保姆级教程!Spring AI可观测性零代码改造,手把手教你告别AI“黑盒”!
自 2022 年底 GPT-3.5 引爆大模型革命以来,AI 应用经历了从技术探索到产业落地的快速演进。开源模型迭代与低代码平台的兴起,推动了 AI Agent 开发效率的显著提升。然而,行业普遍面临一个核心矛盾:绝大多数 AI 应用仍停留在 demo 阶段,很难在企业级生产环境中大规模落地。最终能形成一个线上服务产品的更是少之又少。
自 2022 年底 GPT-3.5 引爆大模型革命以来,AI 应用经历了从技术探索到产业落地的快速演进。开源模型迭代与低代码平台的兴起,推动了 AI Agent 开发效率的显著提升。然而,行业普遍面临一个核心矛盾:绝大多数 AI 应用仍停留在 demo 阶段,很难在企业级生产环境中大规模落地。最终能形成一个线上服务产品的更是少之又少。
在总结了内部和外部的 Agent 落地经验之后,我们发现在 demo 和生产阶段,大家对 AI 应用的要求会有一个非线性的提高。对于一个 demo 应用来说,我们可能只需要基本功能达到 80 分,把这个应用搓出来,最快地看到效果就够了。但要把这个应用部署到生产,则要额外考虑的事情就非常多了:开发效率、业务能力、部署便捷性、问题诊断能力、成本控制、生成质量、安全合规等方面,都是 AI 应用落地前面的一道道“门槛”。

好在现在有一些相对成熟的方案来跨过这些“门槛”,以较低的成本保证 AI 应用的生产可用。按照场景可以基本分为两大类:
- 开发效率、业务能力、部署能力:这些能力与搭建 AI 应用的技术栈强相关,开发者所采用的语言、框架本身特性直接决定了上述能力的强弱。选择一个相对成熟、开发&运维友好、扩展性好的 AI 应用框架是保证这些能力的重要手段。一些如 AI 网关 [1]、AI Runtime [2]、Agent market [3] 等产品或中间件也能一定程度上提高上述能力。
- 问题诊断、成本控制、生成质量监测、安全合规:这些场景业务上看似发散,但本质上都需要先回答“如何观测 AI 应用运行时状态”的问题。目前 AI 应用的可观测性包括三种主要的实现路径,按照无侵入性由弱到强可以分为:
- 通过手动添加埋点:一般需要在应用中引入 metrics、trace、log 框架,通过在关键调用中显示调用 API 来记录数据。该方式最灵活,但实现起来也最繁琐,需要专门的开发者进行开发和维护。
- 基于框架&基础设施原生的可观测性:不少比较成熟的 AI 框架本身内置了一定的可观测性,如 AgentScope [4]、Dify [5]、Spring AI [6] 等,一些中间件 [7] 和基础设施 [8] 也提供开箱即用的可观测数据透出。该集成方式相对最轻量,但可扩展性最差,且难以打通众多框架与中间件之间的数据关联,使用起来并不方便。
- 基于专门的可观测采集套件:对于那些较容易实现代码增强的语言,如 Java、Python、Golang 等,存在一些像 OpenTelemetry [9] 和 LoongSuite [10] Instrumentation 这样的自动插桩工具(一般也称之为无侵入探针),可以在编译时或运行时对业务代码进行增强,从而自动化地完成一些可观测性数据的采集。这些工具集成时不需要修改代码与依赖,仅需要修改编译或启动命令,就可以启用应用的可观测性。这种集成方式最简单友好,可观测数据也更加标准通用。基于套件提供的扩展机制,也能比较好地与手动埋点扩展兼容,是许多开发团队的第一选择。
