大模型微调(一)为什么要模型微调?
解读Lawyer LLaMA,延申自己领域大模型微调:数据集构建,模型训练自己领域的大模型微调,实现思路大都和这篇文章是一样的,有的是基于LLaMA,或者有的是基于Chinese-LLaMA,或者是其他开源的大模型,本文基于自己训练过程和参考了老刘说NLP中的《也读Lawyer LLaMA法律领域微调大模型:从训练数据、模型训练到实验效果研读》,从模型要达到的结果出发,倒推介绍整个流程,供大家参考
为什么要模型微调
「微调」 是利用预训练LLM并训练至少一个内部参数(即权重),通常是使用预训练好的通用基础模型(例如GPT-3)转换为特定用例(例如 ChatGPT)的专用模型。
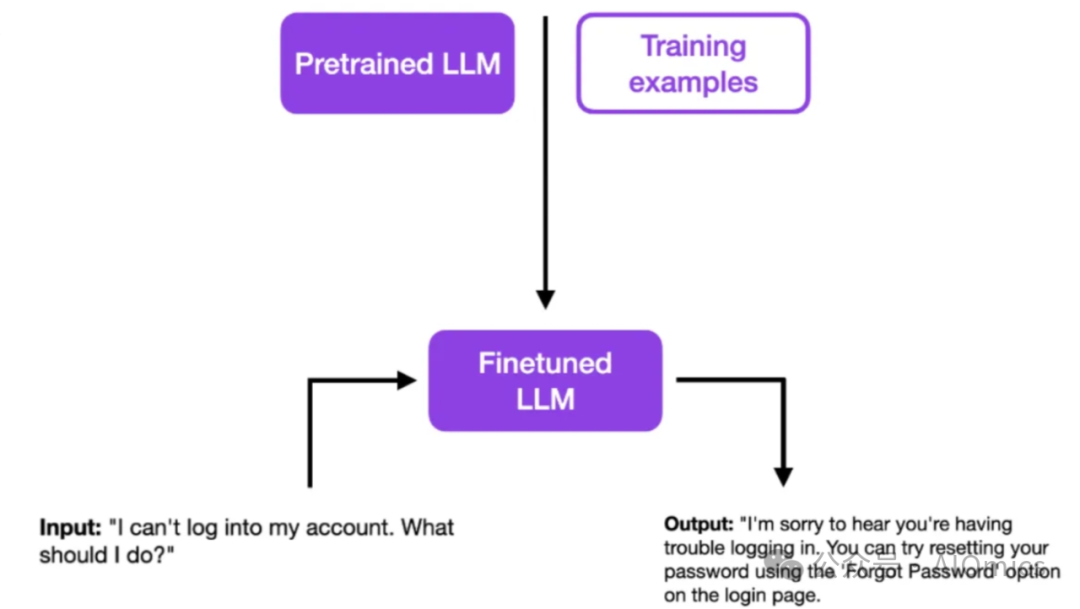
与完全依赖 「监督训练」 的模型做提示词工程相比,微调后的模型可以实现更好的性能,同时需要(远)更少的手动标记示例(优点之一)。
虽然在提示工程的帮助下,严格的 「自监督基础模型」 可以在多种任务中表现较好的性能,但这些基础模型仍然是单词预测器,可能生成不完全有用或不准确的结果。由于LLM是有限上下文窗口(context window),所以这些模型在需要大量特定领域知识的任务上性能有限。微调模型可以通过在微调过程中“学习”这些特定领域信息来避免此问题。这也避免使用额外的上下文填充提示,从而降低推理成本。
例如,比较 davinci(基于GPT-3模型)和 text-davinci-003(微调模型)如下。

text-davinci-003 是对齐微调(alignment tuning[1]),旨在使 LLM 的响应更有帮助、更诚实、更无害。
微调不仅可以提高基础模型的性能,而且针对较小的预训练模型进行特定任务集的微调通常可以胜过较大的模型。OpenAI 用他们的第一代“InstructGPT[2]”模型已证明,1.3B参数 InstructGPT 模型的完成率优于175B参数 GPT-3 基本模型。
- [](javascript:;)赞
- [](javascript:;)收藏
- [](javascript:;)评论
- [](javascript:;)分享
- [](javascript:;)举报
下一篇:大模型入门 | 给普通开发者如何入局 AI 的几点建议!

