N8N查询超页限制数据并自动分流解决方案
N8N查询超页限制数据
需求简介
-
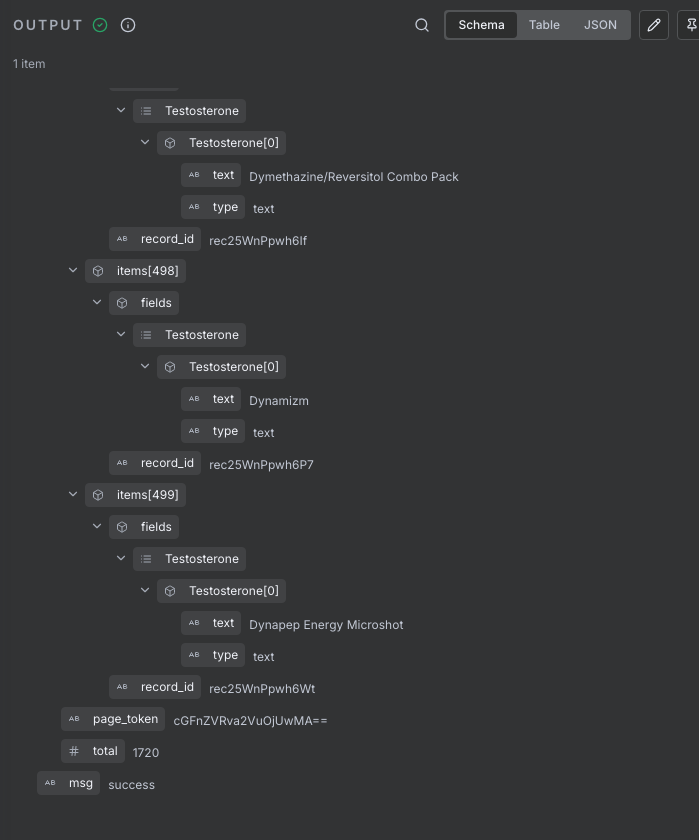
使用云端数据库时,一般分页大小会做出最大查询数,例如飞书多维表格的限制为500,如果查询超过500则会停留,如图:total有1720而具体记录只能查询到500
-
使用N8N进行循环分析时候每次都需要加入分流节点进行循环
技术痛点与解决思路
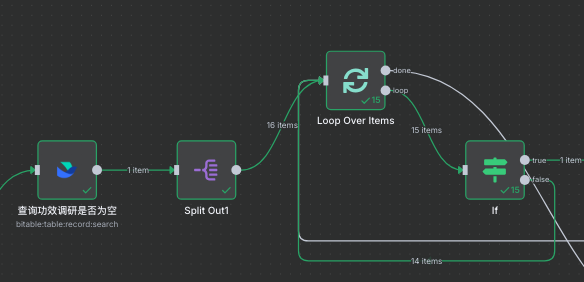
飞书第三方节点不支持自动分页查询,必须填入每次查询的pagetoken,而用N8N--IF节点结合循环查询多维表格的超量数据,我使用判断去得到hasmore跟pagetoken。会出现每次循环只有一次,因为hasmore跟pagetoken一直停留在第一页循环不起来,第一次循环肯定用第一次查询的hasmore,问题就是这里就已经设定了一个定值,循环无法读取后面得到新查询的hasmore和pagetoken,如果手动再去添加新IF节点去接受查询后的参数,那么第二次第三次查询也得人工查询,无法满足自动化需求。
所以解决思路有两个,要么一次性得到每个页的hasmore和pagetoken设立在数组中进行循环查询再合并数据,但是由下图可知,我们无法一次性得到所有的hasmore和pagetoken,必须顺序查询记录才能得到,详细原因参考下图:
 所以我们都会想到,经典中间层,让IF节点前面能得到变量是自己会变化的,而Code节点完美解决这个问题,让IF节点读取Code节点的数据而Code是能默认对新输入的任何数据进行操作的而不需要跟N8N一样指定一个前面数据流中的变量,就能解决只能指定查询节点中的数据导致无法进行二次变化循环的问题,流程如下
所以我们都会想到,经典中间层,让IF节点前面能得到变量是自己会变化的,而Code节点完美解决这个问题,让IF节点读取Code节点的数据而Code是能默认对新输入的任何数据进行操作的而不需要跟N8N一样指定一个前面数据流中的变量,就能解决只能指定查询节点中的数据导致无法进行二次变化循环的问题,流程如下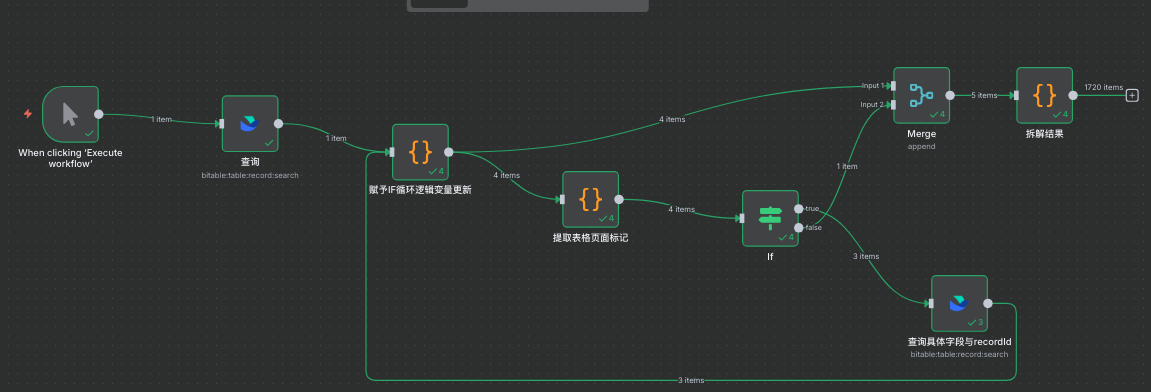 先用代码将查询结果格式化,提取hasmore与pagetoken,然后进行IF判断,再用查询对赋予IF循环变量更新进行数据更新即可完成循环更新迭代
