端到端驾驶中三平面实现高效的多摄像头token化
25年6月来自Nvidia和斯坦福的论文“Efficient Multi-Camera Tokenization with Triplanes for End-to-End Driving”。自回归 Transformer 因其可扩展性以及利用互联网规模预训练进行泛化的潜力,正日益被部署为端到端机器人和自动驾驶汽车 (AV) 策略架构。因此,高效地对传感器数据进行token化对于确保此类架构在嵌入
25年6月来自Nvidia和斯坦福的论文“Efficient Multi-Camera Tokenization with Triplanes for End-to-End Driving”。
自回归 Transformer 因其可扩展性以及利用互联网规模预训练进行泛化的潜力,正日益被部署为端到端机器人和自动驾驶汽车 (AV) 策略架构。因此,高效地对传感器数据进行token化对于确保此类架构在嵌入式硬件上的实时可行性至关重要。为此,本文提出一种高效的基于三平面的多摄像头token化策略,该策略利用 3D 神经重建和渲染领域的最新进展,生成与输入摄像头数量及其分辨率无关的传感器tokens,同时明确考虑其在自动驾驶汽车 (AV) 周围的几何。在大规模 AV 数据集和最先进的神经模拟器上进行的实验表明,与当前基于图像块的token化策略相比,该方法可显著节省成本,产生的tokens最多可减少 72%,从而使策略推理速度提高 50%,同时实现相同的开环运动规划精度,并改进闭环驾驶模拟中的路外率。
三平面是一种体潜表征,由三个轴对齐的正交特征平面 P_xy、P_xz、P_yz(如图所示)组成,其中 S_i × S_j 表示每个平面的空间维度,每个网格单元对应一个 s_i × s_j m2 的空间区域,D_f 表示特征维度。本研究中平面充当了多摄像头图像的分辨率无关、摄像头数量无关且几何-觉察的表征,从而能够为 AR Transformer 提供高效的token化功能。
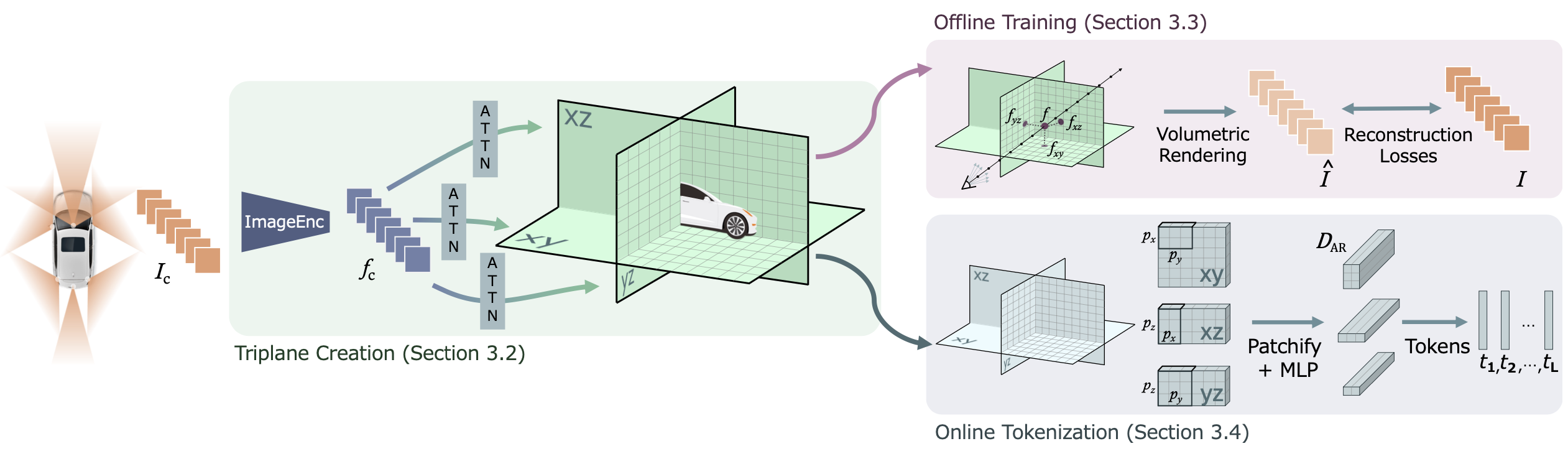
将多摄像头图像编码为三平面
在时间 t,假设自动驾驶汽车 (AV) 从其 N 个摄像头 c ∈ {C_1, …, C_N} 中分别获取图像 I_c。为了将这 N 幅图像编码为三平面 {P_xy, P_xz, P_yz},首先使用骨干编码器网络对图像进行特征化。
