从Math RL初窥LLM推理模型:是怎么work、哪些trick是有效的!
一下这些在base模型上面进行RL过程中的tricks可以看出,目前证明有效的都是要让训练又快又好的tricks,而对于恢复智商类的tricks目前基本是没有用的。主要原因我认为是这些策略虽然初衷是好的,但是在LLM的训练过程中起到了拖后腿的作用,无脑将模型往回拉。上面的介绍中,包含了基于 DeepSeek-R1-Distill-Qwen-1.5B这样的continue RL实验,也包含了基于qw
从Math RL初窥LLM推理模型:是怎么work、哪些trick是有效的!
羽毛书 吃果冻不吐果冻皮 2025年04月23日 21:59 四川
原文:https://zhuanlan.zhihu.com/p/1895568864848356926
笔者前面几个月进行了对R1/R1-Zero[1]的复现。在这个过程中走了很多弯路,但是弯路上面的风景也是挺精彩的。所以想把路上的内容分享出来。
由于是一篇阶段总结性的想法,既不是严谨的paper,又不是科普文章。所以文中会包含中比较多未经证明,没那么严谨的想法。并且想谈的方面比较多,并不聚焦。当然,也会呈现了一些对比实验,可能能回答一些Math RL是怎么work的,哪些trick是有效的,对这些我会尽量严谨呈现。
当然,因为实验也会产生疑团、思考、观察和对未来的想法,这些私货和实验会交织在一起,见谅。另外,本文并没有把提到的方法是什么详尽讲清楚,只能用一两句我脑海中的理解的话去介绍,也会带来很多不准确性。如果需要,建议还是去原文了解一下更准确的定义和做法。
在团队同意的情况下,将这些认知的更新分享出来,大家如果有是否有建议、触动、共鸣或不同的认知。
首先,我们先拿我们目前训练的不错的模型出来,可视化看一看GRPO[2]学到了什么。
第一部分:可视化看GRPO学到了哪些东西
在基于7B的zero训练中,我们用两种方法,adaptive entropy(下面会展开)和DAPO[3]的tricks,做到了比ORZ更好的一个效果。所以,这应该是一个不错的模型。

为了知道GRPO给模型带来了什么。我拿着一个上面adaptive entropy策略训练最好的4000+ step的点,与base模型进行比较,从模型输出概率上来可视化GRPO前后的模型的表现。
这里用了两种可视化策略:
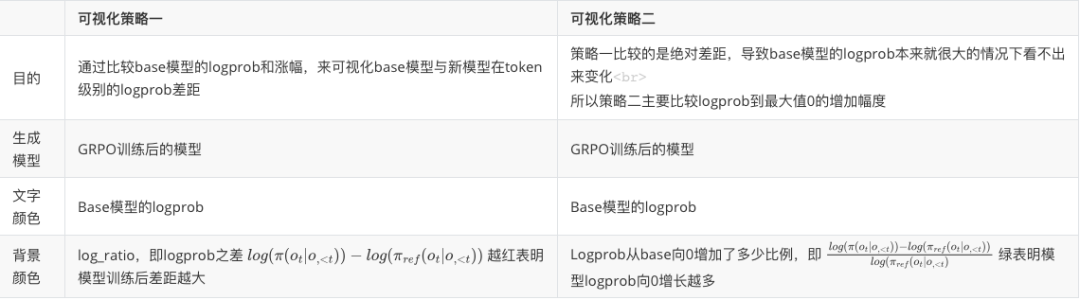
可视化策略一结果
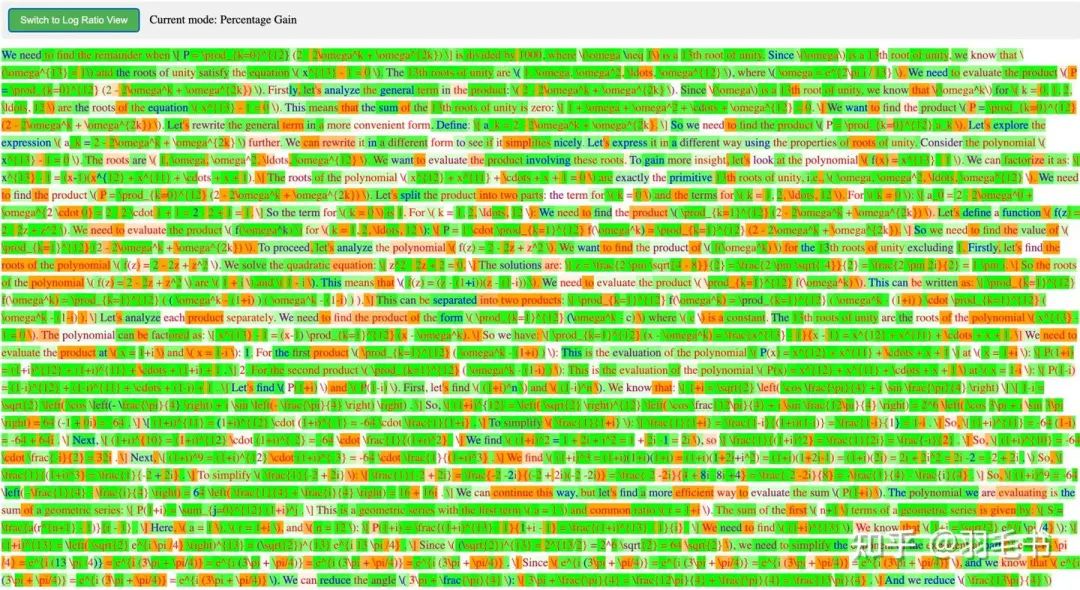
可视化策略二结果
观察一:RL非常依赖base模型
首先,可视化最明显能看出来的是训练后的模型推理能力依然极度依赖base model。输出概率的改变大部分都发生在连接词、推理流程影响的词,而在单步公式、数字、推理这些基本能力上,模型输出几乎还是在沿用base模型认为最好的路径,说明这些基础能力几乎完全来自base model。
如果类比围棋的话,R1-zero的过程虽然有个zero字眼,但是完全还是依赖人类语言去推理的AlphaGo阶段,而不是从零探索的AlphaZero阶段。而在RL过程中,最显著学到的是对更长思考的倾向,以及可能出现的局部推理能力的增强。
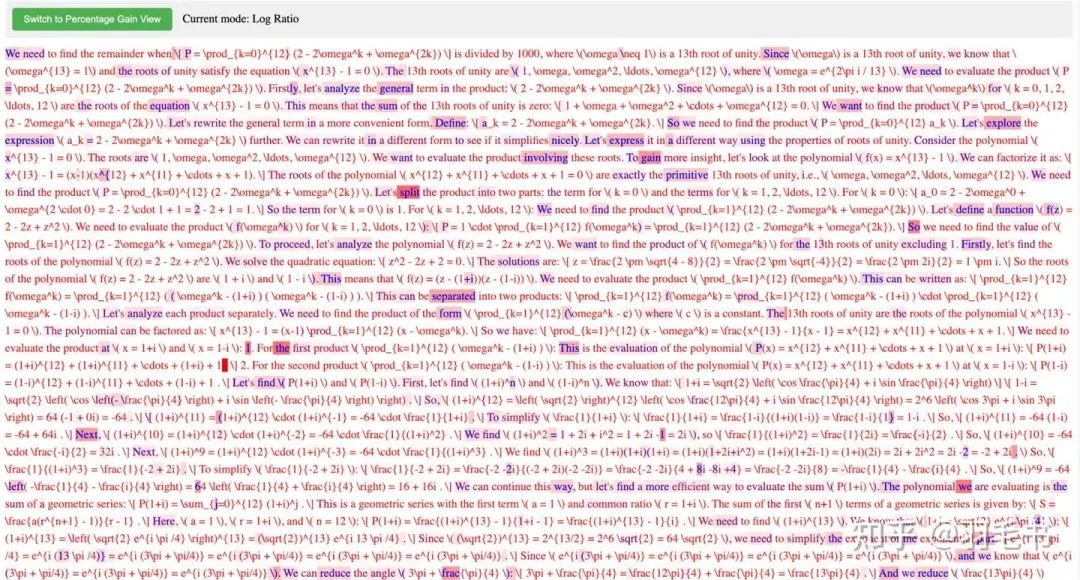
这里还做了一个训练时间太长,已经训练崩溃了的checkpoint的可视化,可以看到一旦离base模型太远,正常输出都没法进行下去了,会出现重复、乱码等情况。同时可以看到,这个崩溃的实验其实还没有完全崩溃,输出的前面一段还是正常的,只是训练到了后期,才开始出现模式坍塌。
从这个实验的观察可以推出,RL是不能远离base模型太多的,一旦把模型训练偏得多了一些,模型的输出就会崩溃,中断。导致无法输出最终答案,所有rollout的reward分数都是0,模型就没有正确的方向了。

训练时间太长,训练崩溃的可视化(策略一)
总之,目前的Math RL是强依赖一个非常强大的base model:不同大小的模型,相同算法RL后,提升的上限有很大的不同,RL可以通过激发base模型的长推理模式,充分发挥base模型的潜在推理能力。这意味着,想要获得最好的推理效果,就必须要在最好的base模型上面训练。
这里再继续类比一下围棋,提一个假设:假设就像AlphaZero一样,AI需要从头开始用一套语言,完全靠探索去重新理解或建立一个数学体系,才能进一步推高数学的上限。如果这个假设成立,想做到的话一定还需要一个巨大的范式转换才可能走到。
