具身论文]Whole-body Humanoid Robot Locomotion with Human Reference
近年来,仿人机器人在执行复杂任务方面取得了显著进展,主要得益于强化学习(RL)的应用。然而,仿人机器人的复杂性,包括规划复杂的奖励函数和训练整个复杂系统的难度,仍然是一个显著的挑战。。
全文总结
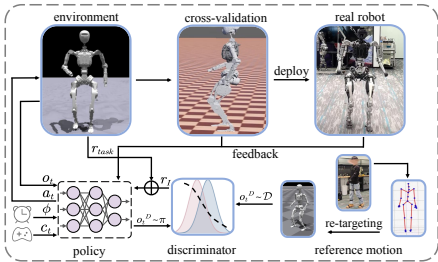
这篇论文介绍了一种全尺寸仿人机器人Adam的全身模仿学习框架,旨在通过人类参考数据实现复杂的运动任务。
研究背景
-
背景介绍:
近年来,仿人机器人在执行复杂任务方面取得了显著进展,主要得益于强化学习(RL)的应用。然而,仿人机器人的复杂性,包括规划复杂的奖励函数和训练整个复杂系统的难度,仍然是一个显著的挑战。 -
研究内容:
该问题的研究内容包括开发一种名为Adam的全尺寸仿人机器人,并提出一种基于对抗性运动先验的全身模仿学习框架。该框架不仅适用于Adam,也适用于一般的仿人机器人。 -
文献综述:
该问题的相关工作包括波士顿动力公司的Atlas机器人、特斯拉的Optimus机器人、Cassie机器人及其仿人版本Digit、Unitree的H1机器人、Apptronik的Apollo机器人以及OpenAI的1X机器人公司等。这些工作展示了仿人机器人在不同领域的应用和发展。
研究方法
这篇论文提出了基于对抗性运动先验的全身模仿学习框架。具体来说:
-
对抗性模仿学习:
采用生成对抗模仿学习(GAIL)中的AMP方法,通过对抗性判别器来评估代理生成的状态转移与参考演示之间的相似性。判别器的目标是区分来自代理和参考演示的状态转移,从而引导代理生成更接近参考演示的运动。 -
模仿奖励:
rI=max[0,1−41(D(otD,ot+1D)−1)2]
通过模仿奖励函数来指导策略训练,公式如下:其中,D是判别器,otD和ot+1D是从策略中采样的状态转移。
-
端到端强化学习:
在全身模仿学习框架中,引入了协调任务奖励,包括命令奖励、周期性奖励和正则化奖励,以增强机器人在世界坐标系下的控制能力,并促进从仿真到现实的平滑过渡。
实验设计
-
训练设置:
使用无模型的强化学习算法PPO在4096个Isaac Gym模拟环境中并行训练策略。动作由25维向量表示,观察值包括机器人的线性和角速度、IMU测量的重力向量方向等。 -
域随机化:
通过调整机器人的质量分布、质心位置、电机强度、冲击力和外部力等参数,模拟不同的动态环境,以增强策略的鲁棒性。
结果与分析
-
交叉验证:
在Webots和Isaac Gym两个仿真平台上进行交叉验证实验,结果表明模型在不同平台上的表现一致,验证了模型的可靠性。 -
实际测试:
在真实环境中进行测试,展示了机器人从站立到跑步状态的平滑过渡,证明了模型的有效性和实际应用潜力。
结论
这篇论文在仿人机器人Adam上实现了全身模仿学习框架,使其在复杂步态任务中的表现与人类相当,并首次在仿人机器人中展示了“脚跟到脚尖”的过渡和直膝运动等人类的特征。实验结果表明,该框架具有实用性和高效性,为进一步研究仿人机器人提供了巨大的潜力。未来计划集成更多的感知模块,使Adam能够在综合感知条件下模仿人类动作。
这篇论文通过创新的模仿学习框架,展示了仿人机器人在复杂运动任务中的潜力,具有重要的理论和实践意义。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何提高人形机器人在复杂运动任务中的表现。尽管强化学习(RL)在机器人控制中取得了显著进展,但由于人形机器人的复杂性和训练难度,仍存在显著挑战。
- 研究难点:该问题的研究难点包括:规划复杂的奖励函数、训练整个复杂系统、传统控制算法在未知或动态变化环境中的鲁棒性和泛化性不足、深度神经网络的可解释性问题以及Sim2Real差距。
- 相关工作:该问题的研究相关工作包括:波士顿动力公司的Atlas和Spot机器人使用模型预测控制(MPC)算法展示极限机动性;Tesla的Optimus和Figure的机器人从人类数据中学习执行复杂桌面操作任务;Cassie和Digit机器人通过电机驱动成功跨越多种地形;Unitree的H1机器人和Apptronik的Apollo机器人;OpenAI收购1X机器人公司并提出具身智能的发展计划。
研究方法
这篇论文提出了一种基于对抗性运动先验的人形机器人全身模仿学习框架,用于解决人形机器人在复杂运动任务中的表现问题。具体来说,
- 对抗性运动先验(AMP):AMP方法通过引入一个判别器D来区分代理和参考演示的状态转移。判别器观察包含每个驱动关节的速度和位置以及两只手和两只脚的位置。公式如下:
Lexpert=E(otD,ot+1D)∼D[(D(otD,ot+1D)−1)2]
其中,otD和ot+1D是从参考演示中采样的状态转移。
2. 梯度惩罚:为了稳定训练,对参考样本的梯度进行惩罚:
LGP=E(otD,ot+1D)∼D[∥▽D(otD,ot+1D)∥2]
- 总AMP损失:将专家损失、策略损失和梯度惩罚结合起来:
LAMP=21Lexpert+21Lpolicy+λGPLGP
- 模仿奖励:策略训练的模仿奖励函数为:
rI=max[0,1−41(D(otD,ot+1D)−1)2]
