如何使用Dynamo搭建百万用户级别大模型完整服务(附服务部署详细步骤)
大型语言模型(LLMs)——参数量超过数千亿的模型现在已经变得司空见惯。这些庞大的模型究竟是高效地服务于数百万用户的?在幕后又有哪些关键的技术细节?今天我决定为你一步步拆解这些架构。让我们一起来看看,如何将真实世界中的LLM推理服务带给大众。关注公众号,拷贝并后台发送"",获取大模型服务部署详细步骤。
大型语言模型(LLMs)——参数量超过数千亿的模型现在已经变得司空见惯。
这些庞大的模型究竟是如何高效地服务于数百万用户的?在幕后又有哪些关键的技术细节?
今天我决定为你一步步拆解这些架构。
让我们一起来看看,如何将真实世界中的LLM推理服务带给大众。
关注公众号,拷贝并后台发送"大模型服务部署",获取大模型服务部署详细步骤
第一步:清晰理解问题
我们先快速梳理一下大模型推理在扩展过程中面临的具体问题:
- GPU 利用率低:由于工作负载不匹配,GPU 经常处于闲置状态。
- KV 缓存效率低:频繁重新计算 KV 缓存会浪费大量资源。
- 内存瓶颈:GPU 内存很快被填满,限制了上下文长度和并发能力。
- 网络延迟:在多个 GPU 和节点之间传输数据会引入延迟。
- 动态流量需求:静态的 GPU 分配无法应对不断变化的工作负载。
接下来,我们看看如何系统性地解决这些问题。
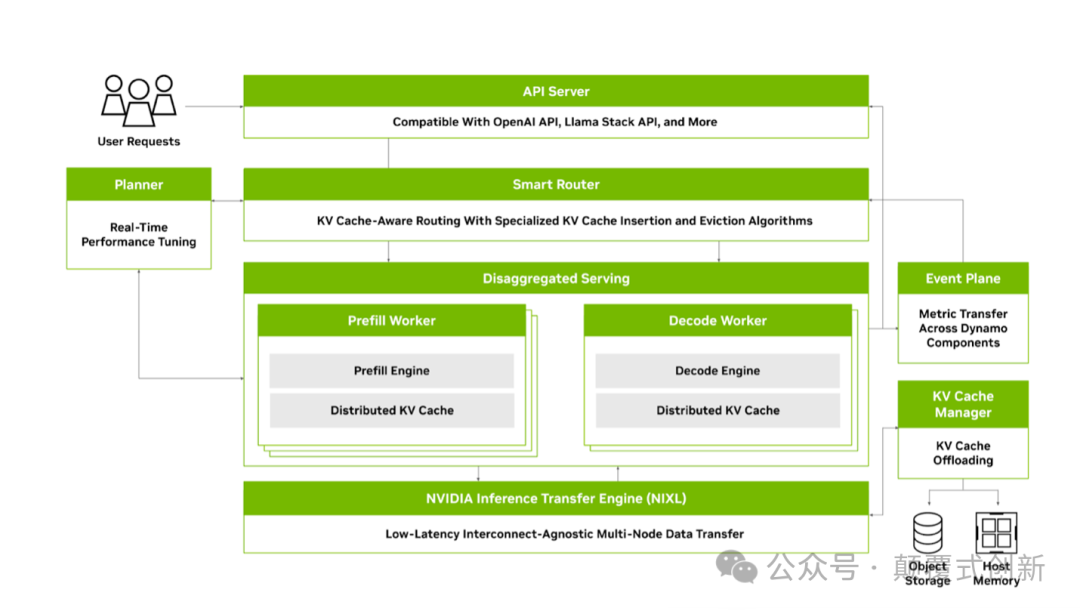
第2步:Dynamo 的架构概览
为了应对这些挑战,架构设计需要是模块化的,并包含以下四个关键组件:
- 分离式预填充和解码(Disaggregated Prefill and Decode)
- 动态GPU调度器(Dynamic GPU Scheduler,简称 Planner)