AI Coding 与多语言 AI 框架的强势发展,使得目前越来越多的内部和外部开发团队选择使用 Python 以外的语言搭建 AI 应用。本文将围绕 Java + Spring AI (Alibaba) 的 AI 应用为例,介绍框架原生及无侵入探针的集成方式的最佳实践。
Java 开发者的 AI Agent 框架:
Spring AI Alibaba
Cloud Native
Spring AI 的局限与突破
Spring AI 作为 Spring 官方推出的 AI 开发框架,借鉴了 Python 语言中炙手可热(至少曾是)的 Langchain 与 LlamaIndex 的实现,通过封装大模型调用、向量数据库、工具调用等基础能力,帮助开发者用几行代码即可构建智能体原型。例如,以下代码可快速实现一个带工具调用的对话 Agent:
public Flux<String> streamChat(String chatId, String userMessageContent) {
return this.chatClient.prompt()
.system("你是一个提供预定服务的chatbot")
.user(userMessageContent)
.toolNames("getBookingDetails")
.stream()
.content();
}
然而,当业务场景涉及多 Agent 协同、复杂工作流时,Spring AI 的单体化设计显现出明显短板:
- 缺乏工作流编排能力:难以实现 Agent 间的任务流转与状态管理;
- 生态集成有限:未提供企业级所需的 RAG、模型评估等开箱功能。
Spring AI Alibaba 的增强能力
作为对 Spring AI 的企业级增强方案,Spring AI Alibaba 通过三大核心特性解决了上述问题:
- Graph 框架:基于有向无环图实现多 Agent 协同编排,支持条件分支、并行执行等复杂逻辑;
- DSL 转换器:兼容 Dify 等低代码平台的 DSL 配置,实现“低代码设计-高代码部署”的无缝衔接;
- 阿里云生态集成:内置 RAG、百炼平台对接、可观测性等企业级能力,加速智能体工业化落地。
以多 Agent 协同场景为例,开发者可通过 Spring AI Alibaba 多 Agent 框架定义如下工作流,并快速完成 Agent 编排:
// 定义 Agent 1
ReactAgent writerAgent = ReactAgent.builder()
.name("writer_agent")
.model(chatModel)
.description("可以写文章。")
.instruction("你是一个知名的作家,擅长写作和创作。请根据用户的提问进行回答。")
.outputKey("article")
.build();
// 定义 Agent 2
ReactAgent reviewerAgent = ReactAgent.builder()
.name("reviewer_agent")
.model(chatModel)
.description("可以对文章进行评论和修改。")
.instruction("你是一个知名的评论家,擅长对文章进行评论和修改。对于散文类文章,请确保文章中必须包含对于西湖风景的描述。")
