大模型transformer架构训练和推理方法
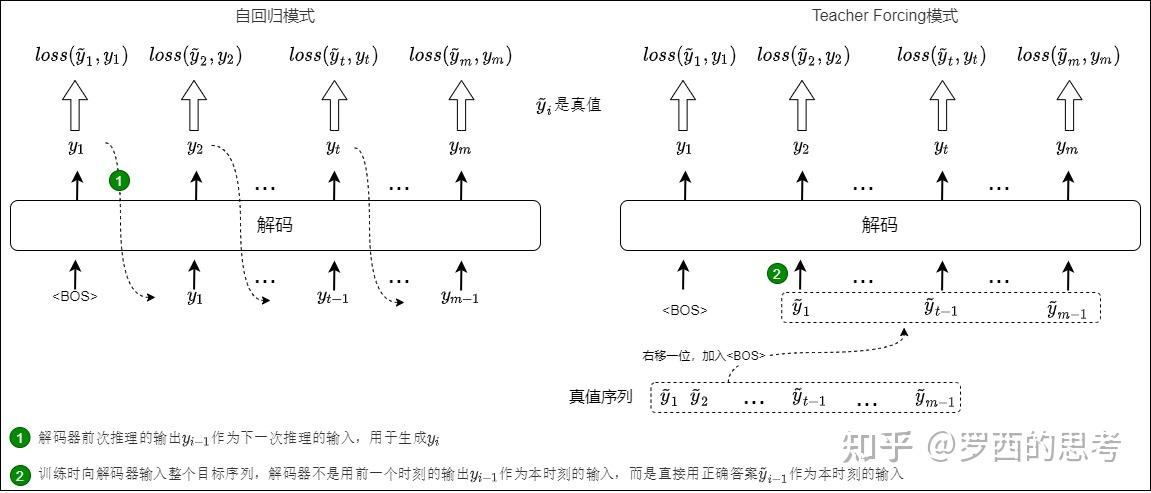
因为训练可以“靠老师”,推理还得“靠自己”,这样推理时遇到的错误输出对于下次推理来说就是在训练数据分布之外(out of distribution)的异常输入,所以会导致用Teacher Forcing模式训练出来的模型在训练环节和预测环节存在行为差异。具体来说,Teacher Forcing就是每次推理给解码器输入时,不使用前次推理的输出作为下一次推理的增加输入,而是使用训练标签的真值(grou
transformer架构训练和推理的主要区别是,推理是自回归模式,需要串行进行运算;训练主要是teacher forcing模式,可以通过真实答案,进行并行计算。
1. 为什么训练开始要用teacher foring模式?
(1)自回归方式容易累积错误,导致训练效果不佳。在训练时,我们可以使用与推理时相同的方法,即用自回归模式进行。然而这样整个模式就是串行化过程,如果编码器在某一轮预测错了,那么这个错误的输出就会作为下一轮解码器的输入,这样基于错误输入继续解码就是在错误道路上越走越远,这将导致模型向全局最优收敛的速度减慢。
(2)自回归只能串行进行。
我们用下面表格来看看上面两个问题。首先,对于所提供的输入,模型必须经过5个时间步才能完成推理,因为Decoder每一次只会预测一个单词。但是,按照上述流程进行训练会过于缓慢,我们应采用并行(矩阵计算)的方式去训练。其次,推理步骤中会出现错误,而且容易在错误道路上越走越远。
| 时间步 | 解码器输入1 | 解码器输入2 | 解码器输出 | 真值 | 说明 |
|---|---|---|---|---|---|
| 1 | "我吃了一个苹果"编码后的隐向量 | I | I | 预测正确 | |
| 2 | I | "我吃了一个苹果"编码后的隐向量 | like | ate | 预测错误 |
| 3 | I like | "我吃了一个苹果"编码后的隐向量 | play | an | 预测错误 |
| 4 | I like play | "我吃了一个苹果"编码后的隐向量 | football | apple | 预测错误 |
| 5 | I like play football | "我吃了一个苹果"编码后的隐向量 | 预测正确,但是没啥用处 |
2. teacher foring模式介绍
具体来说,Teacher Forcing就是每次推理给解码器输入时,不使用前次推理的输出作为下一次推理的增加输入,而是使用训练标签的真值(ground truth)作为下一次推理的增加输入。Teacher Forcing机制保证了 Transformer 在训练阶段可以并行地输出所有的词,而不需要循环,这大大加快了训练速度。这种模式具体如下图所示,图中简化了输入,实际上解码器的输入是一个拼接,而非单纯输入某个标签。
teacher foring模式操作时,对真值要使用mask掩盖。
