NeurIPS2025 |DMMV:自适应分解 + 门控机制,43 次登顶 SOTA后拿捏LTSF 周期偏置难题!
来自NeurIPS2025,最新前沿时序技术,针对长期时间序列预测与视觉大模型的融合应用的难题,提出了一种分解式多模态视图框架 DMMV。
收假快乐呀~久违的双节8天假结束了,小时又得回来继续读论文了!
本篇论文来自NeurIPS2025,最新前沿时序技术,针对长期时间序列预测与视觉大模型的融合应用的难题,提出了一种分解式多模态视图框架 DMMV。
国庆几天小时跟小伙伴们也没闲着,重新整理以及补充了2025顶会时序合集,整合了更完整的“2025顶会时序合集”,包含论文及代码,无偿分享给大家~需要的可以在宫🀄蚝“时序大模型”回复“资料”自取~
文章信息
论文名称:Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
论文作者: ChengAo Shen, Wenchao Yu, Ziming Zhao, Dongjin Song, Wei Cheng, Haifeng Chen, Jingchao Ni

研究背景
长期时间序列预测(LTSF)在地球科学、神经科学、能源、医疗健康等多个领域至关重要。近年来,受 Transformer 和大型语言模型(LLMs)在自然语言领域成功的启发,研究者开始探索类似架构用于时间序列预测,同时,视觉大模型(LVMs,如 ViT、BEiT、MAE)在视觉领域的突破也促使其被尝试应用于 LTSF。
时间序列可通过数值序列、图像、文本等多种模态视图(MMVs)呈现,这些视图能揭示互补模式,并让 LVMs 等预训练大模型得以应用。然而,现有研究存在不足:
-
直接将 LVMs 应用于 LTSF 时,会因基于周期的成像方式产生对 “预测周期” 的归纳偏置,过度关注周期性而忽略全局趋势。
