详解 Transformer 中的两大核心机制:掩码多头注意力与教师强制训练
本文深入解析Transformer模型的两项核心技术——掩码多头注意力机制和教师强制训练。掩码多头注意力通过并行计算多个注意力头,结合填充掩码和序列掩码处理无效字符和未来信息,实现精准的上下文建模。教师强制训练则通过使用真实序列指导解码器训练,加速模型收敛但可能引发暴露偏差。这两项技术共同构成了Transformer模型在NLP任务中卓越性能的基础,为理解BERT、GPT等先进模型提供了关键理论基
在 Transformer 模型中,掩码多头注意力机制和教师强制训练是保证模型性能的核心技术。前者让模型能精准捕捉序列中的上下文关系,后者则优化了训练过程的效率与稳定性。本文结合实例通俗解读这两个概念,包含关键公式和原理分析,并引用相关图片辅助理解。
一、掩码多头注意力机制
1.1 产生背景
在序列任务(如机器翻译、文本生成)中,解码器需要实现并行计算(一步预测所有目标单词)与自回归特性(预测第iii个单词时只能依赖第 1 到i−1i-1i−1个单词)的兼容,核心矛盾在于:
-
解码第 1 个单词时,仅能关注第 1 个单词的特征;
-
解码第iii个单词时,仅能关注第 1 到iii个单词的特征;
-
需严格避免模型 “偷看” 未来位置(第i+1i+1i+1个及之后)的信息。
为此,引入掩码(Masked)操作,通过掩码矩阵遮挡未来信息,保证自回归属性。其中,用于防止 “偷看” 未来信息的掩码被称为因果掩码。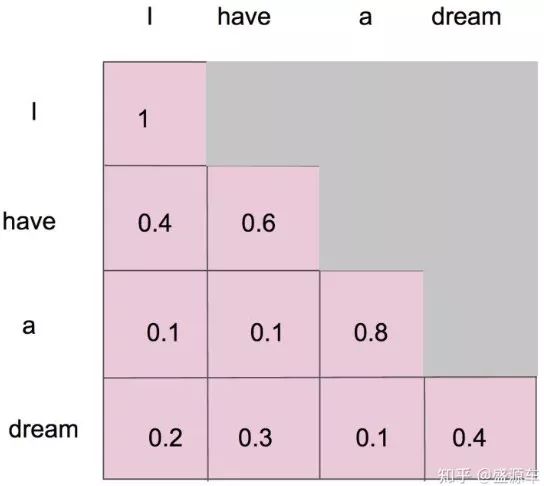
1.2 内部结构
