立体匹配7——经典算法ADCensus
本文介绍了ADCensus立体匹配算法的完整流程。算法首先通过融合Census结构特征和AD亮度差异特征进行代价计算,然后采用可变形状支持窗进行多方向代价聚合。接着使用扫描线优化方法减少噪声,并通过视差后处理步骤进一步优化结果,包括错误检测分类、区域投票、分情况插值、边缘修正和亚像素增强等处理。实验结果表明,该方法能有效处理图像中的平坦区域、重复结构和遮挡等问题,最终生成高精度的视差图。整个算法在
目录
首先我们回顾一下标准立体匹配算法中我们都要做什么:
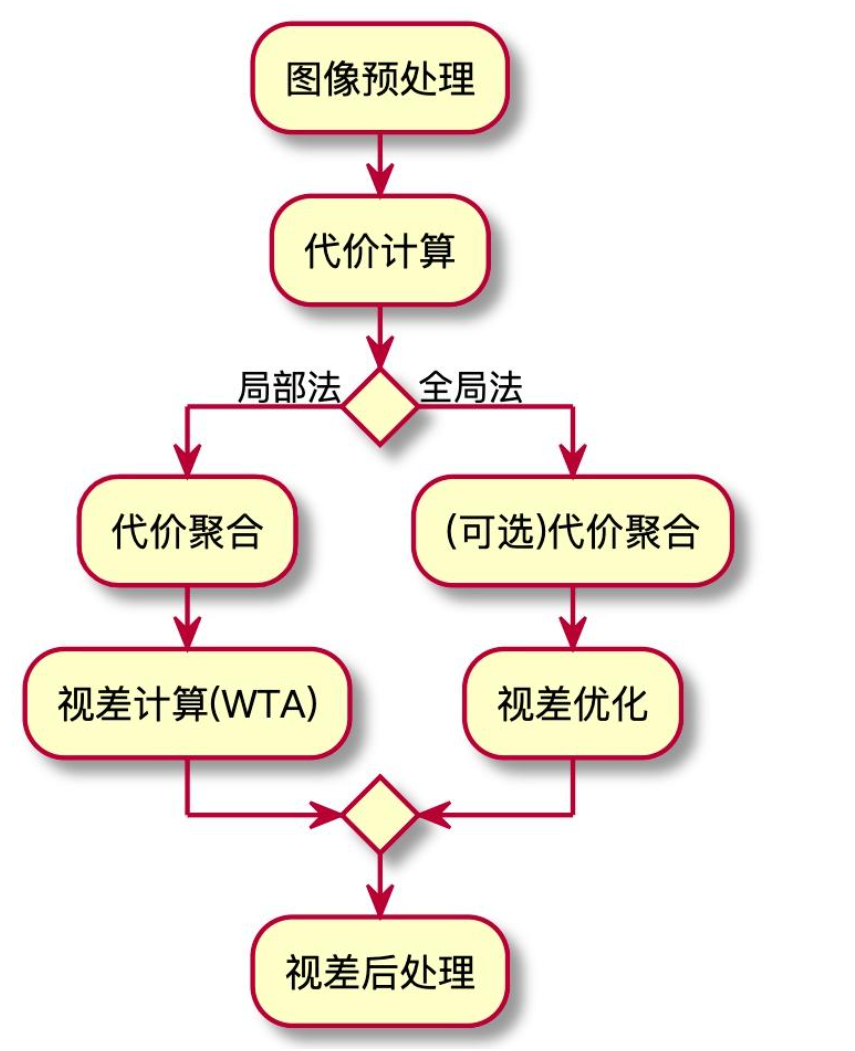
1.代价计算
代价计算的过程类似于连连看的过程:
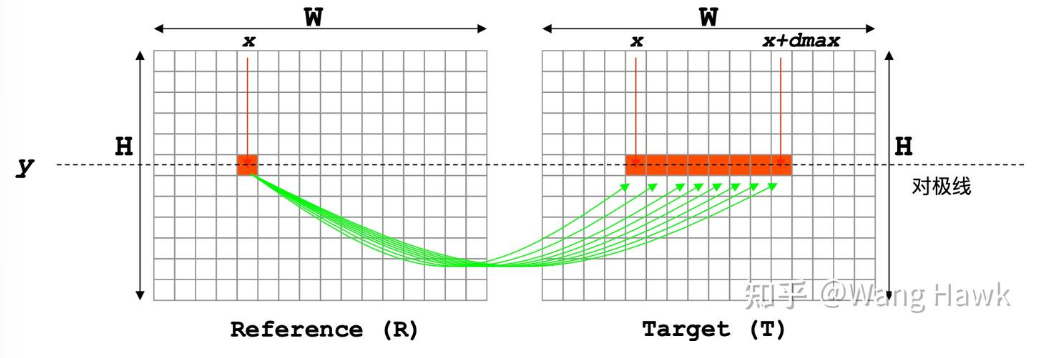
最简单的代价就是左右图中相应像素的亮度绝对差,这种代价被称为AD:
然而,这种代价在图像中的平坦区域(亮度值都差不多)很显然会得到错误的结果。此时显然应该使用别的特征来计算代价。 Cencus就是一种很好的特征,它衡量了局部区域中像素亮度的排序,这是一种结构信息。这就使得它很好的避免了左右图像素亮度差异、噪声、重复纹理等因素带来的错误。
不过,仅使用Census特征的话,在图像中重复结构的区域,也会得到错误的结果。这时候颜色或亮度特征则可以加以辅助。所以ADCensus的作者创造了一种很不错的融合亮度差异和结构差异的方法,如下面公式所述。这里前一部分是基于Census的代价,后一部分是AD代价,所以这个算法才被很多人称为ADCensus:
这里面,为了让两部分代价归一化到[0,1]之间,作者采用了下面这个归一化函数,它能很方便的将输入的原始代价转换为[0,1]之间的值,而这里的λ则用于设置代价的权重:
我们通过作者给出的下图可以很容易的看到混合两种代价带来的好处:

这时候,直接利用AD-Census计算固定窗口的代价,然后用WTA得到视差图,如下图所示。我们可以看到这里有大量的噪声和空洞区域。这是很容易理解的,所以才需要下一节所述的代价聚合过程:

2.代价聚合
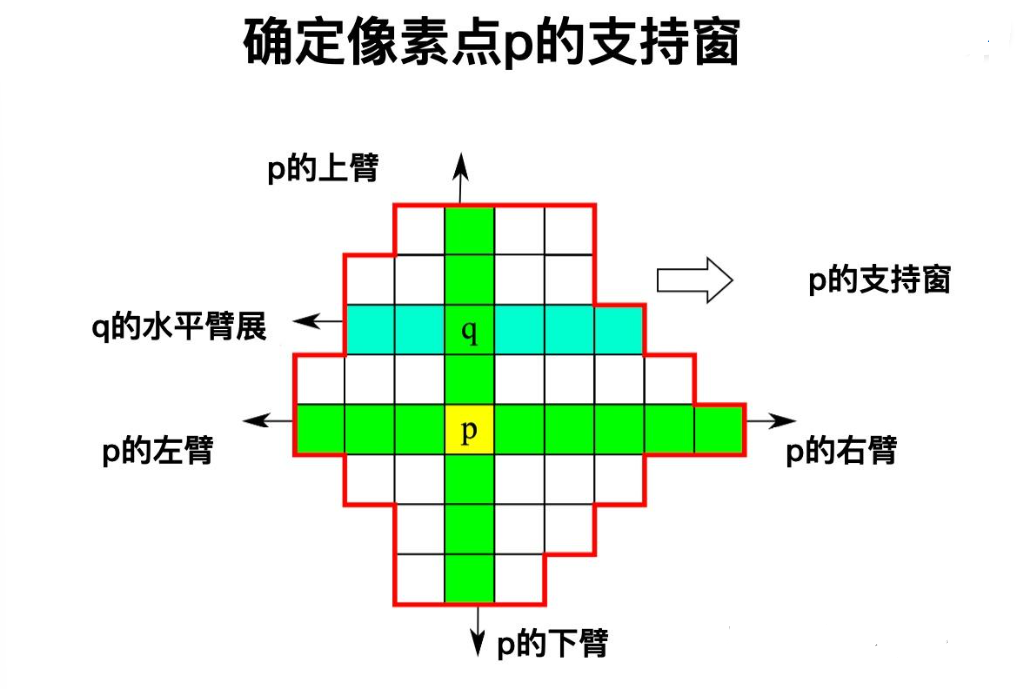
ADCensus的方法属于用可变形状的支持窗来进行聚合的。当要确定某个像素点p的支持窗时,它是通过寻找上下左右四个"臂",在这四个臂的包裹下构成了其支持窗。确切说,首先找到p的上下臂,也就是在空间和像素值两个维度上都尽可能接近p的两端像素。这样就构成了一个包含在p内的垂直的像素线段。在这条线段上的任何一个点q,我们都确定其左右臂,得到水平的远端像素。这样,所有q点的左右臂的远端像素就形成了一个包络,其中就是p点的支持窗。
有了支持窗后,就比较容易聚合了,先在水平方向聚合,将水平方向的代价值加到一起。然后在垂直方向聚合,得到总的代价:
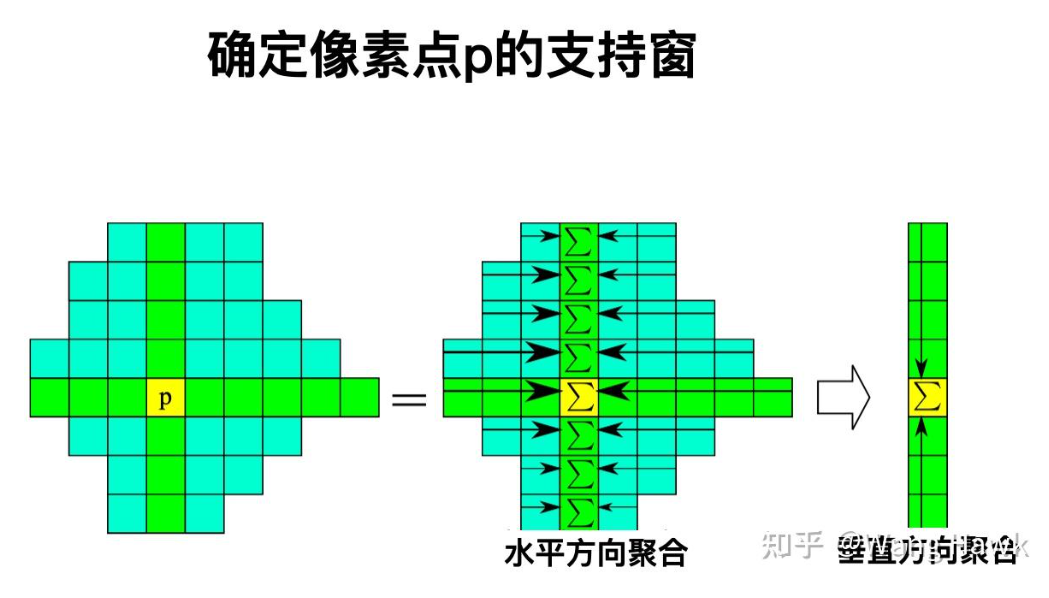
事实上,ADCensus中为了让结果更好,进行了4次交替方向的聚合。即先水平再垂直,这是第1次。第二次相反,先垂直,再水平。然后再进行2次交替的聚合。最终四次的代价整合到一起,成为最后聚合后的代价值。
那么,如何得到上面所说的p点的四个臂呢?这似乎是得到支持窗的关键。我们以获得p的左臂为例来说明:

所以很显然,这里面的几个参数都很重要。总之,通过这一步代价聚合后,我们能够得到更加平滑的视差图,如下图所示:

3.扫描线优化
在视差优化方面,ADCensus也采用了扫描线方法,通过聚合后的代价优化得到视差图。在这篇文章中我已经详细阐述了方法,这里只说说不同之处。在原始的扫描线优化方法中,一共是8个方向。而ADCensus为了提高计算速度,只采用了其中的0、1、2、3这几个水平和垂直的扫描线:
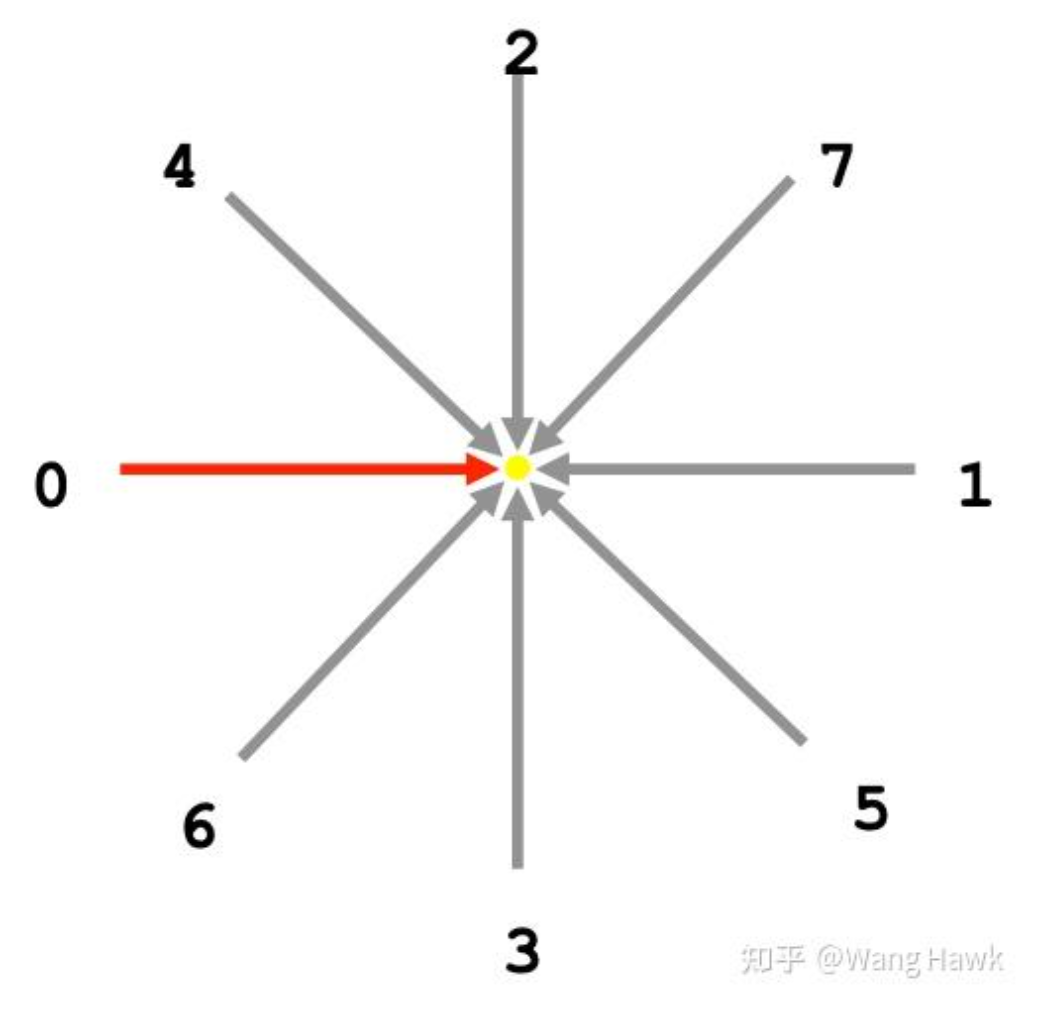
通过这一步,能得到更加准确的视差图,如下图所示。相比上面代价聚合后的结果,这里明显噪声小了很多:

4.视差后处理

4.1 错误检测和区分
首先需要通过左右一致性检查判断哪些像素是错误的:

然后,通过一个简单的法则来区分到底是因为遮挡导致的错误,还是因为错误匹配导致的错误。遮挡像素无论调整d为多少,都无法通过左右一致性检测。而错误匹配则可以通过调整d,得到满足左右一致性检查的新视差值。