-
现有多模态方法(如 Time-VLM)融合策略简单,未考虑各视图独特归纳偏置,且文本输入提升有限却增加计算开销。
-
分解方法在时间序列预测中应用广泛,但现有分解方法未结合 LVMs 的特性。
为解决上述难题,提出分解式多模态视图框架 DMMV,可以利用趋势 - 季节分解和基于回溯残差的自适应分解,整合多模态视图以优化 LTSF 性能。
模型框架
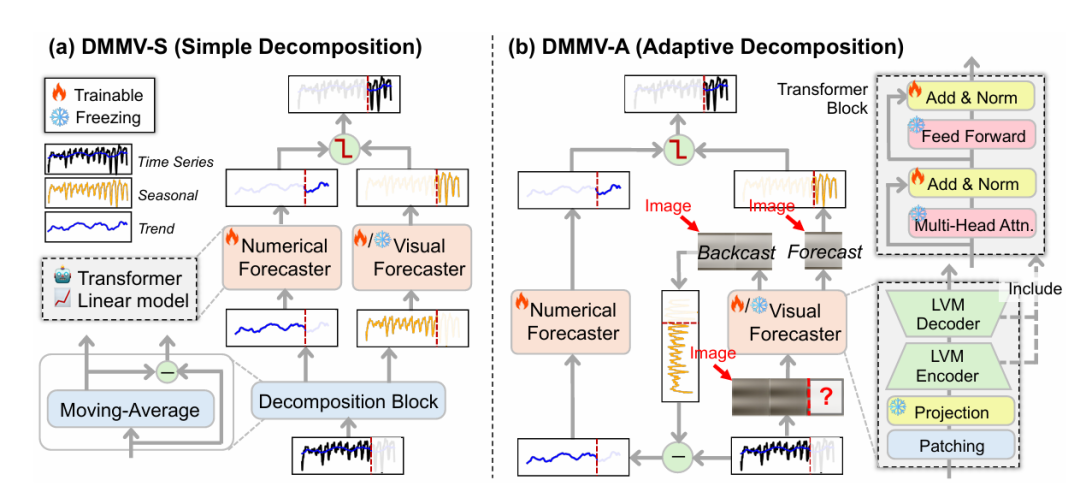
DMMV框架:是基于分解的多模态视图框架,整合数值和视觉视图,排除文本视图(因提升有限且开销大),包含数值预测器和视觉预测器,通过后期融合(门控机制)结合两者输出,分为 DMMV-S(简单分解)和 DMMV-A(自适应分解)两个变体。
问题定义:给定多元时间序列(回溯窗口长度为 T),目标是预测未来 H 个时间步的MTS
最小化均方误差:
1.基础准备
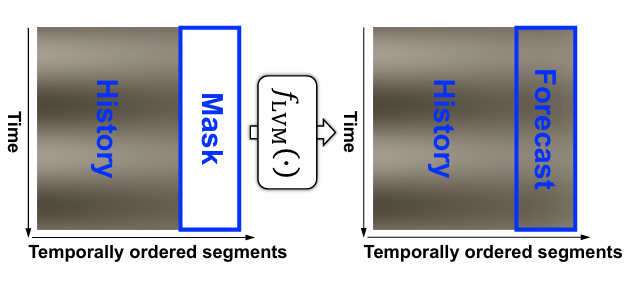
MAE:通过重建被掩码的图像块在 ImageNet 上自监督预训练。
时间序列成像:借鉴 TimesNet 的周期成像技术,将长度为 T 的分割为个长度为 P(周期,通过 FFT 或采样频率先验知识获取)的子序列。堆叠为 2D 图像,经标准化、灰度图像转换和双线性插值, resize 为 224×224×3 以适配 MAE 输入。预测时通过重建图像右侧掩码区域实现,再经反标准化和逆变换得到时间序列预测结果。
2.DMMV-S(简单分解)
分解方式:采用移动平均分解,用长度为的滑动窗口提取趋势成分(低频部分),残差为季节成分(周期性部分):
预测器设计:
-
视觉预测器:将季节成分转换为图像,通过 MAE 输出季节成分预测。
-