例如借助一些连续向量作为中间过程,然后在上面进行从易到难的RL,或者打破AR这种输出后就不能改的方式,而是全局思考过程可修改的方式去进行推导。当然,也有可能仅使用人类语言就足够让RL有无限的推理能力了。
观察二:训练后的base模型容易过度自信
在可视化策略二中,可以看出,base模型中本来概率很高的token,依然在GRPO中被不断加强,在训练后likelihood变得更接近1,也就是进行了过度自信的优化。这样的优化对模型的生成准确率能力基本是没有帮助的,但是会导致对模型的修改,产生额外的学习税。并且在token的prob都被推高的情况下,也会影响模型的探索的可能,例如prob在比较高的情况下,例如0.99时,在同一个context下,做16次rollout还有15%的可能出现非最高的token,相当于每7个这种token,rollout 16次中会有一个非最高token被探索,但是如果prob推高至0.999,概率就会降低为1.6%。这些token的探索就会几乎不存在。
这个现象在我跑的GRPO(例如下面的adaptive entropy loss实验)和DAPO复现实验上,表现都是类似的。这可能是GRPO算法的通病,会影响RL的上限。
既然目前的RL是完全离不开base模型的,下面一部分主要聊一聊RL的学习动力学,讨论一下在RL训练过程中的各个tricks是怎么影响RL训练过程的。
第二部分:RL过程与base模型的纠葛
从模型的演变角度来说,对一个大模型做RL,是从base/SFT模型作为ref开始,逐渐训练远离这个ref模型,同时获得越来越高的reward的过程。但是与此同时,RL又不能离ref模型太远,否则轻则无法继续训练、重则模型崩溃,而且离ref模型渐行渐远的过程,模型会忘掉前面学过的知识,降智交智商税。在这两层看似矛盾的要求下,要想RL训练的好,大家提出了很多tricks。
-
• 第一种是让训练过程对ref模型修改的又快又好,这样可以最大限度保留原始模型的能力。
-
• 另一个思路是在模型训练的过程中,持续恢复智商。
实际上,在LLM中大家探索的这些tricks,都是在想办法让RL过程向以上两个目标。这里列举如下:
在想办法让RL过程向以上两个目标。这里列举如下:
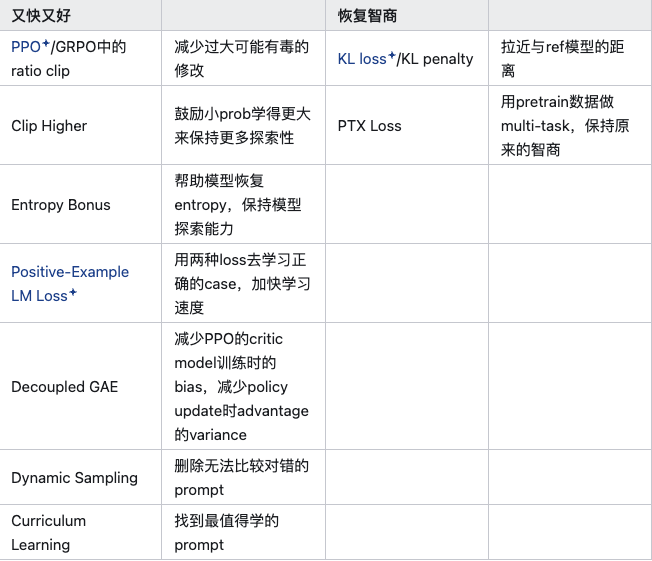
PPO/GRPO中的ratio clip
PPO/GRPO中的clip是PPO算法中一个重要的维持稳定的操作,可以干掉训练过程中可能有毒的改动。但是,ratio clip作为一种被动策略,实际上并不能实时鉴别有毒的修改。
在每一次rollout中,由于 ,所以第一次的ratio一定是1,clip是必然不生效的,同时这一次更新的结果是无法预先获知的,所以,存在一种极端的可能,在某一次更新中,某一个token的prob被更新了很多,prob ratio远超clip范围,但是这次更新是无法被撤回的。不但无法撤回,由于新policy是不会对同样的rollout再forward一次的,更新后的prob ratio都是无法被观测的。这种情况一般是不容易出现的,但是如果某一个rollout数据太脏,例如这次rollout包含大量重复现象,同时这是第一个mini train step,clip一定就不会发生,而又由于重复段中同一个token的context都是类似的,这个词每重复出现一次,就会将这个token向更低的prob的方向推一些,这样这个token的训练就过火了。
为了缓和上面的情况,让clip生效,需要在一次rollout中更新更多次,这样才容易积累到触发clip的生效。所以在GRPO的超参数调节上,可以把rollout的batch size调大,mini batch size调小,从而让rollout的次数更多一些。同时除了对prompt过滤以外,也需要对rollout中的sample进行过滤,不要让重复、杂乱的rollout参与更新。
Clip Higher
Clip Higher实际上利用了Clip机制,在论文中,通过将clip_high从0.2调整成0.28,来让小prob可以一次学到更大,这些prob的扩大大概率是会增加entropy的(因为大概率存在一个更大prob的token,prob会降低,整个概率变得更平均)。而对大prob,本来clip就不生效(例如old prob为0.9,prob为0.99,ratio只有0.99/0.9=1.1)
这里也给出一组我们对clip higher的消融实验
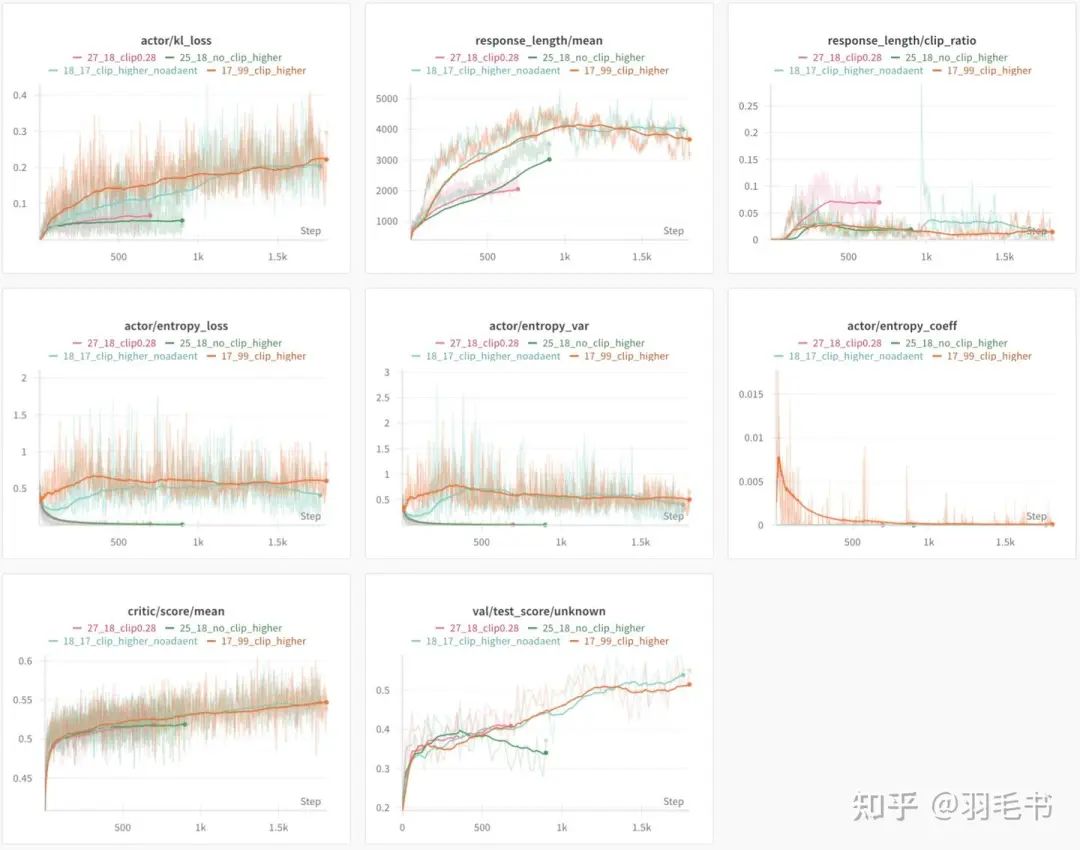