掩码多头注意力是解码器中第一个多头注意力层,其核心是在标准自注意力计算中增加掩码(Mask)步骤,流程为:先施加掩码,再通过 Softmax 得到归一化注意力权重。
计算公式为:
Z=softmax(QKTdq+M)VZ = \text{softmax}\left( \frac{Q K^T}{\sqrt{d_q}} + M \right) VZ=softmax(dqQKT+M)V
其中,M∈Rn×nM \in \mathbb{R}^{n \times n}M∈Rn×n为与注意力分数矩阵同形状的掩码矩阵(nnn为序列长度)。
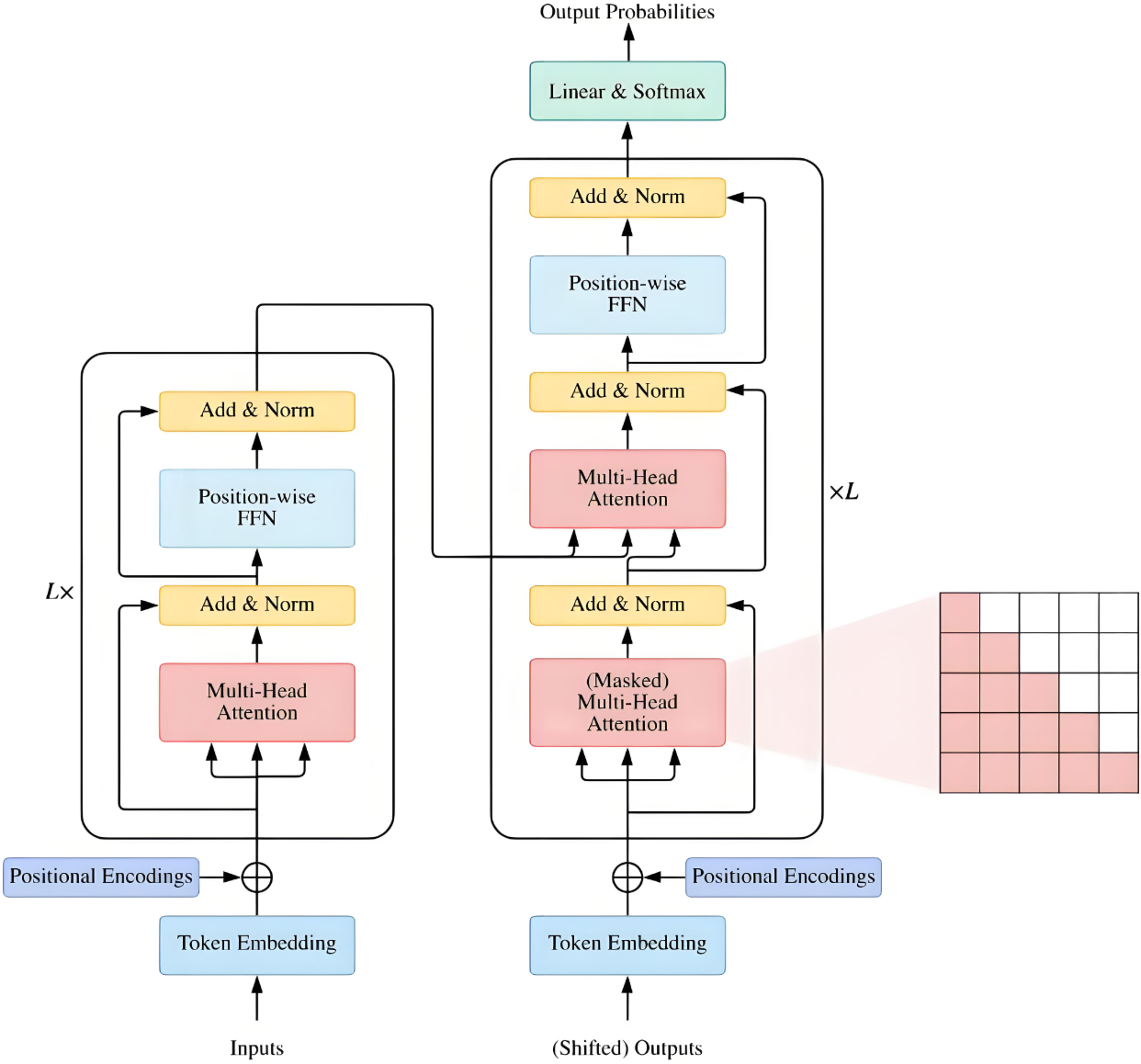
内部结构:
](https://i-blog.csdnimg.cn/direct/fcf8674773484be3bf765073e67248d3.png)
1.3 掩码矩阵(MMM)的类型
掩码矩阵的作用是通过修改注意力分数,控制模型可关注的位置,主要分为两种类型:
1.3.1 填充掩码(Padding Mask)
目的:处理批量数据中长度不一的序列,忽略无意义的<pad>填充符号。
取值规则:
-
有效位置(非
<pad>):Mij=0M_{ij} = 0Mij=0(不影响注意力分数); -
填充位置(
<pad>):Mij=−∞M_{ij} = -\inftyMij=−∞(或极小负数,如−1e9-1e9−1e9)。
工作原理:填充位置的注意力分数经 “分数 +−∞-\infty−∞” 后为−infty-infty−infty,Softmax 后权重为 0,使填充符号不贡献到输出中。