- 端到端强化学习:为了在世界坐标系下控制运动方向,生成交替更自然的步态,引入了协调任务奖励,包括命令奖励、周期性奖励和正则化奖励。命令奖励公式为:
rcom=∑λiexp(−ωi(vdesi−vti)i∈(x,y,yaw)
周期性奖励公式为:
rper=∑αiE[Ii(ϕ)]Vi(st)
正则化奖励包括动作差异、自由度限制、自由度速度、自由度加速度等,公式为:
\exp\left(-0.05\left\\|a_{t}-a_{t-1}\right\\|_{2}\right)
实验设计
-
训练设置:使用Proximal Policy Optimization(PPO)算法在4096个Isaac Gym模拟环境中并行训练策略。观察包括机器人的线速度和角速度、重力的平均速度和方向、每个关节的位置和速度。
-
域随机化:通过调整质量、质心位置、电机强度、脉冲、外力和线速度噪声来应对建模差异、传感器噪声和不可观测的扰动和冲击。

-
交叉验证和反馈微调:使用Webots和Isaac Gym进行全面的交叉验证实验,评估模型在接近真实世界条件下的有效性。此外,还进行了现实世界的测试,验证模型的实用性和潜力。

结果与分析
- 训练效果:在4096个Isaac Gym模拟环境中并行训练策略,确保Adam的平滑训练过程。
- 交叉验证结果:在Webots和Isaac Gym上的交叉验证实验表明,人形机器人在不同平台上的步态同步且一致,验证了模型的可靠性。
- 现实世界测试:人形机器人在现实世界中的无缝跑步状态转换,展示了模型的有效性和实际部署的潜力。
总体结论
本文实现了一种基于对抗性运动先验的人形机器人全身模仿学习框架,使Adam在复杂步态任务中的表现与人类相当,并在人形机器人中首次展示了“脚跟到脚趾”转换和直膝运动等人性化特征。实验结果表明,该框架在实际应用中具有高效性和实用性,为人形机器人研究的进一步发展提供了新的视角和数据支持。未来计划整合更多的感知模块,使Adam能够在综合感知条件下模仿人类运动。
论文评价
优点与创新
- 创新的人体仿生机器人设计:开发了名为“Adam”的全尺寸人体仿生机器人,其肢体运动范围接近人类,且具有低成本和维护方便的显著优势。
- 全身模仿学习框架:设计并验证了一种新的全身模仿学习框架,有效解决了强化学习中复杂的奖励函数设置问题,大大减少了仿真到现实的差距,提高了机器人的学习能力和适应性。
- 对抗性运动先验:引入了对抗性运动先验(AMP)方法,使机器人能够在复杂运动任务中展示出高度类似人类的特性。
- 多种交叉验证和反馈调整步骤:在框架中加入了大量的交叉验证和反馈调整步骤,不仅展示了机器人在执行复杂运动任务时的高度人类化表现,还为未来的人体运动学习和优化提供了新的视角和数据支持。
- 端到端的强化学习:引入了协调任务奖励,包括命令奖励、周期性奖励和正则化奖励,以生成更自然的步态并促进从仿真到现实的平滑过渡。
- 领域随机化:通过领域随机化策略,解决了机器人及其环境建模差异、传感器噪声和不可观测扰动等关键不确定性,增强了模型的鲁棒性和适应性。
不足与反思
- 感知模块的集成:当前框架支持感知模块的集成,但未来计划引入更多传感器,以便在综合感知条件下模仿人类运动。
关键问题及回答
问题1:Adam机器人在设计和结构上有哪些创新之处?
Adam机器人在设计和结构上有多个创新之处。首先,Adam采用了模块化设计,全身使用了25个QDD(准直接驱动)力控PND(压力控制非线性驱动器)执行器,这使得机器人在实验过程中易于维修,并进一步降低了维护成本。其次,Adam的腿部装有四个QDD高灵敏度、高反向驱动的执行器,最大扭矩可达340N·m,确保了机器人具有接近人类的运动范围。此外,Adam的手臂有五个自由度,腰部有三个自由度,全身采用全栈自研设计,具备实时通信网络PND(PND网络)和执行器,运动控制计算机为第12代Intel i7处理器(Intel NUC),并配备了PND RCU(机器人控制单元),能够进行大规模并行动态仿真和神经网络训练,适应复杂多变的人类社会环境。
问题2:对抗性运动先验(AMP)方法在Adam机器人中的应用是如何实现的?
对抗性运动先验(AMP)方法在Adam机器人中的应用主要通过引入判别器D来实现。判别器D的任务是区分代理和参考演示的状态转移。具体步骤如下:
- 判别器观察:判别器观察包含每个驱动关节的速度和位置以及两只手和两只脚的位置。
- 专家损失:计算判别器从参考演示中采样的状态转移的预测损失:
Lexpert=E(otD,ot+1D)∼D[(D(otD,ot+1D)−1)2]
- 策略损失:计算判别器从策略中采样的状态转移的预测损失:
Lpolicy=E(otD,ot+1D)∼D[(D(otD,ot+1D)+1)2]
- 梯度惩罚:对参考样本的梯度进行惩罚,以稳定训练:
LGP=E(otD,ot+1D)∼D[∥▽D(otD,ot+1D)∥2]
- 总AMP损失:将专家损失、策略损失和梯度惩罚结合起来:
LAMP=21Lexpert+21Lpolicy+λGPLGP
通过上述步骤,AMP方法指导判别器对样本进行评分,使得参考运动的评分接近+1,而策略生成的运动评分接近-1。策略的目标是生成足够令人信服的运动,以使判别器给出较高的评分,从而展示其模仿参考运动的能力。
问题3:Adam机器人在实验中如何利用人类运动数据进行训练?