clip higher对比实验
实验分析
Clip Higher对entropy的保持是很有帮助的
-
• 观察18号实验,其entropy最初会掉下去,但是很快就保持住了原来的大小。
Clip Higher之所以能够维持entropy,最重要的是两边clip的非对称性带来的。
-
• 观察25和27两个实验,都是low=high,一个都设置为0.2,另一个都设置为0.28,两个实验的entropy都很快变得非常低。
另外,17这个实验在打开clip higher的同时,也用到了下面会提到的adaptive entropy,可以看到两者都打开后,entropy也会更稳定。当然仅用clip higher就能达到不错的效果。
另一个有趣的观察是,PPO clip的比例通常是很小的,通常在千分之几的token会触发clip。只有这么小的触发比例就能让entropy保持相对稳定,而且效果还相对不错,这一定程度也佐证了可视化中的现象,即目前的RL算法在base模型的基础上,仅在很少数的token上面在探索和进化。
Entropy bonus
Entropy bonus在传统RL里面是一个很好用的东西,加入MaxEnt优化目标后,可以防止模型模式坍塌,模型的探索能力得以加强。上面提到的DAPO核心trick clip higher也是为了解决这个问题的。但是,在近期做的比较好的工作中,都不会使用Entropy bonus。例如DeepCoder工作中发现,加入Entropy bonus后,entropy就会不断提升,最终崩溃。
但是在我复现DeepScaleR-1.5B[3]的时候,也观察到了entropy不断降低,会导致模型还没提升多少就停止提升了。所以,我用了一种adaptive entropy loss的方法,让entropy bonus的系数与当前entropy相关。通过adaptive entropy loss的方法,也全面超越了DeepScaleR-1.5B。
这里就聊一下我关于entropy bonus的私货实验,首先上结果:
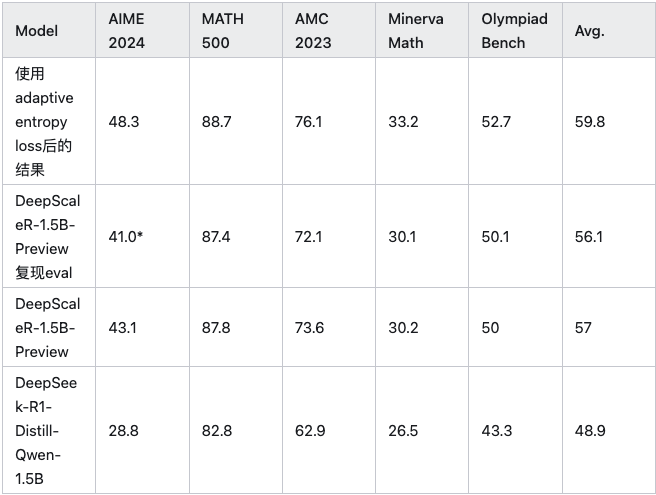
DeepScaleR-1.5B的43.1应该是一个抖动的结果,这个不止我不能复现,多个人跑eval都只有41%或42%,在最近的一篇工作Sober Reasoning[4]中用不同的seed去重新计算了一下这些开源模型的结果,其中DeepScaleR-1.5B的accuracy,只有37.0%。
Adaptive entropy loss具体策略
计算整个batch的entropy,根据当前计算的与预定target进行比较,根据偏离程度计算一个entropy_coef,来起到动态调整的效果
实验参数
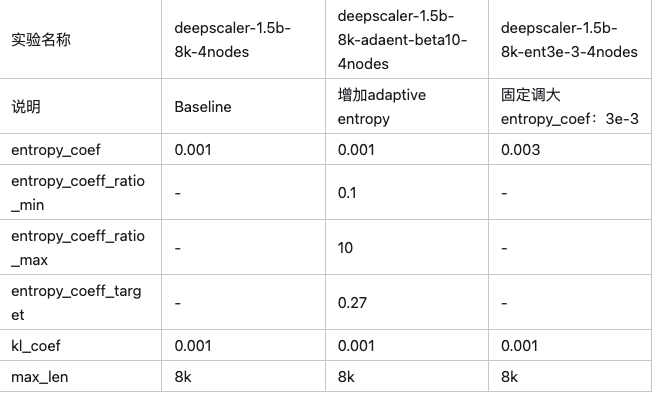
实验结果
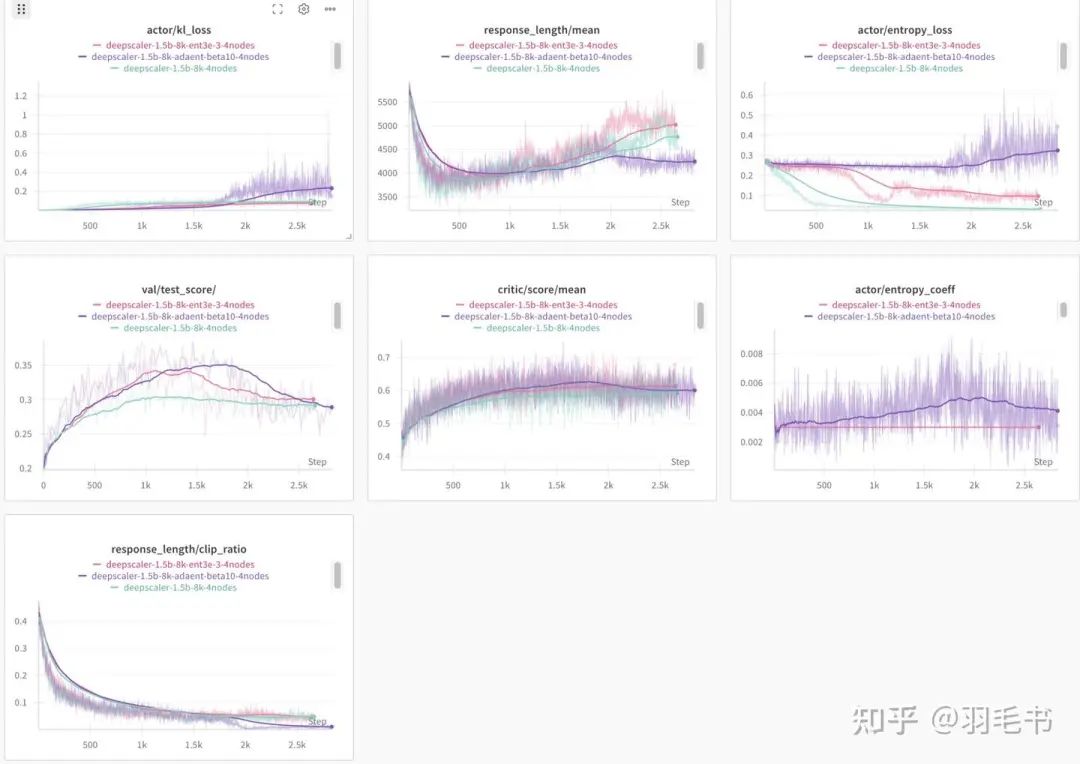
实验现象
增加adaptive entropy后,正常训练的时间更长了,但是到了1.5k step,会出现kl迅速增加的问题,效果会变差。
-
• baseline:绿线,700 step时test_score达到最高,entropy很小,之后test_score就不涨了
-
• adaptive entropy:紫色,1500 step前,KL增长明显慢于baseline,且1500 step时test_score达到最高,entropy基本保持。但是1500 step之后,kl开始突然变大,entropy_loss艰难保持在比较高的位置,test_score也开始下降。
-
• 固定entropy_coef:初始entropy靠固定的entropy_coeff=0.3正好能够保持。但是,后期会变得不太够,表现在entropy迅速变低。不如adaptive entropy对entropy的保持能力明显更强。
所以到目前为止,adaptive entropy loss还是起到了一定作用的,可以增加训练轮数,从而让效果持续提升。在各个测试集上,加入adaptive entropy的实验也明显有更高的准确率。
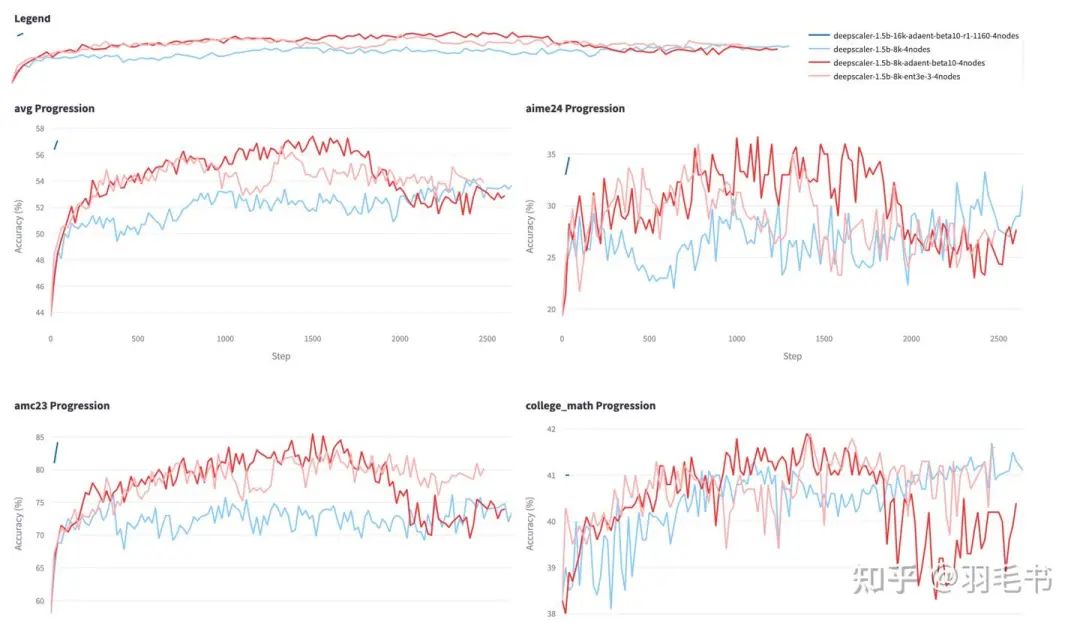
浅蓝色:baseline 浅红色:固定entropy coefficient 深红色:adaptive entropy loss
但是,其后期崩溃的问题仍然需要想办法解决。
先观察为什么会崩溃。从训练曲线上看,训练到2000轮的时候,模型就开始变差了。并且entropy的抖动变得非常大。进一步观察模型的输出结果。找到entropy最大的一些token:
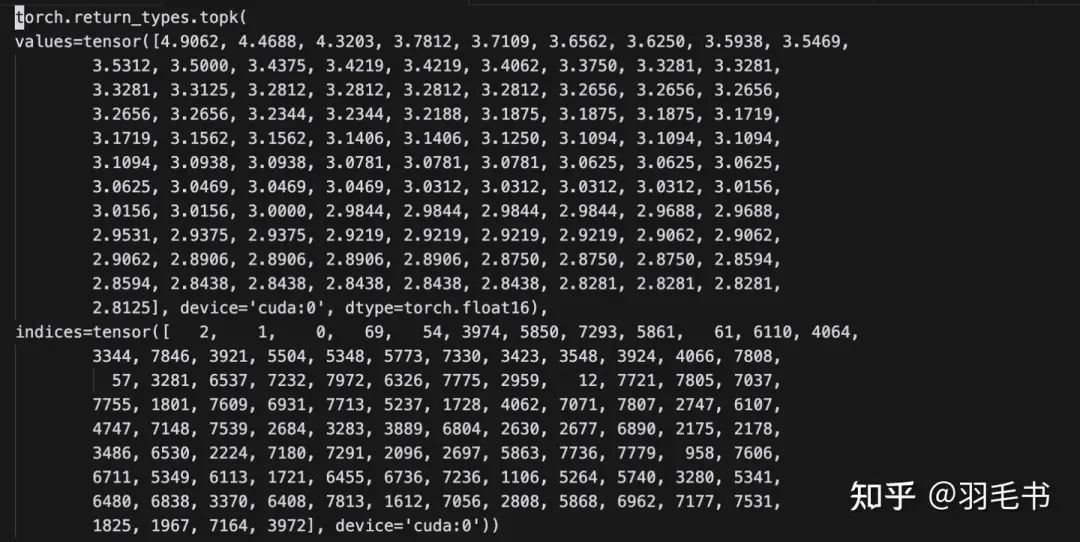
模型起点
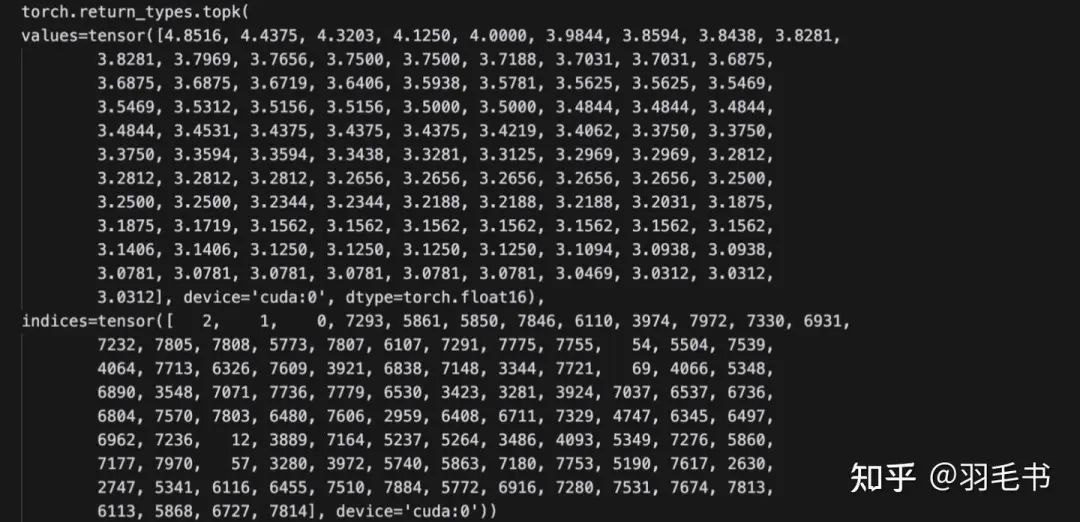
Step 1160
Step 2000
Step 2500
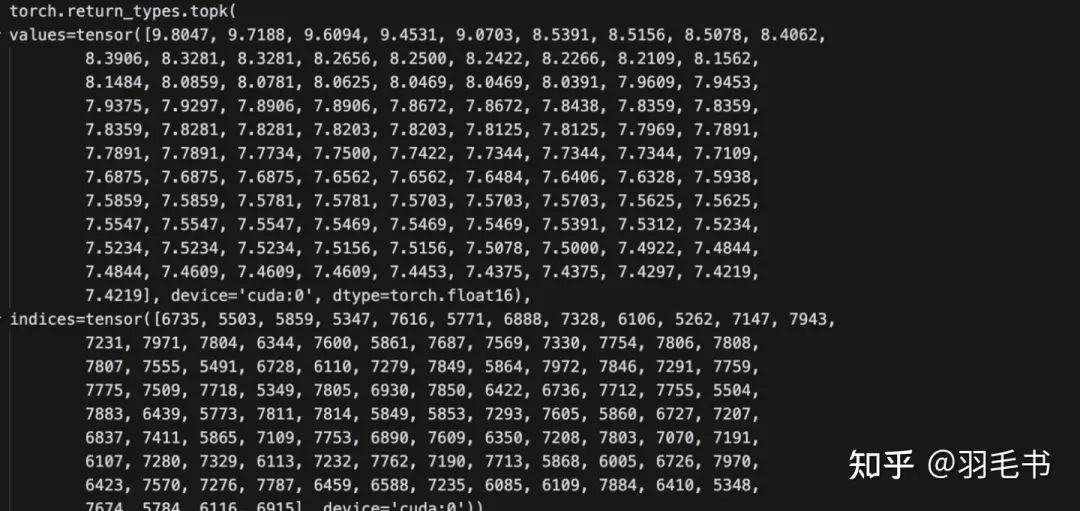
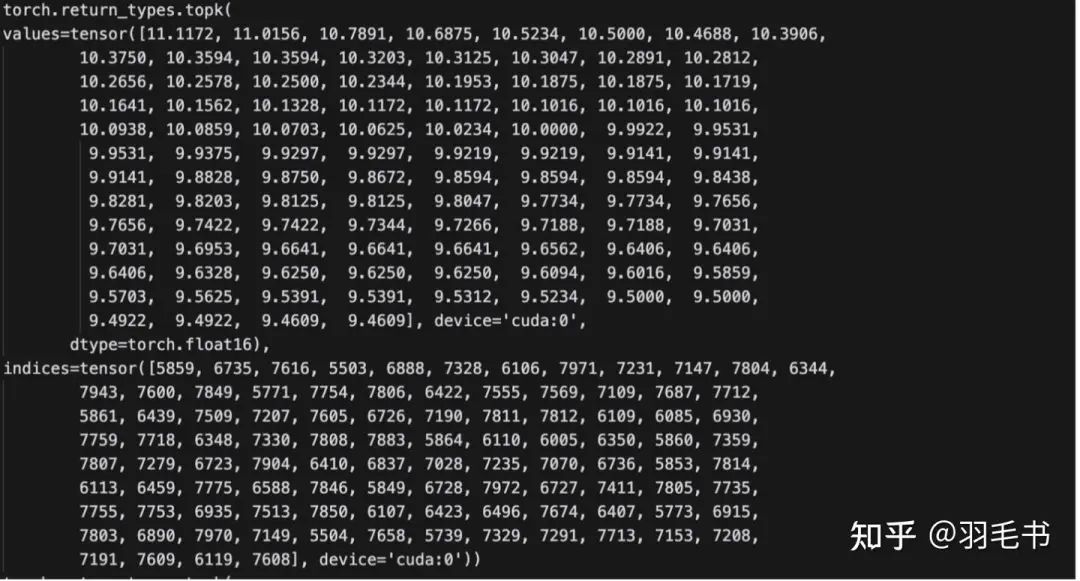
可以观察到在1160的step上,entropy最大的token和初始点相比基本是没有变化的,只是entropy的值略微变大。而到了2000 step,entropy最大的token变成了一些之前entropy很小的token。
我们进一步观察2000 step时entropy最大的token到底是在说什么,以idx=6735为例:
Ref模型:input是wait,next token最高概率为逗号,entropy为0
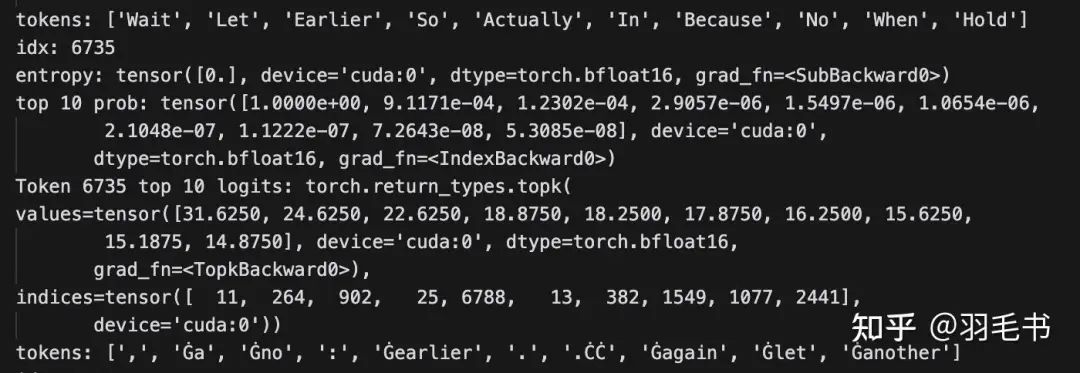
Ref模型
1160 step:input是wait,next token最高概率为逗号,entropy为0.0156
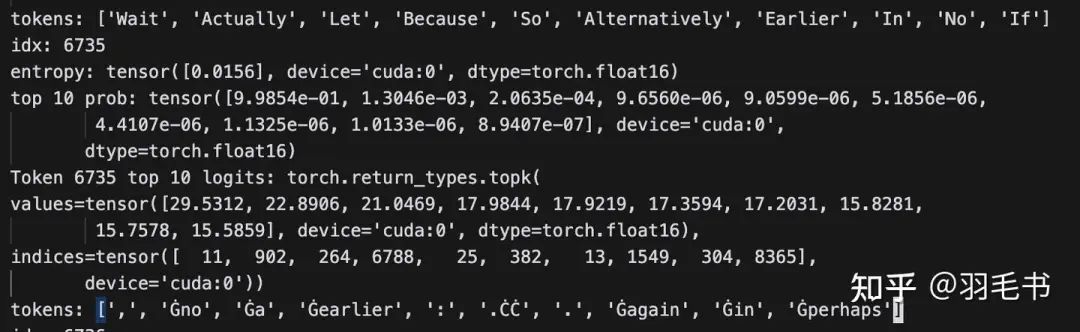
1160 step
2000 step :input是wait,next token的logits绝对值都有了很大的下降,entropy达到了整句最高的9.8047
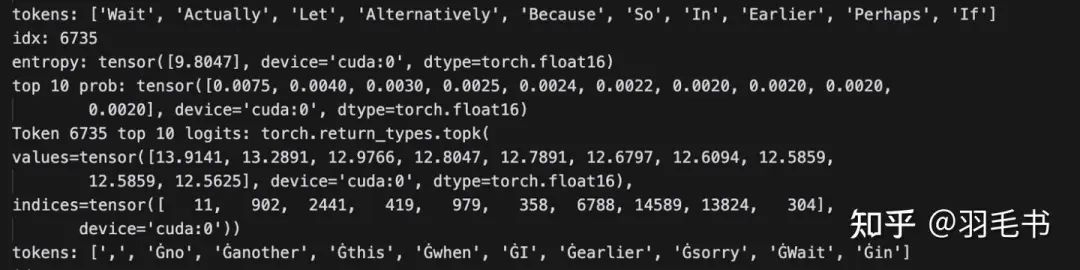
2000 step
通过几张图,可以推测出entropybonus导致模型崩溃的原因:
-
• entropy bonus是无脑加在所有token上面的,导致rollout中出现多的一些pattern(例如wait后面的逗号)被不断向平均优化(entropy更高),最终反而会导致模型失去这些pattern。
为了解决entropy无限制增加的问题,我增加了一个ref_gain_clip策略:
如果一个token的entropy超过ref模型的entropy某个阈值,就不能继续在上面加entropy bonus了。
原始entropy bonus优化的loss如下
我们同时计算ref entropy,并且加入ref_gain_clip策略,要求entropy比ref的entropy大 或者是ref的entropy的 倍以上时,应用clip
𝟙
对于被clip的token,不继续优化entropy,修改过的entropy loss为
实验现象
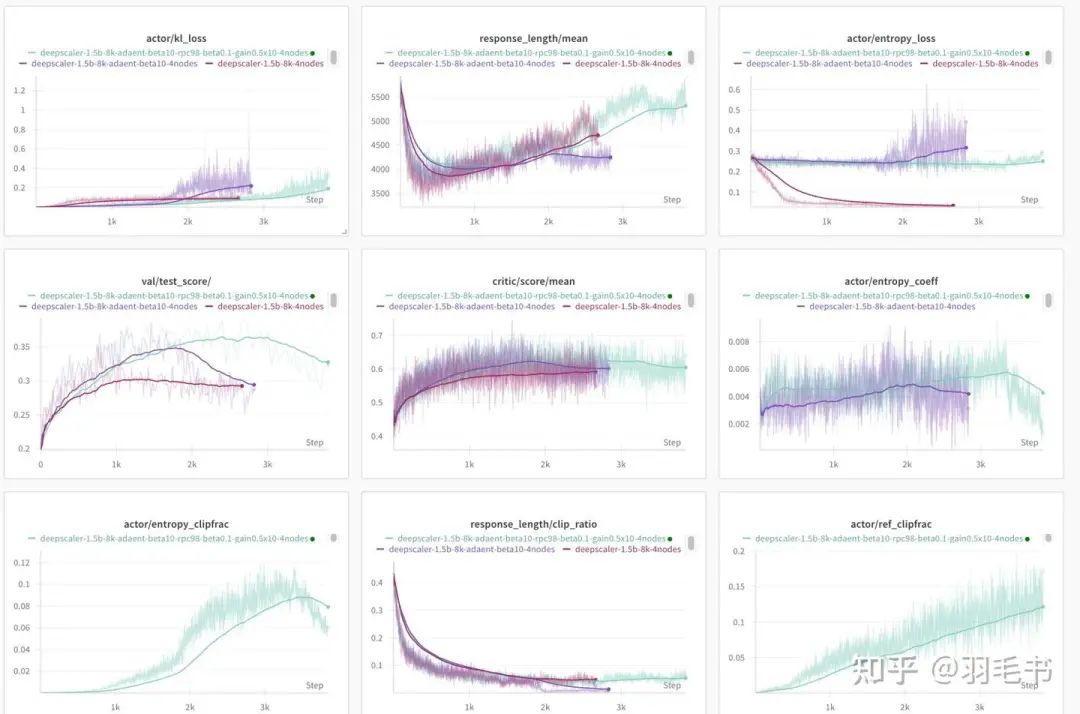
从下图可以看到,这个ref_gain_clip策略是有效的:
加入ref_gain_clip策略后,实验一直训练到了3k长度,比之前的1.5k开始崩溃增加了一倍左右。而且test_score(AIME24)也是持续上涨的。
从左下图可以看到,到了2k step时,entropy_clipfrac也开始明显起作用了,限制了对entropy bonus普遍作用于所有token。这个策略也让长度/AIME24的score有了进一步增长。
利用这个策略,将模型类似DeepScaleR-1.5训练了8k、16k、24k三个训练阶段后,在AIME24上面做到前面表中48%的准确率。
三个阶段的各个测试集的准确率(pass@1 avg16)如下图,其中8k阶段没有使用ref_gain_clip策略,后期崩溃了,取了1160 step进行16k训练,持续提升一段时间后,取了3300 step继续进行24k训练,24k训练结果中cherry pick了step 300的点,AIME24的准确率为48%。
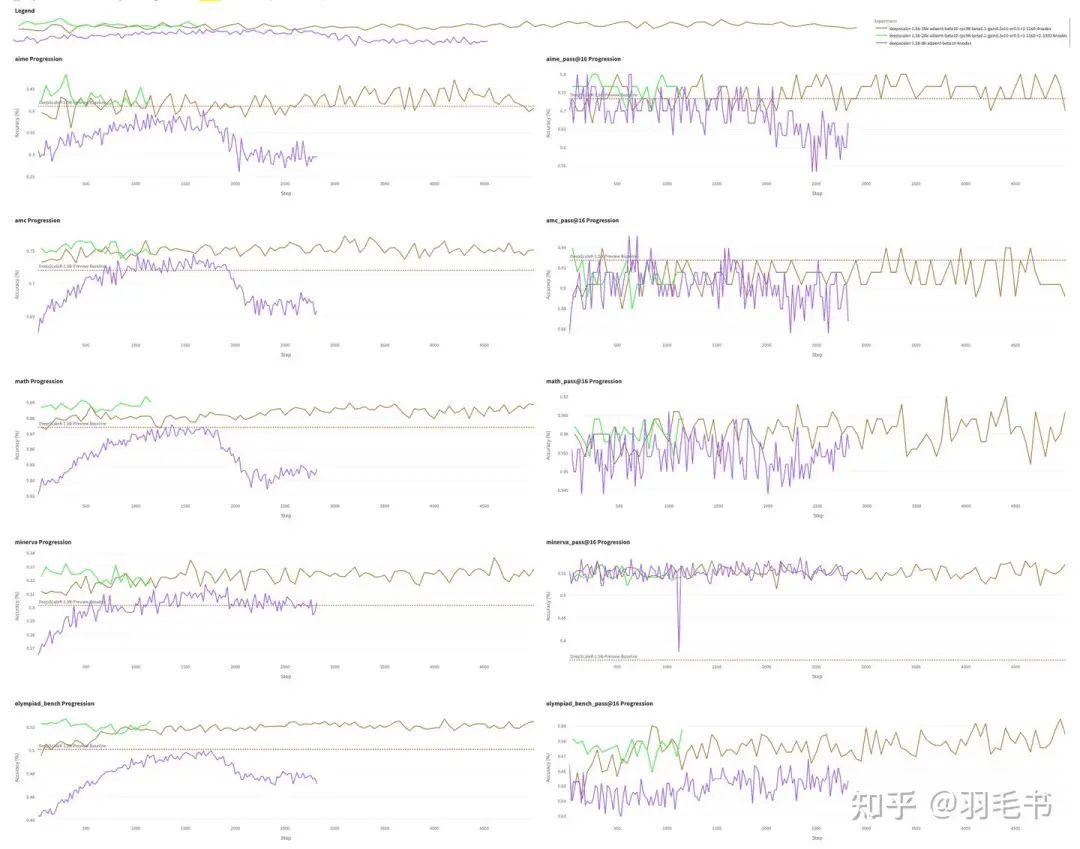
为了消除cherry pick的bias进一步,计算了step 250/step 300/step 350点的pass@1 avg64,准确率分别为45.7%/44.3%/45.6%,平均准确率为45.2%。
除了上面的1.5B模型训练外,我们也用adaptive entropy策略基于qwen-2.5-7B进行了训练,达到了和换成DAPO策略近似的效果。

因为adaptive entropy策略是和clip higher策略在解决相同的问题,这里对两种方法进行一下比较:
-
• 从策略上,Clip higher通过不对称性让训练更倾向探索,而adaptive entropy+entropy clip用了更直接的手段去奖励entropy的增加。
