Elasticsearch:使用推理端点及语义搜索演示
本文介绍了如何在Elasticsearch中使用推理端点进行语义搜索。主要内容包括:1)安装Elastic Stack 9.1.4版本;2)部署ELSER(稀疏向量)和E5(密集向量)模型;3)创建和管理推理端点;4)演示语义搜索示例,包括多语言搜索;5)介绍混合搜索方法,结合词汇搜索提高相关性。文章展示了如何利用Elasticsearch的语义搜索功能,通过向量化文本实现更智能的搜索效果,并提供
在今天的文章中,我来详细描述如上在 Elasticsearch 中使用推理端点,并展示进行语义搜索的。更多阅读,请参阅 “Elasticsearch:Semantic text 字段类型”。在本次展示中,我讲使用 Elastic Stack 9.1.4 版本来进行展示。
通过我们的点播网络研讨会提升你的技能:使用 Elasticsearch 的 Agentic RAG,以及 Elasticsearch MCP Server 的 MCP 入门。
安装
Elasticsearch 及 Kibana
如果你还没有安装好你自己的 Elasticsearch 及 Kibana,那么请参考如下的文章来进行安装:
在安装的时候,请参考 Elastic Stack 8.x/9.x 的安装指南来进行。在本次安装中,我将使用 Elastic Stack 9.1.2 来进行展示。
首次安装 Elasticsearch 的时候,我们可以看到如下的画面:
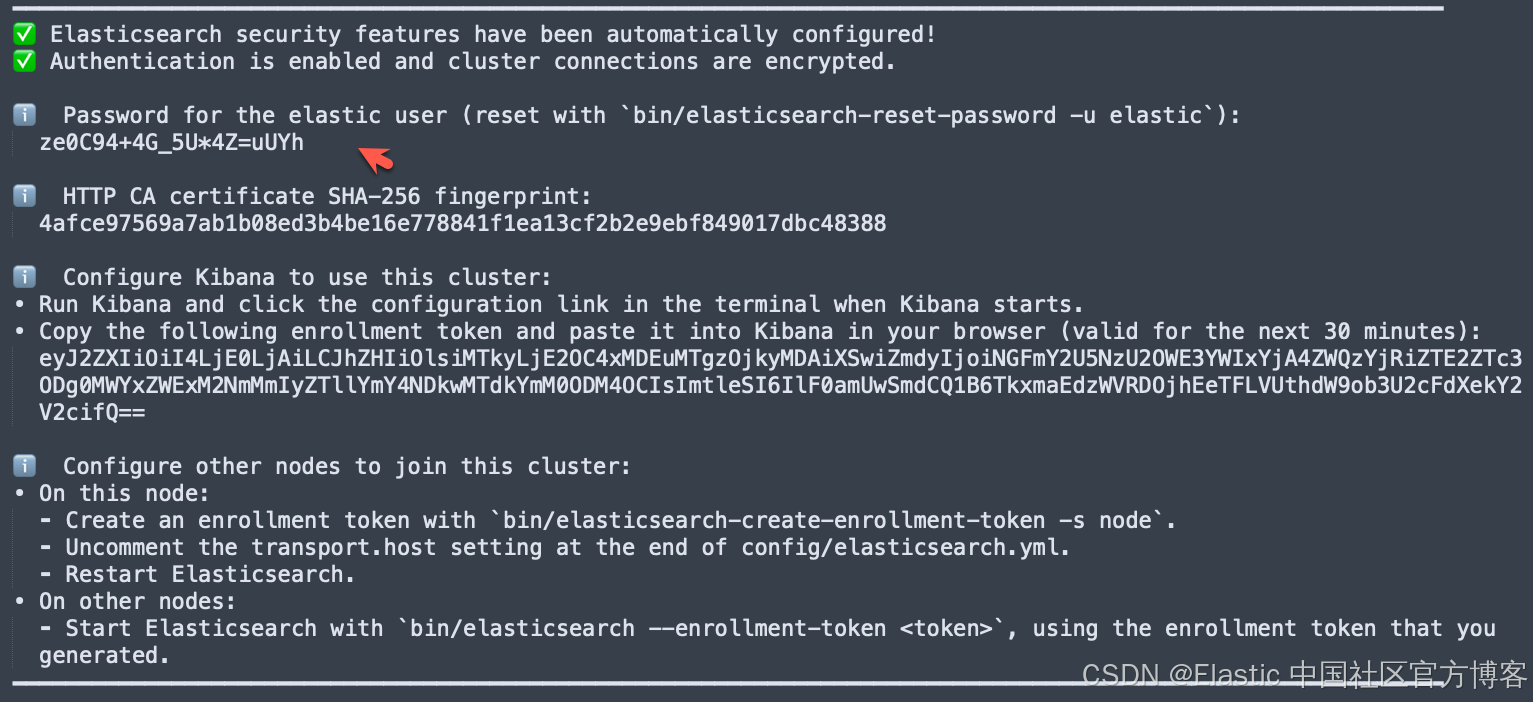
我们按照上面的链接把 Elasticsearch 及 Kibana 安装好。
下周 ELSER 及 E5 模型
在我们如下的练习中,我们将下载 Elastic 自带的模型:ELSER(稀疏向量) 及 E5(密集向量)。由于这两个嵌入模型是安装在 Elasticsearch 的机器学习节点上的,我们需要启动白金试用。特别值得指出的是:如果你不使用 Elasticsearch 机器学习节点来向量化你的语料,那么你不必启动白金试用。你可以在 Python 代码里实现数据的向量化,或者使用第三方的端点来进行向量化,而只把 Elasticsearch 当做一个向量数据库来使用!
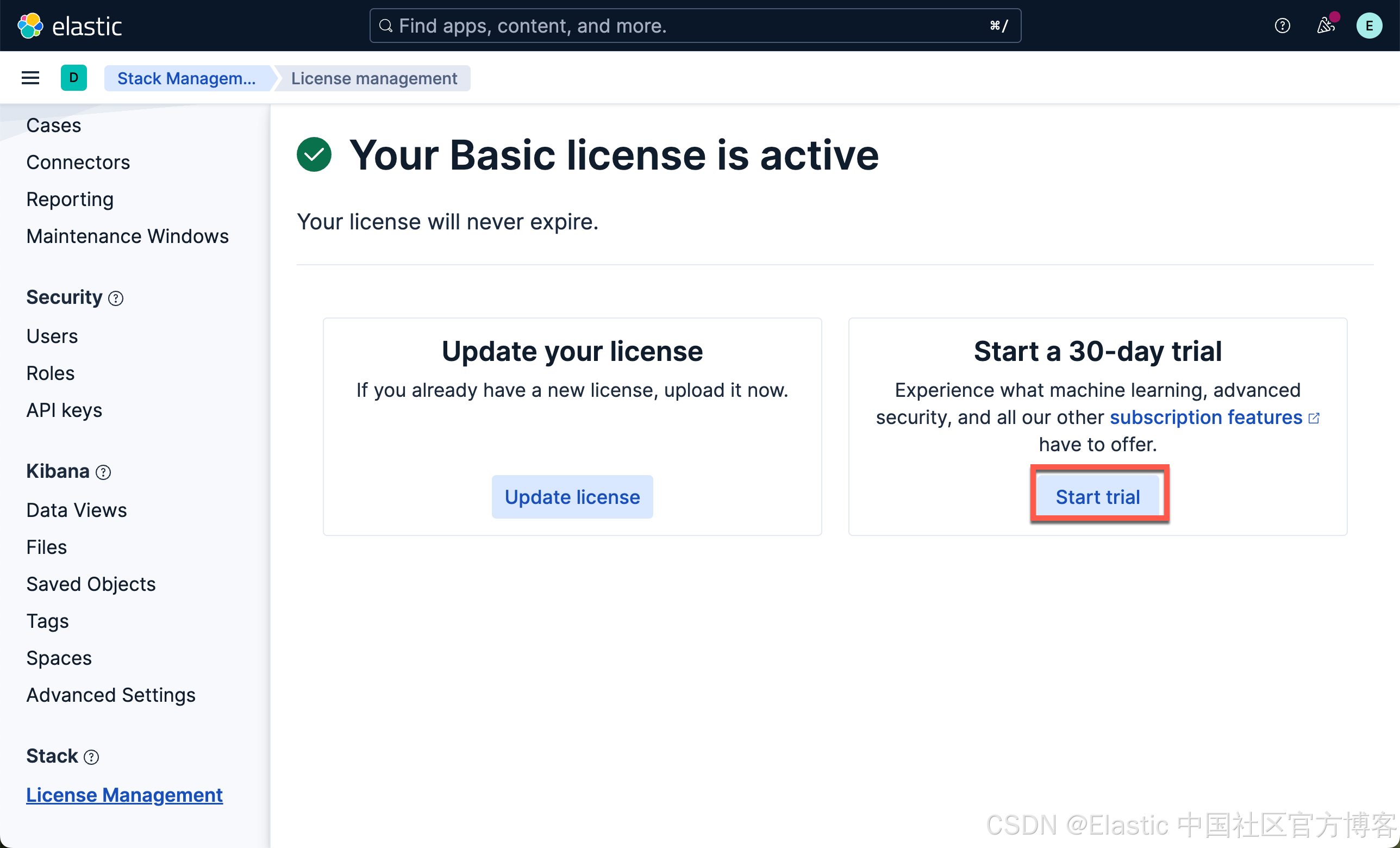
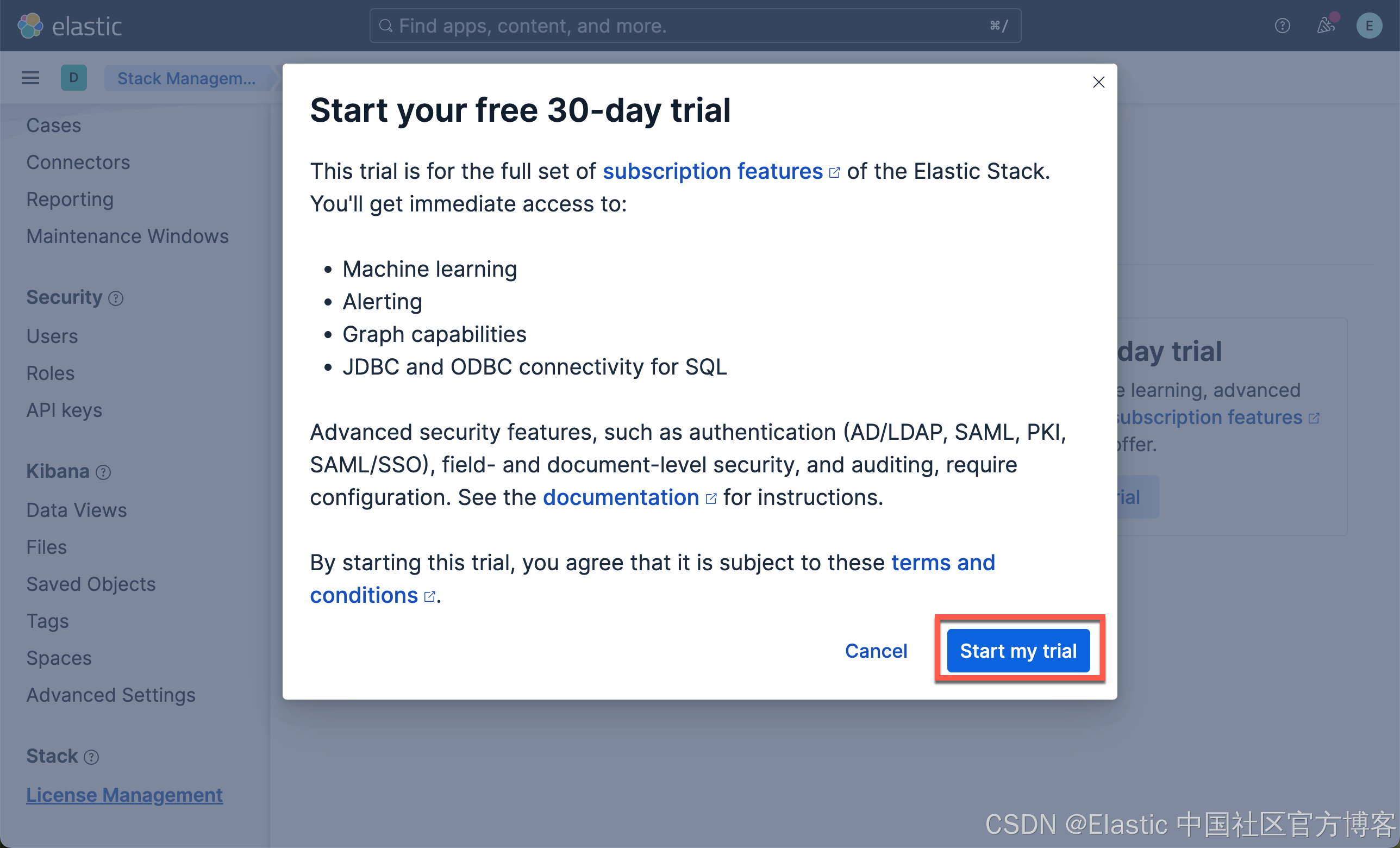
这样我们就启动了白金试用。
我们现在下载 ELSER 及 E5 嵌入模型:
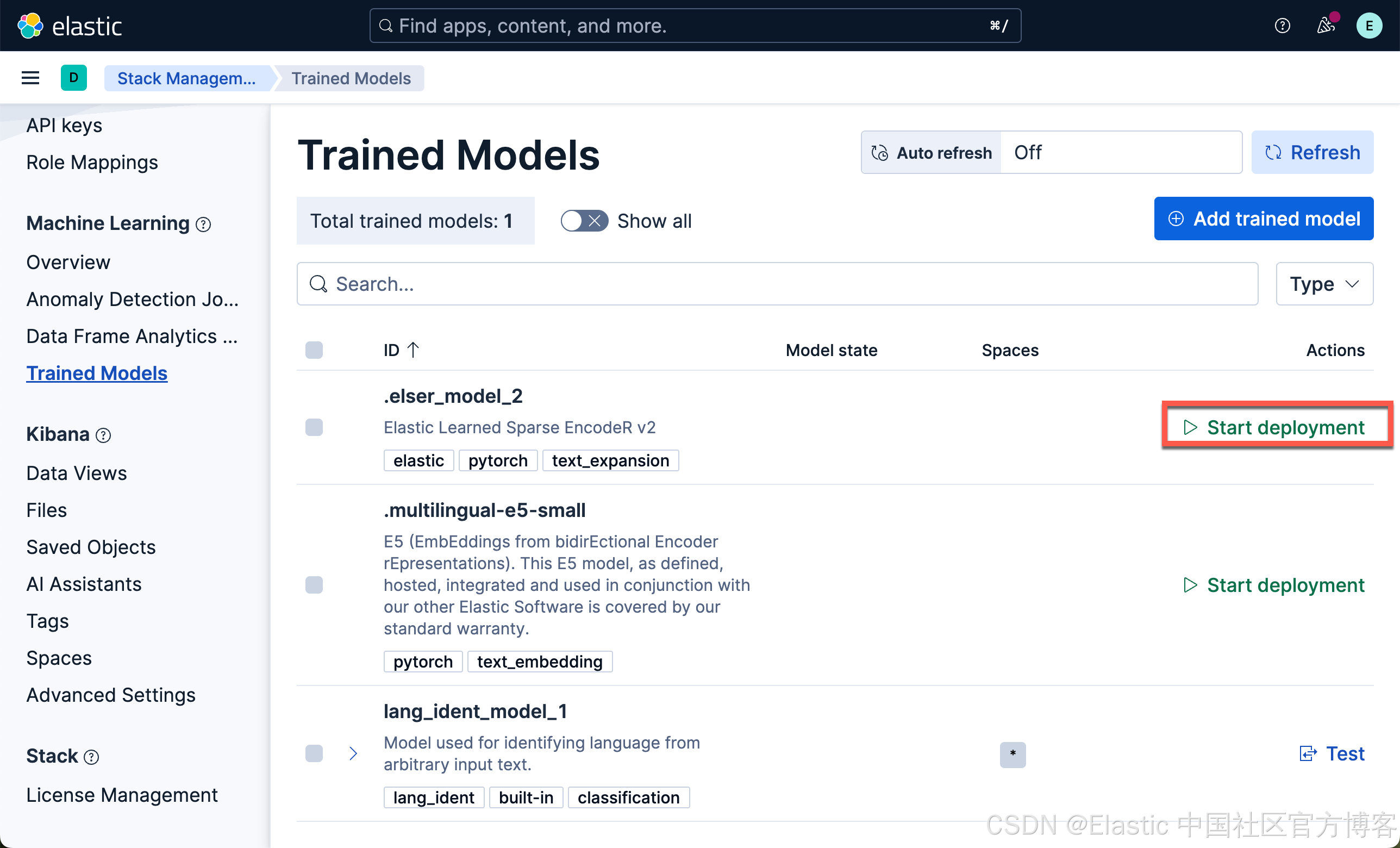
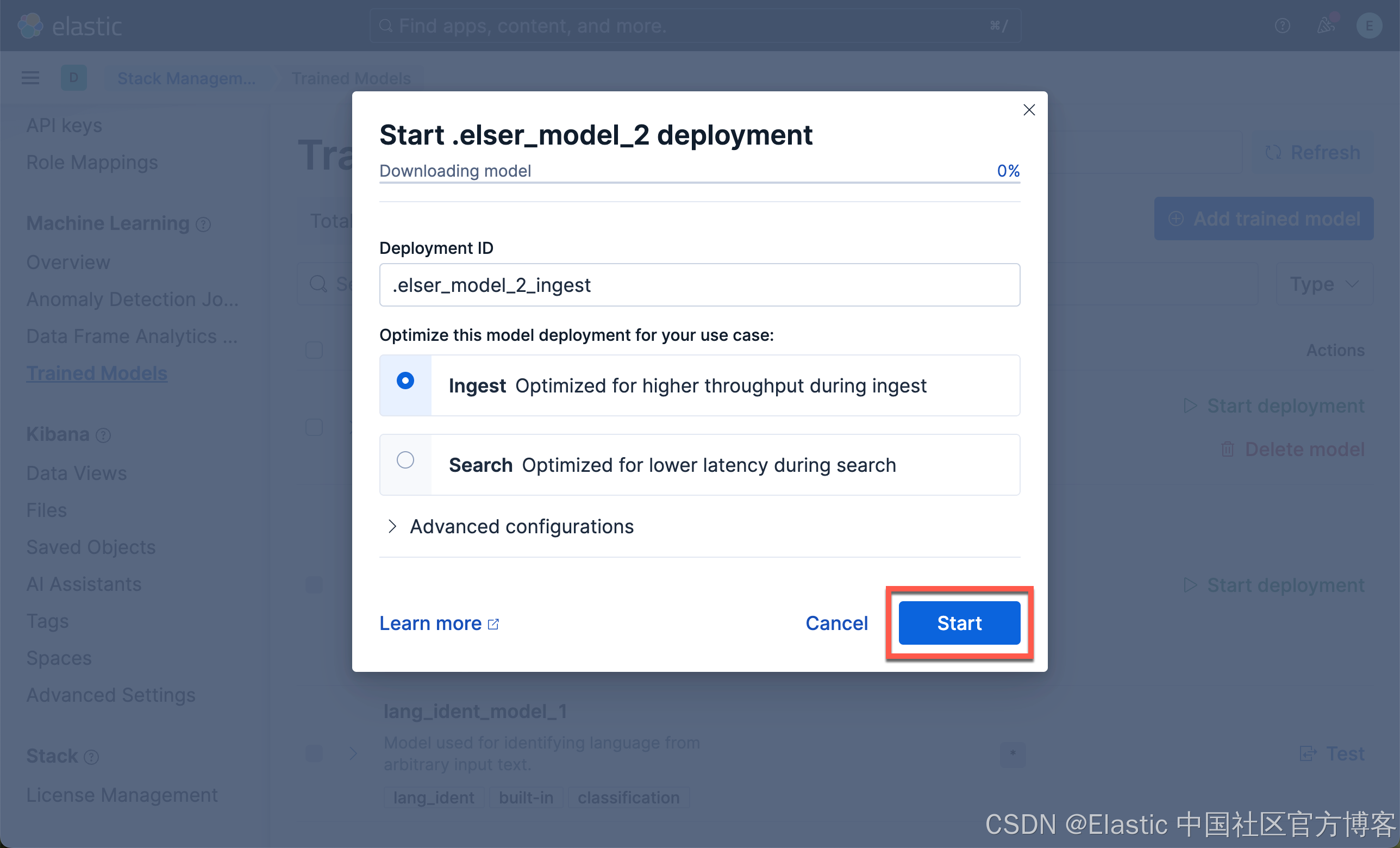
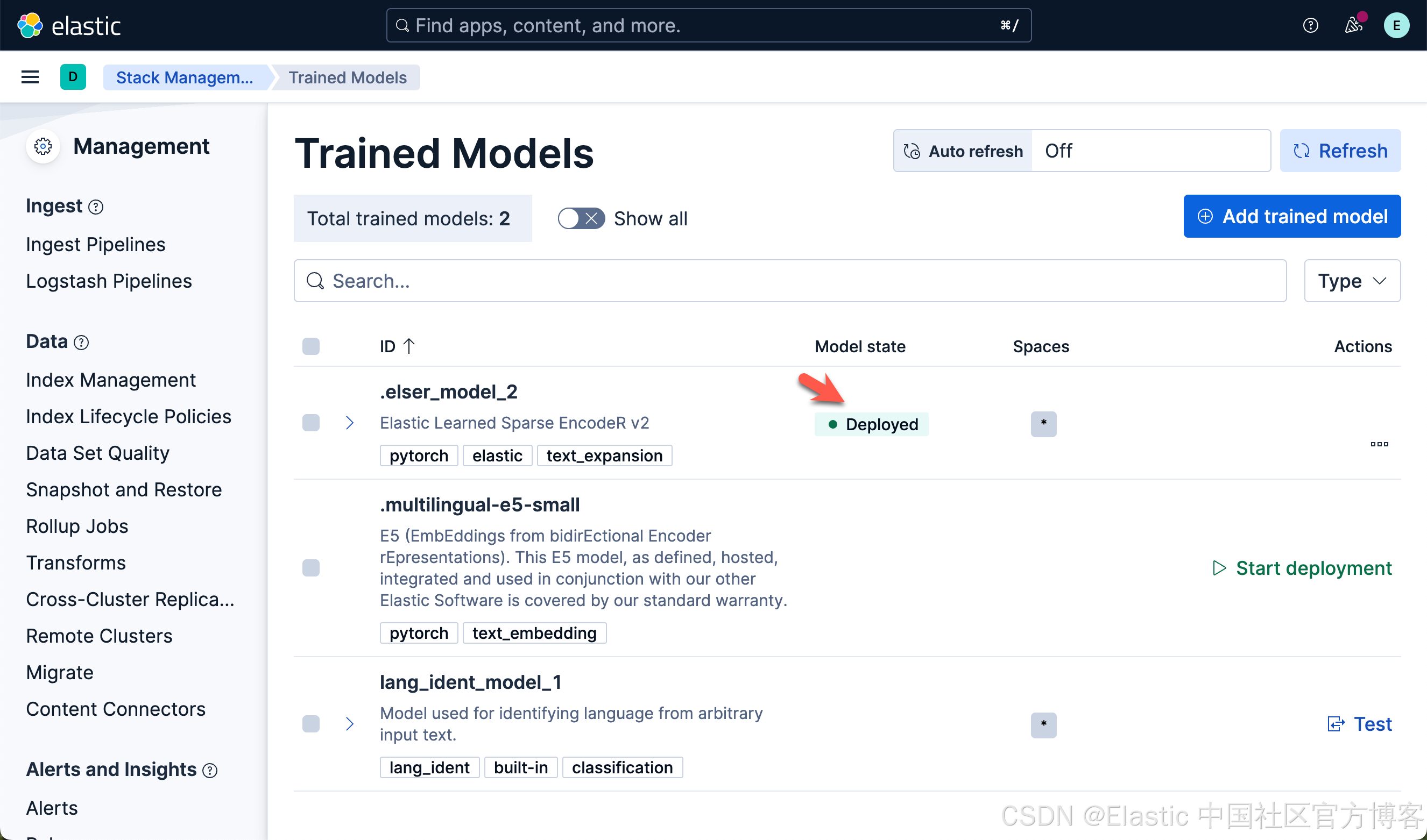
我们按照同样的方法来部署 E5 模型:
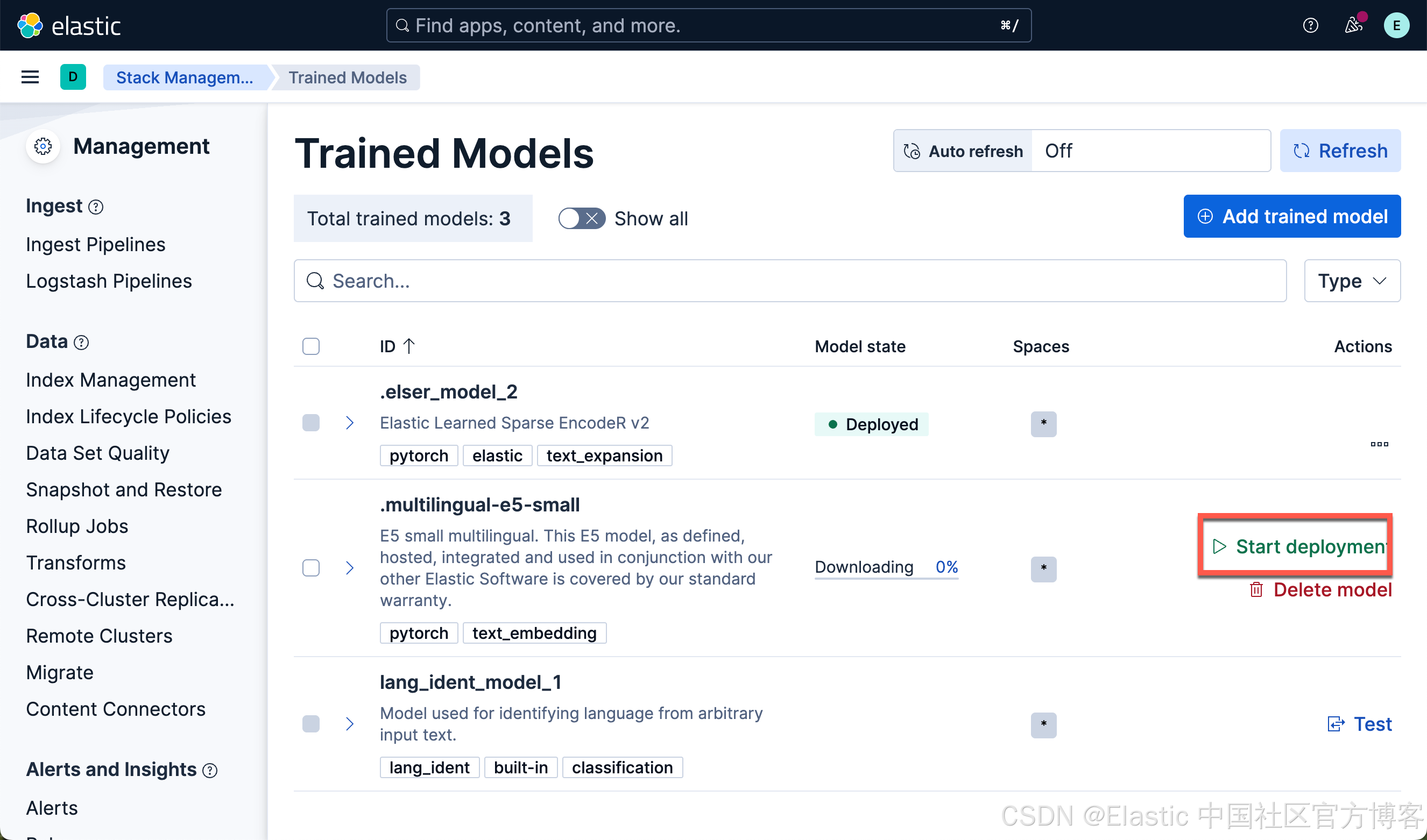
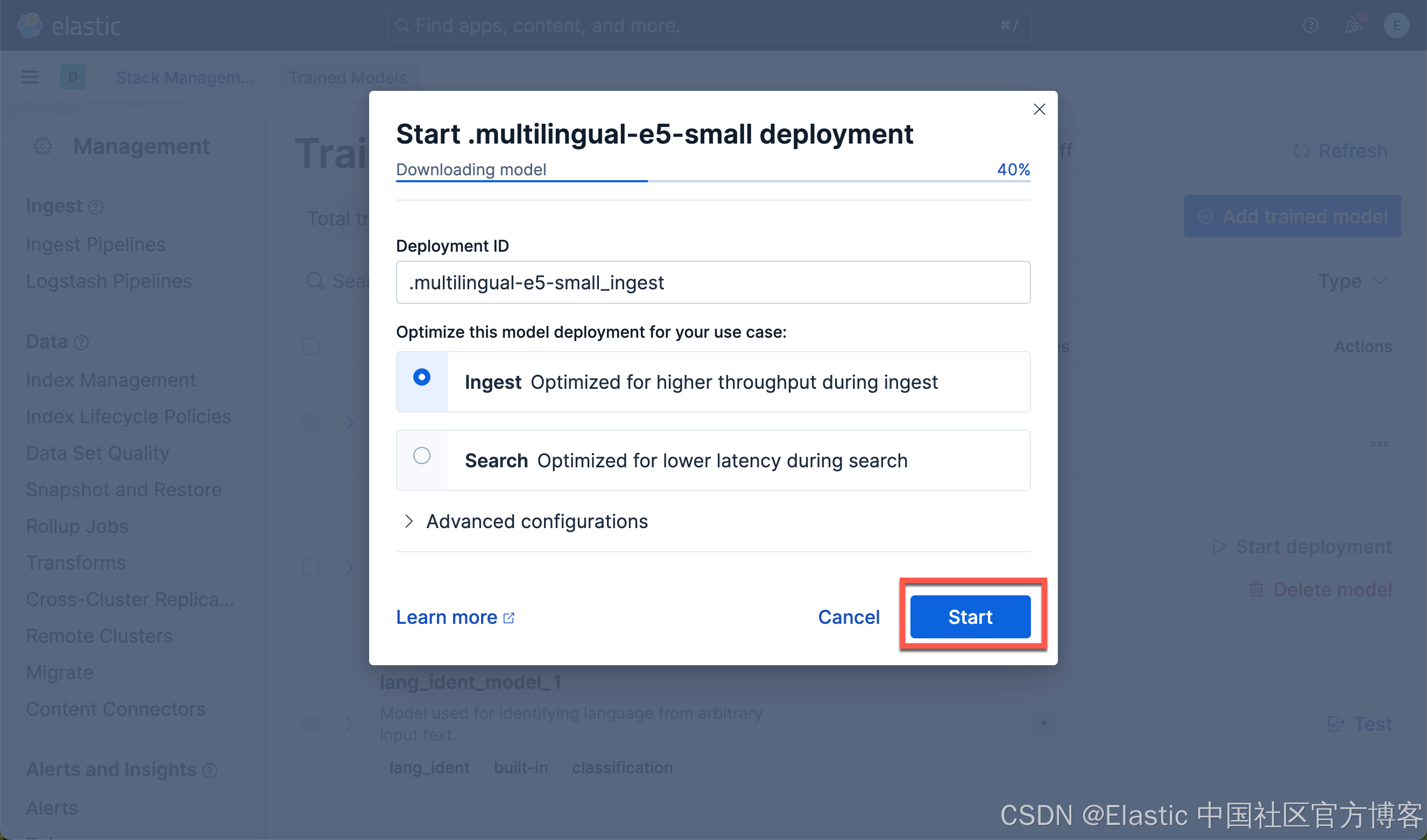
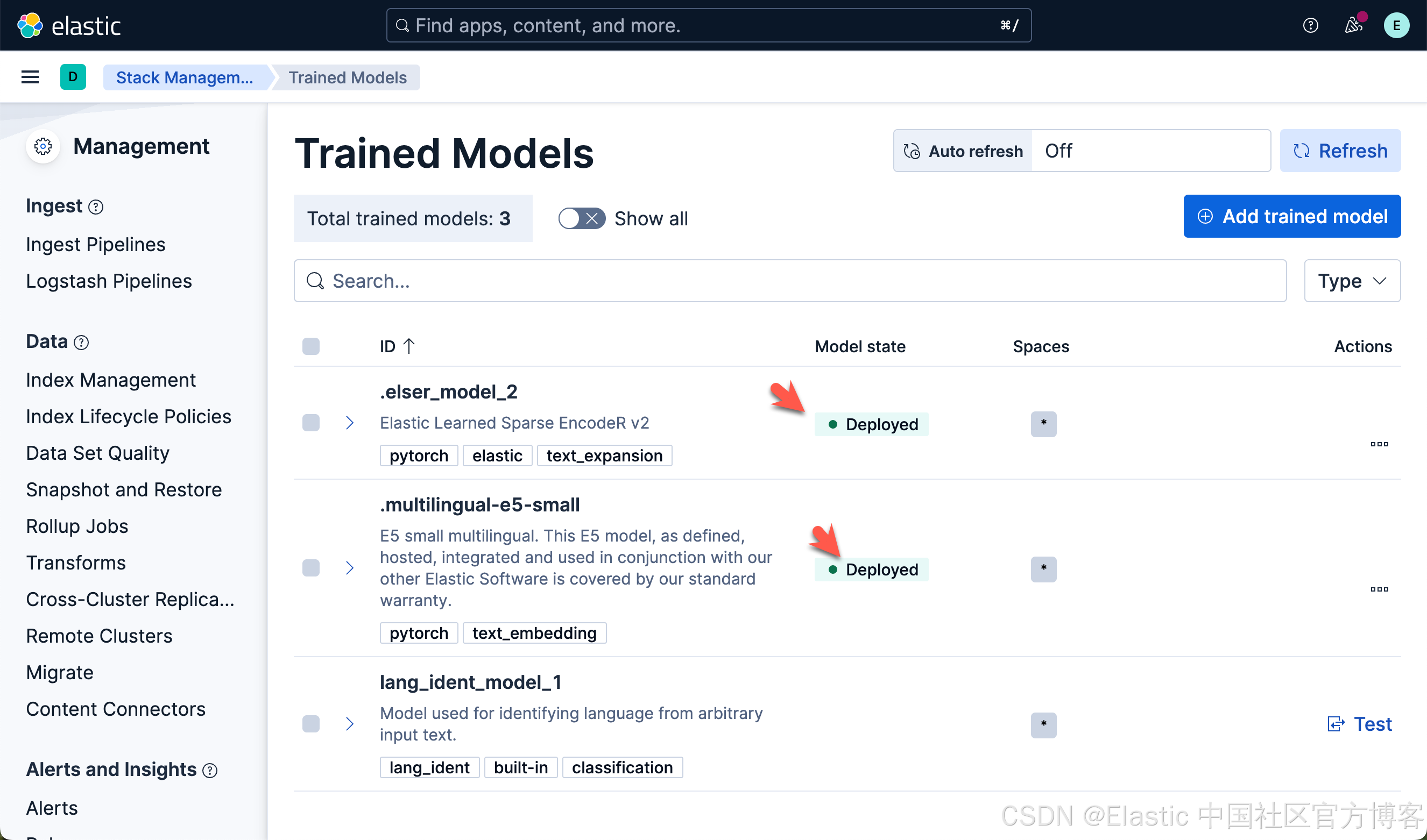
我们可以看到上面的两个模型都已经部署好了。如果你想部署其它的模型,可以参考文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索” 使用 eland 来上传模型。
我们可以通过如下的命令来查看已经创建好的 inference endpoints:
GET _inference/_all{
"endpoints": [
{
"inference_id": ".elser-2-elasticsearch",
"task_type": "sparse_embedding",
"service": "elasticsearch",
"service_settings": {
"num_allocations": 0,
"num_threads": 1,
"model_id": ".elser_model_2",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 0,
"max_number_of_allocations": 32
}
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
},
{
"inference_id": ".multilingual-e5-small-elasticsearch",
"task_type": "text_embedding",
"service": "elasticsearch",
"service_settings": {
"num_threads": 1,
"model_id": ".multilingual-e5-small",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 0,
"max_number_of_allocations": 32
}
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
},
{
"inference_id": ".rerank-v1-elasticsearch",
"task_type": "rerank",
"service": "elasticsearch",
"service_settings": {
"num_threads": 1,
"model_id": ".rerank-v1",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 0,
"max_number_of_allocations": 32
}
},
"task_settings": {
"return_documents": true
}
}
]
}从上面的输出中,我们可以看到有几个已经被预置的 endpoints。我们可以使用如下的命令来创建我们自己的 endpoint:
PUT _inference/text_embedding/multilingual_embeddings
{
"service": "elasticsearch",
"service_settings": {
"model_id": ".multilingual-e5-small",
"num_allocations": 1,
"num_threads": 1
}
}
在上面,我们创建了一个叫做 multilingual_embeddings 的 endpoint。如果不是特别要求,我们可以使用系统为我们提供的 .multilingual-e5-small-elasticsearch 端点。
我们可以使用如下的方法来创建一个 ESLER 的 endpoint:
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elasticsearch",
"service_settings": {
"model_id": ".elser_model_2",
"num_allocations": 1,
"num_threads": 1
}
}我们可以通过如下的方式来删除一个已经创建好的推理端点:
DELETE _inference/my-elser-model定义变量
我们可以参考 “Kibana:如何设置变量并应用它们” 来定义变量:
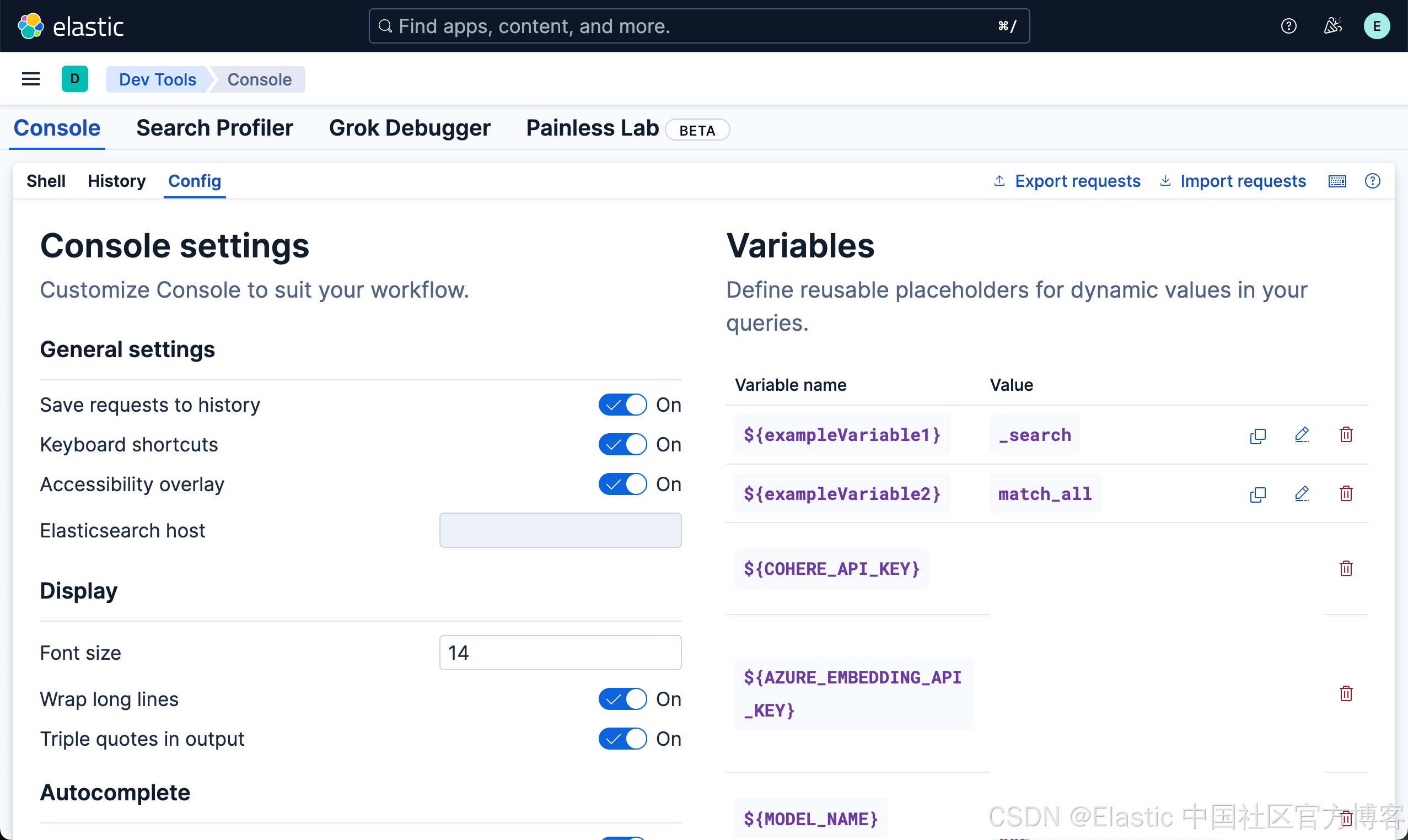
如上所示,我们在 “Config” 中定义如上所示的变量。
默认和自定义 endpoints
你可以在 semantic_text 字段中使用预配置的 endpoints,这对大多数用例很理想,或者创建自定义 endpoints 并在字段映射中引用它们。
展示
ELSER
我们可以按照如下的命令来创建一个叫做 my-elser-model 的 ELSER 推理端点。
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elasticsearch",
"service_settings": {
"model_id": ".elser_model_2",
"num_allocations": 1,
"num_threads": 1
}
}运行完上面的命令后,我们可以使用如下的命令来查看:
GET _inference/_all{
"endpoints": [
{
"inference_id": ".elser-2-elasticsearch",
"task_type": "sparse_embedding",
"service": "elasticsearch",
"service_settings": {
"num_threads": 1,
"model_id": ".elser_model_2",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 0,
"max_number_of_allocations": 32
}
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
},
{
"inference_id": ".multilingual-e5-small-elasticsearch",
"task_type": "text_embedding",
"service": "elasticsearch",
"service_settings": {
"num_threads": 1,
"model_id": ".multilingual-e5-small",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 0,
"max_number_of_allocations": 32
}
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
},
{
"inference_id": ".rerank-v1-elasticsearch",
"task_type": "rerank",
"service": "elasticsearch",
"service_settings": {
"num_threads": 1,
"model_id": ".rerank-v1",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 0,
"max_number_of_allocations": 32
}
},
"task_settings": {
"return_documents": true
}
},
{
"inference_id": "elser-endpoint",
"task_type": "sparse_embedding",
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".elser_model_2"
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
},
{
"inference_id": "my-elser-model",
"task_type": "sparse_embedding",
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".elser_model_2"
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
}
]
}如上所示,我们可以看到已经创建的 my-elser-model 推理端点。我们也可以采用带有参数的方法来创建推理端点:
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elasticsearch",
"service_settings": {
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 1,
"max_number_of_allocations": 10
},
"num_threads": 1,
"model_id": ".elser_model_2"
}
}我们也可以使用如下的命令来确认推理端点已经被成功创建:
GET _inference/my-elser-model或者:
GET _inference/sparse_embedding/my-elser-model{
"endpoints": [
{
"inference_id": "my-elser-model",
"task_type": "sparse_embedding",
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".elser_model_2"
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
}
]
}因为 .elser_model_2 本身的 metadata 数据含有信息表面它是 sparse vector,上面不含 sparse_embedding 路径的 API 接口更加方便简捷。
接下来,我们使用如下的命令来进行测试我们刚才创建的 ELSER 推理端点:
POST _inference/sparse_embedding/my-elser-model
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
上面的命令返回的结果是:
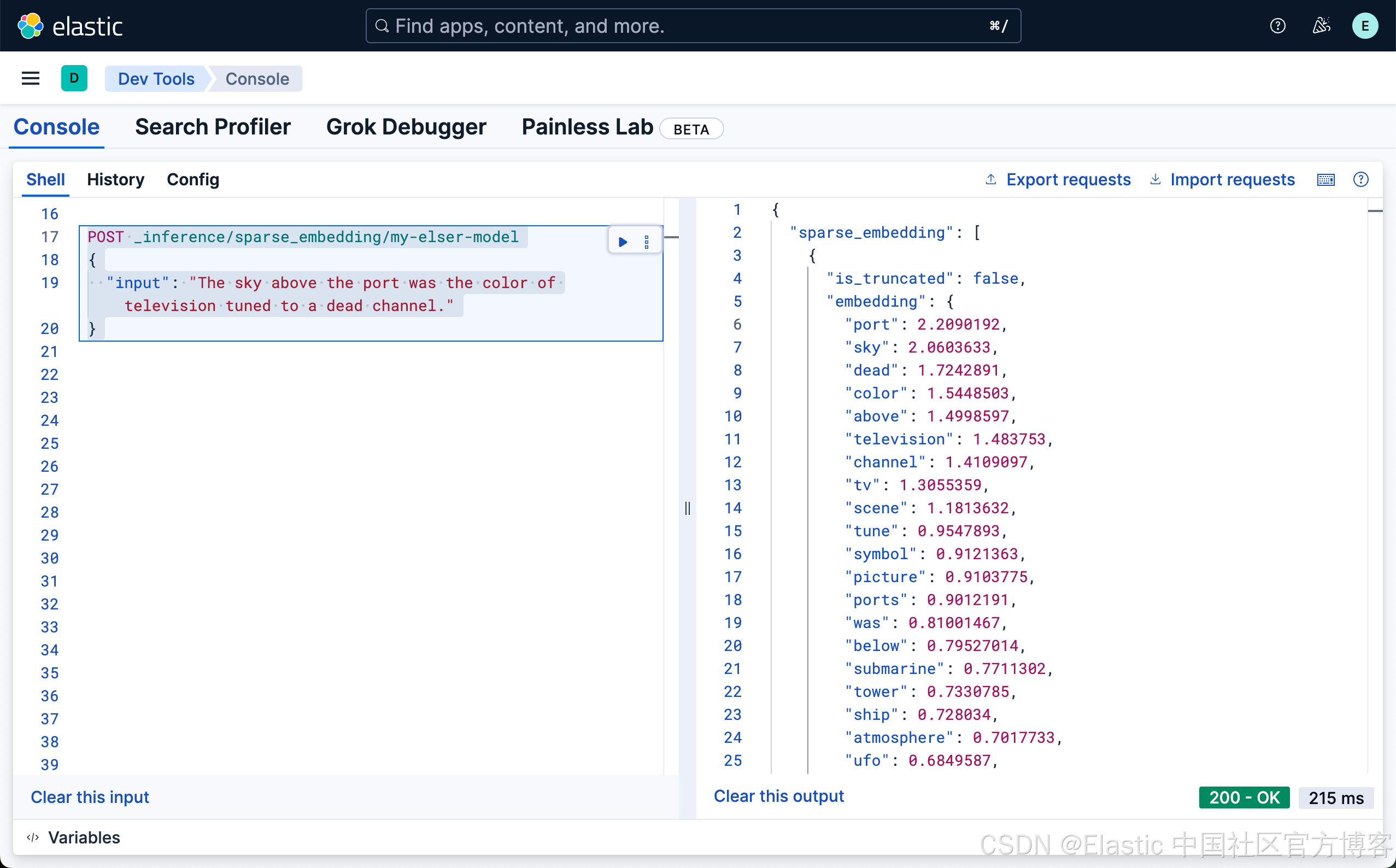
从上面的输出结果,我们可以看出来,ELSER 是通过文本扩展来完成向量的输出,比如 television 通过文字扩展的方法可以联系到 tv,甚至和 channel 也有关联。每个词的关联度,还有一个系数。
通过这样的文字扩展,我们可以实现文字的语义搜索。为了简便搜索,我们也可以省去路径中的 sparse_embedding:
POST _inference/my-elser-model
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}值得注意的是:目前 ELSER 模型针对英文工作的非常好,但是它不适合中文的文章扩展。目前国内的阿里已经支持稀疏向量的嵌入。它不需要针对任何的领域进行微调:开箱即用!