- KV缓存感知路由(KV Cache-Aware Routing,简称 Smart Router)
- 分层KV缓存管理器(Hierarchical KV Cache Manager)
- NVIDIA推理传输库(NVIDIA Inference Transfer Library,简称 NIXL)
我知道如果你对这些概念不熟悉,这个列表可能看起来有点抽象。
别担心,我会一步步地详细讲解每个组件,然后再深入探讨。
1. 分离 Prefill 和 Decode 阶段
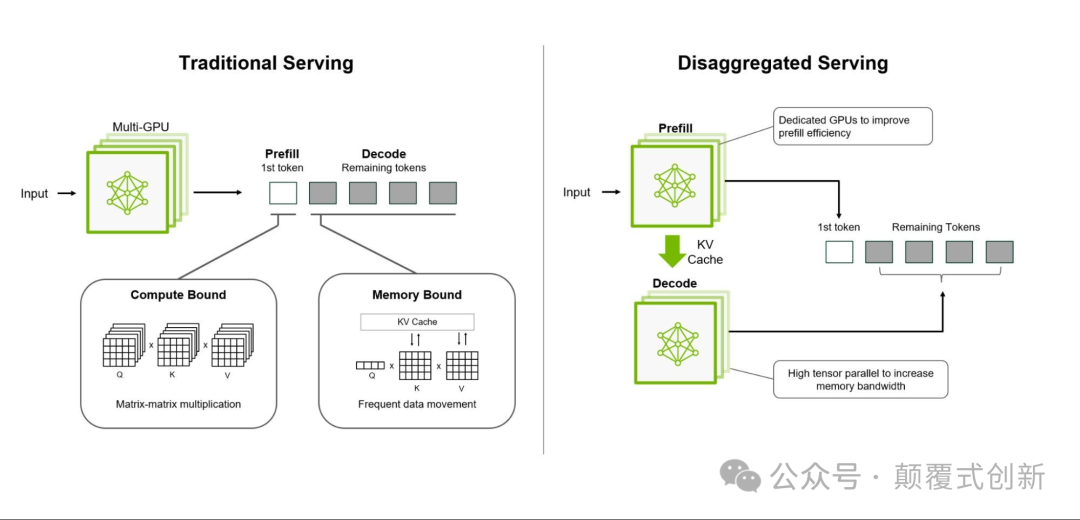
LLM 推理分为两个阶段:
-
Prefill 阶段
:将用户的提示转换为初始嵌入(embeddings)——这个阶段计算量很大。
-
Decode 阶段
:生成后续的 token——这个阶段对内存需求高,同时对延迟也很敏感。
如果在同一块 GPU 上混合处理这两个阶段,会导致频繁的空闲周期。
因此,我们需要将 GPU 分成两个专门的池子——一个专注于 Prefill(计算密集型),另一个专注于 Decode(内存密集型)。
这种分离可以确保 GPU 始终以最佳状态工作。
通过这种设置,你通常可以实现:
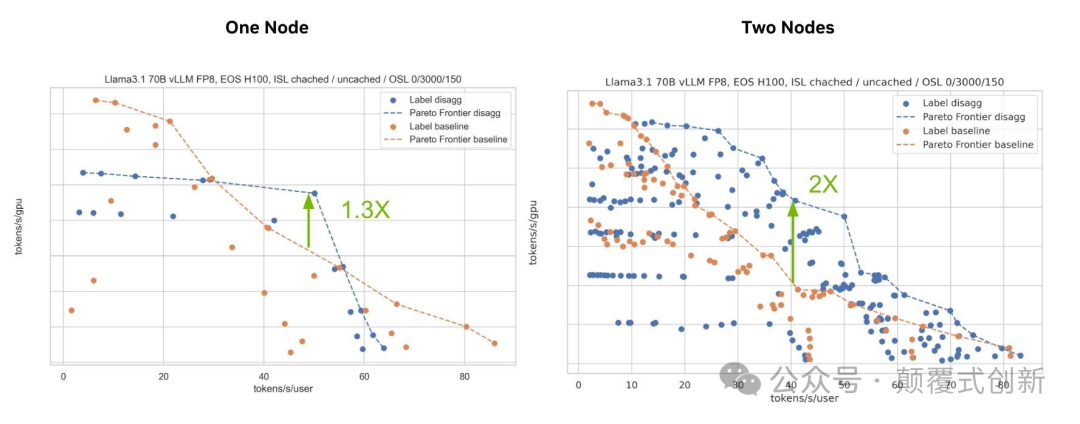
- 在单节点设置中,GPU 吞吐量提升约 30%
- 在多节点设置中,吞吐量提升超过 2 倍
2. 动态GPU调度(Planner)
推理任务的负载是波动的。
传统的静态GPU分配方式要么会浪费资源,要么在突发需求激增时无法应对。
这就是为什么我们需要一个动态调度器(Planner),它能够持续监控实时的GPU使用情况、请求队列长度以及延迟指标。