示例:对于序列["猫", "坐", "<pad>"],掩码矩阵中第三行和第三列对应位置为−∞-\infty−∞。
1.3.2 前瞻掩码(Look-ahead Mask / 因果掩码)
目的:保证解码器的自回归特性,预测第iii个位置时仅能关注第 1 到iii个位置,不可 “偷看” 未来(j>ij > ij>i)的信息。
取值规则:
-
上三角区域(j>ij > ij>i,未来位置):Mij=−∞M_{ij} = -\inftyMij=−∞;
-
下三角及对角线(j≤ij \leq ij≤i,过去及当前位置):Mij=0M_{ij} = 0Mij=0。
工作原理:未来位置的注意力分数经 “分数 +−∞-\infty−∞” 后为−infty-infty−infty,Softmax 后权重为 0,使每个位置的输出仅依赖于其之前(包括自身)的位置。
示例:长度为 3 的序列[A, B, C]的前瞻掩码矩阵为:
M = [
[0, -inf, -inf],
[0, 0, -inf],
[0, 0, 0]
]
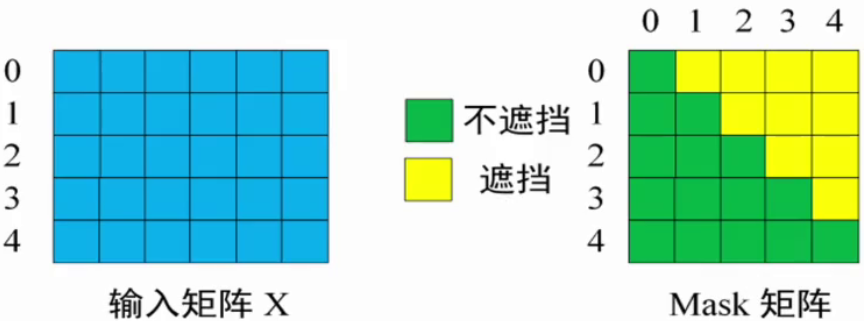
1.4 实现步骤(以序列<Begin> I have a cat为例)
设序列<Begin> I have a cat对应索引为0,1,2,3,4,实现步骤如下:
第一步:准备输入与掩码矩阵
-
解码器输入矩阵XXX:包含 5 个单词的表示向量;
-
掩码矩阵MMM:5×55 \times 55×5的上三角矩阵(符合前瞻掩码规则)。
第二步:计算注意力分数(与掩码无关)
通过输入矩阵XXX计算QQQ(查询)、KKK(键)、VVV(值),并计算QKTQK^TQKT(未加掩码的原始注意力分数)。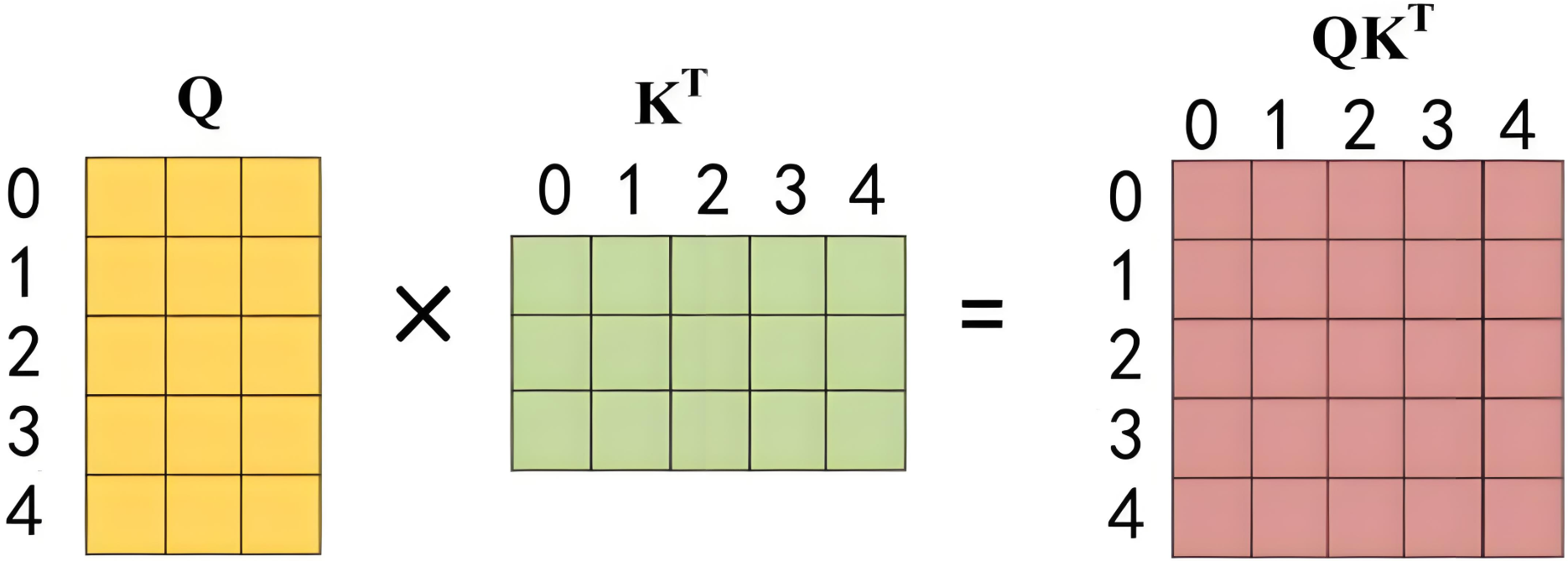
