半在线RL新范式UI-S1,使得GUI Agent既稳定又规划长远
工作仍有一些可以改进的方向:例如,探索更精细的补丁策略,或将方法扩展到更广泛的任务领域和智能体架构中。,在多个动态测试环境中达到了同类7B参数模型的最高水平,性能提升显著(如在AndroidWorld上+12.0%,在AITW上+23.8%),同时论文还提出了一个能高效代理真实线上性能的新评估指标。它巧妙地在离线收集的静态数据上模拟在线交互过程,既保持了离线训练的稳定性,又获得了在线学习的长远规划
你是否想象过,让AI像真人一样操作手机APP,完成订餐、查天气、甚至管理文件等复杂任务?这背后是“图形用户界面(GUI)自动化”的研究领域,近年来因多模态大模型的进步而飞速发展。然而,现有的AI训练方法陷入两难:离线强化学习(Offline RL) 虽稳定高效,但像个“死记硬背的学生”,一到多步实际任务就漏洞百出;在线强化学习(Online RL) 虽能实战学习,但成本极高且效率低下,宛如“让新手直接上战场试错”。

-
链接:UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
-
论文:https://arxiv.org/pdf/2509.11543
为了解决这一根本矛盾,本文提出了一种创新的半在线强化学习(Semi-online RL) 范式。它巧妙地在离线收集的静态数据上模拟在线交互过程,既保持了离线训练的稳定性,又获得了在线学习的长远规划能力。由此训练出的UI-S1-7B模型,在多个动态测试环境中达到了同类7B参数模型的最高水平,性能提升显著(如在AndroidWorld上+12.0%,在AITW上+23.8%),同时论文还提出了一个能高效代理真实线上性能的新评估指标SOP。这不仅是一项技术突破,更是迈向实用化AI智能体的重要一步。
方法核心:半在线强化学习详解
整体框架与问题形式化
GUI自动化任务本质是一个多轮序列决策问题:AIagent接收一个高层指令(如“用相册里的收据图片在Markor应用里创建一份CSV文件”),然后通过观察屏幕截图、思考推理、执行操作(点击、输入、滑动等)一系列动作,最终完成任务。
关键挑战在于“训练与部署的条件失配”:
-
离线训练时,模型每一步看到的都是专家提供的“正确历史”;
-
在线部署时,模型每一步依赖的是自己之前生成的“可能包含错误的历史”。
这种差异导致离线训练出的模型在实际多步任务中非常脆弱,一旦自生错误就无法恢复。在线RL能解决但成本太高。半在线RL的核心思想就是:不进行真实代价高昂的在线交互,而是利用已有的专家轨迹(离线数据),通过算法模拟出在线交互的流程和历史条件来进行训练。
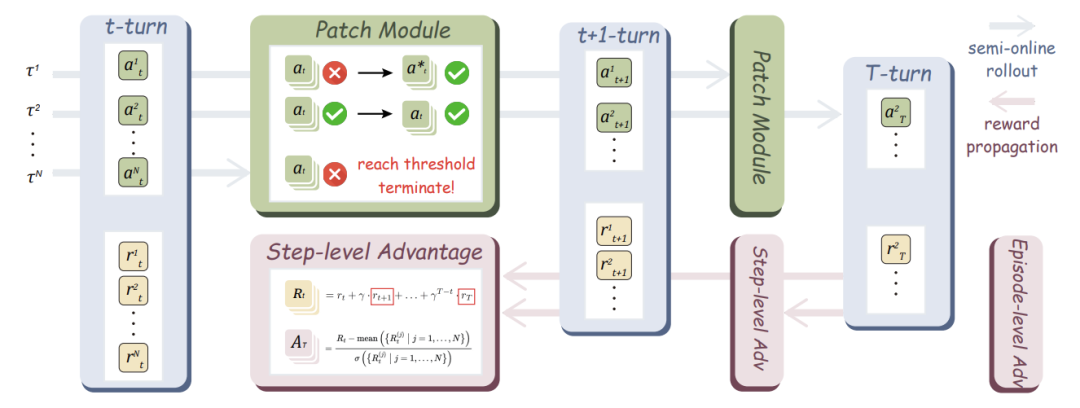
关键组件1:半在线滚动(Semi-Online Rollout)
这是模拟过程的核心。算法从一条专家轨迹 出发,让当前策略模型 像在线一样一步步生成自己的动作和推理 ,并构建自己的历史 。