Adam机器人在实验中通过多种方式利用人类运动数据进行训练,以确保模型能够学习和模仿多样化的运动特性。具体方法包括:
- 使用公共运动捕捉数据库:Adam使用了SFU和CMU两个公共运动捕捉(mocap)数据库,这些数据库包含了多种人类活动(如日常动作、体育运动、舞蹈和战斗动作)的运动捕捉序列。通过整合这两个数据库,Adam获得了一个多样化且高质量的人类全身运动数据集。
- 自定义运动捕捉:除了公共数据集,Adam还使用高精度运动捕捉设备进行自定义运动记录,特别是那些难以在公共数据库中找到的特殊动作或序列。这些自定义数据不仅增加了数据集的多样性,还使模型能够更精确地进行微调和优化,以适应特定的运动任务和挑战。
- 手动校准和转换:Adam的研究团队手动校准和转换每个数据集,以确保高质量的运动数据适合Adam。这一过程避免了将人类运动数据直接用于优化的问题,而是专注于为Adam获取定制化的高质量运动数据。
全身仿人机器人运动以人类为参考
张强 1,∗,崔鹏 2,∗,严大卫 2,孙景凯 1,段一坤 3,张亚瑟 2,徐仁杰 1,†
2024年2月28日 [计算机科学研究与进展][计算机科学研究与进展]arXiv:2402.18294v1[计算机科学研究与进展]2=传输(θ1,θ2)2
摘要——近期,由于强化学习(RL)的应用,仿人机器人在执行复杂任务的能力上取得了显著进步。然而,仿人机器人的固有复杂性,包括规划复杂奖励函数的难度以及训练整个复杂系统的挑战,仍然构成一个显著的难题。为了克服这些挑战,经过多次迭代和深入研究,我们精心开发了一款全尺寸仿人机器人“亚当”,其创新结构设计极大地提高了模仿学习过程的效率和效果。此外,我们还开发了一种基于对抗性运动先验的新颖模仿学习框架,不仅适用于亚当,也普遍适用于仿人机器人。利用该框架,亚当能够在运动任务中展示出前所未有的类人性特征。我们的实验结果显示,所提出的框架使亚当能够在复杂的运动任务中实现与人类相当的性能,这标志着首次将人类运动数据用于全尺寸仿人机器人的模仿学习。如需更多视频演示,请访问我们的YouTube频道:https://www.youtube.com/watch?v=7hK2ySYBa1I
一、引言
近年来,仿人机器人领域受到了广泛关注,众多研究机构和公司相继发布了尖端创新和研究结果,标志着该领域的快速发展和崛起。波士顿动力公司的Atlas机器人1展示了类似跑酷的动作能力;特斯拉的Optimus和Figure的仿人机器人2通过学习人类数据来执行复杂的桌面操作任务;双足机器人Cassie及其仿人版Digit 3由电机驱动,成功跨越多种地形;著名的腿部机器人公司Unitree推出了他们的仿人机器人产品H1;Apptronik开发了全由推杆电动马达驱动的仿人机器人Apollo;在通用人工智能领域享有盛誉的OpenAI收购了1X机器人公司7,并提出了具身智能的发展计划。上述情况表明,仿人机器人正成为研究人员和公司的关键方向之一,掌握仿人机器人的核心技术对于弥合数字通用人工智能与实体硬件之间的差距至关重要。

传统机器人控制算法通常依赖于精确的数学模型和预定义的运动规划,在过去对于四足、双足和人形机器人的运动任务已被证明非常有效。值得注意的是,波士顿动力公司的Atlas和Spot机器人通过使用模型预测控制(MPC)算法展示了这些方法的有效性,在各种演示中展现了令人印象深刻的极端机动性。然而,这些算法经常依赖于对环境的准确建模,这在鲁棒性和泛化性方面可能引入重大挑战,特别是在未知或动态变化的环境中,传统控制算法的性能可能会显著下降,限制了在更广泛应用场景中的实用性。此外,这种对准确建模的依赖还需要高水平的专门知识来构建和维护这些模型,增加了开发和调试的复杂性。
传统机器人控制算法在适应性、灵活性和用户友好性方面明显有限,尽管它们在特定环境中表现出优异的性能,这促使研究人员探索替代方法来克服这些障碍,设计出更智能、更具适应性的机器人控制策略。其中,基于深度神经网络的强化学习算法在腿部机器人的控制中取得了有希望的结果。通过与环境的互动,深度强化学习算法可以学会自主导航。
学习算法能够自主发现有效的策略来执行复杂任务,并且可以扩展到未知或动态变化的环境中,这为机器人提供了前所未有的适应性和灵活性。
强化学习算法在多种腿部机器人中取得了显著进展,但在仿人机器人领域的应用仍然缺乏足够的探索。这主要归因于以下几个因素:首先,大多数仿人机器人价格昂贵且维护困难,这对于资金有限的研究机构来说是一个相当大的障碍;其次,深度神经网络的可解释性问题以及深度强化学习训练过程中的Sim2Real差距使得模型难以转移到实际应用中;最后,仿人机器人的复杂性远远超过其他腿部机器人,这使得在训练过程中设计奖励函数和训练策略更具挑战性。
为了应对这些挑战,经过反复设计和深入探索,我们推出了电机-关节驱动的仿人机器人“亚当”,与传统液压驱动机器人相比具有显著的成本优势,其模块化设计便于实验期间的维修,并进一步降低了维护成本。此外,我们的高性能驱动器确保了机器人的卓越机动性,使其肢体运动范围接近人类。鉴于在强化学习中设置复杂奖励函数的难度,我们采用了一种创新策略,利用人类运动数据来指导学习过程。结合我们的模仿学习训练框架,Adam 在实验中的运动任务表现令人印象深刻。
总结来说,我们介绍了一款全新的人形机器人 Adam,并为人形机器人的学习、适应和优化提供了新的方法和实验验证,为人形机器人研究与发展开辟了新途径。本文的贡献可概括为以下三点:
-
我们开发并详细设计了一款创新型的仿生人形机器人 Adam,其肢体不仅具有接近人类的运动范围,同时在成本低廉和维护简便方面也具有显著优势。
-
