一文讲清:图像token压缩方法概述
本文系统梳理了图像token压缩的四种方法:基于变换的方法通过调整token尺寸和维度实现压缩,包括pixel unshuffle、池化/插值和卷积等;基于相似性的方法通过合并相似token减少数量;基于注意力的方法利用注意力分数指导token剪枝;基于查询的方法则通过prompt指导选择相关token。各类方法各有优劣,变换方法保留空间信息但压缩率低,注意力方法需权衡计算效率。文章还穿插了AI大
1. 引言
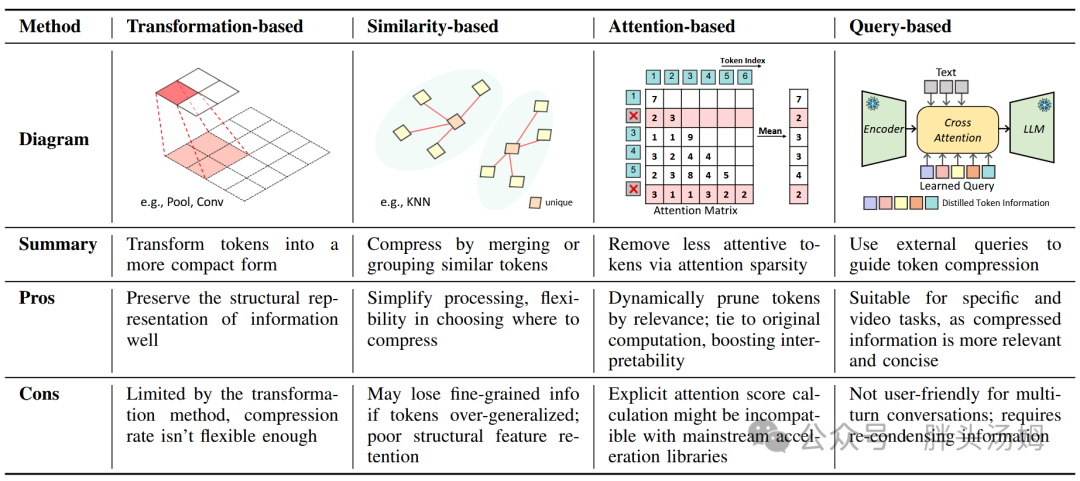
图像token压缩方法可以分为四个类别,分别是:
- 基于变换的方法:变换视觉token的长、宽、维度,来压缩token;
- 基于相似性的方法:通过利用token间内在相似性,去重或分组,来压缩token;
- 基于注意力的方法:利用多模态数据中attention的稀疏性,去掉低激活token,来指导压缩;
- 基于查询的方法:在prompt的指导下选择最相关的token。
方法的总结、优劣详见下图:
2. 基于变换的压缩方法
该方法变换视觉token的长、宽、维度,将token压缩成更紧密的形式。
2.1. pixel unshuffle
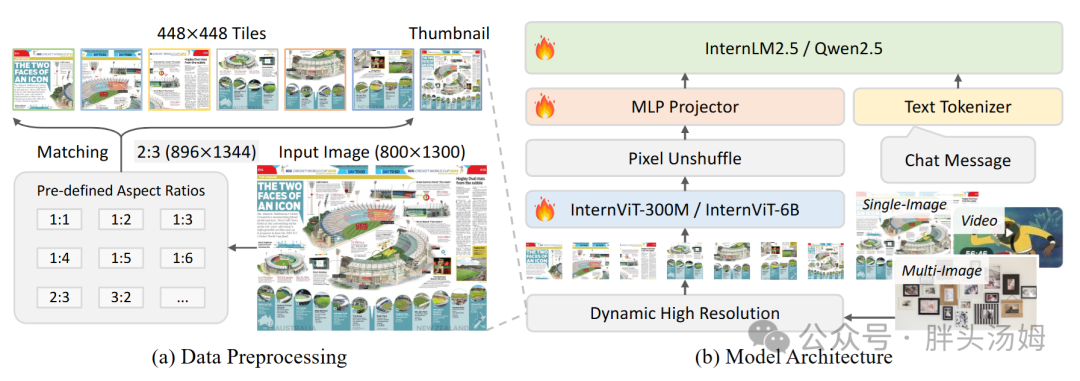