但当模型生成的动作 与专家动作 不匹配时,就遇到了问题:下一步的真实屏幕状态 未知,模拟无法继续。简单的处理是直接终止该条轨迹,但这浪费了后续大量可能包含有价值信息的数据。
关键组件2:补丁模块(Patch Module)
为了解决上述问题,补丁模块 被引入。它的作用是在动作不匹配时进行干预和修复,用专家动作 替换模型的原错误动作,并生成一段合成的推理内容 ,然后将这个“修正后的步骤”加入历史,使得滚动过程可以继续下去。这极大地提高了离线数据的利用率。
论文探索了三种补丁策略,各有优劣:
-
无思考补丁 (Thought-Free Patch) :只替换动作,不生成新推理。高效且直接,性能不俗。
-
离策略思考补丁 (Off-Policy Thought Patch) :用一个辅助模型(如DeepSeek-R1)来生成高质量的合成推理。能保证推理质量,但可能导致辅助模型与当前策略模型的风格不匹配。
-
同策略思考补丁 (On-Policy Thought Patch) :用当前策略模型本身,在给定专家动作的提示下生成推理。能保持推理风格的一致性,效果最好,但计算成本稍高。

最终,基于效果和效率的权衡,论文选择了无思考补丁(Thought-Free Patch) 作为默认策略。
关键组件3:半在线策略优化(Semi-Online Policy Optimization)