.outputKey("reviewed_article")
.build();
// 定义顺序的 AgentFlow
SequentialAgent blogAgent = SequentialAgent.builder()
.name("blog_agent")
.state(stateFactory)
.description("可以根据用户给定的主题写一篇文章,然后将文章交给评论员进行评论,必要时做出修改。")
.inputKey("input")
.outputKey("topic")
.subAgents(List.of(writerAgent,reviewerAgent))
.build();
Optional<OverAllState> result = blogAgent.invoke(Map.of("input", "帮我写-个I00字左右的散文");
受限于篇幅,本篇不对框架本身过多介绍,更多 Spring AI Alibaba 框架的最佳实践请移步:Spring AI Alibaba 官方网站[11]。
可观测性集成:框架原生方式
Cloud Native
基本原理
Spring AI Alibaba 的可观测性体系基本基于 OpenTelemetry(OTel)标准构建,通过分层架构实现数据采集、处理与上报的全链路覆盖:
- 埋点层:框架内部通过 Micrometer(Spring 官方推荐的可观测中间件)对关键调用(如模型推理、工具调用、外部调用)自动埋点;
- 数据导出层:Micrometer 在运行时提供可插拔的 Tracer 实现,支持将埋点层产生的数据使用 OpenTelemetry SDK 导出为满足 OTLP 协议的格式;
- 存储层:兼容任何支持 OTLP 协议格式的可观测存储,如 Prometheus、Langfuse、Jaeger 等;
- 扩展层:Spring AI Alibaba 基于 Spring AI 原生实现提供了一些可观测性扩展 [12],支持如输入输出采集、提示词版本关联采集等更多 Spring AI 暂不支持的数据格式与语义。
接入实践
STEP 1:准备 Agent 应用
Spring AI Alibaba 示例项目中提供了非常多类型的实例项目,本次实践采用的机票预定助手项目可以在该链接找到:https://github.com/spring-ai-alibaba/examples/tree/main/spring-ai-alibaba-agent-example/playground-flight-booking [13]。
STEP 2:引入相关依赖
<!-- 用于实现各种 OTel 相关组件,如 Tracer、Exporter 的自动装载 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- 用于将 micrometer 产生的指标数据对接到 otlp 格式 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-otlp</artifactId>
</dependency>
<!-- 用于将 micrometer 底层的链路追踪 tracer 替换为 OTel tracer -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-otel</artifactId>
