什么是高质量数据集?如何建设高质量数据集?
摘要: 高质量数据集是AI训练的基础,需具备完整性、准确性等标准。当前全球开源数据集中英语占比56.9%,中文仅5.6%,制约中国AI发展。数据集短缺源于标准缺失、共享不足等问题,影响模型效果。评估数据集需从定量、定性多维度分析,包括规范性、均衡性等指标。AI大模型是未来趋势,学习资源包括路线图、面试题等可免费获取,助力零基础者入门。(150字)
一、高质量数据集是什么?
高质量数据集是指具有一定主题,可以标识并可以用于人工智能训练、验证及测试等处理过程的数据形式,并且在完整性、规范性、准确性、均衡性、及时性、一致性、相关性等多个方面都达到了较高标准的数据集合。能够帮助研究人员、工程师和人工智能在开展数据分析、机器学习和模型计算时获得更可靠的结果。
二、为什么需要高质量数据集?
数据集是人工智能“学习”的基础和源泉。从全球开源数据集语种来看,英语是世界上分布最广泛的语言,其开源数据集占比也最高,截至2023年底达到了56.9%;美国、英国等以英语为主的国家为英语开源数据集的积累奠定了良好的基础。
作为世界上使用人数最多的语言之一,中文开源数据集占比仅为5.6%,暴露出中国在数字基础设施建设方面的短板,这与中国在人工智能领域的发展实力和愿景不符。造成国内高质量数据集紧缺的原因是多方面的,包括数据标准和规范的缺失、数据共享和开放程度低、数据处理投入不足等。数据集的紧缺会限制人工智能算法的训练效果,影响模型的准确性和泛化能力。
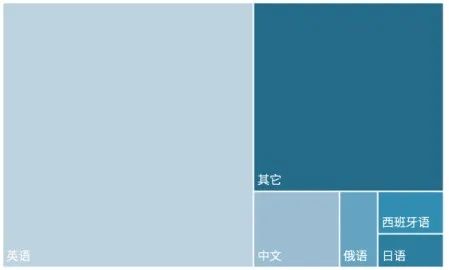
图表:截至2023年底全球按语言划分的开源数据集百分比(单位:%)
三、如何评估高质量数据集?
根据《面向人工智能的数据集通用评估方法》,面向人工智能应用的数据集质量评估需要遵循科学的评估方法,基于人工智能应用需求与数据集质量目标选取合适的评估指标和相应的评估准则。人工智能数据集的评估主要分为定量、定性以及将前两者有机集合起来进行综合分析的方法。人工智能数据集的质量评估主要包括完整性、规范性、准确性、均衡性、及时性、一致性、相关性和其他等维度。




来源:数据学堂、CDO研习社
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)