然后,与 TPVFormer [24] 类似,一个由 3D 查询点 q 组成的网格(S_x, S_y, S_z 分别为每个空间维度上的三平面网格单元数量)通过一系列逐图和跨图的可变形注意操作来关注图像特征,利用每个摄像头的内外参进行 3D 到 2D 的投影。在内部,使用正弦位置编码 [45] 来表示三平面网格的位置。最后,沿每个空间维度对更新后的查询进行平均,以生成所需的三平面 {P_xy, P_xz, P_yz}。由于三平面尺寸 S_x,S_y,S_z 是固定的,因此此过程将摄像机数量 N 及其分辨率 H × W 与最终的 token 数量分离开来。
最后,由于驾驶场景无界,采用类似 Mip-NeRF 360 [1] 中的非线性场景参数化方法,在不增加三平面尺寸的情况下对远处物体进行建模。具体而言,以 x 轴为例,将网格坐标 p_g,x 映射到具有对称双线性网格分辨率的自我相关坐标 p_ego,x。
通过体渲染实现可扩展训练
与先前利用多个复杂(例如基于 Hessian [25])自监督损失函数的研究相比,本研究仅训练最小化两个像素级重建损失函数。
图像 Iˆ 通过射线采样和聚合,从三平面实现渲染。首先将 x 投影到三个特征平面上,通过双线性插值检索相应的特征向量 f_xy, f_xz, f_yz,然后通过逐元乘积将这三个特征向量聚合成 f,从而查询三平面的三维位置 x。然后,轻量级多层感知器 (MLP) 将三维特征 f 解码为颜色和密度,并使用体渲染 [31] 将其渲染成 RGB 图像。
值得注意的是,与目前基于自编码器的方法 [7, 13, 58] 相比,该方法不使用任何 GAN 损失函数(其训练过程尤其敏感)。、即使没有这些损失函数,基于三平面的驾驶模型也能达到甚至超越基于自编码器方法的驾驶性能。
为下游应用token三平面
有了训练好的模型,多摄像头输入图像可以通过前馈方式转换为三平面。获得三平面后,即可对其进行token化并由下游 AR Transformer 提取。
连续token。三平面可以通过多种方式转换为一维token序列。在本研究中,像 ViT [11] 中一样对其进行 patch 处理,将三平面分割成特征块,并将它们编码为一组具有所需维数的特征向量,以供下游使用。
