Prompt工程论文:AdaPlanner-基于反馈与语言模型的自适应规划
论文地址:https://arxiv.org/pdf/2305.16653摘要:大型语言模型(LLMs)近期在作为自主代理执行顺序决策任务方面展现出巨大潜力。然而,目前多数方法要么在没有规划的情况下贪婪地采取行动,要么依赖于无法根据环境反馈进行调整的静态计划。因此,随着问题复杂度和计划跨度的增加,LLM 代理的顺序决策性能会逐渐下降。我们提出了一种闭环方法——,使 LLM 代理能够根据环境反馈自适
论文地址:https://arxiv.org/pdf/2305.16653
摘要:大型语言模型(LLMs)近期在作为自主代理执行顺序决策任务方面展现出巨大潜力。然而,目前多数方法要么在没有规划的情况下贪婪地采取行动,要么依赖于无法根据环境反馈进行调整的静态计划。因此,随着问题复杂度和计划跨度的增加,LLM 代理的顺序决策性能会逐渐下降。
我们提出了一种闭环方法——AdaPlanner,使 LLM 代理能够根据环境反馈自适应地优化其自生成的计划。在 AdaPlanner 中,LLM 代理结合计划内与计划外的优化策略,从反馈中自适应地改进其计划。为了减轻幻觉问题,我们设计了一种类代码风格的提示结构,以支持在多种任务、环境和代理能力下的有效计划生成。