第三步:施加掩码并归一化
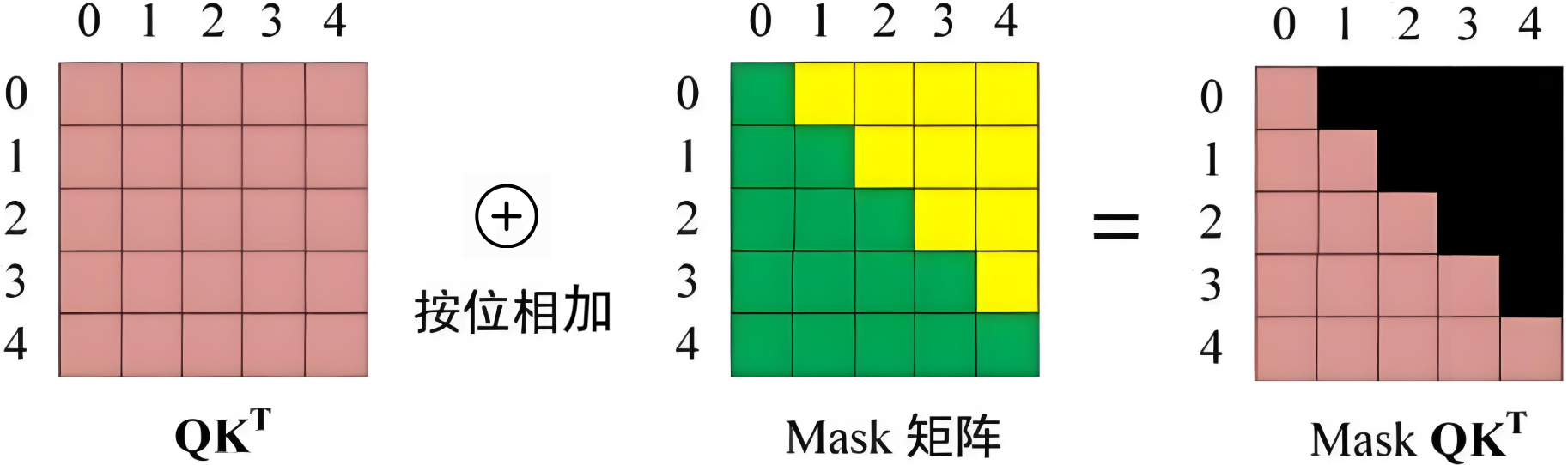
将掩码矩阵MMM加到QKTQK^TQKT上,再通过 Softmax 得到归一化注意力权重。此时:
-
每行和为 1;
-
位置iii在位置j>ij > ij>i上的注意力权重为 0(被掩码遮挡)。
掩码矩阵的数学表示:
Mij={0,if i≥j−∞,if i<jM_{ij} = \begin{cases} 0, & \text{if } i \geq j \\ -\infty, & \text{if } i < j \end{cases}Mij={0,−∞,if i≥jif i<j
本示例的掩码矩阵为:
M=(0−∞−∞−∞−∞00−∞−∞−∞000−∞−∞0000−∞00000)M = \begin{pmatrix} 0 & -\infty & -\infty & -\infty & -\infty \\ 0 & 0 & -\infty & -\infty & -\infty \\ 0 & 0 & 0 & -\infty & -\infty \\ 0 & 0 & 0 & 0 & -\infty\\ 0 & 0 & 0 & 0 & 0\end{pmatrix}M= 00000−∞0000−∞−∞000−∞−∞−∞00−∞−∞−∞−∞0
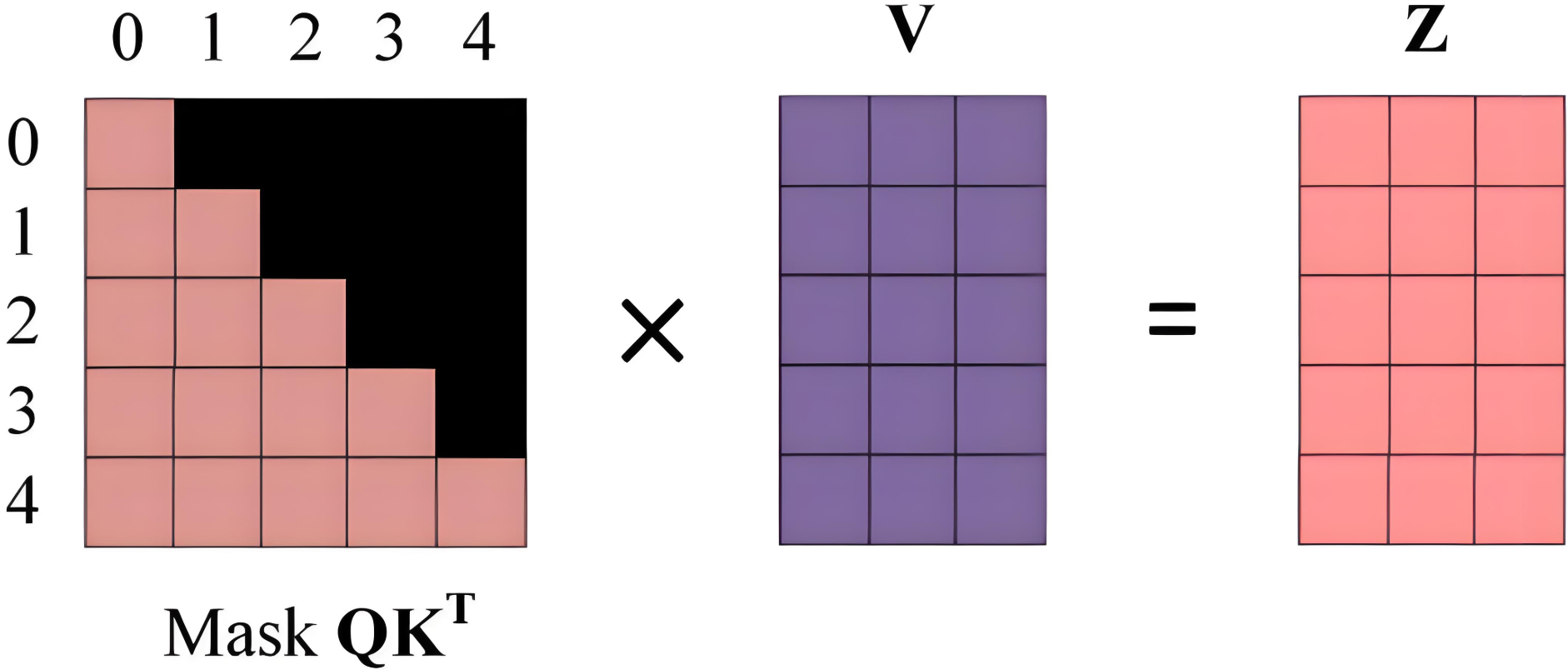
第四步:计算输出特征
将掩码后的注意力权重与VVV相乘,得到输出ZZZ:
-
