轻量化视觉大模型实战:TinyMind(90M)从训练到端侧部署的完整教程
本文将详细记录这一过程中的技术方案、实现细节和踩坑经验。如果这些内容能对正在探索轻量化多模态模型的开发者有所启发,那将是我最大的欣慰。
为实现手机端高效多模态推理,作者探索了超轻量视觉语言模型TinyMind的构建。通过整合TinyCLIP视觉编码器与MiniMind语言模型,并以SmolVLM为指导优化架构,最终实现89M参数模型。文章完整分享了训练策略、改进尝试与工程化部署路径,为端侧AI提供实践参考!
前段时间,我突发奇想,把Qwen3和SmolVLM2拼了一下,整出了一个SmolVLM2-256M-Married-Qwen3-0.6B(https://zhuanlan.zhihu.com/p/1947674801566128094)(没错,就是一个“把SmolVLM视觉能力和Qwen3中文能力硬缝合”的模型)。 效果嘛,能用,但模型还是太大,不够“轻盈”,手机一跑就喘。
"能不能做得更小、更快,甚至更好?” ——这个念头一旦冒出来,就再也按不住了。经过半个月的探索,成功实现了一个参数量仅89M的超轻量视觉语言模型(初版),并完整跑通了从模型训练、优化到移动端工程化部署的全流程。程。
本文将详细记录这一过程中的技术方案、实现细节和踩坑经验。如果这些内容能对正在探索轻量化多模态模型的开发者有所启发,那将是我最大的欣慰。当然,由于个人能力有限,文中难免存在疏漏或不足之处,恳请各位读者不吝指正。
相关代码已经开源tinymind(https://github.com/TalkUHulk/tinymind) —— 欢迎一键 Star ⭐(顺手点个更香)。

Demo截图
训练
作为一个个人项目,“从头训练大模型” 这种事对我来说基本等同“跳进深渊”。所以首先做的,当然是看看现有的开源路线。
选择:MiniMind 系列
经过一番调研,我最终选择了 MiniMind 系列作为基座。原因很简单:
足够小:最小的模型仅有 25.8M 参数,对个人开发者极其友好 代码清爽:整体架构简洁明了,阅读体验丝滑,非常适合二次开发 多模态支持:官方提供了 MiniMind-V 多模态版本,省去了从零搭建的麻烦
但问题也随之而来:MiniMind-V 的视觉编码器采用了标准的 CLIP ViT-B/16,光这一个组件就有约 86M 参数。即便文本部分只有 26M,整个模型也达到了 104M——对于追求轻量化的目标来说,是否有办法进一步缩减模型。
于是,优化方向就很明确了:
保留 MiniMind 的语言模型架构,替换一个更轻量的视觉编码器。
尝试一:MobileCLIP——理想很丰满,现实很骨感
既然要换视觉编码器,那就从最小的开始试。我首先盯上了 Apple 开源的 MobileCLIP,其中最小的 MobileCLIP-S0 视觉编码器仅有 11.4M 参数,简直是为轻量化而生。
不过,MobileCLIP 的输出格式与 CLIP 有所不同。CLIP ViT 输出的是序列化的 patch embeddings(形状为 [B, N, D]),MobileCLIP 输出 CNN-style 的 feature map,形状为 [B, C, H, W]。因此需要做一个简单的格式转换:
B, C, H, W = vision_tensors.shape vision_tensors = vision_tensors.flatten(2).transpose(1, 2)
训练流程沿用经典的两阶段策略:
Stage 1:冻结视觉编码器和语言模型,仅训练 Projection 层,学习视觉-文本特征对齐 Stage 2:解冻 Projection 层和语言模型,进行端到端微调 训练数据使用 Objects365 数据集,通过大模型自动生成图像描述和问答对。
Loss 曲线看起来一切正常,稳步收敛到 2.0 左右。然而,当我满怀期待地看结果时:
| 图片 | 回答 |
|---|---|
完全答非所问。 模型输出的内容与图像毫无关联,典型的 视觉-文本对齐失败(Vision-Text Misalignment) 。
我尝试了各种补救措施:
增加 Projection 层的深度和宽度 为视觉 token 添加可学习的位置编码 调整学习率和训练轮数 检查数据预处理流程 但效果依然不理想。经过反复排查,我基本确认了问题根源:
MobileCLIP-S0 的语义表征能力不足以支撑多模态对齐任务。
尝试二:TinyCLIP——找到甜蜜点
既然 MobileCLIP 的路走不通,我转向了另一个轻量化方案:TinyCLIP。
TinyCLIP 是微软提出的 CLIP 蒸馏方案,通过知识蒸馏将大型 CLIP 模型压缩到更小的尺寸,同时尽可能保留其语义理解能力。官方提供了多种规格的模型:
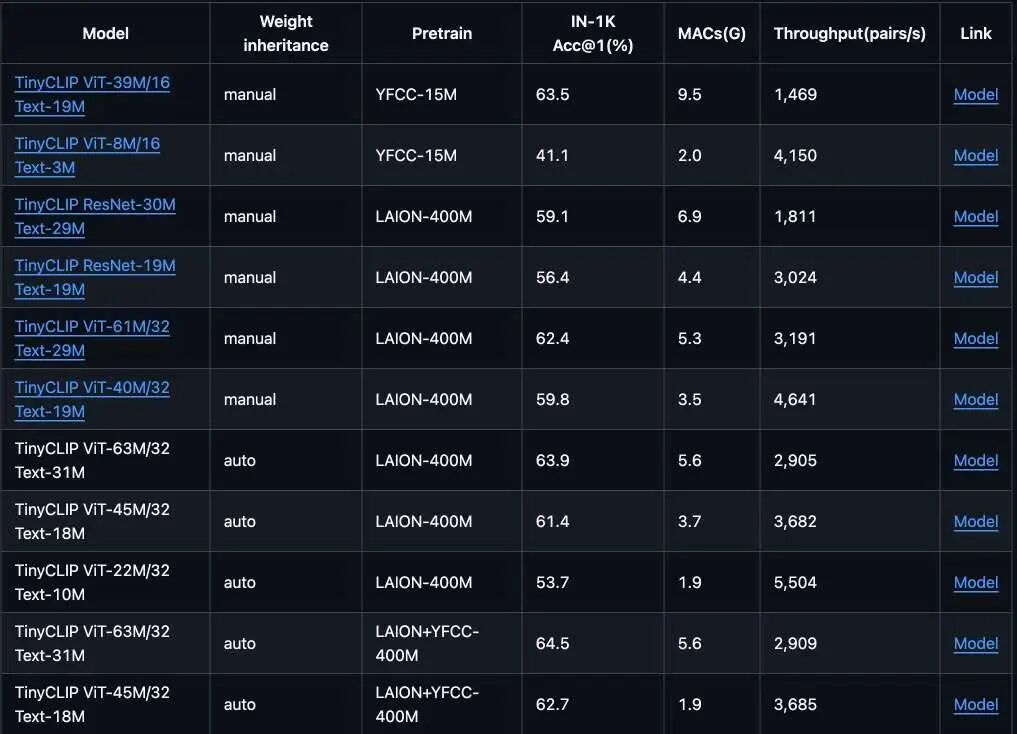
我首先尝试了最小的 TinyCLIP-ViT-8M(视觉编码器 8M,文本编码器 3M),结果与 MobileCLIP 如出一辙——模型依然在"一本正经地胡说八道"。
这进一步验证了我的猜想:视觉编码器存在一个"能力下限",低于这个阈值就无法学到稳定的视觉语义表征。
经过多轮实验,我最终选定了 TinyCLIP-ViT-40M-32-Text-19M(视觉编码器约 63M)。虽然比预期的大一些,但这是在"能用"和"够小"之间能找到的最佳平衡点。
训练过程终于顺利了:
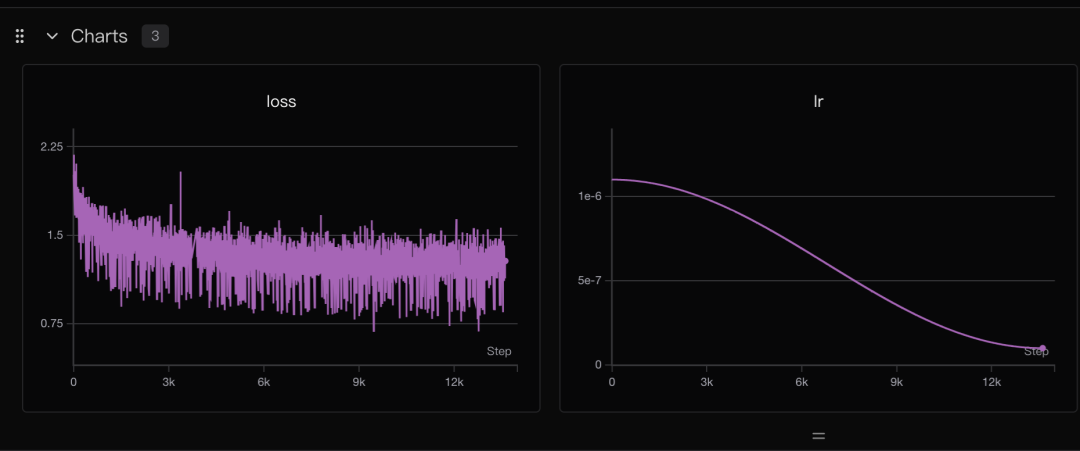
训练loss
推理效果也明显改善:
| 图片 | 回答 |
|---|---|
这里留下两个值得深入探索的问题,留个坑给自己:
- 如何快速评估视觉编码器的适用性? 是否有一些 proxy task 或指标可以在训练前预判其效果?