此外,我们还提出了一种技能发现机制,能够利用成功的计划作为小样本示例,从而使代理在更少任务演示的情况下进行规划与优化。
在 ALFWorld 和 MiniWoB++ 环境中的实验证明,AdaPlanner 分别以 3.73% 和 4.11% 的优势超越了当前最先进的基线方法,同时分别使用了 2 倍和 600 倍更少的样本。AdaPlanner 的实现已开源于:https://github.com/haotiansun14/AdaPlanner。
研究背景
- 研究问题:本文提出了一种名为AdaPlanner的闭环规划方法,旨在解决大型语言模型(LLMs)在复杂环境中进行顺序决策时的适应性不足问题。现有方法往往缺乏对环境反馈的适应能力,导致决策性能在问题复杂度和计划范围增加时下降。传统的决策方法(如强化学习)需要大量特定任务的训练数据,且通常难以跨任务和跨环境进行泛化。LLMs虽然在多任务处理上表现出色,但在动态环境中,如何有效利用反馈信息进行计划调整仍然是一个挑战。
- 创新点:
- 提出了AdaPlanner,一个自适应闭环规划方法,能够根据环境反馈动态调整计划,提高了决策的灵活性和效率。
- 采用代码风格的提示结构,有效减少了LLM的幻觉现象,提升了任务执行的准确性。
- 通过技能发现机制,利用成功的计划作为少量示例,显著提高了样本效率,减少了对大量训练数据的依赖。
研究方法
本文提出的AdaPlanner方法结构如下:
- 方法:AdaPlanner模型包括一个基于LLM的代理,负责生成初步计划和执行反馈修正,以及一个技能记忆模块,旨在通过技能发现提升样本效率。
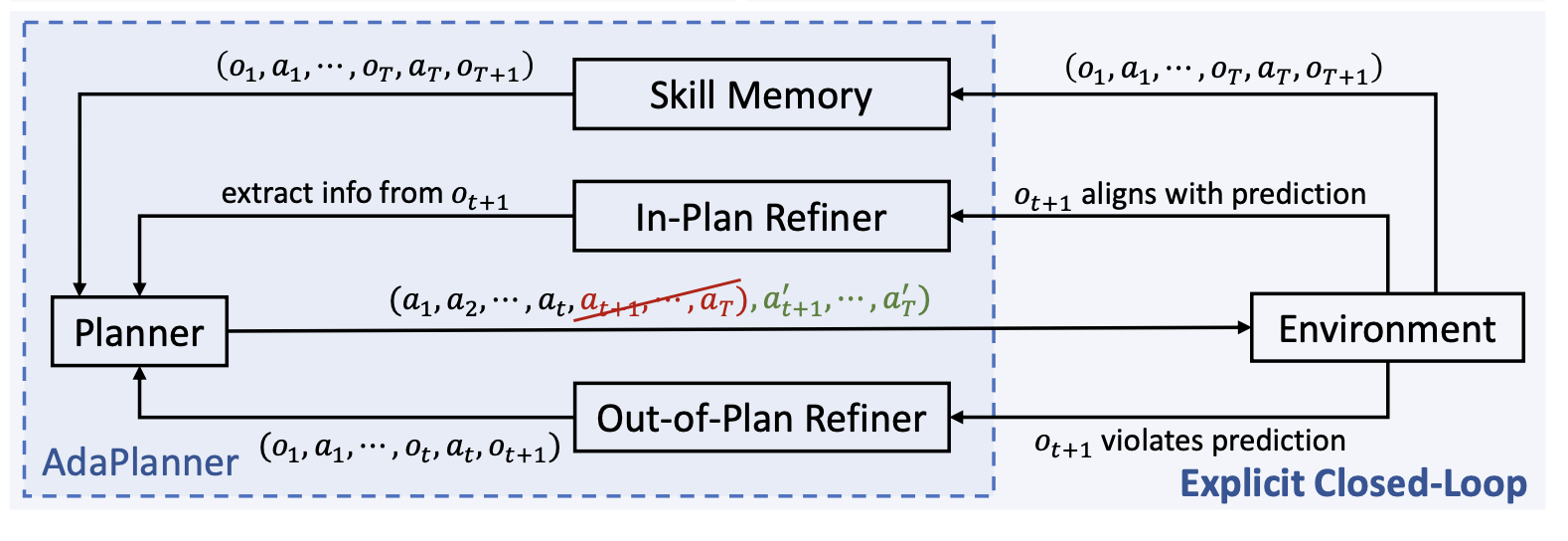
- 初步计划生成:通过输入任务描述、可行动作和示例演示生成初步计划。此过程采用代码风格的提示,以减少模糊性和误解。
- 闭环适应性:在执行过程中,AdaPlanner根据环境反馈进行两种类型的反馈修正:在计划内反馈和计划外反馈。计划内反馈允许代理在执行过程中进行信息提取,而计划外反馈则允许代理根据环境变化重新修订整个计划。
示例:
结果与分析
本文实验结果显示,AdaPlanner在多个任务上均优于现有基线方法,具体如下:
-
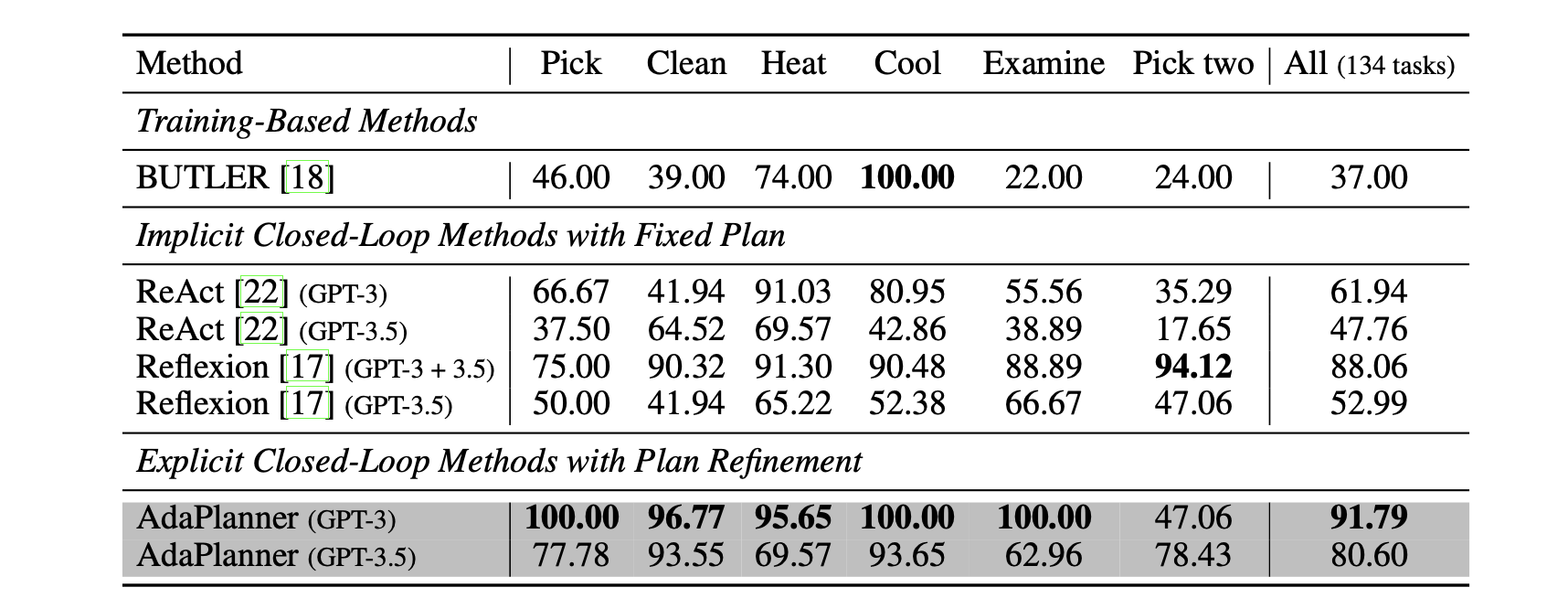
ALFWorld任务成功率:在134个任务中,AdaPlanner的成功率达到91.79%,显著高于其他方法。
