的魅力
作者:孙伟高 上海人工智能实验室
近年来,大语言模型(LLMs)展现出强大的语言理解与生成能力,推动了文本生成、代码生成、问答、翻译等任务的突破。代表性模型如 GPT、Claude、Gemini、DeepSeek、Qwen 等,已经深刻改变了人机交互方式。LLMs 的边界也不止于语言和简单问答。随着多模态(VLMs)与推理能力(LRMs)的兴起,LLMs 正不断扩展到多模态理解、生成与复杂推理场景。
但模型性能持续提升的背后,是模型尺寸、数据规模、RL 推理长度的快速 Scaling,是算力和存储资源的急剧消耗。大模型的训练与推理的成本居高不下,成为制约其广泛落地和应用的现实瓶颈。
本文从 LLM 架构角度出发,带你剖析大模型的效率秘诀。这一切的核心在于 Transformer 架构。Transformer 的自注意力机制虽带来了远距离建模的突破,却因 O(N2) 的复杂度在长序列任务中成本高昂。而在 RAG、智能体、长链推理、多模态等新兴场景下,长序列需求愈发突出,进一步放大了效率与性能之间的矛盾。同时 Transformer 的 FFN 部分采用密集的 MLP 层,同样面临模型规模放大后的训练和推理效率问题。
近年来针对 Transformer 架构改进的创新工作层出不穷,却一直缺乏一篇全面深入的综述文章进行总结。

图 1:常见长序列场景
近期,上海 AI Lab 联合港科广、澳门大学、中科院自动化所、苏州大学、瑞典 KTH、北大、港中文等多家机构,总结 440 余篇相关论文,深入探讨了当前 LLM 高效结构的最新进展,形成这篇 82 页的综述论文:
论文标题:Speed Always Wins: A Survey on Efficient Architectures for Large Language Models
论文地址:https://arxiv.org/pdf/2508.09834
项目仓库:https://github.com/weigao266/Awesome-Efficient-Arch

图 2:大语言模型高效架构概览
该综述将目前 LLM 高效架构总结分类为以下 7 类:
- 线性序列建模:降低注意力训练和推理复杂度,无需 KV Cache 开销。
- 稀疏序列建模:通过稀疏化注意力矩阵,降低计算与显存需求。
- 高效全注意力:在保持完整注意力的前提下优化内存访问与 KV 存储。
- 稀疏专家模型:通过条件激活部分专家,大幅提升模型容量而不增加等比例计算成本。
- 混合模型架构:结合线性/稀疏序列建模与全注意力,兼顾效率与性能。
- 扩散语言模型:利用非自回归的扩散模型进行语言生成。
- 其他模态应用:将这些高效架构应用于视觉、语音、多模态模型。
这些方向的探索不仅关乎 LLM 的未来效率,也关乎如何在算力受限的条件下,持续推动 AI 走向更强的智能的关键选择。综述涉及的方法类别和代表性论文可见如下树状图:

图 3:综述完整组织架构
线性序列建模
线性序列建模是近年来研究相当火热的一个方向,代表性工作像 Mamba、Lighting Attention、RWKV、GLA、TTT 等在模型架构方向都引起过广泛关注。我们将这类技术细分为以下几个类别:
- 线性注意力
- 线性 RNN
- 状态空间模型
- 测试时推理 RNN
并且正如在多篇文献里已经提出的,这些线性序列建模方法可以概括为统一建模的数学形式,并且能够通过线性化过程将预训练模型权重的 Softmax Attention 架构转为 Linear Sequence Modeling 架构,从而获得模型效率的大幅提升,如下图所示。

图 4:线性序列建模方法
我们将已有的线性序列建模方法从记忆视角和优化器视角分别进行梳理和对比,详细形式可见下表:

表 1:线性序列建模方法统一建模的 Memory 视角和 Optimizer 视角
其中线性化技术可以进一步细分为基于微调的线性化,和基于蒸馏的线性化,如下图所示:

图 5:线性化方法
综述还进一步总结归纳了目前在线性序列建模领域常见的硬件高效实现方法,可以归纳为 Blelloch Scan、Chunk-wise Parallel 和 Recurrent for Inferences,如下图所示:

图 6:线性序列建模方法的硬件高效实现
稀疏序列建模
稀疏序列建模是另一类有代表性的高效注意力机制,通过利用 Attention Map 天然具有的稀疏性加速注意力的计算,这类方法可以进一步细分为:
- 静态稀疏注意力
- 动态稀疏注意力
- 免训练稀疏注意力
代表性的稀疏注意力方法如 Global Attention、Window Attention、Dilated Attention 等,及其工作原理如下图所示:

图 7:稀疏注意力的几种经典形式
高效全注意力
另一类高效注意力算法可以统一归纳为高效全注意力,这类方法可以根据算法思路进一步细分为如下几类:
- IO-Aware Attention
- Grouped Attention
- Mixture of Attention
- Quantized Attention
其中 IO-Aware Attention 指代目前使用非常广泛的 Flash Attention 系列工作,Grouped Attention 则包含广为使用的 GQA、MLA 等全注意力变体,几种代表性方法如下图所示。

图 8:Grouped Attention 的几种代表性方法
稀疏混合专家
稀疏混合专家是对 Transformer 架构中另一个重要模块 FFN 做的一类重要改进,已经逐渐成为(语言和多模态)大模型架构的事实标准。综述中将相关文献按以下三个方向进行分类:
- Routing Mechanisms
- Expert Architectures
- MoE Conversion
路由机制包括 Token-choice 和 Expert-choice 两类,其原理如下图所示:

图 9:MoE 路由机制
专家结构的创新工作包括:共享专家、细粒度专家、零专家、深度路由等,其作用和原理可见下图:

图 10:MoE 专家架构
另外一个重要的方向是 MoE 转换,已有的工作包括通过 Split、Copy、Merge 等手段对专家进行构造,如下图所示:

图 11:MoE 转化机制
混合架构
混合架构是近年来出现的一种实用的新型架构,可以在线性/稀疏注意力和全注意力之间取得微妙的 Trade-off,也在效率和效果间找到了最佳甜蜜点。具体可细分为:
- 层间混合
- 层内混合

图 12:混合架构形式
扩散大语言模型
扩散大语言模型是近期出现的一个热门方向,创新性地将扩散模型从视觉生成任务迁移至语言任务,从而在语言生成速度上取得大幅进步。相关工作可以细分为:
- Non-Autoregressive Diffusion LLM
- Bridging Diffusion LLM and Autoregressive
- Extending Diffusion LLM to Multimodality

图 13:扩散大语言模型机制
应用至其他模态
最后一个重要的部分是高效架构在其他模态上的应用,涵盖视觉、音频和多模态。以 Mamba 为代表的线性模型被广泛应用至多种模态任务上,并取得了优秀的表现,综述将这类模型总结梳理至如下表格:

寄语
最后正如帝国时代 3 中这条神奇代码「Speed Always Wins」能让游戏世界「Increases build, research, shipment, and gather rates by 100 times for all players」一样,我们希望综述中的 Efficient Architectures 可以真被用来 100x 加速 AI 世界的构建,更快更便宜地训练出更强更实用的大模型。请记住这条神奇代码:「Speed Always Wins」
.....
#没有思考过 Embedding,不足以谈 AI
Embedding终于有份“说明书”。哈工大万字综述一次性说清:文本嵌入如何用 PLM 完成通用、多模态、多语言的三级跳,并给出性能跃迁的三板斧。
文本嵌入(Text Embedding)几乎贯穿了所有 NLP 任务:检索、分类、聚类、问答、摘要……
随着 BERT、T5、LLaMA/Qwen3 等预训练语言模型(PLM)的出现,文本嵌入进入了“通用+可迁移”时代。
哈工大这篇 30+ 页综述系统回答了(论文链接在文末):
- 通用文本嵌入(GPTE)的架构、数据、模型
- PLM 到底给GPTE带来了哪些基础能力与高级扩展?
01 一张图先看清 GPTE 架构
图1:GPTE 典型架构——Bi-Encoder + 对比学习
- 骨干:任意 PLM(BERT、T5、LLaMA…)
- 池化:CLS / Mean / Last-Token / Prompt-Pooling
- 训练:大规模文本对 + InfoNCE 对比损失
- 微调:任务特定的轻量适配(LoRA、Adapter)
Embedding训练数据
02 PLM 的「基础角色」
50种有代表性的开源GPTE方法(模型)

基于不同预训练语言模型(PLM)主干的通用文本嵌入(GPTE)模型性能对比,聚焦于广泛采用的开源 PLM:模型规模越大、主干越强,GPTE 性能越好,但解码器架构需更多参数才能与编码器架构匹敌。
03 PLM 的「高级角色」
(6) 多模态
- 说到多模态,典型应用是RAG检索,从rag到multimodal-rag已然成一种趋势
- 另外现有MLLM能力也都很强,给一张照片,就能基于掌握的知识(结合河流走向和城市结构)推理出这是:纳什维尔(Nashville)是美国田纳西州
|
模型 |
模态 |
训练数据 |
特色 |
|
E5-V |
T + I |
LLaVA-NeXT |
把 LLM 当图文编码器 |
|
VLM2Vec-V2 |
T + I + V |
Qwen2-VL |
统一视频/图像/文档检索 |
|
MegaPairs |
T ↔ I |
合成 500M 图文对 |
数据即战力 |
表6:多模态嵌入模型全家福
表7:多模态嵌入数据
(7) 多语言
|
模型 |
Backbone |
语言数 |
亮点 |
|
mE5 |
XLM-R |
100+ |
中英跨语种零样本检索 |
|
BGE-M3 |
XLM-R + Long |
200+ |
8192 token 长文本 |
表4:多语言 GPTE 模型概览
表5:多语言 GPTE 训练数据概览
(8) 代码嵌入
- 早期:CodeBERT、GraphCodeBERT(结构+文本)
- LLM 时代:CodeLlama、DeepSeek-Coder → 直接做 Code Embedding
- 对比学习:UniXcoder、ContraBERT、CodeSage
表8:基于 CL 的代码嵌入模型
表9:代码嵌入的训练数据
04 三句话总结
- PLM 让文本嵌入从“专用”走向“通用”,现在正迈向“多模态+多语言+多任务”大一统。
- 数据合成 + 对比学习 + 大模型上下文窗口,是当前性能提升的三板斧。
- 下一步,嵌入模型需要“会推理、懂安全、能解耦”,而不仅是向量维度更高。
https://arxiv.org/pdf/2507.20783v1
On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey.....
#生成和理解多模态大模型发展到哪一步了?
本文将探讨到2025年年中,生成和理解统一的多模态大模型的发展趋势,特别是图片理解和图片生成一体的多模态大模型,揭示该领域的重要进展和挑战。
本文将结合之前阅读的论文和一些工业界的进展,谈谈到2025年年中为止,生成和理解统一的多模态大模型的发展概况。如有不当之处,烦请指出,我再更正原文。
当然更详细论文介绍可以refer我的系列笔记生成和理解多模态大模型、生成和理解多模态大模型之二等。
首先要说明的是,本文谈的“生成和理解多模态大模型”主要指图片理解和图片生成一体的多模态大模型,至于更多模态理解和生成的(俗称Omini-LLM)大模型就不在谈论之列了,原因是这一个方向的学术界论文相比“图片理解和图片生成一体的多模态大模型”来说还是显著少了。不过也可以推荐一些早期的论文,供大家参考,比如Google的Unified-IO和Unified-IO-2(这个系列的工作可以看作是Omini-LLM的早期代表作)、阿里的OFA、复旦的AnyGPT、meta的CM3Leon和Chameleon(多模态预训练)还有ANOLE、VITA等工作,这些工作其实也对后面的一系列工作有很大的影响,其中AnyGPT、CM3Leon、Chameleon和ANOLE也比较新了,所以也会介绍一下。
Unified-IO
Unified-IO 2
OFA
ANYGPT
CM2Leon
Chameleon
Anole
依照我之前阅读的论文,“生成和理解一体”的多模态大模型的研究主要集中在两个大方面:
- 训练一个适合于理解和生成任务的Visual Tokenizer,这样做的目的是大家发现视觉生成和理解所以来的视觉特征的特点是不一样的,视觉生成更依赖于偏高频、low-level的视觉特征,比如VAE-Based的特征,而视觉理解更偏向于偏高层语义的特征,比如CLIP、SigLIP等,不过一些早期的方法似乎不管这些,CLIP的视觉Encoder直接作为视觉生成的表征提取模型,不过后面就不是主流了。所以目前这方面的研究要么是 视觉生成和视觉理解特征分开提取 (比如DeepSeek的Janus、Janus-Pro),要么是训练一个 两种任务都适配的Visual Tokenizer ,比如字节跳动的Token-Flow、Muse-VL,港大的UniTok等,当然这一块也包含有 两个Visual Encoder 和 单个Visual Encoder 的。
- 构建一个适合于两种任务的多模态大模型结构,比如meta的meta-query、MetaMorph和Pisces、字节的Mogao和BAGEL等,包括自回归、自回归+扩散、纯扩散(目前还较少,可以参见字节的MMaDA)
下面来看一些典型的论文。
统一视觉Tokenizer
Dual Visual Encoder
首先来看字节的TokenFlow,其针对视觉生成和理解提供了不同的视觉Encoder:视觉理解侧用CLIP ViT-B/14-224/了ViTaminXL-256/SigLIP-SO400M-patch14-384提取适合于理解任务的高层视觉语义特征,而适合于生成任务的视觉特征则使用一个类似于Stable-Diffusion里面的VAE的Encoder的结构(确切来说是VQ-GAN,看代码可以确定)来提取low-level的视觉特征,两类特征在不同的Codebook里面去计算和Codebook的Embedding的距离,两类距离相加之后,再取argmax,得到的ID,作为两类特征的share的ID去各自的Codebook里面检索量化之后的特征,然后通过各自的Decoder,去做图像像素或者图像语义特征重建。
TokenFlow
字节的的另外一个团队的Muse-VL的操作类似,唯一的不同点是两种特征在dimension侧concat之后经过一个MLP映射,再做特征的离散量化。Semantic encoder用的SigLIP-SO400m-patch14-384和SigLIP-Large-patch16-256,Image Encoder用的SigLIP权重做初始化,这一点和TokenFlow也不一样。
Muse-VL
中山大学和华为联合提出的工作SemHiTok和Token-Flow、Muse-VL有异曲同工之妙,SemHiTok的特点是将语义特征重建和像素级图片重建任务结合起来,同时又解耦了Codebook,这样可以让Image Tokenizer同时具备提取高级语义特征(理解)和low-level特征(重建、生成)的能力。
SemHiTok
文中先是训练了一个Semantic-Priority Codebook(SPC),发现这样的语义特征在图片重建任务上质量比较差。
输入图片 经过语义编码器 (CLIP、SigLIP的Image Encoder)之后得到语义特征 ,量化bottleneck 将 量化到离散的特征空间 ,量化的公式化表达如下,