- 给定一个视觉编码器,如何确定其性能上限? 即在最优训练配置下,它能达到的最佳效果是什么?
改进篇:向 SmolVLM 取经
通过替换视觉编码器,我们得到了一个能够正常工作的轻量化多模态模型。但"能用"和"好用"之间还有很长的路要走。为了进一步优化模型性能,我参考了 Hugging Face 发布的 SmolVLM 论文(《SmolVLM: Redefining small and efficient multimodal models》),尝试将其中针对紧凑型多模态模型的设计准则应用到 TinyMind 上。
视觉编码器与语言模型的参数配比
SmolVLM 论文指出,紧凑型多模态模型需要在视觉编码器和语言模型之间保持合理的参数配比。当语言模型规模较小时,配备过大的视觉编码器反而会导致性能下降——因为小型 LM 难以有效利用过于丰富的视觉信息,造成"消化不良"。
在我的配置中:
- 视觉编码器:62.75M
- 语言模型:25.8M
这个比例(约 2.4:1)其实已经偏离了 SmolVLM 推荐的均衡配置。理想情况下,应该使用更大的语言模型来匹配视觉编码器的容量。但考虑到训练资源限制和快速迭代的需求,我暂时保持了这个配置,将其作为后续优化的方向。
视觉输入处理:图像分块与 Token 压缩
对于紧凑型多模态模型,如何高效处理视觉输入是一个关键问题。SmolVLM 提出了两个核心策略:
- 图像分块(Image Tiling) :将输入图像切分为多个子图,分别编码后拼接,以获取更丰富的细节信息
- 视觉 Token 压缩:通过 Pixel Shuffle 等技术减少视觉 token 数量,降低计算开销
仿照SmolVLM,在 TinyMind 中,我采用了 4×4 分块 + 全局图像的策略:
- TinyCLIP 的输入分辨率为 224×224,输出的 last_hidden_state 形状为 [B, 49, 1024](7×7 个 patch)
- 将原图按 4×4 网格切分为 16 个子图,每个子图独立编码
- 加上原始全图,共 17 个图像块
- 总视觉 token 数:17 × 49 = 833 个
为了保持图像的原始宽高比,我没有强制进行 4×4 切分,而是根据实际尺寸尽可能切分,不足的位置用占位图填充,并在后续的 attention mask 中将其屏蔽。
833 个视觉 token 对于小型语言模型来说可以吃得下,同时考虑到小模型的视觉特征的表征能力欠佳,这里暂时没有引入 Pixel Shuffle 进行进一步压缩。
def adaptive_square_split(image_path, max_rows=4, max_cols=4): img = Image.open(image_path) original_width, original_height = img.size rows, cols, block_size = calculate_optimal_split_with_fixed_max( original_width, original_height, max_rows, max_cols ) blocks = [] for i in range(rows): for j in range(cols): left = j * block_size upper = i * block_size right = left + block_size lower = upper + block_size block = img.crop((left, upper, right, lower)) blocks.append(block) return blocks, rows, cols, block_sizedef calculate_optimal_split_with_fixed_max(width, height, max_rows, max_cols): best_rows = 1 best_cols = 1 best_block_size = 0 best_coverage = 0 # 固定行数为4,自适应列数 rows_fixed = max_rows for cols in range(1, max_cols + 1): block_width = width // cols block_height = height // rows_fixed square_size = min(block_width, block_height) if square_size > 0: coverage = (cols * square_size) * (rows_fixed * square_size) / (width * height) # 选择覆盖率高且正方形尺寸大的方案 if coverage > best_coverage or (coverage == best_coverage and square_size > best_block_size): best_rows = rows_fixed best_cols = cols best_block_size = square_size best_coverage = coverage # 固定列数为4,自适应行数 cols_fixed = max_cols for rows in range(1, max_rows + 1): block_width = width // cols_fixed block_height = height // rows square_size = min(block_width, block_height) if square_size > 0: coverage = (cols_fixed * square_size) * (rows * square_size) / (width * height) if coverage > best_coverage or (coverage == best_coverage and square_size > best_block_size): best_rows = rows best_cols = cols_fixed best_block_size = square_size best_coverage = coverage # 如果可能,行列都达到最大值 block_width = width // max_cols block_height = height // max_rows square_size = min(block_width, block_height) if square_size > 0: coverage = (max_cols * square_size) * (max_rows * square_size) / (width * height) if coverage > best_coverage or (coverage == best_coverage and square_size > best_block_size): best_rows = max_rows best_cols = max_cols best_block_size = square_size best_coverage = coverage # 最终确定的正方形尺寸(向下取整到16的倍数) best_block_size = (best_block_size // 16) * 16 if best_block_size == 0: best_block_size = 16 # 最小尺寸 return best_rows, best_cols, best_block_size
文本处理:结构化 token 远比你想象的更重要
对于紧凑型 VLM,可学习的位置标记显著优于原始文本标记。标记的结构化设计(而非原始文本)是保证训练稳定性和最终性能的基础,特别是在处理需要空间感知的任务(如子图像定位、OCR)时至关重要。通过引入明确的、结构化的文本标记,来引导和约束紧凑型VLM的注意力,从而降低任务歧义、防止过拟合,并最终提升其在图像任务上的泛化能力。
原版 MiniMind-V 的输入格式比较简单粗暴:
[{‘role’: ‘system’, ‘content’: ‘简短回复问题.’}, {‘role’: ‘user’, ‘content’: ‘@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@看这张图片,说说你看到的。’}]
用 N(针对TinyClip是49) 个 @ 符号作为图像占位符,缺乏明确的结构信息。
为了引入结构化设计,分别进行了以下修改。
- tokenizer
开源minimind的tokenizer只有<|im_start|>、<|im_end|>和<|endoftext|>3个special token。而观察SmolVLM,包括了大量的类似<row_1_col_1>图片相关特殊token,如果想使用标记的结构化设计,首先需要重新训练tokenizer。这里直接使用minimind提供的训练代码即可。
我增加了如下的special token:
special_tokens = [ '<fake_token_around_image>', # 图像边界标记 '<global-img>', # 全局图像标记 '<image>', # 单个视觉 token 占位符 '<row_1_col_1>', '<row_1_col_2>', ..., '<row_4_col_4>' # 子图位置标记]
- 在输入前添加简洁的系统提示词,以明确模型在特定任务中的角色和目标。
{“role”: “system”, “content”: “你是一个多模态AI助手,能够理解图片和文本信息.”}
- chat template
直接借鉴SmolVLM的chat template
{%- if tools %} {{- '<|im_start|>system\n' }} {%- if messages[0].role == 'system' %} {{- messages[0].content + '\n\n' }} {%- endif %} {{- "# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }} {%- for tool in tools %} {{- "\n" }} {{- tool | tojson }} {%- endfor %} {{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}{%- else %} {%- if messages[0]['role'] == 'system' -%} {{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }} {%- else -%} {{- '<|im_start|>system\n你是一个多模态AI助手,能够理解图片和文本信息。