位置 1 的输出Z1Z_1Z1仅包含位置 1 的信息;
-
位置 2 的输出Z2Z_2Z2包含位置 1 和 2 的信息;
-
以此类推,确保每个位置的输出仅依赖于历史信息。
1.5 编码器与解码器中掩码的差异
| 特性 | Transformer Encoder | Transformer Decoder |
|---|---|---|
| 掩码类型 | 填充掩码 | 填充掩码 + 前瞻掩码(因果掩码) |
| 目的 | 忽略序列中的<PAD>标记,防止无效计算。 |
1. 忽略<PAD>标记(填充掩码);2. 防止 “偷看” 未来信息,保证自回归生成(前瞻掩码)。 |
| 注意力模式 | 双向注意力:每个词可关注所有输入词。 | 单向注意力:每个词仅关注自身及之前的输出词。 |
二、教师强制训练(Teacher Forcing)
2.1 什么是教师强制训练?
在序列生成任务(如机器翻译、文本生成)中,解码器的训练过程采用教师强制策略:每一步都使用训练数据中的真实前序 token 作为输入,而非模型上一步生成的 token。
例如训练 “我爱中国”→“I love China” 时:
-
生成 “I” 时,输入为
<start>(起始符); -
生成 “love” 时,输入为真实的 “I”(而非模型可能生成的错误词,如 “me”);
-
生成 “China” 时,输入为真实的 “I love”。
用公式表示解码器第 ttt 步的输入:
xtdecoder=yt−1truex_t^{\text{decoder}} = y_{t-1}^{\text{true}}xtdecoder=yt−1true