其中 是量化之后的特征在码本里面的index, 是量化之后的特征,会作为semantic decoder 的输入,得到 ,整个训练过程是 和 。
文中尝试将这样的特征作为LLaVA-1.5的输入,做图像理解任务,发现比未经过量化之前的、连续的图像特征效果差一些,但是也不赖,但是用到图片重建任务上,效果比较差。
文中就引入了层次化的Codebook即Semantic-Guided Hierarchical Codebook (SGHC)。
基于上面的步骤训练的semantic codebook即 ,pixel codebook为 ,每一个pixel codebook 和一个semantic codebook里面的code 对应。输入图片经过Pixel Encoder提取特征 ,基于semantic codebook的量化结果选择对应的Pixel codebook,然后对Pixel特征做量化,即

然后semantic和pixel方式量化得到的特征连接起来 ,作为Pixel Decoder 的输入,重建图片,
![]()
训练损失函数为,

这样Semantic Codebook和Pixel Codebook的训练是解耦的,避免了训练过程之中的冲突。一句话总结,就是semantic-encoder的量化结果引导pixel-encoder选择codebook然后做量化。
Single Visual Encoder
QLIP是UT Austin和Nvidia提出的工作,这个工作算是另辟蹊径,核心仍然是优化视觉理解和生成的Visual Tokenizer,只不过QLIP不是从视觉理解和生成特征的特性差异出发,而是转了一个弯:前面的工作这些高层语义特征其实一般是CLIP、SigLIP的视觉Encoder,都是经过视觉-文本预训练的,而我们的特征不管是视觉理解、还是视觉生成都需要作为LLM的输入,那么特征需要能和文本特征对齐,那么能不能让适合于视觉生成(比如VAE、VQ-GAN提取的视觉特征)和文本特征先做一个对齐呢,这样其实也算是让适合于图片生成的特征包含适合于视觉理解的语义信息了。而且真的是Unified Visual Tokenizer,因为无论是视觉理解还是视觉生成的特征提取都只用了一个Visual Encoder。
QLIP
训练的时候比较讲究,用到了两阶段的训练策略:
第一个阶段对Text Encoder、Visual Encoder、Quantizer和Visual Decoder进行训练,损失函数包括图片重建损失、量化损失和对比学习的Loss,这个阶段主要是优先学习语义丰富的特征表达,而不是视觉重建,所以也没有Perceptual Loss和Adversarial Loss,视觉特征量化方式为二进制球量化(Binary Spherical Quantization, BSQ)。
![]()
![]()

第二个阶段会着重提高图片重建质量并且恢复高频细节,这个阶段的损失函数为
![]()
港大、华科和字节的工作UniTok和QLIP其实做法有点儿类似,也是只有一个视觉Encoder,而且同时用作视觉生成和理解的特征提取器,只不过在训练的时候,用到了多个codebook的量化,而且和文本特征的对齐也是放在经过离散量化的视觉特征这儿,而不是Vision Encoder输出的特征。
UniTok
损失函数包括VQ-GAN的重建损失和对比学习损失函数,
Multi-codebook quantization (MCQ)的操作比较常见了(提高codebook利用率),具体操作如下,
视觉特征 在通道维度分为 个块 ,量化过程为:
是离散量化之后的特征, 是code index lookup操作, 是第 个sub-codebook,这种方式理论上增加了Codebook的Size,但是由于是每一个sub-codebook都会用到,所以利用率低和优化难问题会不明显一些。再看一下
再看一下Attention factorization,之前的VQ方法一般在特征量化之前和之后一般是用卷积层或者线性层做特征的维度升降,但是这个方法过于简单的,因此文中提出了一种attention的结构。
Atte Proj
基于UniTok的MLLM,文中用到了Liquid,有一些细节需要注意一下,UniTok把图片映射为 的Token ID,其中 表示有 个Sub-Codebook,在M-LLM输入侧,会把 个Embedding Merge起来得到一个Embedding,在预测的时候,则是一个视觉Token预测K个Code,这里是用了RQ-Transformer里面的Depth Transformer Head。
百川、西湖大学、浙江大学、上海AI Lab、上海创新中心和武汉大学提出的DualToken也是只用一个Visual Encoder提取适合于理解和生成任务的视觉特征,DualToken和TokenFlow、Muse-VL类的方法不一样,没有引入Vision Encoder和Semantic Encoder,而是使用了单一的Vision Encoder,其中底层的视觉特征用于图片重建,深层的视觉特征用于semantic对齐;相同的是针对语义特征和图片重建特征分别用了不同的Visual Codebook。
DualToken
在训练的时候,视觉Encoder的浅层特征(1-6层)输出的特征经过特征量化之后,送入视觉Decoder重建图片,而深层特征(26层)输出的特征则是经过量化(文中使用了残差量化RQ-VAE)之后,和不经过量化的特征进行对比计算损失。
DualToken LLM
在结合DualToken的LLM的模型中,sementic和pixel的视觉Token在通道维度concat在一起之后,和文本Token连接在一起,作为LLM的输入。在输出侧,用到了RQ-VAE里面的Depth-Transformer预测对应的Token,然后经过Visual Decoder解码出图片。
腾讯提出的TokLIP也是Single-Encoder的形式,VQGAN Encoder提取视觉特征之后,经过离散量化的特征经过一个Causal Token Encoder得到Semantic Feature,之后计算图片Semantic Feature的蒸馏Loss以及和文本特征的对比学习Loss。
TokLIP
TokLIP & MLLM
TokLIP Tokenizer包括VQGAN的encoder 、MLP和Causal Token Encoder ,输入图片为 ,得到的特征为 ,
损失函数包括文本-图片对比学习Loss和特征的蒸馏Loss,
TokLIP Tokenizer包括VQGAN的encoder 、MLP和Causal Token Encoder ,输入图片为 ,得到的特征为 ,
损失函数包括文本-图片对比学习Loss和特征的蒸馏Loss,
UniLip是北大、阿里和中科院提出的一个工作,把CLIP的Vision Encoder改造成了一个适合于生成和理解任务的Visual Tokenizer。
UniLip
Training Recipe
第一阶段的损失为:
第二阶段的损失为:
最后和MLLM以及DiT结构进行结合。和BILIP3O和MetaQuery一样,都用到了attention-pooling的方式得到DiT的条件Embedding,和BLIP3O不一样的事,MLLM输出的最后一层的Embedding也作为了DiT的条件Embedding输入。
MLLM结构和MetaQuery类似,包含 MLLM、扩散 Transformer、像素解码器、连接器和 个可学习Query。MLLM 采用 InternVL3 - 1B,Pixel Decoder采用了DC-AE,扩散 Transformer 为 SANA - 0.6B,Connector是 6 层 Transformer,与 InternVL3 - 1B 的 LLM 结构一致。
MLLM
图像生成与编辑训练的训练 分三阶段。第一阶段冻结 MLLM 和扩散 Transformer,仅在生成数据上训练connector 5 万步;第二阶段训练connector和扩散 Transformer,在生成与编辑数据上训练 20 万步;第三阶段在生成与编辑的指令微调数据上训练 2 万步。
.....
#马斯克将OpenAI和苹果告上法庭
指控ChatGPT垄断iPhone,自家Grok被打压
当地时间周一,马斯克向 OpenAI 和苹果「开炮」了!
据多家外媒报道,马斯克旗下 xAI 一纸讼书,控告它们通过 ChatGPT 和苹果 App Store 进行非法垄断。
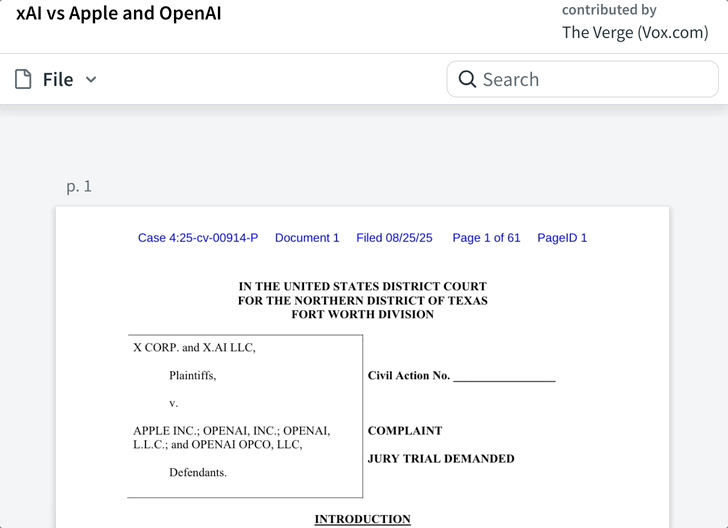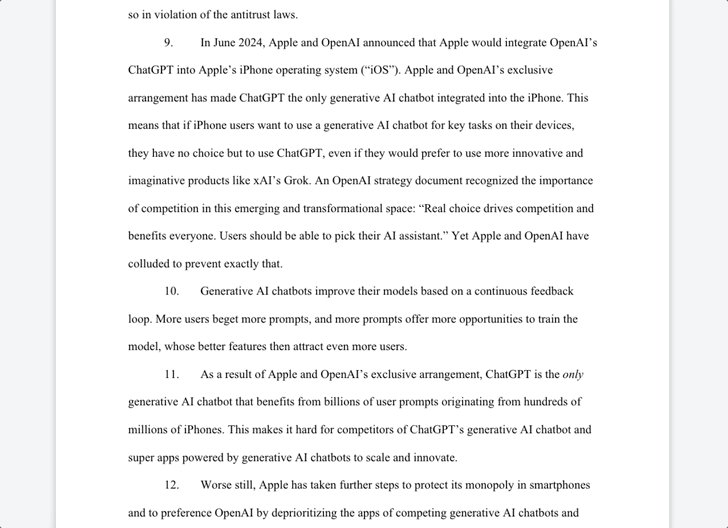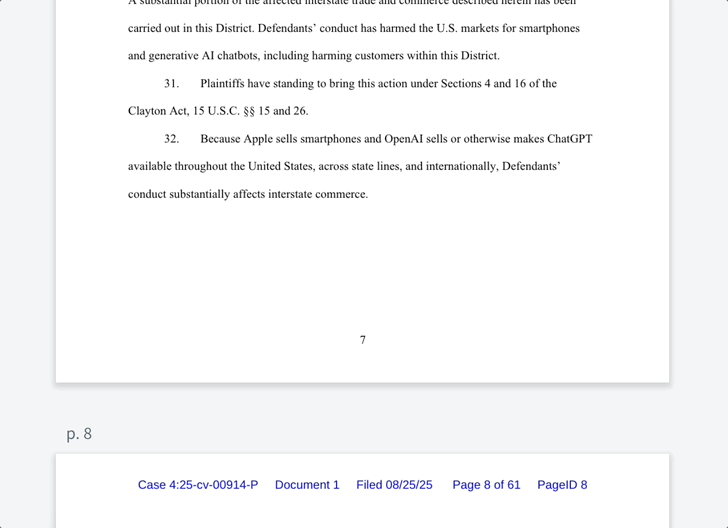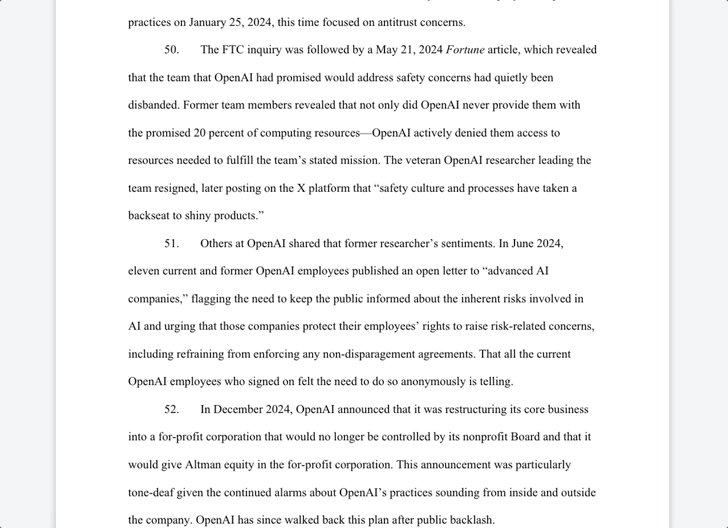
在一则推文中,马斯克表示,自家 Grok 有 100 万条评论,评论分高达 4.9,但苹果仍然拒绝在任何排名中将 Grok 列入其中。

xAI 指控 OpenAI 和苹果通过达成协议,将 ChatGPT 内置到 iPhone 中,从而扼杀 AI 行业的竞争。此外,苹果的 App Store 被指控「降低」了竞品聊天机器人和「超级应用」的优先级,包括 Grok 和 X。
我们搜索发现,在苹果 App Store 最新的免费 App 应用榜单中,「ChatGPT 排在首位,而 xAI 和 X 分别排在了 31 和 36 位。」


通过双方达成的协议,iPhone 用户「没有理由」下载第三方 AI 应用。苹果在启用 Apple Intelligence 时「强迫」他们使用 ChatGPT 作为默认聊天机器人应用。
正如 xAI 在诉讼书中所言,「苹果和 OpenAI 已经锁定了市场,并得以维持垄断地位,阻止像 xAI 和 X 这样的创新者参与竞争。」
诉讼书中还称,尽管 Grok 和 X 获得了很高的评分,但它们都没有出现在 App Store 官方的「必备应用」(Must-Have Apps)一栏中。而在 2025 年 8 月 24 日,该栏据称只有 ChatGPT 是唯一的 AI 聊天机器人。不过,搜索后发现,ChatGPT 也没有在其中。