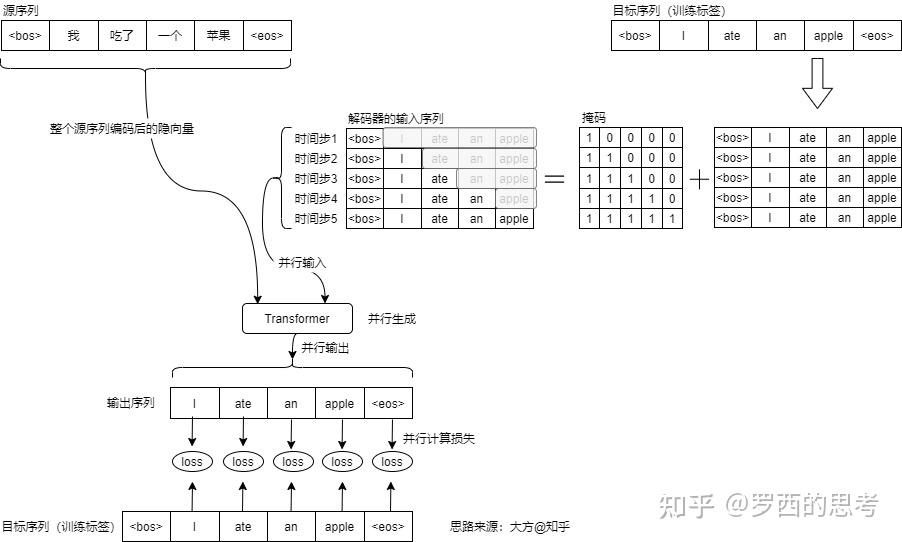
Teacher Forcing的优势是因为模型是在“正确答案”指引下进行预测,训练的稳定性得到大大增强,收敛速度也得以大幅提升。而且我们可以一次性的输入全部目标序列,然后以并行的方式一次性的输出完整的目标序列,训练效率大幅提升。
但是Teacher Forcing也存在一定的问题。因为训练可以“靠老师”,推理还得“靠自己”,这样推理时遇到的错误输出对于下次推理来说就是在训练数据分布之外(out of distribution)的异常输入,所以会导致用Teacher Forcing模式训练出来的模型在训练环节和预测环节存在行为差异。这种因为训练和推理之间数据分布存在差异,导致模型在部署中表现变差的现象叫做exposure bias(曝光误差)。另外,因为模型生成的结果都必须和参考句一一对应。这种约束在训练过程中减少模型发散,加快收敛速度。但是一方面也扼杀了翻译多样性的可能。
因此研究人员也针对exposure bias做了一些改进工作。比如其中一个变种是Curriculum Learning,它的思路是:既然自回归模式的全靠自身预测结果和Teacher Forcing模式的全靠真值均不可取,那么就不如折中方案,进行有计划的学习。在训练过程的每一步会以一定的概率随机选择是用模型输出还是用真值。上述选择概率是随着训练的推进不断调整的:训练过程会从Teacher Forcing开始,慢慢降低在训练阶段输入真值的频率。即一开始学生是小白,只能老师带着学,后续随着学生的进步,老师慢慢放手让学生自主学。
3. 训练中loss的计算
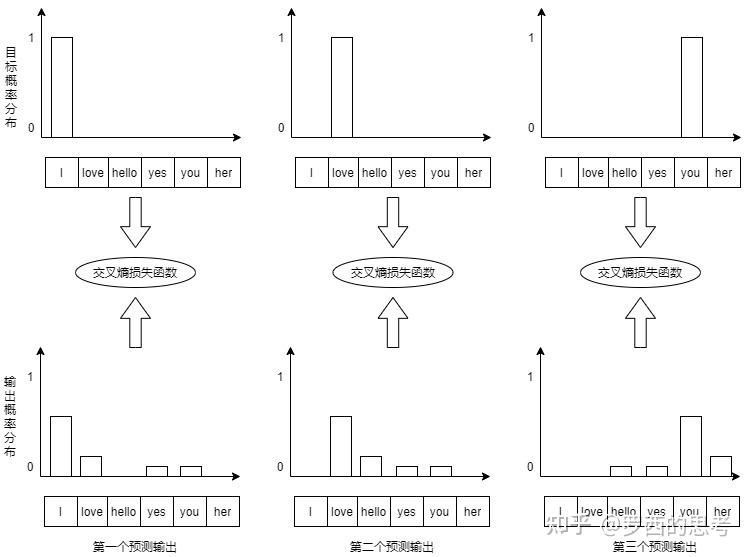
使用交叉熵损失函数来比较模型的预测的概率分布(logits)和真实分布(targets)之间的差异。然后对损失计算梯度,用反向传播算法来略微调整所有模型的权重,以便接下来生成更接近结果的输出。
我们用下图来进行分析。假设词表包含6个单词,我们希望得到与预期的目标序列 "I love you"相符的概率分布。图中上方是目标概率分布。第一个输出词的概率分布中,“I”的概率应该是1,而词表中其它词的概率都应该是0。类似的,第二个和第三个输出词的概率分布中,“love”和"you"的概率都应该是1,词表中其它词的概率都应该是0。图下方则是模型对应预测输出的概率分布。损失函数就是要计算两者之间的差异。
计算损失函数的代码如下,传入的参数criterion是损失函数。该类除了包含损失计算外,还包含模型generator部分的前向传播逻辑。下面代码有个正则化的细节,这是为了平滑。假设有两个batch,第一个batch有6个字,则loss是这6个预测结果计算损失的和。第二个batch有60个字,则loss是这60个预测结果计算损失的和。显然第二个损失大,这不符合逻辑。所以我们用除以有效token数目来进行平均。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)