我们设计并验证了一种新颖的人形机器人全身模仿学习框架,有效解决了强化学习中人形机器人面临的复杂奖励函数设置问题,大幅缩小了仿真到现实的差距,并提高了人形机器人的学习能力和适应性。
-
为了应对复杂人形机器人强化学习控制算法中的仿真到现实挑战,我们在框架中加入了众多交叉验证和反馈调整步骤。我们不仅展示了机器人在执行复杂运动任务时的高度类人性表现,还提供了新的视角和数据支持。
用于未来的人形机器人运动学习和优化。
二、相关工作
A. 腿部机器人的运动
随着腿部机器人运动作为实现人形机器人的基础,其发展已取得显著进步。强化学习(RL)的融入[7]、[8]在此领域发挥了关键作用。机器人Cassie利用周期性参数化奖励函数[9],实现了多种行走和跑步模式,甚至通过预先优化的步态创下了100米冲刺的世界吉尼斯纪录[10]。Jeon等人[11]强调了基于势能的奖励塑形在加速学习和增强腿部运动鲁棒性方面的有效性。同样,Shi等人[12]通过引入辅助力课程,拓宽了腿部机器人的能力,使其能够在没有明确参照的情况下进行敏捷的运动学习。HRP-5P人形机器人通过利用执行器电流反馈[13],展示了卓越的步行能力;而Kim等人[14]提出了一种基于扭矩的方法,有效地弥合了仿真训练与现实世界应用之间的差距。DeepMind的研究[15]是一项创新尝试,通过独特的教师-学生蒸馏和自我对弈方法,使微型人形机器人掌握了复杂的足球技能。此外,在Digit人形机器人中使用基于注意力机制的变压器,促进了更适应性和多功能的运动模式[16]。最近,Tang等人[17] 采用对抗性批评组件和特别设计的Wasserstein距离来从人类参考中迁移运动。然而,Adam具有更大的灵活性,整体上更像人类,这导致在实际机器人实验中有更好的表现。
B. 从人类参考中学习
人类凭借其先进的智能和多样的运动能力,展现出蕴含丰富信息的复杂动作模式。通过从人类参考中学习人类行为的洞察力,可以极大地增强机器人的适应性。传统的行为克隆方法依赖于手动编程,被证明是耗时且不灵活的[18]、[19]。此外,手动定义类人机器人复杂多样的运动技能提出了重大挑战[20]、[21]。
近年来,模仿学习(IL)策略已经变得突出,涉及跟踪参考关节轨迹或提取的步态特征[22]-[25]。然而,这些跟踪技术通常在单个运动剪辑上操作,导致在不同运动模式之间过渡时出现不连续性。为了解决这一限制,Peng等人引入了生成对抗模仿学习(GAIL),他们提出了两种创新方法:AMP和继任者ASE[26]-[28]。这些方法使基于物理的化身能够在隐式模仿来自广泛非结构化数据集的多样运动风格的同时执行客观任务。AMP的变体已成功应用于学习敏捷的四足动物运动能力和地形适应技能[29]-[33]。此外,唐等人引入了一种带软边界约束的水斯坦对抗模仿系统,进一步增强了AMP方法的能力[17]。为了促进参考运动向机器人的传递,许多工作引入了再定位技术[17]、[34]、[35],这些技术考虑了原始骨架和几何一致性,使得能够进行精确的动态建模和复杂的平衡控制器设计。
III. 初步
A. 人形机器人亚当的结构
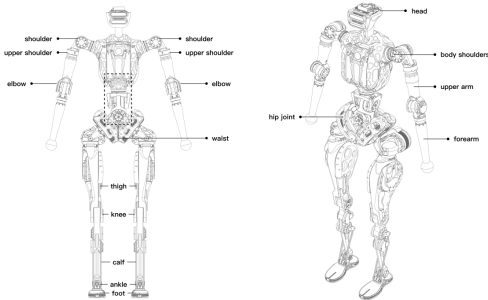
在本文中,我们使用了亚当的轻量版进行实验。亚当(Lite)配备了遍布全身的25个准直接驱动、力控制的脉冲神经驱动器(PND)执行器,身高1.6米,重60公斤。其腿部装有四个QDD高灵敏度、高度可逆向驱动的执行器,最大扭矩可达340牛·米。手臂有五个自由度,腰部有三个。这种完全模块化、高度可重复使用的柔性执行器设计,加上高度仿生的躯干配置,赋予了亚当卓越的机动性和适应性。整个身体采用全栈自主研发设计,实时通信网络PND(PND网络)以及PND执行器。运动控制计算机是第12代英特尔i7处理器(英特尔迷你电脑)和PND遥控单元(RCU)。个人导航设备(PND)遥控单元集成了所有执行器、电池管理系统(BMS)、电源管理,并配备了一个具有网络管理功能的16端口千兆以太网可编程交换机,形成了机器人的感知与控制通信枢纽。这种配置使亚当能够执行大规模并行动态仿真和神经网络训练,实现真正适用于实际服务场景的多样化全身运动控制,适应复杂多变的人类社会环境。可任选配备灵巧的手部和视觉模块。由于本文侧重于盲动任务,这些部件未被包括在内。亚当(轻量版)全身结构的示意图如图2所示,其关节结构信息详见表I。
表I:人形机器人亚当的规格参数。
| Humanoid Robot | Adam(Lite) |
|---|---|
| Height | 1.6M |
| Weight | 60 Kg |
| Full-body degrees of freedom | 25 |
| Single-leg degrees of freedom | Hip x3+ Knee x1+ Ankle x2 |
| Single-arm degrees of freedom | Shoulder x3+Elbow x2 |
| Waist degrees of freedom | 3 |
B. 运动捕捉与重新定位
在我们的研究中,我们探索了多种人类运动数据源以丰富我们的训练集,确保我们的模型能够学习到多样化的人类动作特征。最初,我们使用了两个公共的运动捕捉(mocap)数据库:四川师范大学的运动捕捉数据集和卡内基梅隆大学的运动捕捉数据集。
数据集9。两个数据集都包含多个动作捕捉序列,涵盖了广泛的人类活动,包括日常动作、体育动作、舞蹈和战斗动作。通过整合这两个数据库,我们为亚当提供了一个多样化且高质量的人体全身运动数据集,这对于训练机器人理解和模仿人类运动模式至关重要。