-
• 从副作用上,adaptive entropy引入了entropy策略,不可避免地在训练过程中离ref越来越远导致崩溃。即使崩溃是一定程度缓解的。
总之,虽然这一系列entropy的实验并不如clip higher策略优雅,但是也证明了控制entropy的必要性,以及在不加控制的情况下,entropy bonus为什么会带来副作用。
KL loss/KL penalty
KL loss是想减少与ref模型的diff,在每次训练过程中,都会将模型往ref拉近一些。但是,在近期做的比较好的工作中,都会选择删除掉KL Loss/penalty。
对于这个trick,我猜测弃用的原因是和entropy bonus类似的,KL loss是在每一个token上面都无脑加上去的。会出现RL好不容易把一个重要的pattern发现了(例如wait),开始广泛使用,但是KL loss发现ref并不喜欢这个pattern,又把模型往回学习的情况。这样RL和KL拽来拽去的,其实会影响模型进行分布的迁移,也会付出了更多的学习税。
PTX Loss
PTX Loss是在InstructGPT里面提出来的,通过在训练RL的过程中,混入pretrain数据和CE loss来让模型不要忘掉pretrain时学到的东西。也就是一种恢复智商的做法,和KL loss是类似的,都是在让模型往ref的方向靠近一步,只是用的数据不同,KL Loss用的是采样数据估算的KL来优化,PTX Loss用的是pretrain的loss。很不幸的是,PTX loss和KL loss类似,都没有什么人用。
Positive-Example LM Loss
Positive-Example LM loss是在VAPO里面被提到的,实际上就是在PPO的基础上,融合了DeepSeekMath中的Online RFT(用当前正在被训练的actor模型型去采样,删除错误答案后,用SFT的loss训练模型),这样一来,采样数据中的整理会用两种不同的loss去学习,来让模型学得更快,所以是一种又快又好的学习过程。
字节新作 VAPO:使用基于价值的强化学习框架进行长思维链推理
Dynamic Sampling
Dynamic Sampling会去掉采样过程中全对全错的prompt,对于这些prompt,在GRPO中每一个rollout的reward分数都是一样的,这会导致normalize后score全是0,Advantage也全是0,训练的内容就会与题目和答案的正确完全无关,只会训练额外的KL/entropy/长度损失这些loss。这些训练会给训练带来噪声,所以删掉不训练会更好。这个trick在不少工作都有在用,在我们的前期实验中,我们也发现按照正确率来过滤(例如20%-80%),而不只是去掉全对全错的,能进一步提升模型效果。
Curriculum Learning
在kimi1.5[5]/seed-thinking-v1.5中,都用到了通过改变喂数据顺序的方式去提高模型训练效果。这个应该是一个非常自然的最大化训练效率的方式。
总结
一下这些在base模型上面进行RL过程中的tricks可以看出,目前证明有效的都是要让训练又快又好的tricks,而对于恢复智商类的tricks目前基本是没有用的。主要原因我认为是这些策略虽然初衷是好的,但是在LLM的训练过程中起到了拖后腿的作用,无脑将模型往回拉。
上面的介绍中,包含了基于 DeepSeek-R1-Distill-Qwen-1.5B这样的continue RL实验,也包含了基于qwen25-7B的zero RL的实验。而且基于distill的1.5B模型比7B的zero RL效果要好。下面就谈一谈我对zero的一些思考。
第三部分:关于R1-Zero和R1的路径
DS R1呈现了一条仅使用Zero RL(让模型自己发现长思考能力),一次SFT distill(去除zero模型中的杂音),然后继续RL(继续增强长思考能力),就能得到一个很强的推理模型的路径。这其中不需要任何外界给的长思考数据,就达到了基本是SOTA的效果,显得格外优雅。
这个优雅其实还是挺难得的,在我们对推理模型探索的初期,也进行了RedStar[10]的尝试,主要提升也是来自于scale distill其他模型数据的大小,但是当时在RL方向的提升是比较小的,没能做到通过RL让模型自动获得更长推理的能力。
但是,zero RL的适用范围是非常有限的。DS通过在qwen32b上面的zero-RL实验证明了,如果你的模型小,做zero RL是没有任何意义的。甚至是完全比不过distill的。