除了以上诉讼之外,xAI 还指控苹果与 OpenAI 的合作关系为后者建立了「护城河」,毕竟苹果智能手机市场占有率方面称得上垄断。
诉讼书中指出,iPhone 集成 ChatGPT 让 OpenAI 获得了「可能数十亿条来自数亿台 iPhone 用户的提示」,从而获得了不公平的优势。
针对马斯克以及 xAI 的指控,OpenAI 发言人 Kayla Wood 在发给《The Verge》的邮件声明中表示,「最新的诉讼文件与符合马斯克一贯的骚扰模式」。
其实,本月早些时候,马斯克就曾指控苹果操纵 App Store 排名、偏袒 OpenAI,并威胁要对苹果采取法律行动。
他表示:「苹果的行为使得除 OpenAI 之外的任何 AI 公司都不可能在 App Store 排第一,这无疑是违规垄断行为。」

在当时,针对马斯克的指控,苹果回复称其 App Store「公平且不带偏见」。
面对马斯克与 OpenAI、苹果再起纷争,评论区看热闹的网友纷纷表示,「是时候推出 X Phone 手机了。」



xAI 诉讼书部分截图如下:
这场纷争的走向会如何,大家怎么看?
参考链接:
https://www.theverge.com/news/765171/elon-musk-apple-openai-antitrust-lawsuit
https://x.com/elonmusk/status/1960069756360560735
.....
#Speculating LLMs’ Chinese Training Data Pollution from Their Tokens
ChatGPT到底学了多少「污言秽语」?清华团队首提大语言模型中文语料污染治理技术
本文第一作者是清华大学博士生张清杰,研究方向是大语言模型异常行为和可解释性;本文通讯作者是清华大学邱寒副教授;其他作者来自清华大学、南洋理工大学和蚂蚁集团。
如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。
来自清华大学、南洋理工大学和蚂蚁集团的研究人员发现,GPT-4o/o1/o3/4.5/4.1/o4-mini 的中文词表污染高达 46.6%,甚至同时包含「波*野结衣」、「*野结衣」、「*野结」、「*野」、「大发时时彩」、「大发快三」、「大发」等色情、赌博相关词元(如下图所示)。
研究团队对 OpenAI 近期发布的 GPT-5 和 GPT-oss 的词表也进行了分析,它们词表的中文 token 没有变化。

图 1:GPT-4o/o1/o3/4.5/4.1/o4-mini 的中文词表污染高达 46.6%,主要涉及色情、赌博。
研究团队认为,这种现象是由于来自互联网数据的大模型预训练语料库不可避免地包含污染内容,导致在此之上构建的大语言模型(LLM)词表包含污染词。那么,这些污染词会如何影响 LLM 的性能?与污染数据的关系如何呢?
为了系统性研究 LLM 的中文词表和数据污染问题,研究团队首先定义和分类了中文污染词(Polluted Chinese tokens, PoC tokens),分析了它们对 LLM 性能的影响;其次,为了高效识别不同 LLM 词表里的 PoC tokens,研究团队设计了一个中文污染词检测模型;最后,通过中文词表污染有效估计数据污染,为污染数据治理提供轻量化解决方案。
- 论文标题:Speculating LLMs’ Chinese Training Data Pollution from Their Tokens
- 录用会议:EMNLP 2025 Main
- 项目网站:https://pollutedtokens.site/
值得注意的是,本项研究工作于 2025 年 5 月 29 日在清华大学基础模型学术年会上由邱寒老师首次分享,并提出针对 10T 级的大语言模型训练语料库的污染数据治理技术。
央视于 2025 年 8 月 17 日的新闻中也指出,AI 数据被污染存在风险。

中文污染词的定义、分类和危害
该研究首先组建了包含 6 名跨学科领域专家的标注团队(拥有哲学、社会学、中文语言学、计算机科学博士学位),对先进 ChatGPT 模型的中文词表进行污染词标注,总结出中文污染词的定义和分类,为后续研究打下基础。
定义:中文污染词(Polluted Chinese tokens, PoC tokens)是存在于 LLM 词表中,从主流中文语言学的角度编译了不合法、不常见、不常用内容的中文词(多于 2 个字)。
分类:中文污染词主要包括如下 5 个类别:
- 成人内容,例如「波*野结衣」。
- 在线赌博,例如「大发彩票网」。
- 在线游戏,例如「传奇私服」。
- 在线视频,例如「在线观看」。
- 奇怪内容,例如「给主人留下些什么吧」。
参照这种定义和分类,专家标注团队对先进 ChatGPT 模型的中文长词(共计 1659 个)进行标注,发现污染词有 773 个(46.6%),其中成人内容的污染词最多,足足有 219 个(13.2%)。
进一步,研究团队分析了中文污染词的危害,发现即使是最先进的 ChatGPT 模型(GPT-4o/o1/o3/4.5/4.1/o4-mini)在输入中文污染词后也会胡言乱语。如下图所示,ChatGPT 不能理解甚至不能重复中文污染词,输入一个中文污染词甚至会输出另一个中文污染词。

图 2:ChatGPT 不能理解甚至不能重复中文污染词,输入一个中文污染词甚至会输出另一个中文污染词。
如下表所示,与输入正常中文词相比,输入中文污染词会显著降低 ChatGPT 的回答质量,在解释和重复任务上有约 50% 的性能损失。

表 1:输入中文污染词会造成 ChatGPT 在解释和重复任务上约 50% 的性能损失。
为了初步解释这一现象,研究团队分析了开源预训练语料库(例如 mC4)中的中文网页,发现多种中文污染词聚集于一些网页的头部和尾部(如下图所示)。这些低质量语料使得 LLM 错误理解了不同中文污染词之间的相关性,且没有在后训练阶段被矫正回来,导致模型在推理时无法理解也无法重复中文污染词。

图 3:开源预训练语料库 mC4 的中文网页:中文污染词聚集于一些网页的头部和尾部。
污染检测:自动化识别中文污染词
为了将中文污染词的识别和分类扩展到更多的 LLM,研究团队微调中文能力强且污染较少的 GLM-4-32B,构建自动化中文污染词识别模型。
由于中文污染词通常是晦涩难懂的(例如「青青草」看似正常,但 Google 搜索结果与互联网色情平台有关),即使是中文语言学专家也无法判断中文词是否污染、属于哪一种污染类别。
因此,研究团队为识别模型设计网络检索机制,对每一个待检测中文词返回 10 条 Google 检索信息,作为判断是否为污染词的背景信息。并且,微调以专家标注结果作为真值标签,最终使模型达到 97.3% 的识别正确率。
如下图所示,研究团队用识别模型对 23 个主流 LLM 的 9 个词表进行了中文污染词检测。不只有先进的 ChatGPT 系列模型,中文污染词在其他 LLM 词表中也存在。其中成人内容、在线赌博、奇怪内容占了大多数。
然而,上一代 ChatGPT 模型(GPT-4/4-turbo/3.5)包含很少量的表征多个中文字的 token,其中却不包括中文污染词。

图 4:Qwen2/2.5/3 和 GLM4 的部分中文污染词。
污染追踪:由词表污染估计数据污染
由于词表污染是训练数据污染的反映,研究团队进一步设计污染追踪方案,通过 LLM 的词表反向估计训练数据的污染情况,为海量数据治理提供轻量化方案。
LLM 的词表构建大多基于 BPE 算法。简单来说,BPE 算法对语料库里的词频进行统计,并将出现频率越大的词放在词表越靠前的位置,即词 ID 越小。由词表污染估计数据污染即为对 BPE 算法做逆向,然而,逆向 BPE 的结果不唯一,因为一个词 ID 并不对应于一个确定的词频,只能给出词频范围的估计。
因此,研究团队结合经典语言学的 Zipf 分布和上下确界理论,在开源语料库上用分位数回归拟合出词 ID-词频的经验估计。
如下图所示,该经验估计有效拟合了词 ID-词频分布的上下界,并且落于理论上下确界之间,因此是一种有效的污染追踪方案。

图 5:词 ID-词频的经验估计有效拟合了分布的上下界,并且落于理论上下确界之间。
基于这种经验估计,研究团队估计了开源语料库 mC4 的数据污染,并与真值做比较。如下图所示,该估计方案对整体数据污染的估计是比较接近的,而对于具体污染类别的估计存在优化空间,这是因为具体污染类别的组分更少,其分布特征在海量语料库的统计中被削弱了。

图 6:开源语料库 mC4 的数据污染估计及与真值的比较。
进一步,研究团队估计了 GPT-4o 词表里出现的中文污染词「波*野结衣」在训练语料里的污染情况。结果显示,「波*野结衣」相关页面在 GPT-4o 中文训练语料的占比高达 0.5%,甚至是中文常用词「您好」的 2.6 倍。
由于 GPT-4o 的中文训练语料没有开源,为了验证这种估计,研究团队在无污染的开源数据集上按照 0.5% 的比例混合「波*野结衣」相关页面,并用 BPE 算法构建词表以模拟 GPT-4o 构建词表的过程。如下图所示,该比例几乎准确复现了 4 个相关词「*野」、「*野结」、「*野结衣」、「波*野结衣」在 GPT-4o 词表里的词 ID。

图 7:按照 0.5% 的比例混合「波*野结衣」相关页面可以在开源语料库上复现出 4 个相关词「*野」、「*野结」、「*野结衣」、「波*野结衣」在 GPT-4o 词表里的词 ID。
未来展望:污染数据是否百弊而无一利?
尽管污染语料会导致大语言模型的词表里混入「污言秽语」,那么污染数据是否百弊而无一利呢?哈佛大学于 ICML 2025 发表的文章《When Bad Data Leads to Good Models》指出,预训练中适量的污染数据可作为对齐模型的催化剂。
该研究基于如下图所示的理论假设:当预训练中有害数据过少时,有害表征会与其他表征混杂在一起,不易区分;反之,当有害数据适量时,有害表征更容易被区分。

图 8:预训练包含适量有害数据 vs 极少有害数据:前者更易区分有害表征向量。
进一步,研究团队按照 0-25% 不同有害数据比例预训练 Olmo-1B 模型,并在 inference 阶段识别并偏转有害表征,从而抑制有害内容输出。实验结果显示适量(10%)有害数据预训练的模型在应用抑制方法后的有害性最低,甚至低于不包含有害数据的预训练模型。
水至清则无鱼,适量的污染数据有助于模型的安全对齐。在促进安全对齐和预防过度污染间保持平衡,是未来的污染数据研究值得探索的方向。
总结
最新 ChatGPT 系列模型的《新华词典》里有 46.6% 都是「污言秽语」,并且输入这些「污言秽语」会让模型胡言乱语。基于这一现象,研究团队系统性给出了此类中文污染词的定义和分类,构建了中文污染词自动识别模型,并基于词表污染估计训练语料污染。综上所述,该研究期待为 LLM 海量训练语料的治理提供轻量化的方案。
.....
#DeepSeek V3.1惊现神秘「极」字Bug
模型故障了?
这个先进的 AI 为何会突然对一个汉字「情有独钟」?DeepSeek 最新的 V3.1 模型上线不到一周,就因一个离奇的 Bug 引发社区热议:无论任务是写代码还是整理物理试卷,模型总会莫名其妙地在文本中插入「极」字,甚至在自我修复时也无法幸免 。
上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。

经过这差不多一周时间的真实用户测试,DeepSeek-V3.1 却被发现存在一个相当让人无语的问题:其某些输出 token 会被随机替换为「极」。
具体来说,据知乎用户 Fun10165 描述,她在调用火山引擎版 DeepSeek V3.1 帮助整理一份物理试卷时发现,该模型的输出中会莫名出现一些「极」字。

图源:知乎 @Fun10165
而后面在 Trae 中测试 DeepSeek-V3.1 时也同样出现了这个问题。
有意思的是,她还尝试了调用官方 API 修复这个问题。结果,在修复的过程中又出现了这个问题。

图源:知乎 @Fun10165
她表示:「实测,官方网页 / API 能复现,概率不高,但多试几次就能出来。VolcEngine API 复现概率非常高。」
帖子下方,也有一些其他用户分享了类似的发现。
比如知乎用户「去码头整点薯条」分享说 R1 也存在类似的问题,他还简单猜想了原因:「使用 R1 0528 的时候就遇到了很多次,我观察到的现象更离谱,会在代码里面插入 “极客园”,而且遇到不止一次,怀疑是不是学习的时候吃进去了什么电子水印吃坏肚子了。」
知乎用户「琪洛」则发现 V3-0324 也存在类似问题,只不过这一次输出的是「极速赛车开奖直播」字符串。
![]()
图源:知乎 @琪洛
她猜想道:「怀疑可能数据没洗干净,即便重新训了 base 这个问题还是留下了,题主和其他回答所述「极」和「极速」可能就是这个词的残余痕迹。」
而在 Reddit 上,相关话题也正被热烈讨论中。
发帖者用户 u/notdba 表示,在测试 DeepSeek V3.1 时,他发现模型会莫名地在某些意料之外的位置输出如下 token:
- extreme (id:15075)
- 极 (id:2577)
- 極 (id:16411)
很显然,这仨都是同一个词。
他继续描述到,除了这 3 种「极」 token 在贪婪解码中成为首选的情况之外,这些「极」 token 也经常在其他意想不到的地方潜伏为第二或第三选择。
他说:「我已经对所有流行的编码模型都做过同样的评估,这是我第一次遇到这种问题。」
他的猜测是该问题可能会被 MTP(多 token 预测)掩盖,并且当推理堆栈不支持 MTP 时就会变得更加明显,比如 llama.cpp 就还不支持 MTP。这个猜想的合理之处在于支持 MTP 的 DeepSeek 官方 API 更不容易遇到这种情况,而第三方部署的同款模型则更容易出现这个问题。
用户 u/nekofneko 则分享了另一个案例:

