大模型训练中的总步数是怎么计算的?
在训练进度条中显示的“144”代表模型微调过程中的,其形成与数据集的规模、训练配置(如批量大小、梯度累积步数、训练轮数等)直接相关。
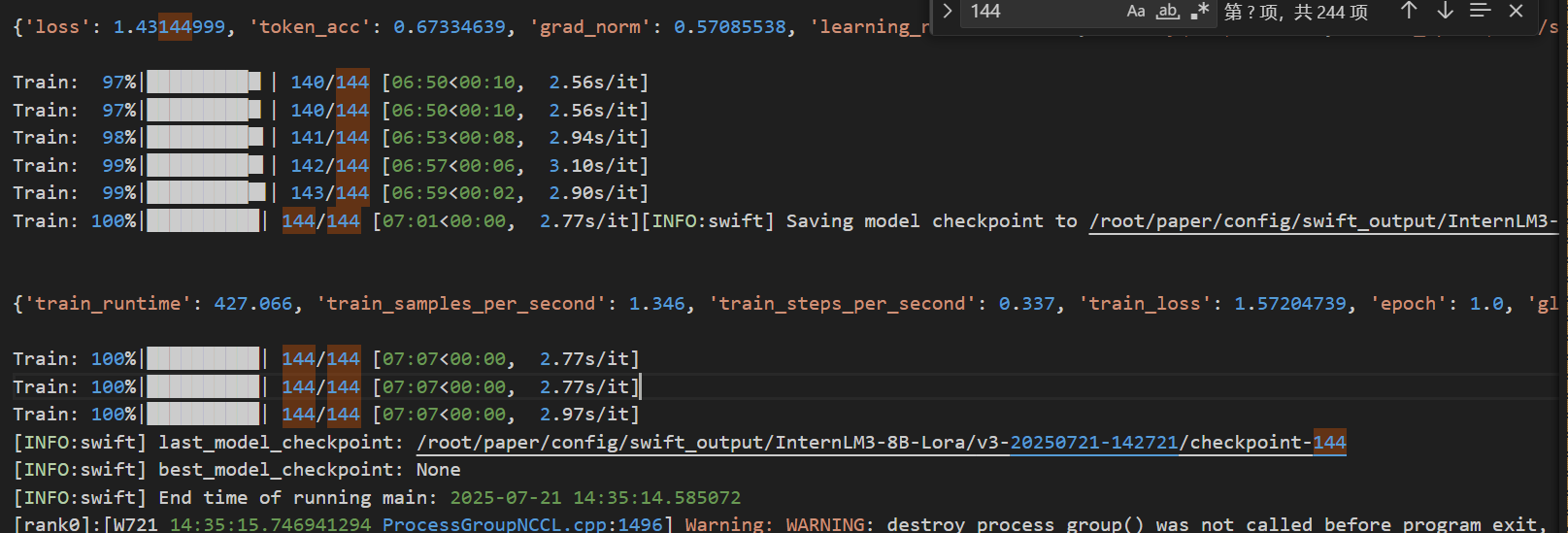
Train: 97%|█████████▋| 140/144 [06:50<00:10, 2.56s/it]
Train: 97%|█████████▋| 140/144 [06:50<00:10, 2.56s/it]
Train: 98%|█████████▊| 141/144 [06:53<00:08, 2.94s/it]
Train: 99%|█████████▊| 142/144 [06:57<00:06, 3.10s/it]
Train: 99%|█████████▉| 143/144 [06:59<00:02, 2.90s/it]
在训练进度条中显示的“144”代表模型微调过程中的总训练步数(global steps),其形成与数据集的规模、训练配置(如批量大小、梯度累积步数、训练轮数等)直接相关。以下是具体分析:
⚙️ 总步数(144)的形成原理
总训练步数由以下公式决定:
总步数 = 训练样本总数 ÷ (每设备批量大小 × 梯度累积步数 × 设备数量) × 训练轮数结合用户提供的训练脚本参数6:
- 每设备批量大小(
per_device_train_batch_size): 2 - 梯度累积步数(
gradient_accumulation_steps): 2 - 设备数量(
NPROC_PER_NODE): 1(单卡训练) - 训练轮数(
num_train_epochs): 1
假设训练集样本数为 N,则:
总步数 = $ N \div (2 \times 2 \times 1) \times 1 = N \div 4 $因此,144步意味着训练集样本数 N = 144 \times 4 = 576。
(实际中可能因数据对齐有微小调整,但逻辑一致)
🔗 与数据集的直接关联
-
数据集来源
用户使用的数据集是/root/paper/data/swift_formatted_pretrain_data.jsonl,来源于 arXiv论文分类数据集(smartflow-arxiv-dataset),包含论文标题、作者、摘要及对应的科学分类标签6。- 该数据集已预处理为
jsonl格式,每条样本对应一个训练样本。 - 样本数
576符合实际任务需求(例如论文分类通常需数百至数千样本)。
- 该数据集已预处理为
-
数据分块与加载
- 批量计算逻辑:
每步(step)处理一个批量(batch),每个批量包含batch_size × gradient_accumulation_steps = 4个样本。
例如:- 第140步:已处理样本数 =
140 \times 4 = 560 - 第144步:累计处理
144 \times 4 = 576个样本(完整覆盖数据集)6。
- 第140步:已处理样本数 =
- 批量计算逻辑:
⚡️ 训练进度条的意义
进度条 140/144 表示:
- 分子(140):当前已完成的训练步数。
- 分母(144):总训练步数(由数据集规模与配置决定)。
- 时间标注(如
06:50<00:10):06:50:当前步骤已耗时6分50秒<00:10:预计剩余10秒完成训练
(实际每步耗时约2.5~3.1秒,符合日志中的平均速度2.77s/it)6。
💎 总结
- 144的由来:由训练集样本数(576)与训练配置(批量大小2 + 梯度累积步数2 + 单卡)共同决定,公式为:
总步数 = 样本数 ÷ (批量大小 × 梯度累积步数) × 训练轮数。 - 与数据的关系:
- 数据集规模直接决定总步数(样本越多,步数越多)。
- 配置参数(如增大批量大小或梯度累积步数)可减少总步数,但需权衡显存限制与收敛效果6。
若需调整训练效率,可修改以下参数:
# 示例:增大批量大小至4(总步数降至72)
--per_device_train_batch_size 4
# 或减少梯度累积步数至1(总步数降至144)
--gradient_accumulation_steps 1下面为训练完成的设置
