7B小模型逆袭32B大模型!AgentEvolver框架让AI智能体自我进化,彻底告别人工标注数据!
AgentEvolver是阿里巴巴通义实验室发布的AI智能体训练框架,通过自提问、自导航、自定责三大机制,解决了传统强化学习数据贵、探索难、反馈慢的痛点。该框架让AI像人类一样在实践中学习,通过自我提问生成任务,利用经验池提升探索效率,并引入LLM Judge提供细粒度过程奖励。实验证明,7B参数模型使用该框架后性能超越32B大模型,训练效率提升55%-67%,标志着AI智能体开发从人工流程式向模
2025年11月,Gemini 3.0正式对外发布,可以说在基础模型快速迭代和发展的今天,AI智能体的研发方向也愈加的清晰。那么,在构建基于 LLM 的智能体(Agent)时,开发者往往面临一个“先有鸡还是先有蛋”的死循环: 想要训练一个厉害的 Agent,你需要海量高质量、长链路的复杂任务数据;但想要获得这些数据,你又需要雇佣昂贵的人力专家,或者已经拥有一个很厉害的 Agent 去生成。
传统的强化学习(RL)更是面临三大痛点:
- 数据贵: 手工构建任务极其耗时。
- 探索难: 在复杂环境中,Agent 像无头苍蝇一样随机乱撞,效率极低。
- 反馈慢: 只有任务彻底完成才有奖励(Sparse Reward),中间做对了什么全靠猜。
近日,阿里巴巴通义实验室发布了最新框架 AgentEvolver。这套系统彻底打破了上述僵局,它不依赖昂贵的人工数据,而是让 LLM 作为一个“自驱力”极强的学生,通过自我提问、自我导航、自我归因,实现了能力的螺旋式上升。
更令人惊讶的是: 实验显示,仅有 7B 参数的模型在使用该框架后,在 AppWorld 和 BFCL 榜单上甚至超越了 32B 参数的大模型!
👉 **论文链接:**arXiv:2511.10395👉 **代码仓库:**GitHub/AgentEvolver
一、 AgentEvolver 的核心理念
AgentEvolver 的核心思想非常像人类的学习过程:“在实践中发现问题,在复盘中总结经验。”
它构建了一个自动化闭环,由三个协同工作的机制组成:
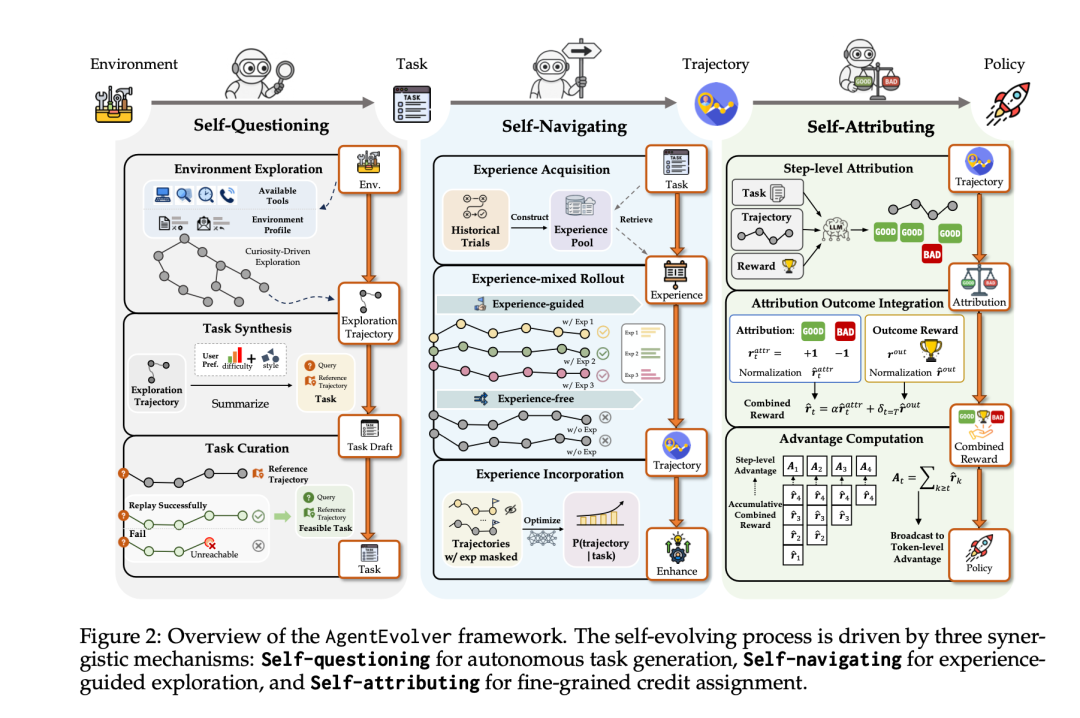
(图注:AgentEvolver 的三大核心支柱:自提问、自导航、自定责)