传统的离线RL只优化当前一步的正确性(“近视”),而半在线RL引入了长远规划的考量。
1. 复合奖励(Composite Reward)
每一步的奖励 不是一个简单的分数,而是由三部分加权构成:
-
:输出格式是否正确(是JSON吗?)
-
:预测的动作类型是否正确(是点击还是输入?)
-
:动作是否与专家动作完全匹配(点击的坐标对吗?)
这种设计引导模型先做对“大事”(格式、类型),再抠“细节”(精确坐标)。
2. 折扣未来回报(Discounted Future Return)
为了衡量当前决策对未来的影响,计算从当前步骤t到轨迹结束的折扣回报:
其中 是折扣因子(0到1之间), 越小越看重眼前收益, 越大越有长远眼光。实验发现 时效果最佳。
3. 双级优势函数(Dual-Level Advantages)
这是策略优化的核心,用于更精确地评估一个动作的好坏。
-
步骤级优势 ( ):在同一时间步
t上,比较不同滚动轨迹的回报值。它捕捉局部、短期的优化信号。
( 和 是第t步所有滚动回报的均值和标准差) -
回合级优势 ( ):评估整条轨迹 的总体回报。它捕捉全局、任务级别的完成信号。
( 和 是所有轨迹总回报的均值和标准差)
最终,将一个动作的优势定义为两者加权和,同时考虑它对当前步骤和整个任务的贡献:
(实验中设 )
4. 优化目标
最终的优化目标基于PPO算法,使用上述优势函数来更新策略参数θ,同时加入KL散度惩罚项以防止策略更新偏离旧策略太远。