图源:Reddit u/nekofneko
他给出的可能解释是:「极」的 token 是 2577,而省略号「...」的 token 是 2576。这两者可能被模型混淆了。
还不只是「极」,也有用户发现 DeepSeek-V3.1 还存在多语言混用的问题,u/Kitano_o 分享说:「我使用 3.1 从中文翻译成俄语时,遇到一些奇怪的行为。它开始混合多种语言 —— 添加英文词,也留下些中文词。有时这些问题会占到文本的 5%,有时只占 1%,甚至 0%。而且使用 OpenRouter 的不同提供商都会出现这个问题,即使我使用 DeepSeek 作为提供商也会。」

图源:Reddit u/Kitano_o
总体而言,对于 DeepSeek-V3.1 这个可以说相当严重的问题的原因,网友给出的猜测更多还是「数据污染」。
比如阶跃星辰黄哲威表示:「我认为是本身 sft 数据合成甚至是构造预训练数据的时候没洗干净引入了 “极长的数组” 这种怪东西(从 R1 的行为看,似乎大量使用了 RAG 方法来造难题的解答),然后 RL 的时候模型直接把这个字当某种终止符或者语言切换标记使用了。」

图源:知乎 @hzwer 黄哲威
他还提到:「其实推理出 bug,大概率都是数据问题,很多人都知道。只是 R1 的其它 bug 没有这么高频发生,社区不太关注而已。」
这次事件也给所有模型开发者敲响了警钟:在追求更高性能的 AI 模型时,最基础的数据质量,才是决定 AI 是否会「行为异常」的关键。
我们也把相关事件发送给了 DeepSeek 本尊,让它分析了一下可能的原因:

上下滑动查看
你遇到过这个问题吗?觉得可能的原因是什么?
请在手机微信登录投票
你觉得可能的原因是什么? 单选
数据污染
极与省略号出现 token 混淆
推理框架差异(MTP 问题)
以上都有
其它原因
.....
#Intent
清华辍学、斯坦福睡地板,华人小哥用AI社交挑战Meta,融资数千万美元
打造更聪明、更全能的社交。
大家都说,在国外,社交应用是 Meta 的天下。
但来自中国的一位小哥偏不信邪,他打造的一款 AI 原生即时通讯工具 Intent,广受好评。

小哥名叫 Brandon Chen,小小年纪经历不少,清华辍学,生物学专业却跨行搞起了社交软件开发,不懂英语却敢只身一人来到美国闯荡,还在斯坦福睡了一个学期的地板。至于为啥睡地板,Brandon 也没说原因。

据介绍,Intent 已经拿到了数千万美元融资。
我们再回到这个通讯工具 Intent,下面是操作展示。看完后,你可能觉得,这不就是微信那种社交软件吗?但如果你细细看就会发现不一样的地方:我们暂且把聊天对象命名为 ABC。
A 问:你们有我们仨昨晚的合照吗?
B 回:我没有,我只拍了张我和你的。然后上传了一张 AB 两人合照。
这时 C 回答:没关系,Al 可以把我们的照片合在一起…… 然后发了一张自己的美照。
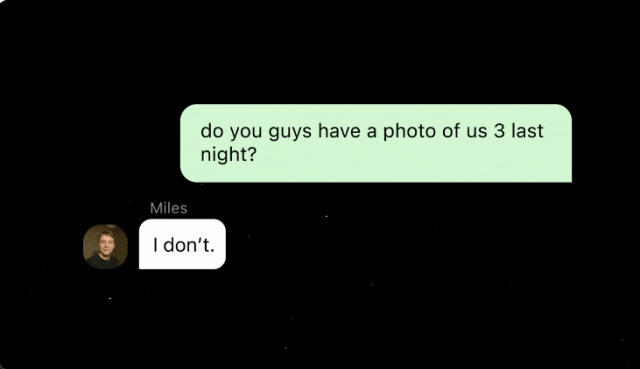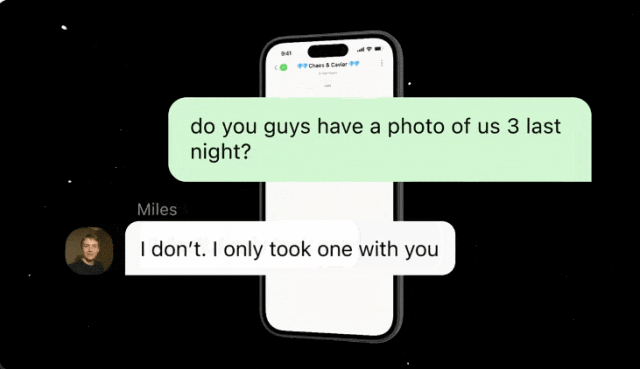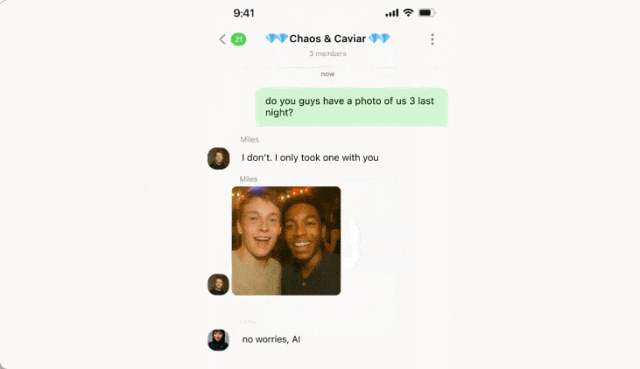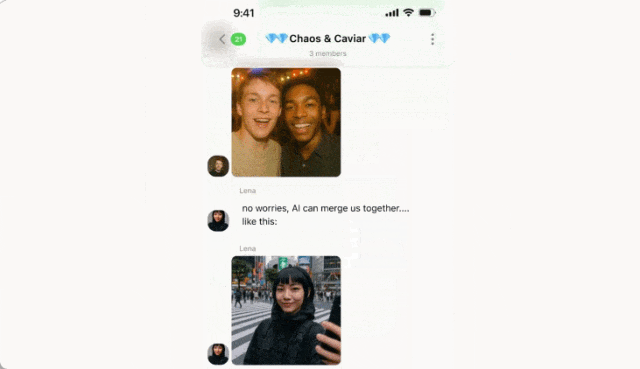
接下来就是魔法时刻,只见 AI 成功的捕捉了用户意图,将两张照片合二为一。
最后效果是这样的,看起来一点拼接的痕迹都没有。

你还可以继续提要求,把照片变成皮克斯风格:
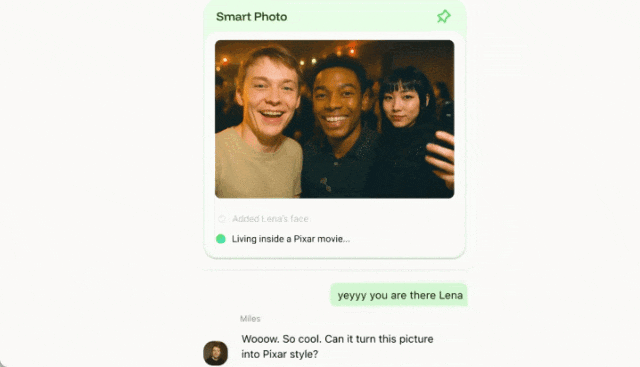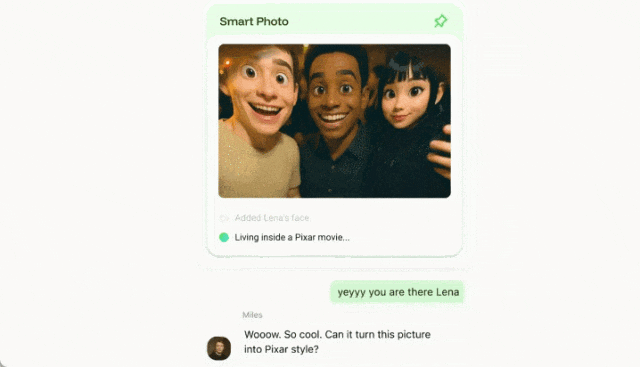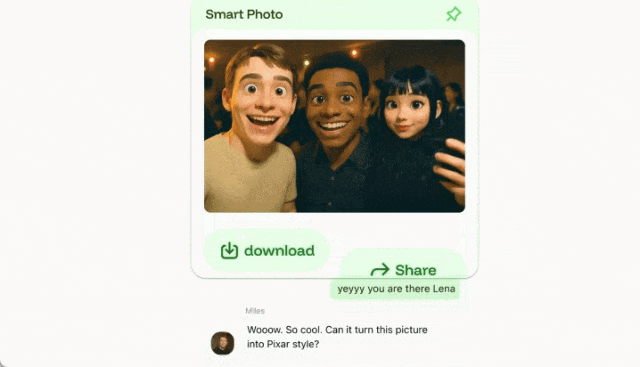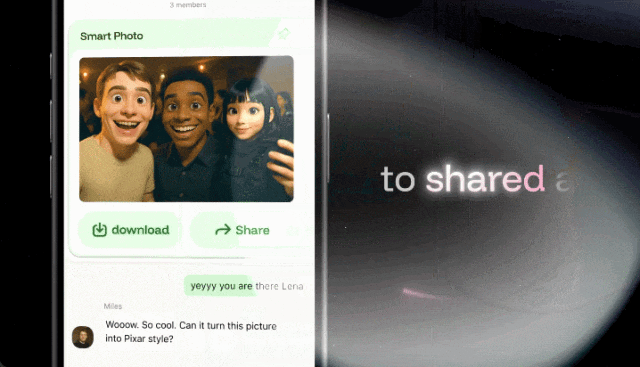
就这样,你也不用费劲的切换到修图软件,聊天过程就把图片给处理好了。
同样地,当规划旅行时,AI 自动识别聊天记录中的地址,帮忙预约车辆,并随着计划实时变动持续跟进调整。聊天过程我们同样用 ABC 代替:
A:我到机场了。
B:发了语音进行回复,AI 可以自动转录成文本(信息为来圣马特奥的枫木大道 1739 号,就在日本花园附近)。
C:我把地图位置发给你。
这时 A 回应,AI 会搞定一切。
确实,这个 AI 真的搞定了一切,它先是定位了一下起始位置:旧金山国际机场 → 圣马特奥枫木大道 1739 号。然后给出车程 15 分钟、7.4 英里。并且在自动打车后帮你比价,绝对不让你多花一分钱。
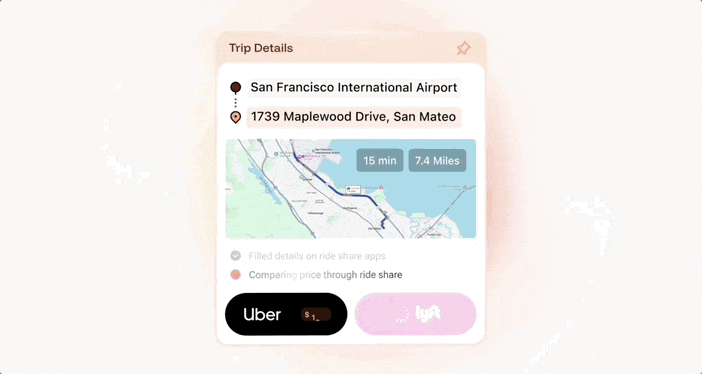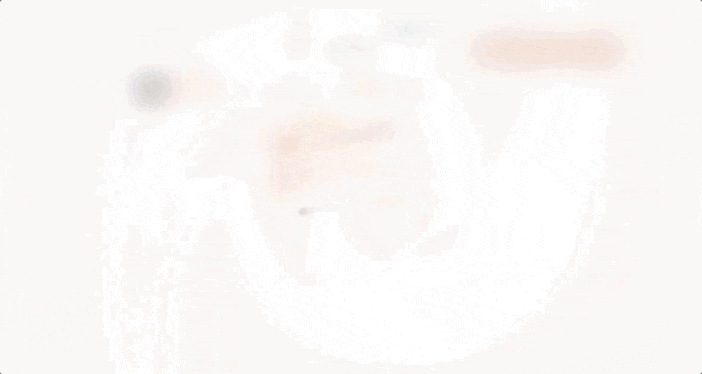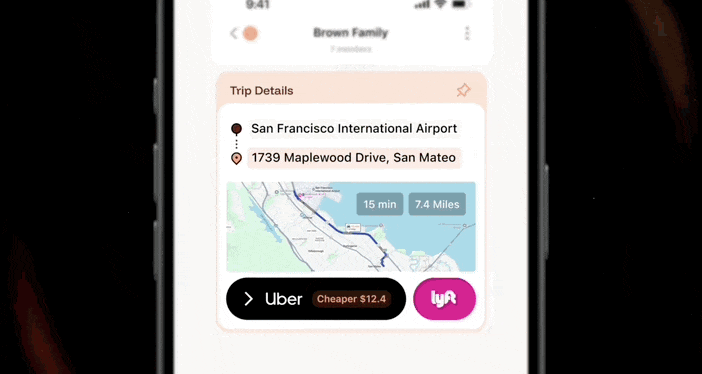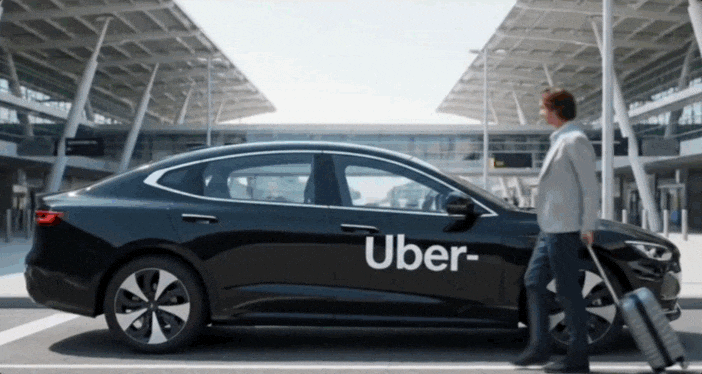
当集中采购时,AI 能在聊天界面直接生成共享购物清单。
A:想买点家具,矮一点的茶几,简约的。
B: 我还想要一个不是从 CVS (美国的一家药妆店连锁企业)买的垃圾桶。
如果想买的东西一多,就容易忘,这时,共享购物清单就发挥了重大作用:
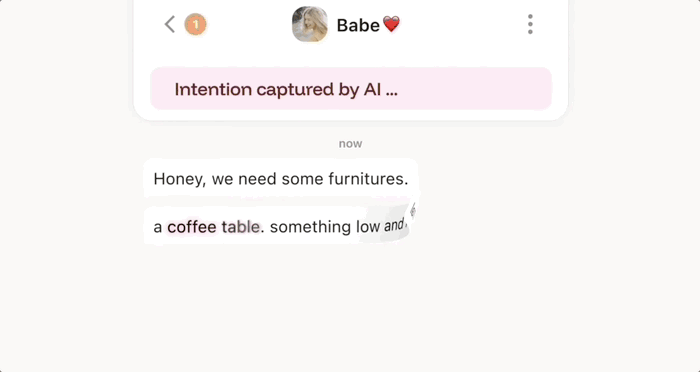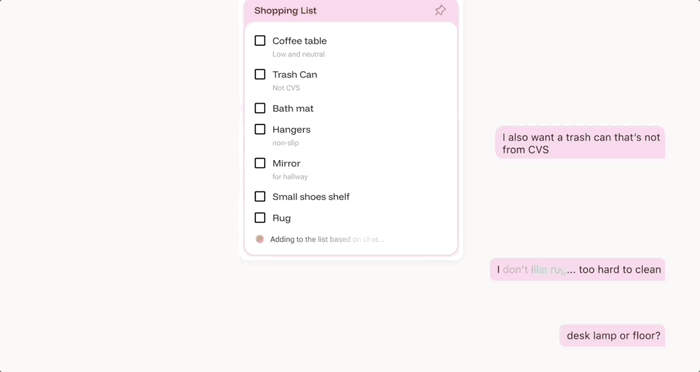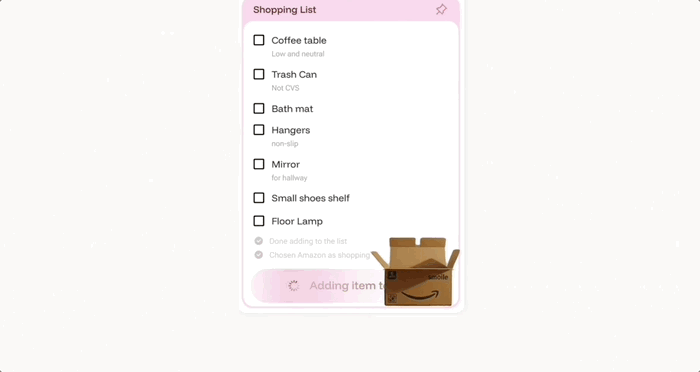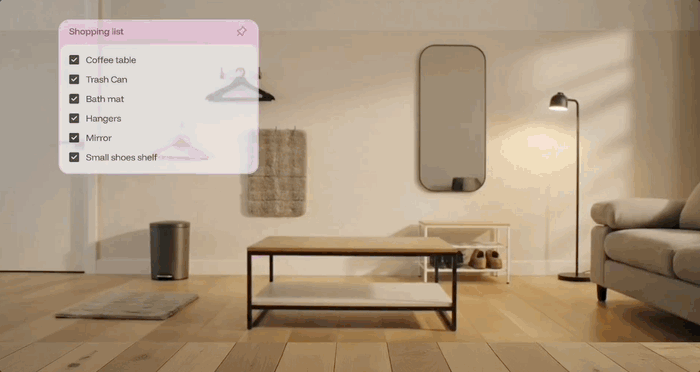
几个示例看下来,这款社交应用应该是把微信那种聊天功能以及大模型的自动执行功能结合起来了。如果你也想体验一下这种最新聊天方式,可以申请:
地址:https://intent.app/
Brandon Chen 简介
根据领英资料显示,Brandon Chen 自 2022 年 9 月共同创立了 Intent Inc.,并担任 CEO,旨在打造面向群体协作的 AI 原生产品,包括 atmealtime.com(2024)、riffo.ai(2024)和 moobius.ai(2023)。
通过 Intent,他正在打造一款 AI 原生的即时通讯工具,能够将意图无缝转化为结果。过程中,利用 AI 消除协作中的种种障碍。
在成立 Intent 之前,他还是 Ottor Game(一家游戏工作室,融资约 100 万美元,并获得了 Newgen Capital 和真格基金的支持)的联合创始人。