该操作将分辨率高、维度低的特征图转换为分辨率低、维度高的特征图。token数量和分辨率相关,因此该操作能有效减少token数量。

最近的工作如InternVL2[1]利用pixel unshuffle来减少视觉token数量。随后,使用MLP来对齐视觉向量维度与大模型输入向量维度,解决维度不匹配问题。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
2.2. 空间池化/插值
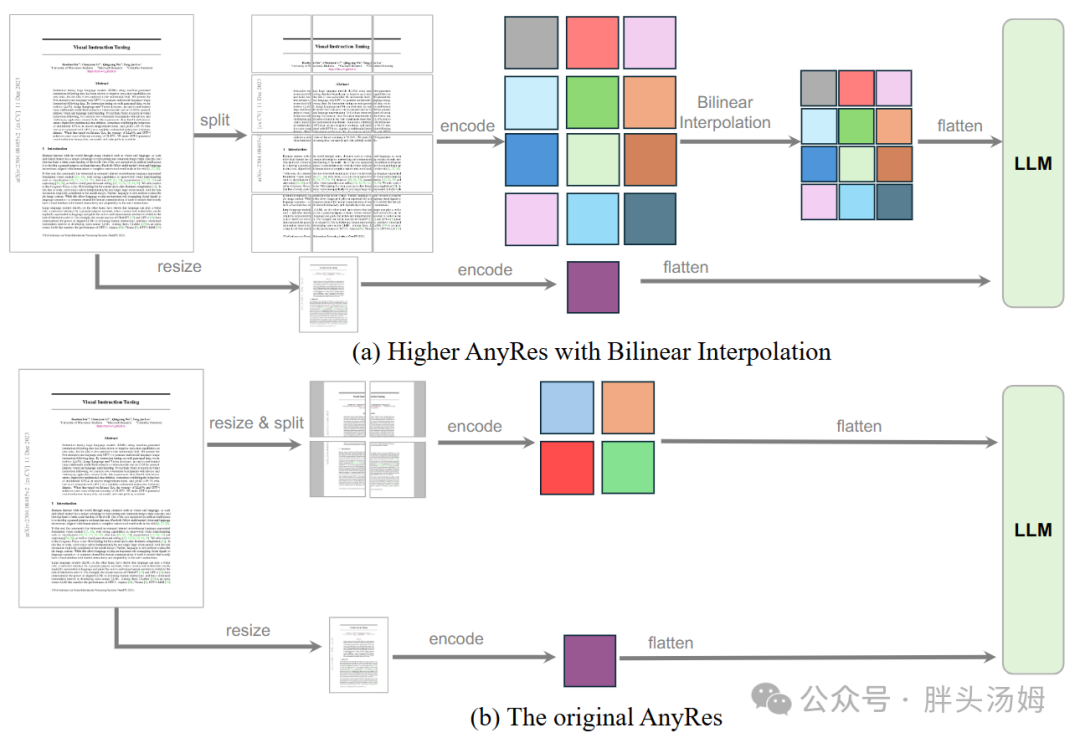
与pixel unshuffle不同,池化和插值直接对特征图进行2D降采样,不改变向量维度。

LLaVA-OneVision[2]采用双线性插值对视觉token进行2D降采样。
2.3. 空间卷积
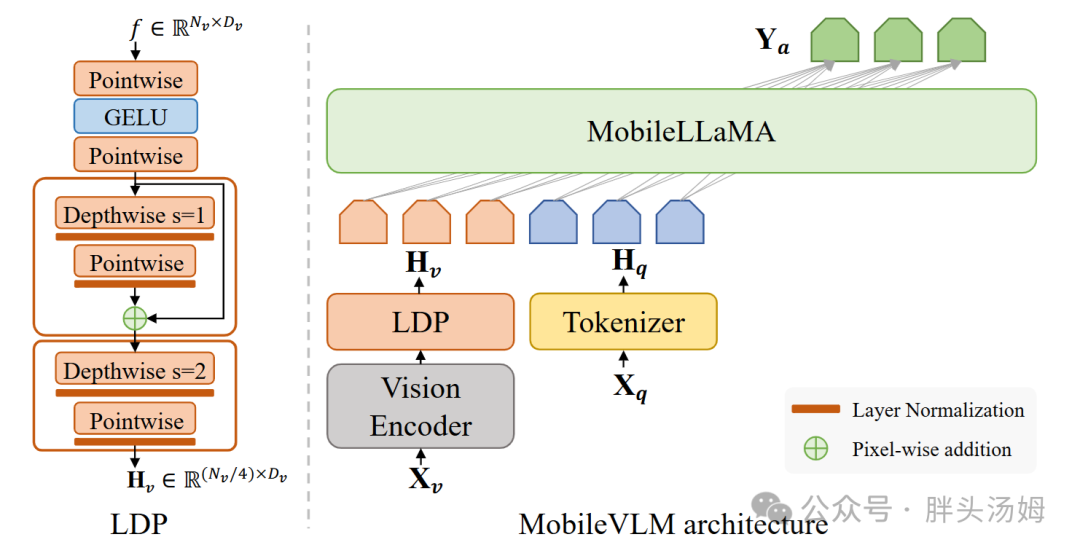
卷积操作提供了一种比池化/插值更复杂的压缩方法,通过学习局部信息来减少空间维度。

MobileVLM[3]利用了深度可分离卷积,视觉token降低75%。
2.4. 变换方法的比较分析
基于变换的压缩方法有效地利用所有图像信息,同时保留2D特征的空间局部信息。pixel unshuffle、池化和插值本质上是无参数的,对训练推理效率影响不大。相比之下,空间卷积更复杂,会引入可训练的权重。
