AI自动化测试框架browser use 项目测试总结
BrowserUse是一个基于Python的开源库,深度整合AI技术与浏览器自动化功能,支持通过大型语言模型(如GPT-4、Claude)实现网页自动化操作。测试比较显示,GPT-4o执行效果最佳但成本高,而国产模型如Qwen2.5-32B和阿里云qwen系列表现尚可。当前存在cookie频繁获取、验证码处理、GIF保存优化等问题需二次开发解决,同时需完善元素定位和提示词优化。该库使用Playwr
01 browser use简介
Browser Use 是一个基于 Python 开发的开源库,它将先进的 AI 技术与浏览器自动化功能深度融合。通过集成Playwright等浏览器自动化工具,Browser Use允许开发者使用任何支持LangChain的大型语言模型(如GPT-4、Claude等)来自动化浏览网页、提取信息、模拟用户操作等。
-
playwright
Playwright 是一个由微软开发的现代化 端到端(E2E)测试工具,专门用于自动化 Web 浏览器操作。它支持 Chromium(Chrome、Edge)、Firefox 和 WebKit(Safari)三大浏览器引擎,且适用于跨平台(Windows、macOS、Linux)。
-
LangChain
LangChain 是一个用于构建大语言模型(LLM)应用的开发框架,它通过模块化设计简化了 LLM 应用的开发流程,支持开发者快速搭建基于语言模型的复杂应用(如聊天机器人、知识库问答、自动化工作流等)。其核心思想是通过“链(Chain)”将不同组件(如模型、数据、工具)灵活组合,实现端到端的功能。
02 测试demo用例1
测试用例提示词
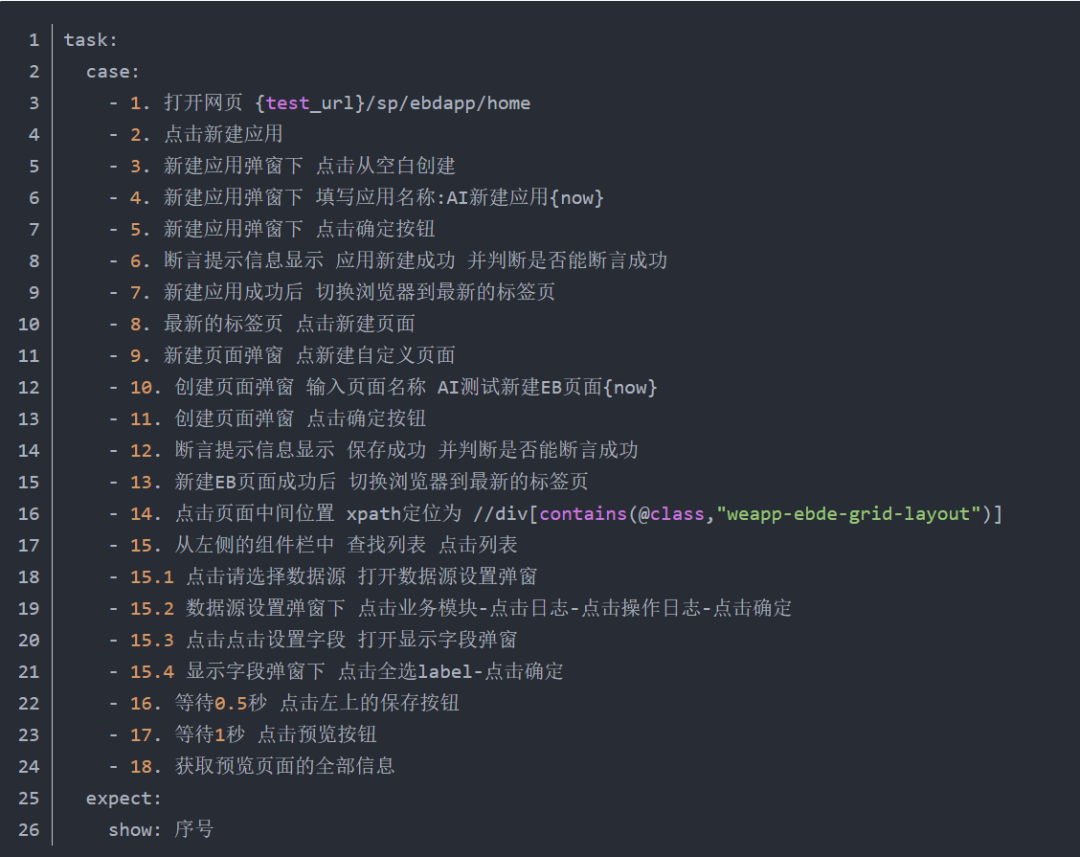
执行过程