Cohere
我们可以使用如下的方式来创建一个 Cohere 嵌入推理端点:
PUT _inference/text_embedding/cohere_embeddings
{
"service": "cohere",
"service_settings": {
"api_key": "${COHERE_API_KEY}",
"model_id": "embed-english-light-v3.0",
"embedding_type": "byte"
}
}在上面,我们定义了 embedding_type 为 byte,也就是 8-bit。这也是一种标量量化。
我们可以使用如下的方式来获取 embedding:
POST _inference/text_embedding/cohere_embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel.",
"task_settings": {
"input_type": "ingest"
}
}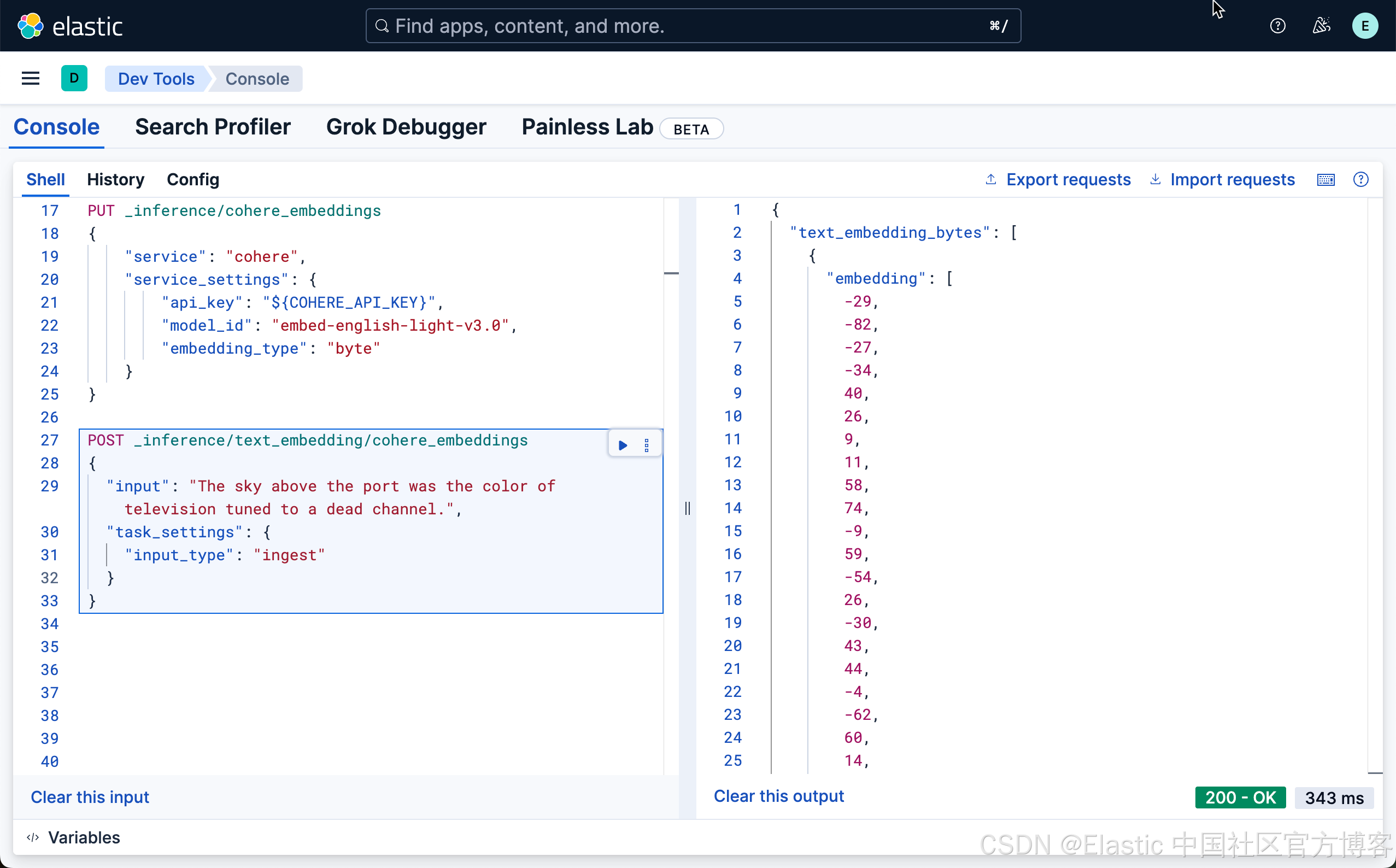
我们可以看到一个 byte 的输出。我们也可以使用如下的方式来获取:
POST _inference/cohere_embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel.",
"task_settings": {
"input_type": "ingest"
}
}在上面,我们省去了路径中的 text_embedding,这是因为 model_id 的元数据里本身就含有这个信息。
Open AI
我们使用如下的命令来创建一个嵌入的推理端点:
PUT _inference/text_embedding/openai-embeddings
{
"service": "openai",
"service_settings": {
"api_key": "${OPENAI_API_KEY}",
"model_id": "text-embedding-3-small",
"dimensions": 128
}
}
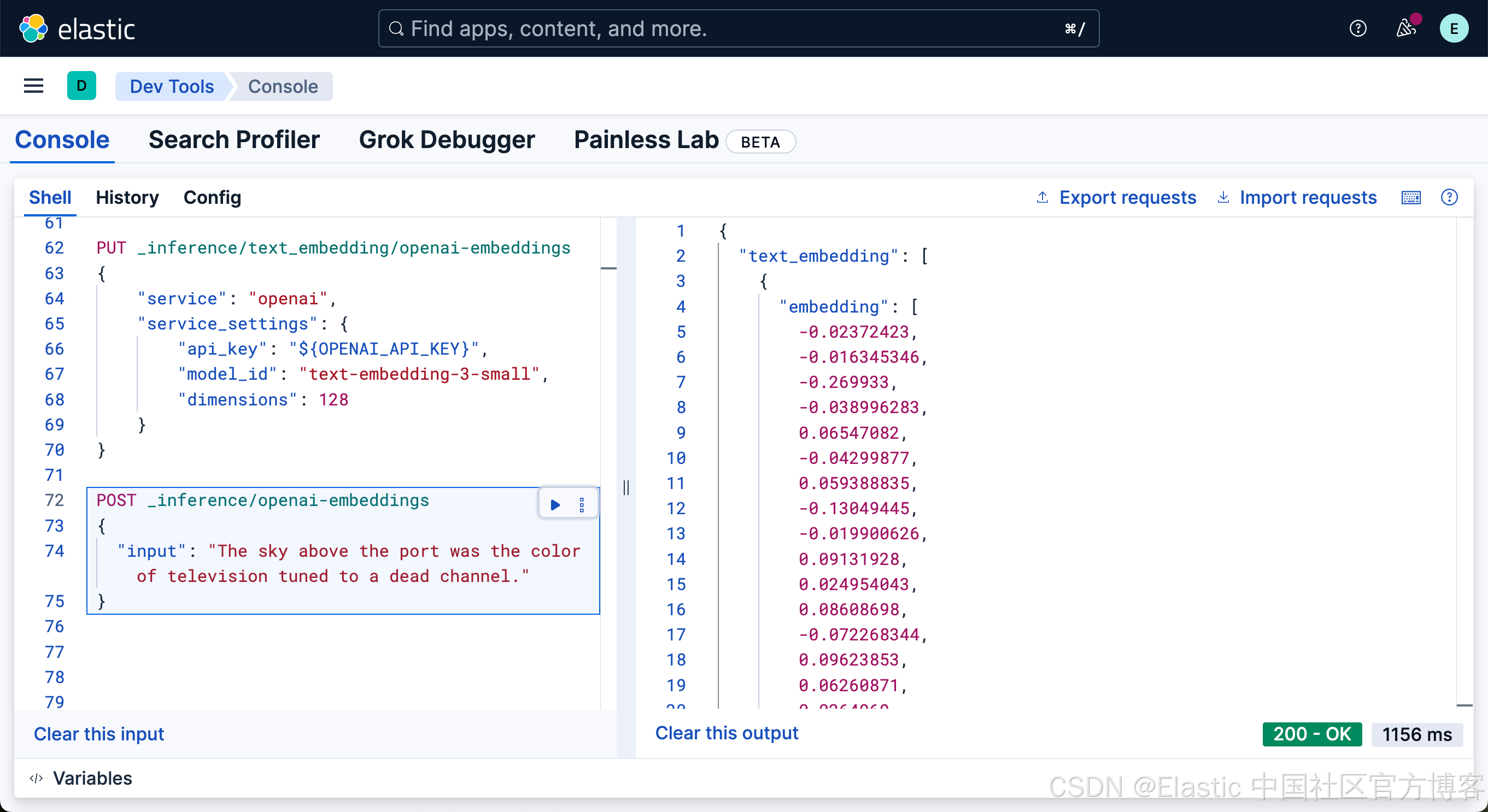
我们使用如下的命令来获得 Open AI 的嵌入:
POST _inference/openai-embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
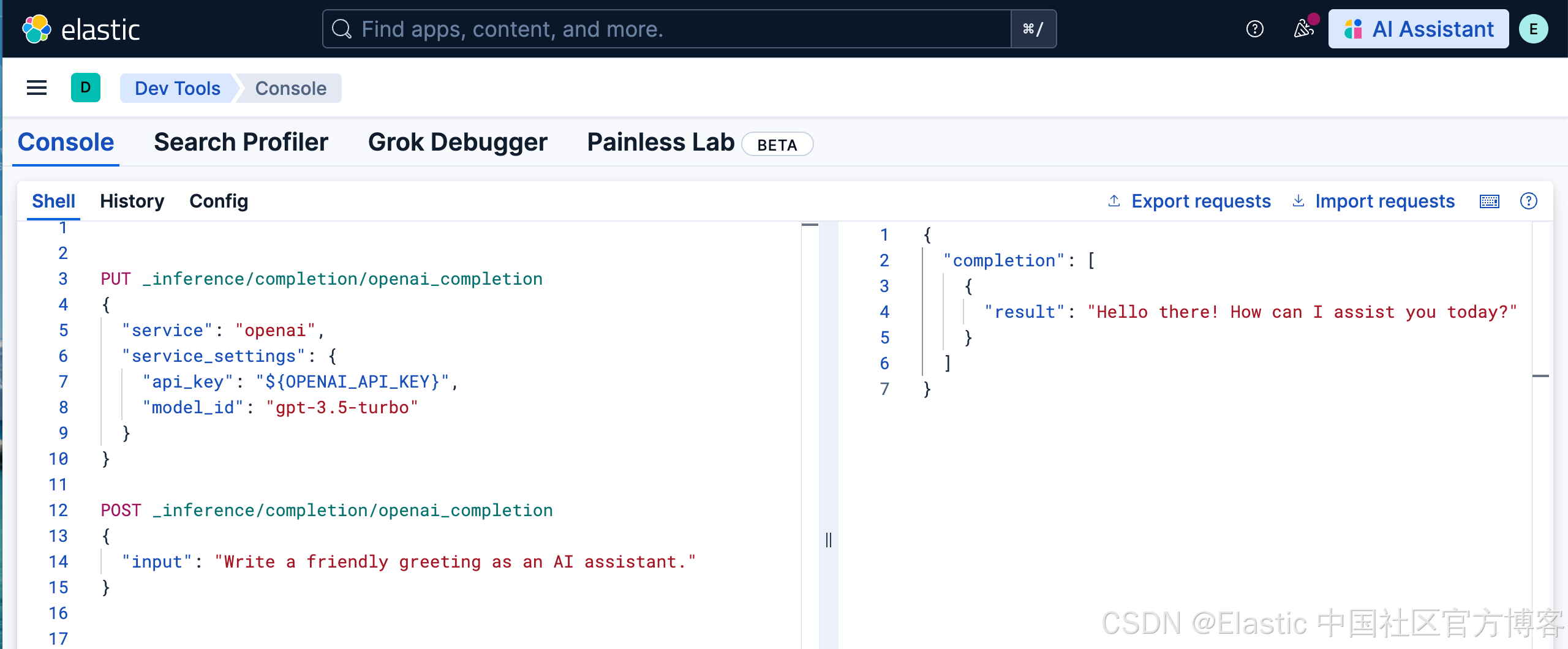
我们使用如下的命令来活动 OpenAI chat completion:
PUT _inference/completion/openai_completion
{
"service": "openai",
"service_settings": {
"api_key": "${OPENAI_API_KEY}",
"model_id": "gpt-3.5-turbo"
}
}POST _inference/completion/openai_completion
{
"input": "Write a friendly greeting as an AI assistant."
}
DeepSeek
请参考我的另外一篇文章 “Elasticsearch:创建一个定制的 DeepSeek 嵌入推理端点” 来体验 DeepSeek 的嵌入生成及 Chat completion。
GTP-OSS
我们可以仿照文章 “如何使用 Ollama 在本地设置和运行 GPT-OSS” 及 文章 “Elasticsearch:创建一个定制的 DeepSeek 嵌入推理端点” 来创建一个 chat completion 的端点。目前 gpt-oss:20b 不支持嵌入。
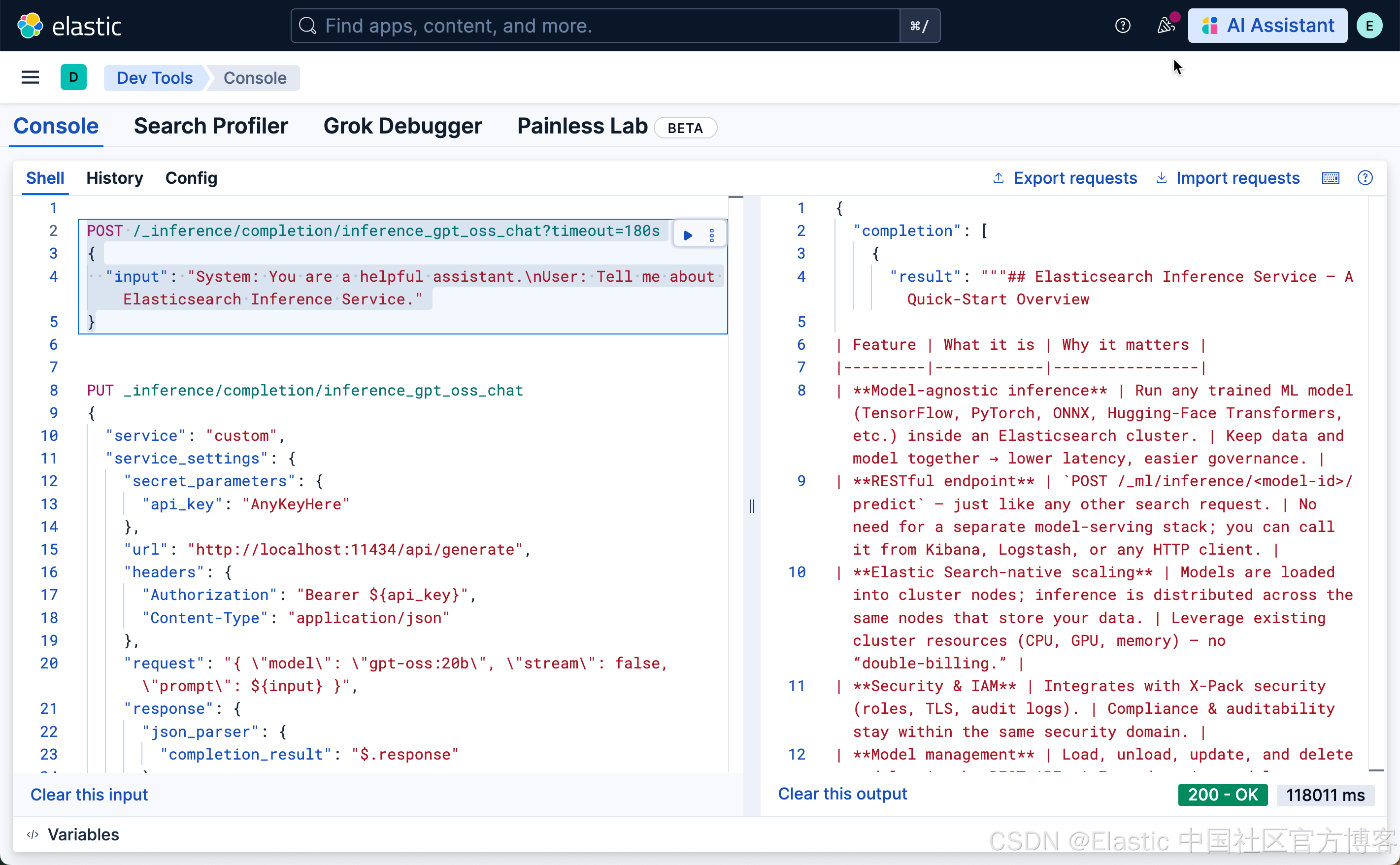
PUT _inference/completion/inference_gpt_oss_chat
{
"service": "custom",
"service_settings": {
"secret_parameters": {
"api_key": "AnyKeyHere"
},
"url": "http://localhost:11434/api/generate",
"headers": {
"Authorization": "Bearer ${api_key}",
"Content-Type": "application/json"
},
"request": "{ \"model\": \"gpt-oss:20b\", \"stream\": false, \"prompt\": ${input} }",
"response": {
"json_parser": {
"completion_result": "$.response"
}
},
"input_type": {
"default": "input"
}
}
}我们可以使用上面已经创建好的端点来进行推理:
Azure OpenAI
我们可以参考之前的文章俩创建 Azure OpenAI 的账号及嵌入模型:
PUT _inference/text_embedding/azure_openai_embeddings
{
"service": "azureopenai",
"service_settings": {
"api_key": "${AZURE_EMBEDDING_API_KEY}",
"resource_name": "ada-embeddings1",
"deployment_id": "${MODEL_NAME}",
"api_version": "2023-05-15"
}
}一旦创建成功,我们可以使用如下的命令来创建 Aure OpenAI 的嵌入:
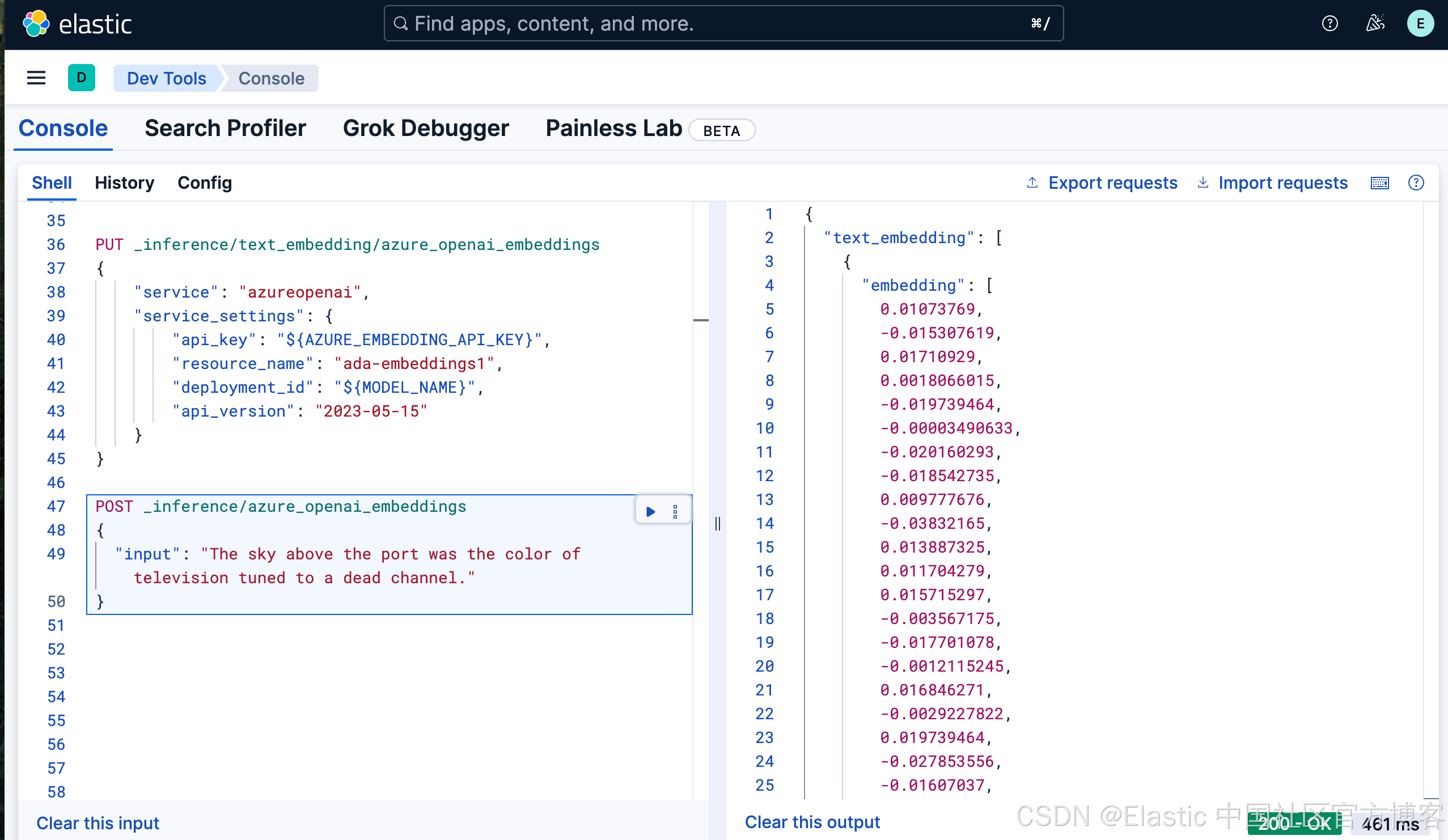
POST _inference/azure_openai_embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
我们可以使用如下的方式来创建一个 Azure OpenAI 的 chat completion 推理端点:
PUT _inference/completion/azure_openai_completion
{
"service": "azureopenai",
"service_settings": {
"api_key": "${AZURE_API_KEY}",
"resource_name": "${AZURE_RESOURCE_NAME}",
"deployment_id": "${AZURE_DEPLOYMENT_ID}",
"api_version": "${AZURE_API_VERSION}"
}
}
我们可以使用如下的方法来使用这个 chat completion 推理端点:
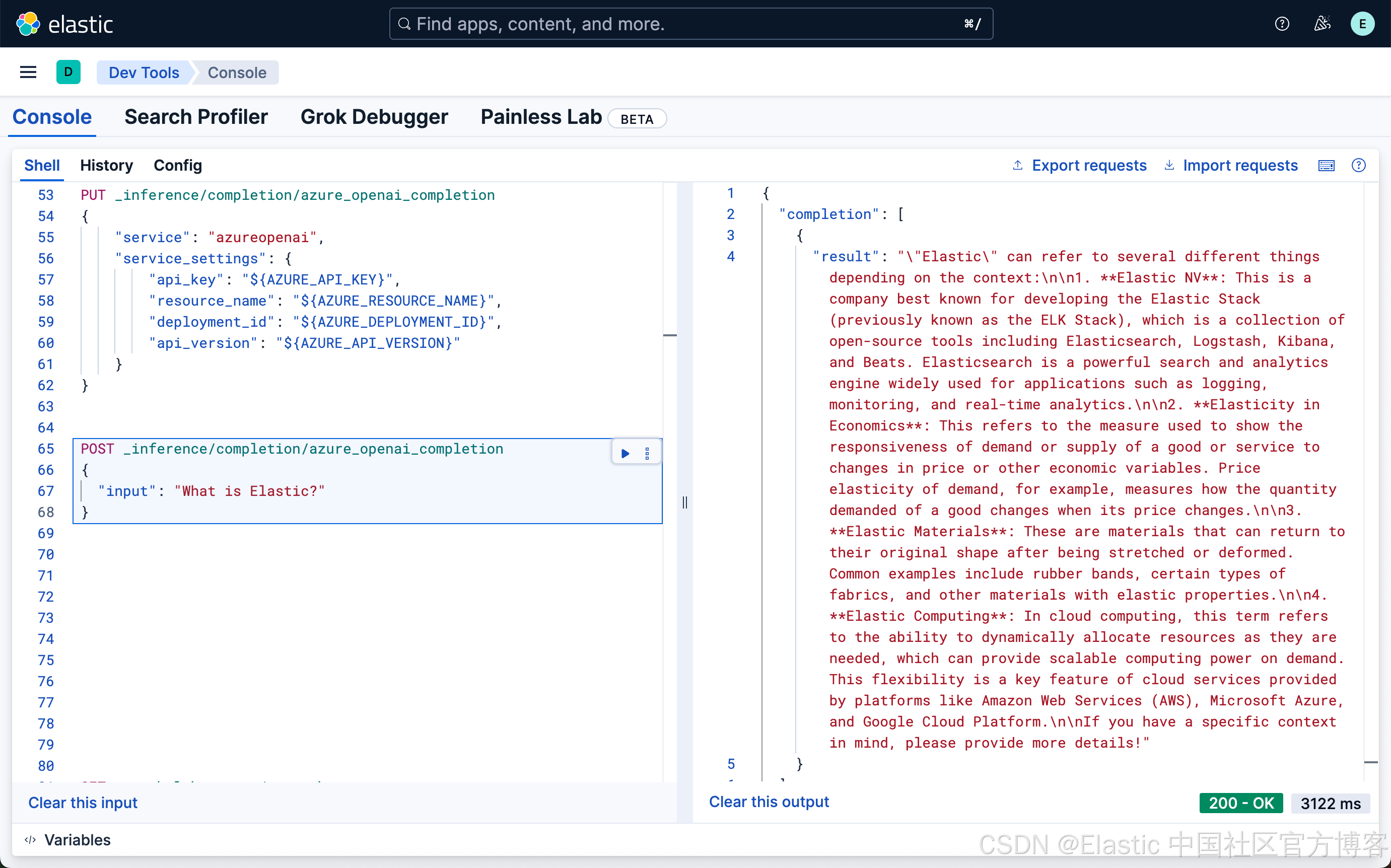
POST _inference/completion/azure_openai_completion
{
"input": "What is Elastic?"
}
我们使用如下的命令来创建一个 OpenAI 的 chat completion 端点:
PUT _inference/completion/my_openai_chat
{
"service": "openai",
"service_settings": {
"api_key": "${OPENAI_API_KEY}",
"model_id": "gpt-4o-mini"
}
}我们可以使用如下的命令来使用它:
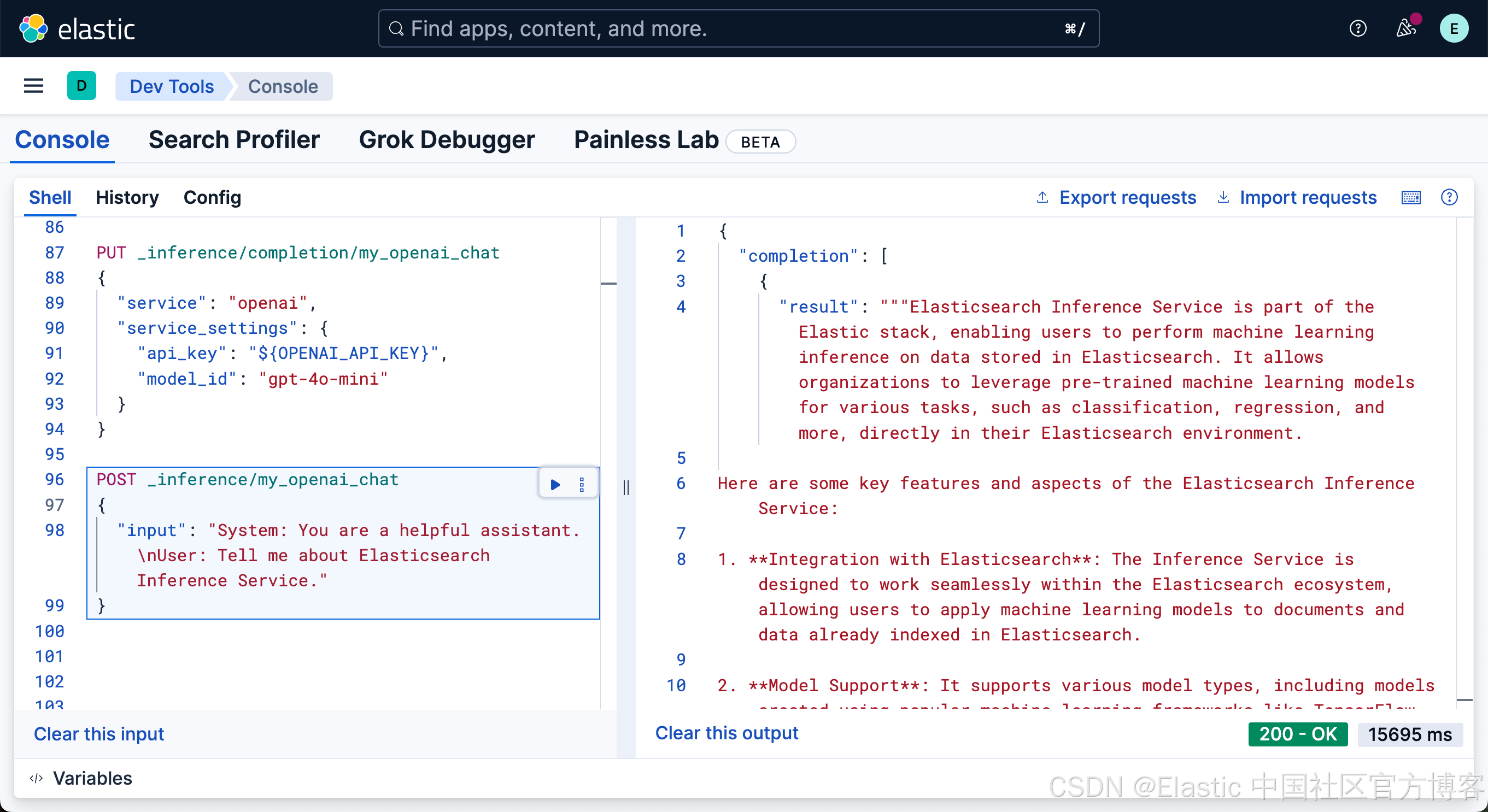
POST _inference/my_openai_chat
{
"input": "System: You are a helpful assistant.\nUser: Tell me about Elasticsearch Inference Service."