另一个显著的区别在于如何处理特征维度:pixel unshuffle改变特征维度,需要额外接MLP来对齐LLM输入维度。相反,其他方法不会改变特征维度。
基于变换的压缩方法的压缩率不高,一般只有25%。
3. 基于相似性的压缩方法
基于相似性的压缩方法通过识别和合并相似token来减少视觉token的数量。
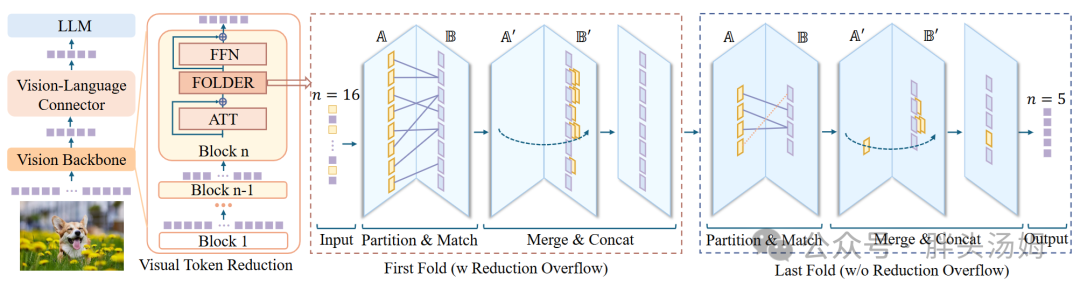
在多模态大模型时代,FOLDER在视觉编码器的最后一个注意力块中插入FOLDER模块,实现“删多少token”、“删哪些token”、“如何做token合并”,减少了传递给LLM解码器的token数量。
4. 基于注意力的压缩方法
基于注意力的压缩方法利用视觉特征的固有稀疏性来指导token剪枝。注意力分数低的token对计算结果影响小,可以被移除。
在视觉语言模型中,视觉编码器和LLM都包含transformer,因此基于注意力的压缩方法能用在视觉编码器和LLM中。
4.1. 视觉编码器中的注意力
将视觉token送入LLM之前,根据单个图像中的注意力分数来动态选择token。
根据视觉token相对于[CLS]token的注意力分数,来选择需要保留的token:

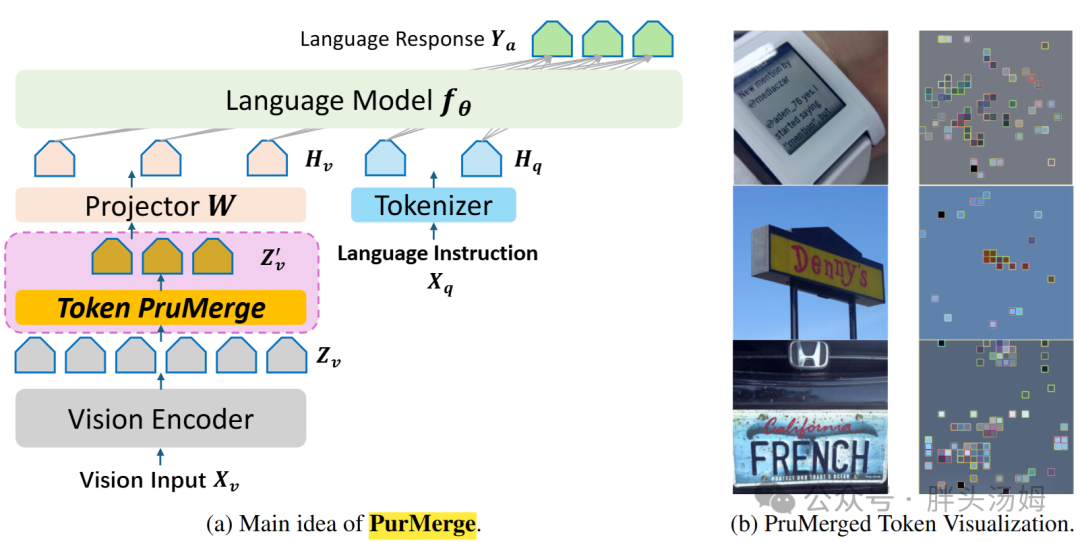