03 专项事井然-测试用例demo
测试用例提示词:
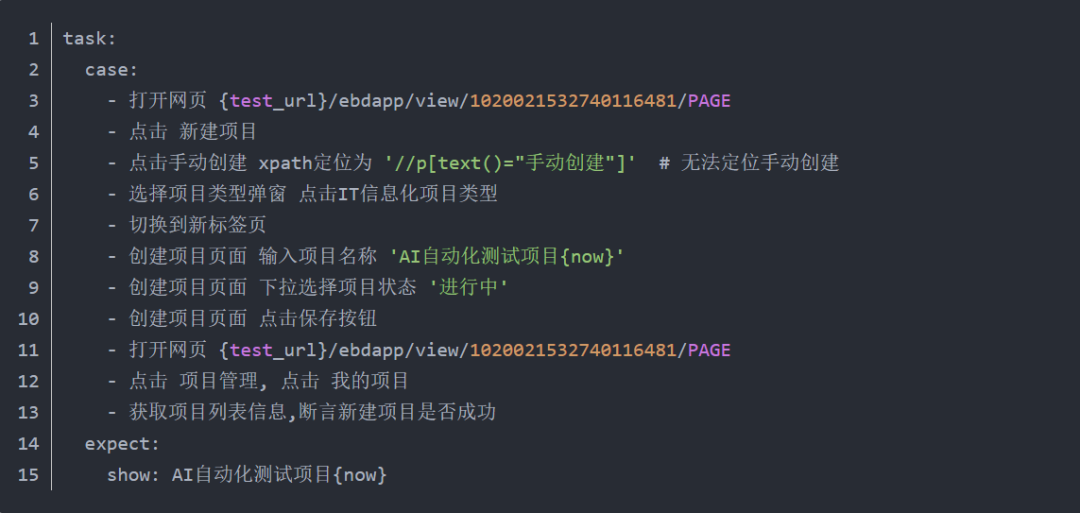
执行过程

04 专项九氚汇-测试用例demo2-提交流程
测试用例提示词:
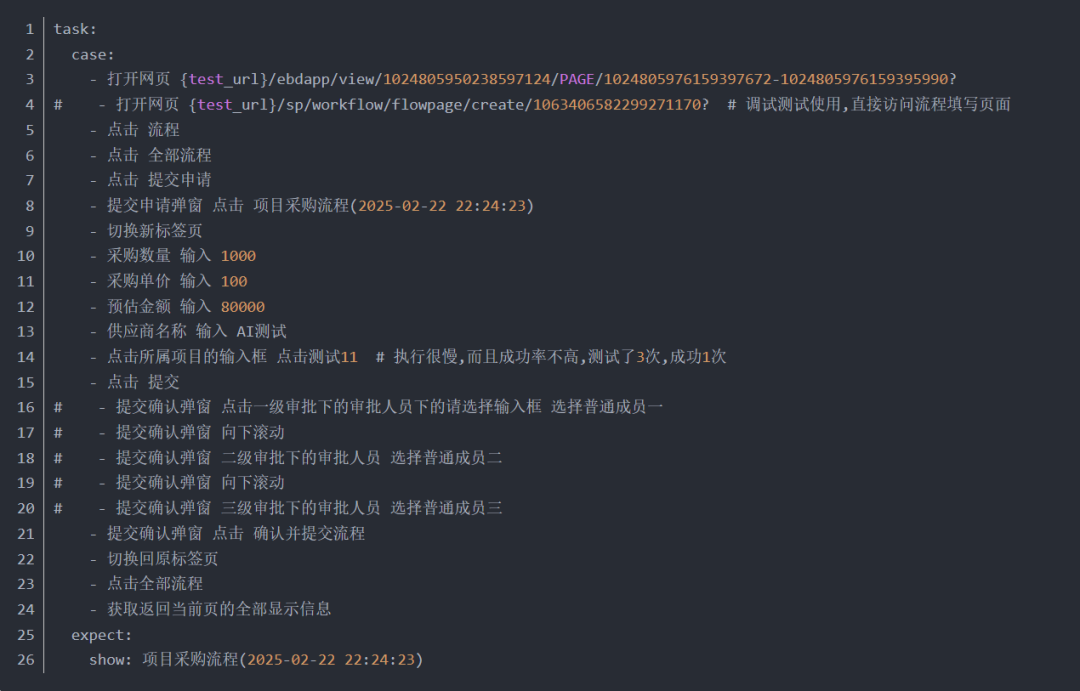
执行过程

05 多家大语言的执行速度和执行效果测试
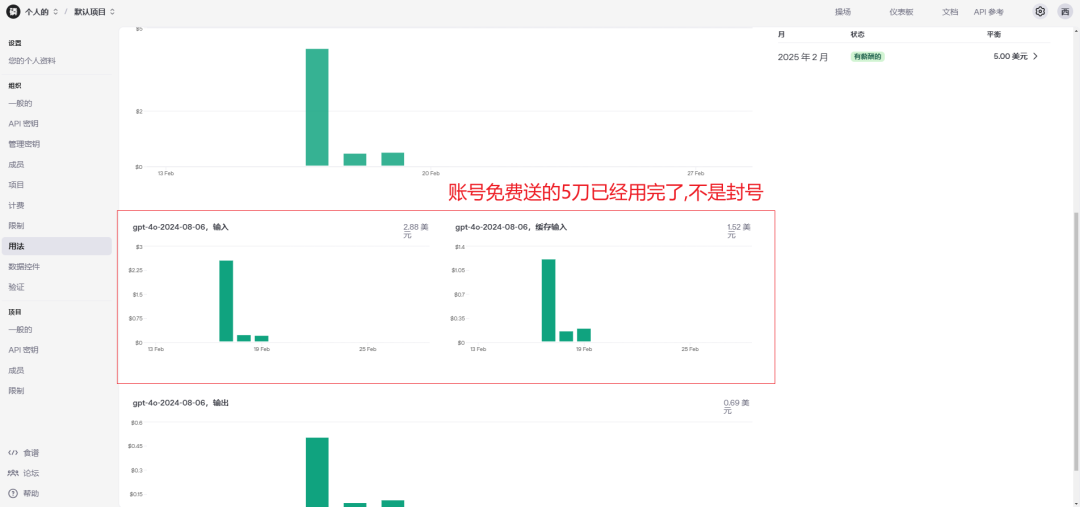
1.gpt-4o
-
优点: 效果最好的, 速度快, 操作的准确率也较高
-
缺点: 需要网络代理,且价格较贵,差不多是deepseekR1费用的7倍,仅测试几天的使用就用完了5美金的赠送费用
-
执行test_task用例: 45秒
2.deepseek官方接口
-
优点: 聪明
-
缺点1: deepseek官方接口目前很不稳定,经常无法调用.或者第一次调用成功,第二次就失败.