其中 yt−1truey_{t-1}^{\text{true}}yt−1true 是训练数据中的真实前序 token。
2.2 为什么需要教师强制?
教师强制的核心作用是加速训练收敛并稳定过程:
-
训练初期,模型生成能力较弱,若使用自身生成的错误 token 作为输入,会导致错误累积,严重影响训练效果;
-
真实序列的分布更稳定,能为模型提供更可靠的梯度信息,帮助模型快速学习到正确的映射关系。
这就像教小孩学说话时,我们会用正确的词汇引导他,而不是让他一直重复错误表达。
2.3 教师强制的潜在问题与解决思路
教师强制虽然简化了训练,但存在暴露偏差(Exposure Bias):
-
训练时模型依赖真实序列,推理时却只能依赖自身生成的序列,两者的输入分布存在差异;
-
推理时一旦生成错误 token,后续生成会累积偏差,导致输出质量下降。
解决方法包括:
-
Scheduled Sampling:训练时随机用模型生成的 token 替换真实 token,逐步缩小训练与推理的差异;
-
自回归推理优化:如束搜索(Beam Search),通过保留多个候选序列减少错误累积的影响。
总结
-
掩码多头注意力:通过多头并行捕捉多维度关联,结合填充掩码和序列掩码分别处理无效字符和未来信息,是 Transformer 实现上下文建模和并行计算的核心;
-
教师强制训练:用真实序列指导解码器训练,加速收敛但存在暴露偏差,需结合推理策略优化。
这两项技术共同支撑了 Transformer 在 NLP 任务中的卓越性能,是理解 BERT、GPT 等模型的基础。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)