<|im_end|>\n' }} {%- endif %}{%- endif %}{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}{%- for message in messages[::-1] %} {%- set index = (messages|length - 1) - loop.index0 %} {%- if ns.multi_step_tool and message.role == "user" and message.content is string and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %} {%- set ns.multi_step_tool = false %} {%- set ns.last_query_index = index %} {%- endif %}{%- endfor %}{%- for message in messages %} {#- 处理消息内容:支持字符串、列表、图像等多种格式 #} {%- if message.content is string %} {%- set content = message.content %} {%- elif message.content is iterable %} {#- 处理多部分内容(文本+图像) #} {%- set content_parts = [] %} {%- for part in message.content %} {%- if part.type == 'text' %} {%- set _ = content_parts.append(part.text) %} {%- elif part.type == 'image' %} {#- 图像占位符,实际图像数据会在processor中处理 #} {%- set _ = content_parts.append('<image>') %} {%- endif %} {%- endfor %} {%- set content = content_parts | join('\n') %} {%- else %} {%- set content = '' %} {%- endif %} {#- 用户消息或系统消息 #} {%- if (message.role == "user") or (message.role == "system" and not loop.first) %} {{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }} {#- 助手消息 #} {%- elif message.role == "assistant" %} {{- '<|im_start|>' + message.role + '\n' + content }} {%- if message.tool_calls %} {%- for tool_call in message.tool_calls %} {%- if (loop.first and content) or (not loop.first) %} {{- '\n' }} {%- endif %} {%- if tool_call.function %} {%- set tool_call = tool_call.function %} {%- endif %} {{- '<tool_call>\n{\"name\": \"' }} {{- tool_call.name }} {{- '\", \"arguments\": ' }} {%- if tool_call.arguments is string %} {{- tool_call.arguments }} {%- else %} {{- tool_call.arguments | tojson }} {%- endif %} {{- '}\n</tool_call>' }} {%- endfor %} {%- endif %} {{- '<|im_end|>\n' }} {#- 工具消息 #} {%- elif message.role == "tool" %} {%- if loop.first or (messages[loop.index0 - 1].role != "tool") %} {{- '<|im_start|>user' }} {%- endif %} {{- '\n<tool_response>\n' }} {{- content }} {{- '\n</tool_response>' }} {%- if loop.last or (messages[loop.index0 + 1].role != "tool") %} {{- '<|im_end|>\n' }} {%- endif %} {%- endif %}{%- endfor %}{%- if add_generation_prompt %} {{- '<|im_start|>assistant\n' }} {%- if enable_thinking is defined and enable_thinking is false %} {{- '<think>\n\n</think>\n\n' }} {%- endif %}{%- endif %}
下面用代码生成结构化的输入:
def _create_chat_prompt(self, conversations): image_place_holder = random.choice(["图片如下:", "如下所示的图片:", "请见下面这张图:", "如下图显示:", "参考下方图片:", "图示如下:"]) for row in range(self.max_rows): for col in range(self.max_cols): image_place_holder += f"<fake_token_around_image><row_{row + 1}_col_{col + 1}>" image_place_holder += self.image_token * self.per_image_token_num image_place_holder += f"<fake_token_around_image><global-img>{self.image_token * self.per_image_token_num}<fake_token_around_image>" if isinstance(conversations, dict): messages = [ {"role": "system", "content": "你是一个多模态AI助手,能够理解图片和文本信息."}, { "role": "user", "content": conversations["q"] + image_place_holder if isinstance(conversations["q"], str) else conversations["q"][0] }, { "role": "assistant", "content": conversations["a"] if isinstance(conversations["a"], str) else conversations["a"][0] } ] elif isinstance(conversations, str): messages = [ {"role": "system", "content": "你是一个多模态AI助手,能够理解图片和文本信息."}, { "role": "user", "content": random.choice(prompts_template) + image_place_holder }, { "role": "assistant", "content": conversations } ] else: raise ValueError("unsupport format") return self.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=False )
把结构化的结果可视化一下:
<|im_start|>system你是一个多模态AI助手,能够理解图片和文本信息.<|im_end|><|im_start|>user描述图片内容如下所示的图片:<fake_token_around_image><row_1_col_1><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_1_col_2><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_1_col_3><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_1_col_4><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_2_col_1><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_2_col_2><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_2_col_3><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_2_col_4><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_3_col_1><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_3_col_2><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_3_col_3><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_3_col_4><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_4_col_1><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_4_col_2><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_4_col_3><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><row_4_col_4><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><global-img><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><image><fake_token_around_image><|im_end|><|im_start|>assistant
<fake_token_around_image><row_1_col_1>后连续49个,表示左上角的图片patch,<fake_token_around_image>后连续49个则为整图。后续直接替换为视觉特征,送入LM即可。 这种结构化设计让模型能够明确感知每个视觉 token 的空间位置,有助于提升对图像布局的理解能力。
数据配比:纯文本数据是把双刃剑
SmolVLM 论文还指出,在训练小型多模态模型时,直接复用 LLM 的 SFT 文本数据可能适得其反。原因在于:
- 大量纯文本数据会稀释多模态数据的比例,降低整体数据多样性
- 小模型的容量有限,难以同时兼顾文本和多模态能力
论文建议将纯文本数据比例控制在 14% 以内。
在我的实验中,我在 Objects365 多模态数据基础上,额外加入了 10 万条开源纯文本数据,希望能提升模型的语言理解能力。
训练可视化
同样的训练步骤和训练参数,训练过程如下:
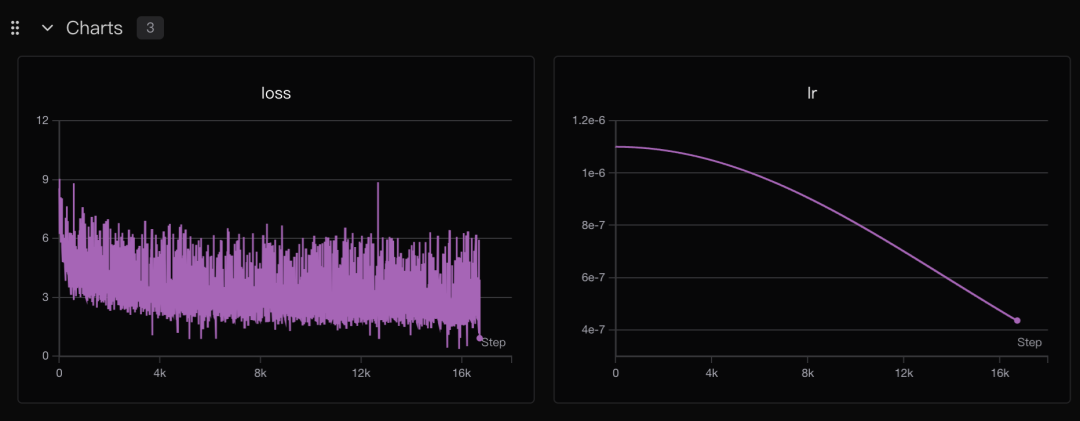
前半部分,中间机器问题断了一下
| step | 图片 | 回答 |
|---|---|---|
| 1 | ||
| 100 | ||
| 1600 |
实验结果:意料之外的"负优化"
一顿操作猛如虎,一看结果250…
当我在验证集上进行定量评估时,结果却让人大跌眼镜——
改进后的模型在 CIDEr 和 BGE-M3 相似度指标上,均不如直接替换视觉编码器的基线版本!
这里展示几个对比结果:
| 图片 | 问题 | 标签 | 直接替换视觉编码器 | 基于SmolVLM准则优化 |
|---|---|---|---|---|
| 他们正在做什么? | 他们在进行广播或录制音频的工作。 | 他们在使用笔记本电脑 | 他们在进行一场学习或讨论。 | |
| 这张照片中有什么主要食物? | 有酸菜沙拉、烤肉片和香肠。 | "煎饼"是这张照片中最突出的食物之一 | “蛋糕片”, “酒瓶”, 和 “餐具” | |
| 请描述这张图片的内容。 | 这是一张展示红色拖拉机的照片,在一片草地上停着几辆其他车辆,并且背景中有树木。 | 一辆红色拖拉机停在草地上。 | 一辆红色跑车停在草地上,周围有绿色草地和树木。背景中可以看到一些树木和其他车辆。 | |
| 请描述这张图片的内容。 | 一架大型白色飞机停靠在机场跑道上,周围有其他飞行器和地面设备。 | 一架停在机场跑道上的飞机。 | 一架停在机场跑道上的一辆车辆。 | |
| 请描述这张图片的内容。 | 一辆橙色自行车停靠在树干旁的一片草地上。 | 一辆红色自行车停在草地上,旁边有一棵树干。 | 一辆红色自行车停在草地上,周围有绿色植物。 |
可以看到,改进模型在某些情况下甚至出现了明显的错误(如把"飞机"说成"车辆")。
可能的原因分析:
- 纯文本数据的负面影响:10 万条开源纯文本数据可能过多,稀释了多模态学习信号?
- 图像分块策略不当:4×4 分块产生了 833 个视觉 token,可能超出了小型 LM 的有效处理能力?
- 训练超参数需要调整:结构化输入可能需要不同的学习率或训练策略?