Prumerge[4]在编码器中基于 [CLS] 注意力选择视觉token的聚类中心。它使用KNN聚类和加权聚类中心更新机制来合并其余注意力较低的token。
4.2. LLM解码器中的注意力
与编码器中的注意力压缩不同,解码器中的方法侧重于利用LLMs的注意力来指导token压缩。
LLM解码器注意力考虑了LLM的本文token和视觉token,因此能更全面的进行上下文感知的token剪枝。

这种方法允许模型根据注意力分数来确定每一层的压缩比率,模型可以更细粒度、自适应得调整视觉token。
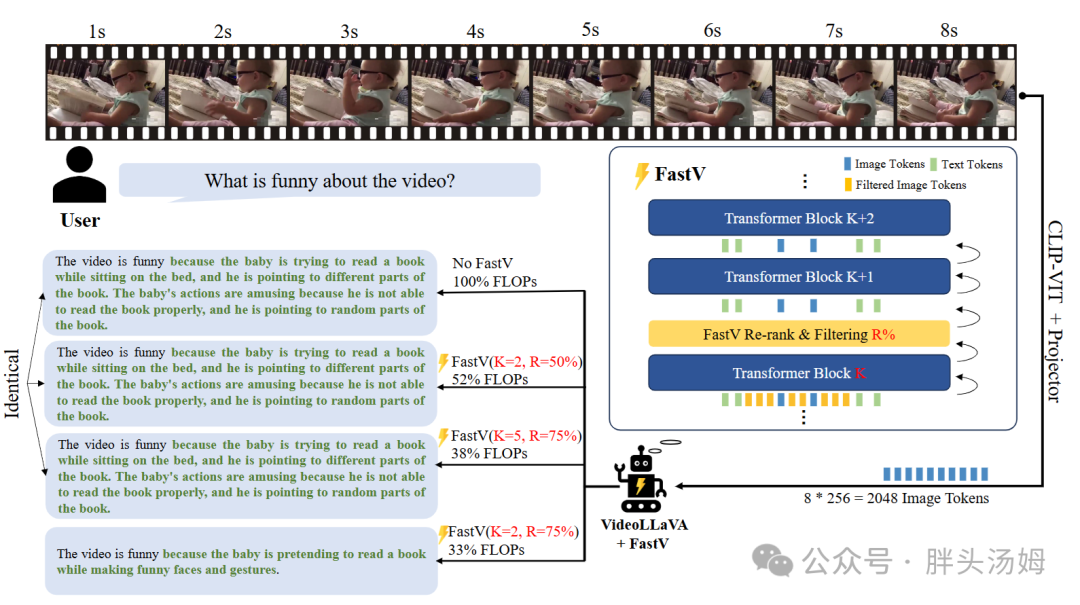
FastV[5]发现在多模态大模型中,存在视觉token的注意力分数极低的问题。在LLaVA-v1.5中,视觉token在第二层之后仅获得系统prompt的0.21%的注意力。因此,在第二层之后根据注意力分数剪枝50%的视觉token,对整体性能影响不大。
4.3. 解码器中剪枝的关键挑战
解码器中剪枝需要频繁访问LLM内部的注意力分数,往往和高度优化的加速库,例如Flash-Attention不兼容。可能存在视觉token压缩了,但加速库加速效果变差,最终效率抵消的情况。
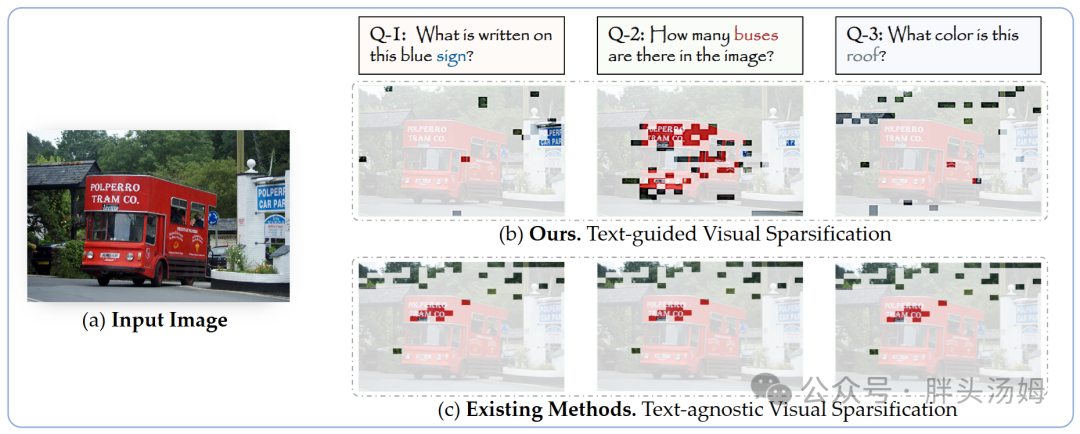