</dependency>
<!-- 用于将 OTel tracer 产生的 span 按照 otlp 协议进行上报 -->
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-otlp</artifactId>
</dependency>
<!-- 引入 ARMS 可观测性扩展 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-autoconfigure-arms-observation</artifactId>
</dependency>
以上依赖彼此之间的关系如下图所示,实线为直接依赖,虚线为间接依赖:
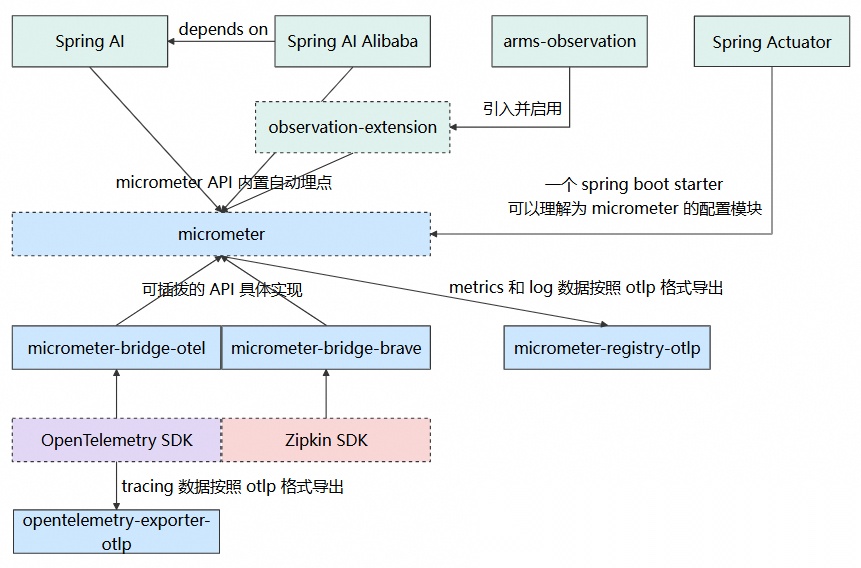
STEP 3:修改 application.properties 相关配置,启用可观测性
# arms 扩展相关配置
spring.ai.alibaba.arms.enabled=true
spring.ai.alibaba.arms.tool.enabled=true
spring.ai.alibaba.arms.model.capture-input=true
spring.ai.alibaba.arms.model.capture-output=true
# otel 扩展相关配置
management.otlp.tracing.export.enabled=true
management.tracing.sampling.probability=1.0
management.otlp.tracing.endpoint={YOUR_TRACE_ENDPOINT}
management.otlp.metrics.export.enabled=true
management.otlp.metrics.export.url={YOUR_METRICS_ENDPOINT}
management.otlp.logging.export.enabled=false
management.opentelemetry.resource-attributes.service.name={YOUR_SERVICE_NAME}
management.opentelemetry.resource-attributes.service.version=1.0
management.opentelemetry.resource-attributes.deployment.environment=test
要获取数据上报端点,你可以参考文档通过OpenTelemetry上报Java应用数据[14] 将数据上报到阿里云,你也可以将其替换为任何一个其他支持 OTLP 上报协议的上报端点,如 Spring AI Alibaba Admin [15]。
STEP 4:启动应用
启动命令为:java -jar spring-ai-demo.jar。
STEP 5:登录阿里云应用监控 OpenTelemetry 版,查看可观测数据
访问应用后,能够查看到大模型的部分调用链路。通过 span 名称可以看到过程中发生了两次大模型调用(chat qwen-max),中间还调用了一次工具(execute_tool get-booking-details),在每个 span 中都可以看到对应的上下文信息,如模型输入输出、消耗 token 数、调用的工具名与入参等等。