这个调度器应该能够在预填充(prefill)和解码(decode)池之间动态、实时地重新分配GPU资源——而且要在几秒内完成——以适应不断变化的工作负载。
通过这种方式,我们可以在不可预测的工作负载下保持一致的延迟,同时通过避免GPU闲置来减少资源浪费。
3. KV Cache-Aware Routing(智能路由器)
重复计算KV缓存状态(这是生成token所需的)会消耗不必要的GPU资源,并增加延迟。
我们需要一个智能路由器,它可以对传入的提示进行指纹识别,并将请求路由到已经持有相关KV缓存的GPU上。
这个路由器需要记住之前的计算发生在哪里,并巧妙地利用这些记忆。
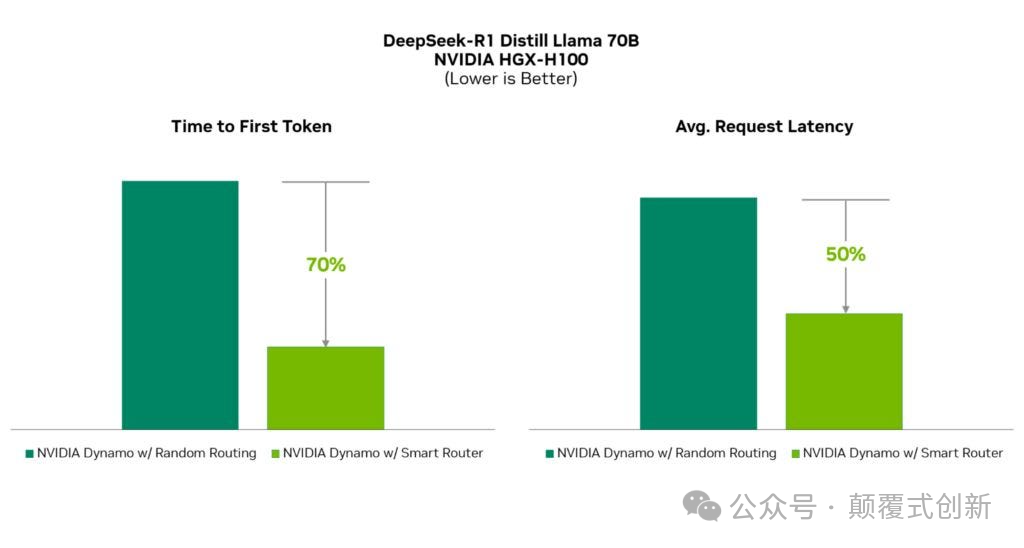
通过实现这一点,我们可以将首次生成Token的时间(TTFT)加速3倍,并将延迟平均减少2倍。
这意味着由于最小化KV缓存的重复计算,我们可以显著节省带宽。
4. 分层KV缓存管理
GPU内存很快会成为大上下文模型或高并发场景的瓶颈。
将所有KV缓存都保存在GPU内存中既昂贵又低效。
我们需要一种分层的缓存存储方法,可以使用以下三种类型的键:
- 热键(Hot keys):频繁使用的缓存存储在快速的GPU内存(HBM)中。
- 暖键(Warm keys):中等频率使用的缓存存储在系统内存(CPU RAM)中。
- 冷键(Cold keys):很少使用的缓存存储在SSD或对象存储中。
这种多层次的策略将不太重要的缓存数据从宝贵的GPU内存中移开。
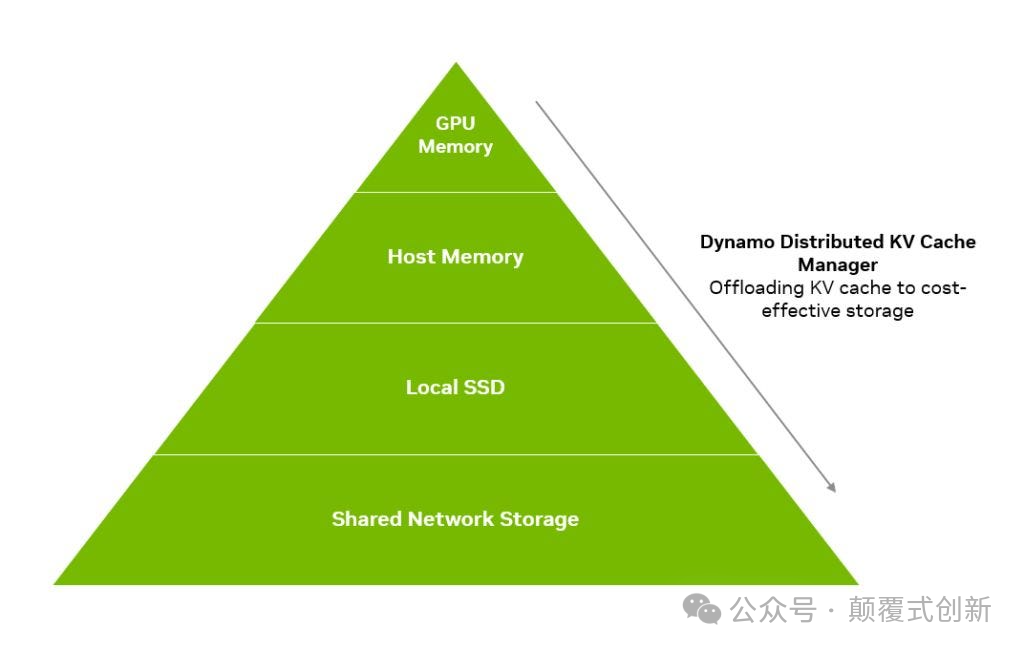
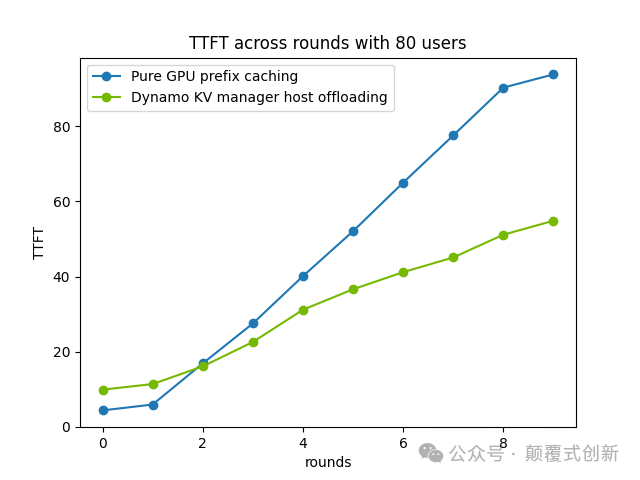