先用代码将查询结果格式化,提取hasmore与pagetoken,然后进行IF判断,再用查询对赋予IF循环变量更新进行数据更新即可完成循环更新迭代
核心代码示例
// 提取表格页面标记 节点
return [
{
json: {
data: {
has_more: items[items.length - 1].json.data.has_more,
page_token: items[items.length - 1].json.data.page_token
}
}
}
];
// 提取表格页面标记 节点
return [
{
json: {
data: {
has_more: items[items.length - 1].json.data.has_more,
page_token: items[items.length - 1].json.data.page_token
}
}
}
];
// 拆解结果 节点
// 取输入数据
const input = $input.first().json.data.items;
// 只保留 record_id 和 所需字段
const output = input.map(item => {
return {
record_id: item.record_id,
Testosterone: item.fields?.Testosterone?.map(t => t.text) || []
};
});
// n8n Function 节点必须返回 [{json: {...}}] 格式
return output.map(o => ({ json: o }));
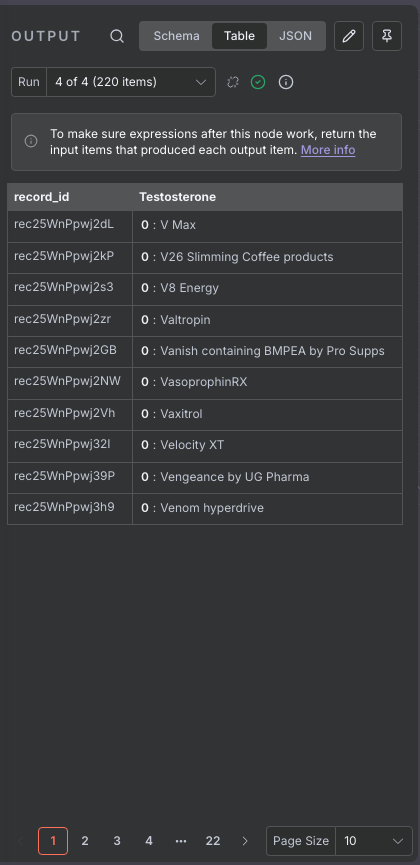
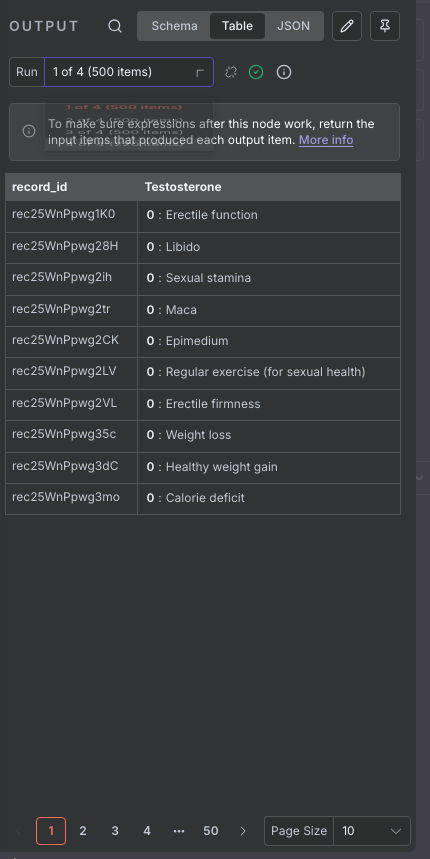
效果如图:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)