}
或者:
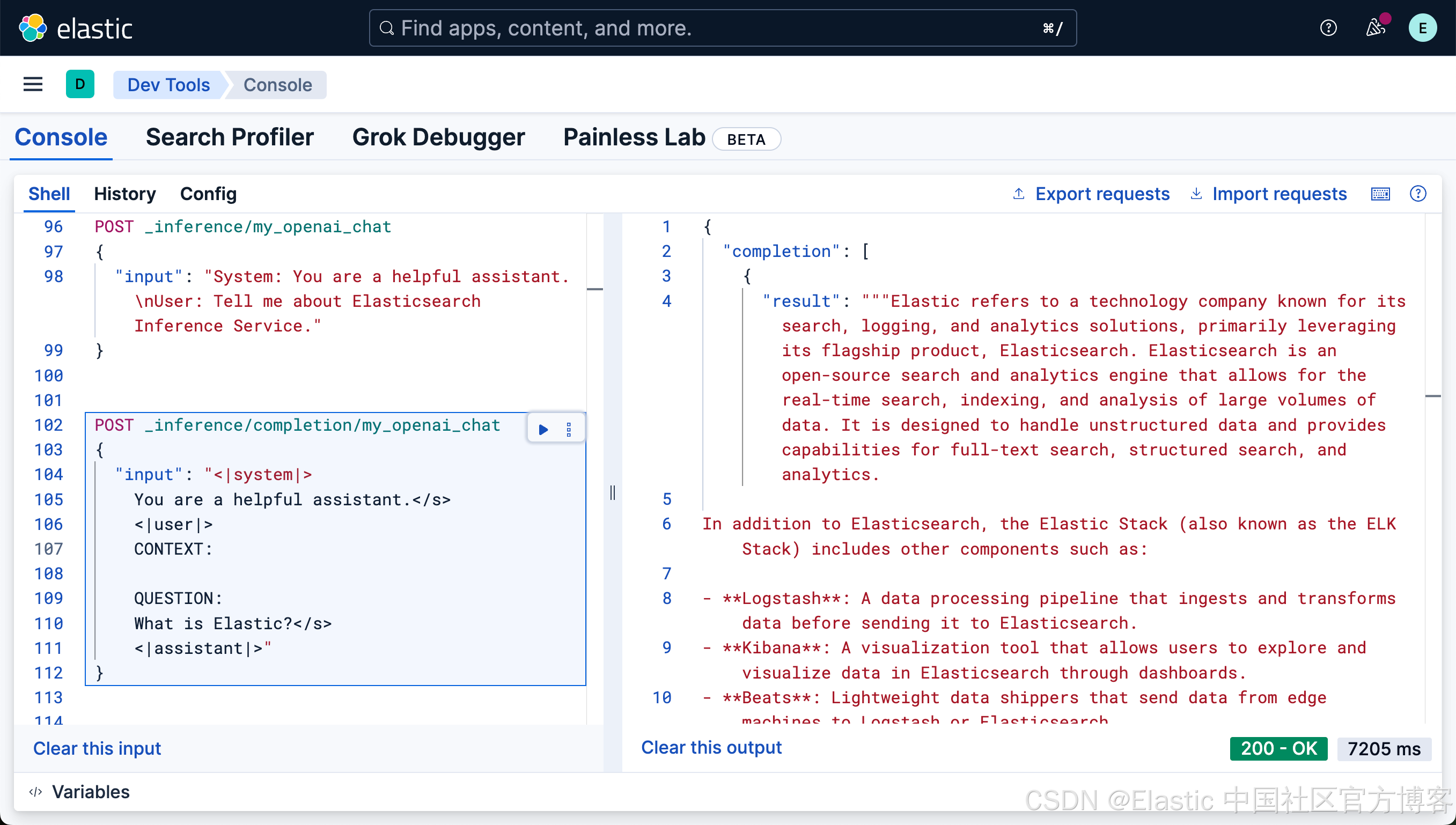
POST _inference/completion/my_openai_chat
{
"input": "<|system|>
You are a helpful assistant.</s>
<|user|>
CONTEXT:
QUESTION:
What is Elastic?</s>
<|assistant|>"
}
E5
在上面我们已经部署了 E5 small 模型。我们可以使用如下的方式来创建一个端点:
PUT _inference/text_embedding/multilingual_embeddings
{
"service": "elasticsearch",
"service_settings": {
"model_id": ".multilingual-e5-small",
"num_allocations": 1,
"num_threads": 1
}
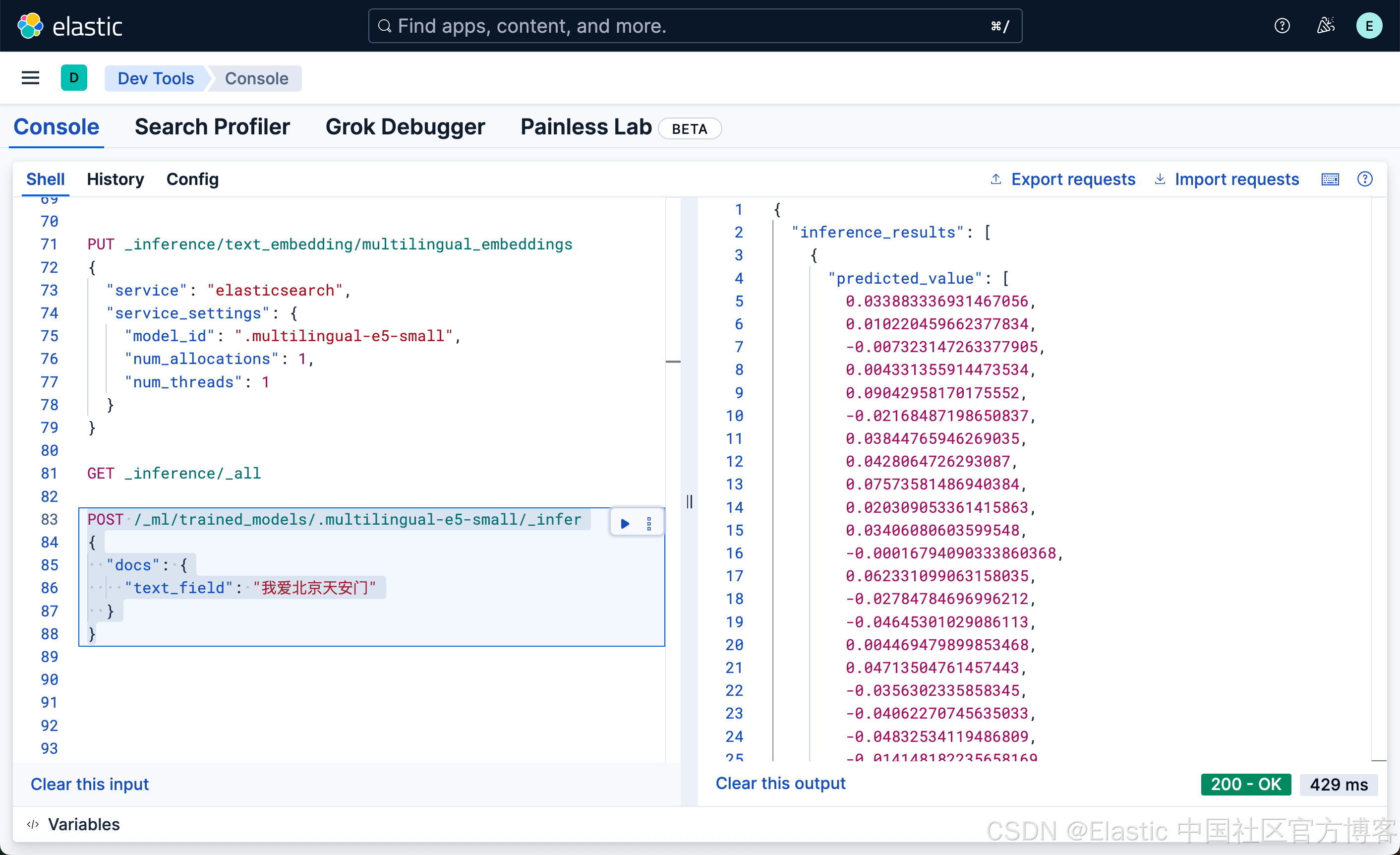
}我们可以使用如下的方式来获取嵌入:
POST /_ml/trained_models/.multilingual-e5-small/_infer
{
"docs": {
"text_field": "我爱北京天安门"
}
}
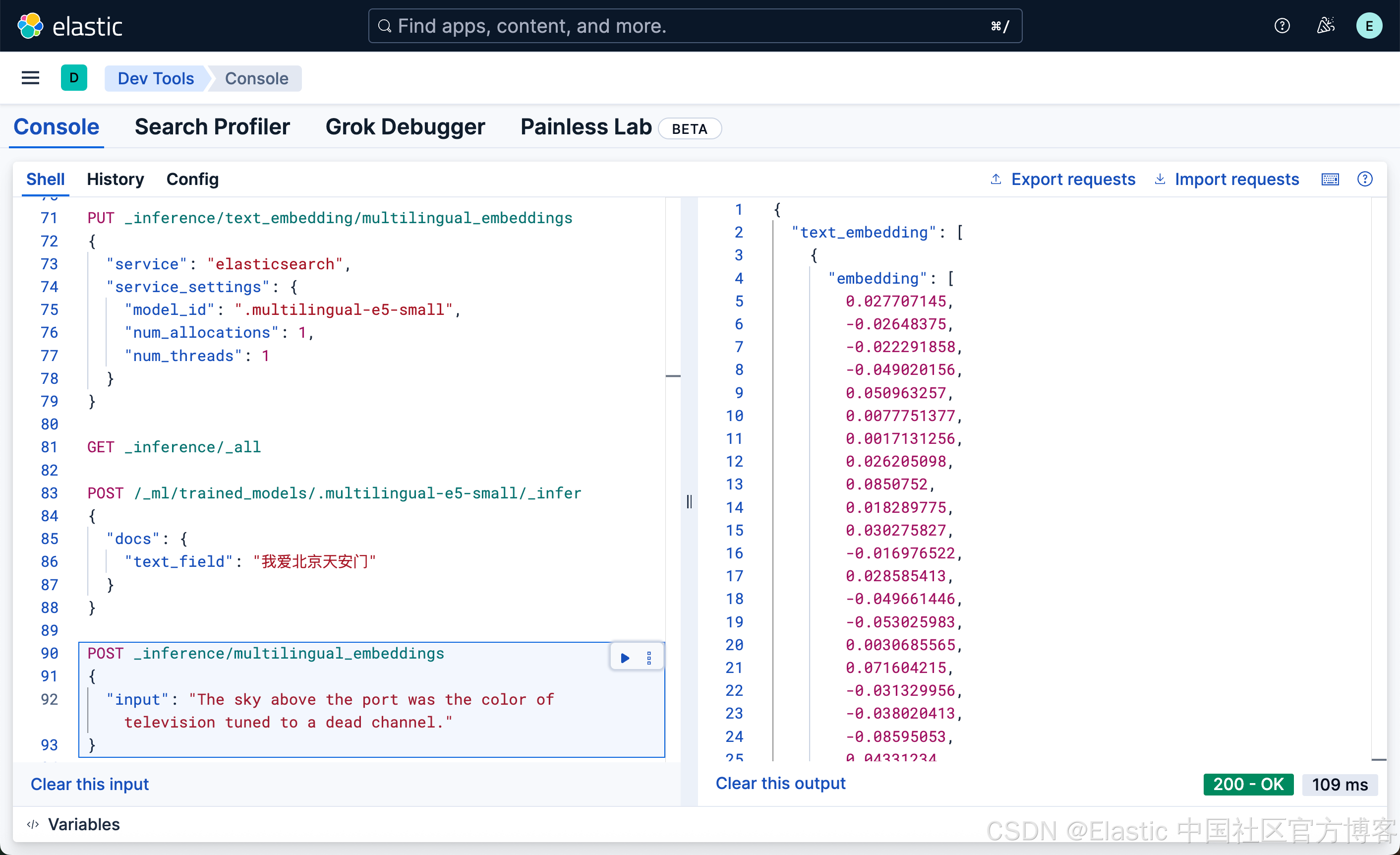
我们也可以使用我们刚才已经创建好的端点 multilingual_embeddings 来创建:
POST _inference/multilingual_embeddings
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
第三方模型
我们可以参考之前的文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索” 来部署一个第三方的模型,比如 sentence-transformers__msmarco-distilbert-base-tas-b。
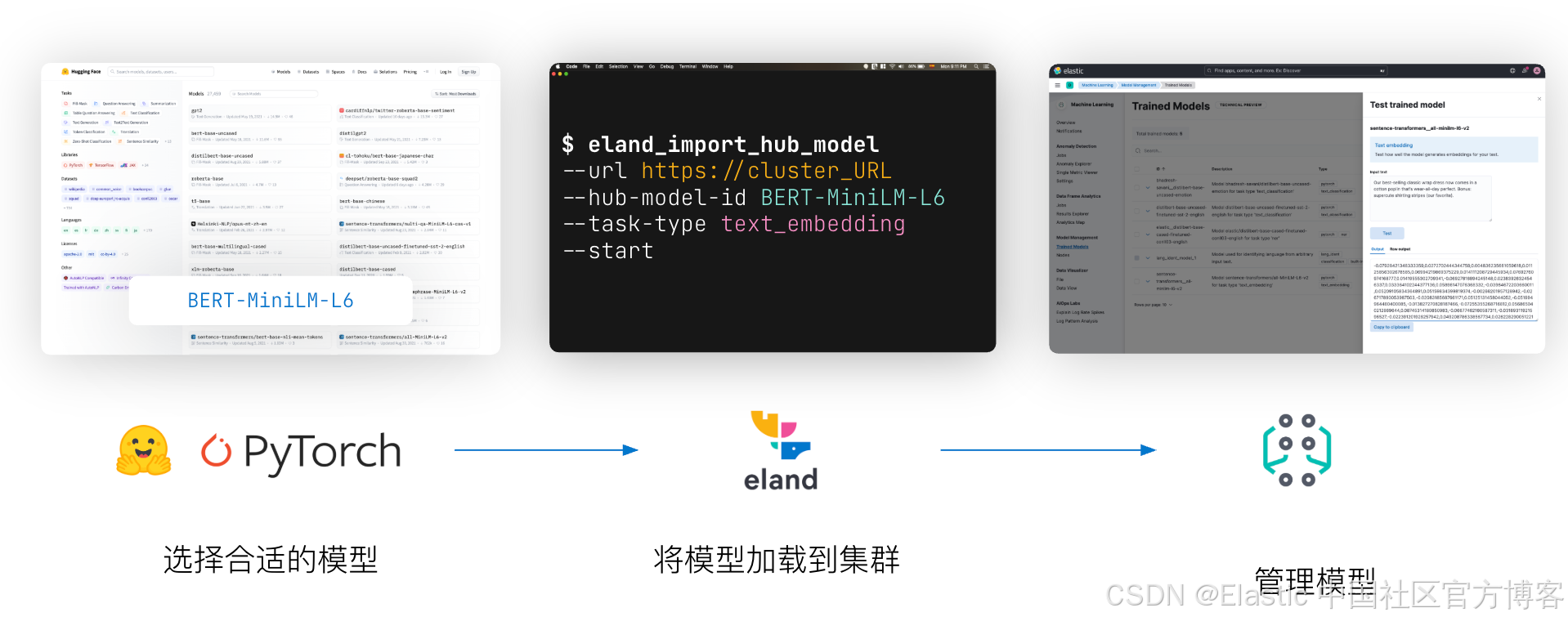
eland_import_hub_model --url https://elastic:GK1JT0+tbYQV02R9jVP*@localhost:9200 \
--hub-model-id sentence-transformers/msmarco-distilbert-base-tas-b \
--task-type text_embedding \
--insecure \
--start在运行完上面的命令后,我们可以在 Trained models 界面看到如下已经部署的模型:
我们可以使用的如下的命令来生成嵌入:
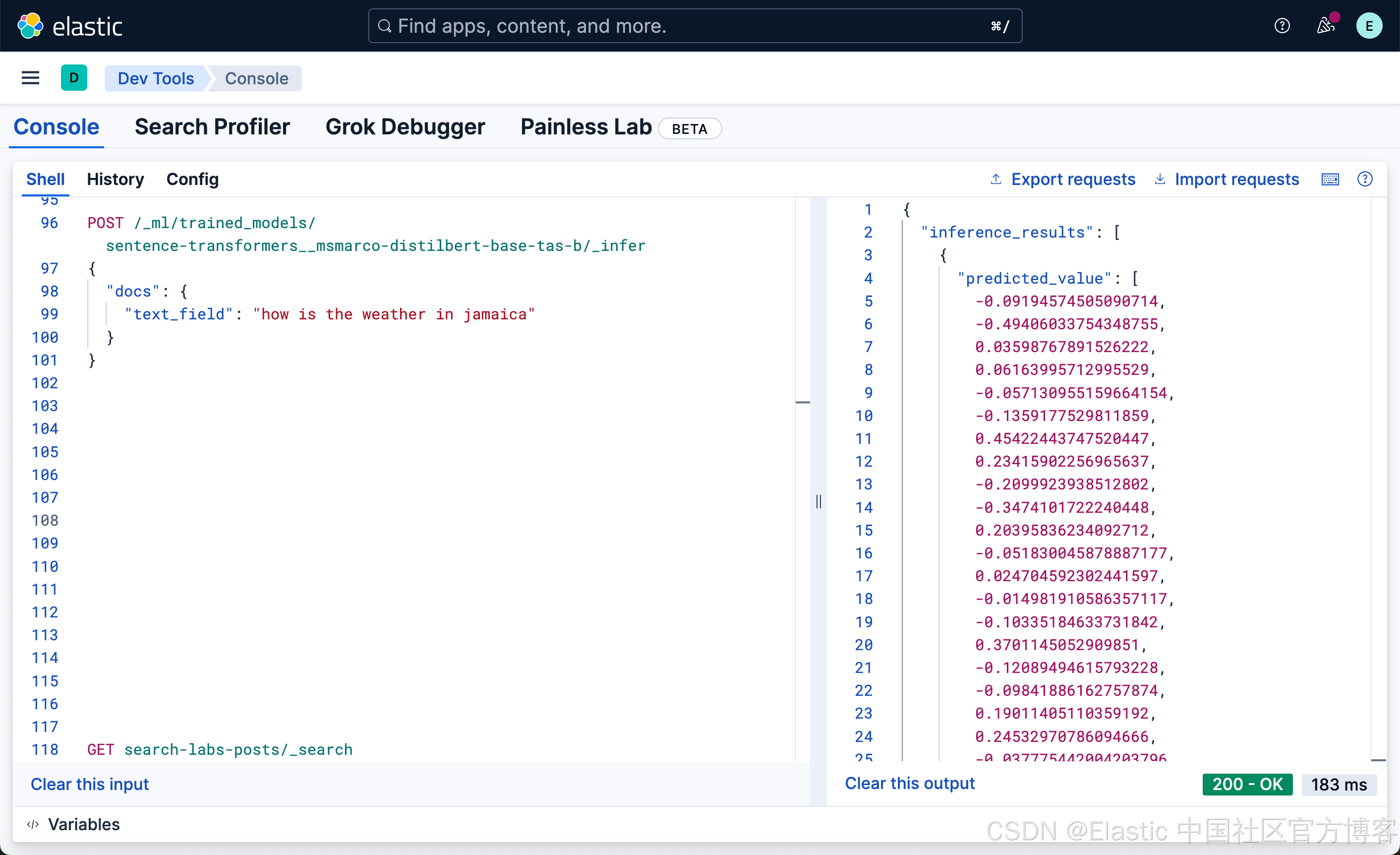
POST /_ml/trained_models/sentence-transformers__msmarco-distilbert-base-tas-b/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}
我们也可以创建一个推理端点来实现:
PUT _inference/text_embedding/distilbert
{
"service": "elasticsearch",
"service_settings": {
"model_id": "sentence-transformers__msmarco-distilbert-base-tas-b",
"num_allocations": 1,
"num_threads": 1
}
}然后,我们使用如下的方法来创建嵌入:
POST _inference/distilbert
{
"input": "The sky above the port was the color of television tuned to a dead channel."
}
Huggingface
你需要在 huggingface 网站上使用自己的信用卡来创建一个端点,并且获取在该网站上的 API key。我们可以使用如下的方式来创建一个端点:
PUT _inference/text_embedding/hugging-face-embeddings
{
"service": "hugging_face",
"service_settings": {
"api_key": "Your Huggingface key",
"url": "Your endpoint"
}
}Alibaba
我在之前的文章 “Elasticsearch:使用阿里 infererence API 及 semantic text 进行向量搜索” 详述了如何创建阿里的嵌入及 completion 端点。这里就不再赘述了。
语义搜索示例
意图展示
PUT drink_dense_vectors
{
"mappings": {
"properties": {
"content": {
"type": "text",
"copy_to": "inference_field"
},
"inference_field": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
}
}在上面,我们定义了一个叫做 drink_dense_vectors 的索引。其它的有一个字段叫做 inference_field。它是 semantic_text 字段。semantic_text 是密集向量及稀疏向量的总称。在这里它表示的是由 E5 所定义的密集向量。接下来,我们写入如下的 3 个文档:
PUT drink_dense_vectors/_bulk
{"index": {"_id": "1"}}
{"content": "我想喝橙汁"}
{"index": {"_id": "2"}}
{"content": "我想要保时捷"}
{"index": {"_id": "3"}}
{"content": "我想看电影"}我们做如下的查询:
POST drink_dense_vectors/_search?filter_path=**.hits
{
"query": {
"match": {
"inference_field": "我想喝饮料"
}
}
}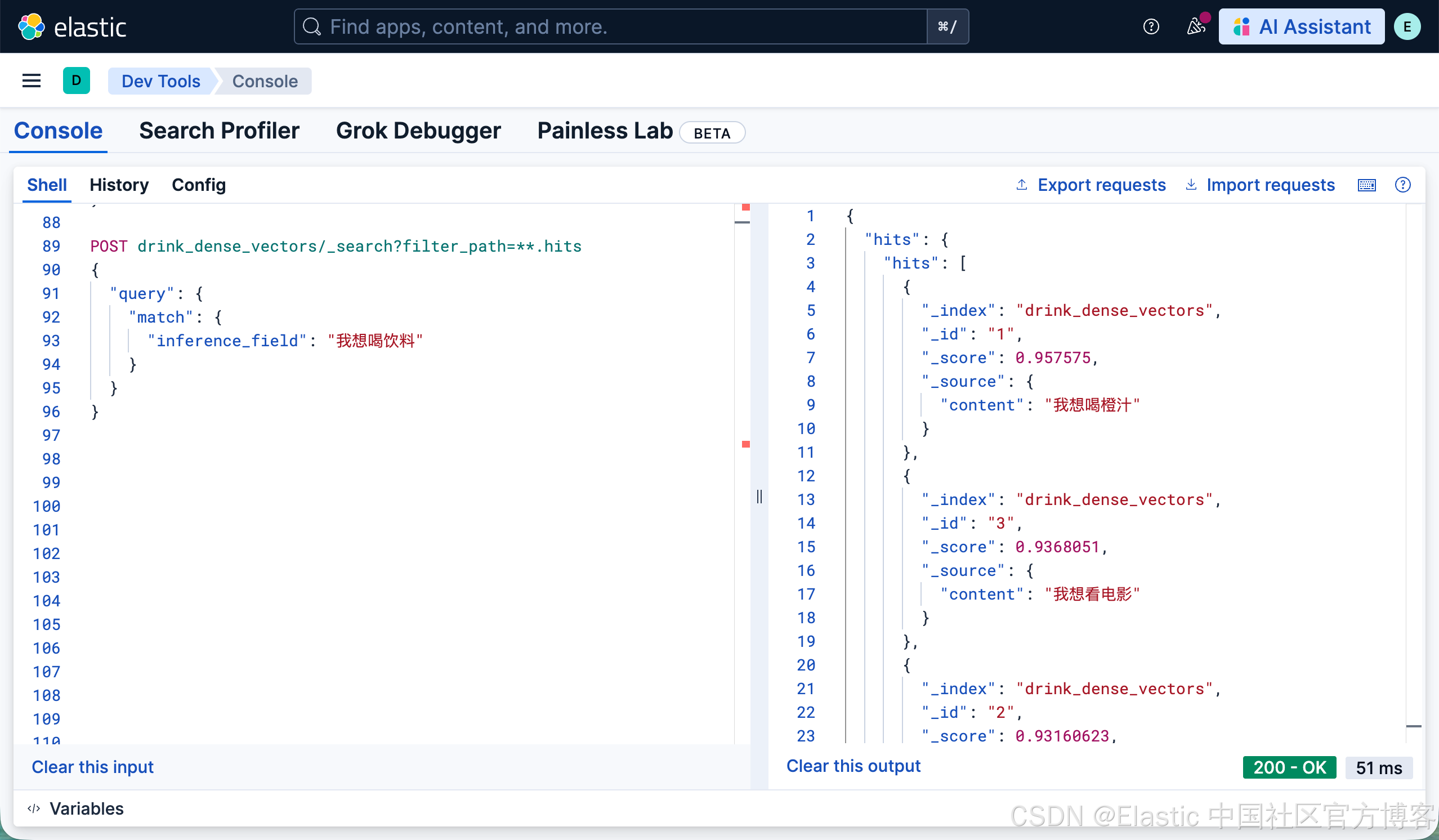
很显然橙汁是饮料的一种,那么最为匹配的就是 “我想喝橙汁”。我们接下来做如下的查询:
POST _query?format=csv
{
"query": """
FROM drink_dense_vectors METADATA _score
| WHERE MATCH(inference_field, "我想买一辆车")
| SORT _score DESC
| KEEP content
"""
}
很显然,在这里,我们可以看到最为匹配的结果就是 “我想要保时捷”。它的意思和 “我想买一辆车” 最为相似。
我们使用如下的命令来创建一个叫做 dense_vectors 的索引:
PUT dense_vectors
{
"mappings": {
"properties": {
"content": {
"type": "text",
"copy_to": "inference_field"
},
"inference_field": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
}
}我们使用如下的命令来创建两个文档:
PUT dense_vectors/_bulk
{"index": {"_id": "1"}}
{"content": "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"}
{"index": {"_id": "2"}}
{"content": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}我们使用如下的方式来进行搜索:
GET dense_vectors/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "腾讯是什么样的一家公司?"