在实际场景中,仅将缓存卸载到CPU内存就可以将TTFT(首次令牌生成时间)提高约40%,并且可以在不增加额外GPU的情况下支持更长的上下文长度和更多的并发请求。
5. 高效数据传输 (NIXL)
在分布式环境中,在GPU节点、CPU内存或存储层之间传输数据会引入延迟和复杂性。
传统的通信库并未针对这些动态推理工作负载进行优化。
NIXL(NVIDIA Inference Transfer Library)通过抽象和加速在各种内存层级之间的数据传输(包括GPU、CPU、SSD和网络存储),以最小的开销实现高效传输。它能够智能地批量处理请求,减少同步延迟。
这显著降低了延迟并提升了吞吐量。
同时,它通过抽象复杂的内存层级和数据传输,简化了多节点部署的过程。
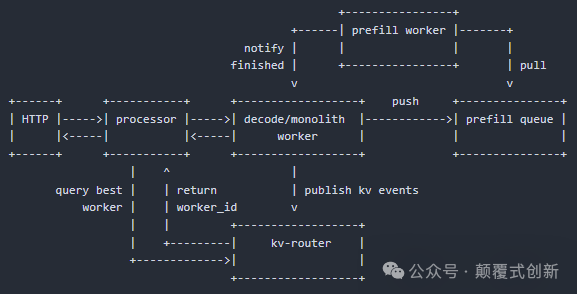
第三步:Dynamo 组件如何协同工作 - 一个实际例子
从图表中可以看到,NVIDIA 已经将所有这些组件集成到了 Dynamo 中。Dynamo 是一个高吞吐量、低延迟的推理框架,专为在多节点分布式环境中服务生成式 AI 和推理模型而设计。
为了更直观地理解这些组件如何协同工作,来看一个简单的场景:
- 用户请求到达,工作负载是混合的——有些是短提示(prefill 负载较重),有些是长对话(decode 负载较重)。
- 规划器识别负载——短而多的请求迅速让 Prefill GPU 饱和,而 Decode GPU 则处于未充分利用的状态。
- 规划器动态重新分配 GPU,在几秒内将空闲的 Decode GPU 转移到 Prefill 池中,从而稳定延迟和吞吐量。