- …等等
这些问题留待后续实验逐一排查。虽然这次"优化"变成了"负优化",但失败本身也是宝贵的经验——至少我们知道了哪些路可能走不通。
工程化篇:从 PyTorch 到移动端
不管模型效果如何,先把部署流程跑通再说!这部分将介绍如何将 TinyMind 从 PyTorch 模型一步步部署到移动端设备上。
整体流程:PyTorch → ONNX → MNN → C++ SDK → 移动端应用
ONNX 模型导出
移动端部署的第一步是将 PyTorch 模型转换为 ONNX 格式。TinyMind 的整体结构比较清晰:
首先我们抛开tokenizer部分,先专注模型。回顾下inference的过程:
- 首先输入文本部分整体送入词嵌入层,拿到文本embedding;
- 同时图片经过预处理,经过视觉编码器编码,得到视觉特征;
- 经过投影层,与文本embedding对齐;
- 将对齐后的视觉特征嵌入到文本embedding(查找special token的位置,替换部分);
- 送入LM部分,得到相关输出(主要适用next token和kv cache)。
以上步骤就是prefill的过程,后面我们只需要拿kvcahce以及next token,不断的送入LM,更新kv cache,获取next token即可。
综上,我将其拆分为三个独立的子模型:
| 子模型 | 功能 | 输入 | 输出 |
|---|---|---|---|
| Vision Encoder | 视觉编码 + 投影对齐 | 图像像素值 | 视觉特征序列 |
| Embed | 文本嵌入 | Token IDs | 文本嵌入向量 |
| LLM | 语言模型主体 | 嵌入向量 + KV Cache | Logits + 更新后的 KV Cache |
这种拆分方式的好处是:
- 各模块可以独立优化和量化
- Prefill 和 Decode 阶段可以灵活组合
- 便于调试和性能分析
导出 ONNX 时,需要特别注意设置 dynamic_axes,以支持可变长度的输入序列:
torch.onnx.export( model, (input_ids, attention_mask, cos_pe, sin_pe, past_keys, past_values), "onnx_model/llm.onnx", input_names=["input_ids", "attention_mask", "cos_pe", "sin_pe", "past_keys", "past_values"], output_names=["logits", "hidden_states", "present_keys", "present_values"], dynamic_axes={"input_ids": {0: "batch", 1: 'token'}, "attention_mask": {0: "batch", 1: 'token'}, "cos_pe": {0: "batch", 1: 'token'}, "sin_pe": {0: "batch", 1: 'token'}, "past_keys": {1: "cache"}, "past_values": {1: "cache"} }, do_constant_folding=True, verbose=False, opset_version=15)
此外,为了适配 ONNX 的静态图特性,需要对原始代码做一些调整:
- 将 KV Cache 的 key 和 value 分开传递(而非打包成 tuple)
- 将 RoPE 的 cos 和 sin 分量分开传递
- 移除动态的条件分支逻辑
def forward(self, hidden_states: Optional[torch.Tensor] = None, attention_mask: Optional[torch.Tensor] = None, cos_position_embeddings: Optional[torch.Tensor] = None, sin_position_embeddings: Optional[torch.Tensor] = None, past_keys: Optional[torch.Tensor] = None, past_values: Optional[torch.Tensor] = None, use_cache: bool = True): use_cache = True present_keys = [] present_values = [] for layer_idx, layer in enumerate(self.model.layers): hidden_states, present_key, present_value = layer( hidden_states, cos_position_embeddings=cos_position_embeddings, sin_position_embeddings=sin_position_embeddings, past_key=past_keys[layer_idx].unsqueeze(0), past_value=past_values[layer_idx].unsqueeze(0), use_cache=use_cache, attention_mask=attention_mask ) present_keys.append(present_key) present_values.append(present_value) hidden_states = self.model.norm(hidden_states) logits = self.lm_head(hidden_states) return logits, hidden_states, torch.cat(present_keys, 0), torch.cat(present_values, 0)
MNN转换
MNN 是阿里开源的轻量级深度学习推理引擎,在移动端有着出色的性能表现。ONNX 转 MNN 非常简单,使用官方提供的转换工具即可:
MNNConvert -f ONNX --modelFile onnx_model/llm.onnx --optimizePrefer 0 --bizCode MNN --fp16 --info --MNNModel mnn_model/llm.mnn
很幸运,MNN中集成了mnn-llm模块,可以直接将主流大模型转到MNN,其中更是支持tokenizer,这里直接参考MNN官方代码,转为MNN tokenizer支持的格式:
def export_tokenizer(tokenizer_path, export_path, stop_ids=[2]): import base64 tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, trust_remote_code=True, use_fast=False) # TOKENIZER MAGIC NUMBER MAGIC_NUMBER = 430 # TOKENIZER TYPE SENTENCEPIECE = 0 TIKTOIKEN = 1 BERT = 2 HUGGINGFACE = 3 def write_line(fp, *args): for arg in args: for token in arg: fp.write(str(token) + ' ') fp.write('\n') def write_header(fp, type, speicals, prefix=[]): fp.write(f'{MAGIC_NUMBER} {type}\n') fp.write(f'{len(speicals)} {len(stop_ids)} {len(prefix)}\n') write_line(fp, speicals, stop_ids, prefix) file_path = os.path.join(export_path, "tokenizer.txt") special_list = list(tokenizer.added_tokens_decoder.keys()) if hasattr(tokenizer, 'special_tokens'): for k, v in tokenizer.special_tokens.items(): special_list.append(v) if hasattr(tokenizer, 'all_special_ids'): # gemma3 special_list.extend(tokenizer.all_special_ids) if hasattr(tokenizer, 'gmask_token_id'): special_list.append(tokenizer.gmask_token_id) if hasattr(model, 'generation_config') and model.generation_config is not None: generation_config = model.generation_config if hasattr(generation_config, 'user_token_id'): special_list.append(generation_config.user_token_id) if hasattr(generation_config, 'assistant_token_id'): special_list.append(generation_config.assistant_token_id) vocab_list = [] prefix_list = [] if hasattr(tokenizer, 'get_prefix_tokens'): prefix_list = tokenizer.get_prefix_tokens() # Simple prefix token detection if len(prefix_list) == 0: try: test_txt = 'A' ids = tokenizer.encode(test_txt) get_txt = tokenizer.decode(ids[-1]) if len(ids) > 1 and get_txt == test_txt: prefix_list += ids[:-1] except Exception: pass # Determine tokenizer type based on tokenizer class and characteristics tokenizer_class_name = type(tokenizer).__name__.lower() vocab = tokenizer.get_vocab() # Check for SentencePiece-based tokenizers first if ('xlmroberta'in tokenizer_class_name or 'roberta'in tokenizer_class_name or 'sentencepiece'in tokenizer_class_name or hasattr(tokenizer, 'sp_model') or (hasattr(tokenizer, 'vocab_file') and tokenizer.vocab_file and 'sentencepiece'in tokenizer.vocab_file.lower()) or # Check if tokenizer uses SentencePiece patterns (▁ prefix) (len(vocab) > 0 and any('▁'in token for token in list(vocab.keys())[:100]))): tokenizer_type = SENTENCEPIECE print(f"Detected SentencePiece-based tokenizer: {tokenizer_class_name}") elif'bert'in tokenizer_class_name: tokenizer_type = BERT print(f"Detected BERT tokenizer: {tokenizer_class_name}") else: tokenizer_type = TIKTOIKEN print(f"Detected TikToken tokenizer: {tokenizer_class_name}") vocab = tokenizer.get_vocab() if tokenizer_type == SENTENCEPIECE: # Handle SentencePiece tokenizer (like XLMRoberta) # Try to get SentencePiece model if available sp_model_path = None if hasattr(tokenizer, 'vocab_file') and tokenizer.vocab_file: sp_model_path = tokenizer.vocab_file elif hasattr(tokenizer, 'sp_model_kwargs'): sp_model_path = getattr(tokenizer, 'vocab_file', None) if sp_model_path and os.path.exists(sp_model_path): # Use existing SentencePiece export logic print(f"Found SentencePiece model file: {sp_model_path}") # This will be handled by the existing SentencePiece logic above # For now, fall back to vocab-based export pass # Export SentencePiece vocabulary in the correct format vocab_list = [] NORMAL = 1 # SentencePiece piece type for token, token_id in sorted(vocab.items(), key=lambda x: x[1]): try: # SentencePiece tokens are typically already properly encoded token_bytes = token.encode('utf-8') token_b64 = base64.b64encode(token_bytes).decode('utf-8') # Format: token_base64 score piece_type vocab_list.append(f'{token_b64} 0.0 {NORMAL}\n') except Exception as e: print(f"Warning: Failed to encode SentencePiece token '{token}': {e}") # Use replacement character for problematic tokens token_b64 = base64.b64encode('▁'.encode('utf-8')).decode('utf-8') vocab_list.append(f'{token_b64} 0.0 {NORMAL}\n') with