值得关注的是,他曾凭借生物奥赛金牌进入清华大学(学习生物),研究方向包括 DNA 折纸,并曾担任 2019 年 iGEM 团队的负责人。不过,他从清华肄业。
此后,他还在斯坦福大学呆过一段时间,期间意外上线了一个产品,收获 2600 名用户。

参考链接:
https://www.linkedin.com/in/brandonchen2000/?locale=en_US
https://x.com/brandonchen00/status/1960048494376636849
.....
#Jetson Thor
英伟达通用机器人芯片来了,AI算力提升7.5倍,宇树、银河通用已搭载
这是老黄给机器人们送上的礼物。

本周一,英伟达正式发布了旗下的新一代机器人专用芯片 Jetson Thor。与上一代 Jetson Orin 相比,新一代算力旨在大幅提升算力,以适配xx智能新算法,支持人形机器人等各种形态。
英伟达表示,Jetson Thor 搭载的最新 Blackwell 架构 GPU 的 AI 计算能力是上一代的 7.5 倍,最高达到 2070 FP4 TFLOPS,功耗 130W,能效是上一代的 3.5 倍。此外 Thor 的内存容量提升两倍达到 128G,显存带宽为 273GB/s。

所有这些新功能旨在解锁基于端侧的高速传感器数据和视觉推理,从而帮助人形机器人能够更好地自主观察、移动和做出决策。
更具体的配置如下:

Jetson Thor 专为生成式 AI 模型的推理打造,可支持下一代「物理 AI」智能体。这类智能体由大型 transformer 模型、视觉语言模型(VLM)及视觉语言动作模型(VLA)驱动,能够在端侧实时运行,最大限度地降低对云端的依赖。
在配套的软件栈上,Jetson Thor 的配套工具可满足实时应用对低延迟与高性能的需求,且支持所有主流生成式 AI 框架与 AI 推理模型,实时性能优势显著。这些模型包括 Cosmos Reason、DeepSeek、Llama、Gemini、Qwen 等通用模型,以及 Isaac GR00T N1.5 等机器人专用模型,开发者可以快速在本地开展模型实验以及运行推理。

英伟达表示,通过 FP4 精度与推测解码优化,Jetson Thor 的性能有望进一步提升。
Jetson Thor 还支持运行完整的 NVIDIA AI 软件栈,为几乎所有物理 AI 工作流加速,其覆盖的平台包括面向机器人的 NVIDIA Isaac、面向视频分析 AI 智能体的 NVIDIA Metropolis,以及面向传感器处理的 NVIDIA Holoscan。
在英伟达三个计算机解决方案的愿景中,DGX 负责在云端进行 AI 模型的训练,Omniverse 负责合成数据生成和仿真,而 AGX 则负责端侧 AI 的实际运行。Jetson Thor 的发布,可以说是为端侧的版图,换上了最新最强的算力。
Jetson Thor 产品包含开发者套件与量产级模组。其中开发套件 NVIDIA Jetson AGX Thor 包含 Jetson T5000 模组以及参考载板、电源和带风扇的有源散热器,目前已在公司网站上发售,起售价为 3499 美元(约合 2.5 万元人民币),NVIDIA Jetson T5000 模组的价格为千片以上 2999 美元(约合 2.14 万元)。

在xx智能兴起,机器人算法经历大规模革新的现在,英伟达提供的新算力早已受到大量厂商重视。此前在世界机器人大会,国内顶尖的机器人公司宇树科技、银河通用机器人等已经宣布将首发搭载英伟达最新的 Jetson Thor 芯片。银河通用的机器人 Galbot 就在大会上展示了一系列工业场景的应用。
联影医疗、万集科技、优必选、众擎机器人和智元机器人等国内公司也宣布将首批使用新一代端侧机器人算力。
在产品生态上,研华科技、Aetina、ConnectTech、米文动力、天准科技等硬件合作伙伴正打造成套的 Jetson Thor 系统;亚德诺半导体、e-con Systems、英飞凌、Leopard Imaging、RealSense、森云智能等传感器与执行器企业正在构建相应的传感器组件。
与此同时,面向自动驾驶汽车的 Nvidia Drive AGX Thor 也即将上市,现已开放预订,该套件预计将于 9 月开始交付。
在人工智能领域,英伟达不仅提供算力基础,还一直在有新研究出炉。本周一,英伟达研究人员提出 Jet-Nemotron,这是一系列新的混合架构语言模型,性能优于 Qwen3、Qwen2.5、Gemma3 和 Llama3.2 等先进开源全注意力模型,同时显著提高了效率 —— 在 H100 GPU 上生成吞吐量提高了 53.6 倍。

论文《Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search》,链接:https://www.arxiv.org/abs/2508.15884
本周三,英伟达即将发布最新一期季度财报,其在人工智能发展中的核心地位使其成为市场风向标。英伟达目前有 40% 收入来自 Meta、微软、谷歌、亚马逊等科技巨头,其云端 AI 芯片无处不在,但展望未来,英伟达正在押注机器人、自动驾驶等未来的万亿美元级市场。
今年 6 月,黄仁勋就表示,未来将是自动驾驶汽车、机器人和自动机器的十年。除了 AI 技术之外,机器人技术也将为公司带来最大的增长,两者结合起来代表着「数万亿美元的增长机会」。
不过,英伟达帮助人们构建 AI 的努力方向并没有改变。英伟达机器人和边缘人工智能副总裁 Deepu Talla 在昨天与记者的电话会议上表示:「我们不制造机器人,也不造汽车,但我们利用基础设施计算机和相关软件为整个行业提供支持。」
参考内容:
https://blogs.nvidia.cn/blog/jetson-thor-physical-ai-edge/
.....
#RollingEvidence
视频「缺陷」变安全优势:蚂蚁数科新突破,主动式视频验证系统RollingEvidence
近日,蚂蚁数科 AIoT 技术团队独立完成的论文《RollingEvidence: Autoregressive Video Evidence via Rolling Shutter Effect》被网络安全领域学术顶会 USENIX Security 2025 录用。
该论文提出了一套创新性的主动式可信视频取证系统,利用相机卷帘门效应在视频中嵌入高维物理水印,并结合 AI 技术与概率模型进行精准验证,能够有效抵御深度伪造(Deepfake)和视频篡改等攻击。相较于传统被动识别技术,该系统在检测准确率和安全防护能力上均有显著提升。
会议简介:USENIX Security 于 1990 年首次举办,已有三十多年历史,与 IEEE S&P、ACM CCS、NDSS 并称为信息安全领域四大顶级学术会议,也是中国计算机学会(CCF)推荐的 A 类会议,本届会议的论文录用率为 17.1%,被录用的稿件反映了网络安全领域国际前沿研究水平。
- 论文:《RollingEvidence: Autoregressive Video Evidence via Rolling Shutter Effect》
- 论文链接:https://www.usenix.org/conference/usenixsecurity25/presentation/qian
在深度伪造(Deepfake)与视频篡改日益泛滥的今天,真实性的边界正在被不断挑战。对此,蚂蚁数科 AIoT 技术团队提出了一项突破性创新 ——RollingEvidence,一种将 CMOS 摄像头 “缺陷” 转化为安全优势的主动式视频验证算法和系统。
它巧妙地利用相机卷帘门效应,在每一帧画面中实时注入滚动的条纹探测信号,就像为视频嵌入 “数字脉搏”。这些高维探测信息通过自回归加密机制动态演化,确保内容不可伪造、篡改可追溯。在验证端,深度神经网络与概率模型智能推断协同运作,对视频内容验证信息对齐,精准锁定异常帧。论文从理论证明、原型实现、大规模实验三个方面共同验证了其在视频真实性保障上的卓越性能。
整体方案
当前,摄像头设备已无处不在,其生成的视频证据在司法审判、公共安全及法律实务中发挥着关键作用。然而,随着 Sora、Pika 等 AI 视频生成技术和深度伪造(Deepfake)技术的持续突破,视频证据的真实性保障正面临严峻挑战。
本文提出 RollingEvidence 系统,这是一种通过自回归方式将物理探针与视频内容主动耦合的创新方案,可构建具备内在保护机制的视频证据。具体而言,在摄像过程中,我们通过动态调节 LED 设备产生人眼不可见的变频闪烁信号,结合相机逐行曝光的特性,将探针以条纹模式嵌入视频帧中。在验证阶段,我们开发了专用深度网络提取条纹特征并解码探针信息,进而基于指数最小蕴涵算法识别可能被篡改的帧。
通过理论分析、原型系统及大量实验,我们验证了 RollingEvidence 在生成和验证可信视频证据方面的有效性。该系统可广泛应用于公证认证、身份核验及司法取证等关键场景。

相机卷帘门效应
卷帘快门效应是指 CMOS 传感器采用逐行扫描方式曝光时,由于扫描时序与物体运动或光源频率不匹配,导致动态物体出现形变(如拍摄旋转风扇)或产生时域混叠现象(如拍摄闪电)。

(注:以上图片中的风扇和闪电等图片来自网络)
本研究创新性地利用这种时域混叠特性,通过自回归建模将验证探针嵌入视频信号中。


探针包的设计
在可见光通信(VLC)系统中,通常采用多周期发送、数据重传等策略来确保数据完整性和传输速率。而 RollingEvidence 系统专注于视频帧篡改检测,无需考虑通信传输问题,因此可以采用更紧凑的高维探针定义方案。具体实现上,我们采用带分隔频率的频移键控(FSK)技术,使用 16 种不同频率构建 4096 种探针组合(涵盖从单频到四频的所有排列组合)。