#!/bin/bash
# 创建日志目录
LOG_DIR="logs"
mkdir -p $LOG_DIR # 确保日志目录存在,如果不存在则创建
# 获取当前时间戳,用于生成唯一的日志文件名
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
LOG_FILE="$LOG_DIR/internlm3-8b_lora_sft_${TIMESTAMP}.log" # 设置日志文件路径
# 设置CUDA环境变量
export NPROC_PER_NODE=1 # 设置每个节点使用的进程数为1
export OMP_NUM_THREADS=1 # 限制OpenMP线程数为1,避免过多线程竞争
export CUDA_VISIBLE_DEVICES=0 # 指定使用的GPU编号为0
# 使用nohup命令在后台运行训练任务,即使终端关闭也能继续运行
nohup swift sft \
--model /root/share/new_models/internlm3/internlm3-8b-instruct \ # 指定基础模型路径
--train_type lora \ # 使用LoRA训练方法
--dataset '/root/paper/data/swift_formatted_pretrain_data.jsonl' \ # 指定训练数据集
--torch_dtype bfloat16 \ # 使用bfloat16精度以节省显存
--num_train_epochs 1 \ # 设置训练轮数为2
--per_device_train_batch_size 2 \ # 每个设备的训练批次大小为4
--learning_rate 5e-5 \ # 学习率设置为5e-5
--warmup_ratio 0.1 \ # 预热阶段占总训练步数的10%
--split_dataset_ratio 0 \ # 不拆分数据集
--report_to wandb \ # 将训练日志报告到Weights & Biases平台
--lora_rank 8 \ # LoRA的秩设置为8
--lora_alpha 32 \ # LoRA的alpha参数设置为32
--use_chat_template false \ # 不使用聊天模板
--target_modules all-linear \ # 对所有线性层应用LoRA
--gradient_accumulation_steps 2 \ # 梯度累积步数为2,用于增大有效批次大小
--save_steps 2000 \ # 每2000步保存一次模型
--save_total_limit 5 \ # 最多保存5个检查点
--gradient_checkpointing_kwargs '{"use_reentrant": false}' \ # 梯度检查点设置,禁用重入
--logging_steps 5 \ # 每5步记录一次日志
--max_length 2048 \ # 最大序列长度设为2048
--output_dir ./swift_output/InternLM3-8B-Lora \ # 输出目录
--dataloader_num_workers 256 \ # 数据加载器使用256个工作线程
--model_author JimmyMa99 \ # 模型作者信息
--model_name InternLM3-8B-Lora \ # 模型名称
> "$LOG_FILE" 2>&1 & # 将标准输出和错误输出重定向到日志文件,并在后台运行
# 打印进程ID和日志文件位置,便于用户跟踪
echo "Training started with PID $!" # 显示后台进程的PID
echo "Log file: $LOG_FILE" # 显示日志文件位置
# 提示用户如何实时查看日志
echo "To view logs in real-time, use:"
echo "tail -f $LOG_FILE"注意:不要有空格

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)