open(file_path, "w", encoding="utf8") as fp: write_header(fp, SENTENCEPIECE, special_list, prefix_list) fp.write(f'{len(vocab_list)}\n') for vocab_line in vocab_list: fp.write(vocab_line) else: # Handle BERT or TikToken tokenizer # bert tokenizer def unicode_to_byte(u: int): # Handle special unicode mappings for BERT tokenizers if u >= 256 and u <= 288: return u - 256 if u >= 289 and u <= 322: return u - 162 if u == 323: return 173 return u vocab_list = ['<unk>'for i in range(len(vocab))] # Process vocabulary with better UTF-8 handling for k, v in vocab.items(): if tokenizer_type == "BERT": try: # For BERT tokenizers, preserve the original token format # Most BERT models already have proper UTF-8 encoded tokens vocab_list[int(v)] = k.encode('utf-8') except Exception as e: # Fallback: try unicode_to_byte conversion for special cases try: vocab_list[int(v)] = bytes([unicode_to_byte(ord(c)) for c in k]) except Exception as e2: print(f"Warning: Failed to encode token '{k}' with id {v}: {e2}") vocab_list[int(v)] = k.encode('utf-8', errors='replace') else: # Fallback: try unicode_to_byte conversion for special cases try: vocab_list[int(v)] = bytes([unicode_to_byte(ord(c)) for c in k]) except Exception as e2: print(f"Warning: Failed to encode token '{k}' with id {v}: {e2}") vocab_list[int(v)] = k.encode('utf-8', errors='replace') special_list = list(tokenizer.added_tokens_decoder.keys()) with open(file_path, "w", encoding="utf8") as fp: write_header(fp, tokenizer_type, special_list) fp.write(f'{len(vocab_list)}\n') for v in vocab_list: line = base64.b64encode(v).decode("utf8") + "\n" fp.write(line) return file_path
C++推理
如上节所说,MNN 还内置了 mnn-llm 模块,支持主流大模型的一键转换和部署。不过,对于自定义模型结构,直接使用 mnn-llm 需要修改较多源码,不如自己基于 MNN 底层 API 实现来得灵活。
这部分没啥好说,直接开撸上代码。
- Tokenizer
避免造轮子,tokenizer直接使用mnn-llm中的源码,把相关文件摘出来(tokenizer、llmconfig、prompt以及minja和rapidjson),简单修改即可使用。
配置文件
{ "system_prompt": "你是一个多模态AI助手,能够理解图片和文本信息.", "system_prompt_template": "%s", "user_prompt_template": "%s", "assistant_prompt_template": "%s", "jinja": { "chat_template": “jinja文件中的聊天模版”, "bos": "<|im_start|>", "eos": "<|im_end|>" }}
测试代码:
std::shared_ptr<LlmConfig> mConfig(new LlmConfig(“./llm_config.json")); std::shared_ptr<TalkUHulk::LlmContext> mContext(new TalkUHulk::LlmContext); std::shared_ptr<Prompt> mPrompt(Prompt::createPrompt(mContext, mConfig)); std::shared_ptr<Tokenizer> mTokenizer; mTokenizer.reset(Tokenizer::createTokenizer("上一步生成的tokenizer/tokenizer.txt")); std::string user_content = "如何做一道番茄炒蛋"; std::string prompt = mPrompt->applyTemplate(user_content, true); std::cout << "prompt:" << prompt << std::endl; std::vector<int> input_ids = mTokenizer->encode(prompt); auto seqlen = input_ids.size() ; std::cout << "input_ids length:" << input_ids.size() << std::endl; for(auto i: input_ids){ std::cout << i << ","; } std::cout << std::endl;
- 位置编码
预计算 RoPE 所需的 cos/sin 值,避免推理时重复计算:
void TinyMind::precompute_freqs_cis( std::vector<std::vector<float>> &freqs_cos, std::vector<std::vector<float>> &freqs_sin, int dim, int end, float rope_base, bool use_scaling, int orig_max, float factor, float beta_fast, float beta_slow ) { int half = dim / 2; std::vector<float> freqs(half); for (int i = 0; i < half; ++i) { float exponent = float(i) / half; freqs[i] = 1.0f / std::pow(rope_base, exponent); } if (use_scaling && float(end) / orig_max > 1.0f) { // 找 corr_dim:第一个满足 2π/freq > orig_max 的 index int corr_dim = half; for (int i = 0; i < half; ++i) { if (2 * M_PI / freqs[i] > orig_max) { corr_dim = i; break; } } // 计算 beta[i] = beta_slow + (beta_fast - beta_slow) * (i / (half-1)) std::vector<float> beta(half); for (int i = 0; i < half; ++i) { float power = float(i) / std::max(half - 1, 1); beta[i] = beta_slow + (beta_fast - beta_slow) * power; } // scale[i] std::vector<float> scale(half); for (int i = 0; i < half; ++i) { if (i < corr_dim) { scale[i] = (beta[i] * factor - beta[i] + 1) / (beta[i] * factor); } else { scale[i] = 1.0f / factor; } } // apply scale for (int i = 0; i < half; ++i) { freqs[i] *= scale[i]; } } std::vector<float> t(end); for (int i = 0; i < end; ++i) t[i] = float(i); std::vector<std::vector<float>> freqs_mat(end, std::vector<float>(half)); for (int i = 0; i < end; ++i) { for (int j = 0; j < half; ++j) { freqs_mat[i][j] = t[i] * freqs[j]; } } freqs_cos.resize(end, std::vector<float>(dim)); freqs_sin.resize(end, std::vector<float>(dim)); for (int i = 0; i < end; ++i) { for (int j = 0; j < half; ++j) { float v = freqs_mat[i][j]; float c = std::cos(v); float s = std::sin(v); freqs_cos[i][j] = c; freqs_sin[i][j] = s; freqs_cos[i][j + half] = c; freqs_sin[i][j + half] = s; } } }
- Prefill 阶段
Prefill 阶段处理完整的输入序列,生成初始的 KV Cache:
int TinyMind::prefill(const std::vector<int> &input_ids, const std::vector<int>& input_ids_shape, const std::vector<int>& attention_mask, const std::vector<int>& attention_mask_shape, const std::vector<float> &deepstack_embeds, const std::vector<int> &deepstack_embeds_shape, int& predict_token){ if(!m_initialed) return 101; std::vector<float> embed_tokens; std::vector<int> embed_tokens_shape; mEmbedTokensModel->forward(input_ids.data(), input_ids_shape, embed_tokens, embed_tokens_shape); //替换图片token std::vector<int> image_indices; find_indices(input_ids, image_indices); assert(image_indices.size() == 17); int N=17, T=49, D=512; // deepstack_embeds_shape, 17张图固定的尺寸,1x17x49x512 // embed_tokens 的大小应该是 1xLx512 // 默认batch=1 for(int i = 0; i < N; i++){ int image_index = image_indices[i]; int start_idx = image_index + 2; float* dst = embed_tokens.data() + D * start_idx; const float *src = deepstack_embeds.data() + i * T * D; std::copy(src, src + T * D, dst); } std::vector<std::vector<float>> outputs; std::vector<std::vector<int>> outputs_shape; std::vector<int> pe_shape{static_cast<int>(input_ids.size()), m_dim}; std::vector<int> past_kv_shape{m_num_hidden_layers, 0, m_num_key_value_heads, m_dim}; std::vector<float> pos_cos, pos_sin; for(int i = 0; i < static_cast<int>(input_ids.size()); i++){ for(int j = 0; j < m_dim; j++){ pos_cos.push_back(m_freqs_cos[i][j]); pos_sin.push_back(m_freqs_sin[i][j]); } } std::vector<float> past_keys, past_values; mLLMModel->forward(embed_tokens.data(), embed_tokens_shape, attention_mask.data(), attention_mask_shape, pos_cos.data(), pe_shape, pos_sin.data(), pe_shape, past_keys.data(), past_kv_shape, past_values.data(), past_kv_shape, outputs, outputs_shape ); auto logits = std::move(outputs[0]); auto logits_shape = std::move(outputs_shape[0]); m_past_keys = std::move(outputs[2]); m_past_values = std::move(outputs[3]); m_past_kv_shape = std::move(outputs_shape[3]); int product = (int)std::accumulate(logits_shape.begin(), logits_shape.end(), 1.0f, std::multiplies<>()); std::vector<float> last_logit(logits.begin() + product - m_vocab_size, logits.begin() + product); predict_token = TalkUHulk::argmax(last_logit); return 0; }