形式上,每个特征平面 P_ij 首先被重塑为一组块 P′_ij,然后转换为一个token序列 {t_l}。然后,单层 MLP 将得到的特征维度 D_f p_i p_j 转换为 D_AR,从而生成一组tokens {t_l},其中 L_ij = S_i S_j / p_i p_j 是表示平面 P_ij 所需的 token 数量,D_AR 是下游 AR Transformer 的特征维度。对每个平面执行此操作将生成一个整体 token 序列 {t_l},其中 L = L_xy + L_xz + L_yz。
离散token。虽然上述方法生成连续token,但也可以输出离散token。具体而言,可以在创建三平面后添加有限标量量化 (FSQ) [30] 层,以学习离散码本并生成离散token。然而,在最初的实验中,离散token的表现不如连续token。因此,本研究仅使用连续token。
数据集。为了训练和评估驾驶性能,利用一个庞大的内部数据集,该数据集包含来自 1700 多个城市和 25 个国家/地区的多辆自主车辆的 20,000 小时驾驶数据。因此,它涵盖各种驾驶场景,包括高速公路和城市驾驶、多种天气条件、白天和夜间以及不同的交通流量,并按地理位置划分 90% 的训练样本和 10% 的测试样本。每辆自主车辆配备 7 个摄像头,将其下采样至每个摄像头的分辨率为 H × W = 320 × 512,观测频率为 10 Hz。如图可视化数据集中的一个示例:三平面模型可以准确地表征外部摄像头观察的环境(上图),仅经过自监督像素重建损失函数训练后,即可生成精确的重建结果(下图)和语义特征(右图,三平面特征的 PCA 可视化)。

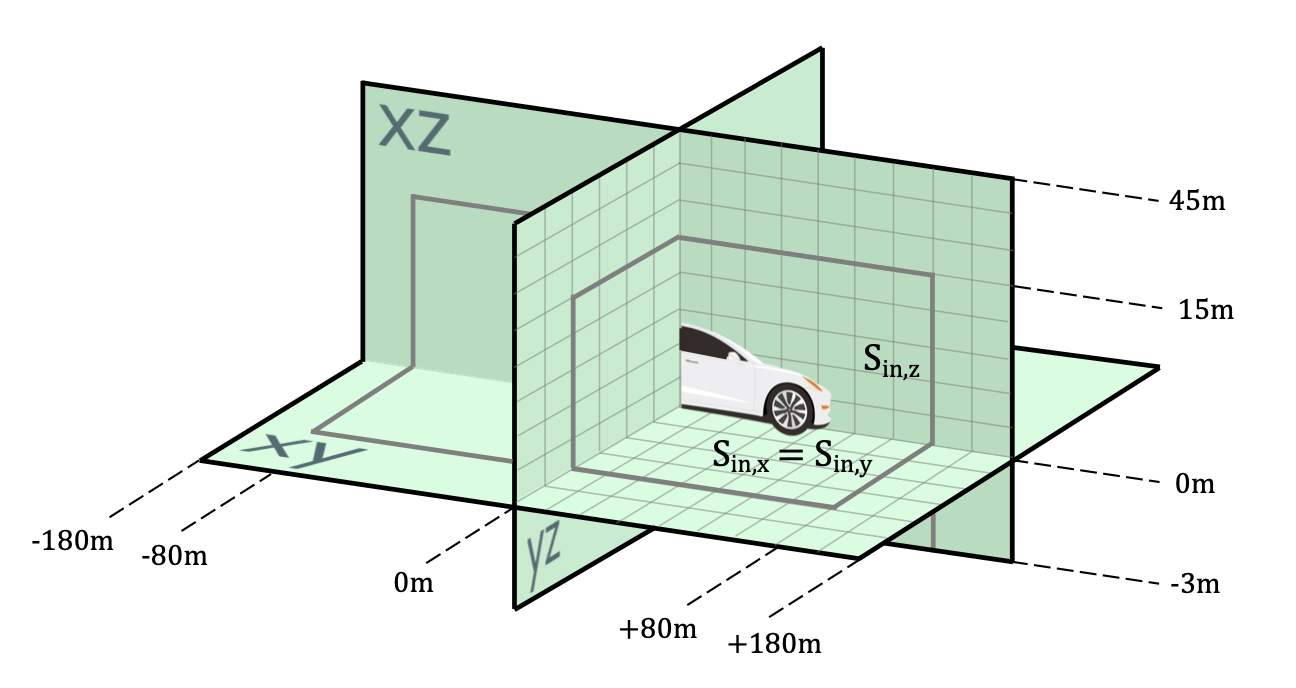
三平面模型。在所有实验中,设置 Sx = Sy = 96、Sz = 48 和 Df = 192。为了考虑在高速公路和较慢的城市街道上行驶,每个三平面在度量上代表本车前方、后方、左侧和右侧 180 米,以及本车上方 45 米和下方 3 米,如图所示。采用对称双线性网格分辨率,其中 S_in,x = S_in,y = 36 个单元。由于无法看到地下,因此 z 轴以不对称的方式用 36 个单元表示 [-3, 15]米,用剩下的 12 个单元表示 (15, 45]米。
用 22M 参数的 DINOv2-small [33] 模型作为图像编码网络,并使用两组单图像和跨图像的注意层(总共 4 个注意层,共计 6.5M 个参数)将图像特征转换为三平面。