- 智能路由器对提示进行指纹识别,将请求定向到已经持有匹配 KV 缓存的 GPU,最大限度地减少重复计算。
- KV 缓存管理器分层缓存——将频繁使用的缓存保存在 GPU 内存中,而将较冷的缓存卸载到 CPU RAM 或 SSD,从而释放宝贵的 GPU 带宽。
- NIXL 快速移动数据,在网络和内存层级之间传输数据,确保节点间通信流畅且延迟最小。
通过这样一个实际的流水线,Dynamo 即使在用户需求动态波动的情况下,也能确保推理过程始终高效稳定。
Dynamo
在一步步了解 Dynamo 的过程中,会发现它为什么是一项重要的创新。
Dynamo 是一个与推理引擎无关的工具,它支持 TRT-LLM、vLLM、SGLang 等多种引擎。
Dynamo 主要通过其 CLI(命令行界面)来使用。
目前它支持以下 4 个子命令:
- 🏃 dynamo run: 快速启动一个服务器,用于实验指定的模型、输入和输出目标。
- 🫴 dynamo serve: 在本地组合一个 worker 图并进行服务。
- 🔨 (实验性) dynamo build: 将整个图或部分图容器化为多个容器。
- 🚀 (实验性) dynamo deploy: 使用 Helm charts 或自定义操作符部署到 K8(Kubernetes)。
- ☁️ (实验性) dynamo cloud: 与您的 Dynamo 云服务器交互。
作为研究人员和工程师,信理解这些细节不仅能加深我们的实践技能,还能激发我们创造更智能、更高效的系统。
需要的小伙伴可在下方获取,大模型服务部署详细步骤!!
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

{kind=link}
所有评论(0)