其中 是新旧策略的重要性采样比率。
实验与评估
提出的新评估指标:半在线性能(SOP)
在线评估(如AndroidWorld)虽真实但耗时耗力;传统离线评估(如AndroidControl-High)虽快但与现实表现脱节。论文提出了半在线性能(Semi-Online Performance, SOP) 指标作为两者间的桥梁。
SOP在静态测试集(AndroidControl-Test)上运行,但关键区别在于:它让模型在整个任务过程中使用自己生成的历史,而不是在每一步都提供真实历史。只有当模型动作与专家动作不匹配时,评估才终止。它计算两个值:
-
进度(PG):平均任务完成比例。
-
任务成功率(TSR):完全完成的任务占比。 SOP分数是这两者的平均值。
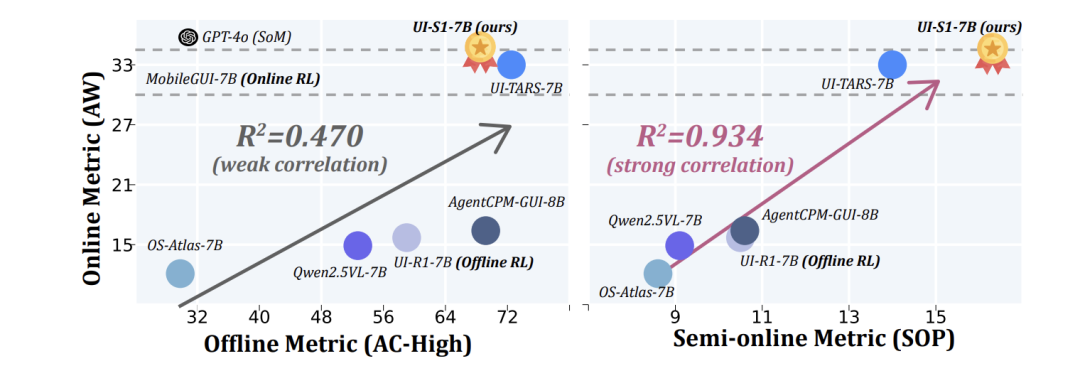
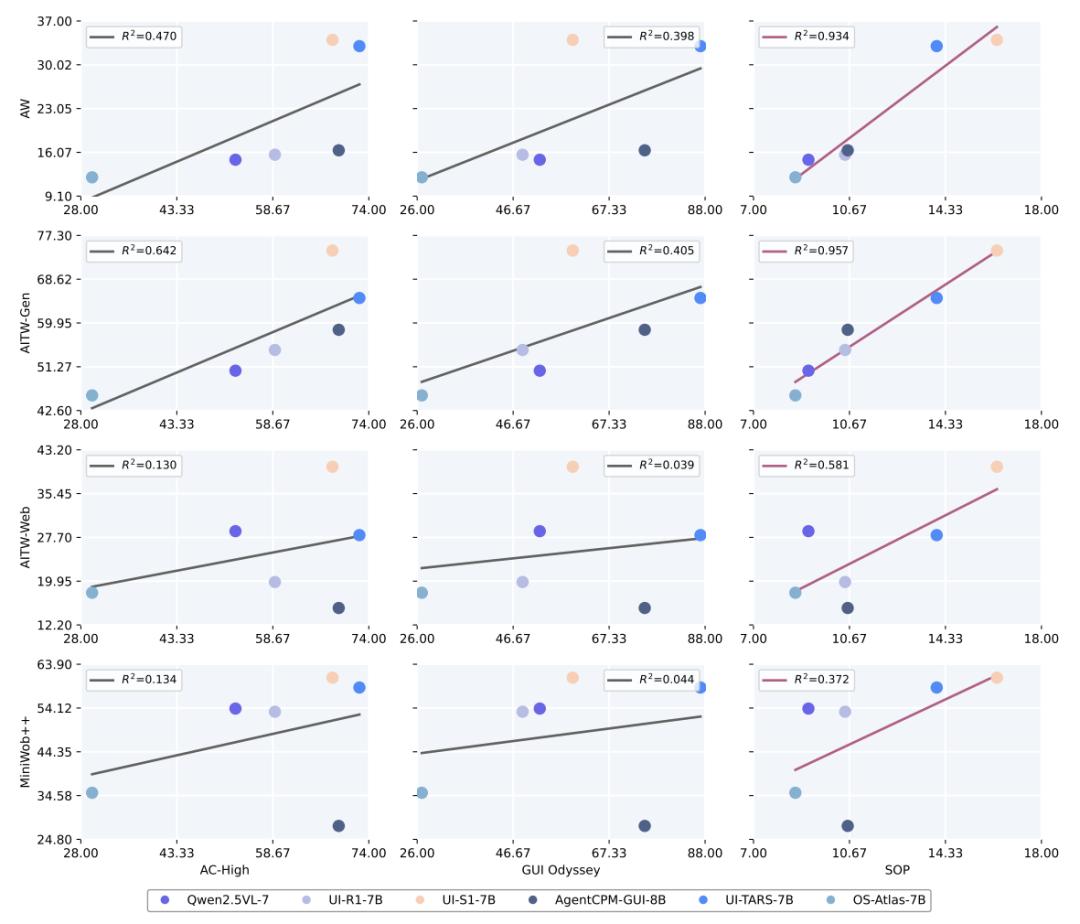
通过线性回归分析表明,SOP与在线指标AndroidWorld具有极强的相关性(R²=0.934),远优于传统离线指标。
数据集与基准模型介绍
论文在多轮和单轮两大类基准上进行了全面评估。
-
多轮基准:评估端到端任务完成能力。
-
-
SOP:论文提出的新指标。
-
AndroidWorld (AW) :116个任务,动态真实环境。
-
AITW-Gen/AITW-Web:450个过滤后的任务。
-
MiniWob++ :92个经典网页任务。