-
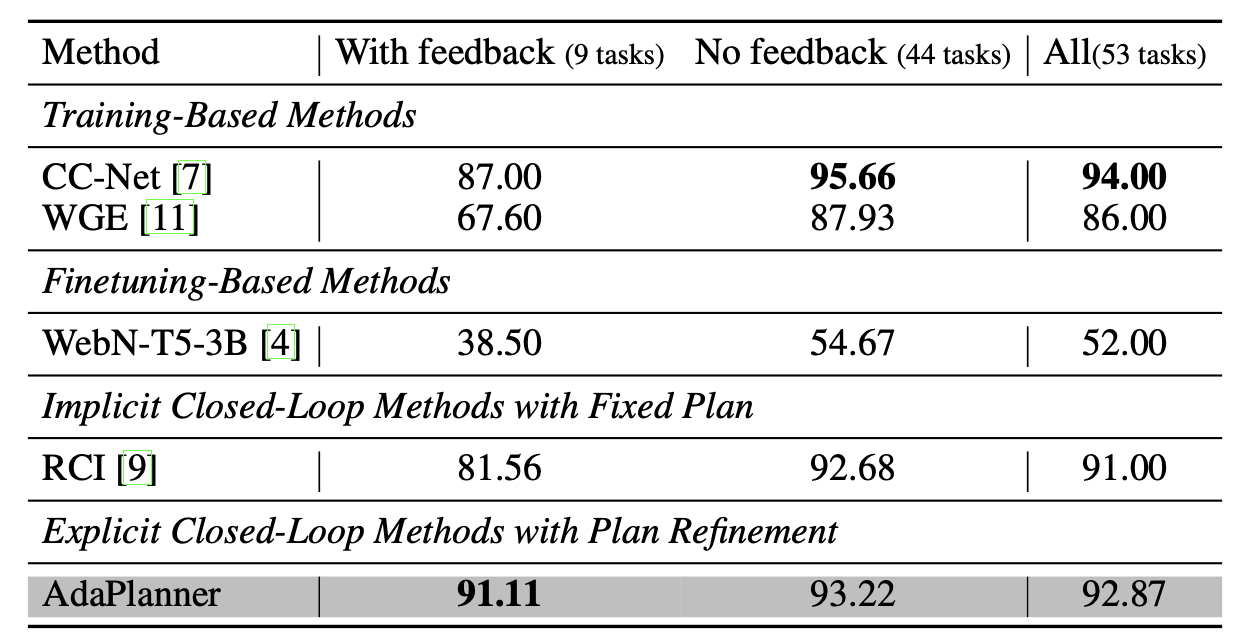
MiniWoB++任务表现:在MiniWoB++任务中,AdaPlanner在反馈任务上的成功率为91.11%,在没有反馈的任务中也达到了93.22%。
-
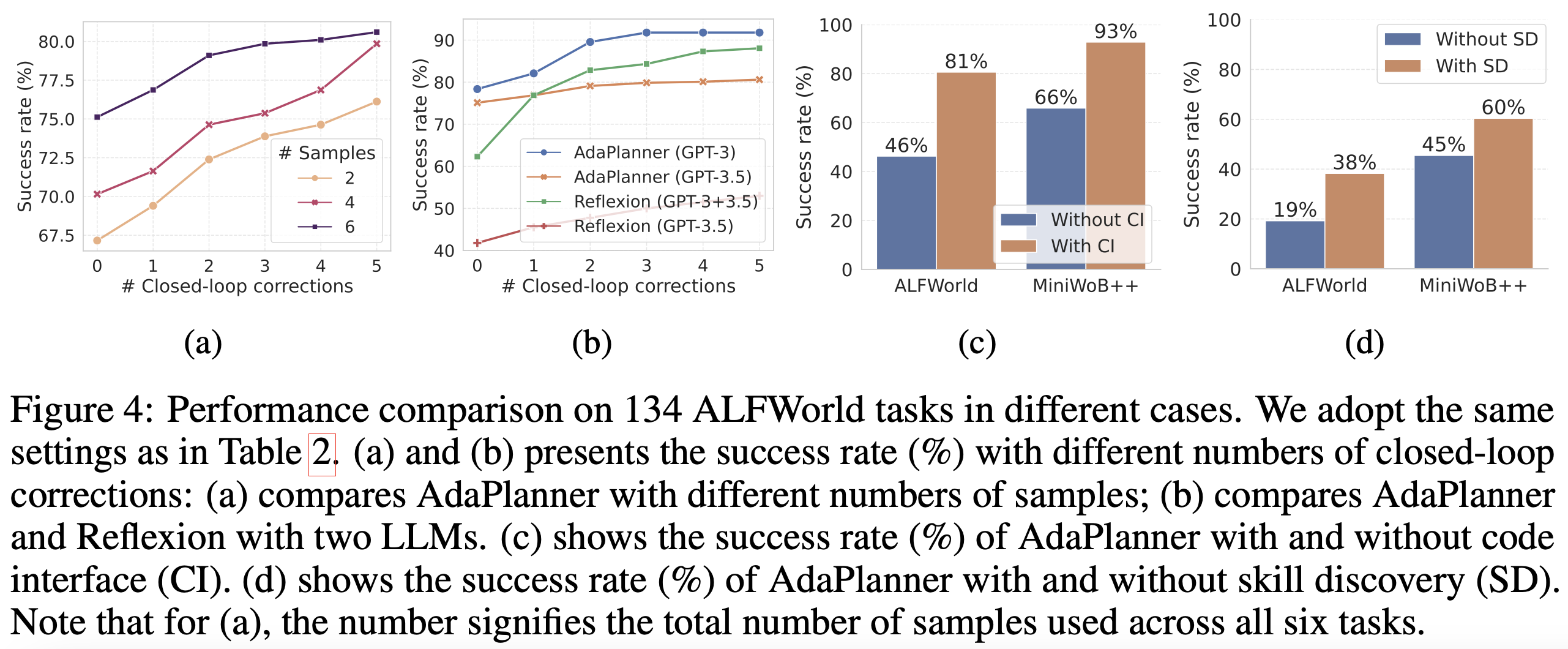
样本效率:AdaPlanner在ALFWorld和MiniWoB++中均表现出极高的样本效率,尤其是在MiniWoB++任务中,其成功率是CC-Net的600倍样本效率。
-
反馈利用:AdaPlanner通过闭环反馈机制,在多次修正后成功完成任务,展现出较强的适应性和灵活性。
总体结论
本文提出的AdaPlanner方法通过引入自适应闭环规划机制,显著提升了LLMs在复杂环境中的决策能力。实验结果表明,AdaPlanner在多个任务中均实现了优异的性能,证明了其在动态环境中有效利用反馈信息的能力。未来的研究可以进一步探索如何在没有示例的情况下提升AdaPlanner的决策能力,以应对更复杂的任务场景。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)