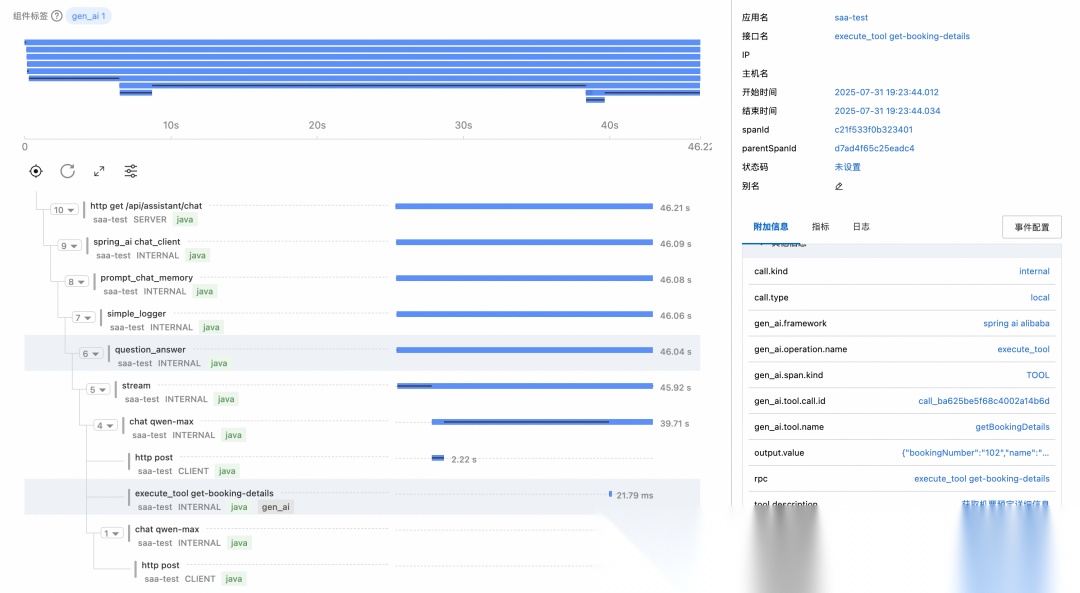
注:由于 Spring AI 目前提供的指标与 OpenTelemetry 命名规范不一致,目前仅支持查看 tracing 数据。
可观测性集成:无侵入探针方式
Cloud Native
框架原生可观测性的痛点
在前言中我们提到,框架原生的可观测性虽然带来了简便的接入体验,但往往存在各种局限性,主要包括以下几个方面:
- 扩展性差:Spring AI 的内置埋点与框架代码是耦合在一起的,如果我们希望为某些 span 添加一些额外的 attributes,或者把部分 attributes 采用日志的形式打印,实现受制于框架埋点实现。一旦框架本身并没有采集某些上下文,实现期望的扩展就会非常困难,往往需要向 Spring AI 仓库提交 PR。
- 端到端实现困难:库原生的可观测实现与无侵入探针方案适配性较差(相关讨论可以参见What are the Best Practices for Providing Instrumentation for Spring AI. [16])。一旦选用了库原生的方案,又在 Agent 中需要发起消息队列/中间件/RPC 等调用时,就必须选择 Spring 原生支持的调用类型,或者基于 Micrometer 机制手动添加埋点透传上下文,否则就会导致调用链断链,影响问题定位和排查。
- 灵活度低:Spring AI 的可观测性大量使用了 Spring Boot 的 Auto Configuration 机制,对手动管理的 Spring Bean 适配性较差。
- 运维复杂:接入需要引入大量不同发行商的依赖,这些依赖之间可能存在诸多版本限制,不利于项目依赖的升级和维护。
为了应对这些问题,进一步简化接入步骤,LoongSuite 商业版自 4.6.0 版本起面向 Spring AI (Alibaba) 提供了无侵入探针的解决方案。
LoongSuite 简介
LoongSuite 是阿里云可观测团队维护的一个可观测性开源品牌,统一管理多个数据采集产品。它包含 LoongCollector,用于主机级别的数据采集,支持日志、Prometheus 指标及 eBPF 网络与安全数据。同时,LoongSuite 提供多种语言的进程探针,如 Python、Go 和 Java 探针,用于无侵入式地采集 AI 应用的运行数据。这些探针可以捕获模型输入输出、工具调用情况及耗时等信息。LoongCollector 负责数据的统一处理与上报,支持 OTLP 协议,可对接开源系统如 Jaeger、Elasticsearch,也可连接云厂商的托管服务。此外,LoongSuite 与 OpenTelemetry 社区紧密合作,其 Python 探针基于社区版本扩展 AI 插件,Go Agent 源自阿里云贡献项目,并参与推动 Go 插桩技术发展及 GenAI 语义规范的制定。[17]
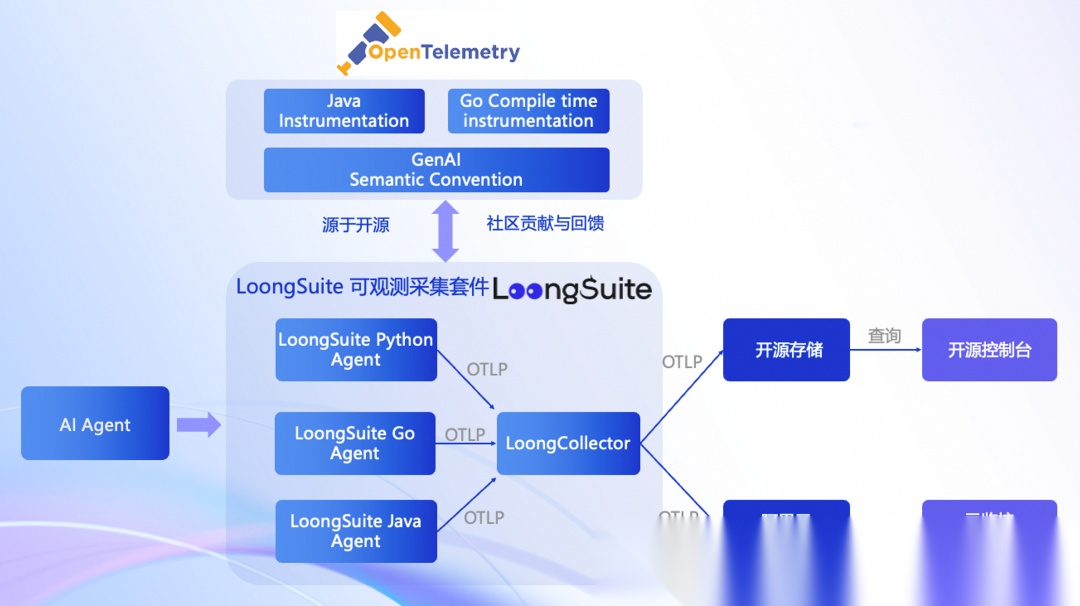
技术原理
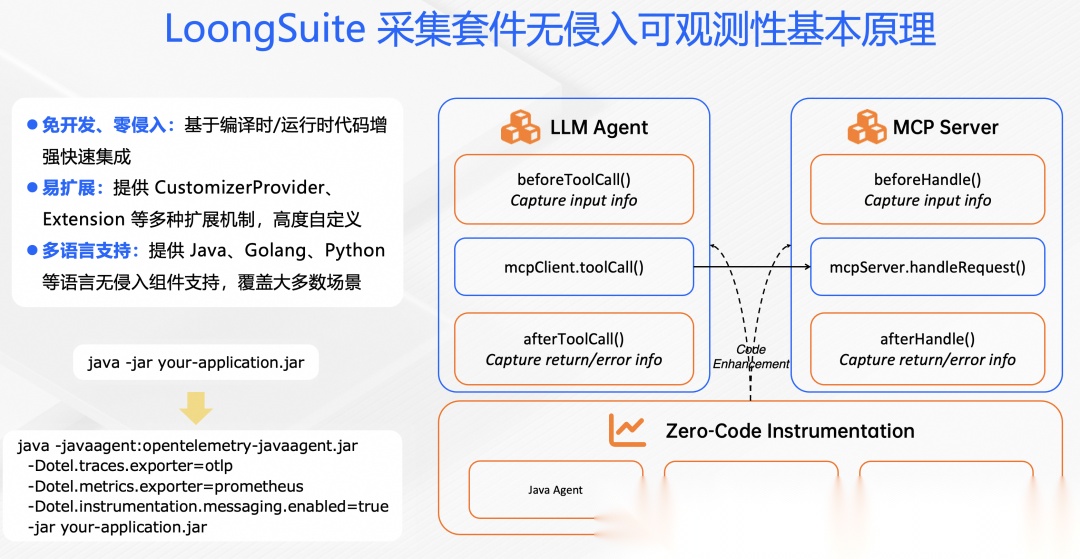