除了公共数据集之外,我们还使用高精度动作捕捉设备进行定制动作记录。这种方法使我们能够捕捉特定的动作数据,尤其是那些为特定实验需求而设计的特殊动作或序列,这些在公共数据库中很难找到。这些定制动作数据不仅增加了我们数据集的多样性,还使我们能够更精确地微调和优化我们的模型,使其适应特定的动作任务和挑战。我们没有像在类似humanMIMIC[17]的方法中那样将重新定位作为一个优化问题来处理。我们的目标是为亚当获取高质量的定制动作数据,这促使我们自行手动校准和转换每个数据集。
C. 在腿部机器人上的强化学习
强化学习应用于腿部机器人被建模为一个部分可观测的马尔可夫决策过程(POMDP),由元组(S,O,A,R,p,γ)定义,其中S定义了状态空间,包括环境的所有状态。O表示部分观测空间,代表状态空间S的一个子集,仅覆盖代理能够观测到的环境方面。同时,A 指定了动作空间,表示智能体能够执行的所有动作。奖励函数,用 R 表示,对每个状态-动作对分配一个标量奖励。转移概率,用 p 表示,指定从当前状态转移到新状态(在选定动作之后)的可能性。折扣因子 γ∈[0,1] ,用于确保未来奖励得到适当的加权。
在此框架下,在每个时间步 t,智能体从环境中观察到 ot∈O 。基于这一观察,智能体输出一个动作 at∈A ,该动作是从策略 π(at∣ot) 中抽取的。随后,环境转移到一个新的状态 st+1 ,由概率分布控制。
st+1根据条件概率p(st+1∣st,at)进行采样,代理因此获得奖励rt=R(st,at)。该目标函数被形式化为最大化接收到的奖励:
argmaxθE(st,at)∼pθ(st,at)[∑t=0T−1γtrt](1)
其中T表示部分可观测马尔可夫决策过程(POMDP)的时间范围。
四、方法
A. 通过对抗性运动先验利用人类参考进行学习
我们的人形机器人模仿框架建立在AMP之上。在我们的框架中,判别器D输出从智能体采样的状态转移与从参考演示D采样的状态转移之间的相似度。选择输入判别器的观察值otD∈R58至关重要,以确保具有相似状态转移的机器人能够执行相似的移动风格。判别器观察值包含速度、每个驱动关节的位置以及人形机器人的两只手和两只脚的位置。在每个时间步骤,我们从演示中随机采样状态转移,并将它们输入到判别器中,以获得专家预测损失,从而让判别器能够区分这些状态转移。
Lexpert=E(otD,ot+1D)∼D[(D(otD,ot+1D)−1)2]
对从策略中抽样的状态转换也执行相同的操作,
Lpolicy=E(otD,ot+1D)∼D[(D(otD,ot+1D)+1)2]
我们遵循[27]的方法,对参考样本的梯度进行惩罚以稳定训练。
LGP=E(otD,ot+1D)∼D[∥▽D(otD,ot+1D)∥2](4)
最后,我们得出总AMP损失为,
LAMP=21Lexpert+21Lpolicy+λGPLGP(5)
AMP损失函数指导判别器对样本进行评分,对于真实参考动作给予接近+1的分数,而对于由策略生成的动作则接近-1。该策略的目标是创建足够令人信服的动作,以使判别器给出更高的分数,从而证明其能够紧密模仿参考动作。
随后,该策略训练的模仿奖励公式表示为,
rI=max[0,1−41(D(otD,ot+1D)−1)2](6)
其中,otD,ot+1D 是从策略中抽样的。
B. 在仿人机器人上进行端到端强化学习
同时,参考运动中的移动方向通常被限制在局部坐标系中。为了便于在世界坐标系下进行控制,生成更自然的步态,并在具有挑战性的地形上实现从仿真到现实的更有效过渡,我们引入了协调任务奖励。任务奖励由三个部分组成:指令奖励、周期性奖励和正则化奖励。指令奖励强制机器人沿指令方向单独移动,其公式为,
rcom=∑λiexp(−ωi(vdesi−vti)i∈(x,y,yaw)(7)
其中,λi 和 ωi 是每个指令方向的奖励权重,vdes 是沿特定方向期望的速度向量,vt 是时间 t 的速度向量。
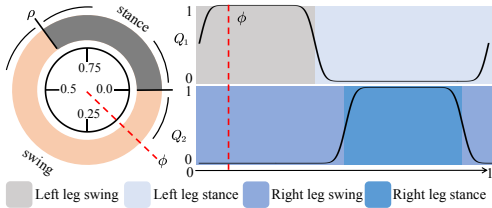
为了促进达到期望的步态性能,我们引入了与模仿奖励一致的周期性奖励。这种方法自然地促进了机器人在保持稳定步态方面的维护。然而,如果期望变化步态,则建议省略此奖励函数。我们遵循[9]的方法,通过摆动阶段和支撑阶段来制定周期性奖励,摆动阶段以脚在空中移动为特征,支撑阶段则以脚牢牢地踩在地面上为特征。每个周期性奖励项由系数 αi、阶段指示器 Ii(ϕ)、以及有值的阶段奖励函数 Vi(st) 组成,ϕ 是周期时间,i 表示阶段是支撑阶段还是摆动阶段。摆动阶段和支撑阶段按顺序排列,并通过建立比率 ρ∈(0,1) 共同跨越整个周期持续时间。这种配置确保摆动阶段占据相当于 ρ 的持续时间,紧接着是支撑阶段,其持续时间为 1−ρ。单脚奖励如下所示,
rperVstance(st)Vswing(st)=∑αiE[Ii(ϕ)]Vi(st)=exp(−10Ff2)=exp(−200vf2)(8)
其中,Ff 是每个足的法向力,vf 是每个足的速度。为了对相位指示器 Ii(ϕ) 进行建模,我们遵循[36]使用冯·米塞斯分布的数学期望。相位指示器的可视化显示在图4中。并且我们将其公式化为,
Q1Q2=Istance(ϕ+θleft)=Istance(ϕ+θright)(9)
其中,θ左 和 θ右 是左右腿在周期时间内的偏移量。除了正常的周期性奖励外,我们还会计算步速、高度差以及在摆动阶段的对称性方面的奖励,以获得更自然的步态风格。足部速度跟踪奖励的公式为,
\begin{aligned} q^{i}&=clip(\frac{\phi}{\rho}-0.5,0,1)\\ r(s_{t})&=\left\{\begin{array}[]{ll}16(q^{i}v_{f}^{i})^{2}&0\leq q_{i}\leq 0.6,\\ 0&q_{i}>0.6.\end{array}\right.\end{aligned}\qquad(10)