提问和评论都可以,用心的回复会被更多人看到 评论
发布评论
全部评论 () 最热 最新
相关文章
-
[
什么是Token?为什么大模型要计算Token数
大模型不是直接做的“字符”的计算,而是将字符变成一个数字,也就是变成了 token 来处理。
](https://blog.51cto.com/u_15214399/10947027)
API Token 大模型 LLM
-
[
腾讯LLaMA Pro大模型:突破大模型微调的知识遗忘难题
大学与腾讯ARC实验室合作开发的LLaMA ,解决了大语言模型微调中的知识遗忘难题。通过独创的Block Expansion方法,LLaMA 在保持原有模型知识的基础上,有效整合新知识。该模型在代码理解和数学推理任务上表现卓越,同时在语言理解方面也有所提升,开启了大模型微调的新篇章。
](https://blog.51cto.com/u_16323307/9424253)
数据集 数学推理 语言模型
-
[
微调大模型:提高其代码修复能力的尝试
随着大型模型技术的日益成熟,涌现出CodeLlama、CodeGeex等代码生成能力较强的模型,催生了一批基于大模型的代码工具,逐步改变软件开发模式。随着技术发展最终会带来软件开发领域的变革。
](https://blog.51cto.com/u_17016983/11999939)
软件开发 应用场景 技术方案
-
[
开源模型微调是什么?为什么要进行模型微调
开源模型微调是指在已经预训练好的开源机器学习模型(例如语言模型、图像分类模型等)的基础上,进行额外的训练,以便使其适应特定任务或特定数据集。微调通常涉及在预训练模型的基础上,使用特定任务的数据进行少量的额外训练,从而优化模型在该任务上的性能。进行模型微调的主要原因包括以下几点:提高模型的特定任务性能:适
](https://blog.51cto.com/u_13171517/11327196)
模型微调 数据集 机器学习 语言模型
-
[
大模型微调基本概念(二)什么是大模型微调、为什么需要微调、微调方法分类、训练框架选择
大模型微调,通常指有,是在预训练模型(一般称为“基座模型”)的基础上进行的训练过程。预训练模型通常已经掌握了广泛的语言知识和语义表示,但为
](https://blog.51cto.com/u_16163510/12218853)
深度学习 人工智能 AI大模型 大模型 ai
-
[
大模型微调学习
一、大模型微调定义大型模型微调即是向模型“输入”更多信息,对模型的特定功能进行“优化”,通过输入特定领域的数据集,使模型学习该领域知识,从而优化大模型在特定领域的NLP任务中的表现,如情感分析、实体识别、文本分类、对话生成等。LLM微调是一个将预训练模型在较小、特定数据集上进一步训练的过程,目的是精炼模型的能力,提高其在特定任务或领域上的性能。「微调的目的是将通用模型转变为专用模型,弥合通用预训练
](https://blog.51cto.com/u_6478076/13962081)
大模型微调
-
[
【深度学习:大模型微调】如何微调SAM
Segment Anything 模型 (SAM) 是由 Meta AI 开发的细分模型。它被认为是计算机视觉的第一个基础模型。SAM在包含数百万张图
](https://blog.51cto.com/u_16742305/10661512)
深度学习 人工智能 数据集 编码器 数据
-
[
大模型微调(三)监督微调的步骤
给大家分享一本大模型入门书籍《从零开始大模型开发与微调:基于PyTorch与ChatGLM》,适合PyTorch深度学习初学者、
](https://blog.51cto.com/u_15620990/11792208)
人工智能 AI ai 大模型 大模型微调
-
[
【大模型微调】一文掌握7种大模型微调的方法
本篇文章深入分析了大型模型微调的基本理念和多样化技术,细致介绍了LoRA、适配器调整(Adapter Tuning)、前缀
](https://blog.51cto.com/u_16163452/12682424)
人工智能 自然语言处理 语言模型 agi ai
-
[
模型微调 python 模型微调 大模型
一、RLHF微调三阶段 参考:https://huggingface.co/blog/rlhf 1)使用监督数据微调语言模型,和fine-tuning一致。 2)训练奖励模型 奖励模型是输入一个文本序列,模型给出符合人类偏好的奖励数值,这个奖励数值对于后面的强化学习训练非常重要。构建奖励模型的训练数据一般是同一个数据用不同的语言模型生成结果,然后人工打分。如果是训练自己
](https://blog.51cto.com/u_16213653/8409192)
模型微调 python 数据 强化学习 git
-
[
大模型微调的架构 什么是模型微调
前言什么是模型的微调? 使用别人训练好的网络模型进行训练,前提是必须和别人用同一个网络,因为参数是根据网络而来的。当然最后一层是可以修改的,因为我们的数据可能并没有1000类,而只有几类。把最后一层的输出类别和层的名称改一下就可以了。用别人的参数、修改后的网络和自己的数据进行训练,使得参数适应自己的数据,这样一个过程,通常称之为微调(fine tuning). 微调时候网络参数是否更新?