- Decode 阶段(自回归生成) Decode 阶段逐 token 生成,支持流式输出:
int TinyMind::generate(const std::string& inputs_text, std::string& response, const cv::Mat &bgr,int max_new_tokens, bool do_sample, float temperature, int topK, float topP){ if(!m_initialed) return 101;// auto bgr = cv::imread(image_path); std::vector<float> pixel_values; std::vector<int> mask_token_id; image_preprocess_with_split(bgr, pixel_values, mask_token_id); std::string prompt = mPrompt->applyTemplate(inputs_text + m_image_place_holder, true); std::vector<int> input_ids = mTokenizer->encode(prompt); std::vector<int> input_ids_shape{1, static_cast<int>(input_ids.size())}; int seqlen = static_cast<int>(input_ids.size()); std::vector<int> attention_mask(static_cast<int>(input_ids.size()), 1); std::vector<int> attention_mask_shape{1, static_cast<int>(input_ids.size())}; // 计算图像token std::vector<float> deepstack_embeds; std::vector<int> deepstack_embeds_shape; std::vector<int> pixel_values_shape{17, 3, 224, 224}; mVisionEncoderModel->forward(pixel_values.data(), pixel_values_shape, deepstack_embeds, deepstack_embeds_shape); // mask掉填充的图片patch for (int token : mask_token_id) { for (int i = 0; i < seqlen - 1; i++) { if (input_ids[i] == 3 && input_ids[i + 1] == token) { // "<fake_token_around_image>"], token int start = i + 2; int end = start + 49; // 49个<image> for (int j = start; j < end; j++) { attention_mask[j] = 0; } break; } } } int token_id; response.clear(); // prefill auto tic = std::chrono::system_clock::now(); prefill(input_ids, input_ids_shape, attention_mask, attention_mask_shape, deepstack_embeds, deepstack_embeds_shape, token_id); auto toc = std::chrono::system_clock::now(); std::chrono::duration<double> elapsed_seconds = toc - tic; std::cout << "首token耗时: " << elapsed_seconds.count() * 1000 << " ms" << std::endl; spdlog::get("TinyMind")->debug("首token耗时: :{}ms", elapsed_seconds.count() * 1000); auto generate_token_num = 0; auto start_pos = seqlen; while(generate_token_num < max_new_tokens){ auto decoded_token = mTokenizer->decode(token_id); std::cout << decoded_token << std::flush; response += decoded_token; if (m_stream_cb) m_stream_cb(decoded_token); attention_mask.push_back(1); attention_mask_shape[1] += 1; std::vector<int> pe_shape{1, m_dim}; std::vector<float> pos_cos, pos_sin; for(int j = 0; j < m_dim; j++){ pos_cos.push_back(m_freqs_cos[start_pos][j]); pos_sin.push_back(m_freqs_sin[start_pos][j]); } input_ids.clear(); input_ids.push_back(token_id); input_ids_shape[1] = 1; std::vector<float> embed_tokens; std::vector<int> embed_tokens_shape; std::vector<std::vector<float>> outputs; std::vector<std::vector<int>> outputs_shape; mEmbedTokensModel->forward(input_ids.data(), input_ids_shape, embed_tokens, embed_tokens_shape); mLLMModel->forward(embed_tokens.data(), embed_tokens_shape, attention_mask.data(), attention_mask_shape, pos_cos.data(), pe_shape, pos_sin.data(), pe_shape, m_past_keys.data(), m_past_kv_shape, m_past_values.data(), m_past_kv_shape, outputs, outputs_shape ); auto logits = std::move(outputs[0]); auto logits_shape = std::move(outputs_shape[0]); // outputs[1] 是 hidden_states,推理用不着 m_past_keys = std::move(outputs[2]); m_past_values = std::move(outputs[3]); m_past_kv_shape = std::move(outputs_shape[3]); int product = (int)std::accumulate(logits_shape.begin(), logits_shape.end(), 1.0f, std::multiplies<>()); std::vector<float> last_logit(logits.begin() + product - m_vocab_size, logits.begin() + product); // 先不开,待检查 if(do_sample){ softmax_with_temperature(last_logit, temperature); if (topK > 0) sample_topK(last_logit, topK); if (topP < 1.0f) sample_topP(last_logit, topP); token_id = multinomial_sample(last_logit); } else{ token_id = TalkUHulk::argmax(last_logit); } if(token_id == m_end_token_id){// decoded_token = mTokenizer->decode(token_id);// response += decoded_token;// if (m_stream_cb) m_stream_cb(decoded_token);// std::cout << decoded_token << std::flush; break; } start_pos++; generate_token_num++; } return 0; }
详细代码参见git。
Mac(intel)deme
移动端部署篇
完成 C++ 推理后,下一步是将其封装为移动端可用的 SDK,并集成到 iOS/Android 应用中。
为了方便跨平台,将C++代码用C方式导出:
#pragma once#if defined(_MSC_VER)#if defined(BUILDING_TalkUHulk_DLL)#define TalkUHulk_PUBLIC __declspec(dllexport)#elif defined(USING_TalkUHulk_DLL)#define TalkUHulk_PUBLIC __declspec(dllimport)#else#define TalkUHulk_PUBLIC#endif#else#define TalkUHulk_PUBLIC __attribute__((visibility("default")))#endifclass TalkUHulk_PUBLIC TinyMindInterpreter{ public: virtual int initial(const char *config) = 0; virtual int forward(const char* prompt, const void *raw, int raw_length, bool flip, int max_new_token, char* response, int* response_length) = 0; virtual void setStreamCallback(void(*cb)(const char* token)) = 0; virtual ~TinyMindInterpreter() = default;};#ifdef __cplusplusextern "C"{#endif//! Dll接口,获取类SDK实例/*! * @return 类实例指针 */TalkUHulk_PUBLIC void *getInstance();//! Dll接口,销毁SDK实例/*! * @param pInstance 待销毁实例 */TalkUHulk_PUBLIC void releaseInstance(void *pInstance);TalkUHulk_PUBLIC void setStreamCallback(void *pInstance, void(*cb)(const char* token));#ifdef __cplusplus};#endif
iOS 部署
这里使用Swift做个简单的demo。
- 编译 iOS Framework
cmake_minimum_required(VERSION 3.20)project(tinymind_vl_cpp CXX C)set(CMAKE_CXX_STANDARD 17)set(CMAKE_CXX_STANDARD_REQUIRED ON)set(CMAKE_OSX_ARCHITECTURES "arm64")find_library(FOUNDATION Foundation)find_library(METAL Metal REQUIRED)find_library(GRAPHIC CoreGraphics)find_library(CORE_VIDEO_LIBRARY CoreVideo)find_library(COREML_LIBRARY CoreML)find_library(CFLIB CoreFoundation REQUIRED)add_definitions(-DGUID_CFUUID)set(OPENCV_FRAMEWORK_PATH ${CMAKE_SOURCE_DIR}/libs/ios/opencv2.framework)set(MNN_FRAMEWORK_PATH ${CMAKE_SOURCE_DIR}/libs/ios/MNN.framework/)set(HEADER_FILES ${CMAKE_SOURCE_DIR}/c_api/talkuhulk.h)set(RESOURCE_FILES ${CMAKE_BINARY_DIR}/Resources)file(MAKE_DIRECTORY ${RESOURCE_FILES})file(GLOB MODEL_FILES ${CMAKE_SOURCE_DIR}/models/*)file(COPY ${MODEL_FILES} DESTINATION ${RESOURCE_FILES})file(GLOB_RECURSE CORE_SOURCE_FILES ${CMAKE_CURRENT_LIST_DIR}/c_api/*.cpp ${CMAKE_CURRENT_LIST_DIR}/3rdparty/minja/*.cpp ${CMAKE_CURRENT_LIST_DIR}/source/*.cpp)include_directories(${CMAKE_CURRENT_LIST_DIR}/3rdparty ${CMAKE_CURRENT_LIST_DIR}/source ${OpenCV_INCLUDE_DIRS} )add_library(tinymind_vl_cpp STATIC ${CORE_SOURCE_FILES}${HEADER_FILES}${RESOURCE_FILES})#add_library(tinymind_vl_cpp SHARED ${CORE_SOURCE_FILES} ${HEADER_FILES} ${RESOURCE_FILES})set_target_properties(tinymind_vl_cpp PROPERTIES FRAMEWORK TRUE FRAMEWORK_VERSION A MACOSX_FRAMEWORK_IDENTIFIER com.TalkUHulk.tinymind # MACOSX_FRAMEWORK_INFO_PLIST Info.plist # "current version" in semantic format in Mach-O binary file VERSION 1.0.0 # "compatibility version" in semantic format in Mach-O binary file SOVERSION 1.0.0 PUBLIC_HEADER "${HEADER_FILES}" RESOURCE "${RESOURCE_FILES}" # XCODE_ATTRIBUTE_CODE_SIGN_IDENTITY "iPhone Developer")target_include_directories(tinymind_vl_cpp PRIVATE ${OPENCV_FRAMEWORK_PATH}/Headers)target_link_directories(tinymind_vl_cpp PRIVATE ${OPENCV_FRAMEWORK_PATH})target_include_directories(tinymind_vl_cpp PRIVATE ${MNN_FRAMEWORK_PATH}/Headers)target_link_directories(tinymind_vl_cpp PRIVATE ${MNN_FRAMEWORK_PATH})target_link_libraries(tinymind_vl_cpp PRIVATE "-framework ${MNN_FRAMEWORK_PATH}/MNN" "-framework ${OPENCV_FRAMEWORK_PATH}/opencv2" "-framework Foundation" "-framework UIKit" "-framework AVFoundation" "-framework CoreGraphics" PUBLIC ${FOUNDATION} PUBLIC ${METAL} PUBLIC ${GRAPHIC} PUBLIC ${CORE_VIDEO_LIBRARY} PUBLIC ${COREML_LIBRARY} PUBLIC ${CFLIB})set_xcode_property(tinymind_vl_cpp GCC_GENERATE_DEBUGGING_SYMBOLS YES "All")add_custom_command( TARGET tinymind_vl_cpp POST_BUILD COMMAND ${CMAKE_COMMAND} -E rm -rf ${RESOURCE_FILES})