接下来,就可以分别对遮挡和错误匹配进行处理了。
4.2 区域投票
首先进行区域投票。在错误像素点p的支持窗内,对所有正确计算视差的像素(即通过了左右一致性检测)的视差值建立一个直方图。如果这个支持窗中稳定视差值足够多,并且直方图中占比最大的视差值的占比大于某个阈值,我们就把p点的视差值更新为最大占比的视差值:
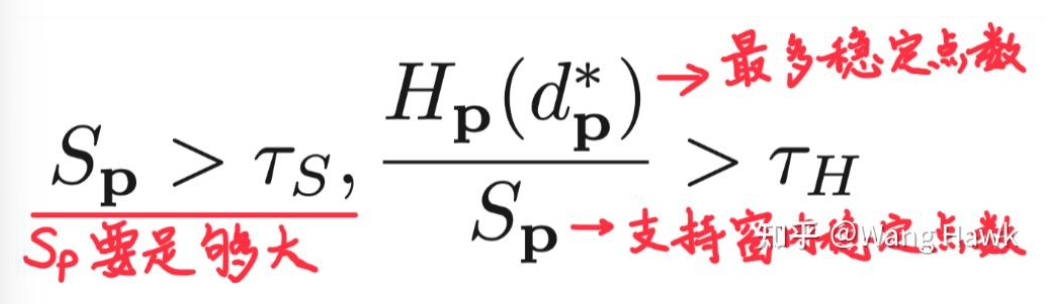
这里面,Sp代表支持窗中正确视差值的个数,Hp(d*p)代表直方图中占比最大的视差值的数量

4.3 分情况插值
前面我们区分了遮挡像素和错误匹配的像素,现在分情况进行插值。
- 首先对于错误像素,我们寻找16个方向上的最相似的正确匹配的像素。
- 接下来,如果当前像素在3.4.1节中被划分为了遮挡像素,那么就从这些正确像素中挑选最小的视差,用于填充当前像素的视差值,也就是说假设遮挡像素属于背景。
- 而如果当前像素是错误匹配的像素,那么就从这些正确点中挑选与当前像素颜色维度最相似的那一个,用其视差填充当前像素。
现在再来看看结果,很明显大量的错误像素被成功插值了。不过也可以看到,部分遮挡像素还是未填充视差值,这是因为在其16个方向都找不到满足条件的正确像素,这里主要是因为用1个参数限制了在一个方向上的最大搜索像素。如果增加这个参数的值,应该可以使得更多的像素得到填充。

4.4 修正边缘处的视差值
考虑到物体边缘的视差值不稳定,容易出错,因此作者还加入了一个步骤,对边缘处的视差值进行微调。具体来说,先检测到所有的边缘,接着对边缘上的像素p,我们判断其在边缘两侧的两个相邻像素p1或p2的代价是否小于p点的代价。如果确实如此,那么就用p1和p2中代价最小的那个像素的视差值来替换p点的视差值。
不过对于当前这对图像,似乎边缘调整带来的变化很小,肉眼几乎分不出来。当然,这是可以理解的,因为这只是“微调”

4.5 亚像素增强和滤波
调整完边缘后,作者采用了亚像素增强,将整数型的视差值插值为了浮点数型的视差值
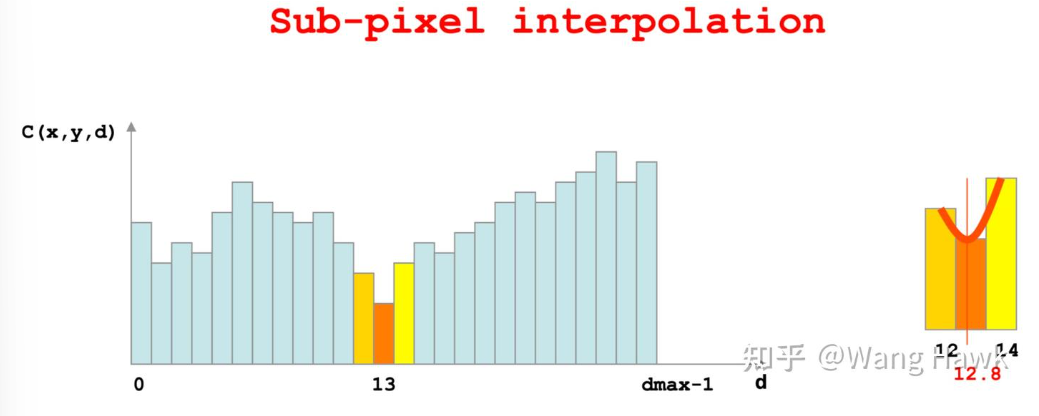
然后,对最后的视差图做了1个3x3的中值滤波,去除微小的噪声,这就得到了最终的视差图:


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)