其中 i∈(左,右),“剪辑”是用于将变量值限制在0到1范围内的函数。脚步速度跟踪奖励鼓励机器人在摆动阶段执行更高的脚步速度。高度差奖励是,
\begin{aligned}& q^{i}=\frac{\phi}{\rho}\\ &\delta h=h_{f}^{i}-h_{f}^{-i}-0.02\\ & r(s_{t})=\left\{\begin{array}[]{ll}2exp(-25(|\delta h|)&0\leq q_{i}\leq 0.3,\\ 0&q_{i}>0.3.\end{array}\right.\end{aligned}
其中 hfi 表示第 i 英尺的高度,hf−i 表示另一侧英尺的高度。该函数的目的是在步态周期的某些早期阶段,仅基于足部高度差来计算奖励。对称奖励的公式如下,
dttfδftδltr(st)=ptleft−ptright=(E[Ileft(ϕ)]>0.5)∧(E[Iright(ϕ)]>0.5)=tf⋅dt+¬tf⋅δft−1=¬tf⋅δft+tf⋅dt=3.3tfexp(−10∣∣dt+δlt∣∣1)(12)
其中,pti 是足部末端执行器的3维位置。该函数基于步态摆动的对称性计算奖励,考虑了左右脚的步态相位以及两脚之间的距离。
为了增强仿真到现实的转移鲁棒性,我们将规则化奖励纳入综合奖励结构中。这些奖励强制执行运动约束,强调平滑性和安全性。每个奖励的详细模拟在表II中展示。自由度(DoF)限制奖励保持运动在机器人的物理能力范围内,确保其不会尝试可能损坏其机构或超出操作范围的移动。b表示自由度向量角度。blower和bupper是关节限制的上限和下限。自由度速度奖励促使系统维持最佳速度。同样,自由度加速度奖励鼓励平稳的速度增加和减少,有助于整体稳定性。对于机械臂,应用臂部自由度惩罚。
表II:规则化奖励
| Item | Detail |
|---|---|
| Action differential | $\exp\left(-0.05\left\ |
| DoF limits | exp(−2.0(min(0,b−bupper) −max(0,b−blower))) |
| DoF velocity | $\exp\left(-1\times 10^{-4}\ |
| DoF acceleration | $\exp\left(-1\times 10^{-7}\ |
| Arm DoF penalty | $\exp\left(\left\ |
| Orientation differential | exp(−300(roll2+pitch2) ) |
| Torso yaw | $\ |
| Torques | $\exp\left(-5\times 10^{-4}\left\ |
表三:领域随机化范围
| Randomization Item | Range | Unit |
|---|---|---|
| Mass | [−0.05,0.05] | |
| Center of mass alone x | [-0.05,0.05] | m |
| Center of mass alone z | [−0.05,0.05] | m |
| Motor strength | [0.7,1.4]× default | N·m |
| Impulse | [0,0.8] | m/s |
| External force | [−500,500] | N |
| Linear velocity | [0.8,1.2]× default | m/s |
为了阻止大量持仓或动作。躯干偏航奖励和方向差异奖励特定于围绕机器人垂直轴的旋转动作。这种控制对于平衡和定位至关重要,尤其是在仿人机器人中。
五、实验
甲、训练和实施细节
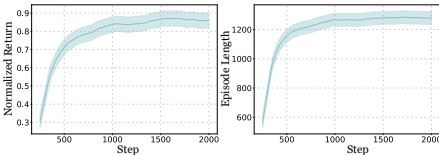
1)训练设置:我们通过一种无模型的强化学习算法——近端策略优化(Proximal Policy Optimization,简称PPO)[37],在4096个艾萨克(Isaac)仿真环境中并行地训练我们的策略。在仿人机器人行走场景中,动作由一个25维向量at∈R25表示,该向量指定了每个驱动关节根据比例-导数(PD)控制器所期望的位置调整。观测值,记作ot∈R91,包括机器人当前的线速度和角速度、(x,y,z)方向的平均速度,以及机器人基座框架内重力向量的方向,所有这些数据均由惯性测量单元(IMU)测量。每个关节的位置和速度由执行器的编码器捕获。引入一个指令ct=(vdesx,vdesy,ωdeszaw),以指定沿机器人基座框架的x轴、y轴和偏航的期望速度。周期性观测值包括周期时间和摆动相位比ρ的正弦和余弦值,以动态调整步态。此外,观测值中还加入了根的高度,以管理仿人机器人的姿势。为了提升性能,上一个时间步骤中执行的动作也会被考虑进来。我们的框架确保亚当(Adam)有一个平稳的训练过程,如图6所示。
2)领域随机化:这种随机化策略旨在解决三个关键的不确定性:机器人及其环境的建模差异、传感器噪声以及不可观测的干扰和脉冲。这些动态特性在表三中表示,其数值在指定范围内进行调整。各个机器人身体(例如,躯干)的质量会变化以模拟不同的重量分布。质心会在特定方向上随机移动。这些技术帮助策略适应……
机器人组件的不确定性。电机力量影响扭矩输出以应对电机的不确定性。此外,通过在机器人根部增加x-y平面上的速度来施加脉冲,复制突然外部冲击的效果。外力也直接作用于机器人的身体,以模拟不可观测的环境力。另外,噪声被注入到线速度中,以模拟速度估计误差。在各种条件下以及应对外部干扰进行了一系列测试,其结果如图5所示。
