微软最新 GraphRAG V2.4.0 全流程手把手使用教程
微软GraphRAG:基于知识图谱的增强检索生成技术 摘要:微软GraphRAG通过构建知识图谱克服了传统RAG技术的局限性。该技术利用LLM从私有数据创建知识图谱,结合图机器学习实现更精准的信息检索。相比基于文本分割的RAG,GraphRAG能更好地保持语义完整性,支持跨文档关联分析,特别适合企业知识库应用。当前版本V2.4.0采用MIT许可,支持Python 3.10-3.12环境,提供命令行
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索和生成的人工智能技术,用于提升大模型生成内容的准确性和相关性。目前,许多企业将 RAG 作为企业知识库的标准应用,但基于文本分割的传统 RAG 存在一些局限性:
- 不均匀分割:文本分割可能导致语义不完整或碎片化,影响检索准确性。例如,过短的片段可能丢失上下文,过长则可能包含无关信息。
- 语义丢失:基于字符数或句子的分割方法可能切分关键信息点,破坏语义连贯性。
- 缺乏信息连接:难以通过共享属性连接不同信息片段,影响综合见解的生成。
- 缺乏整体性:在需要全面理解大型数据集或单个文档的总结性语义时,表现不佳。
微软GraphRAG就是为了解决这个问题而产生。GraphRAG 利用大语言模型(LLM)基于私有数据集创建知识图谱。然后,该知识图谱结合图机器学习技术,在查询时进行RAG。GraphRAG 在回答上述两类问题时表现出显著的改进,展现出超越此前应用于私有数据集的能力。
详见微软GraphRAG的 Research Blog
GraphRAG: Unlocking LLM discovery on narrative private data
https://www.microsoft.com/en-us/research/blog/GraphRAG-unlocking-llm-discovery-on-narrative-private-data/
GraphRAG 的当前版本为 V2.4.0,在 GitHub 上已获得 27.1k 个 Star,采用 MIT License,易于使用。
项目github地址为
https://github.com/microsoft/GraphRAG
项目也有自己单独的网站给出详细的使用指南 https://microsoft.github.io/GraphRAG/
使用GraphRAG有多种方法,比较常用的是用command-line直接运行,因为我们需要build到整个工作流中,所以使用的是API调用方式直接集成到工作流中。
第一步:准备工作
- Python 版本,GraphRAG使用的python版本是 Python 3.10-3.12
- Install GraphRAG
可使用熟悉的工具 pip 或 uv 直接安装 GraphRAG
例如 pip install GraphRAG 或者uv add GraphRAG