](https://blog.51cto.com/u_13360/13985904)
大模型微调的架构 开源框架 caffe 微调 数据库
-
[
大模型微调 pytorch 大模型微调数据集
llama-7b模型大小大约27G,本文在单张/两张 16G V100上基于hugging face的peft库实现了llama-7b的微调。1、模型和数据准备使用的大模型:https://huggingface.co/decapoda-research/llama-7b-hf,已经是float16的模型。微调数据集:https://github.com/LC1332/Chinese-alpa
](https://blog.51cto.com/u_16099239/11861169)
大模型微调 pytorch python 数据 github
-
[hanlp 微调模型 什么是模型微调
前言 什么是模型的微调? 使用别人训练好的网络模型进行训练,前提是必须和别人用同一个网络,因为参数是根据网络而来的。当然最后一层是可以修改的,因为我们的数据可能并没有1000类,而只有几类。把最后一层的输出类别和层的名称改一下就可以了。用别人的参数、修改后的网络和自己的数据进行训练,使得参数适应自己的数据,这样一个过程,通常称之为微调(fine tuning).](https://blog.51cto.com/u_12207/10879966)
hanlp 微调模型 深度学习 Caffe 解决方案 数据库
-
[
embedding模型微调 什么是模型微调
特征提取微调首先要弄清楚一个概念:特征提取。 用于图像分类的卷积神经网络包括两部分:一系列的卷积层和池化层(卷积基) + 一个密集连接分类器。对于卷积神经网络而言,特征提取就是取出之前训练好的网络的卷积基,用新数据训练一个新的分类器。那么为什么要重复使用之前的卷积基,而要训练新的分类器呢?这是因为卷积基学到的东西更加通用,而分类器学到的东西则针对于模型训练的输出类别,并且密集连接层舍弃了空间信息。
](https://blog.51cto.com/u_14230/10272726)
embedding模型微调 深度学习 神经网络 cnn 卷积
-
[
aigc模型微调 什么是模型微调
迁移学习(Transfer Learning)迁移学习是机器学习的分支,提出的初衷是节省人工标注样本的时间,让模型可以通过一个已有的标记数据向未标记数据领域进行迁移从而训练出适用于该领域的模型,直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。 举一个例子就能很好的说明问题,我们学习编程的时候会学习什么?语法、特定语言的API、流程处理、面向对象,设计模式和面
](https://blog.51cto.com/u_16213632/10131810)
aigc模型微调 学习 迁移学习 人工智能 数据
-
[
ollama模型 微调 什么是模型微调
这段时间在系统学习tensorflow的相关知识,恰好学习到了tensorflow的slim轻量级开发库。这个库的目的在于用尽量少的成本组织起来一套可以训练和测试自己的分类任务的代码,其中涉及到了迁移学习,所以我们分为下面几个步骤介绍: 什么是迁移学习; 什么是TF-Slim; TF-Slim实现迁移学习的例程; 应用自己的数据集完成迁移学习。&nb
](https://blog.51cto.com/u_16213570/11095404)
ollama模型 微调 数据集 python git
-
[lora微调llama模型 什么是模型微调
深度学习中的fine-tuning一. 什么是模型微调1. 预训练模型 (1) 预训练模型就是已经用数据集训练好了的模型。 (2) 现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数;](https://blog.51cto.com/u_16099190/10310543)
lora微调llama模型 深度学习 机器学习 微调 预训练模型
-
[
大模型微调 swift
ChatGPT带领着大模型像雨后春笋一般层出不穷,大家都对大模型微调跃跃欲试,现在咱们聊聊其中的常见的算法1 LORA 低秩适应理论Lora( Low-Rank Adaotation),低秩自适应模型微调的方法,它冻结预训练模型的权重,并将可训练的秩分解矩阵注入到transformer架构的每一层,从而大大减少下游任务的可训练参数的数量,怎么微调下游任务:利用LoRA对下游任务数据训练时,只通过训
](https://blog.51cto.com/u_14850/13560459)
大模型微调 swift 算法 矩阵 机器学习 人工智能
-
[
大模型微调outofmemory