-
-
单轮基准:评估基础GUI理解和 grounding(定位)能力。
-
-
ScreenSpot-V2/Pro (SS-V2/Pro) :评估 grounding 精度。
-
AndroidControl-High (AC-High) 和 GUI Odyssey:综合评估GUI理解和高层指令遵循。
-
对比的基线包括仅SFT、传统离线RL(GRPO)、仅半在线RL(无SFT预热)以及众多开源和闭源的SOTA模型。
结果分析与讨论
主实验结果
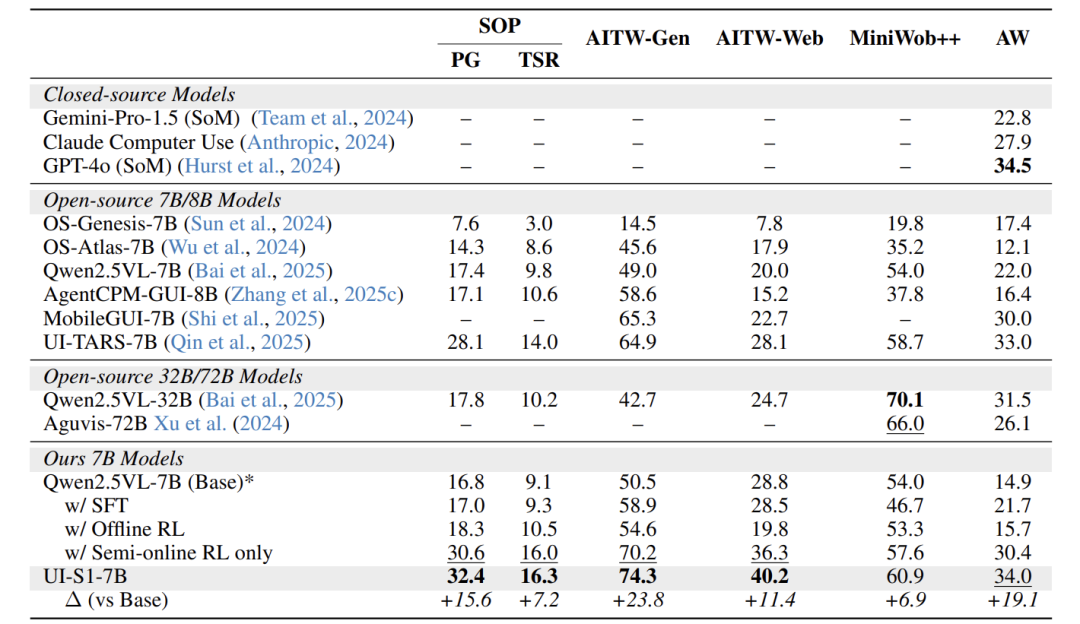
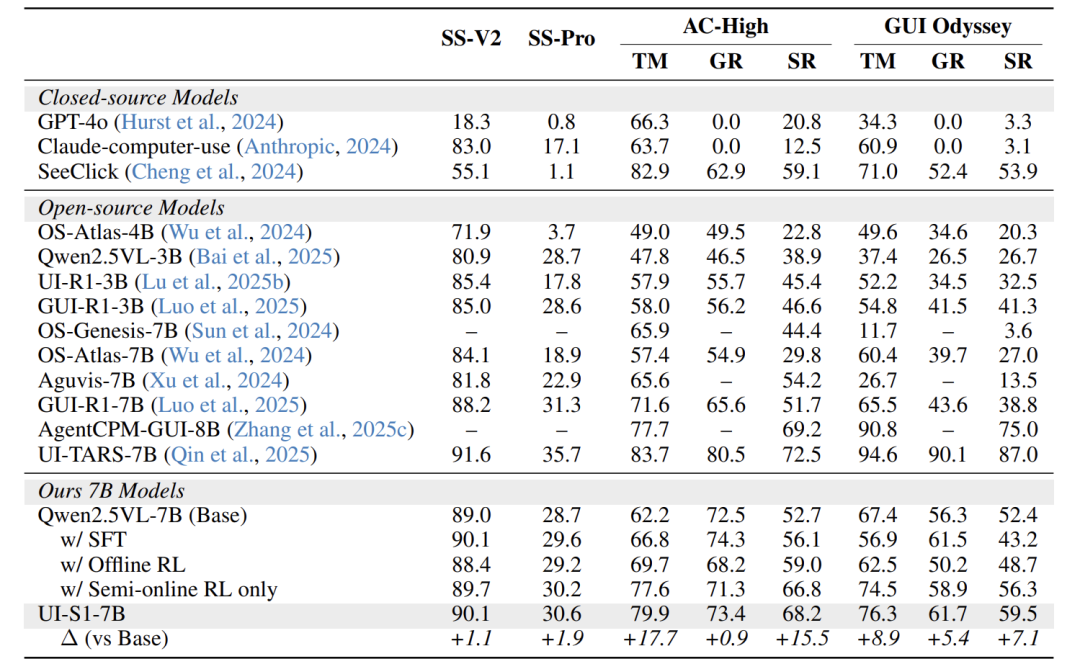
上两表分别展示了模型在多轮和单轮基准上的详细结果。
多轮性能:UI-S1-7B在所有开源的7B/8B模型中取得了最先进的性能。
-
相比基模型Qwen2.5VL-7B,提升巨大:在AndroidWorld上 +19.1% ,在AITW-Gen上 +23.8% 。
-
甚至能与参数量大得多的模型竞争,如Qwen2.5VL-32B (31.5%) 和 Aguvis-72B (26.1%),以及闭源的GPT-4o (34.5%)。
-
训练范式对比证明:SFT+半在线RL的组合效果最佳,显著优于单一范式。
单轮性能:UI-S1-7B在单轮任务上也保持了竞争力,并有稳定提升(如在AC-High SR上+15.5%)。这表明半在线RL增强了多步推理能力,但并未牺牲单步的准确性,实现了两者兼得。