数值预测器:可选线性模型 或基于 Transformer 的模型(借鉴 PatchTST,将趋势成分分割为补丁,经投影、位置编码、Transformer 编码和线性变换输出趋势预测 。
融合方式:通过门控机制融合,,其中 。
3.DMMV-A(自适应分解)
分解逻辑:通过回溯残差机制,根据数值和视觉预测器的优势自适应分解时间序列,无需预先定义分解核大小。
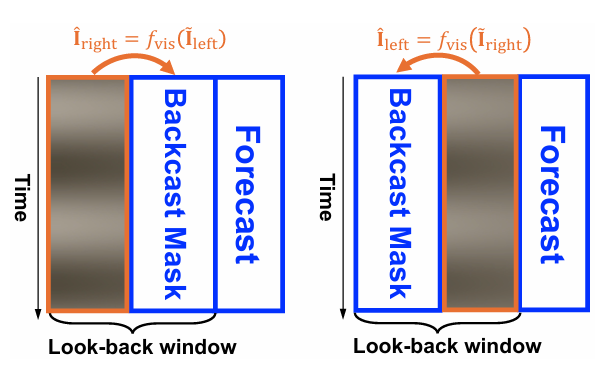
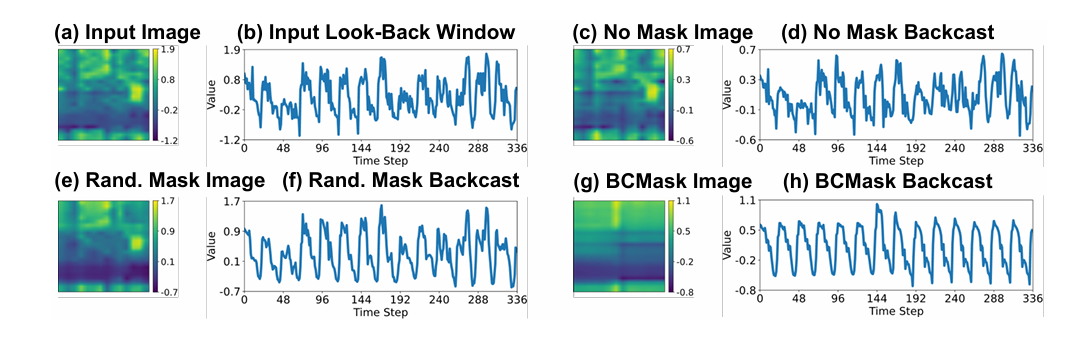
回溯掩码(BCMASK)策略:分两次对图像进行掩码和重建,第一次掩码左侧、保留右侧,重建左侧;第二次掩码右侧、保留左侧,重建右侧,最终拼接得到完整回溯图像 ,满足全窗口重建、与预测流程对齐、低计算开销的需求。
成分提取:回溯图像经反标准化和逆变换得到回溯时间序列(反映周期性成分),残差 为趋势成分。
预测与融合:视觉预测器从预测季节成分 ,数值预测器从 预测趋势成分 ,同样通过门控机制融合:。
4.模型优化
损失函数:最小化预测值与真实值的 MSE。
训练策略:
-
数值预测器从头训练,视觉预测器使用预训练 LVM 权重,仅微调归一化层(性能最佳)。
-
分两阶段训练:先冻结视觉预测器,训练数值预测器(约 30 轮);再解冻视觉预测器的归一化层,与数值预测器联合微调至收敛或早停。

实验数据
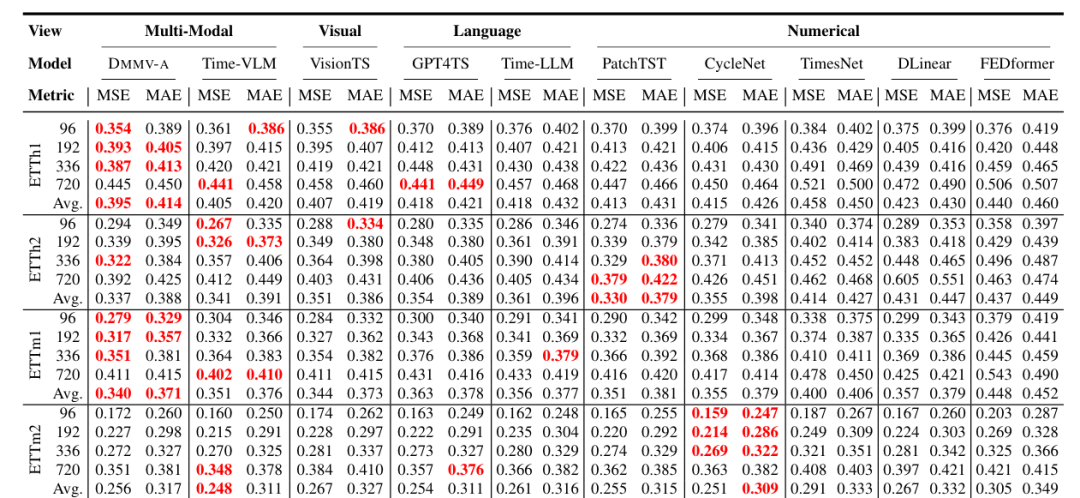
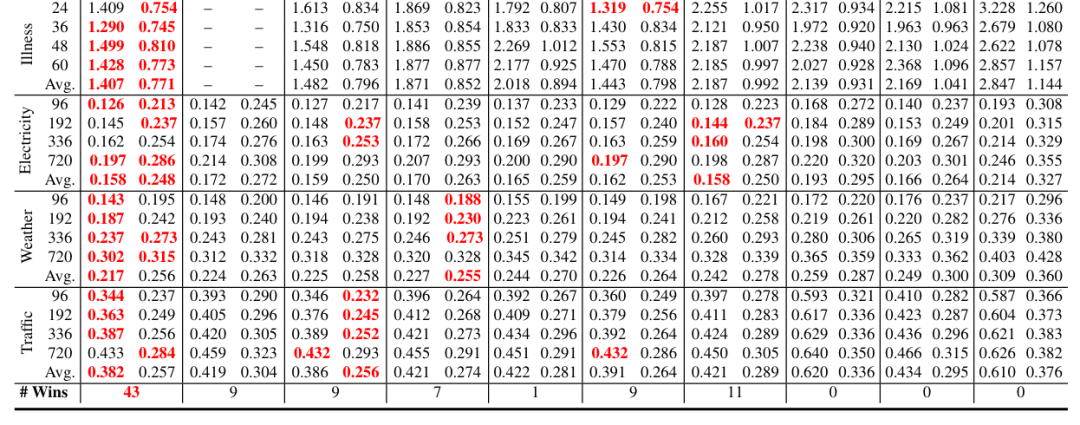
数据集:8 个常用 MTS 基准数据集,包括 ETT 系列(ETTh1、ETTh2、ETTm1、ETTm2,变压器油温数据)、Weather(气象数据)、Illness(流感类疾病数据)、Traffic(交通数据)、Electricity(电力消耗数据),按时间顺序划分训练 / 验证 / 测试集,预测 horizon(H)和回溯窗口(T)按数据集特性设置。