解读Lawyer LLaMA,延申自己领域大模型微调:数据集构建,模型训练自己领域的大模型微调,实现思路大都和这篇文章是一样的,有的是基于LLaMA,或者有的是基于Chinese-LLaMA,或者是其他开源的大模型,本文基于自己训练过程和参考了老刘说NLP中的《也读Lawyer LLaMA法律领域微调大模型:从训练数据、模型训练到实验效果研读》,从模型要达到的结果出发,倒推介绍整个流程,供大家参考
](https://blog.51cto.com/u_16099278/11907246)
大模型微调outofmemory llama 自然语言处理 人工智能 数据
-
[
python大模型微调
1. AlexNet的网络结构AlexNet总共包含8层变换,分别为5层卷积层、2个全连接层和一个全连接输出层第一层卷积窗口的形状为11*11第二层卷积窗口的形状缩减为5*5第三层到第五层卷积窗口均为3*3第六层全连接层输入为25655,输出为4096,激活函数采用了ReLu第七层全连接层输入为4096,输出为4096,激活函数采用了ReLu由于原模型是使用imagenet数据集进行训练的,所以输
](https://blog.51cto.com/u_16213577/12361283)
python大模型微调 python pytorch alexnet 图像增广
-
[
jest mock 组件 jetpack常用组件
文章目录JetPackLifecycle使用Lifecycle解耦页面和组件使用Lifecycle解耦Service与组件使用ProcessLifecycleOwner监听应用程序生命周期ViewModel 与 LiveDataViewModelLiveDataViewModel + LiveData 实现Fragment间通信DataBinding 的意义与应用意义使用前的配置import标签事
](https://blog.51cto.com/u_12902/14032805)
jest mock 组件 android 开发语言 JetPack ide
-
[
python 中 for 后置 python里的for语句
流程控制语句包括If条件判断语句、While循环语句及For循环语句。If 条件判断If语句允许您检查程序的当前状态,并对该状态作出适当的响应。可以编写一个简单的If语句来检查一个条件,也可以创建一系列复杂的if语句来标识您正在寻找的确切条件。条件测试条件测试是一个表达式,可以计算为真或假。Python使用True和False值来决定是否执行If语句中的代码。>>> x == 4
](https://blog.51cto.com/u_16099331/14033214)
python 中 for 后置 列表 python 编程语言 软件测试
-
[
iOS 绘制 线条 苹果手绘线稿
该文章中文采取的直接网页翻译而来本教程将教您如何在iOS设备上实现高级绘图算法,以实现流畅的手绘。继续阅读理论概述触摸是用户与iOS设备交互的主要方式。这些设备预期提供的最自然和最明显的功能之一是允许用户用手指在屏幕上画画。目前App Store中有许多徒手绘制和记笔记应用程序,许多公司甚至要求客户在购买时签署iDevice。这些应用程序如何实际工作?让我们停下来思考一下“引擎盖下”是怎么回事。当
](https://blog.51cto.com/u_16099336/14033501)
iOS 绘制 线条 ios 绘图 应用程序 子类
-
[
Android替代service
期待的事情如期而至,众所周知,国产手机的操作系统一直被安卓垄断着,经过上次的芯片垄断事件越来越多的人认识到了自主研发的重要性。既然芯片可以一下子被美国掐住脖子,那么在不久的将来操作系统也会面临同样的困境。很久之前就有关于华为自主研发的传闻,但是华为的回应是:并没有自主研发独立操作系统的计划。这种传闻到底是不是空穴来风,一直是困扰在广大中国用户心中的一个心结,起码反应了在大多数用户心中对于国产独立系
](https://blog.51cto.com/u_16213566/14033528)
Android替代service 技术支持 IT Android
-
[
Android ptp速率 android bpn
Androidpn其中一个比较成熟的解决方案便是使用XMPP协议实现。而AndroidPn项目就是使用XMPP协议实现信息推送的一个开源项目。Apndroid Push Notification的特点: 快速集成:提供一种比C2DM更加快捷的使用方式,避免各种限制. 无需架设服务器:通过使用"云服务",减少额外服务器负担. 可以同时推送消息到网站页面,andr
](https://blog.51cto.com/u_16099170/14033840)
Android ptp速率 android 服务器 下载地址
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 36
36 0
0- 0



 已为社区贡献195条内容
已为社区贡献195条内容

所有评论(0)