5. 基于查询的压缩方法
视觉信息通常包含大量与给定query无关的特征。基于查询的压缩方法利用query prompt来指导视觉token的压缩。
这些方法可以大致分为两种类型:(1) token蒸馏:将视觉token蒸馏成数量更少的token。(2) 跨模态选择:匹配模态对齐的视觉和文本token来压缩。
5.1. token蒸馏
token蒸馏源于多模态大模型的早期projector设计。其目标是通过蒸馏视觉令牌来学习最具文本相关性的视觉表示,从而减少视觉令牌的数量,同时实现模态对齐。
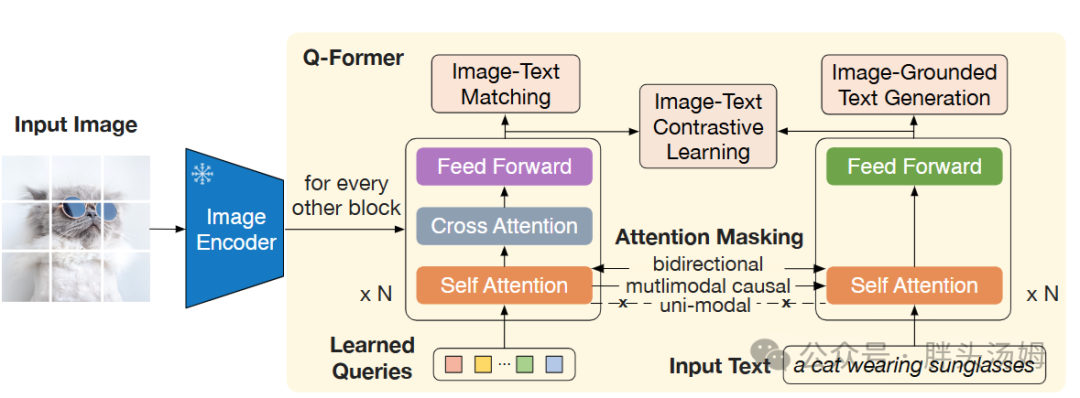
Q-Former[6]系列是一种开创性方法,使用可学习query和交叉注意力从视觉特征中提取相关的视觉表示。
5.2. 跨模态选择
跨模态选择旨在通过利用另一模态的对齐token来减少一个模态中的token数量。这种压缩通过识别并保留跨模态中最相关的信息来实现,从而实现更高效和更有效的处理。
SparseVLM[7]使用视觉令牌来预选相关文本令牌。通过将视觉模态作为初始过滤器,SparseVLM 高效地缩小了文本搜索空间,专注于与视觉内容相关的信息。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)