对比方法:14 个 SOTA 模型,涵盖多模态(Time-VLM)、视觉视图(VisionTS)、语言视图(Time-LLM、GPT4TS、CALF)、Transformer 类(PatchTST、FEDformer 等)、非 Transformer 类(DLinear、TimesNet 等)。
评价指标:MSE 和 MAE。
核心实验结果
性能对比:DMMV(尤其是 DMMV-A)在 8 个基准数据集中的 6 个上取得最佳 MSE,在多模态、视觉视图、语言视图、数值视图等各类方法中表现最优,43 次获得第一,优于包含额外文本编码器的 Time-VLM。
关键发现:
-
多模态和视觉视图方法整体优于语言视图方法,体现 LVMs 在时间序列预测中的有效性。
-
数值视图模型(如 PatchTST、CycleNet)在部分数据集(如 ETTm2、Electricity)上仍具竞争力,可与视觉模型互补。
-
VisionTS 在高周期性数据集(如 ETTh1、ETTm1、Traffic)上表现较好,但 DMMV-A 缓解了其周期偏置,泛化性更强。
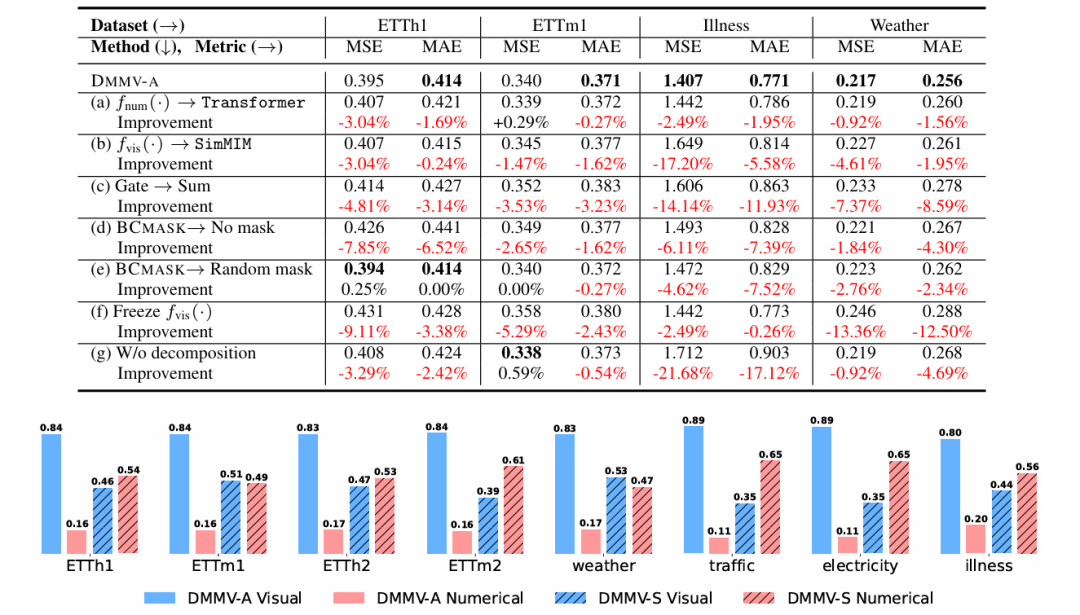
消融实验(以 DMMV-A 为例)
-
数值预测器:线性模型优于 Transformer(Transformer 增加训练难度)。
-
视觉模型:MAE 优于 SimMIM(MAE 的 ViT-based 重建解码器更适配像素级 LTSF 任务)。
-
融合方式:门控融合优于简单求和(能自适应匹配两预测器输出特性)。
-
掩码策略:BCMASK 至关重要,无掩码或随机掩码会导致周期性提取不佳,削弱趋势信号。