-
缺点2: 太慢了,作为推理模型,即使是很简单的问题,也会推理思考很久,就像是一个知识渊博,但回答慢的让人着急的老教授,不适合作用于我们这种测试场景
3.公司本地部署的deepseek-R1-14B
-
优点: 成本低,无需网络代理, 本地部署不存在数据泄露风险
-
缺点: 速度慢,执行时间是gpt-4o的2-3倍,而且操作成功率也更低
4.硅基流动的大模型接口
model="deepseek-ai/DeepSeek-V3", # 慢,不够聪明
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B", # 聪明,但是太慢了,作为推理模型,即使是很简单的问题,也会推理思考很久.就像是一个知识渊博,但回答慢的让人着急的老教授,不适合作用于我们这种测试场景
model="Qwen/Qwen2.5-14B-Instruct", # 相对上面两个deepseek的更快, 执行test_task用例:40秒-62
model="Qwen/Qwen2.5-32B-Instruct", # 比14B相对更聪明,执行时间也没有多多少, 执行test_task用例: 55秒
model="Qwen/Qwen2.5-7B-Instruct", # 执行test_task用例:太笨了, 直接执行失败了
model="01-ai/Yi-1.5-9B-Chat-16K", # 模型不支持
model="THUDM/glm-4-9b-chat", # 智谱AI: 不够聪明,返回数据的格式都不符合要求