补丁模块策略的深入分析
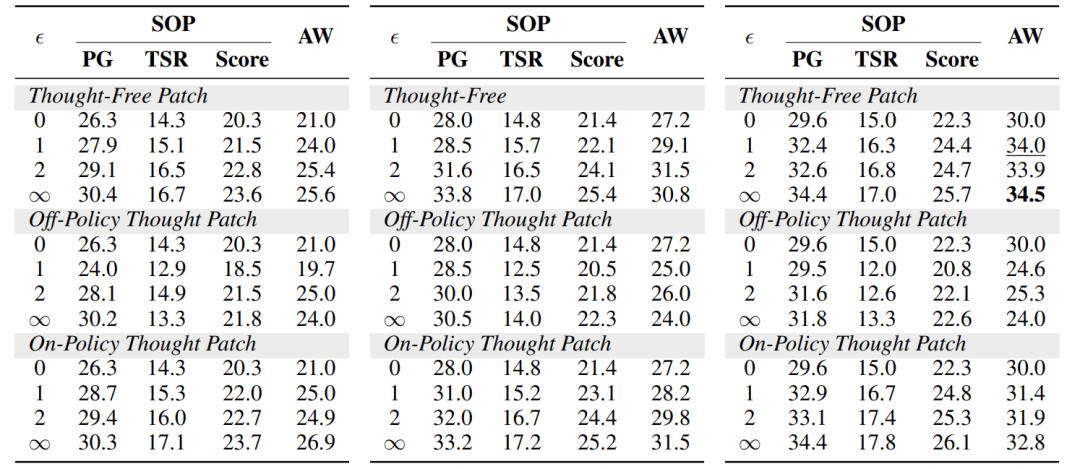
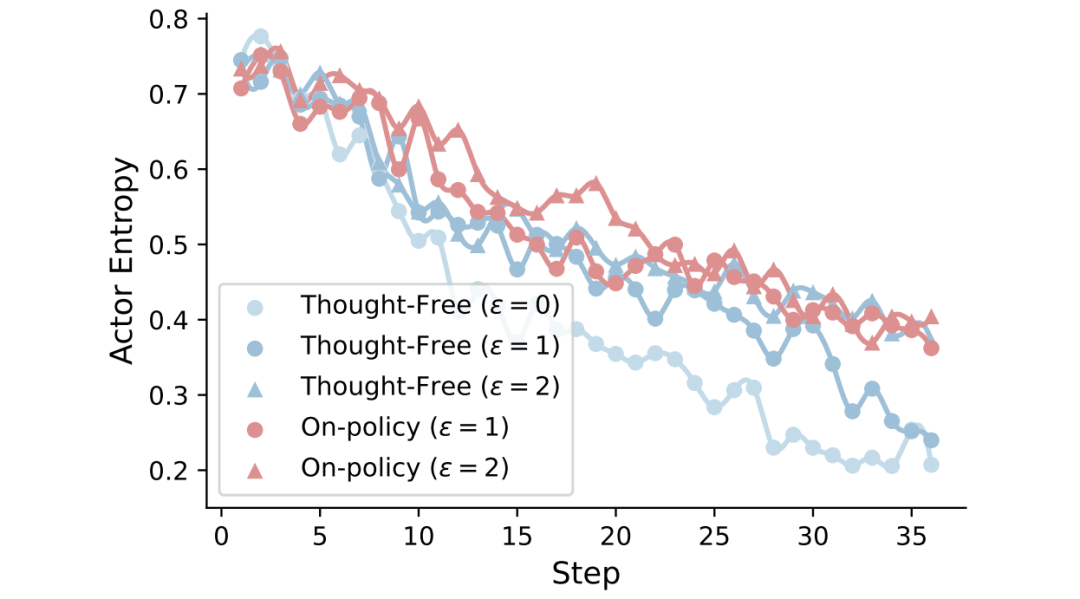
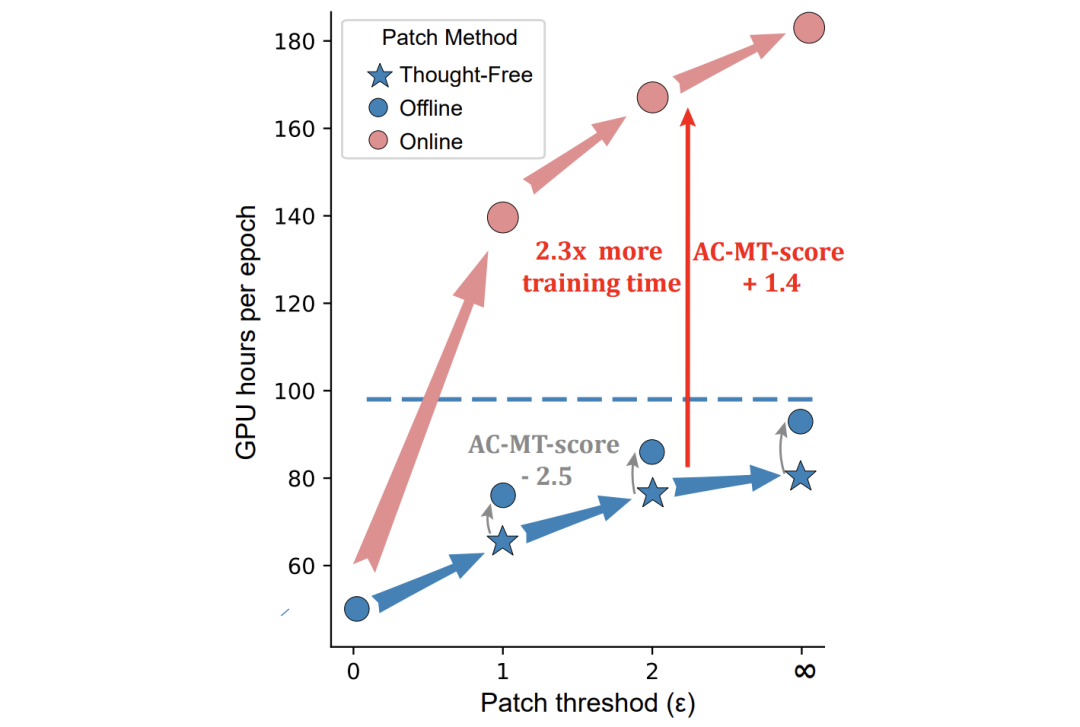
-
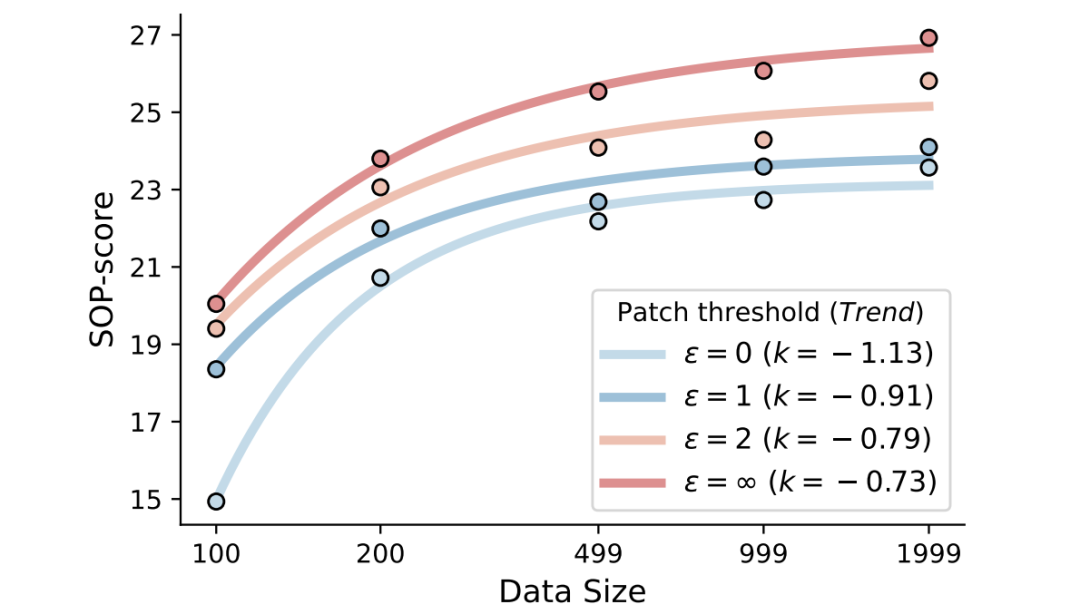
补丁阈值ε:ε控制允许修复多少次动作不匹配。增大ε(允许修复更多错误)能持续提升性能,因为它让模型能从更长的轨迹后半段学习。但ε也不是越大越好,存在计算开销和性能的权衡,最终选择ε=1。
-
补丁方法对比:同策略思考补丁性能最好,但无思考补丁在性能和效率间取得了最佳平衡,因此被选为最终配置。
训练动态与缩放规律
-
数据缩放规律:性能随数据量增加呈指数增长。更大的ε值不仅提高了绝对性能,还提升了数据利用效率。
-
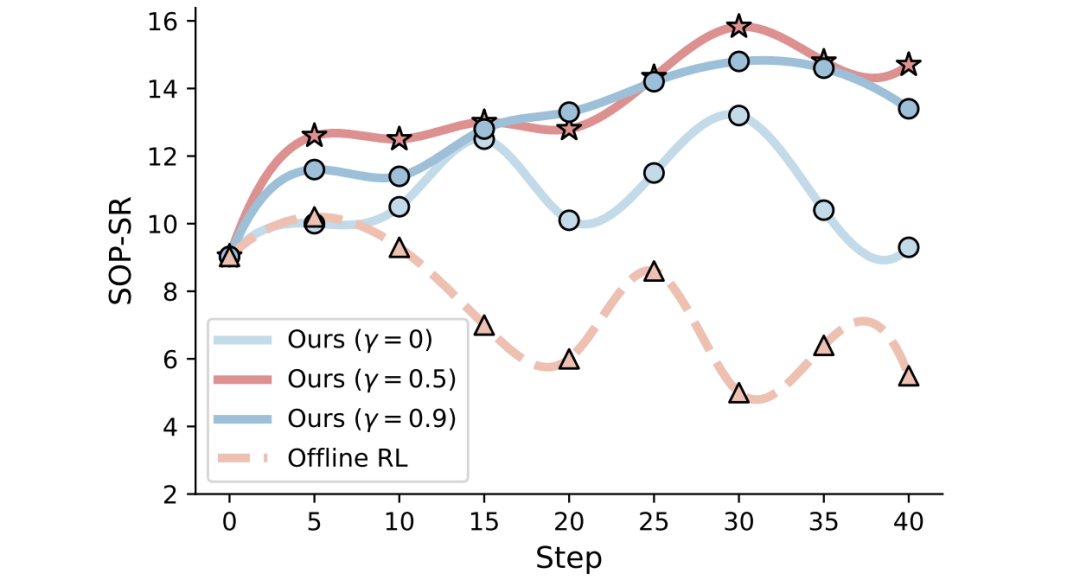
折扣因子γ:实验证明,引入未来奖励(γ>0)对性能至关重要。完全忽略未来(γ=0)效果最差,γ=0.5时达到峰值。
消融实验

-
训练范式:SFT预热后接半在线RL是最佳组合。
-
组件贡献:回合级优势和维护多张历史图像都是提升性能的关键因素。
case分析
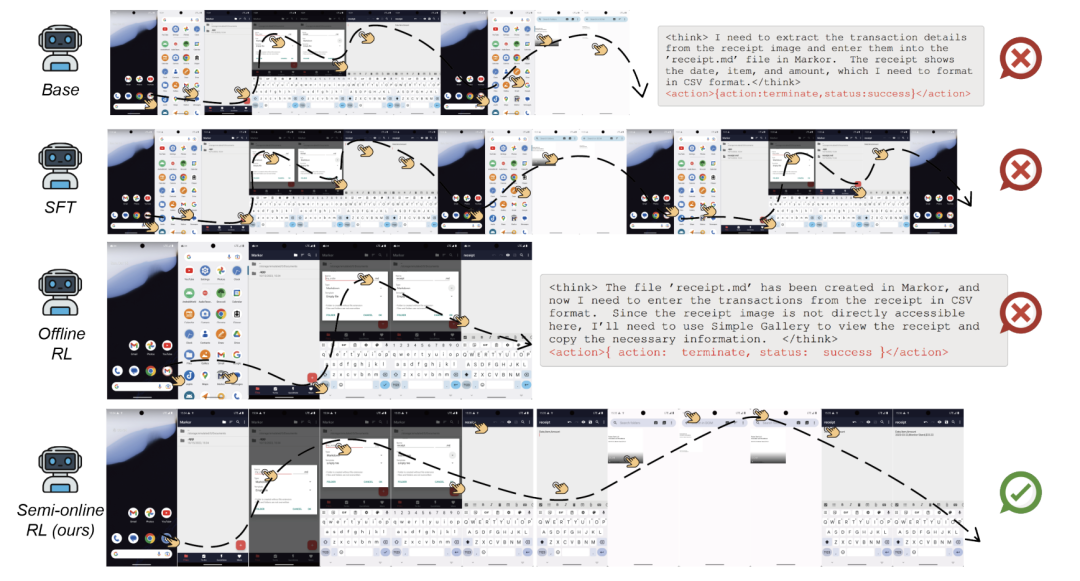