B. 交叉验证和反馈微调
我们使用Webots 10和Isaac Gym作为仿真平台进行了全面的交叉验证实验,以评估我们的模型在紧密模仿现实世界条件的环境中的有效性。值得注意的是,Webots提供先进的物理仿真能力,使我们能够在不同平台上验证我们的策略,同时微调超参数以达到最佳性能。图7生动地展示了这一点,其中仿人机器人的步态在两个模拟器上都显得同步且一致,这强调了模型的可靠性。此外,我们还进行了现实世界的测试,以进一步验证我们模型的实用适用性。图1捕捉了仿人机器人在现实世界中从站立状态到跑步状态的平稳过渡,突显了模型的有效性和实际部署的潜力。
六、结论
在本文中,我们在仿人机器人亚当上实现了一个全身模仿学习框架,其在复杂步态任务中的表现可与人类相媲美,并且首次在人形机器人中展示了类似人类的特征,如“跟到趾”转换和直膝动作。我们的实验证明了该框架的实用性和效率,突显了其在人形机器人学研究中的巨大潜力。此外,我们的框架支持感知模块的集成,未来我们计划整合更多传感器,使亚当能够在综合感知条件下模仿人类动作。
[1] 维基百科,“Optimus(机器人)”,https://en.wikipedia.org/wiki/Optimus_(robot),2024年,访问日期:2024年2月28日。
[2] Y. Gong, R. Hartley, X. Da, A. Hereid, O. Harib, J.-K. Huang, 和 J. Grizzle,“反馈控制一种卡西双足机器人:行走、站立和骑赛格威”,在2019年美国控制会议(ACC)上发表。IEEE,2019年,第4559-4566页。
[3] Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, 和 K. Sreenath,“用于多功能、动态和强健双足运动的强化学习”,arXiv预印本arXiv:2401.16889,2024年。
[4] Z. Li, X. Cheng, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, 和 K. Sreenath,“用于双足机器人强健参数化运动控制的强化学习”,在IEEE国际机器人与自动化会议(ICRA),中国西安,2021年6月。
[5] C.E. Garcia, D.M. Prett, 和 M. Morari,“模型预测控制:理论与实践——综述”,自动化学报,第25卷,第3期,第页。335-348,1989年。
[6] N. 鲁丁(N. Rudin)、D. 赫勒(D. Hoeller)、P. 里斯特(P. Reist)和M. 胡特(M. Hutter),“使用大规模并行深度强化学习在几分钟内学会行走”,载于《机器人学习会议》。PMLR,2022年,第91-100页。
[7] 李志(Z. Li)、彭晓波(X.B. Peng)、阿贝尔(P. Abbeel)、莱文(S. Levine)、贝尔瑟斯(G. Berseth)和斯里南斯(K. Sreenath),“通过强化学习实现稳健且多功能的双足跳跃控制。”
[8] 西克曼(J. Siekmann)、格林(K. Green)、瓦里拉(J. Warila)、费尔南德斯(A. Fern)和赫斯特(J. Hurst),“通过仿真到现实的强化学习实现双足盲走楼梯”,arXiv预印本arXiv:2105.08328,2021年。
[9] 西克曼(J. Siekmann)、戈德塞(Y. Godse)、费尔南德斯(A. Fern)和赫斯特(J. Hurst),“通过周期性奖励组合实现所有常见双足步态的仿真到现实学习”,载于2021年IEEE国际机器人与自动化会议(ICRA)。IEEE,2021年,第7309-7315页。
[10] 克劳利(D. Crowley)、道(J. Dao)、段宏(H. Duan)、格林(K. Green)、赫斯特(J. Hurst)和费尔南德斯(A. Fern),“优化双足运动以进行100米短跑,并与人类跑步进行比较”,载于2023年IEEE国际机器人与自动化会议(ICRA)。IEEE,2023年,第12205-12211页。
[11] 郑世雄(S. H. Jeon)、海姆(S. Heim)、卡兹奥姆(C. Khazoom)和金在湖(S. Kim),“基于潜在奖励的学习仿人机器人运动能力基准测试”,载于2023年IEEE国际机器人与自动化会议(ICRA)。IEEE,2023年,第9204-9210页。
[12] 石峰(F. Shi)、小木由纪夫(Y. Kojio)、牧原健太(T. Makabe)、安斋俊光(T. Anzai)、小岛宽(K. Kojima)、冈田浩(K. Okada)和稻叶正明(M. Inaba),“通过辅助力课程无参考地学习双足运动技能”,载于《国际机器人研究研讨会》。施普林格,2022年,第304-320页。
[13] 辛格(R.P. Singh)、谢宗(Z. Xie)、杰贡迪特(P. Gergondet)和金兼广(F. Kanehiro),“利用电流反馈学习仿人机器人的双足行走”,IEEE Access,2023年。
[14] 金东(D. Kim)、金(G.)贝尔塞斯、施瓦茨和朴俊,“基于扭矩的深度强化学习,用于双足机器人上任务与机器人无关的学习,通过仿真到现实的迁移”,arXiv预印本arXiv:2304.09434,2023年。