model="Pro/THUDM/glm-4-9b-chat", # 智谱AI: 不够聪明,执行失败
model="meta-llama/Meta-Llama-3.1-8B-Instruct", # 不够聪明,执行失败
model="meta-llama/Meta-Llama-3.1-70B-Instruct", # 不够聪明,执行失败
model="meta-llama/Llama-3.3-70B-Instruct", # 执行到最后直接卡死了,不操作也不报错停止
5.阿里云百炼大模型接口
model="qwen-max", # 执行效果还行
model="qwen-plus", # 执行登录用例: 3分钟
model="qwen-turbo", # 执行登录用例: 2分钟,有点笨,执行一直循环
6.字节火山大模型-豆包
model="ep-20250220153306-tswkf", # Doubao-1.5-lite-32k,执行结果数据不符合要求,无法使用
model="ep-20250220154403-wfw29", # Doubao-1.5-pro-32k,执行结果数据不符合要求,无法使用
7.大模型试用总结
效果最好的是gpt4o,但是价格太贵,且使用麻烦,需要网络代理.国产的大模型又没有那个能做到高效执行且精准操作的.
目前体验勉强能用的两个:
硅基流动的Qwen/Qwen2.5-32B-Instruct
阿里云百联的qwen-max和qwen-plus
06 可能需要通过二开解决的问题
1.需二开解决的问题