-
训练策略:微调视觉模型归一化层优于完全冻结(促进两预测器协同学习)。
-
分解机制:移除回溯残差分解会大幅降低性能,验证其分解有效性。
性能分析
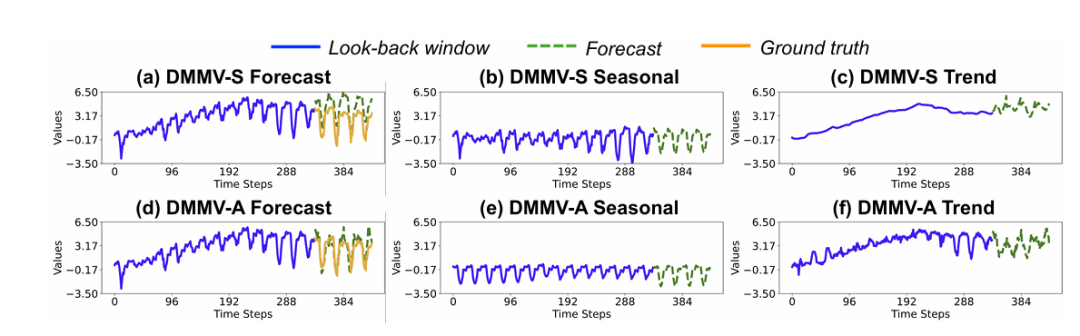
DMMV-S 与 DMMV-A 对比:DMMV-A 因自适应分解,门控权重更倾向于视觉预测器(基于预测性能学习),分解出更清晰的周期性成分和合理趋势成分,预测更贴合真实值;DMMV-S 受固定移动平均分解限制,权重分配非自适应,季节成分含噪声,预测性能较弱。
BCMASK 有效性:BCMASK 能生成时间维度平滑的图像,有效捕捉周期性模式;无掩码则复制输入,无意义分解;随机掩码周期性提取效果较差。
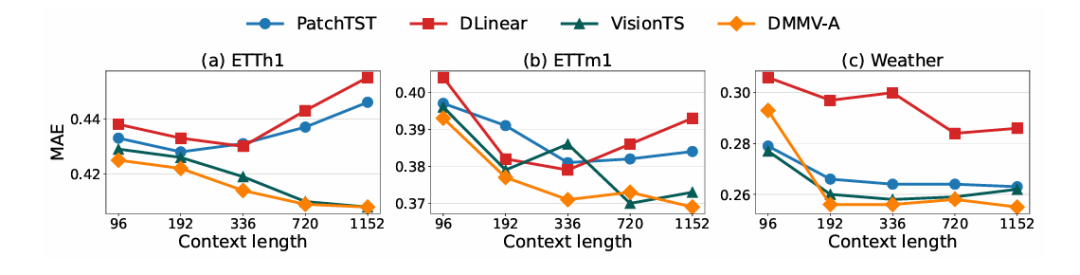
回溯窗口影响:DMMV-A 和 VisionTS 受益于更长回溯窗口,而 PatchTST、DLinear 在窗口长度超过 336 后性能下降;DMMV-A 在窗口长度 1152 时仍优于 VisionTS,体现全局趋势建模优势。
小小总结
文章提出的分解式多模态视图框架 DMMV,针对性解决视觉大模型应用于长期时间序列预测时存在的 “预测周期” 归纳偏置问题,通过趋势 - 季节分解与回溯残差自适应分解整合数值、视觉视图,排除低效文本视图,兼顾周期性与全局趋势捕捉。
设计了 DMMV-S(简单移动平均分解)与 DMMV-A(回溯残差自适应分解)两个变体,前者明确拆分趋势与季节成分,后者通过 BCMASK 掩码策略自适应学习分解,适配不同预测需求,且采用门控机制实现后期融合,充分发挥双预测器优势。
关注小时,持续学习前沿时序技术!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)