}
}
}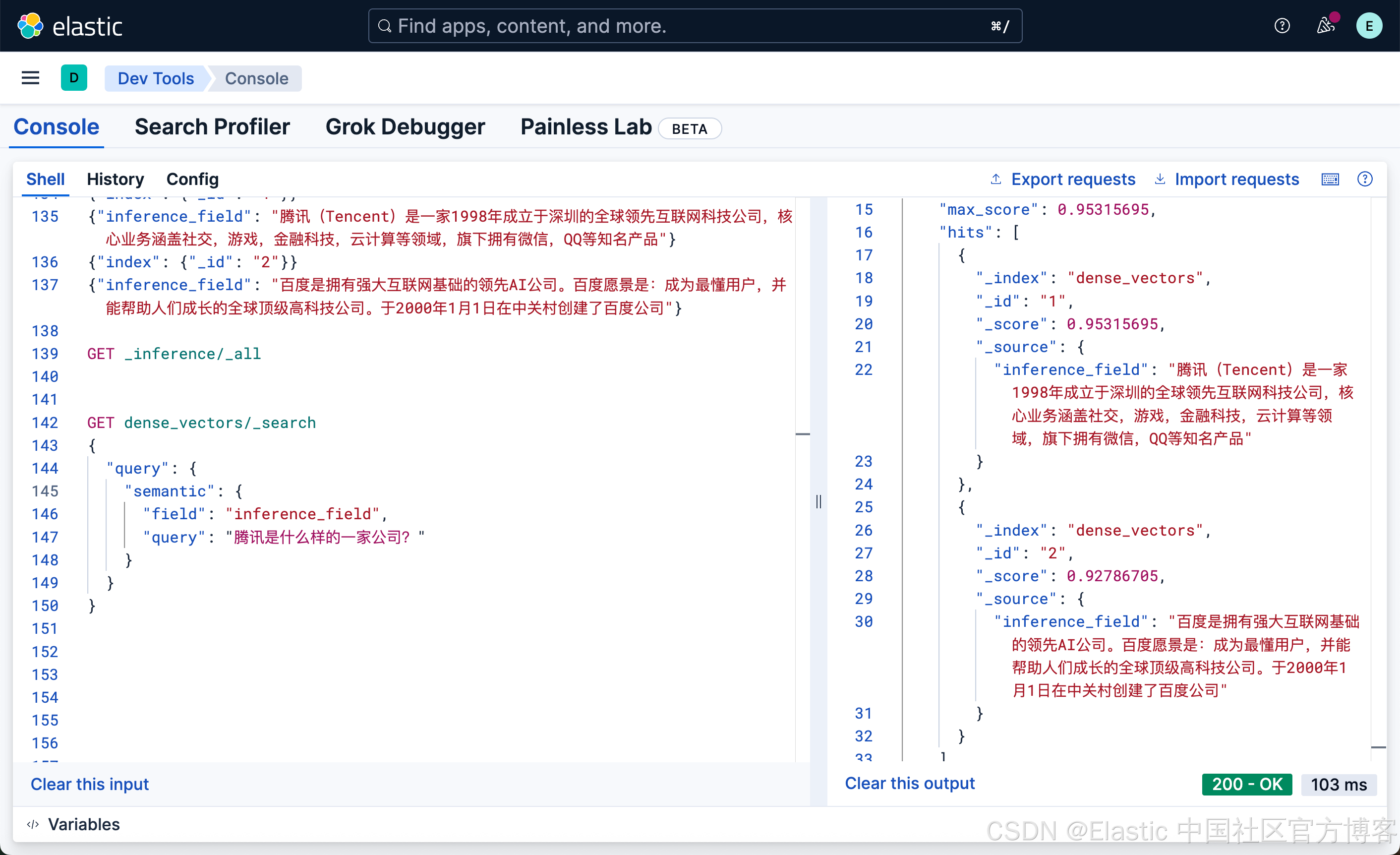
很显然,含有腾讯的文档排名是第一的,尽管百度的结果也出现了。因为我们只有两个文档,含有百度的文档的得分没有腾讯的高,所以排在第二位。
我们也可以使用如下的命令来进行搜索:
GET dense_vectors/_search
{
"query": {
"match": {
"inference_field": "腾讯是什么样的一家公司?"
}
}
}
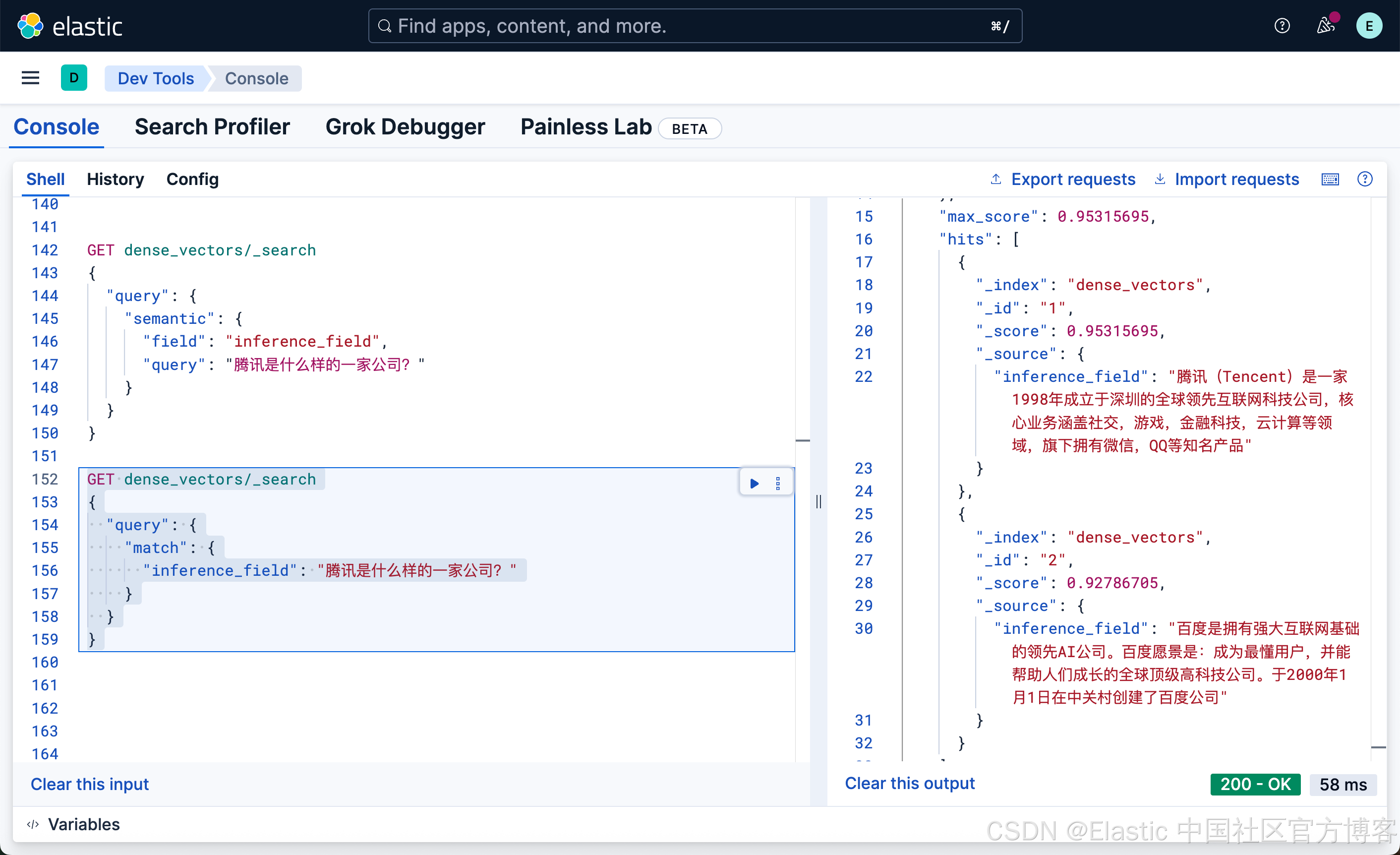
很显然,这种写法和我们之前的 DSL 的 match 写法没有任何的区别,尽管 inference_field 是一个向量字段。相比较之前的词汇搜索:
PUT lexical_index/_bulk
{"index": {"_id": "1"}}
{"text": "腾讯全称“深圳腾讯计算机系统有限公司”,由马化腾,张志东等五位创始人于1998年11月创立,总部位于中国深圳南山区。2004年数据显示,腾讯年营业额达6090亿元,员工超10.5万人,位列《财富》世界500强第141位"}
{"index": {"_id": "2"}}
{"text": "百度拥有数万名研发工程师,这是中国乃至全球都顶尖的技术团队。这支队伍掌握着世界上领先的搜索引擎技术,使百度成为美国,俄罗斯和韩国之外,全球仅有的4个拥有搜索引擎核心技术的国家之一"}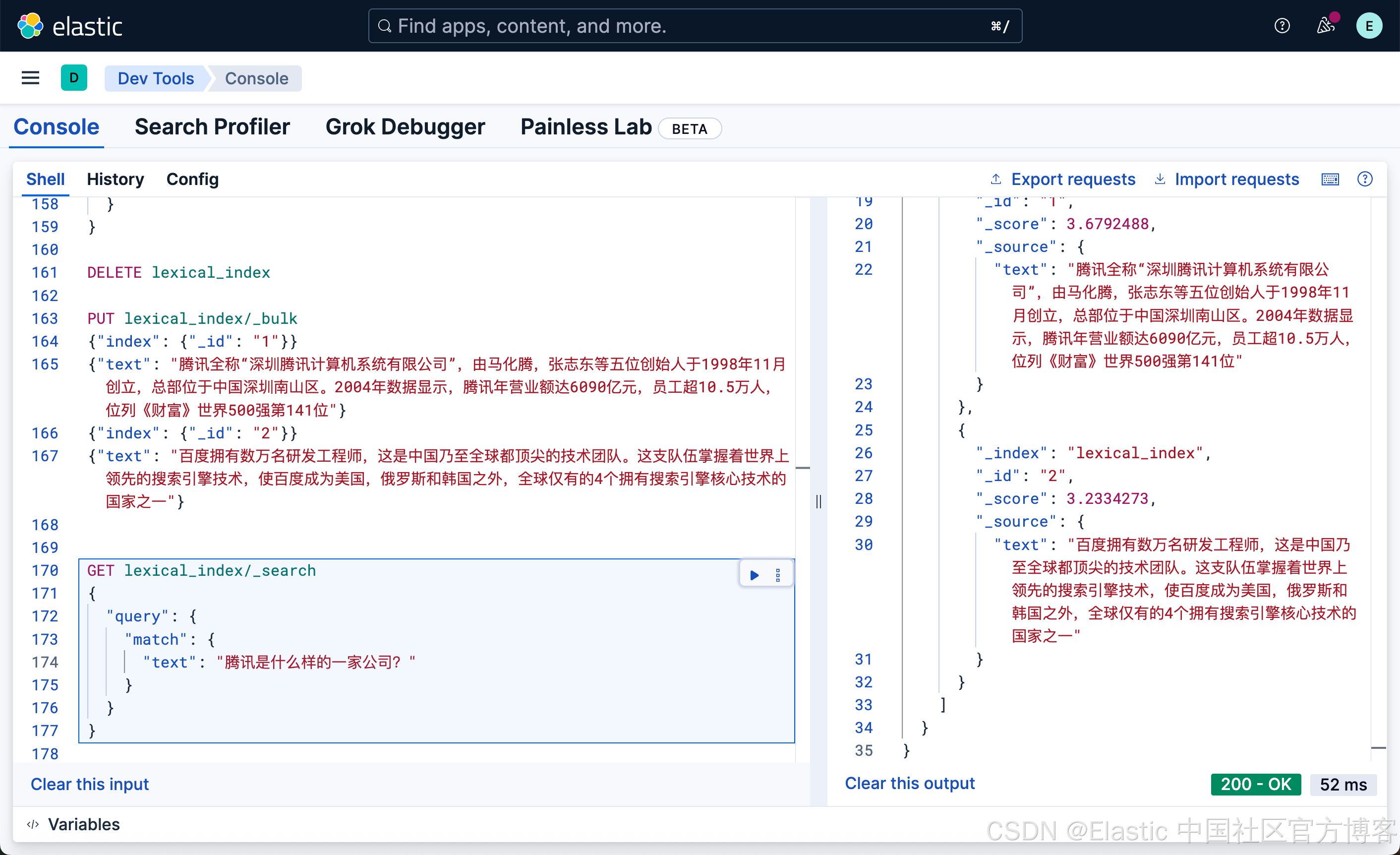
我们还可以使用 ES|QL 来实现向量字段的搜索:
POST _query?format=txt
{
"query": """
FROM dense_vectors METADATA _score
| WHERE inference_field : "Baidu 是什么样的公司?"
| SORT _score DESC
"""
}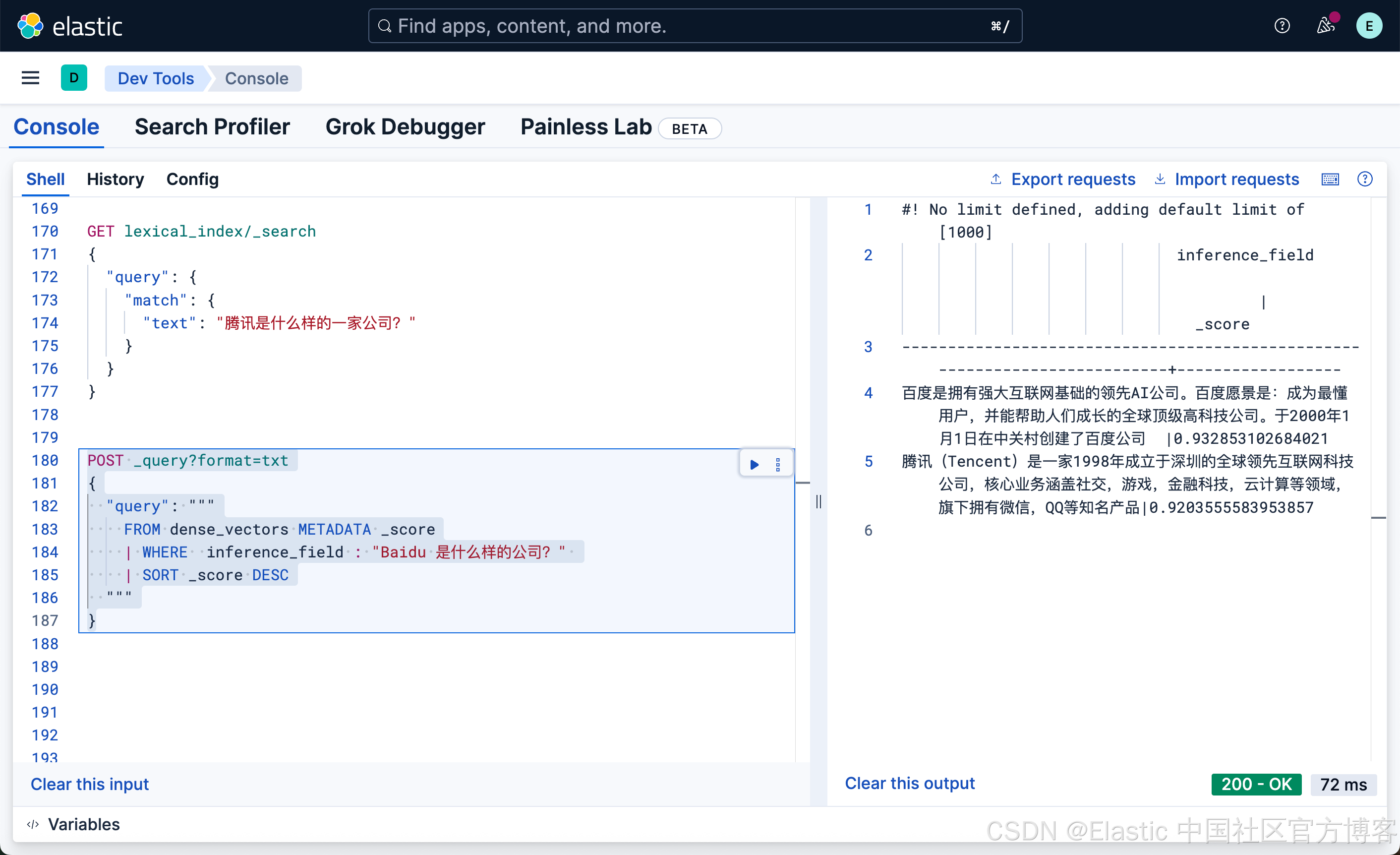
这次我们搜索的结果,百度排名第一,但是细心的开发者可能会发现我们原来的文本中并不含有 Baidu 这样的英文单词?那么它是怎么做到的呢?其实 E5 模型是一个多语言的模型,它可以针对多国语言进行搜索。
如果按照我们之前的词汇搜索,那么我们可能是不能搜索到任何的结果:
GET dense_vectors/_search
{
"query": {
"match": {
"content": "Baidu"
}
}
}我们还可以尝试如下的搜索:
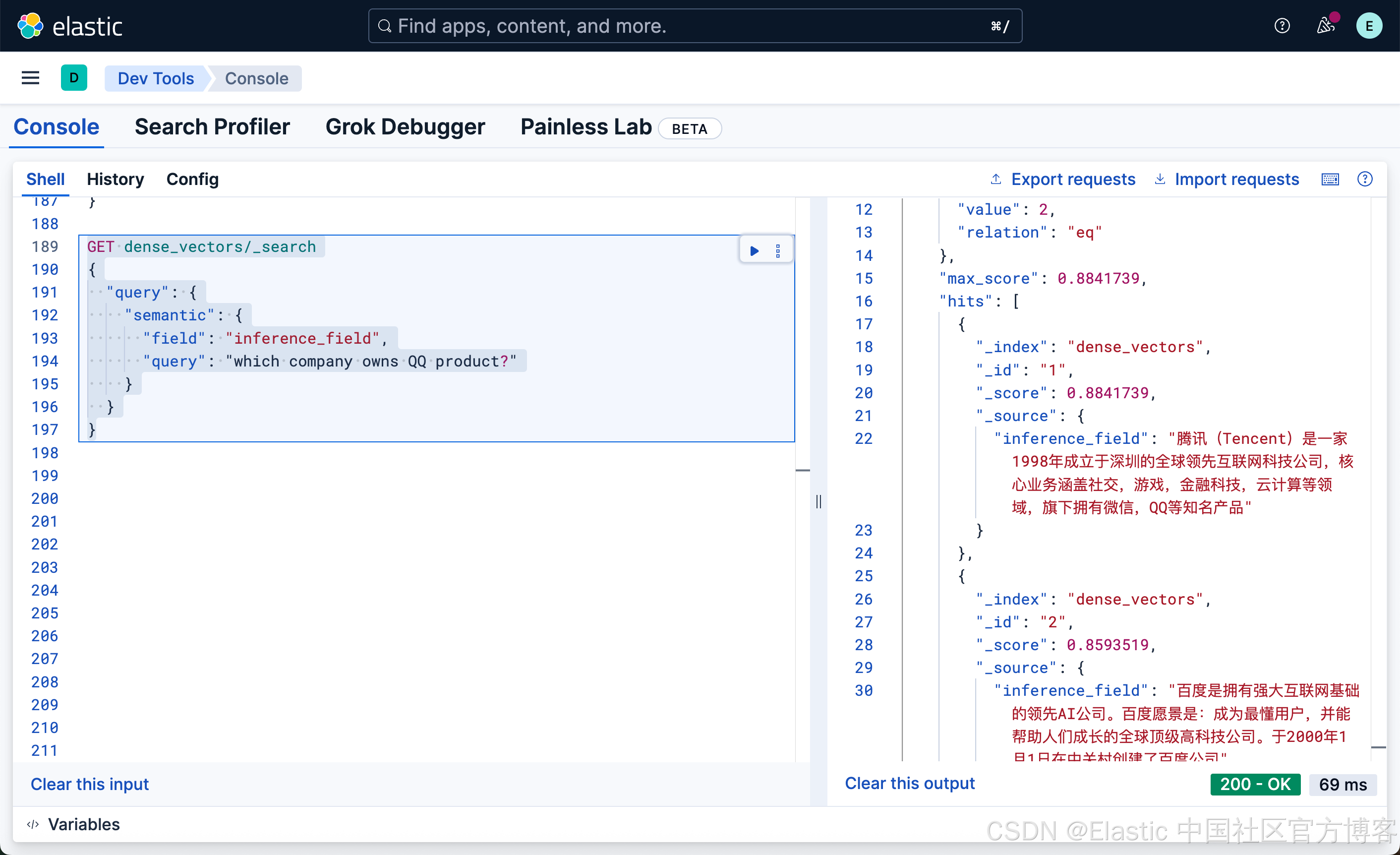
GET dense_vectors/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "which company owns QQ product?"
}
}
}
GET dense_vectors/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "which company has the chat product?"
}
}
}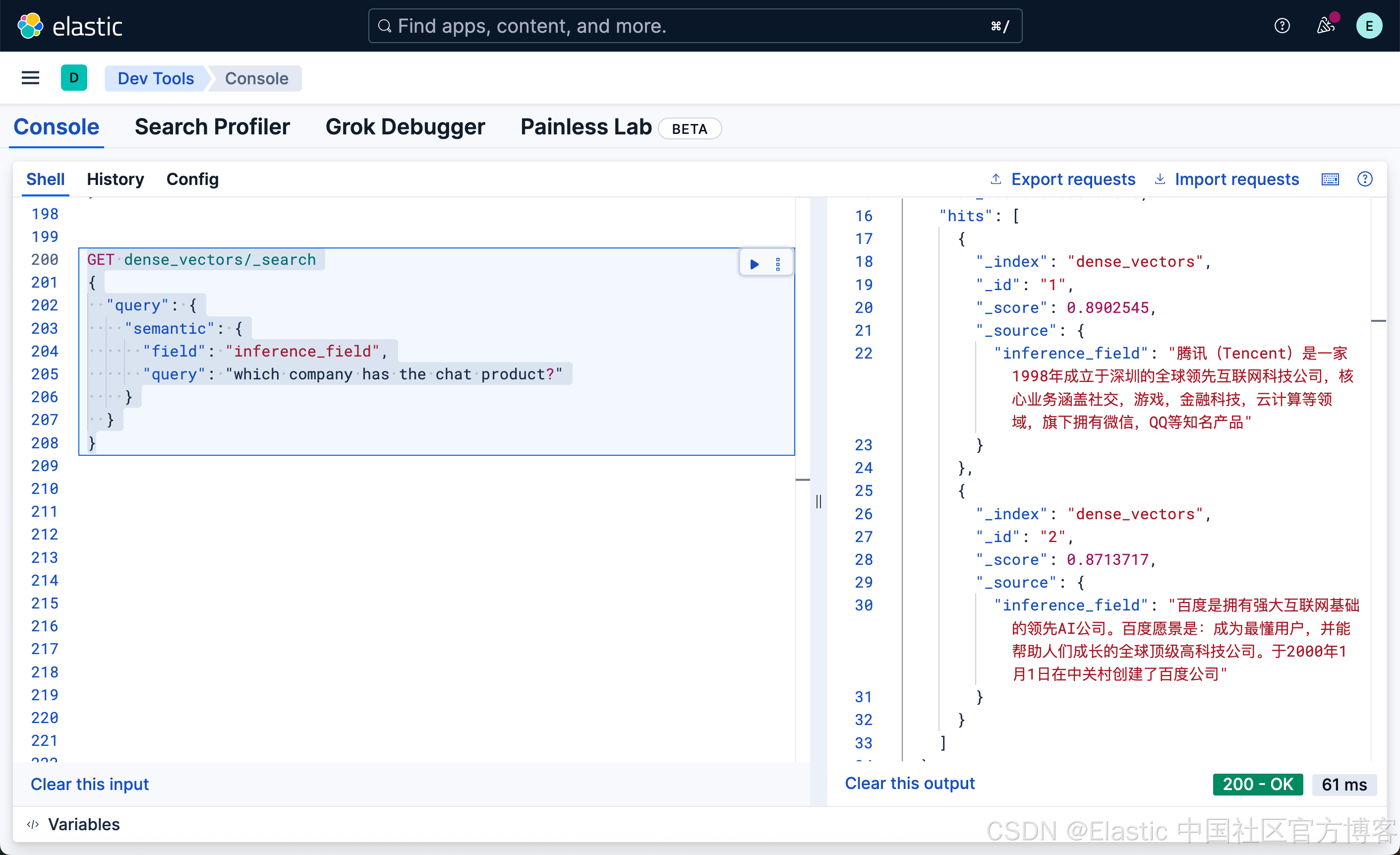
很显然,我们的文档中并没有含有聊天这样的词汇,但是我们使用英文搜索 chat 这样的词,它也能帮我们找到腾讯微第一。我们甚至可以使用日文来进行搜索:
GET dense_vectors/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "チャット製品を提供している会社はどれですか?"
}
}
}
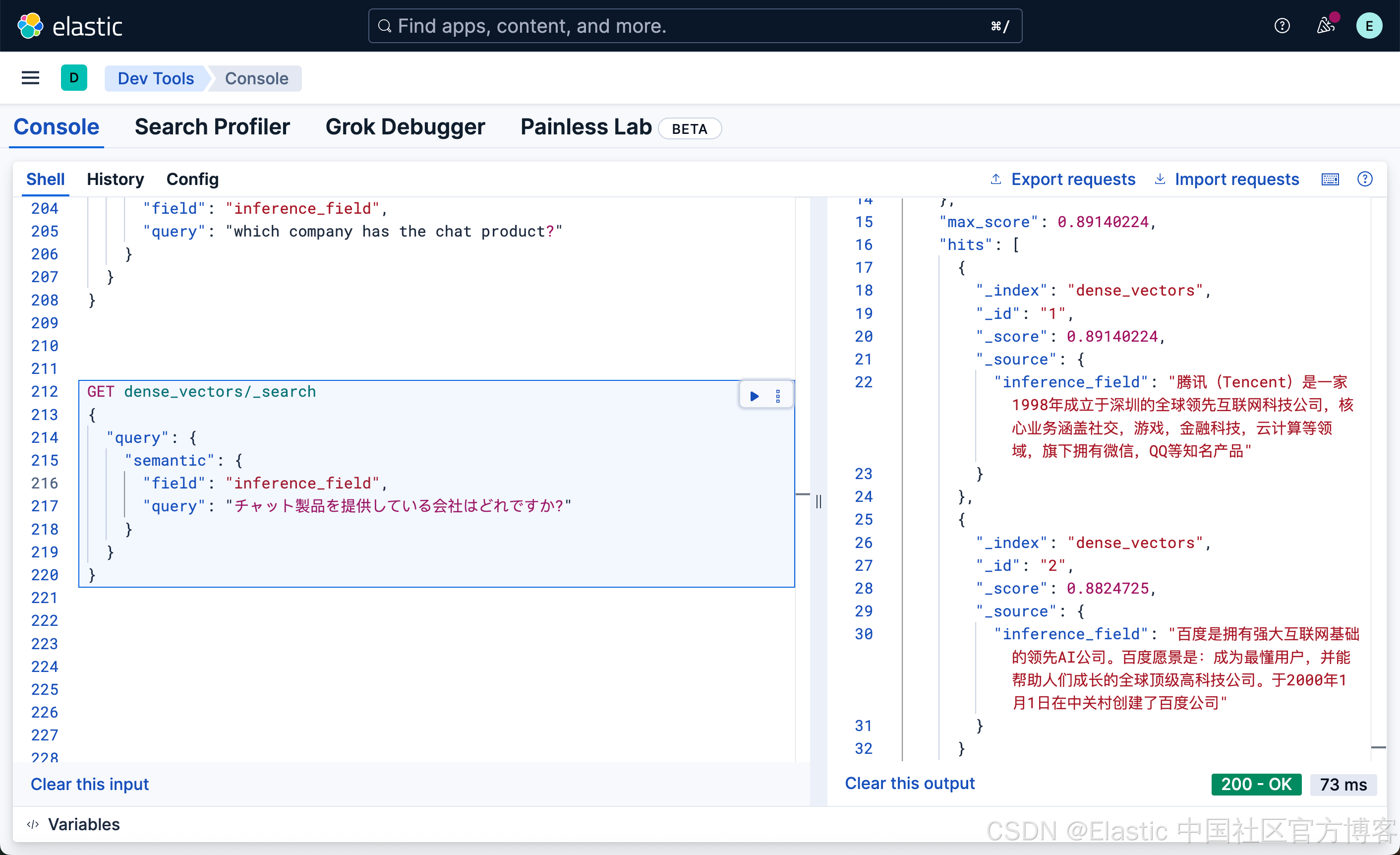
我们可以看出来,使用日文也可以搜素出我们想要的结果。
我们再看看如下的搜索结果:
GET dense_vectors/_search
{
"query": {
"match": {
"inference_field": "中国的搜索公司是哪个?"