执行过程中每个步骤都会频繁的获取和保存cookie,这个需要二开修改限制获取cookie的次数
目前获取cookie的方法是通过登录用例获取,但无法处理验证码,后续需要追加接口登录获取cookie
目前默认执行保存全部操作的GIF动图,用例多了之后文件大小或很大,需要二开修改会仅保存断言截图,或仅保存失败用例的GIF动图(已修改)
部分目前不支持的操作
用例执行过程中断言截图
键盘事件如回车搜索
需要在controller中自定义新增符合我们需求的action,但源码较复杂,二开的难度较大(已新增鼠标悬停方法)
部分元素无法定位的问题, 可能也需要通过二开修改DOM数据解析方法实现,但这个的二开难度更大,需要熟悉前端的同事协助评估
执行报告GIF中的步骤说明,中文乱码,需要处理(修改了源码中使用的字体解决了GIF中文乱码)
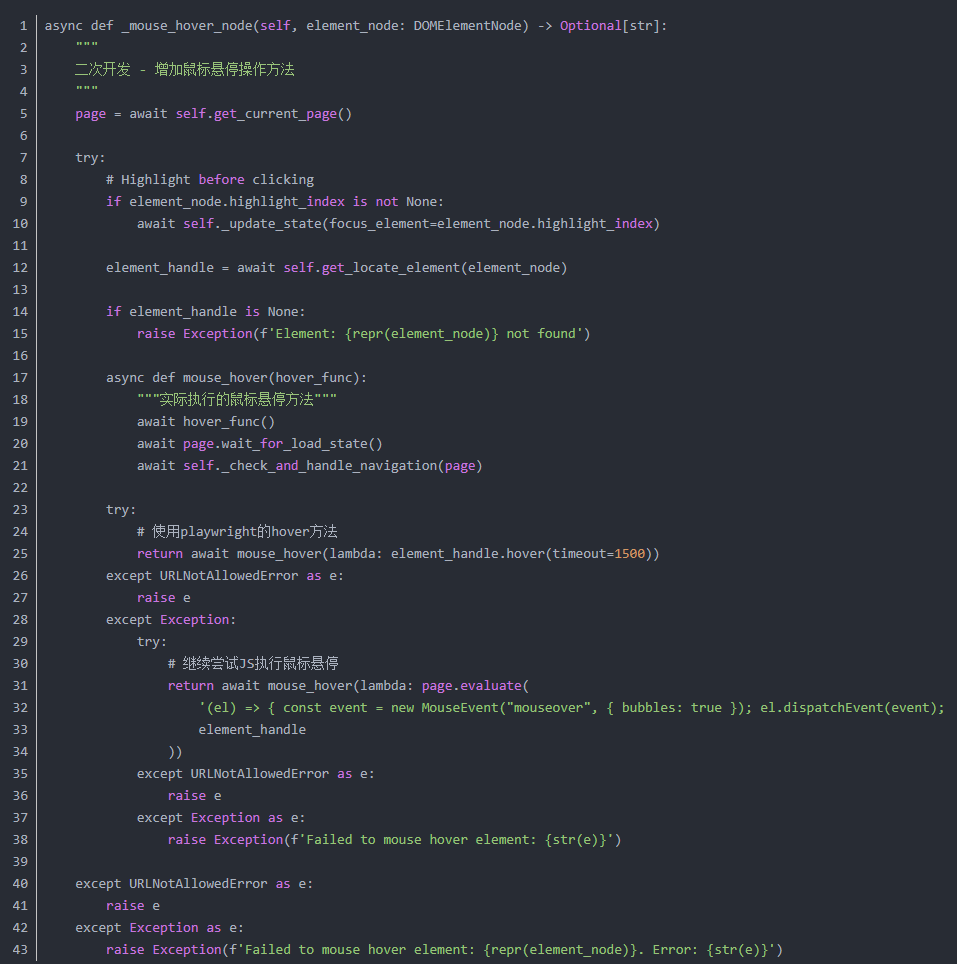
2.鼠标悬停方法(二开新增)
controller下的servise.py
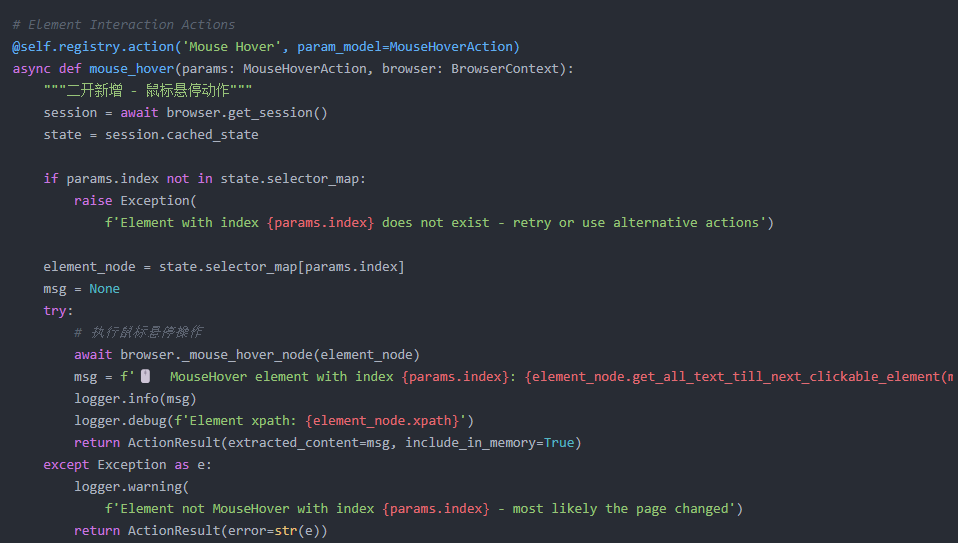
controller下的views.py

browser下的context.py
07 提示词总结
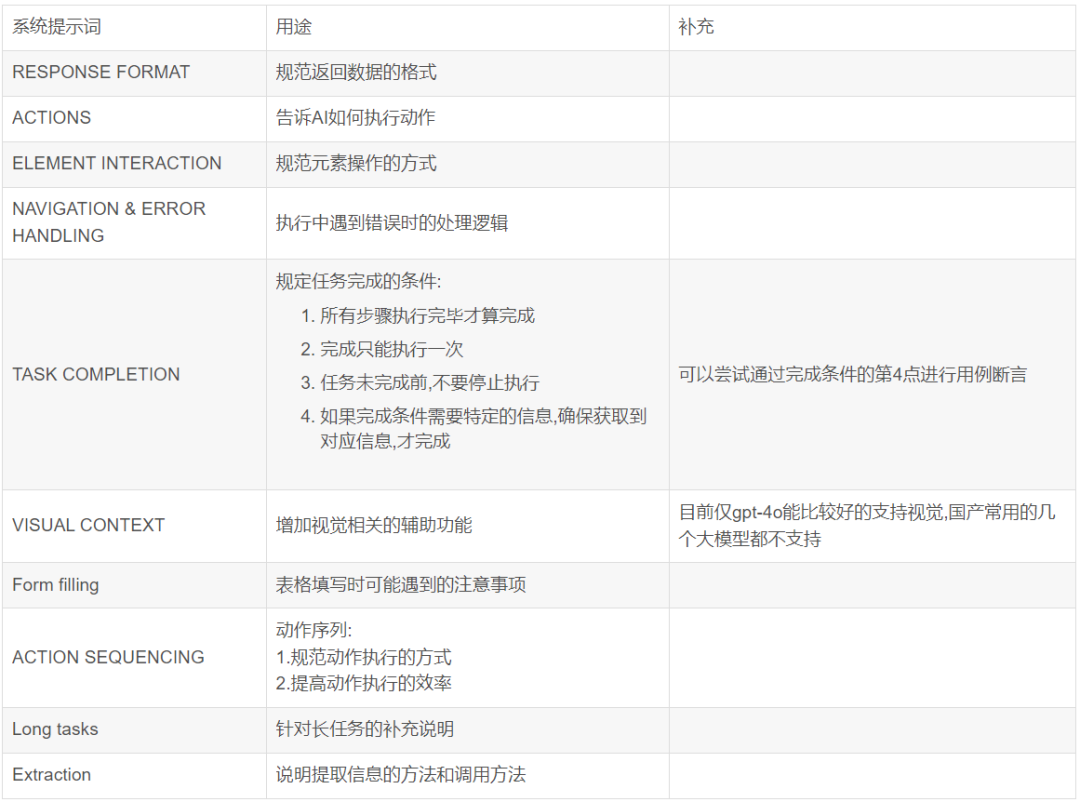
1.系统提示词
class SystemPrompt: 提示词类中定义了核心的系统提示词,给AI设定了身份,告知了AI需要做什么,以什么格式返回数据,包含那些
-
重要规则
-
输入格式input_format