LED 调制频率设定
对于具有不同读出时间的相机,我们固定曝光时间并在设置阶段调整频率字典,以确保深度学习网络获得一致的条纹图案。

在原型系统中,L=16,w0=100,我们使用 16 种固定条纹宽度阵列,起始宽度为 100 像素,并以 5 像素为增量递增。为确定相机曝光时间,我们提出了关于条纹像素强度与曝光时间比例的上下界新发现:

即要维持与曝光时间 Te 成正比的高对比度(∝ Te)—— 这对可靠提取条纹图案至关重要 —— 工作频率必须保持在 1/2Te 以下。我们选择分隔频率因其独特性:在保持足够强度(∝ 2Te/3)的同时,提供更窄的宽度(≈34 像素)和相对更高的对比度(∝ Te/3)。

二阶段工作流程
RollingEvidence 采用随机采样编码技术,将紧凑的高维探针嵌入后续每一帧视频中,确保帧与帧之间、以及与设备加密密钥的关联性。在验证阶段,我们开发了专用的深度神经网络,用于提取条纹特征并解码探针信息,进而基于指数最小蕴涵算法识别可能被篡改的视频帧。同时,RollingEvidence 会生成去条纹化的视频版本,确保画面清晰可供人工查看。

自回归随机编码
在编码阶段,我们采用自回归模式。在摄像头端,视频流经过动态分割处理,生成一系列相邻窗口重叠一帧的窗口序列。对于每个新构建的窗口,都会生成一个随机序列作为对齐基准。该随机序列还与摄像头和 LED 的加密密钥相关联。我们会随机创建一个辅助 λ 序列,并应用指数最小采样法,根据相关窗口的随机序列来选择下一个探针。根据指数最小技巧,最小值运算会产生与多重分布相同的多项式分布,从而生成足够随机的观测值来防范潜在攻击。另一个重要含义是,我们的策略倾向于采样较大的随机值,这将用于识别被篡改的帧。

提取条纹的神经网络
录制完成后,系统进入验证阶段。我们采用批量解码而非逐频解调的方式处理探针:针对每一帧视频,首先提取条纹强度曲线,定位分隔标识并裁剪特征区域,最终解码获得探针信息。这一过程通过我们构建的新型深度神经网络实现。该网络以连续三帧为输入,在提取条纹强度曲线的同时,还能生成无条纹的视频版本。之所以能输出既清晰又真实的画面,关键在于 LED 调制图案以毫秒级速度切换,确保没有任何像素位置会在多帧中持续出现条纹遮挡。

基于此,我们提出了行注意力模块:一方面提升去条纹后的整体画面清晰度,另一方面帮助后续模块聚焦于亮度较高的图像行区域。

模式切分和探针解码
基于提取的光强度曲线,我们可以分割探针模式,随后通过预训练的分类神经网络从曲线模式中解码出探针信息。

篡改检测
在验证阶段,我们按照编码流程重建视频帧窗口及其对应的随机序列。针对每个帧窗口,我们评估其随机序列与从后续窗口提取的解码探针之间的匹配程度。根据以下公式递增窗口支持度:其中预定义参数 q 表示对均匀随机采样值特定分位数(如 98%)的显著性阈值。该方法可理解为针对指数分布的单尾检验。

篡改检测的性能表现
我们通过两组实验评估 RollingEvidence 的篡改检测性能:首组测试针对视频帧的插入、删除和修改操作,次组测试聚焦人脸替换与唇形同步检测。实验结果表明,该系统能准确识别大多数篡改行为,且不会对正常视频产生误判。

验证子模块的性能表现
我们同时评估了系统的验证子模块性能。测试涵盖 13 种室内场景和 3 种室外场景下的强度曲线提取与去条纹视频生成效果。左图为原始采集帧,中图为深度网络生成的去条纹帧,右图为基准真值。我们采用均方误差 (MSE) 评估条纹提取精度,以结构相似性 (SSIM) 衡量去条纹效果。实验表明:尽管存在背景和环境光照变化,深度网络提取的条纹特征仍与真实数据高度吻合,且去条纹处理效果优异。

总结
本研究提出了一种基于卷帘快门效应的防篡改视频录制系统,创新点包括:1) 在物理层嵌入防篡改探针;2) 采用自回归编码方案,利用前序帧和设备密钥生成高效探针;3) 设计多任务深度网络,提取条纹模式、解码探针并检测篡改;4) 实现原型系统,并通过实验验证了 RollingEvidence 框架的高效性和安全性。
.....
#一天之内,Meta痛失两员大将,小扎钞能力失效?
一亿美元能买一栋别墅,但买不了梦想?
最近,Meta 内部发生了一些有意思的事情 —— 一边是扎克伯格动辄上亿美金薪资招兵买马,高调组建超级智能团队;另一边是一些老员工宣布开启新的「冒险之旅」,转投其他 AI 公司。

今天,有两位资深研究者宣布离开 Meta,一位是专注于强化学习的 Rishabh Agarwal(去向未定);另一位是已经在 Meta 工作了 12 年、参与了 PyTorch 构建的 Bert Maher(确定加入 Anthropic)。
看来,除了小扎挖不到的人,还有一些他留不住的人。甚至有人嘲讽「钱买不到顶级研究员」。

不过,还有很多选择离开的人,可能是因为钱没给够。在超级智能实验室成立之后,Meta 内部的待遇差距多次引发争议。
前 Meta 研究员 Rohan Anil(现 Anthropic)曾发帖称「非超级智能研究者待遇次等,像巨型社会实验」。

有人认为 Meta 内部薪资差距(同事赚 1-2 亿美元)会杀死工作动力,导致更多离职。

当外部挖不来真正的梦想家,内部又因分配不均而人心浮动,这背后折射出的,可能是比薪酬更深层的结构性问题。
这让一些人联想到了「90 年代的微软」,即由一位权力集中的创始人 CEO 主导一个宏大到几乎吞噬公司一切资源的项目。

这种模式正在导致严重的内部管理失衡和人才流失,若再无一位强力的 CTO 来分担和制衡,那巨大的压力可能会压垮这位明星 CEO。
他们正在离开 Meta
Rishabh Agarwal
为「钱也留不住」这一论点提供佐证的,便是顶级 AI 研究员 Rishabh Agarwal。 他最近宣布将离开 Meta,开启新的职业篇章。

他提到,虽然 Meta 的 Superintelligence 实验室提供了诱人的机会,但他遵循 Mark Zuckerberg 的建议:「在一个变化如此之快的世界中,你承担的最大风险就是不冒任何风险。」。用小扎的话拒绝小扎,可以说是以子之矛攻子之盾了。
Rishabh Agarwal 的职业生涯横跨多家顶尖 AI 研究机构。他曾在 Google Brain 和 DeepMind 担任资深研究科学家,奠定了其在强化学习领域的声誉。之后,他加入 Meta AI,领导 Llama 团队的强化学习与推理研究。

Google Scholar 数据显示,Rishabh Agarwal 被引量破万。
在 Meta 期间,Rishabh Agarwal 推动了「思维模型」后训练研究的前沿,特别是在强化学习和合成数据应用方面。他的主要贡献包括:
- 通过强化学习(RL)扩展技术,将一个 8B 参数的密集模型性能提升至接近 Deepseek-R1 的水平。
- 在训练中期使用合成数据,为强化学习(RL)提供「热启动」(warm-start)。
- 开发了更优的同策略(On-Policy)蒸馏方法。
学术上,他在 Mila 取得了博士学位,师从 Aaron Courville 和 Marc Bellemare,其研究成果曾荣获 NeurIPS 杰出论文奖,同时他还担任麦吉尔大学的兼职教授。

关于他的下一步动向,外界猜测他可能会创办个人项目或加入一家新兴的 AI 初创公司。
不过也有人质疑这是否真的是「风险」,认为以他的背景,无论项目成败,他都能迅速加入顶级实验室。

当然也有一些「幽默」的祝福。

Bert Maher
Meta 失去的另一位人才,是在此工作了 12 年之久的元老 Bert Maher。 他最近也宣布,将结束在 Meta 的职业生涯,并加入 Anthropic 的推理团队。

在 Meta 期间,他参与了多个重要项目,专注于优化编译器和机器学习基础设施的开发。
- HHVM(HipHop 虚拟机) 是 Meta 开发的一个高性能虚拟机,最初用于加速 PHP 代码的执行,后来扩展支持 Hack 编程语言,Bert Maher 参与了优化编译器的工作。
- ReDex 是 Meta 开发的 Android 应用程序优化工具,专注于通过重新打包和优化字节码来提高应用的性能和效率。
- PyTorch 是一款广受欢迎的开源机器学习框架,广泛用于深度学习研究和部署。Bert Maher 在 PyTorch 团队中工作,尤其是在编译器方面做出了贡献。
- Triton 是一个由 OpenAI 和其他社区共同开发的开源深度学习编译器框架,旨在优化 GPU 上的张量计算。

评论区也纷纷送出祝福。


为什么 Meta 总是留不住人?
在 AI 公司,人员的频繁流动是非常正常的事情,但我们也注意到有两个极端:一个是 Anthropic,去年的员工保留率高达 80%,居行业之首;另一个则是 Meta,仅为 64%。

种种信息显示,Meta 的这一数字和管理文化脱不了干系。
早在 2022 年,VR 大神 John Carmack 离开 Meta 的时候就控诉公司存在愿景空洞、资源利用率极低等问题,直言公司坐拥「可笑的巨量资源」却产出甚微,整体效率仅为其预期的 50%。

2025 年,这种「血泪控诉」再次上演。前 Meta 研究科学家 Tijmen Blankevoort 离职后发了一封 2000 多字的控诉书,指出 Meta 在管理方面存在以下问题:
- 绩效评估与强制裁员(5% 末位淘汰)导致全员陷入「生存恐慌」,工作动力从「AGI 使命」异化为「避免被解雇」,催生抢功劳、截胡项目等内斗行为。
- CTO(Reality Labs)与首席产品官(生成式 AI)各自为政,资源争夺取代协作;FAIR 实验室(基础研究)因长期导向被边缘化(GPU 资源匮乏)。
- 天价挖人可能引发「新老派系冲突」,FAIR 和生成式 AI 部门因资源倾斜面临新一轮裁员,老员工士气崩塌。
- 新引进的超级智能团队负责人领导能力受质疑。
这份控诉书发酵后,Meta FAIR 研究科学家朱泽园评论说,Tijmen Blankevoort 公开的内部文化批评「基本属实」,而他其实还有很多补充,比如甚至遇到过现实版「农夫与蛇」的经历,不过这些故事只能等离职后才能说出来。
这些管理问题的存在不仅让 Meta 内部军心涣散,也让一些原本有可能加入新超级智能团队的顶级研究者望而却步。
只有金钱买不来顶级 AI 研究者
目前看来,被扎克伯格成功挖走的研究者可以列出一长串,不为所为的其实也可以列出一长串:
- Ilya Sutskever:拒绝出售 Safe Superintelligence 给 Meta。
- Mira 创办的 Thinking Machines Lab 团队:公司拒绝被 Meta 收购,全员拒绝被 Meta 招募。
- Anthropic:员工拒绝 Meta 邀约,公司表示不会因外部高薪妥协公平薪酬原则。
- Perplexity AI:Meta 针对该公司的潜在收购谈判破裂,针对该公司 CEO Aravind Srinivas 的招募被拒绝。
- OpenAI 的 Noam Brown:拒绝被 Meta 招募。
- OpenAI 的 Mark Chen:拒绝邀约,表示在 OpenAI 很开心。有趣的是,此前,Chen 曾在一次闲聊中建议扎克伯格加大人才投入。
- Google AI 架构师 Koray Kavukcuoglu:拒绝被 Meta 招募。
- ……
这些拒绝 Meta 的人,往往都和 Meta 有着愿景、使命和管理文化上的分歧。
具体来说,Meta 追求速度和规模化超智能,关注的是如何盈利以及大模型之间的竞赛,而这些人更强调安全、独立、基础研究或长期主义。
对许多顶尖研究人员和创业者而言,加入 Meta 意味着屈服于其文化 —— 以及扎克伯格的价值观 —— 而这些往往与他们自身的价值观相悖。对于 Sutskever 或 Murati 这类离开 OpenAI 以追求更道德、更负责任的人工智能方法的人物来说,再多的金钱也无法弥补这种妥协。
再者,使命感的缺失让很多人无法说服自己。
比如特斯拉高级工程师 Yun-Ta Tsai 提到,在收到 Meta 邀约时,他正忙于推出 Robotaxi,以及对可持续富足的奉献。「再多的钱也无法让我离开埃隆。这是一生一次(可能是史上唯一)的机会。我喜欢在艰苦的环境中工作。没有目标的赚钱会让我发疯。」「金钱买不到使命感」。
最后,即使是看在「钱」的份上,从长期来看,不少人在其他 AI 公司未必就拿不到扎克伯格许诺的数字。毕竟,AI 人才的含金量已经摆在那里。
对这些人来说,选择留在原地、坚持自我,远比跳槽到一个资源最丰富但缺乏灵魂认同的实验室更有意义。
如果是你,你会选丰厚的待遇,还是那份让人热血沸腾的使命感?
参考链接:https://www.businessinsider.com/meta-ai-talent-war-superintelligence-push-tension-desertion-2025-8
.....
#谷歌偷偷搞了个神秘模型Nano-Banana
实测:强到离谱,但有3大硬伤
神秘AI模型Nano-Banana火了,冒出一堆假网站,李鬼和李逵傻傻分不清。
最近,AI 社区又冒出一个神秘的图像生成和编辑模型,名叫 Nano-Banana。
起初它在 LMArena 平台的「Battle」模式中被发现,但未在公开排行榜上列出,也没有官方开发者明确声称其归属。
不过很多网友循着蛛丝马迹,猜测这可能是谷歌的研究模型。
上周二,谷歌 AI Studio 产品负责人 Logan Kilpatrick 在 X 上发布了一个香蕉表情符号。

谷歌 DeepMind 产品经理 Naina Raisinghani 也发布了一张与意大利艺术家 Maurizio Cattelan 2019 年创作的胶带粘贴香蕉艺术作品类似的图片。