}
}
}
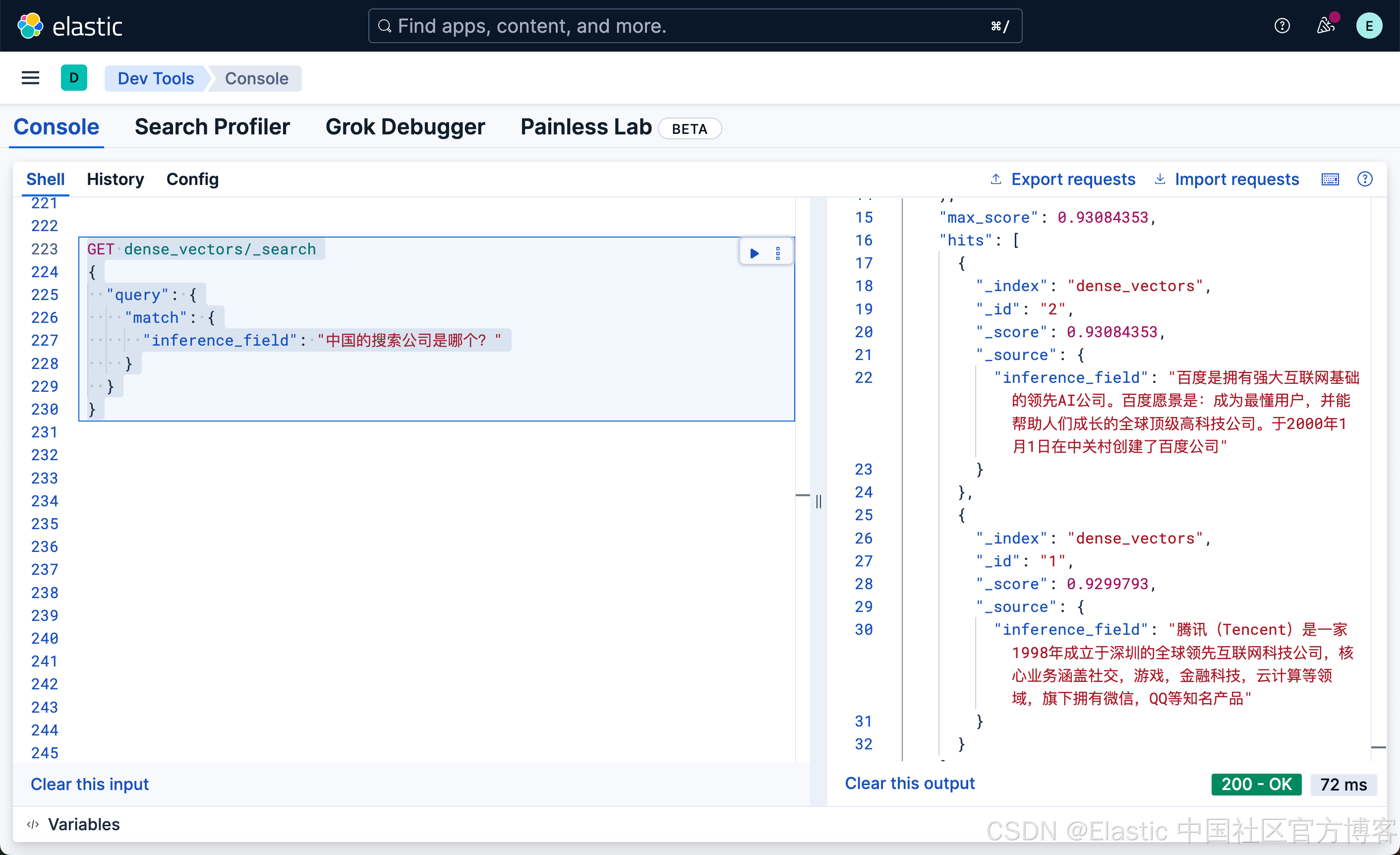
大家如果查看我们的文档,有关百度的文档中 “百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司”,它并不含有任何的搜索关键词,但是我们提问 “中国的搜索公司是哪个”,百度的结果排名为第一。这个也许就是语义搜索的魅力吧!
GET dense_vectors/_search
{
"query": {
"match": {
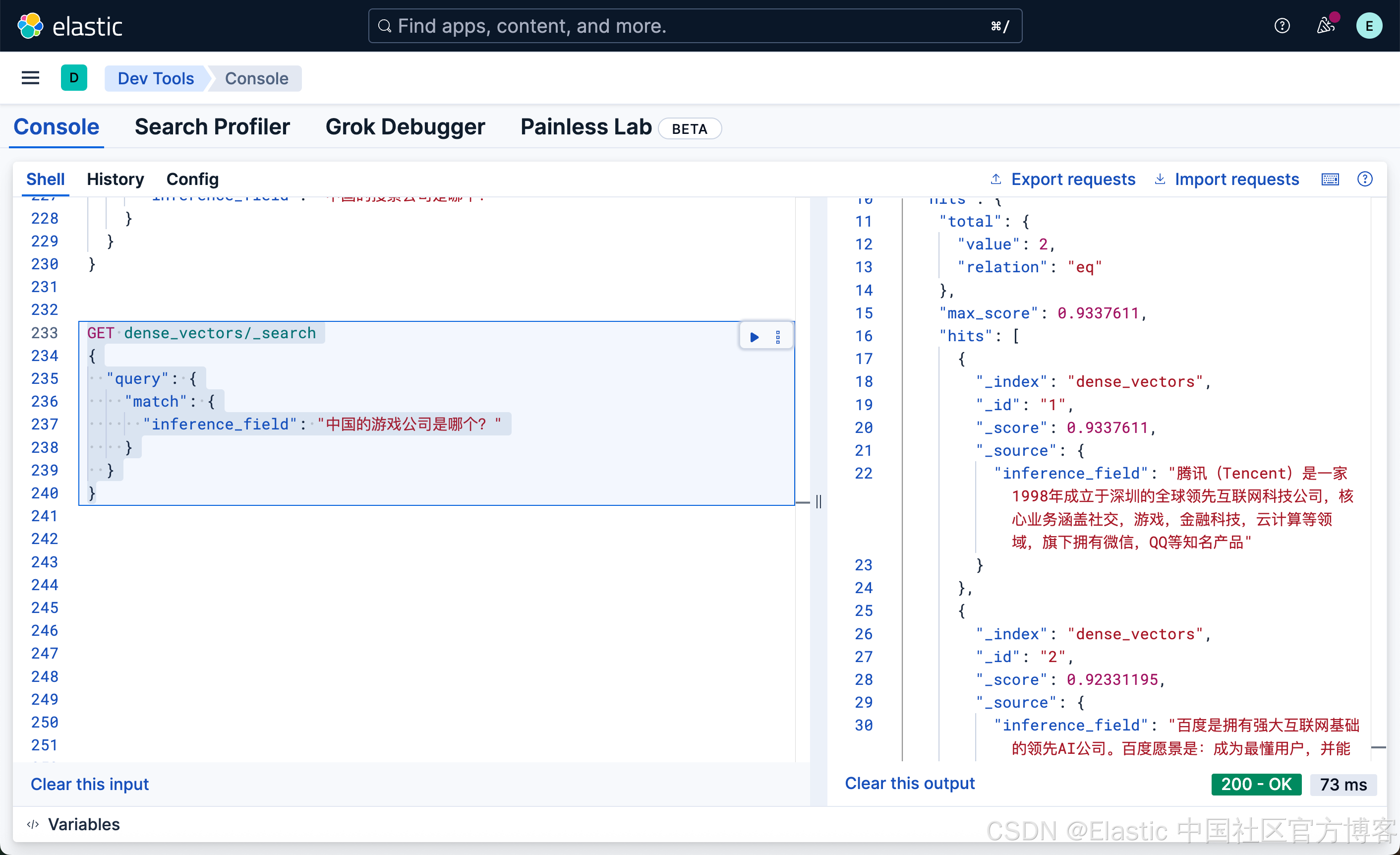
"inference_field": "中国的游戏公司是哪个?"
}
}
}
GET dense_vectors/_search
{
"query": {
"match": {
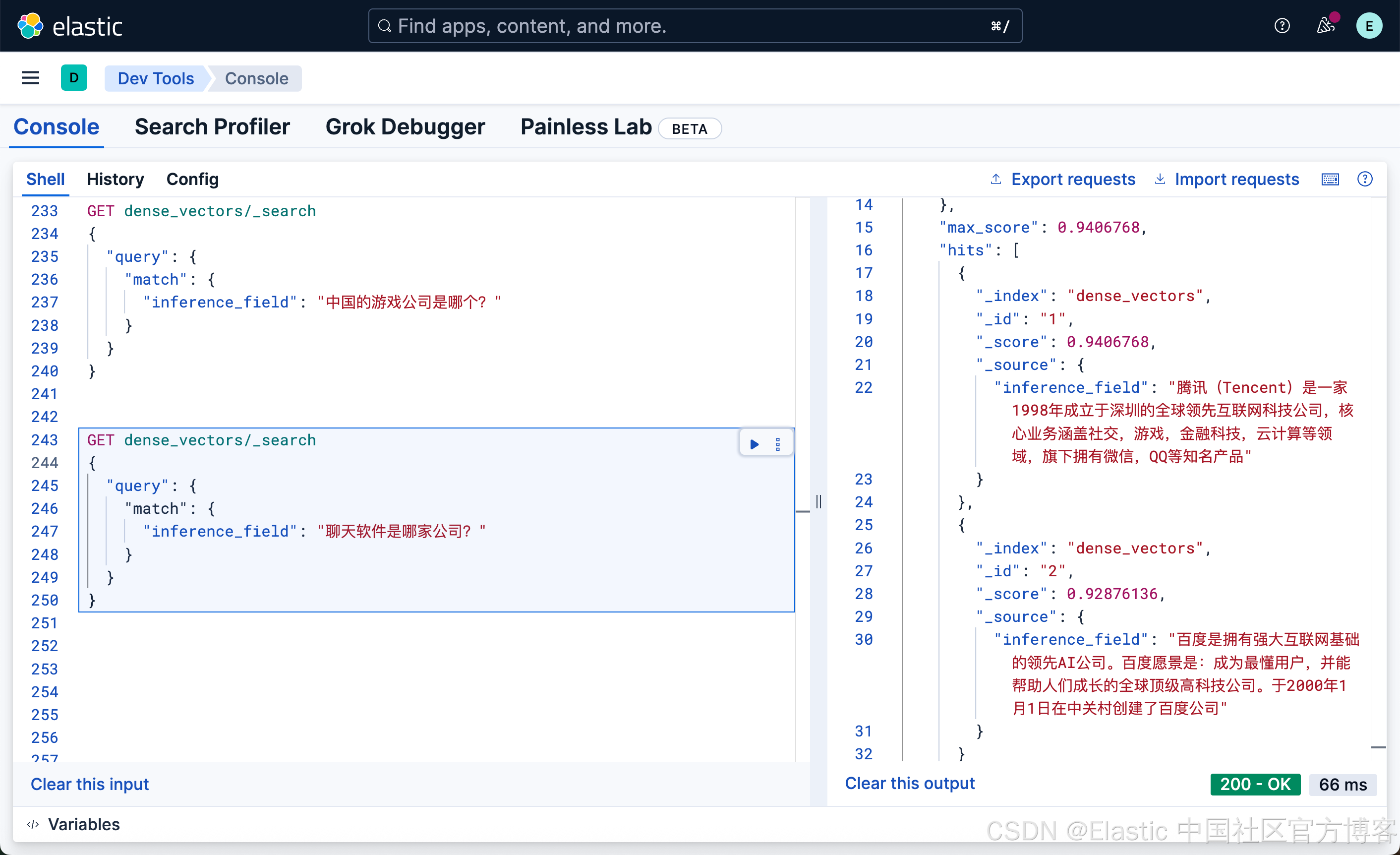
"inference_field": "聊天软件是哪家公司?"
}
}
}
使用 ES|QL 进行推理
我们可以针对上面的数据来做如下的查询并推理:
POST _query?format=txt
{
"query": """
FROM dense_vectors METADATA _score
| WHERE MATCH(inference_field, ?query)
| SORT _score DESC
| LIMIT 1
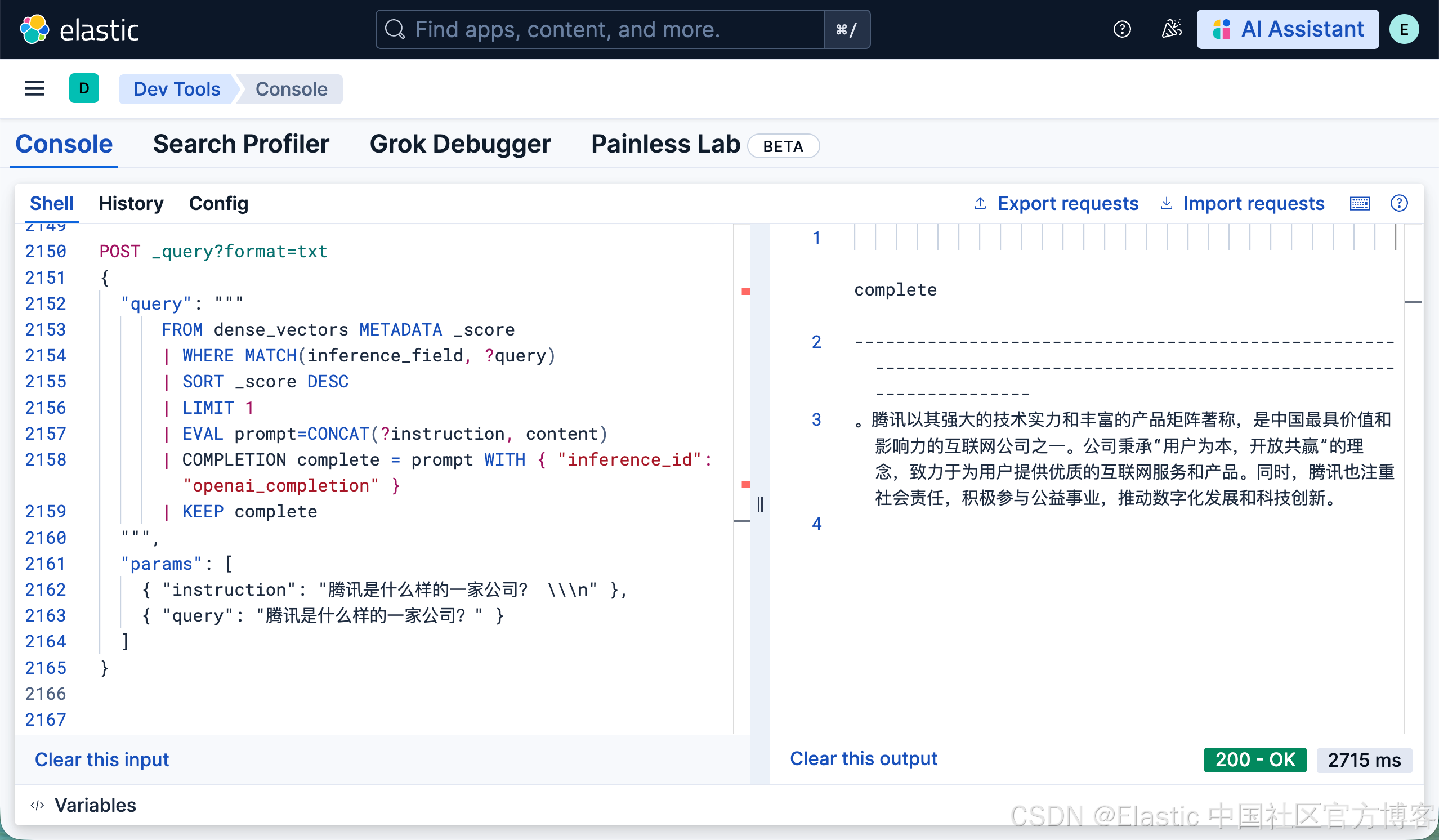
| EVAL prompt=CONCAT(?instruction, content)
| COMPLETION complete = prompt WITH { "inference_id": "openai_completion" }
| KEEP complete
""",
"params": [
{ "instruction": "Where was tencent founded \\\n" },
{ "query": "腾讯是什么样的一家公司?" }
]
}如上所示,我们需要创建推理端点 openai_completion。然后针对 “腾讯是什么样的一家公司?” 进行搜索,并把它的结果进行推理:
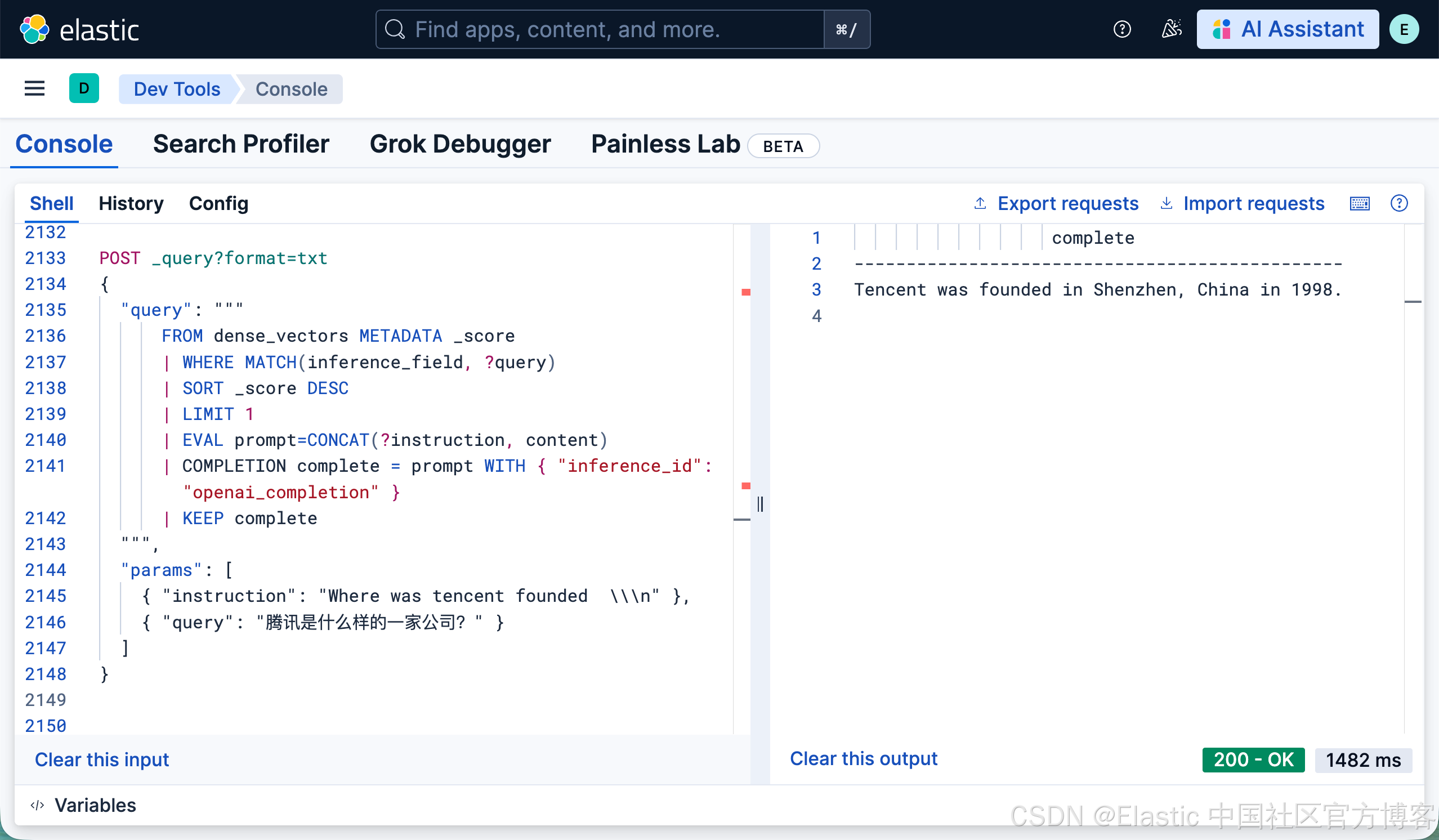
我们也可以使用中文进行提问:
POST _query?format=txt
{
"query": """
FROM dense_vectors METADATA _score
| WHERE MATCH(inference_field, ?query)
| SORT _score DESC
| LIMIT 1
| EVAL prompt=CONCAT(?instruction, content)
| COMPLETION complete = prompt WITH { "inference_id": "openai_completion" }
| KEEP complete
""",
"params": [
{ "instruction": "腾讯是什么样的一家公司? \\\n" },
{ "query": "腾讯是什么样的一家公司?" }
]
}
POST _query?format=txt
{
"query": """
FROM dense_vectors METADATA _score
| WHERE MATCH(inference_field, ?query)
| SORT _score DESC
| KEEP content
| LIMIT 1
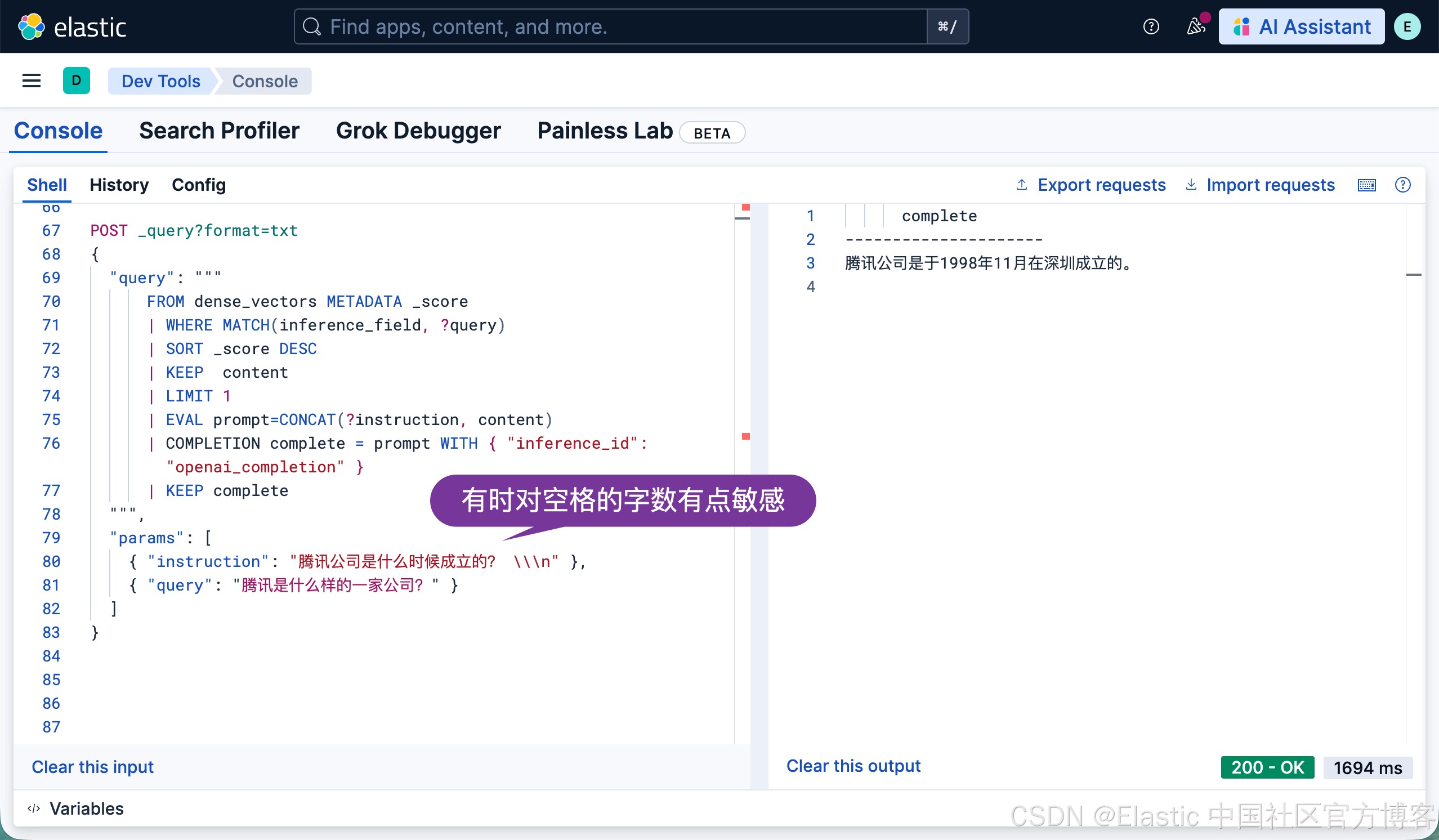
| EVAL prompt=CONCAT(?instruction, content)
| COMPLETION complete = prompt WITH { "inference_id": "openai_completion" }
| KEEP complete
""",
"params": [
{ "instruction": "腾讯公司是什么时候成立的? \\\n" },
{ "query": "腾讯是什么样的一家公司?" }
]
}
我们也可以把自己的数据这样来测试:
POST _query?format=txt
{
"query": """
ROW content = "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"
| LIMIT 1
| EVAL prompt=CONCAT(?instruction, content)
| COMPLETION complete = prompt WITH { "inference_id": "openai_completion" }
| KEEP complete
""",
"params": [
{ "instruction": "腾讯是什么时候成立的? \\\n" },
{ "query": "腾讯是什么样的一家公司?" }
]
}上面的测试对应于如下的 DSL 查询:
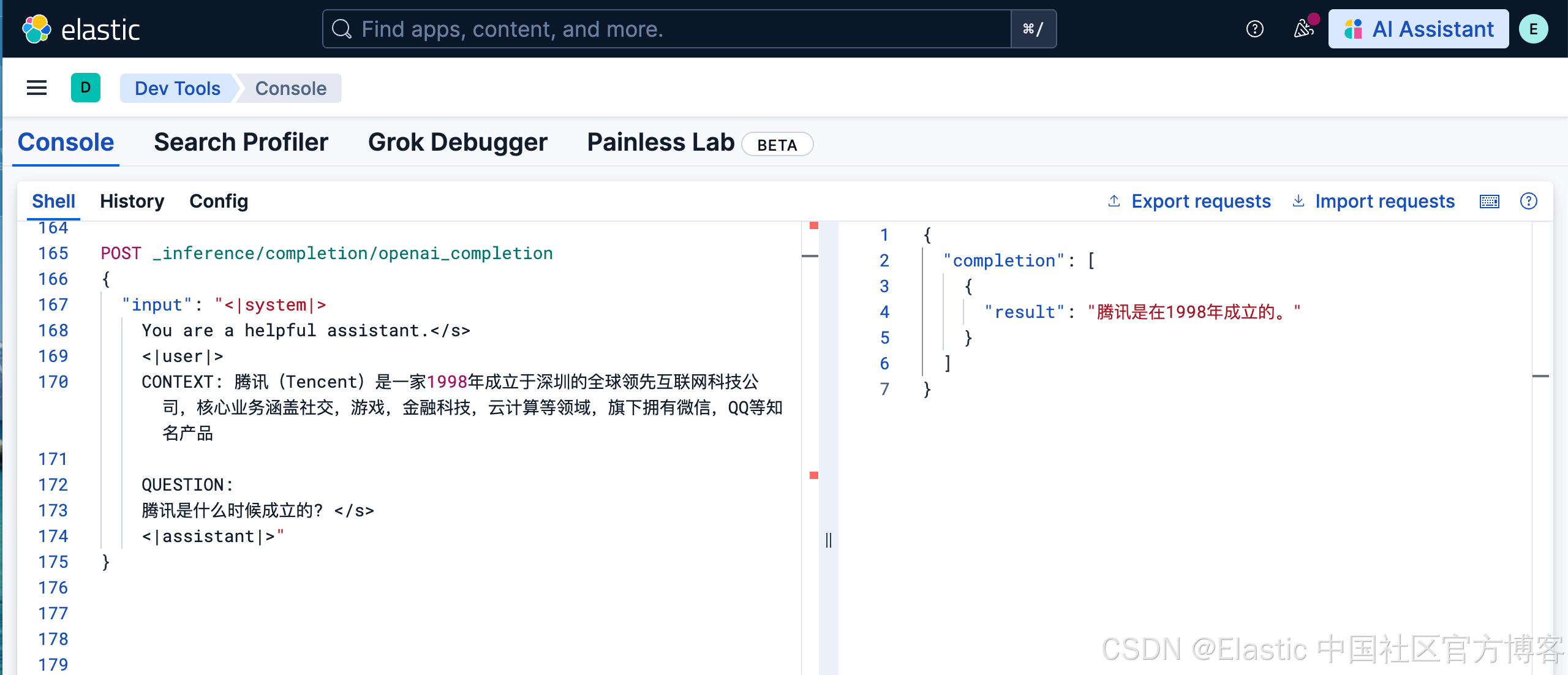
POST _inference/completion/openai_completion
{
"input": "<|system|>
You are a helpful assistant.</s>
<|user|>
CONTEXT: 腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品
QUESTION:
腾讯是什么时候成立的? </s>
<|assistant|>"
}
混合搜索
我们知道,单纯的语义搜索有时并不能完全提高我们的召回率及相关性,甚至有时搜索的结果不具有可解释性。我们可以使用混合搜索的方法来提高相关性及召回率。
方法一
我们可以定义如下的索引:
PUT my_index
{
"mappings": {
"properties": {
"text": {
"type": "text" // raw document text
},
"embedding.predicted_value": {
"type": "dense_vector",
"dims": 384, // E5-small output dim is 384
"index": true, // enable ANN search
"similarity": "cosine" // consine similarity for semantic search
}
}
}
}然后我们定义一个如下的 pipeline:
PUT _ingest/pipeline/e5-embedding-pipeline
{