规范AI转换用户输入的文本为可操作的语句给到框架的格式.需要包含URL,可用标签页,可操作元素.
-
获取系统信息get_system_message
规范获取信息的方式和方法
-
用户自定义补充系统提示词
继承系统提示词类,添加额外的系统提示词,但目前测试的效果比较一般,部分提示词不生效,比如捕获页面错误

2.动作提示词
以下为框架内目前支持的动作,其它的动作可能需要二开补充,或通过优化提示词实现操作
目前不支持或操作困难的组件: 人员选择框, 浏览选择框, 日期时间选择框, 符号操作按钮
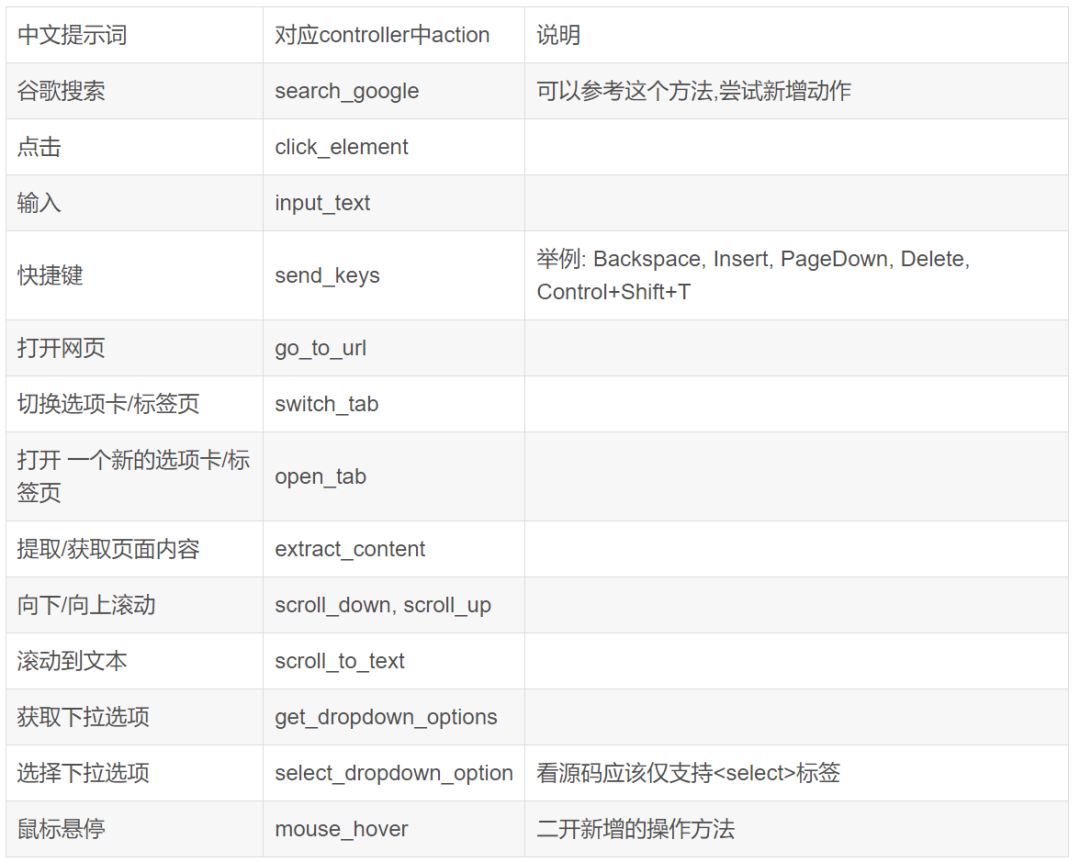
其它自己总结的提示词
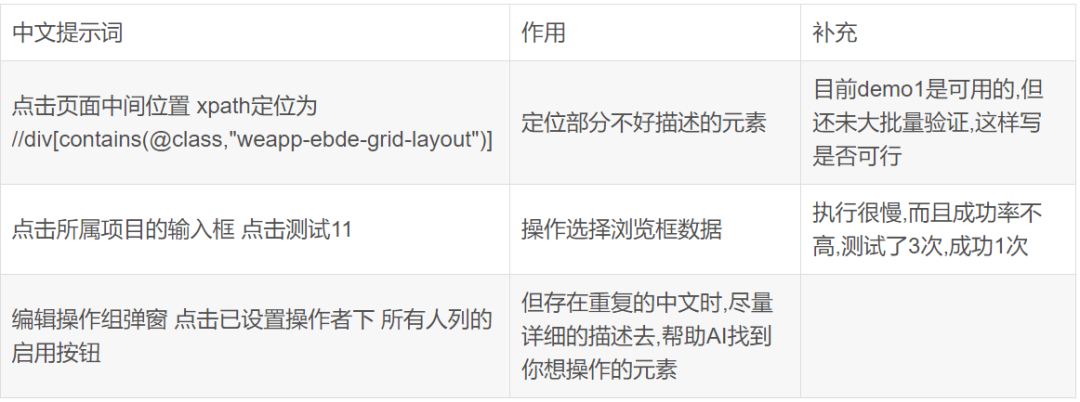
08 browser use中使用的第三方库总结
Pydantic
用在views.py中,用于数据验证和设置管理。通过定义数据模型,确保AI按照提示词生成的输入数据的类型,和结构是否正确。
-
数据验证:自动验证输入数据是否符合类型和规则。
-
数据转换:将原始数据转换为符合模型的 Python 对象。
-
序列化与反序列化:支持将模型转换为字典或 JSON。
-
IDE 友好:利用类型提示提供自动补全和错误提示。
最后作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些软件测试的学习资源,希望能给你前进的路上带来帮助。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)