在小模型上,distill模型现在是完全压着zero模型打的,例如在DeepScalerR中是在DS distill的qwen2.5-1.5B模型上面继续做RL的,AIME24可以做到43,我的实验中加入adaptive entropy loss后可以做到48,这相当于在32B上面DS R1-zero recipe的结果了;例如Light R1给出的SFT+DPO路径,可以在AIME24上面做到76.6/78.1,也远好于DS-qwen25-R1-zero/DAPO/VAPO这种zero的结果。
所以,如果只是做数学的话,zero仅适用于训练了一个全新的巨无霸base模型,并且这个pretrain底子比其他模型都好得多的情况。在上面做zero-RL相当于给他一个自由进化的练习场,最终达到全新的高度。否则做zero是没有意义的。
这是不是意味着,如果想要扩展场景,只需要非常少量地对zero distill过的最大的模型做continue RL即可呢?在目前的算法和形式下,我的答案是基本是的。例如如果想让推理模型扩展到更多垂直长尾场景,显然R1这样的模型本身就有一定泛化能力,这种情况下基于R1做continue RL大概率比zero更好。而对于与世界交互的UI-agent、code-agent这样需要一些格式之类新场景来说,以R1为基础,加入一些人工的指引数据,也更容易让模型在更好的起点开始探索。从而做到效率更高的RL。
当然,目前的RL算法还远没有到最优策略,这个时候用较小规模的zero可以作为一个benchmark,可以用帮助理解算法和调试框架。
在O1/R1的工作出来时,大家对模型的长度增长投入了很多关注,也想了各种办法去触发这种长度增长的pattern。目前终于在现象上,可以复现了长度随训练增长,这里也简单结合我们的实验谈一谈。
第四部分:长度增长是怎么回事
先说我们的几组实验:
数据实验
我们最开始用的RL数据是在类似RedStar中相对困难的数据,但是发现训练RL时效果基本不涨,长度也看不到增长。在STILL-3/DeepScaleR的工作出来后,我们发现他们的数据明显简单很多,换上以后长度就会蹭蹭长了,模型效果也会变好。包括用ORZ/Open-R1的数据,都是有很多简单数据。所以包含一部分简单数据是Math RL能够增长的必要条件。
长度优化实验
我们设计了一些直接优化长度的reward,例如直接对长度加上一个小的奖励项,或者设定一个长度schedule,奖励比较接近长度schedule的rollouts。但是这些实验都无一没什么提升。要不就是模型长度一下就涨上去了,但是效果变差了,要不就是模型长度涨上去了,但是效果没有变得更好。这说明长度增长只是现象,不应该作为直接优化的对象。
结合这些实验,这里给出一个关于长度增长的猜想:
通过增加反思、验算、细致计算,模型是容易获得直接提升的,也是目前RL里面最容易获得提升的pattern,这个pattern会带来长度的增加。RL的过程可以理解成不断hack reward的过程,我们需要一个数据分布,让模型能够正确地hack找到这些pattern,从而得到更好的推理能力。
画成示意图如下
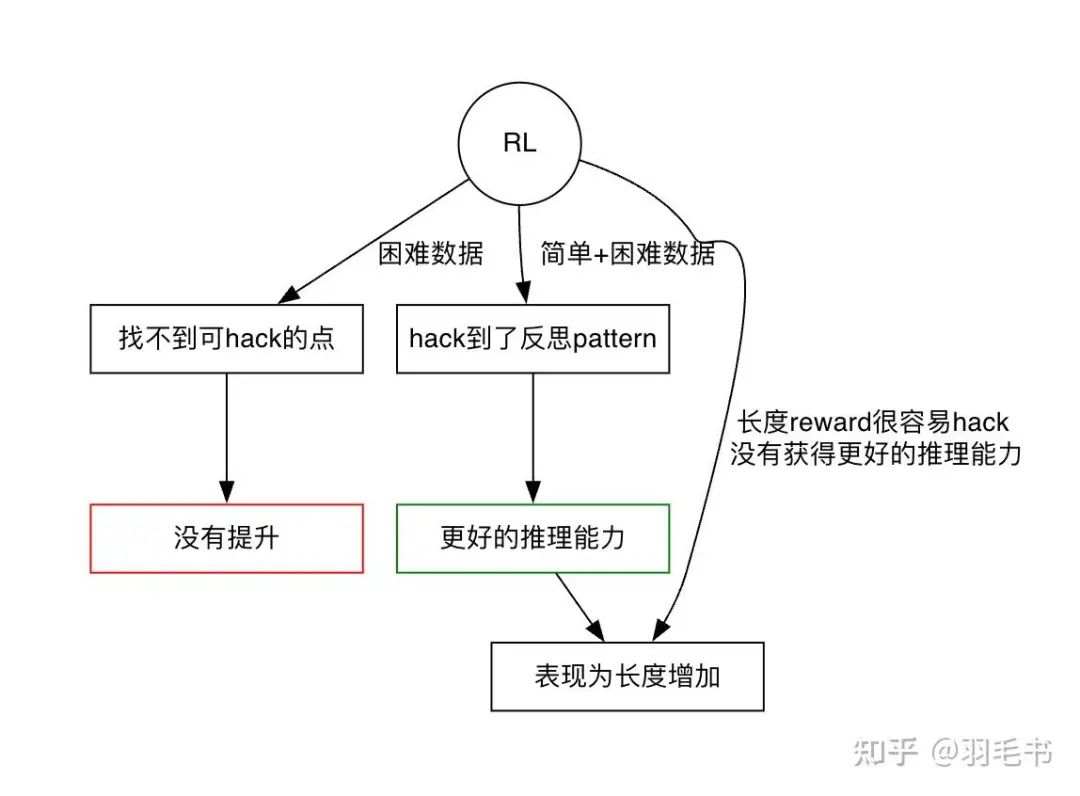
长度增长是怎么回事
在这个猜想下,加一些长度bonus没用就能说的通了。因为模型在rollout过程中有各种方式可以hack长度bonus,包括重复说、说更长的话等等。相比较来说,反思、验算、细致计算这种高级东西太不好被探索到了,RL会用更简单的方式去hack,而在这条路上面,最终是无法获得更好的推理能力的。
Seed最新的一些工作VC-PPO[6]/DAPO/VAPO[7]出来让我很兴奋的,这些工作既说明了对RL算法的改进是明显有帮助的,又能看出来算法上面还有提升空间。在上面的tricks中已经包含了几点DAPO的trick了,但是没有提全,这里也补充谈一下。
第五部分:谈谈DAPO和VAPO中的各个trick
Overlong Filtering
这个方法比kimi1.5里面在reward中的长度惩罚基本是一致的,相当于给kimi1.5的长度抑制加了一个下界,不要都抑制。
我们也做过一系列kimi1.5的实验,在我们的配置中,直接使用kimi1.5的长度惩罚会导致长度随着训练不断下降,最终降成了直接猜答案的样子,测试集上也自然都崩了。解决方法也比较简单,在惩罚上面加一个0.2的系数就可以了。