[15]塔·哈拉诺贾、莫兰·B、莱弗·G、黄世华、蒂鲁马拉·D、沃尔夫迈尔·M、胡姆利克·J、图尼亚苏纳库洛·S、西格尔·N·Y、哈夫纳·R等,“利用深度强化学习为双足机器人学习敏捷足球技能”,arXiv预印本arXiv:2304.13653,2023年。
[16]伊万·拉多萨沃维奇、肖涛、张博、达雷尔·T、马利克·J和斯里纳斯瓦纳图尔·K,“利用变压器学习仿人机器人运动”,arXiv预印本arXiv:2303.03381,2023年。
[17]唐A、平山T、平山N、史F、川原K、小笠原K、冈田K、稻叶M,“HumanMIMIC:通过Wasserstein对抗性模仿学习仿人机器人的自然运动和过渡动作”,arXiv预印本arXiv:2309.14225,2023年。
[18]大场T、帕贾里宁J、诺伊曼G、巴尼埃尔J·A、阿贝尔P、彼得斯J等,“关于模仿学习的算法视角”,《机器人学基础与趋势》,第7卷,第1-2期,第1-179页,2018年。
[19]拉维钱德拉H、波利德罗普洛斯A·S、切尔诺娃S和比拉德A,“从示范中学习机器人学的最新进展”,《控制、机器人学与自主系统年度综述》,第3卷,第297-330页,2020年。
[20]博赫兹S、图尼亚苏纳库洛S、布雷克尔P、萨德吉F、哈森克吕弗L、塔萨Y、帕里斯托托E、胡姆利克J、哈拉诺贾T、哈夫纳R等,“模仿与再利用:从人类和动物行为中学习可重用的机器人运动技能”,arXiv预印本arXiv:2203.17138,2022年。
[21]韩L、朱Q、盛J、张C、谭T李一,张红,刘阳,周超,赵锐等,“使用强化学习和生成预训练模型在四足机器人上实现逼真的敏捷性和玩耍能力”,arXiv预印本arXiv:2308.15143,2023年。
[23] J. 范登堡,S. 米勒,D. 达克沃思,H. 胡,A. 万,徐阳峰,K. 戈德堡和P. 阿贝尔,“通过从人类引导的示范中迭代学习,机器人以超越人类的水平完成外科手术任务”,在2010年IEEE国际机器人与自动化会议上。IEEE,2010年,第2074-2081页。
[24]P.M.Kebria,A. Khosravi,S.M. Salaken,and S. Nahavandi,“基于卷积神经网络的自动驾驶车辆的深度模仿学习”,IEEE/CAA《自动化学报》,第7卷,第1期,第82-95页,2020年。
[25]L. Le Mero, D. Yi, M. Dianati, 和 A. Mouzakitis,“关于端到端自动驾驶车辆模仿学习技术的综述”,IEEE《智能交通系统交易》,2022年。
[26]J. Ho 和 S. Ermon,“生成对抗模仿学习”,《神经信息处理系统进展》,第29卷,2016年。
[27]X.B.彭,Z. 马,P. 阿贝尔,S. 莱文,和 A. 金泽,“Amp:用于风格化物理基础角色控制的对抗性运动先验”,ACM《图形学交易》(ToG),第40卷,第4期,第1-20页,2021年。
[28]X.B.彭,Y.郭,L.哈尔珀,S.莱文,和 S.费德勒,“Ase:用于物理模拟角色的大规模可复用对抗技能嵌入”,ACM《图形学交易》(TOG),第41卷,第4期,第1-17页,2022年。
[29] A. Escontrola, X. B. Peng, W. Yu, T. Zhang, A. Iscen, K. Goldberg, 和 P.阿贝尔,“对抗性运动先验是复杂奖励函数的良好替代品”,在2022年IEEE/RSJ智能机器人与系统国际会议(IROS)上发表。IEEE,2022年,第25-32页。
[30] E.沃伦韦德、M.比耶洛维奇、V.克莱姆、N.鲁丁、J.李和M.胡特,“通过强化学习中的多个对抗性运动先验掌握高级技能”,在2023年IEEE国际机器人与自动化会议(ICRA)上发表。IEEE,2023年,第5120-5126页。
[31] C.李、M.弗拉斯特利卡、S.布拉斯、J.弗雷、F.格里明格和G.马提乌斯,“通过对抗性地模仿粗略的部分示范来学习敏捷技能”,在机器人学习会议上发表。PMLR,2023年,第342-352页。
[32] J.吴、G.辛、C.齐和Y.薛,“使用对抗性运动先验学习稳健和敏捷的腿部运动”,IEEE机器人与自动化快报,2023年。
[33] Y.王、Z.江和J.陈,“野外放大:学习稳健、敏捷、自然的腿部运动技能”,arXiv预印本arXiv:2304.10888,2023年。
[34] K.浅泽和E.吉田,“基于同时变形参数识别和运动优化的仿人机器人运动重定向”,IEEE机器人学交易,第33卷,第6期,第1343-1357页,2017年。
[35] R.格兰迪亚、F.法什迪安、E.克诺普、C.舒马赫、M.胡特和M.比彻,“文档:用于将动作重定向到腿部机器人的可微优化控制”,ACM图形学交易(TOG),第42卷,第4期,第1-14页,2023年。
[36] J.H.朴,“双足机器人运动的阻抗控制”,IEEE机器人学与自动化交易,第17卷,第6期,第870-882页,2001年。
[37] J.舒尔曼、F.沃尔斯基、达尔瓦尔、拉德福德和克里莫夫,“近端策略优化算法”,arXiv预印本arXiv:1707.06347,2017年。
注释
1 波士顿动力公司图谱网站
2 Figure AI网站
3 敏捷机器人公司机器人网站
4 Unitree公司H1系列网站
5 Apptronik公司网站
6 OpenAI网站
7 1x科技公司网站
8 不列颠哥伦比亚大学机械与计算机工程系动作捕捉实验室网站
9 卡内基梅隆大学计算机学院动作捕捉实验室网站
10 Cyberbotics公司网站

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献391条内容
已为社区贡献391条内容

所有评论(0)