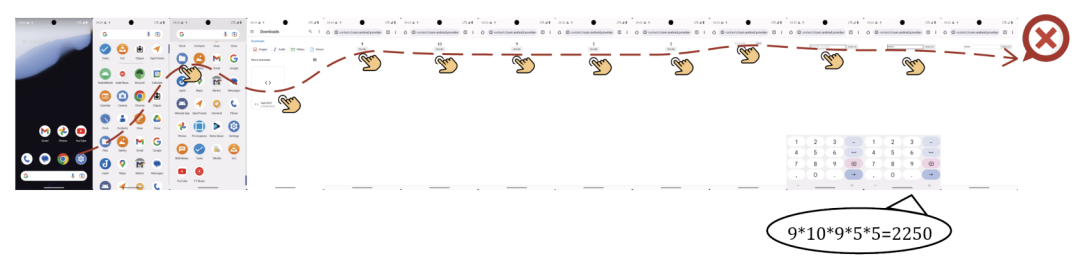
论文通过案例生动展示了模型的能力。在一个复杂的跨应用信息记忆任务中(从Simple Gallery看图片,再到Markor创建文件),UI-S1-7B成功地在12步序列中记住了关键信息“2023-03-23, Monitor Stand, $33.22”并正确生成CSV格式。而基模型和离线RL模型则会出现思维-动作不一致、信息丢失或提前终止等问题。也有失败案例,如模型记住了所有数字但在最后计算乘积时出错,这揭示了数值计算仍是当前纯视觉语言模型的一个弱点。
结论
本文提出的半在线强化学习(Semi-online RL) 成功地在离线训练的稳定性与在线学习的长程规划能力之间架起了一座桥梁。通过半在线滚动、补丁模块和双级优势优化等创新设计,有效解决了GUI自动化中的“训练-部署失配”问题。
由此孕育出的UI-S1-7B模型在多项基准测试中证明了其卓越性能,成为7B尺度下的新SOTA。同时,论文提出的SOP指标为高效、可靠的模型评估提供了新思路。
展望未来,工作仍有一些可以改进的方向:例如,探索更精细的补丁策略,或将方法扩展到更广泛的任务领域和智能体架构中。这项研究为构建真正实用、高效且强大的GUI交互智能体奠定了坚实的基础,推动了AI迈向通用数字助理的关键一步。



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)