实际上,在我们的实验中,kimi1.5的抑制手段对效果提升是有帮助的。这里的猜测是对全局的长度抑制过程不仅仅是长度抑制。其实也会让模型不能无脑地选择无限计算。如果长短都能算出来,还是去选择更精简的方法。这样的模型上限会更高。
Token level loss
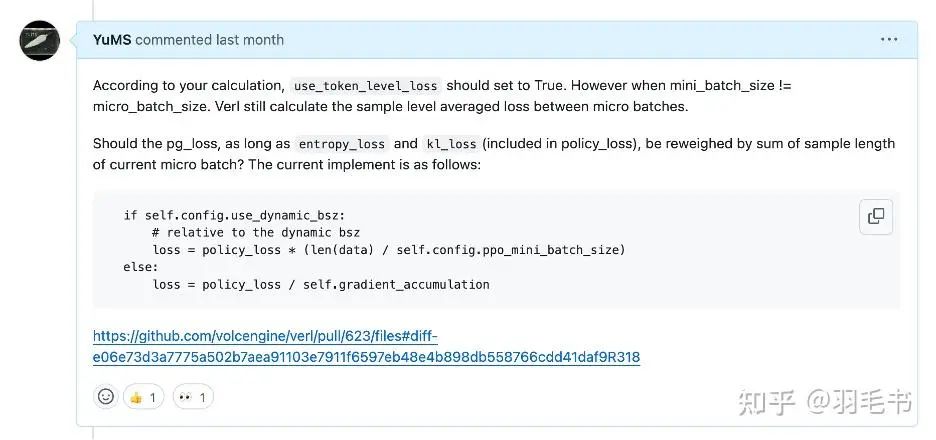
这个其实并不是一个trick,而只是因为框架实现过程中,明显有不合理的地方。每个token对loss的贡献变得与样本长度相关了。这个问题其实SFT训练中也早就可能出现。需要在整个batch中对所有token求平均,而不是先在每个样本上面求平均,再在样本间求平均。
这里一个小插曲是,在DAPO的论文中,使用token level loss其实也并没有实现对,因为Verl框架中使用了dynamic batch size,用micro batch去积累mini batch的gradient,然后在一个mini batch上进行优化器更新。他们的实现其实只是一个micro batch内部的token level loss。我还和他们讨论了一下这个问题。当然在最终合并main分支的代码中已经都修改了。
Data transform
这个trick会预先把所有的数据都转化为整数输出,这样对verifier的要求会显著变小。
但是,在我的实验中,用了这个trick后,amc23会明显变好,AIME24上面持平,其他测试集都会疯狂掉点。
观察此时的模型输出,发现这样训练出来的模型会hack训练集中只有整数输出的情况。导致所有测试集,即使中间过程输出的是一个小数的,最终也会只输出一个整数。
这也体现了RL过程中模型很强的hack能力,以及将hack到的能力泛化到所有题目的能力。
不知道DAPO论文训练出来的模型有没有发现这里可以hack,并因此受益。但是在seed-thinking-v1.5中,其实没有沿用这个data transform的方式,而是改成了使用更强的verifier,甚至是think-verifier来硬刚reward function的问题。这个动作可以看出来,这可能确实是一个问题。
我们换用DAPO数据后,可以看到大部分测试集都是在往下走的:
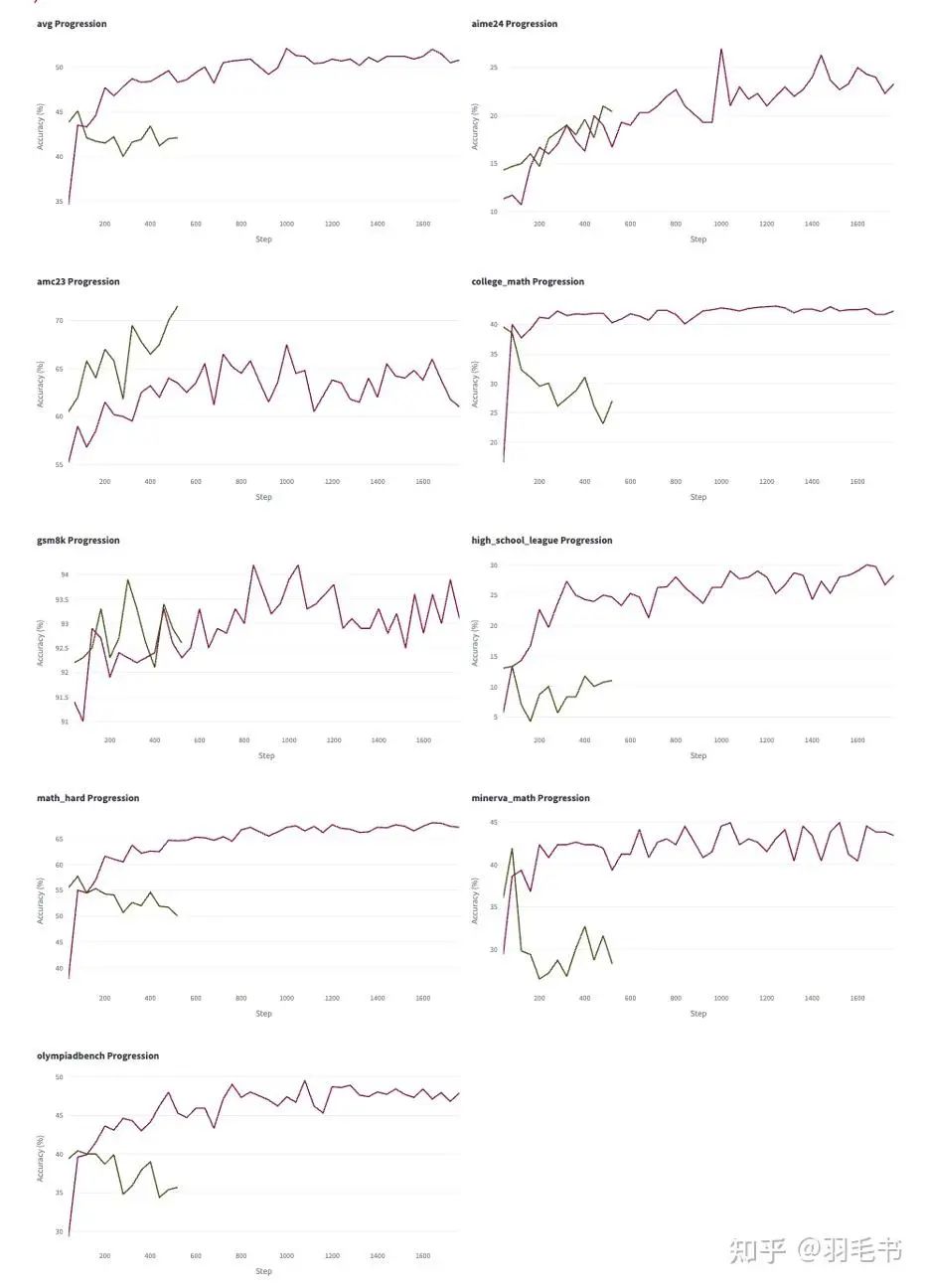
换用DAPO数据后,只有AIME24和AMC23比之前更好,其他测试集反而变差了
最后谈一谈为什么我觉得大模型基于Math的RL还没有到上限
第六部分 GRPO与PPO,以及后面是什么
PPO相比GRPO,最本质的变化就是对advantage estimation更准确。当然,从发展顺序上,其实GRPO才是PPO的“改进版”,所以应该反过来说,GRPO为了省掉value network,去简化了advantage estimation。而这个简化其实是非常粗暴的,在同一个rollout中,每一个token上面的advantage都变成同一个值,即group normalized reward。
GRPO的这种简化会造成两个可能的问题:
-
• 第一个是overconfident问题,在第一部分的可视化中提到过;
-
• 第二个是对整个样本中所有token会不分对错地进行加减分。
那为什么GRPO还能学到哪个好哪个不好呢?我的猜测是,在大量的加分减分之后,大浪淘沙,就把那些比较明显好的pattern给淘出来了。所以模型可以越训越好。但是那些没有明显优势的token,会在GRPO过程中不断抖动,一会儿prob学得更高,一会儿学得更低,最终保持基本不变。当然,在这样的抖动中,模型的学习会付出一些学习税。
而PPO中的value model理论上是可以控制一个每一个token的学习程度的,我们在lambda=1,gamma=1的GAE配置下考虑(其实是Monte Carlo return)。对于不重要的t时刻的token ,我们假设可以让 ,这个token是没有advantage的。而这种操作在GRPO中是完全做不到的。当然,这只是比较极端的假设。V通常不会达到-1,1这样的极值上去,在应用 ) 的情况下,advantage也会受到后面时刻的V影响。
这里再讨论一下,VC-PPO/VAPO中的value pretrain是在做什么。
根据VC-PPO论文的图,我推测value pretrain主要的作用是对输出最初的几十个token的值进行重塑。
在初始化的critic模型中,会认为最开头的几十个token是没做完的,会给出一个低分,而随着token越来越多,渐渐可以看出是否正确,critic score也会渐渐升高。