AR Transformer。一个类似 LLM 的主干模型作为代表性 AR Transformer 模型 [52]。它将上述传感器 token 以及过去的自我轨迹信息作为输入,以生成未来的自车位置。未来轨迹表示为离散 token,并以 10 Hz 的频率解码为位置。
基线。由于图像自动编码器和 ViT 是最常用的图像token化器,将该工作与 VQGAN [13] 和 DINOv2-small [33] 进行比较,作为代表性模型。
训练。采用多阶段训练流程。首先对token化器进行预训练,使其在内部数据集上对驾驶数据进行建模(DINOv2 除外,因为它已经过网络预训练),然后在生成的tokens上训练随机初始化的主干网络。训练整体token化器-LLM 组合以最小化下一轨迹token预测损失。设置 λ_LPIPS = λ_1 = 0.5。更多训练细节可在 [52] 中找到。
指标。为了评估三平面质量,用峰值信噪比 (PSNR) 和结构相似性指数度量 (SSIM) 将重建图像与 GT 图像进行比较。为了评估组合token化-LLM 开环驾驶性能,用常用的 minADE_6 指标(表示 6 条采样轨迹中的最小平均位移误差)。
三平面模型表征质量
为了评估三平面模型能否表征从外置摄像头收集的驾驶场景,首先评估其在第一阶段训练后的重建性能。如表所示,三平面模型能够同时表征场景中近处和远处的元素,在对所有 7 个摄像头进行建模时,峰值信噪比 (PSNR) 达到 28.94 dB,SSIM 达到 0.84,与最先进的神经渲染性能相当 [56]。如果建模的摄像头数量较少(例如,仅建模前置 4 个摄像头),则重建性能提升至 29.15 dB PSNR 和 0.85 SSIM,因为可以使用更多的建模容量/每图像。
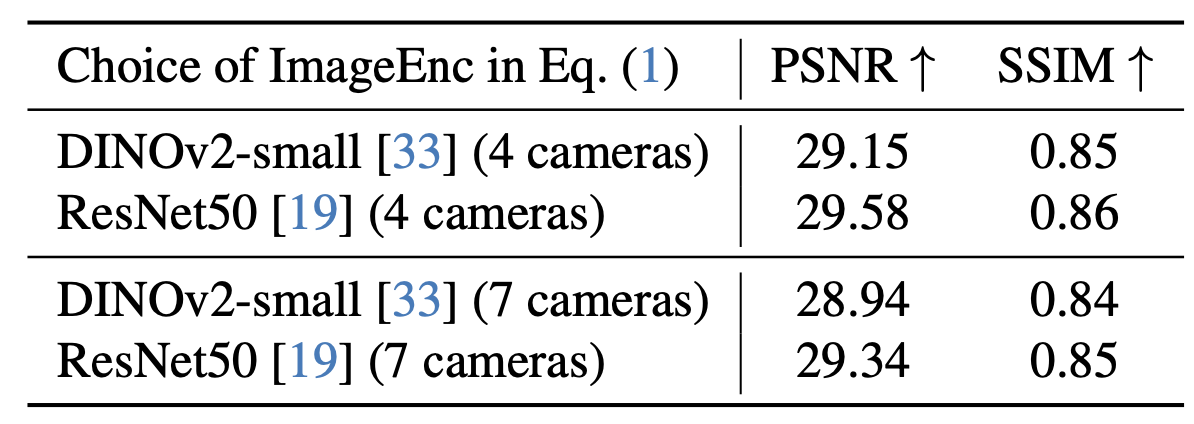
图像编码器的替代选择。该工作可以与任何能够产生二维特征的图像主干网络进行操作。为了证明这一点,该表还展示了使用基于 CNN 的图像编码器(ImageNet 预训练的 ResNet50 [19])进行三平面重建的性能。可以看出,与 DINOv2-small 相比,尽管模型优化的差异导致推理运行时间有所增加,但此选项仍可获得更好的 PSNR 和 SSIM 值。因此,在所有后续实验中,将 DINOv2-small 用于图像编码器。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)