- Self-Questioning (自提问): 解决“没题做”的问题。
- Self-Navigating (自导航): 解决“怎么做”的问题。
- Self-Attributing (自定责): 解决“做得对不对”的问题。
二、 拆解三大黑科技
1️⃣ 自提问 (Self-Questioning):好奇心驱动的任务生成
如果没有训练数据怎么办?AgentEvolver 选择让模型去“探索”环境。
- 环境探索: Agent 像一个好奇的玩家,在环境中随机操作(基于环境配置文件),生成一系列操作轨迹。
- 逆向工程: 看着自己刚刚乱操作生成的结果,Agent 会反问自己:“我刚才这通操作,到底解决了什么问题?” —— 从而反向生成用户的 Query(查询指令)。
- 自我验证: 系统会再派一个 Agent 去尝试执行这个新生成的任务,如果成功,这就是一条高质量的合成训练数据。
结论: 彻底告别手工编写 Prompt 和任务描述。
2️⃣ 自导航 (Self-Navigating):带着“攻略”去探险
传统的 RL 训练是随机探索,效率极低。AgentEvolver 引入了“经验池”机制。
- 提取经验: 系统会从历史的成功或失败案例中,提取出自然语言形式的“经验”(例如:“在调用搜索API前,记得先检查网络连接”)。
- 混合 Rollout 策略: 在采集数据时,一部分让模型自己跑(Vanilla),另一部分把检索到的“经验”塞给模型做参考(Experience-Guided)。
💡 关键技术点:Experience Stripping (经验剥离)这是一个非常有意思的工程细节! 在推理/采样阶段,模型看着“经验攻略”做题;但在训练/更新参数阶段,系统会把这些“攻略”文本删掉。为什么要删? 为了防止模型“作弊”依赖提示词。通过剥离经验,强迫模型将攻略里的逻辑内化为自己的模型参数,真正学会推理,而不是学会“抄答案”。
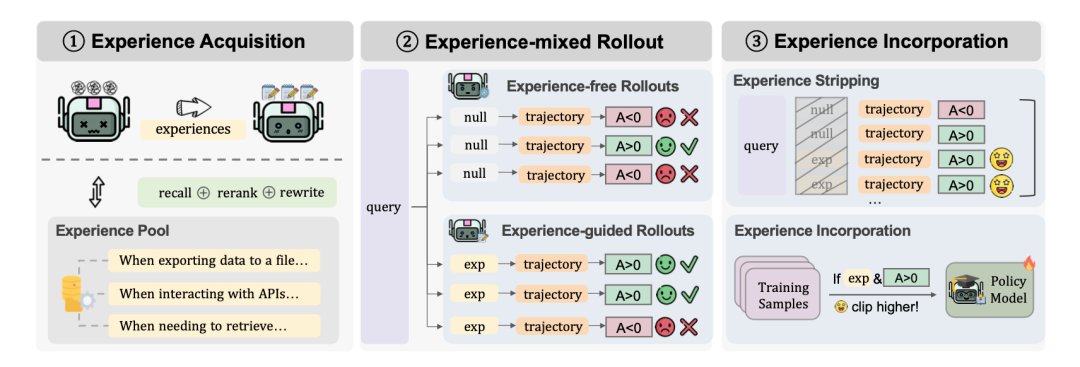
(图注:经验获取 -> 混合采样 -> 经验剥离训练)
3️⃣ 自定责 (Self-Attributing):细粒度的“过程奖励”
在长达几十步的 Agent 操作中,如果只在最后一步给个 Pass/Fail,模型很难学好。
AgentEvolver 引入了一个 LLM Judge 充当“老师”:
- 步步为营: LLM 会回顾整个轨迹,对每一步操作进行打分(GOOD/BAD)。
- 双流奖励: 最终的奖励信号 = 过程分 (LLM 打分) + 结果分 (环境反馈)。
- 独立归一化: 两套分数独立处理,避免互相干扰。
这使得 Agent 即使最终任务失败,也能知道中间哪几步是做对的,极大提高了样本效率。
三、 强大的工程基建
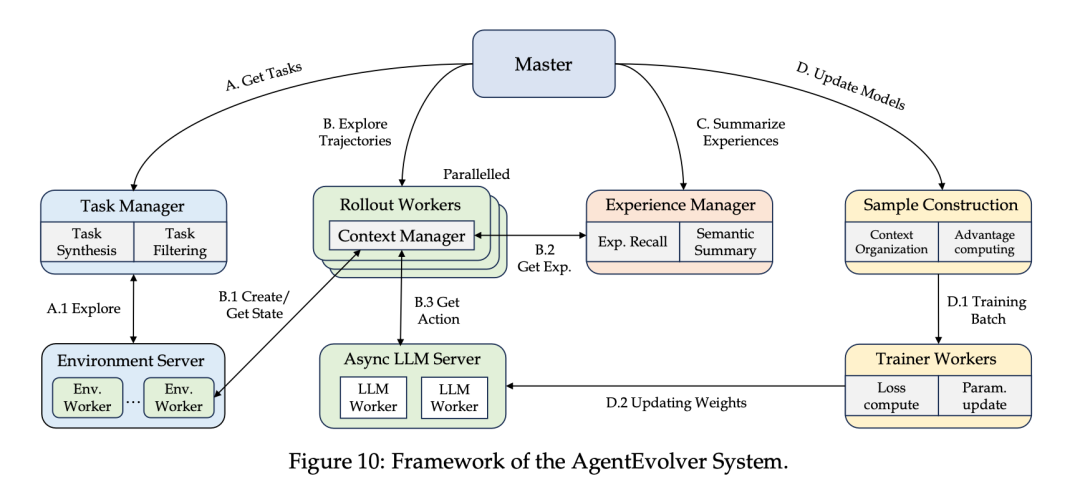
为了支撑这套复杂的自我进化流程,团队设计了非常扎实的底层架构:
- Context Manager (上下文管理器): 针对长链路任务,设计了多种显存管理模板,支持滑动窗口和自我管理的显存压缩,解决了 LLM 处理超长 Context 的痛点。
- Ray 分布式架构: 环境与训练解耦,支持大规模并行训练,确保系统的高并发和安全性。
四、 实验结果:以小博大
在 AppWorld (代码/APP交互) 和 BFCL v3 (函数调用) 两个高难度基准测试中,AgentEvolver 表现亮眼:
- 逆袭大模型: 7B 参数的 AgentEvolver 在综合评分上击败了 Qwen2.5-32B 等更大参数的模型。
- 样本效率飙升: 得益于“自定责”机制,达到同样性能所需的训练步数减少了 55% - 67%。
- 合成数据有效: 实验证明,仅使用模型“自提问”生成的合成数据训练,效果几乎等同于使用昂贵的人工标注数据。
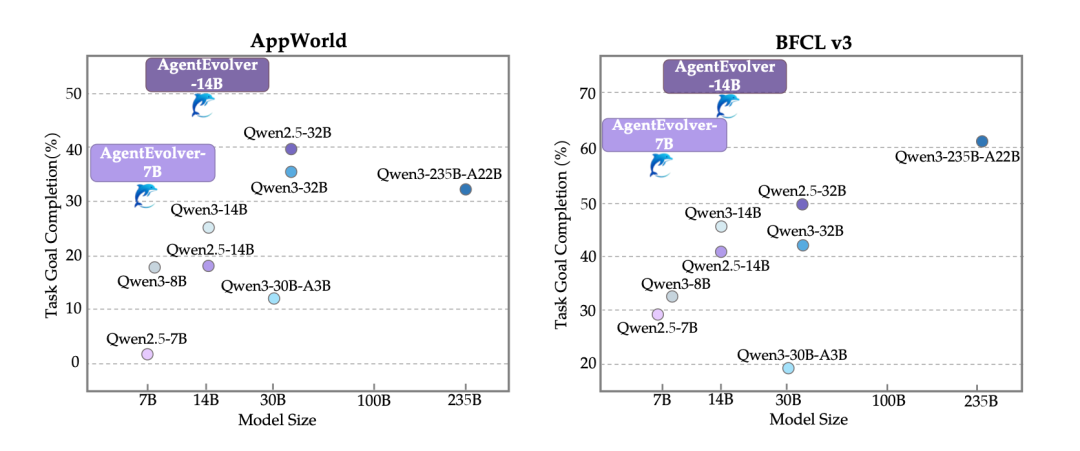
(图注:AgentEvolver-14B 在各项指标上大幅领先基线模型)
五、 写在最后
AgentEvolver 的出现,标志着 Agent 开发范式正在从“人工流程式”向“模型自驱式”转变。
对于开发者而言,这意味着:
- 冷启动更简单: 面对新环境,不需要先痛苦地造数据。
- 成本更低: 用更小的模型、更少的数据,达到更好的效果。
- 上限更高: Agent 不再只是模仿人类的操作,而是通过不断的自我探索和总结,内化出解决问题的通用逻辑。
“授人以鱼不如授人以渔”,AgentEvolver 正是教会了 AI 如何自己去“钓鱼”。
六、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献361条内容
已为社区贡献361条内容

所有评论(0)