3.初始化GraphRAG 配置文件,GraphRAG的配置都是在settings.yaml 文件,需要用初始化命令初始化配置文件。
初始化命令为 GraphRAG init [--root PATH] [--force, --no-force]
例如GraphRAG init --root ./ragtest,将在项目目录下 ./ragtest的目录下建立3个文件或者文件夹
settings.yaml - 配置文件。此文件包含 GraphRAG 的配置设置。
.env - 环境变量文件。这些变量在 settings.yaml 文件中被引用。
prompts/ - 大语言模型提示文件夹。此文件夹包含 GraphRAG 使用的默认提示。
到这一步基本准备工作就做好了,接下来对 settings.yaml 进行详细配置。
第二步:settings.yaml 配置
settings.yaml 的详细配置请参考 https://microsoft.github.io/GraphRAG/config/overview/ 中Default Configuration Mode (using YAML/JSON)章节。
实际使用中,大部分设置可保持默认,文档已详细说明。这里需要提一下,models一般情况下需要修改,因为GraphRAG默认使用的是两种 Model,openai 和 azure openai,这两种model在国内并不普遍。如果需要使用自定义model,需要实现自定义model。
Doc中给出了自定义model的介绍 https://microsoft.github.io/GraphRAG/config/models/,
下面是自定义model的实现例子
请参考 https://github.com/microsoft/GraphRAG/blob/main/tests/mock_provider.py
根据例子实现自己的model provider后,需要在你的主程序中注册一下model然后在settings.yaml 文件中设置自己的自定义model
注册语句如下,直接复制到自己主程序就行
ModelFactory.register_chat("my-custom-chat-model", lambda **kwargs: MyCustomModel(**kwargs))
ModelFactory.register_chat("my-custom-embedding-model", lambda **kwargs: MyCustomModel(**kwargs))
Settings.yaml 文件model 设置如下
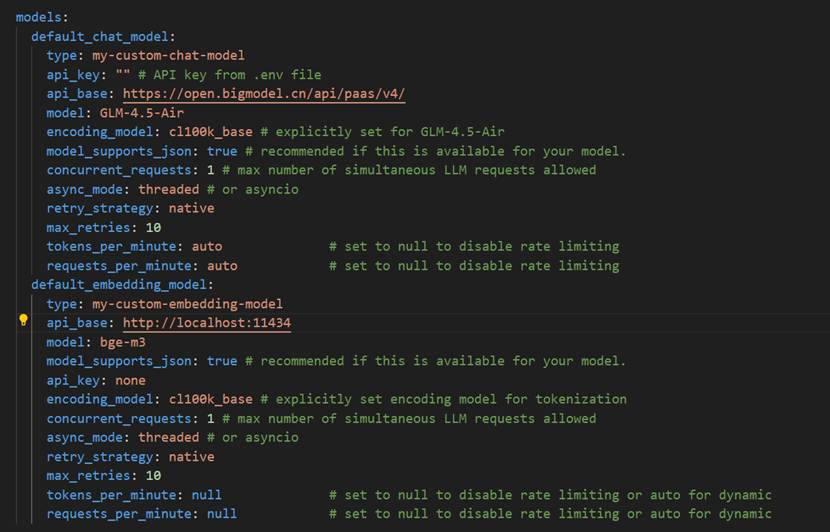