编译一下:cmake .. -G Xcode -DCMAKE_TOOLCHAIN_FILE=../toolchains/ios.toolchain.cmake -DPLATFORM=OS64
cmake --build . --config Release
我们会得到如下的东西:
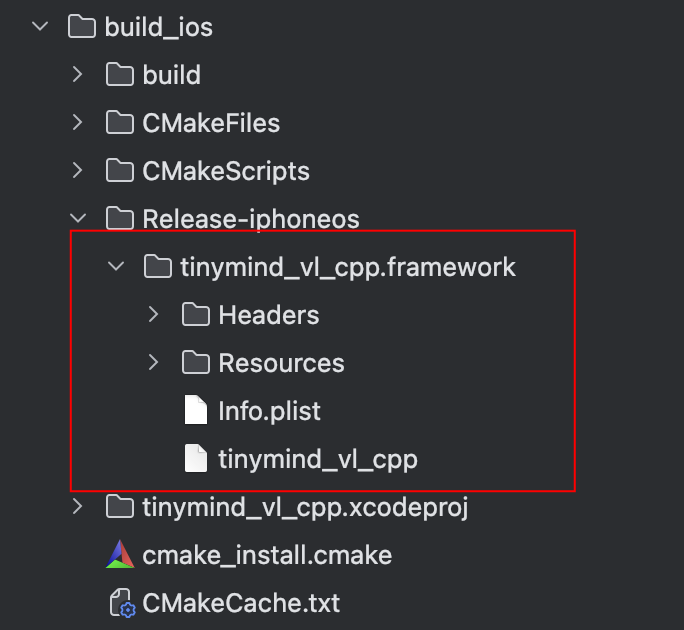
- Swift开发
非移动端开发,作为一个门外汉,自己一些粗略的认知,swift不能直接调用c++,必须用 oc(.mm)当桥梁。
TinyMindInterpreterBridge.h```// Created by TalkUHulk on 2025/12/03. // #import <Foundation/Foundation.h>
@interface TinyMindInterpreterBridge : NSObject
-
(instancetype)init;
-
(void)setStreamCallback:(void (^)(NSString *token))callback;
-
(NSString *)forward:(NSString *)prompt imageRaw:(NSData *)raw flip:(BOOL)flip maxNewToken:(int)maxToken;
-
(instancetype)sharedCurrentBridge;
-
(void)setSharedCurrentBridge:(TinyMindInterpreterBridge *)bridge; @end
> 毕竟不是搞ios的,印象里把模型等资源打包进framework里,可以直接读取的。这里老是读不到模型文件,图省事,直接把json的配置文件做了动态修改。TinyMindInterpreterBridge.mm```#import "TinyMindInterpreterBridge.h"#import "talkuhulk.h"#include <string>#include <vector>extern "C" { void *getInstance(); void releaseInstance(void *pInstance); /// 传递给 C++ 的 token 回调 typedef void(*StreamCallbackC)(const char *token); /// 设置 C++ 流式回调 void setStreamCallback(void *pInstance, StreamCallbackC cb);}class TinyMindInterpreter;static TinyMindInterpreterBridge *gCurrentBridge = nil;@interface TinyMindInterpreterBridge (){ TinyMindInterpreter* _instance; void(^_swiftCallback)(NSString *);}@end@implementation TinyMindInterpreterBridge#pragma mark - Shared Instance for Callbacks+ (instancetype)sharedCurrentBridge { return gCurrentBridge;}+ (void)setSharedCurrentBridge:(TinyMindInterpreterBridge *)bridge { gCurrentBridge = bridge;}#pragma mark - Init / Dealloc- (instancetype)init { self = [super init]; if (self) { // 保存当前实例用于 C 回调 [TinyMindInterpreterBridge setSharedCurrentBridge:self]; // 创建 C++ 对象 _instance = (TinyMindInterpreter *)getInstance(); // 配置文件加载 NSString *configPath = [[NSBundle mainBundle] pathForResource:@"config" ofType:@"json"]; if (!configPath) { NSLog(@"[TinyMind] 找不到 Resource/config.json"); } else { NSLog(@"[TinyMind] 加载配置: %@", configPath); } NSString *bundlePath = [[NSBundle mainBundle] bundlePath]; NSData *jsonData = [NSData dataWithContentsOfFile:configPath]; NSError *error; NSMutableDictionary *jsonDict = [NSJSONSerialization JSONObjectWithData:jsonData options:NSJSONReadingMutableContainers error:&error]; if (error || !jsonDict) { NSLog(@"读取 JSON 失败: %@", error.localizedDescription); } // 4. 修改模型路径为绝对路径 NSString *llmConfigRel = jsonDict[@"llm_config"]; if (llmConfigRel) { NSString *llmConfigAbs = [bundlePath stringByAppendingPathComponent:[llmConfigRel stringByReplacingOccurrencesOfString:@"./" withString:@""]]; jsonDict[@"llm_config"] = llmConfigAbs; } NSString *tokenizerRel = jsonDict[@"tokenizer"]; if (tokenizerRel) { NSString *tokenizerAbs = [bundlePath stringByAppendingPathComponent:[tokenizerRel stringByReplacingOccurrencesOfString:@"./" withString:@""]]; jsonDict[@"tokenizer"] = tokenizerAbs; } NSDictionary *modelDict = jsonDict[@"model"]; NSMutableDictionary *newModelDict = [NSMutableDictionary dictionary]; [modelDict enumerateKeysAndObjectsUsingBlock:^(id key, id obj, BOOL *stop) { NSMutableDictionary *subDict = [obj mutableCopy]; NSString *relPath = subDict[@"model_path"]; if (relPath) { NSString *absPath = [bundlePath stringByAppendingPathComponent:[relPath stringByReplacingOccurrencesOfString:@"./" withString:@""]]; subDict[@"model_path"] = absPath; } newModelDict[key] = subDict; }]; jsonDict[@"model"] = newModelDict; // 5. 写入临时目录生成新 JSON 文件 NSString *tmpDir = NSTemporaryDirectory(); NSString *newConfigPath = [tmpDir stringByAppendingPathComponent:@"config_runtime.json"]; NSData *newJsonData = [NSJSONSerialization dataWithJSONObject:jsonDict options:NSJSONWritingPrettyPrinted error:&error]; if (error) { NSLog(@"写入新 JSON 失败: %@", error.localizedDescription); } [newJsonData writeToFile:newConfigPath atomically:YES]; NSLog(@"新 JSON 路径: %@", newConfigPath); std::string cfg = [newConfigPath UTF8String]; int ret = _instance->initial(cfg.c_str()); if (ret != 0) { NSLog(@"[TinyMind] C++ SDK 初始化失败 ret=%d", ret); } else { NSLog(@"[TinyMind] C++ SDK 初始化成功"); } } return self;}- (void)dealloc { if (_instance) { releaseInstance(_instance); _instance = nullptr; }}#pragma mark - Stream Callback- (void)setStreamCallback:(void (^)(NSString *token))callback { _swiftCallback = [callback copy]; // C回调函数,传给 C++ StreamCallbackC cCallback = [](const char *tokenCStr) { if (!tokenCStr) return; NSString *token = [NSString stringWithUTF8String:tokenCStr]; // 派发回主线程 dispatch_async(dispatch_get_main_queue(), ^{ TinyMindInterpreterBridge *bridge = [TinyMindInterpreterBridge sharedCurrentBridge]; if (bridge && bridge->_swiftCallback) { bridge->_swiftCallback(token); } }); }; // 传给 C++ 层 setStreamCallback(_instance, cCallback);}#pragma mark - Forward- (NSString *)forward:(NSString *)prompt imageRaw:(NSData *)raw flip:(BOOL)flip maxNewToken:(int)maxToken{ if (!_instance) return @""; std::string promptStr = [prompt UTF8String]; int bufSize = maxToken * 4 + 512; std::vector<char> buffer(bufSize); int responseLen = bufSize; int ret = _instance->forward( promptStr.c_str(), raw.bytes, (int)raw.length, flip, maxToken, buffer.data(), &responseLen ); if (ret == -2) { buffer.resize(responseLen); ret = _instance->forward( promptStr.c_str(), raw.bytes, (int)raw.length, flip, maxToken, buffer.data(), &responseLen ); } if (ret != 0) { return @""; } return [[NSString alloc] initWithBytes:buffer.data() length:responseLen encoding:NSUTF8StringEncoding];}@end
下面就可以愉快的在swift中调用了:
private func runVLLM(prompt: String, imageData: Data?) { let placeholderText = "AI 正在思考..." let placeholderMessage = Message(sender: .ai, text: placeholderText) messages.append(placeholderMessage) tableView.reloadData() scrollToBottom() DispatchQueue.global().async { let response = self.sdk?.forward(prompt, imageRaw: imageData, flip: false, maxNewToken: 128) DispatchQueue.main.async { iflet index = self.messages.lastIndex(where: { $0.text == placeholderText && $0.sender == .ai }) { self.messages[index] = Message(sender: .ai, text: response ?? "未能获取 AI 回复") } else { self.messages.append(Message(sender: .ai, text: response ?? "未能获取 AI 回复")) } self.tableView.reloadData() self.scrollToBottom() } } }