LoongSuite 多语言探针通过 Java、Golang、Python 等语言提供的代码增强机制,在探针包中预定义好一系列的代码增强逻辑。通过修改编译或者启动命令,探针包中的代码增强逻辑会生效于目标框架的关键方法中,在方法执行前后分别执行预定义好的一些步骤,如创建/关闭 span、记录 metrics、传递上下文、捕获异常等。使用者不需要修改业务代码,就可以直接集成可观测性。
相比框架原生方案,该实现有诸多优势:

接入实践
STEP 1:准备 Agent 应用
同上一章 STEP 1,项目地址:https://github.com/spring-ai-alibaba/examples/tree/main/spring-ai-alibaba-agent-example/playground-flight-booking。
STEP 2:下载探针
目前仅 LoongSuite 商业版 4.6.0 版本支持 Spring AI (Alibaba) 的无侵入接入,该版本尚未完全发布,您可以通过以下链接获取探针并解压:http://arms-apm-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/4.6.0/AliyunJavaAgent.zip。
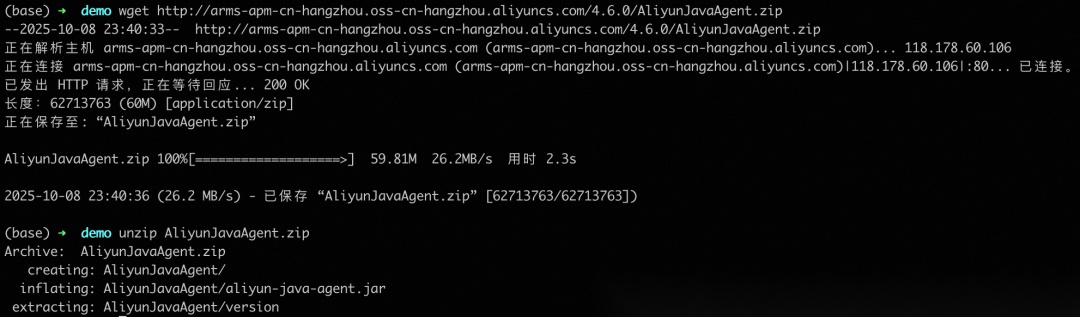
STEP 3:修改启动命令,启动应用
您可以进入云监控 2.0 控制台**[****1]**,选择一个工作空间后,按照接入中心 > 应用监控&链路追踪 > 手动安装 > 自研 Java Agent(通用环境手动接入)中的步骤来接入您的应用。
原启动命令为:
java -jar spring-ai-demo.jar
修改后启动命令为:
java \
-javaagent:{PATH_TO_JAVA_AGENT} \
-Dprofiler.jdk21.async.context.propagation.enable=true \
-Darms.licenseKey={YOUR_LICENSE_KEY} \
-Darms.appName={YOUR_APP_NAME} \
-Darms.workspace={YOUR_WORKSPACE}
-Daliyun.javaagent.regionId={YOUR_REGION} \
-jar spring-ai-demo.jar
注:
- 请把 {PATH_TO_JAVA_AGENT} 替换为 STEP 2 中解压后的探针地址绝对路径
- 如果您使用的是 JDK 21 及以上版本,且未开启虚拟线程,可以使用
-Dprofiler.jdk21.async.context.propagation.enable=true来保证异步上下文自动透传;如若开启虚拟线程,则需谨慎使用,详情参见:探针(Java Agent)版本说明**[**2] - 请把 {YOUR_LICENSE_KEY} 替换为您的 license key,把 {YOUR_WORKSPACE} 替换为您的工作空间名,您可以在 云监控 2.0 控制台选择您的工作空间,并单击接入中心获取您的 license key
- 请把 {YOUR_APP_NAME} 替换为您的应用名,把 {YOUR_REGION} 替换为您需要上报到的地域
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献516条内容
已为社区贡献516条内容

所有评论(0)