在做自定义model的实现的时候请注意一个细节,这个问题让我花了2天时间跟到源代码中才解决,在 create_community_reports 步骤中,总是报KeyError: 'community', 通过查看日志,发现 create_community_reports 时提示“No report found for community”。前面步骤的输出正常,最后跟踪 community_reports_extractor.py 代码后发现,LLM 正常输出结果,但 response.parsed_response 未正确解析。在自定义model代码中添加解析支持后,流程正常运行。
第三步:Indexing
到这一步设置结束就可以进行Indexing了,可以参考doc中给出的例子实现自己的Indexing流程
https://github.com/microsoft/GraphRAG/blob/main/GraphRAG/api/index.py
最后log输出如下结果就恭喜你,说明整个Indexing成功了
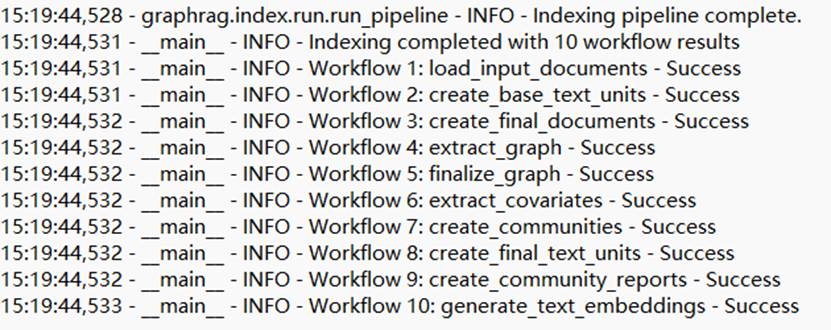
请注意,执行 Indexing 非常耗时且成本较高。例如,使用微软提供的示例电子书《A Christmas Carol》建立Indexing,运行一次需消耗几十万 Token。
以下是output路径下有很多输出文件
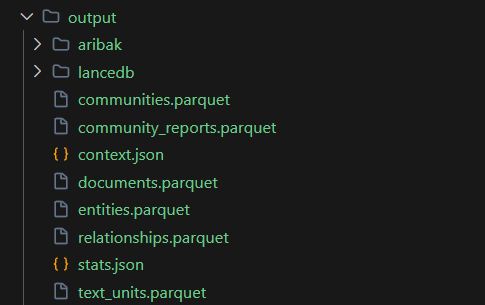
GraphRAG的最终输出是放到向量数据库lancedb中
所有输出文件的详细描述如下
https://microsoft.github.io/GraphRAG/index/outputs/
第四步:Query
GraphRAG 提供三种 Query 模式:Local Search、Global Search 和 DRIFT Search,同时支持类似传统 RAG 的 Basic Search。
DRIFT(Dynamic Reasoning and Inference with Flexible Traversal) Search综合了Local和Global Search技术,准确度更高一些。
这里是DRIFT的Notebook示例
https://microsoft.github.io/GraphRAG/examples_notebooks/drift_search/
不过由于我们用的是自定义Model,并且是在python file中,还是需要做一些修改,修改代码如下
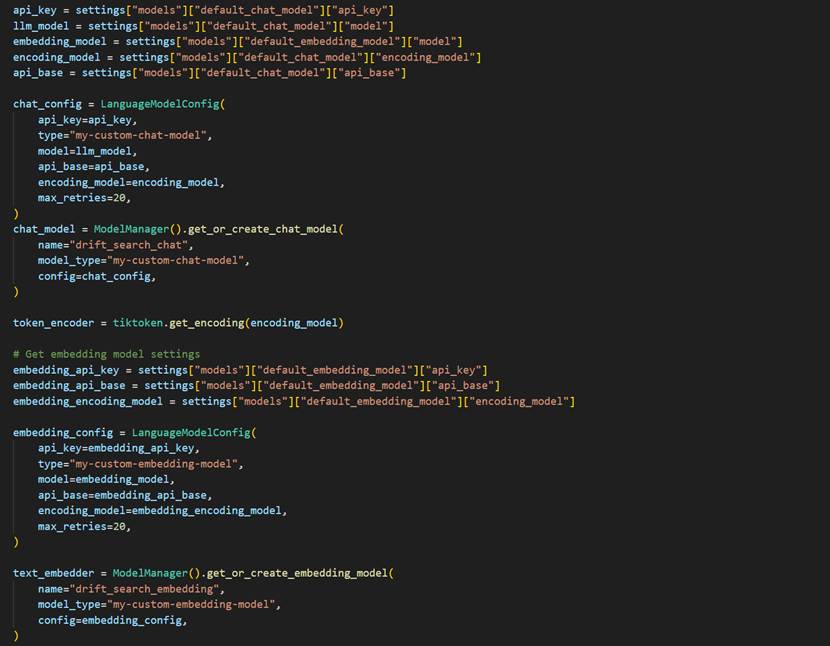
运行后就有Query结果
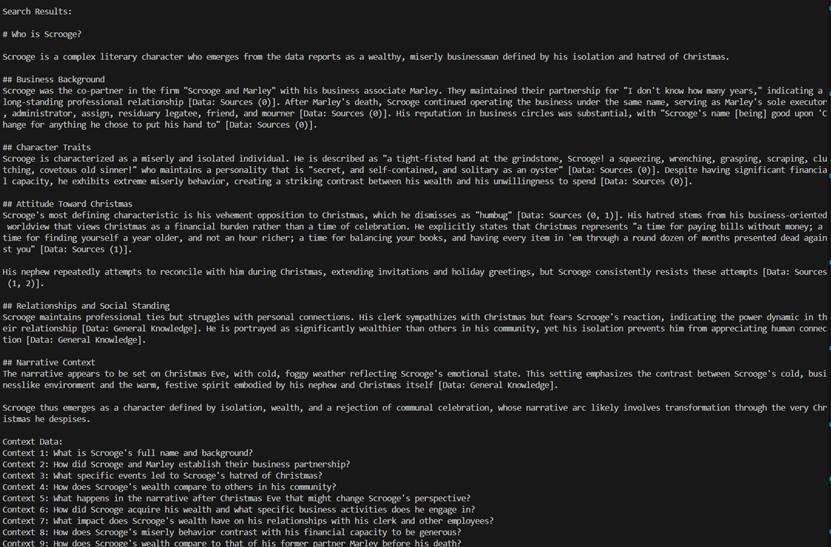
到这里整个流程就跑通了。
总体感觉
- GraphRAG对总结性问题突破了普通RAG的局限性
- GraphRAG抽取了各个实体之间的关系,对这样的问题能够很精确的回答
- 建立Indexing比较耗时,这个应该也和模型的能力和服务有关,我在使用GLM模型时经常会遇到Timeout问题,为了跑通流程,并发基本设为1
- 比较消耗Token

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)