我们还是在 () 的情况去简单分析,t时刻的 的advantage为 , 值小会导致Advantage的值非常高。所以需要把这个偏见消除掉。所以引入了value pretrain。在这个过程中,VAPO使用了( )去学习value model,这相当于让value model直接学习最终的reward。这里虽然论文没有给出value model在value pretrain之后的样子,但是在我的想象中,由于前面几十个token其实是无法推出做对还是做错,所以学到的应该是-1和1的平均分0。这也可以和论文给出的学习后advantage非常平稳的图可以对应。
在这个value pretrain过程后,value model就从最初的“这么短肯定不对,低分”学成了“我也不知道对不对,给个平均分吧”,实际训练时就不会出现advantage在前面的token都是正的的现象了。
以下两图来自VC-PPO
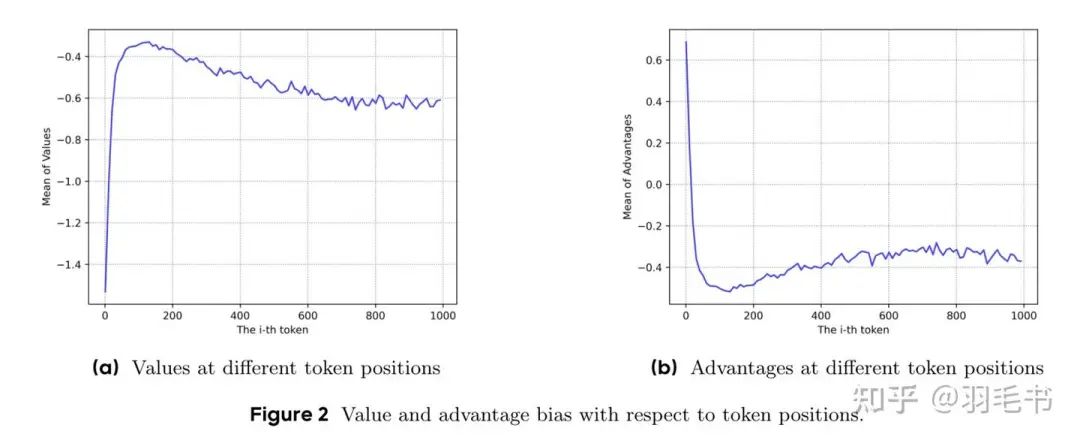
Value model初始化模型的平均values
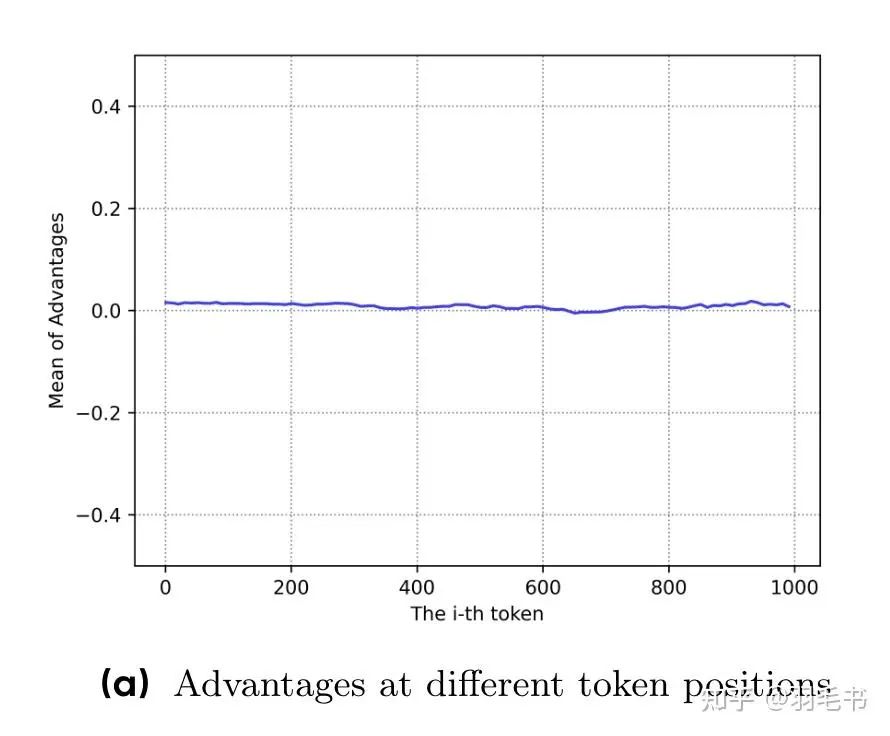
Value Pretrain后的平均advantages
如果前面的几十个token上,critic model都给相同的分数0,其实在这一段上和GRPO就是一模一样的了,reward为1,这些token的advantage就是1,reward为-1,这些token的advantage就是-1。
在actor update阶段,decoupled GAE会在policy update时的advantage估计用的lambda设置为一个小于1的数字(VC-PPO为常数0.95,VAPO中长度越长,离1越近),这个操作实际上借用了t时刻后面所有的时刻i的 ,来一起估算Advantage,这样的估计可以降低方差。这个方式如果work,其实一定程度上意味着目前Value的估计是非常不准确的。
第七部分 畅想
在这段RL探索过程中,我有一种明显的感觉是,目前公开的对LLM的推理的RL方法上还远没有到极限。主要基于以下两点:
-
• 目前的LLM上面的RL方法还是比较粗糙的,GRPO的方法在sample中不分好坏全部优化,需要借助大量rollout去做平均和对冲。PPO中引入的value model能够让优化变成token级别不同的状态,但是目前做的还不够精细。
-
• 目前模型的探索还是非常需要借助base 模型的,这就意味着模型会有一个上限,没办法冲破天际去持续提升。
相信在未来,还能看到很多RL算法的进化。这里根据上面的观察,畅想一些可能的方向:
-
• 更准确的Value Estimation,当可以做到非常准确的时候,甚至是不用decoupled GAE去降低variance的。这样才能更好地发挥PPO的效果;
-
• 对trial and learn的RL范式进行修改,引入更多generative的方式,让RL的进化方向更可靠,让模型可以更多地偏离base模型去稳定提升;
当然,基于Math上面的算法迭代出来的模型基本只有研究意义。要想产生价值,至少要把领域扩充到各种问题上,变成一个比较全能的model。或者升级虚拟环境、物理环境的agent。
从技术发展上来讲,我对目前和未来的技术发展速度是非常乐观的。可能只需要在文本、多模的基础模型以及RL算法上面再出现两三次重大技术突破,一个真的可以干活的agent就会出现,并且给社会带来巨大改变。再往后,我也不知道了。
引用链接
[1] R1/R1-Zero:https://doi.org/10.48550/arXiv.2501.12948[2]GRPO:https://doi.org/10.48550/arXiv.2402.03300[3]DAPO:https://doi.org/10.48550/arXiv.2503.14476[4]Sober Reasoning:https://doi.org/10.48550/arXiv.2503.01491[5]kimi1.5:https://doi.org/10.48550/arXiv.2501.12599[6]VC-PPO:https://doi.org/10.48550/arXiv.2503.01491[7]VAPO:https://doi.org/10.48550/arXiv.2504.05118

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献391条内容
已为社区贡献391条内容

所有评论(0)