再加上谷歌过去曾将其较小的模型称为「Nano」,而且其生成图像的质感与 Google 的 Imagen 或 Gemini 系列相似。

以上种种,似乎都在暗示它出自谷歌之手。
该模型不仅在文本编辑、风格融合和场景理解等方面表现更优,还可以上传两张图片、输入提示词将其中的元素融合。
比如,上传一摞书和卧室床头柜的图片,输入提示词「Flip stack of books to be upright and put on table between two bookends.」
它能精准理解复杂文本提示,将横放的三本书立起来,并加上书挡摆放到柜子上。

上传一张模特照再加上一张棒球帽子图,输入提示词:「Put the baseball hat on the woman.」
棒球帽上有着复杂的文字和图案刺绣,Nano-Banana 编辑后的图片保留了帽子上的所有细节,同时光线、视角和构图也能一致性。

在产品照片、场景搭建图、广告等商业场景下,Nano-Banana 的表现也稳得一批。

当然,它也并非完美无缺,在某些情况下,Nano-Banana 生成的图像可能出现反射、光照逻辑或物体位置不一致等视觉问题,人物的手指也偶尔出现畸形的情况。
如果细看上图中生成的书籍,就会发现其中的瑕疵:书名出现了「鬼画符」。

由于尚无官方 API 或正式的官网链接,我们只能通过 LMArena 随机体验该模型。
换句话说,每次都得靠运气才能遇到 Nano Banana,体验很不稳定。
更搞笑的是,网上出现了一堆假网站,声称提供 Nano Banana 服务,让不少网友李鬼和李逵傻傻分不清。
Nano-Banana 一手测评
我们也来了个一手测评。
打开 lmarena 官网,选择 Battle 模式,可以直接输入提示词进行文生图,也可以上传图片、输入提示词再进行 AI 编辑。
官网链接:https://lmarena.ai/
页面会出现两个匿名模型同时生成图片,只有当我们选出其中生成质量最好的一张图片时,平台才会亮出对战双方的身份。

先来试试文生图效果。
我们输入同样的提示词:Present a portrait-style image in a Polaroid photo shoot style. In the picture, there is a makeup artist with long, loose curly hair, wearing oversized clothing. She has a delicate face and exudes a casual vibe, posing with a peace sign directly at the camera, creating an ultra-free atmosphere. The image has a slight grainy texture, with vibrant and captivating colors,1:1.
第一幅是 Nano Banana 的「作品」,第二幅是 ChatGPT 生成的效果。前者生成的图片背景中有杂乱的眼影盘、指甲油等,更符合提示词中的「化妆师」身份,而且人物的动作、服装细节更自然,手部也没有明显的瑕疵;而后者背景较为单一,大拇指也有些虚化。


左右滑动查看更多
再来试试它的图片编辑功能。
上传一张旧金山阿拉莫广场的野餐照片,输入提示词:Add some humanoid robots in the park,make them blend with the environment.
乍一看我们还以为 Nano Banana「罢工」了,直到在画面右侧找到了一个正在走路的类人机器人,它完全融入环境,毫无违和感。


左右滑动查看更多
我们上传一张人物摄影照片,让 Nano Banana 进行逆向工程描绘其创作过程。
提示词:Show the set being set up before, the model is sitting up scrolling her phone, there is a woman behind the model fixing her hair, a man up on a ladder, hanging the curtain in the background, revealing the studio behind it.


左右滑动查看更多
有网友用 Nano Banana 让碧梨和迈克尔・杰克逊跨时空自拍:

我们也尝试了下。上传马斯克和奥特曼的照片,输入提示词:The two people are happily taking a selfie.
Nano Banana 确实生成了一张自拍照,马斯克的形象、动作也几乎找不出什么问题,只是奥特曼大变样。

为了不「冤枉」它,我们又给了它一次机会,Nano Banana 还是翻车。

难度继续升级。上传小扎、马斯克肖像照和一张风景照,让 Nano Banana 把两个人自然地放在图三中。
Gemini 2.0 flash 生成的效果完全认不出这两个大名人,而 Nano Banana 将二人完美融入图三环境中,不过手指等细节方面还是有瑕疵。

进阶玩法
如果把 Nano-Banana 和谷歌的 Veo3 结合在一起,会碰撞出怎样的火花?
@a16z 合伙人 Justine Moore 就搞了个新工作流,用于制作较长的视频。
下面这个视频是一个游戏或电影中的潜行任务场景,角色从昏暗的博物馆中盗取一幅名画,触发了激光警报。
,时长00:20
她还放出了制作教程。提取第一个视频片段的最后一帧,将该帧上传到 lmarena 上的 Nano Banana,提示生成下一个场景,例如「角色转向走廊」,然后将新生成的帧用 Veo 3 进行动画制作。

X 网友 @ZHO_ZHO_ZHO 则发现了 Nano-Banana 另一种好玩的用法 —— 把插画变成手办。
上传一张图片,输入提示词:turn this photo into a character figure. Behind it, place a box with the character’s image printed on it, and a computer showing the Blender modeling process on its screen. In front of the box, add a round plastic base with the character figure standing on it. Make the PVC material look clear, and set the scene indoors if possible.

据该博主测评,Nano-Banana 生成的图几乎没有 AI 味,五官和细节都保留得很好,真实感十足。
然后再用 Veo3 将其制作为 8 秒视频。提示词:Pick up the figure with both hands and show it from all angles.
,时长00:08
底下评论区不少网友也按照上述工作流整活。比如哪吒双手抱拳的:
,时长00:07
还有哆啦 A 梦的,正面看哆啦 A 梦的尾巴挺正常,但转个身就大变样:
,时长00:07
我们也复刻了下,上传一张 Q 版插画图片,输入以上提示词。

效果如下:

最后打开 Gemini 2.5 Pro,选择 Video,上传生成的图片,输入提示词,静待 1 分钟左右,就能得到一段 8 秒视频。
,时长00:07
上周末,谷歌 Veo 3 对所有 Gemini 用户免费开放,供其体验 AI 视频生成功能。
不过,这项免费体验活动只持续到太平洋时间 8 月 24 日晚上 10 点(北京时间 8 月 25 日上午 1 点) 。在此期间,免费用户每天最多可以生成 3 个 8 秒的视频片段,每个视频都包含自动生成的音频。
通常,Veo 3 的视频生成功能仅对 Google AI Pro 或 Ultra 订阅用户开放。Pro 用户每天可生成 3 个视频,而 Ultra 用户的配额为 10 个视频。
感兴趣的朋友也去体验一波吧。
https://x.com/ginacostag_/status/1959234207127134340
https://x.com/venturetwins/status/1957155767888548160
https://x.com/techhalla/status/1959186906115354692
https://x.com/ZHO_ZHO_ZHO/status/1958550998815023573
.....
#FlashAttention-4
FlashAttention-4震撼来袭,原生支持Blackwell GPU,英伟达的护城河更深了?
在正在举办的半导体行业会议 Hot Chips 2025 上,TogetherAI 首席科学家 Tri Dao 公布了 FlashAttention-4。

据介绍,在 Backwell 上,FlashAttention-4 的速度比英伟达 cuDNN 库中的注意力核实现快可达 22%!

在这个新版本的 FlashAttention 中,Tri Dao 团队实现了两项关键的算法改进。
一、它使用了一种新的在线 softmax 算法,可跳过了 90% 的输出 rescaling。
二、为了更好地将 softmax 计算与张量核计算重叠,它使用了指数 (MUFU.EX2) 的软件模拟来提高吞吐量。
此外,FlashAttention-4 使用的是 CUTLASS CuTe Python DSL,其移植到 ROCm HIP 的难度要高出 10 倍,而 CUDA C++ 移植到 ROCm HIP 则更容易。
有意思的是,Tri Dao 还宣布,在执行 A@B+C 计算时,对于 Blackwell 上在归约维度 K 较小的计算场景中,他使用 CUTLASS CuTe-DSL 编写的核(kernel)比英伟达最新的 cuBLAS 13.0 库快不少。而在标准矩阵算法 A@B 时,两者速度总体是相当的。



据介绍,他的核通过使用两个累积缓冲区来重叠 epilogue,从而击败了 cuBLAS。
Semi Analysis 表示,像 Tri Dao 这样的开发者是 CUDA 护城河的核心优势之一,因为 Tri Dao 只使用英伟达 GPU,并将其大部分核开源给其他英伟达开发者群体。Tri Dao 等研究者均不使用 ROCm AMD GPU 或 Trainium 芯片。
这对于 AMD 等来说可不是好消息,假如 AMD 希望 Tri Dao 和他的团队在 ROCm 上实现算法突破。那么,它就应该为 TogetherAI GPU 云服务上的 AMD GPU 提供优惠支持。Semi Analysis 分析说:「谷歌为 Noam Shazeer 支付了 27 亿美元,Zucc 为 OpenAI 工程师支付了 1 亿美元,AMD 拥有足够的现金,可以为 TogetherAI/Tri Dao 支付 5000 万美元来启动 ROCm 生态系统。」
FlashAttention 最早由 Tri Dao 等人在 2022 年提出,论文标题为《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》。
论文地址:https://arxiv.org/pdf/2205.14135
其背景是传统的注意力机制因需生成 N×N 的注意力矩阵,在序列长度 N 增长时引发二次的(quadratic)时间和内存开销。
而 FlashAttention 强调「IO-awareness」,不再将注意力矩阵完整载入,而是通过「tiling+softmax rescaling」策略,将数据块临时存入高速缓存(SRAM),在内部积累,再写回高带宽内存(HBM),避免了大量读写开销,内存复杂度得到显著降低 —— 从 O (N²) 降至 O (N)。

如图所示,在左图中,FlashAttention 使用了 tiling 技术来防止在(相对较慢的)GPU HBM 上执行很大的 𝑁 × 𝑁 注意力矩阵(虚线框)。在外层循环(红色箭头)中,FlashAttention 循环遍历 K 和 V 矩阵的块,并将其加载到快速片上 SRAM 中。在每个块中,FlashAttention 循环遍历 Q 矩阵的块(蓝色箭头),将其加载到 SRAM 中,并将注意力计算的输出写回 HBM。
在右图中,可以看到相比 GPT-2 上 PyTorch 注意力实现,FlashAttention 速度更快 ——FlashAttention 无需将大型 𝑁 × 𝑁 注意力矩阵读写到 HBM,从而将注意力计算速度提升了 7.6 倍。
整体上,初代 FlashAttention 带来的增益也很显著:在 BERT-large(序列长度 512)中相比 MLPerf 基线提升训练速度约 15%;GPT-2(序列长度 1K)提升约 3 倍;在 Long-Range Arena(序列长度 1K–4K)提升约 2.4 倍。
一年后,FlashAttention-2 问世,这一次,作者仅 Tri Dao 一人。顺带一提,他还在这一年的晚些时候与 Albert Gu 共同提出了 Mamba。

论文地址:https://arxiv.org/pdf/2307.08691
其改进的焦点是:FlashAttention 已显著提升性能,但在 GPU 上仍存在低吞吐率的问题,仅能达到理论峰值很低的比例(约 25–40%)。
为此,Tri Dao 提出的解决策略包括:
- 工作划分优化:重新设计分块策略与线程分配,提升并行效率,增加硬件利用率;
- 减少非矩阵运算,加快整体执行;
- 支持更大 head size(至 256) 及多查询注意力(MQA) 和分组查询注意力(GQA),适配更多模型架构需求。

结果,相比初代 FlashAttention,FlashAttention-2 速度提高约 2–4×;在 A100 GPU 上 FP16/BF16 可达到高至 230 TFLOPs/s,达 PyTorch 标准实现 9 倍速度提升。参阅xx报道《比标准 Attention 提速 5-9 倍,大模型都在用的 FlashAttention v2 来了》。
又一年,FlashAttention-3 诞生,这一次改进的重点是适配 Hopper 架构,异步与低精度。可以看到,Tri Dao 这一次的名字挂在最后。此时他虽然还继续在普林斯顿大学任教,但也同时已经是 Together AI 的首席科学家。
论文地址:https://arxiv.org/pdf/2407.08608
为了能加速在 Hopper GPU 上的注意力,FlashAttention-3 主要采用了三种技术:
- 通过 warp-specialization 重叠整体计算和数据移动;
- 交错分块 matmul 和 softmax 运算;
- 利用硬件支持 FP8 低精度的不连贯处理。
FlashAttention-3 的速度是 FlashAttention-2 的 1.5-2.0 倍,高达 740 TFLOPS,即 H100 理论最大 FLOPS 利用率为 75%。使用 FP8,FlashAttention-3 的速度更是接近 1.2 PFLOPS。参阅xx报道《英伟达又赚到了!FlashAttention3 来了:H100 利用率飙升至 75%》。
现在,到了 2025 年,FlashAttention-4 准时到来,增加了对 Blackwell GPU 的原生支持——之前,想要在 Blackwell 上跑 FlashAttention,如果直接用开源仓库,常常会遇到编译错误、kernel 缺失或性能未优化的情况,可用的 Blackwell 加速主要是借助英伟达 Triton/cuDNN 的间接支持。

图源:https://www.reddit.com/r/LocalLLaMA/comments/1mt9htu/flashattention_4_leak/
此时,FlashAttention 的 GitHub 软件库已经积累了超过 1.91 万星。

项目地址:https://github.com/Dao-AILab/flash-attention
目前,Tri Dao 团队尚未发布 FlashAttention-4 的技术报告,更多细节还有待进一步揭晓。
参考链接
https://x.com/tri_dao/status/1960217005446791448
https://x.com/SemiAnalysis_/status/1960070677379133949
https://www.reddit.com/r/LocalLLaMA/comments/1mt9htu/flashattention_4_leak/
.....
#Jet-Nemotron
英伟达再出手!新型混合架构模型问世,两大创新实现53.6倍吞吐提速
又一个真正轻量、快速、强悍的大语言模型闪亮登场!
Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。
与此同时,大量工作致力于构建混合模型,将全注意力和线性注意力相结合,以在准确性和效率之间取得平衡。虽然这些模型比全注意力架构具有更高的效率,但其准确性仍明显落后于 SOTA 全注意力模型。
近日,来自英伟达的研究者提出了一种新的混合架构语言模型新系列 ——Jet-Nemotron。其在达到 SOTA 全注意力模型精度的同时,还具备卓越的效率。
具体来说,2B 版本的 Jet-Nemotron 性能就能赶超 Qwen3、Qwen2.5、Gemma3 和 Llama3.2 等最 SOTA 开源全注意力语言模型,同时实现了显著的效率提升。在 H100 GPU 上,其生成吞吐量实现了高达 53.6 倍的加速(上下文长度为 256K,最大 batch size)。
此外,在 MMLU 和 MMLU-Pro 基准上,Jet-Nemotron 的准确率也超过了近期一些先进的 MoE 全注意力模型(如 DeepSeek-V3-Small 和 Moonlight),尽管这些模型的参数规模更大。
- 论文标题:Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search
- 论文地址:https://www.arxiv.org/pdf/2508.15884
下图将 Jet-Nemotron 与之前的高效大语言模型进行了对比。