"processors": [
{
"inference": {
"model_id": ".multilingual-e5-small-elasticsearch",
"target_field": "embedding",
"field_map": {
"text": "text_field"
}
}
}
]
}我们为 my_index 创建索引文档:
PUT my_index/_bulk?pipeline=e5-embedding-pipeline
{"index": {"_id": "1"}}
{"text": "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"}
{"index": {"_id": "2"}}
{"text": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}我们可以使用如下的方法来进行混合搜索:
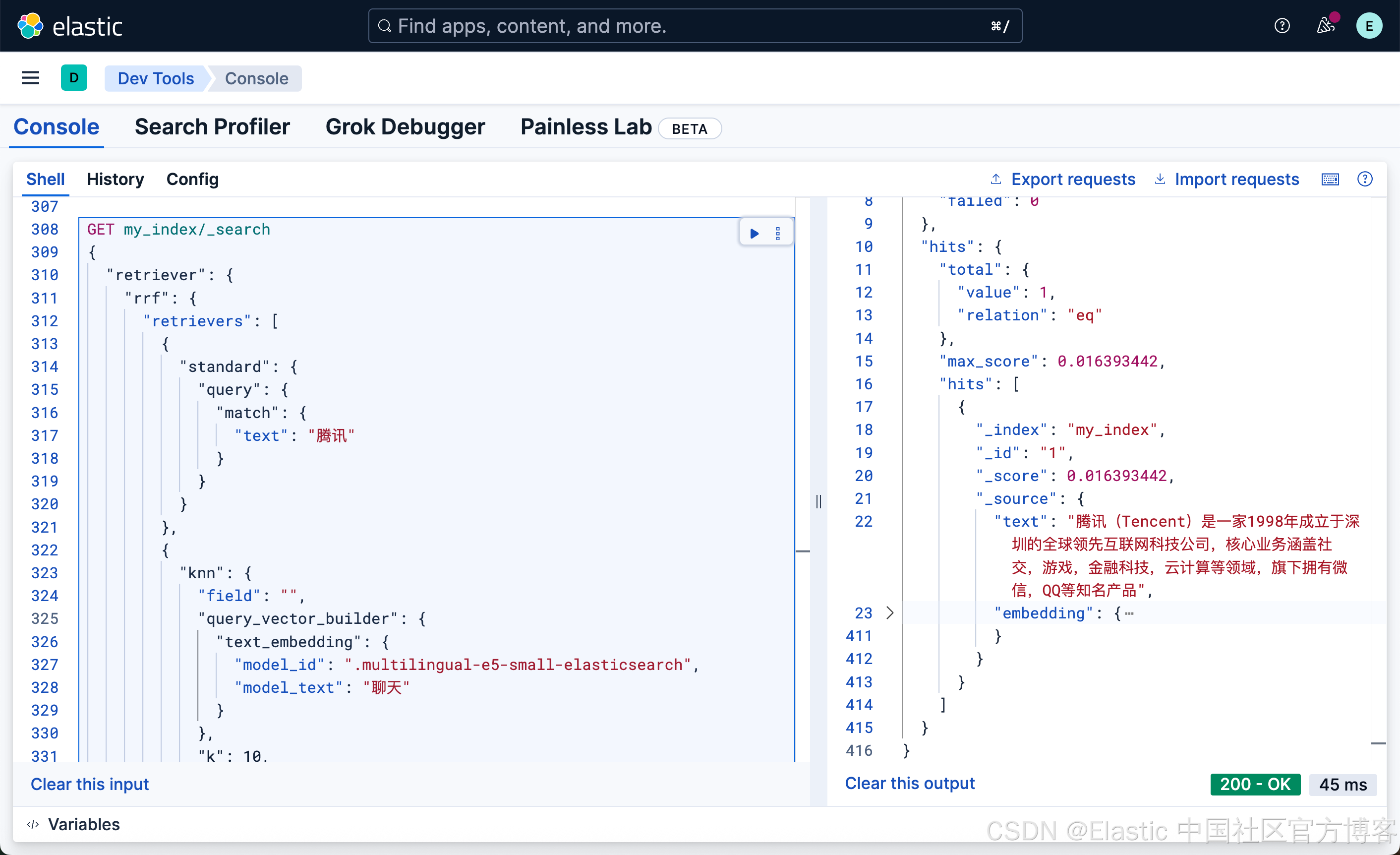
GET my_index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": "腾讯"
}
}
}
},
{
"knn": {
"field": "",
"query_vector_builder": {
"text_embedding": {
"model_id": ".multilingual-e5-small-elasticsearch",
"model_text": "聊天"
}
},
"k": 10,
"num_candidates": 100
}
}
]
}
}
}
方法二
这个方法更为简单。我们定义如下的一个索引:
PUT hybrid_vectors
{
"mappings": {
"properties": {
"inference_field": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
},
"content":{
"type": "text",
"copy_to": "interence_field"
}
}
}
}我们使用如下的命令来写入文档:
PUT hybrid_vectors/_bulk
{"index": {"_id": "1"}}
{"content": "腾讯(Tencent)是一家1998年成立于深圳的全球领先互联网科技公司,核心业务涵盖社交,游戏,金融科技,云计算等领域,旗下拥有微信,QQ等知名产品"}
{"index": {"_id": "2"}}
{"content": "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"}我们使用如下的方法来做混合搜索:
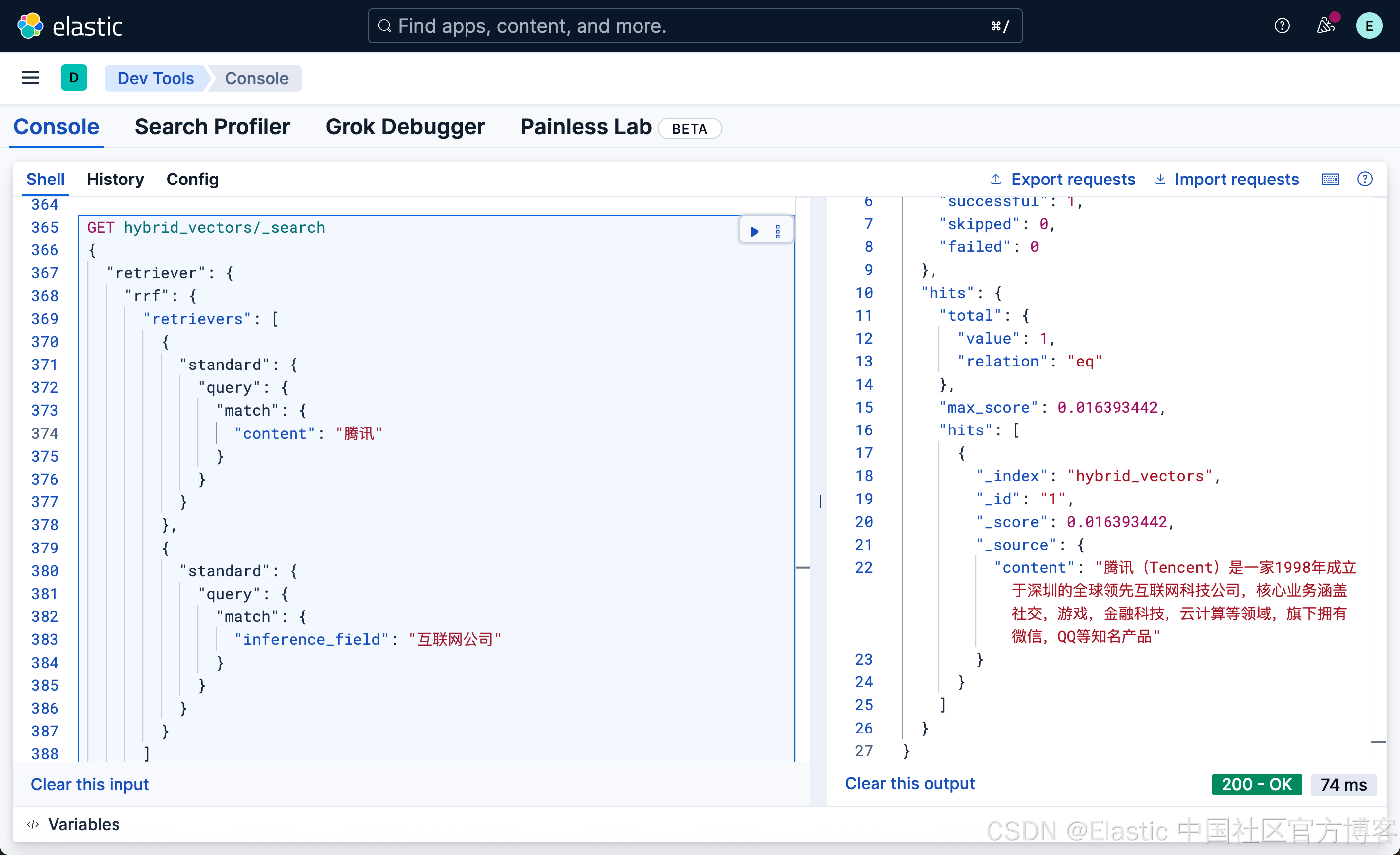
GET hybrid_vectors/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"content": "腾讯"
}
}
}
},
{
"standard": {
"query": {
"match": {
"inference_field": "互联网公司"
}
}
}
}
]
}
}
}
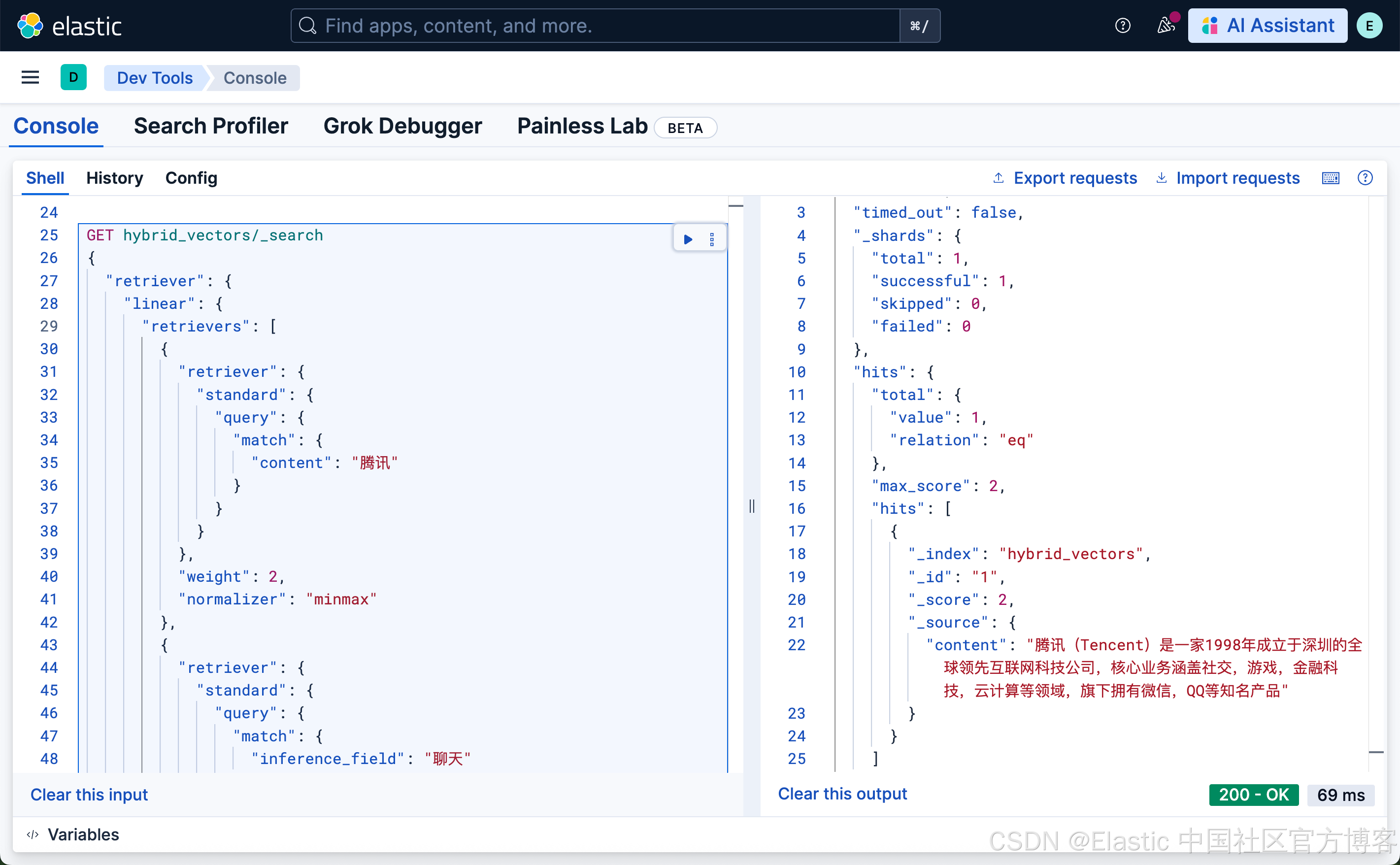
除了上面的 rrf 混合搜索,我们也可以使用线性混合搜索:
GET hybrid_vectors/_search
{
"retriever": {
"linear": {
"retrievers": [
{
"retriever": {
"standard": {
"query": {
"match": {
"content": "腾讯"
}
}
}
},
"weight": 2,
"normalizer": "minmax"
},
{
"retriever": {
"standard": {
"query": {
"match": {
"inference_field": "聊天"
}
}
}
},
"weight": 1.5,
"normalizer": "minmax"
}
]
}
}
}
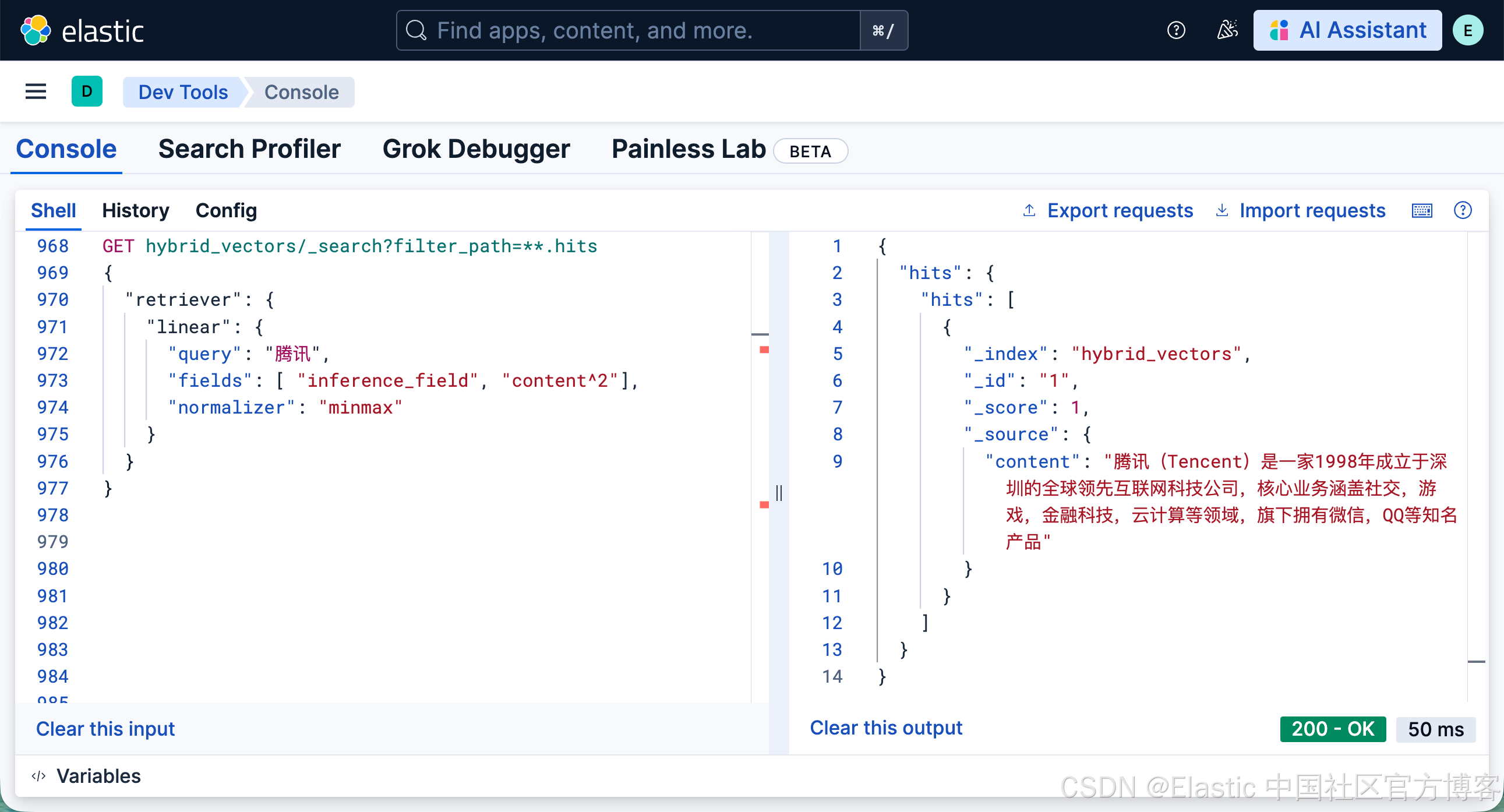
参考文章 “混合搜索无需头疼:使用 retrievers 简化混合搜索”,我们可以更进一步简化为:
GET hybrid_vectors/_search
{
"retriever": {
"linear": {
"query": "腾讯",
"fields": [ "inference_field", "content^2"],
"normalizer": "minmax"
}
}
}
方法三
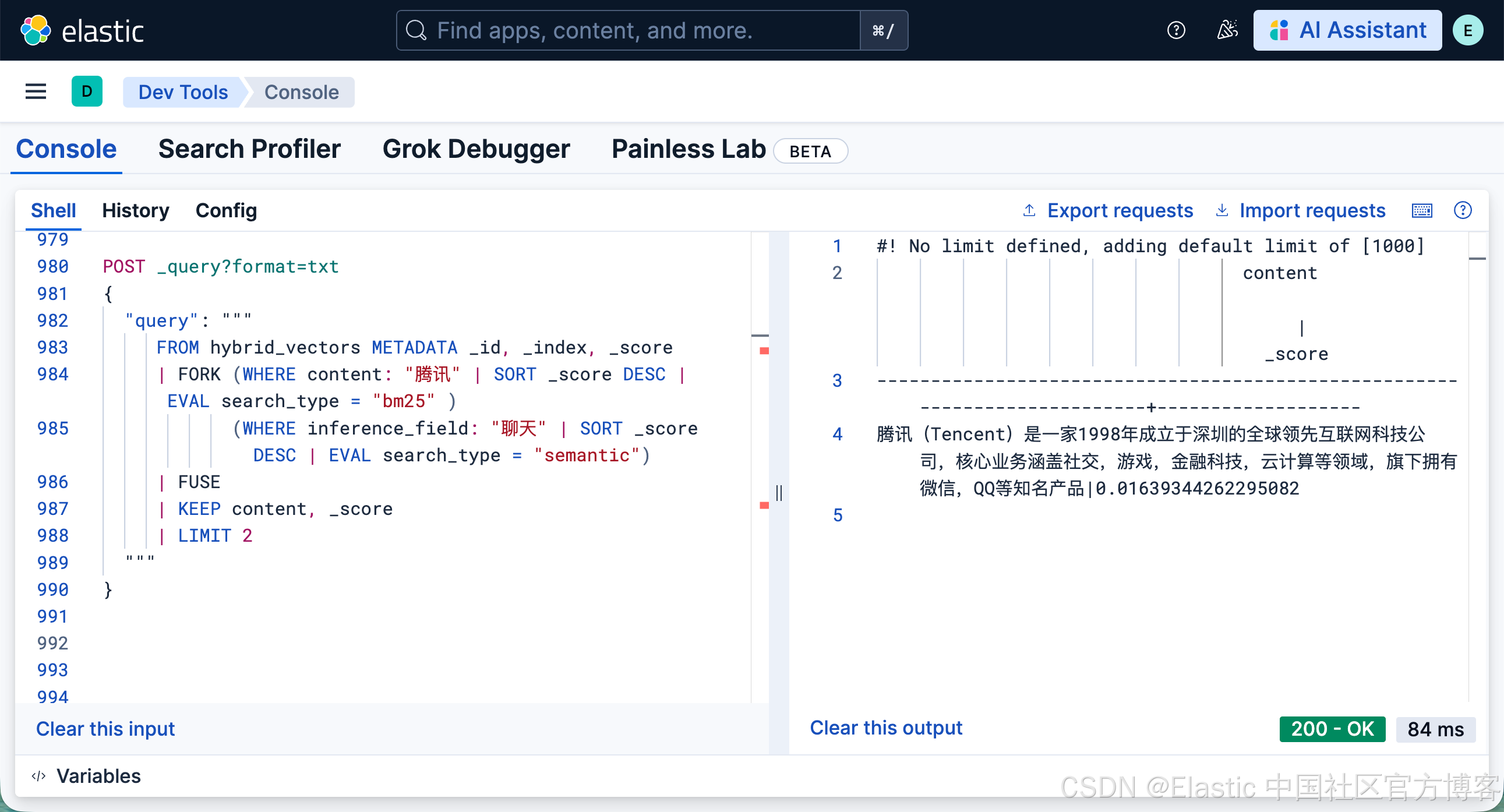
我们可以使用 ES|QL 的方法。参考文章 “Elasticsearch:如何在 ES|QL 中使用 FORK 及 FUSE 命令来实现混合搜索 - 9.1+”。我们可以使用如下的方法来做混合搜索:
POST _query?format=txt
{
"query": """
FROM hybrid_vectors METADATA _id, _index, _score
| FORK (WHERE content: "腾讯" | SORT _score DESC | EVAL search_type = "bm25" )
(WHERE inference_field: "聊天" | SORT _score DESC | EVAL search_type = "semantic")
| FUSE
| KEEP content, _score
| LIMIT 2
"""
}
长文档展示
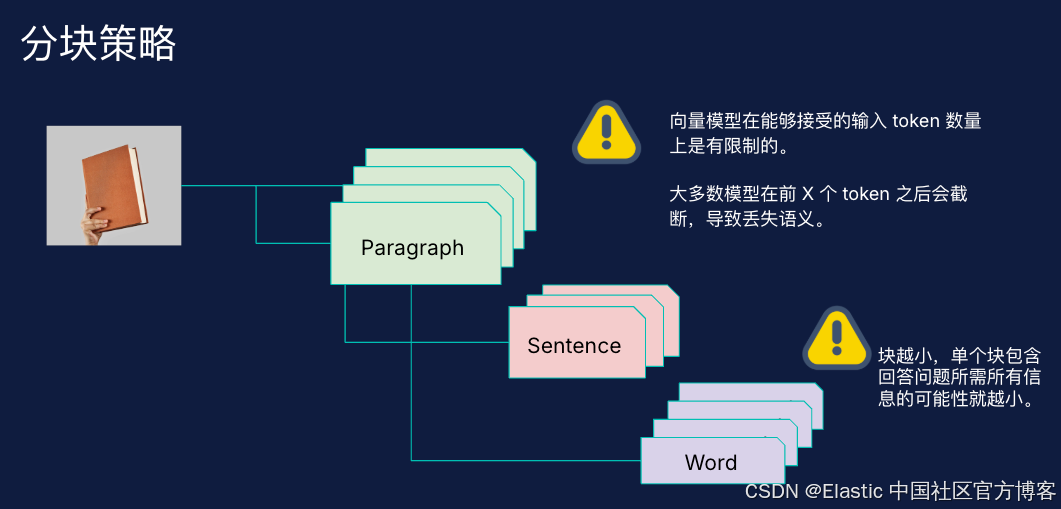
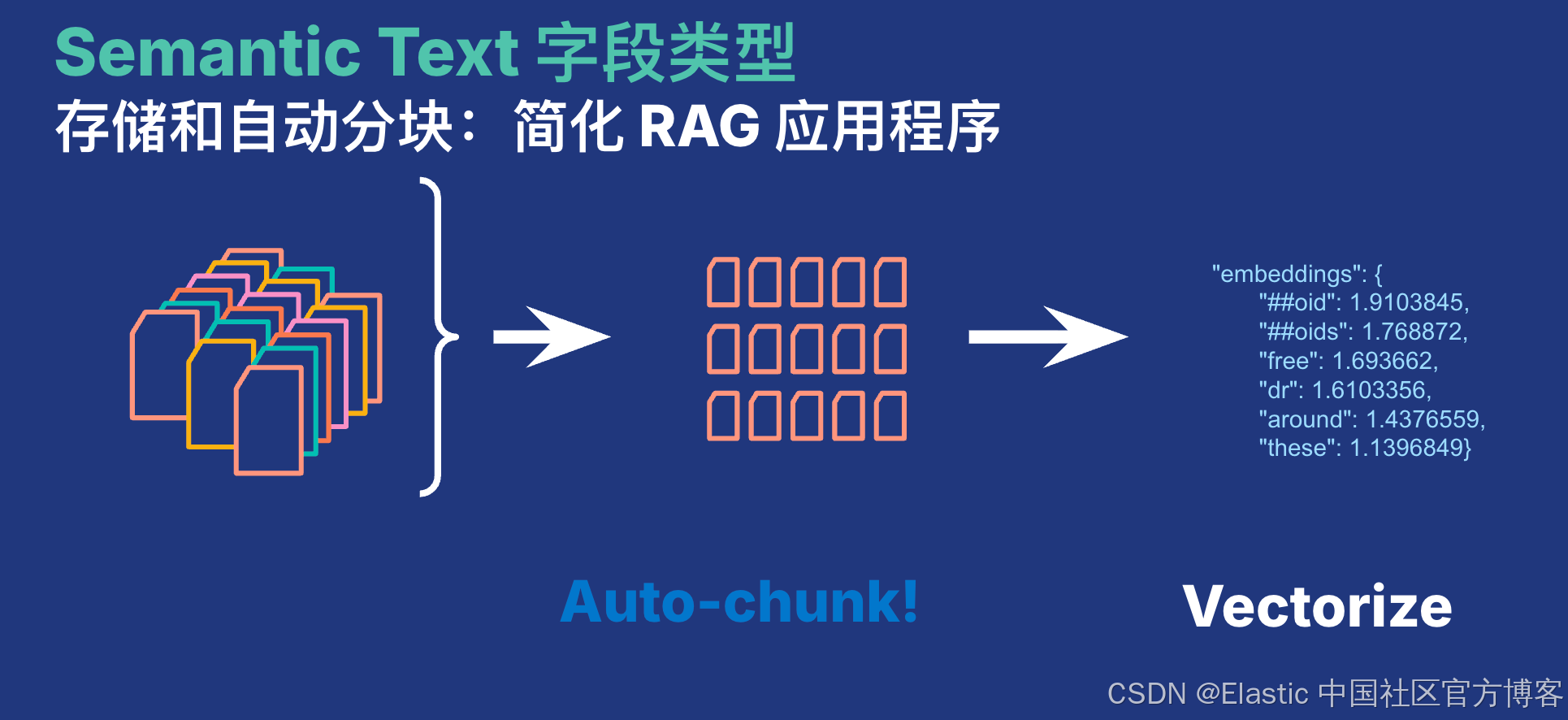
在很多的情况下,我们的文档超过嵌入模型要求的最长长度。下面我们使用 semantic_text 来展示它是如何帮我们自动分块的。
我们定义创建如下的一个索引:
PUT longtext-semantic-index
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
}
}我们写入如下的文档:
PUT longtext-semantic-index/_doc/1
{