测试机器Iphone13 Pro Max(cpu):首token大约500ms,
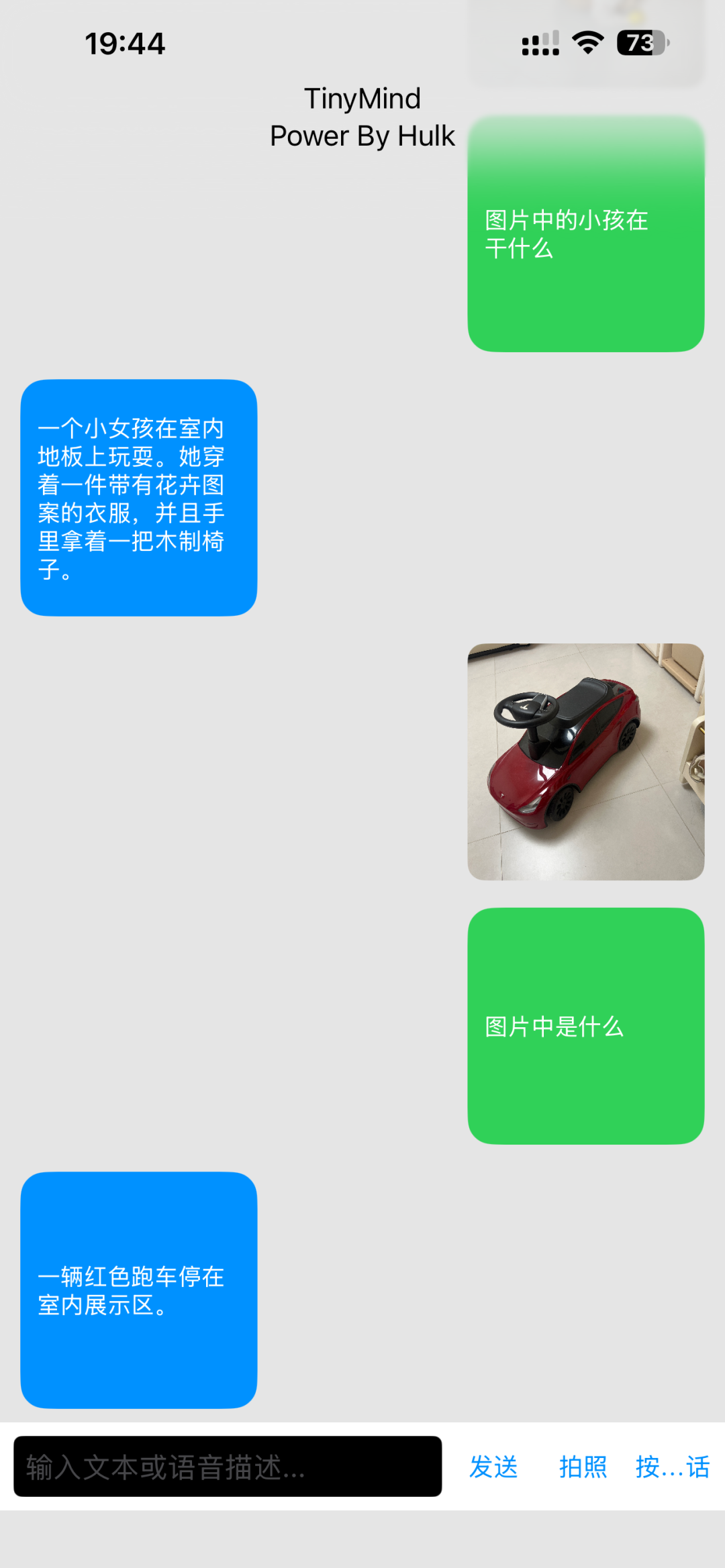
一些不成熟的demo示例:


Android
Android部分类似,在SDK的基础上,首先完成动态库的编译,然后写JNI,最后kotlin的编写。
JNI部分(未验证) TalkUHulkJni.h
//// Created by TalkUHulk on 2025/12/5.//#pragma once#include <jni.h>#include <string>#include "talkuhulk.h"#ifdef __cplusplusextern "C" {#endifJNIEXPORT jlong JNICALLJava_com_hulk_TalkUHulkJni_nativeGetInstance(JNIEnv *env, jclass clazz);JNIEXPORT void JNICALLJava_com_hulk_TalkUHulkJni_nativeReleaseInstance(JNIEnv *env, jclass clazz, jlong handle);JNIEXPORT jint JNICALL Java_com_hulk_TalkUHulkJni_nativeInitial(JNIEnv *env, jclass clazz, jlong handle, jstring config);JNIEXPORT jint JNICALL Java_com_hulk_TalkUHulkJni_nativeForward(JNIEnv *env, jclass clazz,jlong handle, jstring prompt,jbyteArray raw, jboolean flip,jint max_new_token, jbyteArray response,jintArray response_length);JNIEXPORT void JNICALLJava_com_hulk_TalkUHulkJni_nativeSetStreamCallback(JNIEnv *env, jclass clazz, jlong handle,jobject callback);#ifdef __cplusplus}#endif
TalkUHulkJni.cpp
//// Created by TalkUHulk on 2025/12/5.//#include "TalkUHulkJni.h"#include <cstring>static JavaVM *gVm = nullptr;struct JCallbackHolder { jobject callbackObj = nullptr; jmethodID onTokenMethod = nullptr;};static JCallbackHolder gCallback;// 把 C++ token 流给 Java 的回调static void stream_callback(const char *token) { if (!gCallback.callbackObj) return; JNIEnv *env = nullptr; gVm->AttachCurrentThread(&env, nullptr); jstring jToken = env->NewStringUTF(token); env->CallVoidMethod(gCallback.callbackObj, gCallback.onTokenMethod, jToken); env->DeleteLocalRef(jToken);}jint JNI_OnLoad(JavaVM *vm, void *) { gVm = vm; return JNI_VERSION_1_6;}JNIEXPORT jlong JNICALL Java_com_hulk_TalkUHulkJni_nativeGetInstance(JNIEnv *env, jclass clazz) {return reinterpret_cast<jlong>(getInstance());}JNIEXPORT void JNICALLJava_com_hulk_TalkUHulkJni_nativeReleaseInstance(JNIEnv *env, jclass clazz, jlong handle) {releaseInstance(reinterpret_cast<void *>(handle));}JNIEXPORT jint JNICALL Java_com_hulk_TalkUHulkJni_nativeInitial(JNIEnv *env, jclass clazz, jlong handle, jstring config) {const char *cfg = env->GetStringUTFChars(config, nullptr);TinyMindInterpreter *inst = reinterpret_cast<TinyMindInterpreter *>(handle);int ret = inst->initial(cfg);env->ReleaseStringUTFChars(config, cfg);return ret;}JNIEXPORT jint JNICALL Java_com_hulk_TalkUHulkJni_nativeForward(JNIEnv *env, jclass clazz,jlong handle, jstring prompt,jbyteArray raw, jboolean flip,jint max_new_token, jbyteArray response,jintArray response_length) {TinyMindInterpreter *inst = reinterpret_cast<TinyMindInterpreter *>(handle);// promptconst char *c_prompt = env->GetStringUTFChars(prompt, nullptr);// raw imagejsize raw_len = env->GetArrayLength(raw);jbyte *raw_bytes = env->GetByteArrayElements(raw, nullptr);// output bufferjbyte *resp_buf = env->GetByteArrayElements(response, nullptr);// response lengthjint *resp_len = env->GetIntArrayElements(response_length, nullptr);int ret = inst->forward(c_prompt, raw_bytes, raw_len, flip, max_new_token, reinterpret_cast<char *>(resp_buf), resp_len);env->ReleaseStringUTFChars(prompt, c_prompt);env->ReleaseByteArrayElements(raw, raw_bytes, 0);env->ReleaseByteArrayElements(response, resp_buf, 0);env->ReleaseIntArrayElements(response_length, resp_len, 0);return ret;}JNIEXPORT void JNICALLJava_com_hulk_TalkUHulkJni_nativeSetStreamCallback(JNIEnv *env, jclass clazz, jlong handle, jobject callback) {TinyMindInterpreter *inst = reinterpret_cast<TinyMindInterpreter *>(handle);if (gCallback.callbackObj) {env->DeleteGlobalRef(gCallback.callbackObj);}gCallback.callbackObj = env->NewGlobalRef(callback);jclass cls = env->GetObjectClass(callback);gCallback.onTokenMethod = env->GetMethodID(cls, "onToken", "(Ljava/lang/String;)V");inst->setStreamCallback(stream_callback);}
CMakelist.txt
cmake_minimum_required(VERSION 3.20)project(tinymind_vl_cpp)set(CMAKE_CXX_STANDARD 17)set(CMAKE_CXX_STANDARD_REQUIRED ON)file(GLOB_RECURSE CORE_SOURCE_FILES ${CMAKE_CURRENT_LIST_DIR}/c_api/*.cpp ${CMAKE_CURRENT_LIST_DIR}/3rdparty/minja/*.cpp ${CMAKE_CURRENT_LIST_DIR}/source/*.cpp)include_directories(${CMAKE_CURRENT_LIST_DIR}/3rdparty ${CMAKE_CURRENT_LIST_DIR}/source ${CMAKE_SOURCE_DIR}/c_api ${CMAKE_SOURCE_DIR}/jni )link_directories(${CMAKE_CURRENT_LIST_DIR}/libs/android/)add_library(MNN SHARED IMPORTED)add_library(MNN_CL SHARED IMPORTED)add_library(MNN_Express SHARED IMPORTED)add_library(MNN_Vulkan SHARED IMPORTED)add_library(mnncore SHARED IMPORTED)set_target_properties( MNN PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/MNN/arm64-v8a/libMNN.so)set_target_properties( MNN_CL PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/MNN/arm64-v8a/libMNN_CL.so)set_target_properties( MNN_Express PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/MNN/arm64-v8a/libMNN_Express.so)set_target_properties( MNN_Vulkan PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/MNN/arm64-v8a/libMNN_Vulkan.so)set_target_properties( mnncore PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/MNN/arm64-v8a/libmnncore.so)list(APPEND LINK_LIBS MNN MNN_CL MNN_Express MNN_Vulkan mnncore)find_library( log-lib log )list(APPEND LINK_LIBS ${log-lib})set(OpenCV_DIR ${CMAKE_CURRENT_LIST_DIR}/libs/android/opencv)include_directories(${OpenCV_DIR}/native/jni/include)add_library(lib_opencv STATIC IMPORTED)set_target_properties(lib_opencv PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/opencv/native/libs/${ANDROID_ABI}/libopencv_java4.so)add_library(libc++_shared STATIC IMPORTED)set_target_properties(libc++_shared PROPERTIES IMPORTED_LOCATION ${CMAKE_CURRENT_LIST_DIR}/libs/android/opencv/native/libs/${ANDROID_ABI}/libc++_shared.so)list(APPEND CORE_SOURCE_FILES ${CMAKE_SOURCE_DIR}/jni/TalkUHulkJni.cpp)add_library(tinymind_vl_cpp SHARED ${CORE_SOURCE_FILES})target_link_libraries(tinymind_vl_cpp libc++_shared lib_opencv ${LINK_LIBS} android -ljnigraphics)
编译即可得到so库cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=~/Library/Android/sdk/ndk/25.1.8937393/build/cmake/android.toolchain.cmake -DANDROID_ABI=arm64-v8a -DANDROID_PLATFORM=30 -DANDROID_STL=c++_shared ..

更新android studio后,gradle更新一直有问题…搞不动了,kotlin部分就不写了,具体步骤可参考我之前的开源(非专业android开发,谨慎食用):ai.deploy.box
总结
本文在minimind的基础上,通过替换视觉编码器的初级手段,重新训练了一个90M的轻量化多模态模型。之后依据SmolVLM的设计准则,进行了针对性优化实验。最后成功实现了从PyTorch到ONNX到MNN模型的转换,验证了模型在iPhone等移动端设备上高效推理的可行性。尽管当前模型在性能上仍有提升空间,但本次实践在验证移动端实时推理的可行性、探索完整工程化路径等方面取得了实质进展,为社区提供了一个可复现、可改进的基线模型。后续我将持续优化模型性能,并拓展更多应用场景。因个人水平有限,文中若有任何不足,欢迎指正~。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献476条内容
已为社区贡献476条内容

所有评论(0)