值得注意的是,Jet-Nemotron-2B 在 MMLU-Pro 上的准确率高于 Qwen3-1.7B-Base,并且在 64K 上下文长度下,在英伟达 H100 GPU 上的生成吞吐量是后者的 47 倍。
Jet-Nemotron 建立在两项核心创新之上:
- 后神经架构搜索 (Post Neural Architecture Search,PostNAS):一种高效的后训练架构探索与自适应 pipeline,可适用于任意预训练的 Transformer 模型。
- JetBlock:一种新型的线性注意力模块,其性能显著优于 Mamba2 等先前的设计。
英伟达研究科学家 Han Cai 以及 MIT 副教授韩松都各自在推特上「安利」了这项研究,其中韩松表示「一个轻量级且可以快速运行的大语言模型来了。」


PostNAS —— 后训练架构探索与自适应
与以往从零开始训练模型、以探索新架构的方法不同,PostNAS 的思路是:在已有的预训练 Transformer 模型上,灵活尝试不同的注意力(attention)模块设计。这样不仅大大降低了开发新型大语言模型架构的成本和风险,还提高了研究效率。
当然,在这一框架下设计出的新架构,如果直接从零训练,可能并不能达到最优结果。但研究者认为,它们依然非常有价值:
- 立即带来收益 —— 如图 1 所示,这些架构能在现有全注意力模型的基础上,实现效率和精度的立刻提升,从而带来实际好处,例如服务质量改善和运维成本下降。
- 快速的创新试验场 —— 如果一个新设计在该框架下表现不佳,那么它在完整的预训练过程中成功的可能性也极低。这个「过滤机制」帮助研究人员避免在无望的架构上浪费大量算力和资源。

PostNAS 首先确定全注意力层的最佳位置,然后再搜索更优的注意力模块设计。
同时,研究者提出了一种自动化方法,用来高效确定全注意力层的放置位置。整体方法如下图 4 所示。通过在预训练的全注意力模型中加入可选的线性注意力路径,研究者构建了一个 once-for-all 超网络。训练练过程中的每一步都随机采样一条激活路径,从而形成一个子网络,并使用特征蒸馏损失进行训练。

训练完成后,研究者采用束搜索来确定给定约束条件下(例如仅允许 2 层全注意力层)的最优放置方式。
搜索目标与任务相关:对于 MMLU,研究者选择在正确答案上损失最低的配置(即最大化−loss);而对于数学与检索类任务,研究者则选择准确率最高的配置。如下图 5 (b) 所示,PostNAS 在精度上显著优于均匀放置策略。

在预训练的 Transformer 模型中,并非所有注意力层都具有同等贡献。PostNAS 揭示了其中最关键的注意力层。

PostNAS 精度提升分解。通过将 PostNAS 应用于基线模型,论文在所有基准测试上都取得了显著的精度提升。
此外,KV 缓存大小是影响长上下文和长文本生成吞吐量的最关键因素。PostNAS 的硬件感知搜索能够发掘这样的架构:在保持相似生成吞吐量的同时,拥有更多参数并取得更高精度。下表 2 为硬件感知架构搜索的详细结果。

JetBlock —— 具备SOTA 精度的全新线性注意力模块
借助 PostNAS,研究者提出了 JetBlock。这是一种新颖的线性注意力模块,可以将动态卷积与硬件感知的架构搜索相结合,从而增强线性注意力。
结果显示,在保持与现有设计相近训练与推理吞吐量的同时,JetBlock 在精度上实现了显著提升。在相同训练数据与训练方案情况下,下图对 Mamba2 Block 与 JetBlock 的各性能指标(包括通用知识、数学、常识和检索)进行了比较。

主要结果如下图所示:在全面的基准测试套件中,Jet-Nemotron-2B 和 Jet-Nemotron-4B 的精度能够媲美甚至超越领先的高效语言模型(例如 Qwen3),同时运行速度显著更快,它们分别比 Qwen3-1.7B-Base 快了 21 倍和 47 倍。

更多技术细节与实验结果请参阅原论文。
参考链接:https://hanlab.mit.edu/projects/jet-nemotron
.....
#将数据优势发挥到极致
「杭州六小龙」开源搭建空间智能的第一步
如果你拥有了庞大的三维空间数据,你会用来做什么?
大模型时代之后,数据成了支撑模型的承重柱。能否获取足够的可用高质量数据,直接决定了某个领域的 AI 的发展上限。
而有了足够的数据,构建一个强大的大模型和生成模型,似乎总是水到渠成的事情。
想想看,视频生成模型里,可灵即梦等高质量模型,都是依托最大的视频内容 UGC 平台的海量数据而生的。这些数据自然也成为了模型进步最大优势。
数据可以用来训练模型,这些模型又可以进一步强化工具的能力,以此形成了数据飞轮,在三个环节(工具、数据、模型)相互循环。
在三维领域,数据一直是困扰人工智能对空间理解的长期问题。在昨天,我们应邀参加了「杭州六小龙」之一群核科技的首届 TechDay,看到了在室内空间设计领域的企业对于空间智能的思考。

我们想象的人工智能改变生活,都希望人工智能帮助我们打扫卫生做饭,我们可以吟诗作画。但现在反过来了,人工智能在吟诗作画,我们在那边打扫卫生。
要实现对人工智能改变生活的美好愿景,必须让人工智能从数字世界走向物理世界。

群核科技的联合创始人黄晓煌认为,「空间智能是非常关键的桥梁。」
首席科学家周子寒在演讲中提到:「群核空间大模型可以用这三个特点来描述,第一是真实感的全息漫游,第二是结构化可交互,第三是复杂的室内场景。」

在这次的活动中,他们为空间智能发布了两个模型,一个空间语言模型和一个空间生成模型。

空间作为语言训练
大模型助力数据合成
大语言模型的最大优势就是语言的理解和输出,三维世界是否也能作为一门语言让大模型去学习呢?
今年 3 月的 SpatialLM 的空间理解模型,是基于大语言模型训练的。当输入一段视频时,模型能够提取这个视频当中的空间信息,用一段文本的形式将这个空间当中的物体方位和类别解释出来,在开源不久登上了 Hugging Face 趋势榜的前三名。
这一次 SpatialLM 1.5 有了一次巨大的飞跃,被称为空间语言模型。在采用 Qwen3 作为底层模型的基础上,叠加了 3D 空间描述语言能力构建增强型模型,使其既能理解自然语言,又能以类编程语言(如 Python)的结构化方式对室内场景进行理解、推理和编辑。
简单来说,就是大模型学会了空间语言。空间语言是一种结构化的语言,就像参数列一样,用数学的长、宽、高或 X、Y、Z 的方式去描述每一个物体在空间中的位置,描述物体类别,甚至可以从一个已有的素材库中找到对应的模型 ID,通过空间语言的描述就可以去获得整个场景的完整的 3D 信息。

空间语言模型 SpatialLM1.5 能力示意图
支持用户通过对话交互系统 SpatialLM-Chat 进行可交互场景的端到端生成。
例如,当用户输入简单文本描述时,SpatialLM 1.5 可自动生成结构化场景脚本,智能匹配家具模型并完成布局,并支持后续通过自然语言进行问答或编辑。
,时长03:44
SpatialLM-Chat 演示
视频中展示了从户型图生成结构正确的房间信息,通过语言指令生成不同房间场景的家具,甚至完成移动路径的规划。
SpatialLM 1.5 生成的场景富含物理正确的结构化信息,且能快速批量输出大量符合要求的多样化场景,可用于机器人路径规划、避障训练、任务执行等场景,让xx智能的数据合成变的更加简单。
场景数据实现「时空一致」
3DGS 渲染沉浸视频
,时长00:17
SpatialGen 生成场景渲染的漫游视频
在刚进入 TechDay 会场的时候,每个人都领了一张小卡片,在演示设备前刷下卡,就能看到对应的三维漫游场景。
在视频演示中,我们发现了明显的 3DGS 渲染特征,存在一些空间高斯点云的渲染模糊。但是,随着镜头的运动,这个三维场景表现出了惊人的「时空一致性」,并且随着镜头大范围的运动,3DGS 渲染常见的伪影、模糊、形变失真等现象也没有出现。
这一切都是由基于扩散模型架构的多视角图像生成模型 SpatialGen 来实现的。
如果说 SpatialLM 解决的是「理解与交互」问题,那么 SpatialGen 则专注于「生成与呈现」。
SpatialGen 依托群核科技海量室内 3D 场景数据与多视角扩散模型技术,其生成的多视角图像能确保同一物体在不同镜头下始终保持准确的空间属性和物理关系。

群核空间生成模型 SpatialGen 数据集情况
在实现细节方面,首席科学家周子寒在演讲中阐述了基本原理。其输入是场景的一张原图,以及场景布局图。输出则是相应场景的多视角图像,也可以进行深度图、语义图等其他类别的输出。

SpatialGen 模型架构
SpatialGen 可以生成任意视角图片,可以从一张图片生成八张图片,通过环形的视角的限定,它就会去尽量生成不同视角的图片,模拟相机在空间中的旋转。也可以基于这些图片再去生成更多图片,生成更多图片时可以用不同相机的约定的轨迹,这样就可以去生成更加复杂的运镜。
有了多视角图像结果,就可以通过一个开源的高斯重建的算法(AnySplat)重建高斯点云,随后可以进行视频的渲染,最终得到了一个漫游视频。
SpatialGen 的三大技术优势:
- 大规模、高质量训练数据集:由于开源 3D 场景数据稀缺,已有的工作在算法选择上受限,一般通过蒸馏 2D 生成模型,导致结果视觉真实性不足;基于群核数据集,能够设计并训练面向场景的多视角扩散模型(multi-view diffusion model)以生成高质量图像。
- 灵活视角选择:已有方法基于全景图生成还原,3D 场景完整性较差;或基于视频底模,无法支持相机运动控制等。
- 参数化布局可控生成:基于参数化布局生成,未来可支持更丰富的结构化场景信息控制。
针对 3DGS 的场景生成的问题,xx在技术交流会上与周子寒教授进行了一些技术上的交流:
xx:3DGS 生成领域中,传统的方法都是从图像生成的技术去入手做一个 3D 高斯生成,始终无法摆脱多视角生成图像的一致性问题。对于 SpatialGen 而言,使用了大量数据集,在多视角图像一致性上群核科技是否仍在用 Scaling Law 取得进步,在未来我们是不是有新的进步空间?
周子寒:对,现在的多视角的生成模型还是基于图像生成的,它之所以能呈现比较好的空间一致性,更多是依赖于我们在室内空间数据方面的优势,我们可以很高效地获取非常多的任意视角的图片进行训练,当你在训练了足够久的时间以后,未来我们可以继续去 scale up,空间一致性也会做得越来越好。
这里有一些与视频模型不同的点,我们一开始就不想让这样的一个模型受到时间轴的约束,而是让它在空间当中能随意跳跃。这种随意跳跃在工作流当中做任意的运镜视频的时候,会比纯视频模型,一定要从 A 到 B 的固定过程,要更加方便,这是一种新的视角,并不代表着新的技术路线。

当你去反复迭代使用时,这个东西显然不是无止境的,当你用了几轮以后,一致性一定会受到影响,我们相信 scaling law 一定会让它越做越好,但无法从根本上去消除这样的东西,就像你说的那样。
xx:如果依靠群核科技的三维数据集是否会有些进步,例如从文本直接到三维,而不经过二维图像的过程。
周子寒:我们有在探索这样一条路线,希望能将文本和 3DGS,或是 3D 表征直接去做一个连接,而不用中间的这一个多视角图像的东西。
目前来看,它有一个视觉效果与空间一致性的 trade off,如果用图像作为中间过程的视觉效果会好很多,如果直接从文本到 3D 的话,目前视觉效果稍微差了一点,这是在我们自己的过程当中(发现)的,这是两个不同的技术路线,在未来一定会有新突破。
开源方向的思考
目前,在空间语言模型,从参数量而言仍处于 GPT-2 的阶段。虽然空间大模型能够弥补现有模型能力的很多缺陷,但空间大模型的 chatGPT 时代还远未到来。

群核科技联合创始人兼董事长黄晓煌表达了一个明确的观点:
「目前空间智能肯定还是在一个发展的初期阶段的,我觉得任何一家公司都不可能独享这个市场,所以我们在不断地开源数据、模型,我们希望跟全细节最聪明的大脑,全世界最有创新能力的人一起将这个 “蛋糕” 做大。」
在与周子寒教授的交流中,他也表示说:
「我们在设计的时候,刻意地让资产库与模型本身是解耦的,可以让这个模型去对接任何的资产库。这个东西跟群核自己的资产库并没有任何特定的绑定关系,这是为什么我们可以将整个系统做开源的原因,只要大家用任何的资产库都可以同样使用。」
SpatialGen 已面向全球开源,可在以下开源网站下载并部署使用:
- Hugging Face:https://huggingface.co/manycore-research/SpatialGen-1.0
- Github:https://github.com/manycore-research/SpatialGen
- 魔搭社区:https://modelscope.cn/models/manycore-research/SpatialGen-1.0
随着越来越多优秀的方法和高质量的数据集开源,不仅推动了不同 AI 领域的发展,也为研究社区带来了更多交流与碰撞的机会,催生新的灵感与突破,始终是一件令人振奋的事。
c

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)