"content": "百度公司成立于2000年1月,由李彦宏和徐勇在北京创办,是中国乃至全球领先的互联网和人工智能技术公司之一。作为中国最早、最具代表性的搜索引擎企业,百度最初以中文网页搜索业务起家,为用户提供高效、精准的互联网信息检索服务。经过二十多年的发展,百度已经从单一的搜索引擎公司成长为以人工智能为核心驱动力的综合性科技集团,其业务涵盖搜索服务、在线广告、云计算、智能交通、自动驾驶、人工智能芯片、大模型以及智能终端等多个领域。百度的核心产品“百度搜索”长期占据中国搜索市场的主导地位,是国内网民获取信息的重要入口。百度通过自主研发的网页爬虫、自然语言处理和排序算法,不断提升搜索结果的相关性与准确性。除网页搜索外,百度还提供图片搜索、视频搜索、新闻搜索、地图搜索、百科、贴吧、知道、文库等多样化的内容和社区服务,这些产品共同构建了一个庞大的信息生态系统。百度百科成为中国最大、最权威的在线百科全书;百度贴吧则是中国最早、最具活力的兴趣社区之一,为用户提供基于兴趣和话题的互动交流平台。在商业模式方面,百度的主要收入来源是在线广告和营销服务。其搜索广告系统通过竞价排名和智能投放,为广告主提供精准营销方案。百度利用大数据分析和人工智能算法,帮助企业更高效地触达目标用户群体。这一商业模式在中国互联网早期发展中起到了极为关键的作用,为百度积累了大量的流量资源和资金实力,也为其向人工智能转型奠定了基础。自2010年代起,百度开始全面布局人工智能技术,提出了“用科技让复杂的世界更简单”的企业使命。公司建立了领先的深度学习平台——百度飞桨(PaddlePaddle),这是中国首个完全自主研发、开源开放的产业级深度学习框架,广泛应用于图像识别、语音识别、自然语言处理等AI领域。百度还推出了文心大模型(ERNIE),在自然语言理解、生成式AI等方面取得显著成果,成为中国人工智能大模型技术的代表。在自动驾驶方面,百度于2013年启动Apollo计划,目标是打造开放、安全、智能的自动驾驶平台。目前,百度Apollo已在多个城市开展自动驾驶出租车服务(即“萝卜快跑”),成为全球少数实现规模化商业运营的自动驾驶企业之一。百度还积极推进智能交通解决方案,通过车路协同和云端智能决策,提高城市交通的效率与安全性。此外,百度在智能硬件和云计算领域也持续发力。百度智能云为政府、企业和开发者提供从计算、存储到AI训练的全栈服务,已成为中国主流云服务提供商之一。百度还推出了多款智能硬件产品,如搭载小度助手的智能音箱、智能屏、车载语音系统等,构建了一个围绕语音交互和AI生态的智能生活体系。百度的企业文化强调“简单可依赖”,注重技术创新与社会责任并行。公司在人工智能伦理、数据安全、可持续发展等方面不断探索,提出了“AI for Better”理念,希望通过人工智能技术推动社会进步,改善人类生活。百度在教育、公益、环保等社会项目上也积极投入,推动科技向善。如今的百度不仅是中国互联网产业的重要参与者,也是全球人工智能创新的重要力量。面对生成式AI和大模型时代的到来,百度持续强化技术研发,完善从基础模型到产业应用的全链条布局。无论是在搜索引擎、自动驾驶、智能云,还是在AI生态建设方面,百度都展现出强大的技术积累与创新能力。可以说,百度从最初的“中文搜索第一品牌”,成长为中国人工智能领域的中坚力量,代表着中国科技企业向全球科技前沿迈进的缩影。"
}我们知道 E5 small 的最高 token 长度是 512 个 token。也就是说当我们的文本输出超过 512 时,作为 semantic_text 所定义的字段,它会自动帮我们对它进行分块。我们的分块策略有 2 种。可以阅读文章 “Elasticsearch:为推理端点配置分块设置”。
在上面,我们的输入字符长度为 1000 个,那么当我们写入这个数据时,按理应该被分为两个块。我们进行如下的搜索:
GET longtext-semantic-index/_search
{
"query": {
"match": {
"content": "百度业务涵盖哪些?"
}
}
}它返回的结果是:
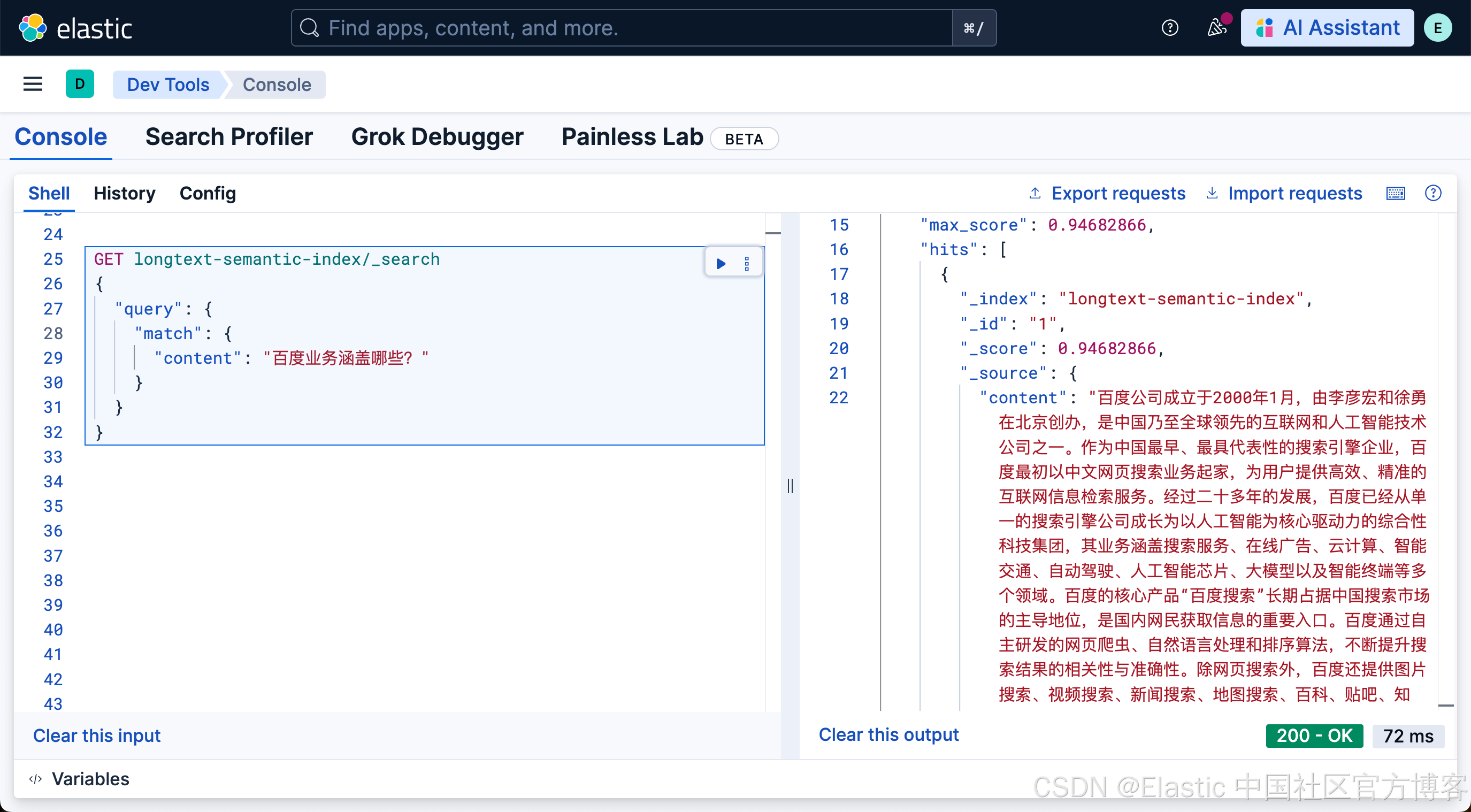
很显然是整个文档被返回来了。。在很多的时候,也许这个并不是我们所想要的。我们可能更希望看到是哪个 chunk 含有和我们搜索更为贴近的内容,否则把所有的内容发到 LLM,那样会增加开销。我们使用如下的查询:
GET longtext-semantic-index/_search
{
"query": {
"match": {
"content": "百度业务涵盖哪些?"
}
},
"highlight": {
"fields": {
"content": {
"number_of_fragments": 2,
"order": "score"
}
}
}
}上面返回的结果是:

很显然,第一个 chunk 对我们最相关,所以它的排名是在前面。
为了更进一步展示,我们做如下的搜索:
GET longtext-semantic-index/_search
{
"query": {
"match": {
"content": "百度构建什么样的智能生活体系?"
}
},
"highlight": {
"fields": {
"content": {
"number_of_fragments": 1,
"order": "score"
}
}
}
}这次,我们只返回一个 fragment:
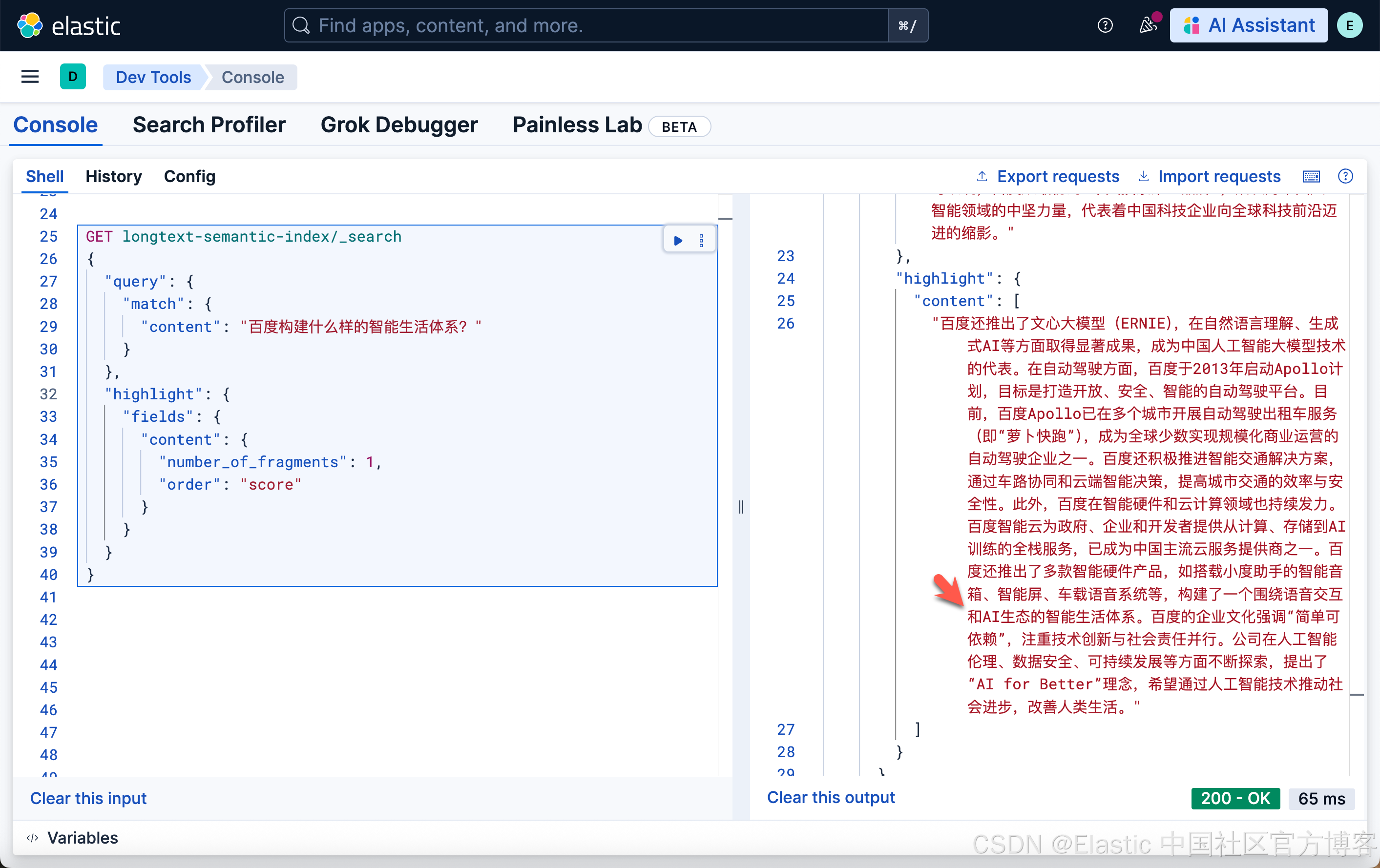
很显然,这次只有第二个 chunk 返回我们想要的数据。
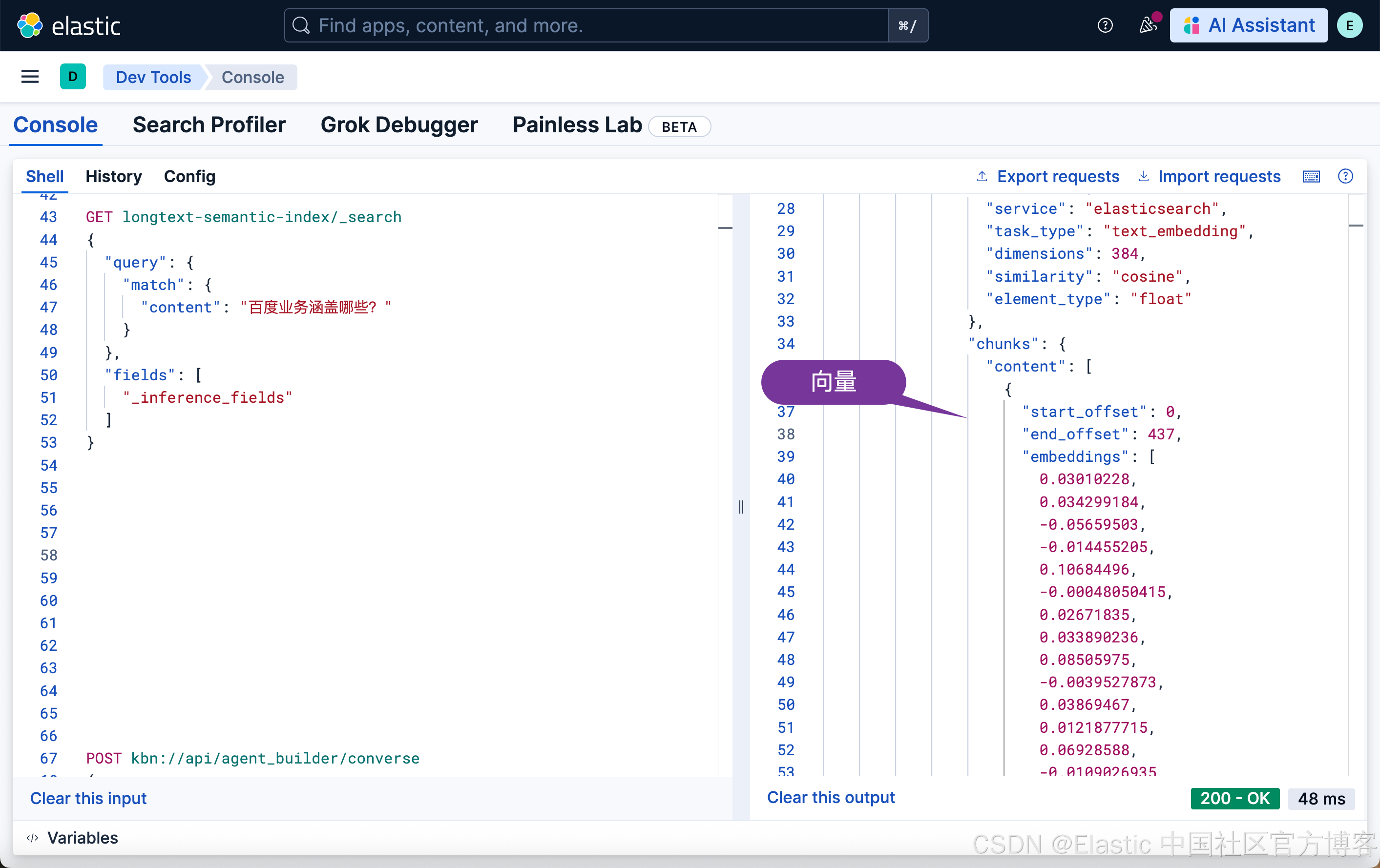
如果我们想得到这些块对应的向量,我们可以通过如下的方式来得到:
GET longtext-semantic-index/_search
{
"query": {
"match": {
"content": "百度业务涵盖哪些?"
}
},
"fields": [
"_inference_fields"
]
}
在 9.2+ 版本中,Elastic 以更加简介的方式来展示 chunks:
GET longtext-semantic-index/_search
{
"query": {
"match": {
"content": "百度业务涵盖哪些?"
}
},
"fields": [
{
"field": "content",
"format": "chunks" /* 1 */
}
]
}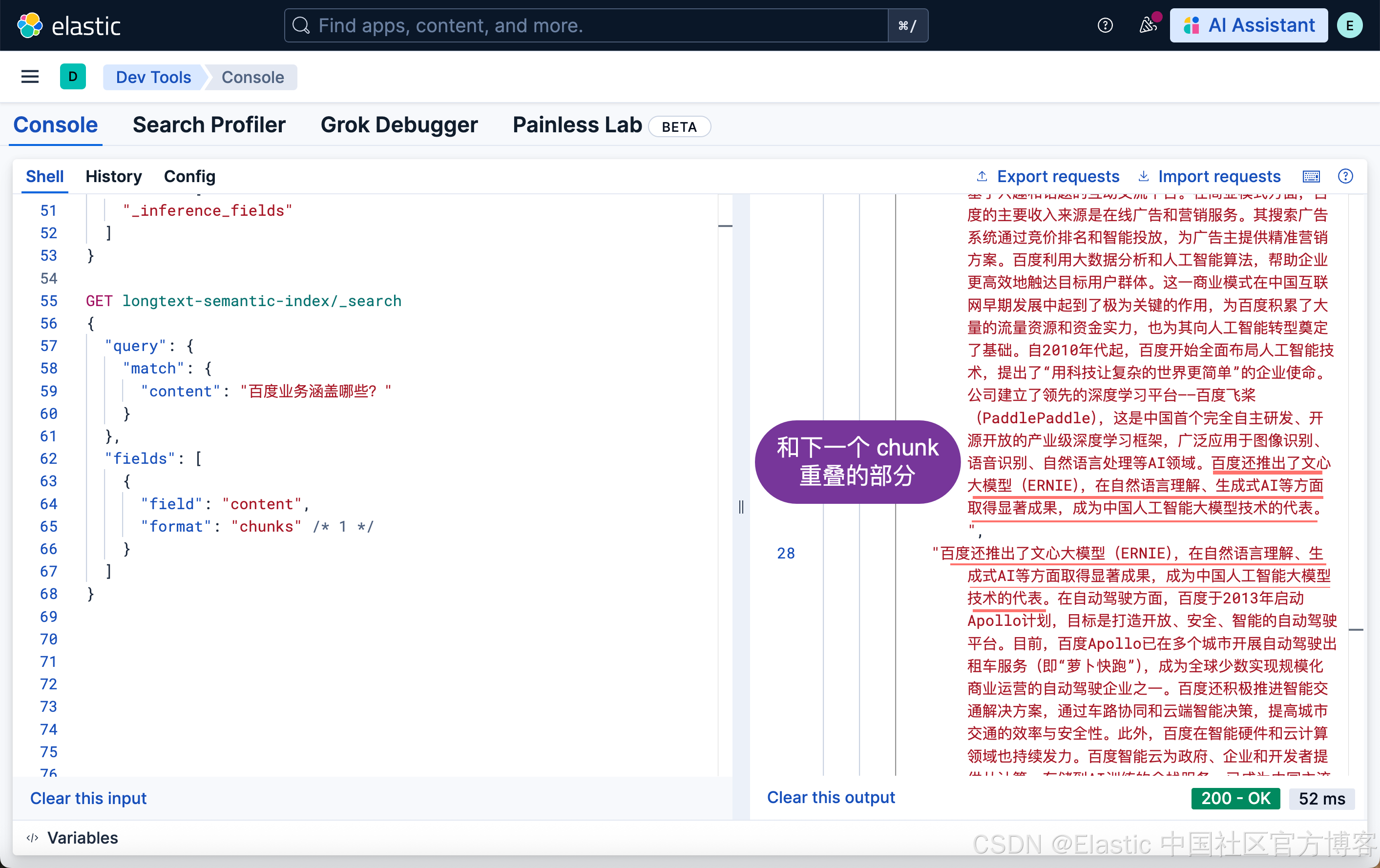
在上面,使用 "format": "chunks" 将字段文本以已索引的原始文本块形式返回。
上面的 demo scripts 可以在地址 https://github.com/liu-xiao-guo/es_vector_search_demo 下载!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 57
57 0
0- 0



 已为社区贡献283条内容
已为社区贡献283条内容

所有评论(0)